
url
stringlengths 14
2.42k
| text
stringlengths 100
1.02M
| date
stringlengths 19
19
| metadata
stringlengths 1.06k
1.1k
|
|---|---|---|---|
https://poznanskielegendy.pl/quarry/Oct_3163_21/
|
# Ball Mill Dimensions And Weight
### Calculate and Select Ball Mill Ball Size for Optimum Grinding
In Grinding, selecting (calculate) the correct or optimum ball size that allows for the best and optimum/ideal or target grind size to be achieved by your ball mill is an important thing for a Mineral Processing Engineer AKA Metallurgist to do Often, the ball used in ball mills is oversize “just in case” Well, this safety factor can cost you much in recovery and/or mill liner wear and tear
### Ball Mill Capacity & Dimensions -2013 - pauloabbe
BAALLLL MMIILLSLLS WEETT & D& DRRYY SSIIZEZE RREEDUCTIONDUCTION JH 3-2014 Talk with the Experts [email protected] pauloabbe Since 1911 phone 6303503012 fax 6302387584 Dry Discharge requires the use of a dust tight enclosurecloosure Shown above is a Full Housing which encloses the entire cylinder - dust seals are on the shaft
### Ball Mill - an overview | ScienceDirect Topics
The ball mill is a tumbling mill that uses steel balls as the grinding media The length of the cylindrical shell is usually 1–15 times the shell diameter (Figure 811)The feed can be dry, with less than 3% moisture to minimize ball coating, or slurry containing 20–40% water by weight
### TECHNICAL NOTES 8 GRINDING R P King
the mill is used primarily to lift the load (medium and charge) Additional power is required to keep the mill rotating 813 Power drawn by ball, semi-autogenous and autogenous mills A simplified picture of the mill load is shown in Figure 83 Ad this can be used to establish the essential features of a model for mill …
### White Ceramic Grinding Balls - Size: 20mm - Weight: 1kg
White Ceramic Grinding Balls - Size: 20mm - Weight: 1kg - Milling Media for Ball Mill - by Inoxia 1kg of 20mm white ceramic grinding balls 20mm diameter alumina (Al2O3) ceramic balls, very hard wearing and ideal for ball milling For volume calculations, 1kg will take up roughly half a litre 1kg of 20mm balls is roughly 55 balls, but the
### How Can I calculate new ball size and weight desing for
Mar 10, 2011 · Re: How Can I calculate new ball size and weight desing for ball mill Hi, We have a similar mill Pregrinding with hammer crusher and mono-chamber mill Thisis what a proposed based on literture review i did and others agree its more and less correct But remember it all depends on your mill feed size after pregrinding
### How can one select ball size in ball milling and how much
How can one select ball size in ball milling and how much material should be taken in mill pot? Metallurgy experts based on the requirement ball size, ball to material weight ratio, milling
### Ball mill - Wikipedia
A ball mill is a type of grinder used to grind, blend and sometimes for mixing of materials for use in mineral dressing processes, paints, pyrotechnics, ceramics and selective laser sinteringIt works on the principle of impact and attrition: size reduction is done by impact as the balls drop from near the top of the shell A ball mill consists of a hollow cylindrical shell rotati
### Ball Mill Dimensions And Weight - antwerpsehavenpijlbe
Ball Mill Dimensions And Weight We are a large-scale manufacturer specializing in producing various mining machines including different types of sand and gravel equipment, milling equipment, mineral processing equipment and building materials equipment
### Ball Mill - RETSCH - powerful grinding and homogenization
Laboratory ball mills for powerful size reduction and homogenization RETSCH is the world leading manufacturer of laboratory ball mills and offers the perfect product for each application The High Energy Ball Mill E max and MM 500 were developed for grinding with the highest energy input
### The grinding balls bulk weight in fully unloaded mill
Apr 11, 2017 · It is done in order to accurately definition the grinding ball mass during measuring in a ball mill and exclude the mill overloading with grinding balls possibility There are two methods for determining the grinding balls bulk weight in a mill: Method with complete grinding media discharge from the mill inner drum
### Ball Mill - an overview | ScienceDirect Topics
The ball mill is a tumbling mill that uses steel balls as the grinding media The length of the cylindrical shell is usually 1–15 times the shell diameter (Figure 811)The feed can be dry, with less than 3% moisture to minimize ball coating, or slurry containing 20–40% water by weight
### WEIGHT OF BALL MILL | Crusher Mills, Cone Crusher, Jaw
Ball Mill Speed,Mill Speed Influence,Grinding Efficiency For … The pulp weight in the mill is obtained by subtracting the mill weight during the test from the empty mill weight, including the ball …
### THE BULK WEIGHT OF GRINDING BALLS - energosteel
Mar 14, 2017 · The act introduces the average value of bulk weight by 3 weighing results The obtained result of bulk weight determination can be used in operational accounting, control of grinding process In our next articles we will consider the methodology for determining the bulk weight of grinding media in a working ball mill
### Ball Mill 16' x 23' Weight - forumbulk-online
Jul 18, 2007 · Greetings All, I'm new to this forum and would like to get some help from anybody My company is going to expand the processing plant and we would like to install a second hand unit of ball mill 16 ft x 23 ft We bought the mill without having full drawings and information on it I need to know what is the total weighed of the mill in tonnes at this size excluding the liners and girth gear
### Grinding in Ball Mills: Modeling and Process Control
Grinding in ball mills is an important technological process applied to reduce the size of particles which may have different nature and a wide diversity of physical, mechanical and chemical characteristics Typical examples are the various ores, minerals, limestone, etc The applications of ball mills are ubiquitous in mineral
### Best way to determine the ball-to-powder ratio in ball
Total weight of ball = number of ball X weight of single ball The maximum power draw in ball mill is when ball bed is 35-40 % by volume in whole empty mill volume How can one select ball
### EFFECT OF BALL SIZE DISTRIBUTION ON MILLING …
EFFECT OF BALL SIZE DISTRIBUTION ON MILLING PARAMETERS François Mulenga Katubilwa 261 Ball size distribution in tumbling mills 37 262 Milling performance of a ball size distribution 40 27 Summary 41 Chapter 3 Experimental equipment and programme 43
### Ball Mills: Steel Ball Mills and Lined Ball Mills | Orbis
Ball Mill Design & Manufacturing Our combined experience in ball mill design and process equipment development totals more than 60 years and allows us to put a unique spin on steel and lined mills Particle size reduction of materials in a ball mill with the presence of metallic balls or other media dates back to the late 1800’s
### E-Series Flanged Ball Valves - flowserve
Ball Valves feature secondary metal-to-metal seating and high-tem-perature body seals and packing Steam Service Standard E-Series Flanged Ball Valves with certain body, seat and trim materials handle low-pressure saturated steam services to 150 psig at 366ºF, and when supplied in the thermopac version, up to 250 psig at 406ºF
### New and Used Ball Mills for Sale | Ball Mill Supplier
New and Used Ball Mills for Sale Savona Equipment is a new and used Ball Mill supplier worldwideA ball mill is a type of grinder used to grind materials into extremely fine powder for use in mineral dressing processes, paints, pyrotechnics, ceramics and selective laser sintering
### Ball Mills - New Drying, Mixing, Blending, and Size
Ball Mills Talk with the Experts Wet & Dry Size Reduction 630-350-3012 Small ball mill with dry discharge housing and drawer to catch milled solids Dry discharge requires the use of a dust tight enclosure Shown here is a full housing with 45° chute (60° chute available) Half …
### CL Attritors Limestone Grinding Mill | Union Process®, Inc
The grinding circuit includes the separation tank, mill recirculating pump, mill product tank, hydrocyclone, hydrocyclone feed pump and all necessary controls Due to the CL Attritor’s high efficiency, the power consumption for this mill is 50% less compared to conventional ball mills of a similar size
|
2022-08-15 15:37:57
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.21637055277824402, "perplexity": 6790.568466904978}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-33/segments/1659882572192.79/warc/CC-MAIN-20220815145459-20220815175459-00209.warc.gz"}
|
https://www.hackmath.net/en/math-problem/3418
|
# Roots count
Substitute the numbers/0,1,2,3/into the equation as x:
(x - 1) (x - 3) (x + 1) = 0
Which of them is its solution?
Is there another number that solves this equation?
x1 = 1
x2 = 3
x3 = -1
### Step-by-step explanation:
${x}_{1}=1$
${x}_{2}=3$
${x}_{3}=-1$
We will be pleased if You send us any improvements to this math problem. Thank you!
Tips to related online calculators
Looking for help with calculating roots of a quadratic equation?
Do you have a linear equation or system of equations and looking for its solution? Or do you have a quadratic equation?
## Related math problems and questions:
• Sphere from tree points
Equation of sphere with three point (a,0,0), (0, a,0), (0,0, a) and center lies on plane x+y+z=a
• Phone numbers
How many 7-digit telephone numbers can be compiled from the digits 0,1,2,..,8,9 that no digit is repeated?
Please determine the solvability conditions of the equation, solve the equation and perform the test: x divided by x squared minus 2x plus1 the whole minus x + 3 divided by x squared minus 1 this is equal to 0: x/(x2-2x+1) - (x+3)/( x2-1) = 0
• Coordinates
Determine the coordinates of the vertices and the content of the parallelogram, the two sides of which lie on the lines 8x + 3y + 1 = 0, 2x + y-1 = 0 and the diagonal on the line 3x + 2y + 3 = 0
• Solve 2
Solve integer equation: a +b+c =30 a, b, c = can be odd natural number from this set (1,3,5,7,9,11,13,15)
• Roots and coefficient
In the equation 2x ^ 2 + bx-9 = 0 is one root x1 = -3/2. Determine the second root and the coefficient b.
• Equation
Eequation f(x) = 0 has roots x1 = 64, x2 = 100, x3 = 25, x4 = 49. How many roots have equation f(x2) = 0 ?
• Complaints
The table is given: days complaints 0-4 2 5-9 4 10-14 8 15-19 6 20-24 4 25-29 3 30-34 3 1.1 What percentage of complaints were resolved within 2weeks? 1.2 calculate the mean number of days to resolve these complaints. 1.3 calculate the modal number of day
• What is
What is the probability that the sum of 9 will fall on a roll of two dice? Hint: write down all the pairs that can occur as follows: 11 12 13 14 15. . 21 22 23 24. .. . 31 32. .. . . . . . .. . 66, count them, it's the variable n variable m: 36, 63,. .. .
Determine the numbers b, c that the numbers x1 = -1 and x2 = 3 were roots of quadratic equation: ?
• Logik game
Letter game Logik is a two player game, which has the following rules: 1. The first player thinks five-letter word in which no letter is not repeated. 2. The second player writes a five-letter word. 3. The first player answers two numbers - the first numb
• Probability of intersection
Three students have a probability of 0.7,0.5 and 0.4 to graduated from university respectively. What is the probability that at least one of them will be graduated?
• Numbers
How many different 3 digit natural numbers in which no digit is repeated, can be composed from digits 0,1,2?
• Centroid - two bodies
A body is composed of a 0.8 m long bar and a sphere with a radius of 0.1m attached so that its center lies on the longitudinal axis of the bar. Both bodies are of the same uniform material. The sphere is twice as heavy as the bar. Find the center of gravi
• The accompanying
The accompanying table gives the probability distribution of the number of courses randomly selected student has registered Number of courses 1 2 3 4 5 6 7 Probability 0.02 0.03 0.1 0.3 0.4 - 0.01 respectively. a) Find the probability of a student registe
• Linear system
Solve a set of two equations of two unknowns: 1.5x+1.2y=0.6 0.8x-0.2y=2
• Perfect cubes
Suppose a number is chosen at random from the set (0,1,2,3,. .. ,202). What is the probability that the number is a perfect cube?
|
2021-04-19 05:23:27
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 3, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5417520403862, "perplexity": 749.0483753556961}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-17/segments/1618038878326.67/warc/CC-MAIN-20210419045820-20210419075820-00487.warc.gz"}
|
https://ndl.iitkgp.ac.in/document/dWJZVEVYZ1k5Z1c1cXpwRzBjUTJ5QT09
|
### Measurement of the production of neighbouring jets in lead-lead collisions at $\sqrt{s_{\mathrm{NN}}} = 2.76$ TeV with the ATLAS detectorMeasurement of the production of neighbouring jets in lead-lead collisions at $\sqrt{s_{\mathrm{NN}}} = 2.76$ TeV with the ATLAS detector
Access Restriction
Open
|
2023-02-08 14:57:06
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9994930028915405, "perplexity": 7485.419327505916}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764500813.58/warc/CC-MAIN-20230208123621-20230208153621-00781.warc.gz"}
|
http://tex.stackexchange.com/questions/72987/how-to-make-a-pagebreak-that-goes-to-the-next-double-sided-page?answertab=active
|
How to make a pagebreak that goes to the next double sided page?
I am writing a problem set for which the professor has mandated that each problem be submitted on a separate sheet (or sheets). To save some paper, I would like to print double-sided.
Thus my question: Is there a way to make LaTeX automatically break to the next new sheet of paper, so that in particular, whenever I page break it skips all the way to the next odd numbered page.
E.g. breaking on page 1 should start again on page 3 (so that the backside of page 1 is empty), but breaking on page 4 should just skip to page 5, since that will be a new sheet anyway.
-
You can use \cleardoublepage.
|
2015-01-27 12:39:24
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6124885082244873, "perplexity": 609.8694597632583}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-06/segments/1422120842874.46/warc/CC-MAIN-20150124173402-00133-ip-10-180-212-252.ec2.internal.warc.gz"}
|
https://brilliant.org/discussions/thread/wedge-block-in-a-different-frame/
|
×
# Wedge Block in a different frame
Could someone please explain the motion of the wedge in the frame of the block. I know the solutions using ground and wedge as reference but how to approach this with block as frame of reference?
Note by Euler 149
11 months, 3 weeks ago
MarkdownAppears as
*italics* or _italics_ italics
**bold** or __bold__ bold
- bulleted- list
• bulleted
• list
1. numbered2. list
1. numbered
2. list
Note: you must add a full line of space before and after lists for them to show up correctly
paragraph 1paragraph 2
paragraph 1
paragraph 2
[example link](https://brilliant.org)example link
> This is a quote
This is a quote
# I indented these lines
# 4 spaces, and now they show
# up as a code block.
print "hello world"
# I indented these lines
# 4 spaces, and now they show
# up as a code block.
print "hello world"
MathAppears as
Remember to wrap math in $$...$$ or $...$ to ensure proper formatting.
2 \times 3 $$2 \times 3$$
2^{34} $$2^{34}$$
a_{i-1} $$a_{i-1}$$
\frac{2}{3} $$\frac{2}{3}$$
\sqrt{2} $$\sqrt{2}$$
\sum_{i=1}^3 $$\sum_{i=1}^3$$
\sin \theta $$\sin \theta$$
\boxed{123} $$\boxed{123}$$
|
2018-02-25 07:50:02
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9994648098945618, "perplexity": 10925.601769873074}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-09/segments/1518891816178.71/warc/CC-MAIN-20180225070925-20180225090925-00066.warc.gz"}
|
http://www.ecice06.com/CN/abstract/abstract28862.shtml
|
• 先进计算与数据处理 •
基于项目评分与类型评分聚类的推荐算法
1. 上海海事大学 信息工程学院,上海 201306
• 收稿日期:2017-05-22 出版日期:2018-06-15 发布日期:2018-06-15
• 作者简介:段元波(1993—),男,硕士研究生,主研方向为数据挖掘;高茂庭,教授、博士。
• 基金项目:
国家自然科学基金(61202022)。
Recommendation Algorithm Based on Clusterings of Item Rating and Type Rating
DUAN Yuanbo,GAO Maoting
1. College of Information Engineering,Shanghai Maritime University,Shanghai 201306,China
• Received:2017-05-22 Online:2018-06-15 Published:2018-06-15
Abstract:
To solve the problems that some similar users will be missed and the basis for selecting nearest neighbors is single while user clustering,a recommendation algorithm based on clusterings of item rating and type rating is proposed.The user-item rating matrix and the user-item type rating matrix according to user’s rating records are firstly generated.The fuzzy C-means clustering is carried out by using the above two matrices and the improved the distance measurement method.Then,the nearest neighbor is selected according to the membership degree matrix generated by the clustering.Finally,the prediction rating is generated by the parameter weighting.Experimental results on MovieLens dataset show that the proposed algorithm can reflect the user’s rating accurately and improve the accuracy of the recommendation system effectively.
|
2019-12-06 03:50:35
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2154010683298111, "perplexity": 5137.962560585067}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-51/segments/1575540484477.5/warc/CC-MAIN-20191206023204-20191206051204-00434.warc.gz"}
|
http://www.isp.uni-luebeck.de/node/385
|
# Network Invariants for Real-time Systems
Title Network Invariants for Real-time Systems Publication Type Conference Paper Year of Publication 2004 Authors Grinchtein, O, Leucker, M Conference Name 5th International Workshop on Verification of Infinite-State Systems Series Electronic Notes in Theoretical Computer Science Volume 98 Publisher Elsevier Science Publishers URL http://www.sciencedirect.com/
Bibtex:
```@inproceedings {GrinchteinL03,
title = {Network Invariants for Real-time Systems},
booktitle = {5th International Workshop on Verification of Infinite-State Systems},
series = {Electronic Notes in Theoretical Computer Science},
volume = {98},
year = {2004},
pages = {57{\textendash}74},
publisher = {Elsevier Science Publishers},
organization = {Elsevier Science Publishers},
url = {http://www.sciencedirect.com/},
author = {Olga Grinchtein and Martin Leucker}
}```
PDF:
Postscript:
|
2018-04-21 13:42:54
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9201064109802246, "perplexity": 11046.091036961616}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-17/segments/1524125945222.55/warc/CC-MAIN-20180421125711-20180421145711-00381.warc.gz"}
|
http://mathhelpforum.com/algebra/113815-solving-systems-equations-print.html
|
# solving systems of equations
• November 11th 2009, 12:10 AM
scubasteve123
solving systems of equations
solve the following for u and t
x= u + t^2
y = t - u^2
• November 11th 2009, 12:17 AM
BabyMilo
Quote:
Originally Posted by scubasteve123
solve the following for u and t
x= u + t^2
y = t - u^2
$u=x-t^2$
sub 1st equation into 2nd equation
$y=t-(x-t^2)^2$
then simplify.
• November 12th 2009, 11:14 PM
scubasteve123
I tried this and was just left with y + x^2 = t +2xt^2 - t^4
... not sure how to simplify this I just end up going in circles with all the substitution.
• November 13th 2009, 12:21 AM
BabyMilo
Quote:
Originally Posted by scubasteve123
I tried this and was just left with y + x^2 = t +2xt^2 - t^4
... not sure how to simplify this I just end up going in circles with all the substitution.
you are right what you are doing.
after you simplfy you get:
$y=t-x^2+2t^2x-t^4$
well we need to rearrange it a little bit, so we get:
$y=-x^2+2t^2x+(t-t^4)$
we sub in the numbers,
$\frac{-2t^2\pm\sqrt{(2t^2)^2-4*-1*(t-t^4)}}{2*-1}=0$
then again simplfy:
$\frac{-2t^2\pm\sqrt{4t}}{-2}=0$
so we get t=1 or t=0
if t=0 x=0
if t=1 x=2 or 0.
hope this helps. correct me if im wrong anyone.
• November 13th 2009, 12:30 AM
Bacterius
You can simplify even further, Babymilo :
$\frac{-2t^2\pm\sqrt{4t}}{-2}=0$
Extract the $4$ from the square root :
$\frac{-2t^2\pm 2 \sqrt{t}}{-2}=0$
Factorize $2$ :
$\frac{2(-t^2 \pm \sqrt{t})}{-2}=0$
Cancel out the $2$ :
$\frac{-t^2 \pm \sqrt{t}}{-1}=0$
Finally :
$t^2 \mp \sqrt{t} = 0$
|
2015-11-30 02:15:19
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 14, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8673504590988159, "perplexity": 2534.5059446395885}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-48/segments/1448398460519.28/warc/CC-MAIN-20151124205420-00116-ip-10-71-132-137.ec2.internal.warc.gz"}
|
https://linguistics.stackexchange.com/questions/28576/vowel-deletion-and-allophone-variation-in-japanese-high-vowel-clusters/28579
|
# Vowel Deletion and Allophone variation in Japanese High Vowel Clusters?
I seem to have heard from films, shows and other japanese programs that there is a kind of vowel deletion in certain contexts which triggers a consonant change which might be allophonic.
This paper seems to cover the phenomenon, although I am interested in something specific
Since I have not studied japanese linguistics, I would need someone who has to help.
Questions:
When a consonant followed by a high vowel follows /r/, does it always become a trill?
Something like:
CV(+high) /ɾ/ -> C [r]
Where C is a consonant that is not /r/
Are trills only allophonic in Japanese?
• sorry looks like my rule doesnt make sense, updating question to clarify your issues – Nathan McCoy Aug 1 '18 at 18:08
Since the only syllable-final consonants in Japanese are /N/, a nasal whose place always assimilates to the following consonant, and /Q/, which geminates the following consonant, and there are no complex onsets (except for /Cj/), and a devoiced vowel is still considered phonologically/prosodically present (and often articulated as a puff of air), Japanese doesn't have a lot of phonological processes that involve adjacent consonants. Most geminates originate in a historical process akin to what you describe (e.g. /ɡaku/ + /koː/ → /ɡakkoː/, 'school'), but /r/ does not geminate.*
Are trills only allophonic in Japanese?
Yes. Not only that, Japanese has only one liquid phoneme, i.e. doesn't contrast rhotics and laterals.
When a consonant followed by a high vowel follows /r/, does it always become a trill?
/ɽ/, which corresponds to 'r' in Romanization, is postalveolar in place rather than retroflex and mainly occurs medially. Initially and after /ɴ/, it is typically an affricate with short friction, [d̠ɹ̝̆]. A postalveolar [l̠] is not unusual in all positions. Approximant [ɹ] may occasionally occur in some environments.
Labrune (2014) says:
The voiced apico-alveolar tap [ɾ] is generally assumed to be the prototypical realization of the liquid consonant in contemporary Japanese [...] Outside of [ɾ], the following phonetic (social or regional) realizations are widely attested: [l], [ɭ], [r], [rː], [d], [ɽ], [ɮ]. [...]
The short and long apical trills, [r] and [rː] are socially marked variants, characteristic of the popular speech of males from the Tokyo region. The higher the number of trills, the more socially marked the rhotic will be.
Although she specifies Tokyo, my empirical impression is that it's not confined to a particular region and may be heard from a speaker from anywhere (usually male indeed), though it might not connote vulgarity in the same way it does in Tokyo.
* There are a few loans with /rr/, such as arrā ('Allah'), but it's usually pronounced as something like [ʔɾ]. [araː] would probably be perceived as /araː/, not /arraː/.
• just realised, so nasal syllable final consonants are /N/ not /n/ (uvular not alveolar)? – Nathan McCoy Aug 3 '18 at 8:15
• No, like I said, its place always assimilates to the following consonant, so it's [n] before [t, d], [ŋ] before [k, ɡ], and so on. The use of "N" (capital N) rather than "ɴ" (small capital N) is deliberate because it's an archiphoneme. When utterance-final, it is traditionally said to be uvular [ɴ], but often the dorsal occlusion is incomplete so it's more like a nasalized vowel. See the Wikipedia article for more. – Nardog Aug 3 '18 at 12:00
Labrune (The phonology of Japanese) does not report any such allophonic rule. She does report a trill realization as a social variant, typifying street thugs. It should be noted that while the standard IPA symbol for an alveolar flap or tap is [ɾ], people commonly write [r], in case there is no contrast. It may be that if your data is from movies, the actors may have been affecting a yakuza accent.
• So then my first question is false while the second is true? – Nathan McCoy Aug 2 '18 at 1:41
|
2019-10-16 13:14:12
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5312049984931946, "perplexity": 7047.959622551748}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-43/segments/1570986668569.22/warc/CC-MAIN-20191016113040-20191016140540-00474.warc.gz"}
|
https://gamedev.stackexchange.com/questions/132838/i-dont-think-my-shaders-are-working-looking-for-help
|
# I don't think my shaders are working, looking for help
Using sharpdx(directx 11) developing on UWP.
This is a link to a previous question of not being able to compile the shader files(written in hlsl) How to compile shader files in UWP Later I have found some method to avoid the original exception(unable to open or find shader files) but still the shaders seem not to be working.
My method to "avoid the original exception" is to change the file path to
System.IO.Path.Combine(Windows.ApplicationModel.Package.Current.InstalledLocation.Path, "ProjectName")
If the method works, I would surely post it as an answer to the previous question
The current problem is no display on the screen(all black), while I can check the stored data in the vertex buffer using graphic diagnostics tools built in visual studio.
Here is my code for the shaders, problem may be going from here because this is the first shader file I've written. Please have a look and discuss may things go wrong.
struct VertexOut
{
float4 PosH : SV_POSITION;
float4 Color : COLOR;
};
float4 PS(VertexOut pin) : SV_Target
{
return pin.Color;
}
cbuffer dataBuffer : register(b0)
{
matrix ViewProjection;
};
struct VertexIn
{
float3 PosL : POSITION;
float4 Color : COLOR;
};
struct VertexOut
{
float4 PosH : SV_POSITION;
float4 Color : COLOR;
};
VertexOut VS(VertexIn vin)
{
VertexOut vout;
// Transform to homogeneous clip space.
vout.PosH = mul(float4(vin.PosL, 1.0f), ViewProjection);
// Just pass vertex color into the pixel shader.
vout.Color = vin.Color;
return vout;
}
where I compiled them
byte[] vertexShaderByteCode = ShaderBytecode.CompileFromFile(this.path + "\\Transf_VS.fx", "VS", "vs_5_0");
device,
);
device,
);
data structure definition
public struct ScatterVertex
{
SharpDX.Vector3 Position;
SharpDX.Color4 Color;
}
inputlayout initialization
this.inputLayout = new D3D11.InputLayout(
this.device,
inputSignature,
new SharpDX.Direct3D11.InputElement[]
{
new D3D11.InputElement(
"Position",
0,
SharpDX.DXGI.Format.R32G32B32_Float,
0
),
new D3D11.InputElement(
"Color",
0,
SharpDX.DXGI.Format.R32G32B32A32_Float,//I'm not very sure whether or why I should use this option
0
)
}
);
Here's the projection matrix in the camera class, which is later sent to the constant buffer
private Matrix View { get { return Matrix.LookAtLH(this.Eye, this.Target, this.Up); } }
private Matrix Proj { get { return Matrix.PerspectiveFovLH(this.Fov, this.Aspect, this.Near, this.Far); } }
public Matrix WorldViewProject
{
get
{
Matrix wvp = (this.View * this.Proj);
wvp.Transpose();
return wvp;
}
}
If you need anything else to solve this, just let me know and I'll manage to get it. Thank you!
• Unfortunately in graphics programming 'blank screen' can come about for any number of reasons. Where is the code where you update the ViewProjection value in your constant buffer? Nov 10 '16 at 6:09
• It's a bit long, let me check it myself first Nov 10 '16 at 6:56
• I've updated the answer Nov 10 '16 at 7:53
It turns out the problem is not with the shader, but the Draw method. I missed setting the first parameter of draw in my code, which should be the primitives I am intending to draw.
|
2021-11-28 23:04:50
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.297913521528244, "perplexity": 5805.520708586319}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-49/segments/1637964358673.74/warc/CC-MAIN-20211128224316-20211129014316-00325.warc.gz"}
|
https://www.storyofmathematics.com/should-you-choose-to-throw-a-rubber-ball-or-a-beanbag-of-equal-size-and-weight/
|
# To win a prize at the country fair, you’re trying to knock down a heavy bowling pin by hitting it with a thrown object. Should you choose to throw a rubber ball or a beanbag of equal size and weight? Explain.
This article aims to find whether a rubber ball or bean bag is best used to knock down a heavy bowling pin to win a prize at a country fair. This article uses the concept of elastic, inelastic collision, and change in momentum.
Elastic collisions
An elastic collision is defined as a collision in which momentum and kinetic energy are observed. This means that there is no dissipative force during the collision and that all kinetic energy of the objects before collision is still in the form of kinetic energy afterward.
Inelastic collisions
An inelastic collision is when some of the kinetic energy is converted to another form of energy during the collision.
Change in momentum is defined as
Change in momentum of an object is defined as its mass times change in its velocity.
$\Delta p = m . ( \Delta v ) = m. ( v _ { f } – v _ { i } )$
Where $v_{ f }$ and $v_{ i }$ are final and initial velocities.
The rubber ball will exert more force on the heavy pin because its kinetic energy will be conserved, while the bean bag will exert less force due to the loss of kinetic energy. A collision between two objects can be elastic or inelastic.
– In an elastic collision, both momentum and kinetic energy are conserved.
– In an inelastic collision, only momentum is conserved.
The impulse experienced by each thrown object is equal to the object’s change in momentum.
$J = \Delta P$
For Rubber Ball
In an elastic collision, it reverses direction and moves at speed equal to or less than the original.
Change in momentum = $P$
$P = m ( v _ { f } – v _ { i } )$
$v _ { f } = – v _ { i }$
$P = – 2 m v _{ i }$
For Beanbag
When velocity is zero, the value of impulse will be large.
$v _ { f } = 0$
$P = – m v _ { i }$
The rubber ball will exert more force on the heavy pin because its kinetic energy will be conserved, while the bean bag will exert less force due to the loss of kinetic energy.
## Numerical Result
The rubber ball will exert more force on the heavy pin because its kinetic energy will be conserved, while the bean bag will exert less force due to the loss of kinetic energy.
## Example
To win a prize at a fair, you try to knock down a heavy skittle by hitting it with a thrown object. Should you choose to throw a bouncy ball or a non-bouncy ball of the same size and weight? Explain.
Solution
The bouncy ball will exert more force on the heavy pin because its kinetic energy will be conserved, while the non-bouncy ball will exert less force due to the loss of kinetic energy.
|
2022-10-02 15:09:42
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2508927583694458, "perplexity": 1112.91228183}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-40/segments/1664030337338.11/warc/CC-MAIN-20221002150039-20221002180039-00310.warc.gz"}
|
https://arxiver.wordpress.com/2016/03/16/revealing-the-z2-5-cosmic-web-with-3d-lyman-alpha-forest-tomography-a-deformation-tensor-approach-cea/
|
# Revealing the z~2.5 Cosmic Web With 3D Lyman-Alpha Forest Tomography: A Deformation Tensor Approach [CEA]
Studies of cosmological objects should take into account their positions within the cosmic web of large-scale structure. Unfortunately, the cosmic web has only been extensively mapped at low-redshifts ($z<1$), using galaxy redshifts as tracers of the underlying density field. At $z>1$, the required galaxy densities are inaccessible for the foreseeable future, but 3D reconstructions of Lyman-$\alpha$ forest absorption in closely-separated background QSOs and star-forming galaxies already offer a detailed window into $z\sim2-3$ large-scale structure. We quantify the utility of such maps for studying the cosmic web by using realistic $z=2.5$ Ly$\alpha$ forest simulations matched to observational properties of upcoming surveys. A deformation tensor-based analysis is used to classify voids, sheets, filaments and nodes in the flux, which is compared to those determined from the underlying dark matter field. We find an extremely good correspondence, with $70\%$ of the volume in the flux maps correctly classified relative to the dark matter web, and $99\%$ classified to within 1 eigenvalue. This compares favorably to the performance of galaxy-based classifiers with even the highest galaxy densities at low-redshift. We find that narrow survey geometries can degrade the cosmic web recovery unless the survey is $\gtrsim 60\,h^{-1}\,\mathrm{Mpc}$ or $\gtrsim 1\,\mathrm{deg}$ on the sky. We also examine halo abundances as a function of the cosmic web, and find a clear dependence as a function of flux overdensity, but little explicit dependence on the cosmic web. These methods will provide a new window on cosmological environments of galaxies at this very special time in galaxy formation, “high noon”, and on overall properties of cosmological structures at this epoch.
K. Lee and M. White
Wed, 16 Mar 16
43/53
Comments: 10 pages, 7 figures. Submitted to ApJ
|
2022-01-18 15:36:34
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.579149603843689, "perplexity": 1630.9005375564047}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-05/segments/1642320300934.87/warc/CC-MAIN-20220118152809-20220118182809-00090.warc.gz"}
|
https://brilliant.org/problems/like-base-system/
|
# Like Base System?
Number Theory Level pending
For each integer $$n\geq 4$$, let $$a_n$$ denote the base-$$n$$ number $$(0.133133133\ldots)_n$$. The product $$a_4a_5\cdots a_{99}$$ can be expressed as $$\dfrac{m}{n!}$$, where $$m$$ and $$n$$ are positive integers and $$n$$ is as small as possible. What is the value of $$m$$?
×
|
2017-09-22 10:05:04
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9602951407432556, "perplexity": 87.02282522708079}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-39/segments/1505818688932.49/warc/CC-MAIN-20170922093346-20170922113346-00369.warc.gz"}
|
https://en.wikipedia.org/wiki/Link_Budget
|
A link budget is accounting of all of the gains and losses from the transmitter, through the medium (free space, cable, waveguide, fiber, etc.) to the receiver in a telecommunication system. It accounts for the attenuation of the transmitted signal due to propagation, as well as the antenna gains, feedline and miscellaneous losses. Randomly varying channel gains such as fading are taken into account by adding some margin depending on the anticipated severity of its effects. The amount of margin required can be reduced by the use of mitigating techniques such as antenna diversity or frequency hopping.
A simple link budget equation looks like this:
Received Power (dB) = Transmitted Power (dB) + Gains (dB) − Losses (dB)
Note that decibels are logarithmic measurements, so adding decibels is equivalent to multiplying the actual numeric ratios.
For a line-of-sight radio system, the primary source of loss is the decrease of the signal power due to uniform propagation, proportional to the inverse square of the distance (geometric spreading).
• Transmitting antennas are for the most part neither isotropic (an imaginary class of antenna with uniform radiation in 3 dimensions) nor omnidirectional (a real class of antenna with uniform radiation in 2 dimensions).
• The use of omnidirectional antennas is rare in telecommunication systems, so almost every link budget equation must consider antenna gain.
• Transmitting antennas typically concentrate the signal power in a favoured direction, normally that in which the receiving antenna is placed.
• Transmitter power is effectively increased (in the direction of highest antenna gain). This systemic gain is expressed by including the antenna gain in the link budget.
• The receiving antenna is also typically directional, and when properly oriented collects more power than an isotropic antenna would; as a consequence, the receiving antenna gain (in decibels from isotropic, dBi) adds to the received power.
• The antenna gains (transmitting or receiving) are scaled by the wavelength of the radiation in question. This step may not be required if adequate systemic link budgets are achieved.
### Simplifications needed
Often link budget equations are messy and complex, so standard practices have evolved to simplify the Friis transmission equation into the link budget equation. It includes the transmit and receive antenna gain, the free space path loss and additional losses and gains, assuming line of sight between the transmitter and receiver.
• The wavelength term (or frequency) term is part of the free space loss part of the link budget.
• The distance term is also considered in the free space loss.
### Transmission line and polarization loss
In practical situations (Deep Space Telecommunications, Weak signal DXing etc. ...) other sources of signal loss must also be accounted for
• The transmitting and receiving antennas may be partially cross-polarized.
• The cabling between the radios and antennas may introduce significant additional loss.
• Fresnel zone losses due to a partially obstructed line of sight path.
• Doppler shift induced signal power losses in the receiver.
### Endgame
If the estimated received power is sufficiently large (typically relative to the receiver sensitivity), which may be dependent on the communications protocol in use, the link will be useful for sending data. The amount by which the received power exceeds receiver sensitivity is called the link margin.
### Equation
A link budget equation including all these effects, expressed logarithmically, might look like this:
${\displaystyle P_{RX}=P_{TX}+G_{TX}-L_{TX}-L_{FS}-L_{M}+G_{RX}-L_{RX}\,}$
where:
${\displaystyle P_{RX}}$ = received power (dBm)
${\displaystyle P_{TX}}$ = transmitter output power (dBm)
${\displaystyle G_{TX}}$ = transmitter antenna gain (dBi)
${\displaystyle L_{TX}}$ = transmitter losses (coax, connectors...) (dB)
${\displaystyle L_{FS}}$ = path loss, usually free space loss (dB)
${\displaystyle L_{M}}$ = miscellaneous losses (fading margin, body loss, polarization mismatch, other losses...) (dB)
${\displaystyle G_{RX}}$ = receiver antenna gain (dBi)
${\displaystyle L_{RX}}$ = receiver losses (coax, connectors...) (dB)
The loss due to propagation between the transmitting and receiving antennas, often called the path loss, can be written in dimensionless form by normalizing the distance to the wavelength:
${\displaystyle L_{FS}{\text{(dB)}}=20\log _{10}\left(4\pi {{\text{distance}} \over {\text{wavelength}}}\right)}$ (where distance and wavelength are in the same units)
When substituted into the link budget equation above, the result is the logarithmic form of the Friis transmission equation.
In some cases it is convenient to consider the loss due to distance and wavelength separately, but in that case it is important to keep track of which units are being used, as each choice involves a differing constant offset. Some examples are provided below.
${\displaystyle L_{FS}}$ (dB) = 32.45 dB + 20×log[frequency(MHz)] + 20×log[distance(km)] [1]
${\displaystyle L_{FS}}$ (dB) = - 27.55 dB + 20×log[frequency(MHz)] + 20×log[distance(m)]
${\displaystyle L_{FS}}$ (dB) = 36.6 dB + 20×log[frequency(MHz)] + 20×log[distance(miles)]
These alternative forms can be derived by substituting wavelength with the ratio of propagation velocity (c, approximately 3×10^8 m/s) divided by frequency, and by inserting the proper conversion factors between km or miles and meters, and between MHz and (1/sec).
Because of building obstructions such as walls and ceilings, propagation losses indoors can be significantly higher. This occurs because of a combination of attenuation by walls and ceilings, and blockage due to equipment, furniture, and even people.
• For example, a “2 x 4” wood stud wall with drywall on both sides results in about 6 dB loss per wall.
• Older buildings may have even greater internal losses than new buildings due to materials and line of sight issues.
Experience has shown that line-of-sight propagation holds only for about the first 3 meters. Beyond 3 meters propagation losses indoors can increase at up to 30 dB per 30 meters in dense office environments.
This is a good “rule-of-thumb”, in that it is conservative (it overstates path loss in most cases). Actual propagation losses may vary significantly depending on building construction and layout.
The attenuation of the signal is highly dependent on the frequency of the signal.
## In waveguides and cables
Guided media such as coaxial and twisted pair electrical cable, radio frequency waveguide and optical fiber have losses that are exponential with distance.
The path loss will be in terms of dB per unit distance.
This means that there is always a crossover distance beyond which the loss in a guided medium will exceed that of a line-of-sight path of the same length.
Long distance fiber-optic communication became practical only with the development of ultra-transparent glass fibers. A typical path loss for single mode fiber is 0.2 dB/km, [2] far lower than any other guided medium.
## Examples
### Earth–Moon–Earth communications
Link budgets are important in Earth–Moon–Earth communications. As the albedo of the Moon is very low (maximally 12% but usually closer to 7%), and the path loss over the 770,000 kilometre return distance is extreme (around 250 to 310 dB depending on VHF-UHF band used, modulation format and Doppler shift effects), high power (more than 100 watts) and high-gain antennas (more than 20 dB) must be used.
• In practice, this limits the use of this technique to the spectrum at VHF and above.
• The Moon must be above the horizon in order for EME communications to be possible.
### Voyager Program
The Voyager Program spacecraft have the highest known path loss (-308 dB as of 2002[1]) and lowest link budgets of any telecommunications circuit. The Deep Space Network has been able to maintain the link at a higher than expected bitrate through a series of improvements, such as increasing the antenna size from 64m to 70m for a 1.2 dB gain, and upgrading to low noise electronics for a 0.5 dB gain in 2000/2001. During the Neptune flyby, in addition to the 70-m antenna, two 34-m antennas and twenty-seven 25-m antennas were used to increase the gain by 5.6 dB, providing additional link margin to be used for a 4x increase in bitrate.[2]
|
2018-03-18 17:45:49
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 13, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7162519693374634, "perplexity": 1903.2516846673975}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-13/segments/1521257645830.10/warc/CC-MAIN-20180318165408-20180318185408-00066.warc.gz"}
|
https://leanprover-community.github.io/archive/stream/116395-maths/topic/Left.20adjoint.20of.20functors.20between.20orders.html
|
## Stream: maths
### Topic: Left adjoint of functors between orders
#### Kenny Lau (Apr 27 2018 at 18:55):
So, the forgetful functor from the category of partially ordered sets to the category of pre-ordered sets has a left adjoint
|
2021-05-18 06:47:01
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9727615118026733, "perplexity": 1160.8520128780522}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-21/segments/1620243989756.81/warc/CC-MAIN-20210518063944-20210518093944-00265.warc.gz"}
|
http://www.worldcat.org/identities/lccn-nr90008476/
|
# Schramm, Oded
Overview
Works: 12 works in 28 publications in 1 language and 719 library holdings Author QA274.75, 530.475
Publication Timeline
.
Most widely held works by Oded Schramm
Brownian motion by Peter Mörters( Book )
7 editions published in 2010 in English and held by 224 WorldCat member libraries worldwide
"This textbook offers a broad and deep exposition of Brownian motion. Extensively class tested, it leads the reader from the basics to the latest research in the area." "Starting with the construction of Brownian motion, the book then proceeds to sample path properties such as continuity and nowhere differentiability. Notions of fractal dimension are introduced early and are used throughout the book to describe fine properties of Brownian paths. The relation of Brownian motion and random walk is explored from several viewpoints, including a development of the theory of Brownian local times from random walk embeddings. Stochastic integration is introduced as a tool, and an accessible treatment of the potential theory of Brownian motion clears the path for an extensive treatment of intersections of Brownian paths. An investigation of exceptional points on the Brownian path and an appendix on SLE processes, by Oded Schramm and Wendelin Werner, lead directly to recent research themes."--Jacket
Noise sensitivity of Boolean functions and applications to percolation. A 1-homotopy theory of schemes / by Fabien Morel ; Vladimir Voevodsky [u.a.] by Itai Benjamini( Book )
3 editions published between 1999 and 2001 in English and held by 12 WorldCat member libraries worldwide
Selected works by Oded Schramm( )
1 edition published in 2011 in English and held by 7 WorldCat member libraries worldwide
Selected works of Oded Schramm by Oded Schramm( Book )
1 edition published in 2011 in English and held by 2 WorldCat member libraries worldwide
On the effect of adding $\epsilon$ -Bernoulli percolation to everywhere percolating subgraphs of $Z^ d$ by Itai Benjamini( Book )
2 editions published in 1999 in English and held by 2 WorldCat member libraries worldwide
Selected works of Oded Schramm by Oded Schramm( Book )
1 edition published in 2011 in English and held by 2 WorldCat member libraries worldwide
Analyticity of intersection exponents for planar Brownian motion by Gregory F Lawler( Book )
1 edition published in 2000 in English and held by 1 WorldCat member library worldwide
One-arm exponent for critical 2D percolation by Gregory F Lawler( Book )
1 edition published in 2001 in English and held by 1 WorldCat member library worldwide
Sharp estimates for Brownian non-intersection probabilities by Gregory F Lawler( Book )
1 edition published in 2001 in English and held by 1 WorldCat member library worldwide
Packing two-dimensional bodies with prescribed combinatorics and applications to the construction of conformal and quasiconformal mappings by Oded Schramm( Book )
1 edition published in 1990 in English and held by 1 WorldCat member library worldwide
Combinatorically Prescribed Packings and Applications to Conformal and Quasiconformal Maps by Oded Schramm( )
1 edition published in 2007 in English and held by 0 WorldCat member libraries worldwide
The Andreev-Thurston Circle Packing Theorem is generalized to packings of convex bodies in planar simply connected domains. This turns out to be a useful tool for constructing conformal and quasiconformal mappings with interesting geometric properties. We attempt to illustrate this with a few results about uniformizations of finitely connected planar domains. For example, the following variation of a theorem by Courant, Manel and Shiffman is proved and generalized. If $G$ is an $n+1$-connected bounded planar domain, $H$ is a simply connected bounded planar domain, and $P_1,P_2,...,P_n$ are (compact) planar convex bodies, then sets $P_j'$ can be found so that $G$ is conformally equivalent to $H-\cup_{j=1}^n P_j'$, and each $P_j'$ is either a point, or is positively homothetic to $P_j$
more
fewer
Audience Level
0 1 Kids General Special
Related Identities
Alternative Names
Oded Schramm israelischer Mathematiker
Oded Schramm matematico israeliano
Oded Schramm wiskundige uit Israël (1961-2008)
Шрамм, Одед
עודד שרם
オデッド・シュラム
Languages
English (20)
Covers
|
2016-08-25 08:11:08
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.19803857803344727, "perplexity": 2323.848178390647}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-36/segments/1471982292975.73/warc/CC-MAIN-20160823195812-00210-ip-10-153-172-175.ec2.internal.warc.gz"}
|
https://www.groundai.com/project/unified-description-of-0-states-in-a-large-class-of-nuclear-collective-models/
|
Unified description of 0^{+} states in a large class of nuclear collective models
# Unified description of 0+ states in a large class of nuclear collective models
Dennis Bonatsos, E.A. McCutchan, and R.F. Casten, Institute of Nuclear Physics, N.C.S.R. “Demokritos”, GR-15310 Aghia Paraskevi, Attiki, Greece Physics Division, Argonne National Laboratory, Argonne, Illinois 60439, USA Wright Nuclear Structure Laboratory, Yale University, New Haven, CT 06520, USA
###### Abstract
A remarkably simple regularity in the energies of states in a broad class of collective models is discussed. A single formula for all states in flat-bottomed infinite potentials that depends only on the number of dimensions and a simpler expression applicable to all three IBA symmetries in the large limit are presented. Finally, a connection between the energy expression for states given by the X(5) model and the predictions of the IBA near the critical point is explored.
The evolution of structure in many-body quantum systems and the emergence of collective phenomena is a subject that pervades many areas of modern physics. Recently, significant strides have been taken in the study of structural evolution in atomic nuclei, particularly with the discovery of nuclei that undergo quantum phase transitions phase1 (); phase2 () in their equilibrium shapes, and the development of descriptions of nuclei at the phase transitional point by simple, parameter-free critical point symmetries, E(5) e5 () and X(5) x5 (), that invoke flat-bottomed, infinite potentials. These descriptions have been well supported by experimental studies 134ba (); 152sm (); 150nd (); 154gd () and also have application molecules () in other systems such as molecules. Thus their study, and that of related models, potentially offers insight into a variety of phase transitional behavior.
E(5) and X(5) are analytic solutions of the Bohr Hamiltonian bohr () that describe collective properties in terms of two shape variables – the ellipsoidal deformation and a measure of axial asymmetry, . Both use an infinite square well in , differing in their dependence. Their success has given rise to numerous other geometrical models, many of which can also be solved analytically. Examples are X(3) x3 () in which the potential is frozen at , Z(4) z4 (), in which it is fixed at = , and Z(5) z5 () which has a minimum at = . In all these models, the number in parentheses is the effective dimensionality, . For example, the 5-dimensional models are couched in terms of , and the three Euler angles.
The nature of low lying states is critical to understanding the structure of nuclei. Their identification and interpretation is a subject of recent experimental des (); dorel () and theoretical work, both in the microscopic quasi-particle phonon model qpm () and in the relativistic mean field framework rmf ().
It is the purpose of this Letter to show that a large class of seemingly diverse models in fact share some remarkable similarities and to exemplify this by pointing out certain heretofore unrecognized but simple and general regularities in the energies of states which characterize these models. We will obtain a single, simple formula for all states in any flat-bottomed infinite potential that depends solely on the number of dimensions and another even simpler expression applicable to the dynamical symmetries of the Interacting Boson Approximation (IBA) model iba () (in the limit of large valence nucleon number, ) and compare these results to available data. We will also use solutions for a series of potentials with intermediate shapes to study the evolution from one description (formula) to the other. Finally, we will show that IBA predictions near the critical point, for large , approach the same energy expression for states as given by the X(5) critical point symmetry.
In Fig. 1, the IBA triangle is shown with its dynamical symmetries and division into spherical and deformed regimes, separated by a phase transitional region phase1 (). We include the Alhassid-Whelan(AW) arc of regularity arc () and the geometric critical point models E(5) and X(5), although the latter do not belong to the IBA space.
For any infinite flat-bottomed (i.e., square well) potential, the energy eigenvalues are proportional to the squares of roots of the Bessel functions () where the order is different for each case. In E(5) e5 (), one has
ν=τ+3/2, (1)
with . In X(5) one has x5 ()
ν=√L(L+1)3+94 (2)
for all bands. In Z(5) one has z5 ()
ν=√L(L+4)+3nw(2L−nw)+92, (3)
with for all bandheads. As a result, in all three cases, the bandhead energies are given by the squares of subsequent roots of .
These energies are given in Table I and are plotted on the left in Fig. 2. While these seem quite different, if we normalize each energy to that of the first excited state - that is, consider relative eigenvalues - we see that these different models produce exactly identical results as seen on the right in Fig. 2 and given by (see column Norm in Table I): 0, 1, 2.5, 4.5, 7, 10. These energies are approximately described by the simple formula
E=An(n+3) (4)
where is the ordinal number of the state and where depends on the model.
This remarkable result systematizes the states of this wide array of seemingly diverse models. However, its significance runs much deeper. Consider now the models Z(4) in four dimensions and X(3) in three.
In Z(4) the order of the Bessel functions is given by
ν=√L(L+4)+3nw(2L−nw)+42, (5)
with for all states, giving () for =0.
In X(3) one has x3 ()
ν=√L(L+1)3+14, (6)
The energies given by Z(4) and X(3) can again be described by simple formulas, satisfying
E = An(n+2.5)Z(4) E = An(n+2).X(3) (7)
The results of Eqs. (4) and (Unified description of states in a large class of nuclear collective models) exemplify a universal formula that depends solely on the number of dimensions. The energies of all 0+ states in any flat-bottomed infinite square well potential in D dimensions are given by:
E=An(n+D+12) (8)
where, again, depends on the model. Figure 3(a) shows the results of Eq. (8) for = 3,4, and 5. These results reflect the deep relation between the order of the Bessel function solutions and the dimensionality of the potential, given by = (-2)/2. These results are exact for =3 and excellent approximations for low otherwise. (Compare Eq. (4) with Table II). These findings have applicability well beyond the models discussed above. For example, Eq. (8) gives the energies of all states in a recent model clark () of the critical point of a pairing vibration to pairing rotation phase transition in which the states span two degrees of freedom – excitation energies within a given nucleus and the sequences of masses along a series of even-even nuclei. Hadronic spectra have also been described brodsky () in terms of roots of Bessel functions.
The regularities found for states in solutions of the Bohr Hamiltonian with an infinite well potential in can be related to the second order Casimir operator of E(), the Euclidean algebra in dimensions, which is the semidirect sum Wyb () of the algebra T of translations in dimensions (generated by the momenta), and the SO() algebra of rotations in dimensions (generated by the angular momenta) symbolically written as E()=T SO(D) Barut (). The square of the total momentum, , is a second order Casimir operator of the algebra, and eigenfunctions of this operator satisfy z4 ()
(−1rD−1∂∂rrD−1∂∂r+ω(ω+D−2)r2)F(r)=k2F(r), (9)
in the left hand side of which the eigenvalues of the Casimir operator of SO(), appear Mosh1555 (). Performing the transformation , and using = + , Eq. (9) is brought into the form
(∂2∂r2+1r∂∂r+k2−ν2r2)f(r)=0, (10)
whose solutions are Bessel functions .
In the original developments of the infinite square well models, the “radial” equations are obtained, after the above transformation has been performed, in the form of Eq. (10) with the corresponding order . In E(5) all states obey Eq. (10) (with ), in Z(4) agreement occurs for all with and z4 (), while in X(5), X(3) and Z(5) (with ) agreement is limited to states with , i.e. to the bandheads. This situation resembles a partial dynamical symmetry AlhLev () of Type I Lev98 (), in which some of the states (here, the states) preserve all the relevant symmetry.
Do we find these patterns in real nuclei? As examples, we use the well-studied X(5) candidates, Nd, Sm and Gd. Normalizing to the experimental energy in each nucleus, Table II gives the energies predicted by Eqs. (4) and (8). In each nucleus, there is indeed a state within 100 keV of the predicted energy. In Nd this is in fact the state, while in the rest, it corresponds to a higher lying state, for which the determination of the degree of collectivity through improved spectroscopic information poses an experimental challenge.
Eqs. (4) and (Unified description of states in a large class of nuclear collective models) are peculiar to infinite square wells and thus limited to a select number of nuclei. What behavior then characterizes other potentials? Of course, this cannot be solved in general but there is at least one other class of models where an easy solution can be derived, namely, in the dynamical symmetries of the IBA.
In U(5), the energies are simply proportional to the number of bosons defining their respective phonon number, thus () = . In SU(3), the eigenvalue expression for = states, in terms of the usual representation labels ( , ), is = [ + + + 3( + ]. In O(6), the corresponding equation, in terms of the major family quantum number , is (for =0, states) = (+4). The irreducible representations for SU(3) and O(6) and the corresponding energies are given in Table III. Taking successive (, ) and quantum numbers and the limit we obtain:
E=An. (11)
Thus, perhaps surprisingly, considering how different their structures are, and analogous to the infinite flat potentials, a single, simple formula applies to all three dynamical symmetries of the IBA which exhibit identical relative energy spectra of states in the large limit. Equations (8) and (11) are compared in Fig. 3(a).
The description of states with a simple analytic formula extends beyond just the vertices discussed above. The behavior of states in the IBA symmetries can be associated with the chaotic properties of the IBA arc (). A regular region connects U(5) and O(6), resulting from the underlying O(5) symmetry. The regular behavior associated with U(5) and O(6) is preserved along the U(5)-O(6) leg, manifesting the relevant quasidynamical symmetries rowea (), until close to the point of the second order transition. An additional regular region, the AW arc of regularity, connects U(5) and SU(3) through the interior of the triangle (see Fig. 1). It has been conjectured chaos () that the regular region between SU(3) and the critical line is related to an underlying partial SU(3) symmetry. Included in Table II is a comparison between two well-deformed nuclei proposed jolie () to lie along the arc of regularity with the SU(3) predictions of Table III for the state and its nearly degenerate companion. Good agreement is observed, although the degree of collectivity of these states needs further experimental examination.
Most nuclei, however, are not described by dynamical symmetries or critical point models but lie somewhere in between mapping (). To study this and to see how Eq. (4) and Eq. (11) are related, or, better, how they evolve into one another moving across the symmetry triangle, we now consider a sequence of potentials of the form, V starting from , corresponding to U(5), and ending at either X(5) or E(5), which is successively approached by increasing powers of . The results are shown in Fig 3(b). As the potential flattens with increasing powers of , the results go from those for the U(5) limit to those for the infinite square well potentials. In each case, the normalized energies are well reproduced by a formula analogous to Eq. (4), namely (+) where for the IBA symmetries and drops to 3 for E(5)/X(5).
Finally, it has recently been discussed how the IBA with appropriate parameters approaches the predictions of the critical point symmetries as newPRL (). We use an IBA Hamiltonian in the form Werner ()
H(ζ,χ)=c[(1−ζ)^nd−ζ4NB^Qχ⋅^Qχ], (12)
where , is the number of valence bosons, and is a scaling factor. Calculations were performed with the IBAR code ibar ().
Included in Fig. 3(b) is an IBA calculation with = -/2 (bottom leg of the triangle), = 250 and = 0.473 newPRL (), which is very close to the critical point ( = 0.472) of the phase transition region in the IBA. One sees that the IBA results are very close to those of Eq. (4) consistent with the flat nature of the IBA energy surface near the critical point. This same result is also illustrated in Fig. 2. The normalized IBA energies are included in Table I and show a strong similarity with the results of the infinite square well potentials. Thus, it appears that the regularities in energies obtained in the infinite square well potentials are not restricted to geometrical models and also occur near the critical point of the IBA.
In summary, we have discussed very simple regularities in excited energies which pervade a number of different models. The energies of excited states in flat-bottomed infinite potentials can be described by a single expression dependent on only the number of dimensions. These observed regularities in energies are linked to the second order Casimir operator of E(). Further, the energies of states in all three dynamical symmetries of the IBA are governed, in the large limit, by a single expression. These results were compared to experimental data. Potentials with shapes intermediate between the U(5) symmetry and the infinite square well give a smooth evolution in the energies. Finally, IBA calculations with large , near the critical point of the phase transition, exhibit nearly the same energy dependence for states as given by the infinite square well potentials.
The authors thank R.J. Casperson, E. Williams, and V. Werner for their expertise with the IBAR code and R.M. Clark and A.O. Macchiavelli for useful discussions. This work was supported by U.S. DOE Grant No. DE-FG02-91ER-40609 and by the DOE Office of Nuclear Physics under contract DE-AC02-06CH11357.
## References
• (1) F. Iachello, N.V. Zamfir, and R.F. Casten, Phys. Rev. Lett. 81, 1191 (1998).
• (2) F. Iachello and N.V. Zamfir, Phys. Rev. Lett. 92, 212501 (2004).
• (3) F. Iachello, Phys. Rev. Lett. 85, 3580 (2000).
• (4) F. Iachello, Phys. Rev. Lett. 87, 052502 (2001).
• (5) R.F. Casten and N.V. Zamfir, Phys. Rev. Lett. 85, 3584 (2000).
• (6) R.F. Casten and N.V. Zamfir, Phys. Rev. Lett. 87, 052503 (2001).
• (7) R. Krücken et al., Phys. Rev. Lett. 88, 232501 (2002).
• (8) D. Tonev et al., Phys. Rev. C 69, 034334 (2004).
• (9) F. Iachello, F. Pérez-Bernal, and P.H. Vaccaro, Chem. Phys. Lett. 375, 309 (2003).
• (10) A. Bohr, Mat. Fys. Medd. K. Dan. Vidensk. Selsk. 26, no. 14 (1952).
• (11) D. Bonatsos et al., Phys. Lett. B 632, 238 (2006).
• (12) D. Bonatsos et al., Phys. Lett. B 621, 102 (2005).
• (13) D. Bonatsos et al., Phys. Lett. B 588, 172 (2004).
• (14) D.A. Meyer et al., Phys. Lett. B 638, 44 (2006).
• (15) D. Bucurescu et al., Phys. Rev. C 73, 064309 (2006).
• (16) N. Lo Iudice, A.V. Sushkov, and N. Yu. Shirikova, Phys. Rev. C 72, 034303 (2005).
• (17) T. Nikšić et al., Phys. Rev. Lett. 99, 092502 (2007).
• (18) F. Iachello and A. Arima, The Interacting Boson Model (Cambridge University Press, Cambridge, 1987).
• (19) Y. Alhassid and N. Whelan, Phys. Rev. Lett. 67, 816 (1991).
• (20) R.M. Clark et al., Phys. Rev. Lett. 96, 032501 (2006).
• (21) G.F. de Téramond and S.J. Brodsky, Phys. Rev. Lett. 94, 201601 (2005).
• (22) B. G. Wybourne, Classical Groups for Physicists (Wiley, New York, 1974).
• (23) A. O. Barut and R. Raczka, Theory of Group Representations and Applications (World Scientific, Singapore, 1986).
• (24) M. Moshinsky, J. Math. Phys. 25, 1555 (1984).
• (25) Y. Alhassid and A. Leviatan, J. Phys. A: Math. Gen. 25, L1265 (1992).
• (26) A. Leviatan, Phys. Rev. Lett. 98, 242502 (2007).
• (27) D.J. Rowe, Nucl. Phys. A 745, 47 (2004).
• (28) M. Macek et al., Phys. Rev. C 75, 064318 (2007).
• (29) J. Jolie et al., Phys. Rev. Lett. 93, 132501 (2004).
• (30) E.A. McCutchan, N.V. Zamfir, and R.F. Casten, Phys. Rev. C 69, 064306 (2004).
• (31) D. Bonatsos et al., Phys. Rev. Lett. 100, 142501 (2008).
• (32) V. Werner et al., Phys. Rev. C 61, 021301(R) (2000).
• (33) R.J. Casperson, IBAR code - unpublished.
You are adding the first comment!
How to quickly get a good reply:
• Give credit where it’s due by listing out the positive aspects of a paper before getting into which changes should be made.
• Be specific in your critique, and provide supporting evidence with appropriate references to substantiate general statements.
• Your comment should inspire ideas to flow and help the author improves the paper.
The better we are at sharing our knowledge with each other, the faster we move forward.
The feedback must be of minimum 40 characters and the title a minimum of 5 characters
|
2020-08-14 17:38:02
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8003571629524231, "perplexity": 1168.2237906117523}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-34/segments/1596439739347.81/warc/CC-MAIN-20200814160701-20200814190701-00376.warc.gz"}
|
http://www.aimsciences.org/article/doi/10.3934/mcrf.2015.5.517
|
# American Institute of Mathematical Sciences
• Previous Article
Controlled reflected mean-field backward stochastic differential equations coupled with value function and related PDEs
• MCRF Home
• This Issue
• Next Article
Transposition method for backward stochastic evolution equations revisited, and its application
September 2015, 5(3): 517-527. doi: 10.3934/mcrf.2015.5.517
## Optimal blowup/quenching time for controlled autonomous ordinary differential equations
1 School of Mathematical Sciences and LMNS, Fudan University, Shanghai 200433 2 School of Mathematical Sciences, Fudan University, Shanghai 200433, China
Received July 2014 Revised November 2014 Published July 2015
Blowup/Quenching time optimal control problems for controlled autonomous ordinary differential equations are considered. The main results are maximum principles for these time optimal control problems, including the transversality conditions.
Citation: Hongwei Lou, Weihan Wang. Optimal blowup/quenching time for controlled autonomous ordinary differential equations. Mathematical Control & Related Fields, 2015, 5 (3) : 517-527. doi: 10.3934/mcrf.2015.5.517
##### References:
[1] E. N. Barron and W. Liu, Optimal control of the blowup time,, SIAM J. Control Optim., 34 (1996), 102. doi: 10.1137/S0363012993245021. [2] S. Kaplan, On the growth of solutions of quasi-linear parabolic equations,, Comm. Pure Appl. Math., 16 (1963), 305. doi: 10.1002/cpa.3160160307. [3] H. Kawarada, On solutions of initial-boundary problem for $u_t=u_{x x}+1/(1-u)$,, Publ. Res. Inst. Math. Sci., 10 (): 729. doi: 10.2977/prims/1195191889. [4] P. Lin, Quenching time optimal control for some ordinary differential equations,, J. Appl. Math., (2014). doi: 10.1155/2014/127809. [5] P. Lin and G. Wang, Blowup time optimal control for ordinary differential equations,, SIAM J. Control Optim., 49 (2011), 73. doi: 10.1137/090764232. [6] H. Lou and W. Wang, Optimal blowup time for controlled ordinary differential equations,, ESAIM: COCV, 21 (2015), 815. [7] H. Lou, J. Wen and Y. Xu, Time optimal control problems for some non-smooth systems,, Math. Control Relat. Fields, 4 (2014), 289. doi: 10.3934/mcrf.2014.4.289. [8] R. Vinter, Optimal Control,, Birkhäuser, (2000). [9] J. Warga, Optimal Control of Differential and Functional Equations,, Academic Press, (1972). [10] K. Yosida, Functional Analysis,, Springer-Verlag, (1980).
show all references
##### References:
[1] E. N. Barron and W. Liu, Optimal control of the blowup time,, SIAM J. Control Optim., 34 (1996), 102. doi: 10.1137/S0363012993245021. [2] S. Kaplan, On the growth of solutions of quasi-linear parabolic equations,, Comm. Pure Appl. Math., 16 (1963), 305. doi: 10.1002/cpa.3160160307. [3] H. Kawarada, On solutions of initial-boundary problem for $u_t=u_{x x}+1/(1-u)$,, Publ. Res. Inst. Math. Sci., 10 (): 729. doi: 10.2977/prims/1195191889. [4] P. Lin, Quenching time optimal control for some ordinary differential equations,, J. Appl. Math., (2014). doi: 10.1155/2014/127809. [5] P. Lin and G. Wang, Blowup time optimal control for ordinary differential equations,, SIAM J. Control Optim., 49 (2011), 73. doi: 10.1137/090764232. [6] H. Lou and W. Wang, Optimal blowup time for controlled ordinary differential equations,, ESAIM: COCV, 21 (2015), 815. [7] H. Lou, J. Wen and Y. Xu, Time optimal control problems for some non-smooth systems,, Math. Control Relat. Fields, 4 (2014), 289. doi: 10.3934/mcrf.2014.4.289. [8] R. Vinter, Optimal Control,, Birkhäuser, (2000). [9] J. Warga, Optimal Control of Differential and Functional Equations,, Academic Press, (1972). [10] K. Yosida, Functional Analysis,, Springer-Verlag, (1980).
[1] Zaidong Zhan, Shuping Chen, Wei Wei. A unified theory of maximum principle for continuous and discrete time optimal control problems. Mathematical Control & Related Fields, 2012, 2 (2) : 195-215. doi: 10.3934/mcrf.2012.2.195 [2] Ping Lin, Weihan Wang. Optimal control problems for some ordinary differential equations with behavior of blowup or quenching. Mathematical Control & Related Fields, 2018, 8 (3&4) : 809-828. doi: 10.3934/mcrf.2018036 [3] Yan Wang, Yanxiang Zhao, Lei Wang, Aimin Song, Yanping Ma. Stochastic maximum principle for partial information optimal investment and dividend problem of an insurer. Journal of Industrial & Management Optimization, 2018, 14 (2) : 653-671. doi: 10.3934/jimo.2017067 [4] Shanjian Tang. A second-order maximum principle for singular optimal stochastic controls. Discrete & Continuous Dynamical Systems - B, 2010, 14 (4) : 1581-1599. doi: 10.3934/dcdsb.2010.14.1581 [5] Md. Haider Ali Biswas, Maria do Rosário de Pinho. A nonsmooth maximum principle for optimal control problems with state and mixed constraints - convex case. Conference Publications, 2011, 2011 (Special) : 174-183. doi: 10.3934/proc.2011.2011.174 [6] Hans Josef Pesch. Carathéodory's royal road of the calculus of variations: Missed exits to the maximum principle of optimal control theory. Numerical Algebra, Control & Optimization, 2013, 3 (1) : 161-173. doi: 10.3934/naco.2013.3.161 [7] Andrei V. Dmitruk, Nikolai P. Osmolovskii. Proof of the maximum principle for a problem with state constraints by the v-change of time variable. Discrete & Continuous Dynamical Systems - B, 2019, 24 (5) : 2189-2204. doi: 10.3934/dcdsb.2019090 [8] Yi Wang, Dun Zhou. Transversality for time-periodic competitive-cooperative tridiagonal systems. Discrete & Continuous Dynamical Systems - B, 2015, 20 (6) : 1821-1830. doi: 10.3934/dcdsb.2015.20.1821 [9] Luong V. Nguyen. A note on optimality conditions for optimal exit time problems. Mathematical Control & Related Fields, 2015, 5 (2) : 291-303. doi: 10.3934/mcrf.2015.5.291 [10] Piermarco Cannarsa, Cristina Pignotti, Carlo Sinestrari. Semiconcavity for optimal control problems with exit time. Discrete & Continuous Dynamical Systems - A, 2000, 6 (4) : 975-997. doi: 10.3934/dcds.2000.6.975 [11] Giuseppe Maria Coclite, Mauro Garavello, Laura V. Spinolo. Optimal strategies for a time-dependent harvesting problem. Discrete & Continuous Dynamical Systems - S, 2018, 11 (5) : 865-900. doi: 10.3934/dcdss.2018053 [12] Piotr Kopacz. A note on time-optimal paths on perturbed spheroid. Journal of Geometric Mechanics, 2018, 10 (2) : 139-172. doi: 10.3934/jgm.2018005 [13] Kim Dang Phung, Gengsheng Wang, Xu Zhang. On the existence of time optimal controls for linear evolution equations. Discrete & Continuous Dynamical Systems - B, 2007, 8 (4) : 925-941. doi: 10.3934/dcdsb.2007.8.925 [14] N. Arada, J.-P. Raymond. Time optimal problems with Dirichlet boundary controls. Discrete & Continuous Dynamical Systems - A, 2003, 9 (6) : 1549-1570. doi: 10.3934/dcds.2003.9.1549 [15] Jérome Lohéac, Jean-François Scheid. Time optimal control for a nonholonomic system with state constraint. Mathematical Control & Related Fields, 2013, 3 (2) : 185-208. doi: 10.3934/mcrf.2013.3.185 [16] Zuzana Chladná. Optimal time to intervene: The case of measles child immunization. Mathematical Biosciences & Engineering, 2018, 15 (1) : 323-335. doi: 10.3934/mbe.2018014 [17] Piermarco Cannarsa, Carlo Sinestrari. On a class of nonlinear time optimal control problems. Discrete & Continuous Dynamical Systems - A, 1995, 1 (2) : 285-300. doi: 10.3934/dcds.1995.1.285 [18] Shu Dai, Dong Li, Kun Zhao. Finite-time quenching of competing species with constrained boundary evaporation. Discrete & Continuous Dynamical Systems - B, 2013, 18 (5) : 1275-1290. doi: 10.3934/dcdsb.2013.18.1275 [19] Y. Latushkin, B. Layton. The optimal gap condition for invariant manifolds. Discrete & Continuous Dynamical Systems - A, 1999, 5 (2) : 233-268. doi: 10.3934/dcds.1999.5.233 [20] Paula A. González-Parra, Sunmi Lee, Leticia Velázquez, Carlos Castillo-Chavez. A note on the use of optimal control on a discrete time model of influenza dynamics. Mathematical Biosciences & Engineering, 2011, 8 (1) : 183-197. doi: 10.3934/mbe.2011.8.183
2017 Impact Factor: 0.631
|
2019-06-20 03:02:32
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6564973592758179, "perplexity": 6047.255487650025}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-26/segments/1560627999130.98/warc/CC-MAIN-20190620024754-20190620050754-00218.warc.gz"}
|
https://math.stackexchange.com/questions/1938606/why-is-identity-element-of-monoid-defined-as-morphism
|
# Why is identity element of monoid defined as morphism?
Sorry, I am new to category theory (actually all fields of math...). When I was learning the concept of monoid in college, the identity element is roughly defined as "an element e of set which satisfy $e * a = a = a * e$, for every a in that set". But when I am learning this concept again for understanding monad. The identity element of monoid is defined as a morphism (see here). Could anyone please explain why these two definitions of monoid (in particular the identity of monoid) are equivalent. Thanks!
EDIT:
Some other definition that represents the identity of monoid as morphism:
A definition from a math website
Another definition in stackoverflow (in the highest vote answer)
• Can you please post the exact definition of monoid and identity element you're referring to? I can probably answer this question given more details, but I can't extrapolate what definition you're trying to clarify from what you've written. – user231101 Sep 23 '16 at 16:15
• The identity element "e" is such $e*a=a=a*e$. Compare your definition of the identity element. – amWhy Sep 23 '16 at 16:16
• Hi @MikeHaskel, sorry I am not familiar with latex notation(it's my first time to post in this site). I have attach a link to wikipedia page where the identity of monoid is defined as a natural transformation. Thank you for you help. – Lifu Huang Sep 23 '16 at 16:27
• In the linked definition, the unit is a morphism, not a natural transformation. Did you misread it, did you have a different definition in mind, or do you not see the difference between the two? – user231101 Sep 23 '16 at 16:43
• @MikeHaskel the definition in the link is what I want to know. I have edited my question. I just realize that the reason why I thought identity as a natural transformation is that I read a definition somewhere else talking about monad. So could you please explain why this definition (identity as morphism) is equivalent to the one I learned in college? Thanks! – Lifu Huang Sep 23 '16 at 16:57
The definition you linked to is doing more than just defining a monoid. It's actually defining a monoid object in a (monoidal) category. The usual notion of a monoid is a monoid object in $\operatorname{Set}$. Let's see how the definition plays out in that context.
According the the linked definition, the identity is a morphism from $1$—the unit object of the monoidal category—into the object of the monoid, $M$. In $\operatorname{Set}$, the unit object is any one-element set. The only data associated with a function from a one-element set to $M$ is knowledge of where the function sends that one element. That is, a function from a one-element set to $M$ is essentially just an element of $M$, so the definition aligns with the usual one.
The reason the general definition is phrased in terms of morphisms is because, in a general monoidal category, there might not be a notion of an "element." A morphism from the unit object to $M$ will still make sense, however.
|
2021-06-13 11:58:54
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9391935467720032, "perplexity": 210.35004227427277}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-25/segments/1623487608702.10/warc/CC-MAIN-20210613100830-20210613130830-00462.warc.gz"}
|
https://cce.sh/2021/01/11/solar-panels.html
|
# Why don't we cover all rooftops in solar panels?
I was walking around the city one day and I noticed how much empty space there is on top of buildings. Why not cover them with solar panels? Would it even be feasible?
Most buildings in my city are soviet-style 10-story apartment buildings with a flat, mostly unused roof. The ground footprint of these buildings is a rectangle.
The average efficiency of solar panels falls between 17%-19%.
This is a map of solar radiation in Europe.
Here, we get around 1,400kWh/$$m^2$$/$$year$$, so ~3.84kWh/$$m^2$$/$$day$$. A 17.5% panel efficiency ratio means that we can extract a maximum of 0.672kWh/$$m^2$$/$$day$$. And this is before conversion and storage losses.
On average, I use 7-8kW / day during the winter and up to 15kW / day during the summer. Adjusted for surface, that's anywhere from 0.2-0.4kW/$$m^2$$/$$day$$, so the solar panels would barely provide enough electricity for an entire floor.
|
2021-09-27 09:56:46
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5742753148078918, "perplexity": 2441.348286451936}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-39/segments/1631780058415.93/warc/CC-MAIN-20210927090448-20210927120448-00300.warc.gz"}
|
http://mathoverflow.net/feeds/user/18384
|
User felipeg - MathOverflow most recent 30 from http://mathoverflow.net 2013-05-19T16:04:58Z http://mathoverflow.net/feeds/user/18384 http://www.creativecommons.org/licenses/by-nc/2.5/rdf http://mathoverflow.net/questions/128259/is-function-from-topological-group-to-metric-space-borel Is function from topological group to metric space Borel? FelipeG 2013-04-21T16:52:51Z 2013-04-21T19:05:58Z <p>Let $G$ be a pseudometrizable compact abelian topological group, $X$ a compact metric space and $f:X\rightarrow G$ a continuous bijective function.</p> <p>Suppose there exists $g\in G$ such that if $d_{G}(g_{1},g_{2})\leq\epsilon$ then there exists $n$ such that $d_{X}(f^{-1}g^{n}g_{1},f^{-1}g^{n}g_{2})\leq\epsilon.$</p> <p>If $G$ is not metrizable then in general $f^{-1}$ is not continuous but can we conclude $f^{-1}$ is Borel? </p> http://mathoverflow.net/questions/128183/existence-of-limit-measure Existence of limit measure FelipeG 2013-04-20T17:46:28Z 2013-04-20T20:50:45Z <p>Let $X$ be a separable metric space, $\mu_{n}$ a sequence of Borel probability measures and $\mathcal{C}$ be a family of sets that is closed under finite unions and interections, and that contains all the balls. If $\mu_{n}(A)$ converges for every $A\in\mathcal{C}$, does there exists a Borel measure $\mu_{\infty}$ such that $\mu_{\infty}(E)=\lim\mu_{n}(E)$ for every $E\in\mathcal{C}?$</p> <p>From Theorem 4.3 in <a href="http://msp.org/pjm/1964/14-3/pjm-v14-n3-p23-p.pdf" rel="nofollow">this paper</a> we can get this result when $X$ is locally compact. Here Sion makes an outer measure and then shows open sets are measurable. His proof definitively uses local compactness. </p> <p>Does anybody know if the result is true when $X$ is not necessarily locally compact?</p> http://mathoverflow.net/questions/123252/extension-of-measures-from-the-ball-sigma-algebra-to-the-borel-sigma-algebra Extension of measures from the ball sigma-algebra to the borel sigma-algebra FelipeG 2013-02-28T18:32:52Z 2013-02-28T19:52:30Z <p>Let $X$ be a metric space, $\Sigma_{1}$ the borel sigma algebra and $\Sigma_{2}$ the sigma algebra generated by balls (open and closed). </p> <p>If $\mu$ is a probability measure on $\Sigma_{2}$ can it be extended to a measure on $\Sigma_{1}?$</p> http://mathoverflow.net/questions/121036/do-ergodic-isometries-have-discrete-spectrum Do ergodic isometries have discrete spectrum? FelipeG 2013-02-07T03:19:11Z 2013-02-07T03:19:11Z <p>Let $X$ be a metric space, $\mu$ a Borel probability measure, and $T:X\rightarrow X$ be an ergodic measure preserving isometry. </p> <p>Is $(X,\mu,T)$ measure theoretically isomorphic to a minimal isometry on a compact metric space (equivalently it has discrete spectrum)?</p> <p>I understand Krieger representation theorem states that ergodic MPT are measure theoretically isomorphic to minimal systems on a compact metric spaces. I would like to know if structure like isometry can be conserved. </p> <p>The general question I am interested in is: do ergodic isometries have discrete spectrum?</p> http://mathoverflow.net/questions/111949/weak-convergence-and-cesaro-convergence-of-mu-n-e-imply-convergence-of-mu Weak convergence, and Cesaro convergence (of mu_n (E) ) imply convergence (of mu_n (E))? FelipeG 2012-11-09T23:16:57Z 2012-11-12T19:55:25Z <p>Let $X$ be a compact metric Borel space. Suppose $\mu_{n}(A)\rightarrow\mu(A)$ for all $\mu-$continuity sets $A$ (sets with zero boundary measure), where $\mu_{n}$ is a sequence of probability measures. (some people call it weak other weak* convergence)</p> <p>If $E$ is a measurable set such that $\mu(E)>0$ and the Cesaro average of $\mu_{n}(E)$ converges; can we conclude that $\mu_{n}(E)$ converges? </p> <p>Can we conclude this with extra hypothesis?</p> <p>I am particularly interested in the case when $T:X\rightarrow X$ is a continuous transformation, $\mu_{n}=T^{n}\mu_{1},$ and $E=\cap T^{-i}A_{i}$ where $A_{i}$ is a sequence of $\mu-$continuity sets. </p> http://mathoverflow.net/questions/48771/proofs-that-require-fundamentally-new-ways-of-thinking/94167#94167 Answer by FelipeG for Proofs that require fundamentally new ways of thinking FelipeG 2012-04-16T01:00:28Z 2012-04-16T01:00:28Z <p>The first formal proofs using limits. (the oldest ones I know are in Newton's Principia)</p> http://mathoverflow.net/questions/87952/a-system-of-equations-for-integers A system of equations for integers FelipeG 2012-02-09T02:20:25Z 2012-02-10T23:43:52Z <p>Working with cellular automata I came across a system of equations for unknown integers $R_{k}$ and $C_{k}$ that looks like this.</p> <p>$\binom{m}{k}=R_{k}+C_{k}+\sum\limits_{j=1}^{k-1}R_{j}C_{k-j}.$</p> <p>Where 0< k$\leq$ 2m </p> <p>(for k>m we take $\binom{m}{k}=R_{k}=C_{k}=0$)</p> <p>Given $R_{1}$, the system has a unique solution. </p> <p>Has anyone seen something similar? Do you know if it still possible to solve it, if instead of $\binom{m}{k}$ in the left you put something else? </p> <p>I just want to know if it's related to something else, and if it's possible to solve more general systems. </p> http://mathoverflow.net/questions/79531/bijective-function-on-a-dense-set Bijective function on a dense set FelipeG 2011-10-30T18:28:23Z 2011-11-03T14:54:41Z <p>Suppose X is a complete metric space, and $f:X↦X$ a continuous surjective function. Let D be a dense set. Suppose $f:D↦D$ is injective and $f^{-1}(D)=D$. </p> <p>Is $f$ injective ?</p> <p>Is there a family of metric spaces where you can conclude $f$ is injective?</p> http://mathoverflow.net/questions/128259/is-function-from-topological-group-to-metric-space-borel/128277#128277 Comment by FelipeG FelipeG 2013-04-22T18:27:40Z 2013-04-22T18:27:40Z Thanks for your comment. There is something I don't understand. Are you assuming the closure of the identity is not a single point? Is this is necessarily true? http://mathoverflow.net/questions/128259/is-function-from-topological-group-to-metric-space-borel Comment by FelipeG FelipeG 2013-04-22T18:13:55Z 2013-04-22T18:13:55Z Sure. The multiplication of g is a dynamical system, a rotation in a compact abelian group. I want to construct a dynamical isomorphism from a dynamical system in X to G. http://mathoverflow.net/questions/128183/existence-of-limit-measure Comment by FelipeG FelipeG 2013-04-21T17:18:41Z 2013-04-21T17:18:41Z Thanks for your comments. Theorem 4.3 talks about two kinds of limits. The other limit is the outer measure constructed in section 3. Theorem 3.3 mentions that the outer measure is Radon (hence every borel set is measurable) if every open set is the countable union of compact sets. http://mathoverflow.net/questions/121036/do-ergodic-isometries-have-discrete-spectrum Comment by FelipeG FelipeG 2013-02-07T08:41:57Z 2013-02-07T08:41:57Z Sure, a theorem by Halmos and Von Neumann state that T is transitive (one dense orbit) and isometric, iff it is topologically isomoprhic to a minimal rotation on a compact abelian group iff T is minimal and has discrete topological spectrum. (topological because in this case the operator associated to the dynamical system is acting on the space of continuous functions. ) A good reference for this is An introduction to ergodic theory by Peter Walters. http://mathoverflow.net/questions/119133/a-similar-result-to-lusins-theorem-to-characterize-borel-measures Comment by FelipeG FelipeG 2013-01-17T18:10:45Z 2013-01-17T18:10:45Z Thank you Bill. Andreas: I am mostly curious about metric spaces but I don't think that assumption is necessary. http://mathoverflow.net/questions/111949/weak-convergence-and-cesaro-convergence-of-mu-n-e-imply-convergence-of-mu/111960#111960 Comment by FelipeG FelipeG 2012-11-12T20:05:31Z 2012-11-12T20:05:31Z Thanks, I was not looking for the case when the cesaro means do not converge. I wanted that as a part of the hypothesis. But I think your counter example works, if you take $x_{n}$=0 only sporadically, then you will have cesaro mean convergence but not convergence. http://mathoverflow.net/questions/101593/discrete-rational-spectrum-and-odometers Comment by FelipeG FelipeG 2012-07-11T22:02:39Z 2012-07-11T22:02:39Z I think that works, thanks. http://mathoverflow.net/questions/87952/a-system-of-equations-for-integers/87995#87995 Comment by FelipeG FelipeG 2012-02-10T18:10:31Z 2012-02-10T18:10:31Z Yes , that exactly what I meant. by "Given R1, the system has a unique solution." thanks for clearing this out. http://mathoverflow.net/questions/87952/a-system-of-equations-for-integers Comment by FelipeG FelipeG 2012-02-10T17:42:10Z 2012-02-10T17:42:10Z Because I want things like $R_{m-1}C_{2}$ to be zero.
|
2013-05-19 16:04:56
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9606780409812927, "perplexity": 923.5476143071231}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368697772439/warc/CC-MAIN-20130516094932-00015-ip-10-60-113-184.ec2.internal.warc.gz"}
|
https://socratic.org/questions/can-someone-help-verify-the-answer
|
# Can someone help verify the answer?
## I obtain 58.1 N for b, can someone verify if my answer is correct?
Mar 22, 2016
(a) $81.928 N$
(b) $81.928 N$
#### Explanation:
(a) Force of static friction which needs to be overcome to move the sled 1
${F}_{k 1} =$Coefficient of static friction ${\mu}_{k} \times$normal force ${\eta}_{1}$
where ${\eta}_{1} = {m}_{1} g$
Inserting given quantities and taking the value of $g = 9.8 m / {s}^{2}$
${F}_{k 1} = 0.22 \times 27 \times 9.8 N$
${F}_{k 1} = 58.212 N$
Similarly, force of static friction which needs to be overcome to move the sled 2
${F}_{k 2} = 0.22 \times 38 \times 9.8 N$
${F}_{k 2} = 81.928 N$
As both the sleds are tied with the help of rope, any force applied by the adult on sled 1 gets transferred to sled 2 via rope. We see that sled 2, which is heavier of the two, will not move unless its force of static friction is overcome.
This implies that greatest horizontal force an adult can apply on sled 1 without either sled moving is ${F}_{k 2} = 81.928 N$
(b) Magnitude of tension in the rope between the sleds when the adult applies this greatest force must be equal to magnitude of $| {F}_{k 2} | = 81.928 N$. Because this is the force which is resisting motion of sled 2.
|
2019-10-13 22:58:39
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 13, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5163854360580444, "perplexity": 1181.7518232481432}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-43/segments/1570986648343.8/warc/CC-MAIN-20191013221144-20191014004144-00429.warc.gz"}
|
https://cs.stackexchange.com/questions/16586/best-worst-and-average-cases-for-a-function-that-uses-random-number-generator
|
# Best, worst and average cases for a function that uses random number generator
For the following function (not in particular coding style or programming languange)
f (N, y) // y is an integer such that 0 <= y < N
{
x = rand (N) // rand (N) returns a random integer x satisfying 0 <= x < N
if (y == rand (N))
return
else f (N, y)
}
I need to find best, worst and average cases using O-notation. So my assumption is that the line
x = rand (N)
does nothing particular but in each recursion it takes O(1) (correct me if my assumption is wrong).
Now, the best case is quite obvious - rand() will give y or O(1).
The thing that I have stuck in are the worst and average cases. In the worst case it will just go into infinite iteration, but what is the complexity for a function that does not halt? And what is the average case? My assumption about the average case is that it will go through all N integers and then find y.
• What have you tried? What do you know about average-case complexity? Do you know the definition of average-case complexity? Have you tried plugging it in? – D.W. Oct 30 '13 at 17:59
To answer your first question, the average-case complexity of an algorithm that does not halt is, well, infinite ($\infty$).
|
2019-11-12 03:48:00
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.738888680934906, "perplexity": 811.4877395497609}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-47/segments/1573496664567.4/warc/CC-MAIN-20191112024224-20191112052224-00098.warc.gz"}
|
http://umj.imath.kiev.ua/authors/name/?lang=en&author_id=3587
|
2019
Том 71
№ 1
# Mosić D.
Articles: 1
Brief Communications (English)
### Representations for the generalized inverses of a modified operator
Ukr. Mat. Zh. - 2016. - 68, № 6. - pp. 860-864
Some explicit representations for the generalized inverses of a modified operator $A + YGZ$ are derived under some conditions, where $A, Y, Z$, and $G$ are operators between Banach spaces. These results generalize the recent works about the Drazin inverse and the Moore – Penrose inverse of complex matrices and Hilbert-space operators.
|
2019-02-17 09:22:29
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4651812016963959, "perplexity": 918.3960107499604}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-09/segments/1550247481832.13/warc/CC-MAIN-20190217091542-20190217113542-00045.warc.gz"}
|
https://en.wikipedia.org/wiki/Clausius-Mossotti_relation
|
# Clausius–Mossotti relation
(Redirected from Clausius-Mossotti relation)
The Clausius–Mossotti relation expresses the dielectric constant (relative permittivity) εr of a material in terms of the atomic polarizibility α of the material's constituent atoms and/or molecules, or a homogeneous mixture thereof. It is named after Ottaviano-Fabrizio Mossotti and Rudolf Clausius. It is equivalent to the Lorentz–Lorenz equation. It may be expressed as:[1][2]
${\displaystyle {\frac {\epsilon _{\mathrm {r} }-1}{\epsilon _{\mathrm {r} }+2}}={\frac {N\alpha }{3\epsilon _{0}}}}$
where
• ${\displaystyle \epsilon _{r}=\epsilon /\epsilon _{0}}$ is the dielectric constant of the material
• ${\displaystyle \epsilon _{0}}$ is the permittivity of free space
• ${\displaystyle N}$ is the number density of the molecules (number per cubic meter), and
• ${\displaystyle \alpha }$ is the molecular polarizability in SI-units (C·m2/V).
In the case that the material consists of a mixture of two or more species, the right hand side of the above equation would consist of the sum of the molecular polarizability contribution from each species, indexed by i in the following form:
${\displaystyle {\frac {\epsilon _{\mathrm {r} }-1}{\epsilon _{\mathrm {r} }+2}}=\sum _{i}{\frac {N_{i}\alpha _{i}}{3\epsilon _{0}}}}$
In the CGS system of units the Clausius–Mossotti relation is typically rewritten to show the molecular polarizability volume ${\displaystyle \alpha '=\alpha /(4\pi \varepsilon _{0})}$ which has units of volume (m3).[2] Confusion may arise from the practice of using the shorter name "molecular polarizability" for both ${\displaystyle \alpha }$ and ${\displaystyle \alpha '}$ within literature intended for the respective unit system.
## References
• C.J.F. Böttcher, Theory of electric polarization, Elsevier Publishing Company, 1952
1. ^ Rysselberghe, P. V. (January 1932). "Remarks concerning the Clausius–Mossotti Law". J. Phys. Chem. 36 (4): 1152–1155. doi:10.1021/j150334a007.
2. ^ a b Atkins, Peter; de Paula, Julio (2010). "Chapter 17". Atkins' Physical Chemistry. Oxford University Press. pp. 622–629. ISBN 978-0-19-954337-3.
• R. Clausius, "Die Mechanische Behandlung der Electricität", Vieweg+Teubner Verlag; Wiesbaden, 1879, ISBN 978-3-663-19891-8, https://link.springer.com/book/10.1007%2F978-3-663-20232-5
• O. F. Mossotti, Discussione analitica sull’influenza che l’azione di un mezzo dielettrico ha sulla distribuzione dell’elettricità alla superficie di più corpi elettrici disseminati in esso, Memorie di Mathematica e di Fisica della Società Italiana della Scienza Residente in Modena, vol. 24, p. 49-74 (1850).
|
2017-10-21 03:19:16
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 9, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8111169934272766, "perplexity": 5008.727174501053}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-43/segments/1508187824543.20/warc/CC-MAIN-20171021024136-20171021044136-00571.warc.gz"}
|
https://homework.cpm.org/category/CON_FOUND/textbook/a2c/chapter/4/lesson/4.3.1/problem/4-136
|
### Home > A2C > Chapter 4 > Lesson 4.3.1 > Problem4-136
4-136.
Start by breaking up the equation into two smaller ones.
|
2020-09-24 12:27:31
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8104202151298523, "perplexity": 4650.212929672585}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-40/segments/1600400217623.41/warc/CC-MAIN-20200924100829-20200924130829-00288.warc.gz"}
|
https://en.wikipedia.org/wiki/Linear_probing
|
# Linear probing
The collision between John Smith and Sandra Dee (both hashing to cell 873) is resolved by placing Sandra Dee at the next free location, cell 874.
Linear probing is a scheme in computer programming for resolving collisions in hash tables, data structures for maintaining a collection of key–value pairs and looking up the value associated with a given key. It was invented in 1954 by Gene Amdahl, Elaine M. McGraw, and Arthur Samuel and first analyzed in 1963 by Donald Knuth.
Along with quadratic probing and double hashing, linear probing is a form of open addressing. In these schemes, each cell of a hash table stores a single key–value pair. When the hash function causes a collision by mapping a new key to a cell of the hash table that is already occupied by another key, linear probing searches the table for the closest following free location and inserts the new key there. Lookups are performed in the same way, by searching the table sequentially starting at the position given by the hash function, until finding a cell with a matching key or an empty cell.
As Thorup & Zhang (2012) write, "Hash tables are the most commonly used nontrivial data structures, and the most popular implementation on standard hardware uses linear probing, which is both fast and simple."[1] Linear probing can provide high performance because of its good locality of reference, but is more sensitive to the quality of its hash function than some other collision resolution schemes. It takes constant expected time per search, insertion, or deletion when implemented using a random hash function, a 5-independent hash function, or tabulation hashing. However, good results can be achieved in practice with other hash functions such as MurmurHash[2].
## Operations
Linear probing is a component of open addressing schemes for using a hash table to solve the dictionary problem. In the dictionary problem, a data structure should maintain a collection of key–value pairs subject to operations that insert or delete pairs from the collection or that search for the value associated with a given key. In open addressing solutions to this problem, the data structure is an array T (the hash table) whose cells T[i] (when nonempty) each store a single key–value pair. A hash function is used to map each key into the cell of T where that key should be stored, typically scrambling the keys so that keys with similar values are not placed near each other in the table. A hash collision occurs when the hash function maps a key into a cell that is already occupied by a different key. Linear probing is a strategy for resolving collisions, by placing the new key into the closest following empty cell.[3][4]
### Search
To search for a given key x, the cells of T are examined, beginning with the cell at index h(x) (where h is the hash function) and continuing to the adjacent cells h(x) + 1, h(x) + 2, ..., until finding either an empty cell or a cell whose stored key is x. If a cell containing the key is found, the search returns the value from that cell. Otherwise, if an empty cell is found, the key cannot be in the table, because it would have been placed in that cell in preference to any later cell that has not yet been searched. In this case, the search returns as its result that the key is not present in the dictionary.[3][4]
### Insertion
To insert a key–value pair (x,v) into the table (possibly replacing any existing pair with the same key), the insertion algorithm follows the same sequence of cells that would be followed for a search, until finding either an empty cell or a cell whose stored key is x. The new key–value pair is then placed into that cell.[3][4]
If the insertion would cause the load factor of the table (its fraction of occupied cells) to grow above some preset threshold, the whole table may be replaced by a new table, larger by a constant factor, with a new hash function, as in a dynamic array. Setting this threshold close to zero and using a high growth rate for the table size leads to faster hash table operations but greater memory usage than threshold values close to one and low growth rates. A common choice would be to double the table size when the load factor would exceed 1/2, causing the load factor to stay between 1/4 and 1/2.[5]
### Deletion
When a key–value pair is deleted, it may be necessary to move another pair backwards into its cell, to prevent searches for the moved key from finding an empty cell.
It is also possible to remove a key–value pair from the dictionary. However, it is not sufficient to do so by simply emptying its cell. This would affect searches for other keys that have a hash value earlier than the emptied cell, but that are stored in a position later than the emptied cell. The emptied cell would cause those searches to incorrectly report that the key is not present.
Instead, when a cell i is emptied, it is necessary to search forward through the following cells of the table until finding either another empty cell or a key that can be moved to cell i (that is, a key whose hash value is equal to or earlier than i). When an empty cell is found, then emptying cell i is safe and the deletion process terminates. But, when the search finds a key that can be moved to cell i, it performs this move. This has the effect of speeding up later searches for the moved key, but it also empties out another cell, later in the same block of occupied cells. The search for a movable key continues for the new emptied cell, in the same way, until it terminates by reaching a cell that was already empty. In this process of moving keys to earlier cells, each key is examined only once. Therefore, the time to complete the whole process is proportional to the length of the block of occupied cells containing the deleted key, matching the running time of the other hash table operations.[3]
Alternatively, it is possible to use a lazy deletion strategy in which a key–value pair is removed by replacing the value by a special flag value indicating a deleted key. However, these flag values will contribute to the load factor of the hash table. With this strategy, it may become necessary to clean the flag values out of the array and rehash all the remaining key–value pairs once too large a fraction of the array becomes occupied by deleted keys.[3][4]
## Properties
Linear probing provides good locality of reference, which causes it to require few uncached memory accesses per operation. Because of this, for low to moderate load factors, it can provide very high performance. However, compared to some other open addressing strategies, its performance degrades more quickly at high load factors because of primary clustering, a tendency for one collision to cause more nearby collisions.[3] Additionally, achieving good performance with this method requires a higher-quality hash function than for some other collision resolution schemes.[6] When used with low-quality hash functions that fail to eliminate nonuniformities in the input distribution, linear probing can be slower than other open-addressing strategies such as double hashing, which probes a sequence of cells whose separation is determined by a second hash function, or quadratic probing, where the size of each step varies depending on its position within the probe sequence.[7]
## Analysis
Using linear probing, dictionary operations can be implemented in constant expected time. In other words, insert, remove and search operations can be implemented in O(1), as long as the load factor of the hash table is a constant strictly less than one.[8]
In more detail, the time for any particular operation (a search, insertion, or deletion) is proportional to the length of the contiguous block of occupied cells at which the operation starts. If all starting cells are equally likely, in a hash table with N cells, then a maximal block of k occupied cells will have probability k/N of containing the starting location of a search, and will take time O(k) whenever it is the starting location. Therefore, the expected time for an operation can be calculated as the product of these two terms, O(k2/N), summed over all of the maximal blocks of contiguous cells in the table. A similar sum of squared block lengths gives the expected time bound for a random hash function (rather than for a random starting location into a specific state of the hash table), by summing over all the blocks that could exist (rather than the ones that actually exist in a given state of the table), and multiplying the term for each potential block by the probability that the block is actually occupied. That is, defining Block(i,k) to be the event that there is a maximal contiguous block of occupied cells of length k beginning at index i, the expected time per operation is
${\displaystyle E[T]=O(1)+\sum _{i=1}^{N}\sum _{k=1}^{n}O(k^{2}/N)\operatorname {Pr} [\operatorname {Block} (i,k)].}$
This formula can be simiplified by replacing Block(i,k) by a simpler necessary condition Full(k), the event that at least k elements have hash values that lie within a block of cells of length k. After this replacement, the value within the sum no longer depends on i, and the 1/N factor cancels the N terms of the outer summation. These simplifications lead to the bound
${\displaystyle E[T]\leq O(1)+\sum _{k=1}^{n}O(k^{2})\operatorname {Pr} [\operatorname {Full} (k)].}$
But by the multiplicative form of the Chernoff bound, when the load factor is bounded away from one, the probability that a block of length k contains at least k hashed values is exponentially small as a function of k, causing this sum to be bounded by a constant independent of n.[3] It is also possible to perform the same analysis using Stirling's approximation instead of the Chernoff bound to estimate the probability that a block contains exactly k hashed values.[4][9]
In terms of the load factor α, the expected time for a successful search is O(1 + 1/(1 − α)), and the expected time for an unsuccessful search (or the insertion of a new key) is O(1 + 1/(1 − α)2).[10] For constant load factors, with high probability, the longest probe sequence (among the probe sequences for all keys stored in the table) has logarithmic length.[11]
## Choice of hash function
Because linear probing is especially sensitive to unevenly distributed hash values,[7] it is important to combine it with a high-quality hash function that does not produce such irregularities.
The analysis above assumes that each key's hash is a random number independent of the hashes of all the other keys. This assumption is unrealistic for most applications of hashing. However, random or pseudorandom hash values may be used when hashing objects by their identity rather than by their value. For instance, this is done using linear probing by the IdentityHashMap class of the Java collections framework.[12] The hash value that this class associates with each object, its identityHashCode, is guaranteed to remain fixed for the lifetime of an object but is otherwise arbitrary.[13] Because the identityHashCode is constructed only once per object, and is not required to be related to the object's address or value, its construction may involve slower computations such as the call to a random or pseudorandom number generator. For instance, Java 8 uses an Xorshift pseudorandom number generator to construct these values.[14]
For most applications of hashing, it is necessary to compute the hash function for each value every time that it is hashed, rather than once when its object is created. In such applications, random or pseudorandom numbers cannot be used as hash values, because then different objects with the same value would have different hashes. And cryptographic hash functions (which are designed to be computationally indistinguishable from truly random functions) are usually too slow to be used in hash tables.[15] Instead, other methods for constructing hash functions have been devised. These methods compute the hash function quickly, and can be proven to work well with linear probing. In particular, linear probing has been analyzed from the framework of k-independent hashing, a class of hash functions that are initialized from a small random seed and that are equally likely to map any k-tuple of distinct keys to any k-tuple of indexes. The parameter k can be thought of as a measure of hash function quality: the larger k is, the more time it will take to compute the hash function but it will behave more similarly to completely random functions. For linear probing, 5-independence is enough to guarantee constant expected time per operation,[16] while some 4-independent hash functions perform badly, taking up to logarithmic time per operation.[6]
Another method of constructing hash functions with both high quality and practical speed is tabulation hashing. In this method, the hash value for a key is computed by using each byte of the key as an index into a table of random numbers (with a different table for each byte position). The numbers from those table cells are then combined by a bitwise exclusive or operation. Hash functions constructed this way are only 3-independent. Nevertheless, linear probing using these hash functions takes constant expected time per operation.[4][17] Both tabulation hashing and standard methods for generating 5-independent hash functions are limited to keys that have a fixed number of bits. To handle strings or other types of variable-length keys, it is possible to compose a simpler universal hashing technique that maps the keys to intermediate values and a higher quality (5-independent or tabulation) hash function that maps the intermediate values to hash table indices.[1][18]
In an experimental comparison, Richter et al. found that the Multiply-Shift family of hash functions (defined as ${\displaystyle h_{z}(x)=(x\cdot z{\bmod {2}}^{w})\div 2^{w-d}}$) was "the fastest hash function when integrated with all hashing schemes, i.e., producing the highest throughputs and also of good quality" whereas tabulation hashing produced "the lowest throughput".[2] They point out that each table look-up require several cycles, being more expensive than simple arithmetic operatons. They also found MurmurHash to be superior than tabulation hashing: "By studying the results provided by Mult and Murmur, we think that the trade-off for by tabulation (...) is less attractive in practice".
## History
The idea of an associative array that allows data to be accessed by its value rather than by its address dates back to the mid-1940s in the work of Konrad Zuse and Vannevar Bush,[19] but hash tables were not described until 1953, in an IBM memorandum by Hans Peter Luhn. Luhn used a different collision resolution method, chaining, rather than linear probing.[20]
Knuth (1963) summarizes the early history of linear probing. It was the first open addressing method, and was originally synonymous with open addressing. According to Knuth, it was first used by Gene Amdahl, Elaine M. McGraw (née Boehme), and Arthur Samuel in 1954, in an assembler program for the IBM 701 computer.[8] The first published description of linear probing is by Peterson (1957),[8] who also credits Samuel, Amdahl, and Boehme but adds that "the system is so natural, that it very likely may have been conceived independently by others either before or since that time".[21] Another early publication of this method was by Soviet researcher Andrey Ershov, in 1958.[22]
The first theoretical analysis of linear probing, showing that it takes constant expected time per operation with random hash functions, was given by Knuth.[8] Sedgewick calls Knuth's work "a landmark in the analysis of algorithms".[10] Significant later developments include a more detailed analysis of the probability distribution of the running time,[23][24] and the proof that linear probing runs in constant time per operation with practically usable hash functions rather than with the idealized random functions assumed by earlier analysis.[16][17]
## References
1. ^ a b Thorup, Mikkel; Zhang, Yin (2012), "Tabulation-based 5-independent hashing with applications to linear probing and second moment estimation", SIAM Journal on Computing, 41 (2): 293–331, doi:10.1137/100800774, MR 2914329.
2. ^ a b Richter, Stefan; Alvarez, Victor; Dittrich, Jens (2015), "A seven-dimensional analysis of hashing methods and its implications on query processing", Proceedings of the VLDB Endowment, 9 (3): 293–331.
3. Goodrich, Michael T.; Tamassia, Roberto (2015), "Section 6.3.3: Linear Probing", Algorithm Design and Applications, Wiley, pp. 200–203.
4. Morin, Pat (February 22, 2014), "Section 5.2: LinearHashTable: Linear Probing", Open Data Structures (in pseudocode) (0.1Gβ ed.), pp. 108–116, retrieved 2016-01-15.
5. ^ Sedgewick, Robert; Wayne, Kevin (2011), Algorithms (4th ed.), Addison-Wesley Professional, p. 471, ISBN 9780321573513. Sedgewick and Wayne also halve the table size when a deletion would cause the load factor to become too low, causing them to use a wider range [1/8,1/2] in the possible values of the load factor.
6. ^ a b Pătraşcu, Mihai; Thorup, Mikkel (2010), "On the k-independence required by linear probing and minwise independence" (PDF), Automata, Languages and Programming, 37th International Colloquium, ICALP 2010, Bordeaux, France, July 6–10, 2010, Proceedings, Part I, Lecture Notes in Computer Science, 6198, Springer, pp. 715–726, doi:10.1007/978-3-642-14165-2_60
7. ^ a b Heileman, Gregory L.; Luo, Wenbin (2005), "How caching affects hashing" (PDF), Seventh Workshop on Algorithm Engineering and Experiments (ALENEX 2005), pp. 141–154.
8. ^ a b c d
9. ^ Eppstein, David (October 13, 2011), "Linear probing made easy", 0xDE.
10. ^ a b Sedgewick, Robert (2003), "Section 14.3: Linear Probing", Algorithms in Java, Parts 1–4: Fundamentals, Data Structures, Sorting, Searching (3rd ed.), Addison Wesley, pp. 615–620, ISBN 9780321623973.
11. ^ Pittel, B. (1987), "Linear probing: the probable largest search time grows logarithmically with the number of records", Journal of Algorithms, 8 (2): 236–249, doi:10.1016/0196-6774(87)90040-X, MR 890874.
12. ^ "IdentityHashMap", Java SE 7 Documentation, Oracle, retrieved 2016-01-15.
13. ^ Friesen, Jeff (2012), Beginning Java 7, Expert's voice in Java, Apress, p. 376, ISBN 9781430239109.
14. ^ Kabutz, Heinz M. (September 9, 2014), "Identity Crisis", The Java Specialists' Newsletter, 222.
15. ^ Weiss, Mark Allen (2014), "Chapter 3: Data Structures", in Gonzalez, Teofilo; Diaz-Herrera, Jorge; Tucker, Allen, Computing Handbook, 1 (3rd ed.), CRC Press, p. 3-11, ISBN 9781439898536.
16. ^ a b Pagh, Anna; Pagh, Rasmus; Ružić, Milan (2009), "Linear probing with constant independence", SIAM Journal on Computing, 39 (3): 1107–1120, doi:10.1137/070702278, MR 2538852
17. ^ a b Pătraşcu, Mihai; Thorup, Mikkel (2011), "The power of simple tabulation hashing", Proceedings of the 43rd annual ACM Symposium on Theory of Computing (STOC '11), pp. 1–10, arXiv:1011.5200, doi:10.1145/1993636.1993638
18. ^ Thorup, Mikkel (2009), "String hashing for linear probing", Proceedings of the Twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, Philadelphia, PA: SIAM, pp. 655–664, doi:10.1137/1.9781611973068.72, MR 2809270.
19. ^ Parhami, Behrooz (2006), Introduction to Parallel Processing: Algorithms and Architectures, Series in Computer Science, Springer, 4.1 Development of early models, p. 67, ISBN 9780306469640.
20. ^ Morin, Pat (2004), "Hash tables", in Mehta, Dinesh P.; Sahni, Sartaj, Handbook of Data Structures and Applications, Chapman & Hall / CRC, p. 9-15, ISBN 9781420035179.
21. ^ Peterson, W. W. (April 1957), "Addressing for random-access storage", IBM Journal of Research and Development, Riverton, NJ, USA: IBM Corp., 1 (2): 130–146, doi:10.1147/rd.12.0130.
22. ^ Ershov, A. P. (1958), "On Programming of Arithmetic Operations", Communications of the ACM, 1 (8): 3–6, doi:10.1145/368892.368907. Translated from Doklady AN USSR 118 (3): 427–430, 1958, by Morris D. Friedman. Linear probing is described as algorithm A2.
23. ^ Flajolet, P.; Poblete, P.; Viola, A. (1998), "On the analysis of linear probing hashing", Algorithmica, 22 (4): 490–515, doi:10.1007/PL00009236, MR 1701625.
24. ^ Knuth, D. E. (1998), "Linear probing and graphs", Algorithmica, 22 (4): 561–568, doi:10.1007/PL00009240, MR 1701629.
|
2016-08-24 02:13:02
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 3, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4605640769004822, "perplexity": 1408.1992511917215}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-36/segments/1471982290752.48/warc/CC-MAIN-20160823195810-00055-ip-10-153-172-175.ec2.internal.warc.gz"}
|
https://www.circuitlab.com/circuit/tne4sa/photodiode-receiver-01/
|
Created by Created December 10, 2012 Last modified December 17, 2012 Tags
### Summary
A very simple model of a photodiode receiver using an
opamp as a transimpedance amplifier.
Simulate > DC Sweep > Run DC Sweep
### Description
A very simple model of a photodiode receiver using an opamp as a transimpedance amplifier.
More complex models take account of the non-linearity of the LED optical power o/p vs current characteristics and may have detailed modelling of rise and fall times and propagation delay.
D1 and D2 are separated by some distance.
Note that, although D1 provides a load that represents an LED, in terms of voltage drop, resistance and junction capacitance etc., the LED model has no optical parameters. The only coupling to the receiver is via the behavioural current source Ictr1 monitoring the current through D1.
Ictr1 is the (LED current)*(the attenuation between LED and photodiode)*(photodiode responsivity)
In this example responsivity=0.6 A/W, which is the typical responsivity of a silicon photodiode.
http://en.wikipedia.org/wiki/Photodiode
D2 has no optical effect. It is present purely to model the reverse leakage (dark current) and junction capacitance effects of a photodiode.
Note that the transimpedance:
V(out)/I(in) set by:
V(out) = -I(in)*Rfb
is a bit too high and the opamp output hits the -5V rail before the LED current reaches its maximum.
Cfb is to compensate for the photodiode capacitance.
Simulate > DC Sweep > Run DC Sweep
|
2022-08-15 16:26:47
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.20012742280960083, "perplexity": 5746.564102698954}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-33/segments/1659882572192.79/warc/CC-MAIN-20220815145459-20220815175459-00067.warc.gz"}
|
https://www.lmfdb.org/Variety/Abelian/Fq/?q=3
|
## Results (1-50 of 279175 matches)
Label Dimension Base field L-polynomial $p$-rank Isogeny factors
1.3.ad $1$ $\F_{3}$ $1 - 3 x + 3 x^{2}$ $0$
1.3.ac $1$ $\F_{3}$ $1 - 2 x + 3 x^{2}$ $1$
1.3.ab $1$ $\F_{3}$ $1 - x + 3 x^{2}$ $1$
1.3.a $1$ $\F_{3}$ $1 + 3 x^{2}$ $0$
1.3.b $1$ $\F_{3}$ $1 + x + 3 x^{2}$ $1$
1.3.c $1$ $\F_{3}$ $1 + 2 x + 3 x^{2}$ $1$
1.3.d $1$ $\F_{3}$ $1 + 3 x + 3 x^{2}$ $0$
2.3.ag_p $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )^{2}$ $0$
2.3.af_m $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )( 1 - 2 x + 3 x^{2} )$ $1$
2.3.ae_i $2$ $\F_{3}$ $1 - 4 x + 8 x^{2} - 12 x^{3} + 9 x^{4}$ $2$
2.3.ae_j $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )( 1 - x + 3 x^{2} )$ $1$
2.3.ae_k $2$ $\F_{3}$ $( 1 - 2 x + 3 x^{2} )^{2}$ $2$
2.3.ad_f $2$ $\F_{3}$ $1 - 3 x + 5 x^{2} - 9 x^{3} + 9 x^{4}$ $2$
2.3.ad_g $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )( 1 + 3 x^{2} )$ $0$
2.3.ad_h $2$ $\F_{3}$ $1 - 3 x + 7 x^{2} - 9 x^{3} + 9 x^{4}$ $2$
2.3.ad_i $2$ $\F_{3}$ $( 1 - 2 x + 3 x^{2} )( 1 - x + 3 x^{2} )$ $2$
2.3.ac_b $2$ $\F_{3}$ $1 - 2 x + x^{2} - 6 x^{3} + 9 x^{4}$ $2$
2.3.ac_c $2$ $\F_{3}$ $1 - 2 x + 2 x^{2} - 6 x^{3} + 9 x^{4}$ $2$
2.3.ac_d $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )( 1 + x + 3 x^{2} )$ $1$
2.3.ac_e $2$ $\F_{3}$ $1 - 2 x + 4 x^{2} - 6 x^{3} + 9 x^{4}$ $2$
2.3.ac_f $2$ $\F_{3}$ $1 - 2 x + 5 x^{2} - 6 x^{3} + 9 x^{4}$ $2$
2.3.ac_g $2$ $\F_{3}$ $( 1 - 2 x + 3 x^{2} )( 1 + 3 x^{2} )$ $1$
2.3.ac_h $2$ $\F_{3}$ $( 1 - x + 3 x^{2} )^{2}$ $2$
2.3.ab_ac $2$ $\F_{3}$ $1 - x - 2 x^{2} - 3 x^{3} + 9 x^{4}$ $2$
2.3.ab_ab $2$ $\F_{3}$ $1 - x - x^{2} - 3 x^{3} + 9 x^{4}$ $2$
2.3.ab_a $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )( 1 + 2 x + 3 x^{2} )$ $1$
2.3.ab_b $2$ $\F_{3}$ $1 - x + x^{2} - 3 x^{3} + 9 x^{4}$ $2$
2.3.ab_c $2$ $\F_{3}$ $1 - x + 2 x^{2} - 3 x^{3} + 9 x^{4}$ $2$
2.3.ab_d $2$ $\F_{3}$ $1 - x + 3 x^{2} - 3 x^{3} + 9 x^{4}$ $1$
2.3.ab_e $2$ $\F_{3}$ $( 1 - 2 x + 3 x^{2} )( 1 + x + 3 x^{2} )$ $2$
2.3.ab_f $2$ $\F_{3}$ $1 - x + 5 x^{2} - 3 x^{3} + 9 x^{4}$ $2$
2.3.ab_g $2$ $\F_{3}$ $( 1 - x + 3 x^{2} )( 1 + 3 x^{2} )$ $1$
2.3.a_ag $2$ $\F_{3}$ $( 1 - 3 x^{2} )^{2}$ $0$
2.3.a_af $2$ $\F_{3}$ $1 - 5 x^{2} + 9 x^{4}$ $2$
2.3.a_ae $2$ $\F_{3}$ $1 - 4 x^{2} + 9 x^{4}$ $2$
2.3.a_ad $2$ $\F_{3}$ $( 1 - 3 x + 3 x^{2} )( 1 + 3 x + 3 x^{2} )$ $0$
2.3.a_ac $2$ $\F_{3}$ $1 - 2 x^{2} + 9 x^{4}$ $2$
2.3.a_ab $2$ $\F_{3}$ $1 - x^{2} + 9 x^{4}$ $2$
2.3.a_a $2$ $\F_{3}$ $1 + 9 x^{4}$ $0$
2.3.a_b $2$ $\F_{3}$ $1 + x^{2} + 9 x^{4}$ $2$
2.3.a_c $2$ $\F_{3}$ $( 1 - 2 x + 3 x^{2} )( 1 + 2 x + 3 x^{2} )$ $2$
2.3.a_d $2$ $\F_{3}$ $1 + 3 x^{2} + 9 x^{4}$ $0$
2.3.a_e $2$ $\F_{3}$ $1 + 4 x^{2} + 9 x^{4}$ $2$
2.3.a_f $2$ $\F_{3}$ $( 1 - x + 3 x^{2} )( 1 + x + 3 x^{2} )$ $2$
2.3.a_g $2$ $\F_{3}$ $( 1 + 3 x^{2} )^{2}$ $0$
2.3.b_ac $2$ $\F_{3}$ $1 + x - 2 x^{2} + 3 x^{3} + 9 x^{4}$ $2$
2.3.b_ab $2$ $\F_{3}$ $1 + x - x^{2} + 3 x^{3} + 9 x^{4}$ $2$
2.3.b_a $2$ $\F_{3}$ $( 1 - 2 x + 3 x^{2} )( 1 + 3 x + 3 x^{2} )$ $1$
2.3.b_b $2$ $\F_{3}$ $1 + x + x^{2} + 3 x^{3} + 9 x^{4}$ $2$
2.3.b_c $2$ $\F_{3}$ $1 + x + 2 x^{2} + 3 x^{3} + 9 x^{4}$ $2$
|
2023-03-31 10:23:31
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.984352171421051, "perplexity": 5194.946067914556}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-14/segments/1679296949598.87/warc/CC-MAIN-20230331082653-20230331112653-00135.warc.gz"}
|
https://blog.nathantsoi.com/article/silent-stepper-3d-printer-upgrade/
|
My printer sits in a closet that shares a wall with our bedroom. Normally it's fine, but when things are quiet I can hear the motors making slight buzzing and ringing noises with the normal A4988 Stepper Motor Drivers. In an attempt to make the printer entirely silent, I got four TMC2100 stepper motor drivers. At \$10 each, they're expensive, but wow, they are awesome.
For the GT2560 on my i3 Clone I have been running the TMC2100s in the default Stealth Chop mode for quite a while now and they are AWESOME! The loudest thing on my printer is now the power supply fan (which seems to be dying) and I can no longer hear any noises when printing, even in the middle of the night.
Any boards with the TMC2100 drivers should work, I ordered these from banggood.com, but have seen this less expensive version recommended on the reprap forums: https://www.aliexpress.com/item/4pcs-3D-Printer-Accessories-Silent-MKS-LV8729-stepper-motor-driver-ultra-quiet-for-MKS-ROBIN-MKS/32797730654.html
The one thing to watch out for when using these drivers is that they do run much hotter than the A4988. If you're losing steps. I would ensure there is enough airflow over the heatsinks before switching the mode from stealth chop.
I was getting lots of missed steps (due to the drivers overheating and shutting off temporarily) with the same fan configuration as my A4988 drivers, but adding a fan like so fixed the issue. I probably should have mounted the heat sinks 90 degrees the other way so the air flows better:
## Easy Installation (steathChop)
The default mode is stealth chop, which some people claim does not provide as much torque as spreadCycle, but in theory it should. Things to watch out for when using this is simply heat. Make sure you have lots of air moving over the heat sink.
To install, simply:
• Note the location of the GND pin and orientation of the existing drivers.
• Remove all the old drivers and the jumpers below them.
• Install the new drivers, placing the GND pin on the new driver in the same location as the old driver.
## Modes
Here are the table of modes
CFG1CFG2SchrittteilungInterpolationMode
VCCopen4 (quarter-step)256 µ-stepsstealthChop
openopen16 µ-steps256 µ-stepsstealthChop
According to the reprap documentation page, you want either of these configs:
CFG1CFG2SchrittteilungInterpolationMode
openopen16 µ-steps256 µ-stepsstealthChop
To test, plug in the driver, with jumpers underneath removed and use the continuity feature to see if the CFG1 and CFG2 pins match the ground or VCC connections in the table above.
Documentation page (Google translated) from: http://www.fysetc.com/store/goods-84.html
Product Description: The use of the chip stepping value in accordance with the 16 subdivision calculation, the chip internal use of the differential algorithm will be extended to 16 subdivision 256 subdivision
Product weight: 4g
Delivery list: TMC2100 driver module * 1, dedicated heat sink * 1
Advantages: quiet, super quiet, super super quiet
Product defects:
1: inherit the consistent characteristics of German products, workmanship, the use of imported chips from Germany, super super expensive, high-end series, the sound requirements of mute, perfect customer is a good choice.
2: the working temperature is higher, without fan case, the working temperature of about 0.5A 70 degrees, 1A operating temperature exceeds
150 degrees, there may be lost, strong demand for good heat dissipation, the best working current 0.5A best.
Algorithm and Adjustment of TMC 2100 Module Driving Current
1, the drive current algorithm: i = vref * 1.9 / 2.5, the default Verf about 0.65V,
So the default current of 0.5A, the maximum current of 1A.
2, Verf measure Gnd and potentiometer intermediate end voltage.
3, be sure to not connect the motor voltage measurement, or easy to burn drive.
4. Measuring voltage should be connected to the power, do not just connect the USB power supply.
Please pay special attention to the direction, do not insert anti! ! !
TMC 2100 drive module
1, Ramps1.4 or MKS Gen, or plot plot touch screen motherboard, please remove the three jumper cap below
2, pay attention to the direction
3, heat sink attached directly to the PCB above
4. Motor direction and A4988 and DRV8825 on the contrary, if you want to directly replace the 4988, adjust
Firmware or adjust the motor line sequence, such as the use of music plot motherboard, please set the motor direction directly above the touch screen.
Set the direction inside.
Reprap documentation page: http://reprap.org/wiki/TMC2100
|
2023-02-09 12:01:58
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.1758488565683365, "perplexity": 4721.162652622599}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764499966.43/warc/CC-MAIN-20230209112510-20230209142510-00122.warc.gz"}
|
https://tex.stackexchange.com/questions/498760/how-scale-a-mathrel-to-match-current-contexts-font-size/498777
|
# How scale a mathrel to match current context's font size?
Revised question:
I'm using TikZ to re-design \rightarrow for the Lucida Bright fonts, to better match tikzcd arrows. How do I scale that mathrel for script- and scriptscript-styles (as well as have the scaling sensitive to enclosing \large, \tiny, etc., commands).
With the lucidascale or lucidasmallscale option of lucidabr.sty (or lucimatx.sty), scaling is non-linear.
Originally I thought I should base the scaling factor upon the document class's font size option (or its default). And Phelype Oleinik;s answer showed how to obtain the document class's font size.
However, as David Carlisle pointed out, that approach is neither necessary or sufficient for achieving my actual aim.
Original question: For a document class being used, is there a way to determine through TeX or LaTeX code what the declared font size option is, or in the absence of a user-declared option, what the default font size is?
I want this font size just as an integer (12, 11, 10, e.g.) and not as an actual dimension such as 12.0 pt.
In particular, is it possible to do this with the article and memoir document classes?
• @PhelypeOleinik: That's almost what I need. I think I'll want the font size parameter as a simple integer, not a decimal length. Unclear to me yet how to do that. (I'll be doing some \ifthenelse tests on the font size parameter, and I think comparing with an integer would be simpler.) – murray Jul 5 '19 at 15:25
• why does knowing the document option help? you may be in the scope of \footnotesize or \large or whatever so knowing what is the document default settings seems of little use. Just use the font dimens of the \textfont0, \scriptfont0 and \scriptscriptfont0 in the current math expression. – David Carlisle Jul 5 '19 at 15:51
• @DavidCarlisle: Yes, I'm aware of that issue of scope. But "Just use the font dimens..." is beyond my depth of understanding. Even after some online searching, I'm at a complete loss as to what \textfont0, etc., mean or how to use them. Since my purpose is to scale a symbol constructed in TikZ, I need to determine a scaling factor for script, etc. – murray Jul 5 '19 at 16:00
• the title of the question is a duplicate of the stated one but the actual question (or at least the stated use case) is a completely unrelated problem so if you wanted to edit the question a bit it could probably be re-opened – David Carlisle Jul 5 '19 at 20:08
For the stated use case knowing the documentclass options does not seem that useful as you need to know the math font sizes in the current size, something more like this which gives the x-height in the three math font sizes current at that point.
\documentclass{article}
\def\zz{\mbox{ex-height is
text: \the\fontdimen5\textfont2\
script: \the\fontdimen5\scriptfont2\
scriptscript: \the\fontdimen5\scriptscriptfont2
}}
\begin{document}
$\zz$
{\large $\zz$}
{\tiny $\zz$}
\end{document}
Or the same scaling an arrow:
\documentclass{article}
\usepackage[T1]{fontenc}
\usepackage{graphicx}
\newbox\zzarrowbox
\sbox\zzarrowbox{\mbox{-->>}}% draw with tikz if you prefer...
\newcommand\zzarrow{\mathrel{%
\mathchoice
{\resizebox{!}{\the\fontdimen5\textfont2}{\usebox\zzarrowbox}}%
{\resizebox{!}{\the\fontdimen5\textfont2}{\usebox\zzarrowbox}}%
{\resizebox{!}{\the\fontdimen5\scriptfont2}{\usebox\zzarrowbox}}%
{\resizebox{!}{\the\fontdimen5\scriptscriptfont2}{\usebox\zzarrowbox}}%
}}
\begin{document}
$a\zzarrow b X_{a\zzarrow b}$
{\large $a\zzarrow b X_{a\zzarrow b}$}
{\tiny $a\zzarrow b X_{a\zzarrow b}$}
\end{document}
• How to detect whether a given string of math is in a \large, \normalsize, \tiny, etc? I'm trying to write a command to scale a \mathrel object. I'm starting with this, from lucidabr.sty, based on font size, not x-height: \def\DeclareLucidaFontShape#1#2#3#4#5#6{% \DeclareFontShape{#1}{#2}{#3}{#4}{% <-5.5>s*[.98]#5% <5.5-6.5>s*[.96]#5% <6.5-7.5>s*[.94]#5% <7.5-8.5>s*[.92]#5% <8.5-9.5>s*[.91]#5% <9.5-10.5>s*[.9]#5% <10.5-11.5>s*[.89]#5% <11.5-13>s*[.88]#5% <13-15.5>s*[.87]#5% <15.5-18.5>s*[.86]#5% <18.5-22.5>s*[.85]#5% <22.5->s*[.84]#5% }{#6}}} – murray Jul 5 '19 at 19:23
• @murray that's the whole point of the answer, you do not need to look at those definitions at all, just make the arrow match the current font size, what else do you need? – David Carlisle Jul 5 '19 at 19:47
• @murray I modified the example to show a scaled arrow rather than text. – David Carlisle Jul 5 '19 at 19:57
• How disentangle my original question, for which Phelype Oleinik provides an emended answer to the poit, from your answer -- which solves my problem but not in the way I thought I had to do it? – murray Jul 5 '19 at 20:17
• @murray well if your problem is solved you could just let it be. it's not like I'm in desperate need of lots of people to come by and vote up my rep:-) – David Carlisle Jul 5 '19 at 20:20
This is the same principle as my other answer, except that here I use expl3's \token_if_dim_register:NTF, \token_if_int_register:NTF, and \token_if_macro:NTF to set the argument of \classfontsize accordingly. If the argument is a dimen register, the value set is the font size (the option used in \documentclass, not the actual font size) as a TeX dimension. If the argument is a count register, then the value is store as an integer, and if it is another control sequence, then the value is also stored as the integer representation of the option.
Note that the font size used in the \documentclass is purely symbolic! The actual size of the font not necessarily (and hardly) matches the class option. For example, the 11pt option loads a 10.95pt font.
Use as \classfontsize<count register> or \classfontsize<dimen register> or \classfontsize<control sequence>:
\documentclass[14pt]{memoir}
\usepackage{xparse}
\ExplSyntaxOn
\NewDocumentCommand \classfontsize { m }
{ \murray_def_class_font_size:N #1 }
\cs_new_protected:Npn \murray_def_class_font_size:N #1
{
\token_if_dim_register:NTF #1
{ \__murray_class_size:NNn \dim_set:Nn #1 { pt } }
{
\token_if_int_register:NTF #1
{ \__murray_class_size:NNn \int_set:Nn #1 { } }
{
\token_if_macro:NTF #1
{ \__murray_class_size:NNn \cs_set:Npx #1 { } }
{
\cs_if_exist:NTF #1
{ \msg_error:nnn { murray } { invalid-token } {#1} }
{ \__murray_class_size:NNn \cs_set:Npx #1 { } }
}
}
}
}
\msg_new:nnn { murray } { invalid-token }
{ Token~#1 invalid~for~assignment~\msg_line_context:.}
\cs_new_protected:Npn \__murray_class_size:NNn #1 #2 #3
{ #1 #2 { \__murray_get_class_size_int: #3 } }
\cs_new:Npn \__murray_get_class_size_int:
{
\cs_if_exist:cTF { ver@beamer.cls } \__murray_get_beamer_size:
{
\cs_if_exist:cTF { ver@memoir.cls } \__murray_get_memoir_size:
{
\cs_if_exist:cTF { ver@extarticle.cls } \__murray_get_extarticle_size:
{ \__murray_get_standard_size: }
}
}
}
\makeatletter
\cs_new:Npn \__murray_get_beamer_size:
{ \exp_args:NNNo \exp_args:No \__murray_get_beamer_size_aux:w \use:n \beamer@size }
\cs_new:Npn \__murray_get_beamer_size_aux:w size#1.clo {#1}
\cs_new:Npn \__murray_get_memoir_size: { \@memptsize }
\cs_new:Npn \__murray_get_extarticle_size: { \@ptsize }
\cs_new:Npn \__murray_get_standard_size: { 1 \@ptsize }
\makeatother
\ExplSyntaxOff
\begin{document}
\newdimen\dimfontsize
\classfontsize\dimfontsize
Length: \the\dimfontsize
\newcount\intfontsize
\classfontsize\intfontsize
Integer: \the\intfontsize
\classfontsize\csfontsize
Macro: \csfontsize
\end{document}
and, as requested, a macro-only version without expl3:
\documentclass[14pt]{extarticle}
\makeatletter
\newcommand{\deffontsize}[1]{%
\edef#1%
{%
\get@beamersize
{%
\get@memoirsize
{%
\get@extartsize
\get@standardsize
}%
}%
}%
}
\expandafter\ifx\csname ver@#1.cls\endcsname\relax
\expandafter\@secondoftwo
\else
\expandafter\@firstoftwo
\fi}
\def\get@beamersize{%
\expandafter\expandafter\expandafter\get@@beamersize
\expandafter\@firstofone\beamer@size}
\def\get@@beamersize size#1.clo{#1}
\def\get@memoirsize{\@memptsize}
\def\get@extartsize{\@ptsize}
\def\get@standardsize{1\@ptsize}
\makeatother
\begin{document}
\deffontsize\mainfontsize
\mainfontsize
\end{document}
• How might I get the "macro" version of the class font size without having to use expl3 syntax (which is totally opaque to me)? That is, how do it based upon your answer tex.stackexchange.com/a/487949/13492? – murray Jul 5 '19 at 16:13
• @murray I added a macro version of that answer. Of course you don't need to understand expl3 to use the code; it works as is. \begin{advertisement} However I must say that once you get used to it, you can do things much easier with expl3 than plain (La)TeX programming. It offers a lot of predefined tests (such as the ones I showed), some new data types, and a precise expansion control, greatly reducing the usage of the infamous \expandaftery. \end{advertisement} – Phelype Oleinik Jul 5 '19 at 16:18
• I do strongly prefer to understand code that I use! Eventually I'll get around to learning expl3, but that would be a diversion right now. Thanks for the expl3-free macro version. – murray Jul 5 '19 at 18:59
• @murray You're welcome. Of course I agree that understanding the code is the best way to make proper use of it. expl3 is really not that hard if you have some TeX background and a little time to get your hands dirty in it. The syntax is a bit scary at first, but you get used to it :-) – Phelype Oleinik Jul 5 '19 at 19:07
• My limitation here will doubtless be in limited understanding of TeX syntax & semantics. – murray Jul 5 '19 at 19:40
|
2020-01-29 19:44:44
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9261915683746338, "perplexity": 3377.2373285865615}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-05/segments/1579251802249.87/warc/CC-MAIN-20200129194333-20200129223333-00398.warc.gz"}
|
https://www.physicsforums.com/threads/sum-of-series.786172/
|
# Sum of Series
1. Dec 7, 2014
### andyrk
Can someone explain how to compute the sum of the following series?
1/(n2 + (r-1)2) + 1/(n2 + (r)2) + 1/(n2 + (r+1)2) + ....1/(n2 + (n-1)2)
2. Dec 7, 2014
### andyrk
Is anyone there?
3. Dec 7, 2014
### Stephen Tashi
Explain the context. Do you seek a closed form expression that is simpler to write than the sum itself? Do you need an approximation?
I suggest we first try to find the summation::
$S_m = \sum_{k=1}^m {\frac{1}{1 + k^2}}$.
since the result might be used to derive the summation of the series you gave.
4. Dec 7, 2014
### andyrk
I don't have an idea as to how to go about finding even the summation you gave. Can you give me a clue?
5. Dec 7, 2014
### Stephen Tashi
I can only give suggestions. ( I could give a "clue" if I knew how to sum it already.)
Apply the section "Rational Functions" in the article: http://en.wikipedia.org/wiki/List_of_mathematical_series
$\sum_{k=1}^\infty \frac{1}{1+k^2} = -\frac{1}{2} + \frac{\pi}{2} coth(\pi)$
So perhaps a substitution involving the hyperbolic cotangent would be useful in doing the finite sum. I'll keep thinking about it.
6. Dec 7, 2014
### andyrk
Woah. I think this is beyond what my curriculum asks for. I am pretty sure that it doesn't involve trigonometric solutions as simplification of any series. I think this has something else to do with. Definitely not this way.
7. Dec 7, 2014
### Stephen Tashi
What has your curriculum covered? Is this in a chapter on mathematical induction?
8. Dec 7, 2014
### andyrk
Mathematical Induction in my curriculum doesn't include sum of series etc. It just involves proving LHS = RHS or proving the given statement by using induction. This topic is done in sequences and series. But it just involves basic sums like - ∑n, ∑n2, ∑n3. And I don't know how to incorporate these 3 into the summation above to simplify it.
9. Dec 7, 2014
### Stephen Tashi
Did you quote the problem exactly? - or does the statement of the problem use summation notation?
10. Dec 8, 2014
### andyrk
Its a part of the problem that I told you. The exact problem is-
Consider a function f(x) = 1/(1+x2)
Let αn = 1/n *($\sum_{r=1}^n {f(\frac{r}{n}}))$
and βn = 1/n *($\sum_{r=0}^{n-1} {f(\frac{r}{n}}))$ ; n ∈ N
α = limn →∞n ) & β = limn →∞n )
then αn/β - βn/α will always be? (Answer: A real number)
Last edited: Dec 8, 2014
11. Dec 8, 2014
### Stephen Tashi
Is the sum supposed to be $\sum_{r=0}^{n-1} f(\frac{r}{n})$ ? It begins at $r = 0$ ?
12. Dec 8, 2014
### andyrk
Yes. I didn't know how to write it up. Anyways, I have edited it now. :)
13. Dec 8, 2014
### Stephen Tashi
My guess is that you don't have to find a summation formula in order to work the problem. I'd start wtih an equation relating $\alpha_n$ to $\beta_n$
$\alpha_n + \frac{1}{n} f(\frac{0}{n}) - \frac{1}{n}f(\frac{n}{n}) = \beta_n$
14. Dec 8, 2014
### andyrk
15. Dec 8, 2014
### Stephen Tashi
Compare the terms in the sum for $\alpha_n$ with those in the sum for $\beta_n$. The sum for $\alpha_n$ is missing the $r= 0$ term that $\beta_n$ has. The sum for $\alpha_n$ has a term for $r = n$ that $\beta_n$ does not.
16. Dec 8, 2014
### andyrk
Oh yeah. I got that now. But the solution that I have says-
$\alpha_n - \beta_n = \frac{1}{n}( f(0) - f(n))$
And comparing to the clue you gave me I get-
$\alpha_n - \beta_n = \frac{1}{n}( f(1) - f(0)$
This leaves me confused as to what went wrong.
Here's the solution that I have. It confuses me everytime I go through it.
#### Attached Files:
• ###### Solution.jpg
File size:
50.1 KB
Views:
102
Last edited: Dec 8, 2014
17. Dec 8, 2014
### zoki85
No:D
18. Dec 8, 2014
### Stephen Tashi
There are two different problems. The problem you stated is related to Riemann sums for $\int_0^1 f(x) dx$. The problem in the solution is related to Riemann sums for $\int_0^n f(x) dx$.
In the problem you stated, the definition of $\alpha_n$ is a Riemann sum using the altitude at the right hand point of the base of each rectangle. In the solution, $\alpha_n$ is defined to use the altitutde at the left hand point of the base of each rectangle.
19. Dec 8, 2014
### andyrk
Woah. This is not even a part of my course. I think you went a bit too far with that. Could you please explain what you said more clearly? How does the limit n→∞ change the limits from 0 to n to 0 to 1 in the integral?
20. Dec 8, 2014
### Stephen Tashi
Have you studied definite integrals? Riemann sums?
21. Dec 8, 2014
### andyrk
I have studied definite integrals. Is Riemann sums just another name of it?
22. Dec 8, 2014
### Stephen Tashi
Definite integrals are usually defined as the limit of an approximation process that divides he area under the graph of a function into rectangles and sums their areas. Such sums are the Riemann sums.
23. Dec 8, 2014
### andyrk
Yup. I know that alright. But still I am not able to understand how the limits change from (0 to n) to (0 to 1)?
24. Dec 8, 2014
### Stephen Tashi
How they change between the two problems is just arbitrary notation. Why they change between $\alpha_n$ and $\beta_n$ is because the symbols $\alpha_n, \beta_n$ are used to denote two different Riemann sums.
One sum computes the area of a rectangle with a given base by using the value of the function at the left endpoint of the base. The other sum computes the area of a rectangle with a given base by using the value of the function at the right endpoint. In the particular problem we have an integral from x = 0 to x = 1. The sum that begins with the term $\frac{1}{n} f(\frac{0}{n})$ is using the left endpoint of the base as the height of the rectangle. That sum ends with the term $\frac{1}{n} f(\frac{n-1}{n})$ because the last rectangle in the interval $[0,1]$ has base $[\frac{n-1}{n}, \frac{n}{n} ]$. So when we we define limits for the summation using an index $k$ , the index goes from $k = 0$ to $k = n-1$.
The other Riemann sum computes the are of a given base by using the value of the function at the right end of the base. You should be able to see why an index $k$ for that sum would go from $k = 1$ to $k = n$.
25. Dec 8, 2014
### Stephen Tashi
If you mean the limits of integration, they don't change for x. I was incorrect to say that. The solution page you has introduces a third variable "$r$" that is also marked on the x-axis and their picture seems to indicated that $r$ goes from zero to infinity.
|
2018-07-23 05:05:21
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8799881339073181, "perplexity": 796.1935482412316}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-30/segments/1531676594886.67/warc/CC-MAIN-20180723032237-20180723052237-00453.warc.gz"}
|
https://www.physicsforums.com/threads/conservation-of-momentum.631754/
|
# Conservation of momentum
Sir , Can you please explain me " The conservation of mometum " with an example ?
I am not able to understand the concept of CONSERVATION OF MOMETUM .
So plz help me Sir .
I will be very thankful .
Thankyou very much Sir .
It was very useful
|
2021-01-25 01:34:45
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8904280662536621, "perplexity": 894.9319469841105}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-04/segments/1610703561996.72/warc/CC-MAIN-20210124235054-20210125025054-00717.warc.gz"}
|
https://planetmath.org/derivationofrecurrenceforsylvesterssequence
|
# derivation of recurrence for Sylvester’s sequence
Let us begin with the product:
$a_{n}=1+\prod_{i=0}^{n-1}a_{i}$
Adding $1$ to $n$ and manipulating the result:
$\displaystyle a_{n+1}$ $\displaystyle=$ $\displaystyle 1+\prod_{i=0}^{n}a_{i}$ $\displaystyle=$ $\displaystyle 1+a_{n}\prod_{i=0}^{n-1}a_{i}$ $\displaystyle=$ $\displaystyle 1+a_{n}(a_{n}-1)=1+(a_{n})^{2}-a_{n}$
Title derivation of recurrence for Sylvester’s sequence DerivationOfRecurrenceForSylvestersSequence 2013-03-22 15:48:27 2013-03-22 15:48:27 rspuzio (6075) rspuzio (6075) 4 rspuzio (6075) Derivation msc 11A55
|
2021-04-18 04:53:03
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 10, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.822036623954773, "perplexity": 7635.077569355953}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-17/segments/1618038468066.58/warc/CC-MAIN-20210418043500-20210418073500-00627.warc.gz"}
|
http://clay6.com/qa/40575/hydrogen-peroxide-acts-both-as-an-oxidising-and-as-reducing-agent-depending
|
Browse Questions
# Hydrogen peroxide acts both as an oxidising and as reducing agent depending upon the nature of the reacting species . In which of the following cases $\;H_{2}O_{2}\;$ acts as a reducing agent in acid medium ?
$(a)\;MnO_{4}^{-}\qquad(b)\;Cr_{2}O_{7}^{2-}\qquad(c)\;SO_{3}^{2-}\qquad(d)\;KI$
|
2017-02-22 15:13:15
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9836049675941467, "perplexity": 2062.5645514050216}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-09/segments/1487501170993.54/warc/CC-MAIN-20170219104610-00096-ip-10-171-10-108.ec2.internal.warc.gz"}
|
https://www.aimsciences.org/article/doi/10.3934/mbe.2006.3.237
|
American Institute of Mathematical Sciences
2006, 3(1): 237-248. doi: 10.3934/mbe.2006.3.237
An improved model of t cell development in the thymus and its stability analysis
1 Department of Mathematics and Mechanics, Applied Science College, University of Science and Technology Beijing, Beijing 100083, China 2 Department of Applied Mathematics, School of Mathematics and Physics, University of Science and Technology Beijing, Beijing 100083
Received February 2005 Revised May 2005 Published November 2005
Based on some important experimental dates, in this paper we shall introduce time delays into Mehrs's non-linear differential system model which is used to describe proliferation, differentiation and death of T cells in the thymus (see, for example, [3], [6], [7] and [9]) and give a revised nonlinear differential system model with time delays. By using some classical analysis techniques of functional differential equations, we also consider local and global asymptotic stability of the equilibrium and the permanence of the model.
Citation: Hongjing Shi, Wanbiao Ma. An improved model of t cell development in the thymus and its stability analysis. Mathematical Biosciences & Engineering, 2006, 3 (1) : 237-248. doi: 10.3934/mbe.2006.3.237
[1] Alan D. Rendall. Multiple steady states in a mathematical model for interactions between T cells and macrophages. Discrete & Continuous Dynamical Systems - B, 2013, 18 (3) : 769-782. doi: 10.3934/dcdsb.2013.18.769 [2] Lena Noethen, Sebastian Walcher. Tikhonov's theorem and quasi-steady state. Discrete & Continuous Dynamical Systems - B, 2011, 16 (3) : 945-961. doi: 10.3934/dcdsb.2011.16.945 [3] Wenbo Cheng, Wanbiao Ma, Songbai Guo. A class of virus dynamic model with inhibitory effect on the growth of uninfected T cells caused by infected T cells and its stability analysis. Communications on Pure & Applied Analysis, 2016, 15 (3) : 795-806. doi: 10.3934/cpaa.2016.15.795 [4] Stéphane Mischler, Clément Mouhot. Stability, convergence to the steady state and elastic limit for the Boltzmann equation for diffusively excited granular media. Discrete & Continuous Dynamical Systems - A, 2009, 24 (1) : 159-185. doi: 10.3934/dcds.2009.24.159 [5] Robert Artebrant, Aslak Tveito, Glenn T. Lines. A method for analyzing the stability of the resting state for a model of pacemaker cells surrounded by stable cells. Mathematical Biosciences & Engineering, 2010, 7 (3) : 505-526. doi: 10.3934/mbe.2010.7.505 [6] Serge Nicaise, Cristina Pignotti, Julie Valein. Exponential stability of the wave equation with boundary time-varying delay. Discrete & Continuous Dynamical Systems - S, 2011, 4 (3) : 693-722. doi: 10.3934/dcdss.2011.4.693 [7] Josef Diblík. Long-time behavior of positive solutions of a differential equation with state-dependent delay. Discrete & Continuous Dynamical Systems - S, 2020, 13 (1) : 31-46. doi: 10.3934/dcdss.2020002 [8] István Györi, Ferenc Hartung. Exponential stability of a state-dependent delay system. Discrete & Continuous Dynamical Systems - A, 2007, 18 (4) : 773-791. doi: 10.3934/dcds.2007.18.773 [9] La-Su Mai, Kaijun Zhang. Asymptotic stability of steady state solutions for the relativistic Euler-Poisson equations. Discrete & Continuous Dynamical Systems - A, 2016, 36 (2) : 981-1004. doi: 10.3934/dcds.2016.36.981 [10] Mei-hua Wei, Jianhua Wu, Yinnian He. Steady-state solutions and stability for a cubic autocatalysis model. Communications on Pure & Applied Analysis, 2015, 14 (3) : 1147-1167. doi: 10.3934/cpaa.2015.14.1147 [11] Wei-Ming Ni, Yaping Wu, Qian Xu. The existence and stability of nontrivial steady states for S-K-T competition model with cross diffusion. Discrete & Continuous Dynamical Systems - A, 2014, 34 (12) : 5271-5298. doi: 10.3934/dcds.2014.34.5271 [12] Claude-Michel Brauner, Josephus Hulshof, Luca Lorenzi, Gregory I. Sivashinsky. A fully nonlinear equation for the flame front in a quasi-steady combustion model. Discrete & Continuous Dynamical Systems - A, 2010, 27 (4) : 1415-1446. doi: 10.3934/dcds.2010.27.1415 [13] Pietro Baldi. Quasi-periodic solutions of the equation $v_{t t} - v_{x x} +v^3 = f(v)$. Discrete & Continuous Dynamical Systems - A, 2006, 15 (3) : 883-903. doi: 10.3934/dcds.2006.15.883 [14] Yuxiang Li. Stabilization towards the steady state for a viscous Hamilton-Jacobi equation. Communications on Pure & Applied Analysis, 2009, 8 (6) : 1917-1924. doi: 10.3934/cpaa.2009.8.1917 [15] Piotr Zgliczyński. Steady state bifurcations for the Kuramoto-Sivashinsky equation: A computer assisted proof. Journal of Computational Dynamics, 2015, 2 (1) : 95-142. doi: 10.3934/jcd.2015.2.95 [16] Daniel Ginsberg, Gideon Simpson. Analytical and numerical results on the positivity of steady state solutions of a thin film equation. Discrete & Continuous Dynamical Systems - B, 2013, 18 (5) : 1305-1321. doi: 10.3934/dcdsb.2013.18.1305 [17] Samir K. Bhowmik, Dugald B. Duncan, Michael Grinfeld, Gabriel J. Lord. Finite to infinite steady state solutions, bifurcations of an integro-differential equation. Discrete & Continuous Dynamical Systems - B, 2011, 16 (1) : 57-71. doi: 10.3934/dcdsb.2011.16.57 [18] Samira Boussaïd, Danielle Hilhorst, Thanh Nam Nguyen. Convergence to steady state for the solutions of a nonlocal reaction-diffusion equation. Evolution Equations & Control Theory, 2015, 4 (1) : 39-59. doi: 10.3934/eect.2015.4.39 [19] Yaru Xie, Genqi Xu. Exponential stability of 1-d wave equation with the boundary time delay based on the interior control. Discrete & Continuous Dynamical Systems - S, 2017, 10 (3) : 557-579. doi: 10.3934/dcdss.2017028 [20] Eugen Stumpf. Local stability analysis of differential equations with state-dependent delay. Discrete & Continuous Dynamical Systems - A, 2016, 36 (6) : 3445-3461. doi: 10.3934/dcds.2016.36.3445
2018 Impact Factor: 1.313
|
2020-07-09 18:51:08
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4179484248161316, "perplexity": 3550.4225243708183}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-29/segments/1593655900614.47/warc/CC-MAIN-20200709162634-20200709192634-00118.warc.gz"}
|
https://www.imperial.ac.uk/people/u.egede/?limit=30&id=00308935&person=true&respub-action=search.html&page=5
|
# Professor Ulrik Egede
Faculty of Natural SciencesDepartment of Physics
Visiting Professor
//
//
### Assistant
Ms Paula Brown +44 (0)20 7594 7823
//
### Location
Blackett LaboratorySouth Kensington Campus
//
## Summary
My research is in the area of High Energy Physics and deals with the most fundamental aspects of how our Universe works.
Our current knowledge of Particle Physics is described through what is called the Standard Model. We know this is only an effective theory as it predicts unphysical observables at energies close to the Planck Scale. Current studies are focused on looking for small deviations from Standard Model predictions that can give us an insight into the underying theory. We call these effects "New Physics" or "Physics beyond the Standard Model".
The experiment I am working on is called the LHCb experiment and is located at CERN, the European Centre for Particle Physics (Geneva, Switzerland). At this experiment I am leading the effort in using a class of decays called penguin decays to find indications of New Physics. Protons collide at an energy of 13 TeV to produce large quantities of B-mesons which we subsequently can analyse the decays of.
I am also involved in the development of Grid computing for the future. One of the greatest challenges for individual researchers is to overcome the technological barrier of how to access large scale computing. The tool, Gnaga that I am a project manager for was developed within the LHCb experiment and has now been adapted by STFC as the default tool for new user communities that join Grid computing.
## Publications
### Journals
Aaij R, Beteta CA, Ackernley T, et al., 2021, Branching Fraction Measurements of the Rare B-s(0) -> phi mu(+)mu(-) and B-s(0)-> f(2)' (1525)mu(+)mu(-) Decays, Physical Review Letters, Vol:127, ISSN:0031-9007
Aaij R, Beteta CA, Ackernley T, et al., 2021, Search for the doubly charmed baryon Omega(+)(cc), Science China-physics Mechanics & Astronomy, Vol:64, ISSN:1674-7348
Aaij R, Abdelmotteleb ASW, Abellán Beteta C, et al., 2021, Observation of a $${\varLambda}_b^0$$ − $${\overline{\varLambda}}_b^0$$ production asymmetry in proton-proton collisions at $$\sqrt{s}$$ = 7 and 8 TeV, Journal of High Energy Physics, Vol:2021
Aaij R, Abellán Beteta C, Ackernley T, et al., 2021, Search for CP violation in Ξb−→pK−K− decays, Physical Review D, Vol:104, ISSN:2470-0010
Aaij R, Beteta CA, Ackernley T, et al., 2021, Search for CP violation in Xi(-)(b) -> pK(-)K(-) decays, Physical Review D, Vol:104, ISSN:2470-0010
More Publications
|
2021-10-26 03:42:23
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.725968599319458, "perplexity": 3577.365278542717}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-43/segments/1634323587794.19/warc/CC-MAIN-20211026011138-20211026041138-00106.warc.gz"}
|
http://mathhelpforum.com/differential-geometry/95152-question-about-sequences.html
|
it's a fact that every convergent sequence is bounded. recall that, by definition, a sequence {An}has the limit L if for every W>0 there is a corresponding integer N such that
absolute value of (An-L)<W whereever n>N
Use this definition to prove that every sequence that converges to 0 is bounded, i.e to prove that if lim(n is infinity) An =0 then there is a positive number M such that absolute value of (An)<= M for all n belong to natural numbers.
2. Originally Posted by shannon1111
it's a fact that every convergent sequence is bounded. recall that, by definition, a sequence {An}has the limit L if for every W>0 there is a corresponding integer N such that
absolute value of (An-L)<W whereever n>N
Use this definition to prove that every sequence that converges to 0 is bounded, i.e to prove that if lim(n is infinity) An =0 then there is a positive number M such that absolute value of (An)<= M for all n belong to natural numbers.
Why are you asked to prove something that you already know is true?
3. Why not prove the fact first, and then by an obvious corollary, your statement will be true?
Proposition 3.1.4: Convergent Sequences are Bounded
4. Originally Posted by Plato
Why are you asked to prove something that you already know is true?
I don't know , my prof ask to do that , that is the assignment for this week
5. Let $\{x_n\}$ be a sequence which converges to 0. Given any epsilon ball about 0, say $B(0,\epsilon)$ you know that there exists $N\in \mathbb{Z}$ such that $x_n\in B(0,\epsilon)$ for all $n > N$. So simply take
$M=max\{x_1,x_2,...,x_N, \epsilon \}$ and you can be sure that $x_n < M$ for all n, i.e. it is bounded.
6. Shannon: While well intentioned, Gamma did you no favor by posting a solution to your problem (no offense intended Gamma but I hope you will think about this too; more hints, less solution will teach more). This most fundamental question and the technique for proving it touches on about every area of mathematics. We've taken away your chance to discover the solution with the hints that you've been given as you've progressed to this point over the years.
All is not lost. You should write your own proof for a simple case on the real line in about a month without looking at Gamma's proof to make sure you know it and aren't just repeating Gamma's work. I realize that the idea isn't obvious to you now but believe me, it will pay off in your future.
|
2016-12-07 16:48:59
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 7, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9361076951026917, "perplexity": 413.5510710315184}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-50/segments/1480698542217.43/warc/CC-MAIN-20161202170902-00211-ip-10-31-129-80.ec2.internal.warc.gz"}
|
https://www.muchlearning.org/?page=62&ccourseid=1437§ionid=2804
|
# Step By Step Calculus » 14.2 - Sketching Polar Curves
Synopsis
For drawing a curve from a polar equation, one can either
• evaluate values of rr for several values of \theta\theta, then plot the (r,\theta)(r,\theta) pairs and connect them by a smooth line to form the polar curve,
• or, draw the curve in the Cartesian co-ordinates of rr and \theta\theta, and then retrace them in polar co-ordinates.
In either case, the following symmetry test can be helpful.
• Symmetry about the polar axis exists if a polar equation is even in \theta\theta.
• Symmetry about the vertical line \theta=\pi/2\theta=\pi/2 exists if a polar equation remains the same on the change of \theta\theta by \pi-\theta\pi-\theta.
• Symmetry about the pole exists (i.e., rotating the curve by \pi\pi radian doesn’t change the curve), if a polar equation remains the same on the change of rr by -r-r (i.e. even in rr), or \theta\theta by \pi+\theta\pi+\theta.
Note that passing a symmetry test is a sufficient but not necessary condition for a polar equation to exhibit that type of symmetry.
|
2019-01-22 21:45:31
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9690525531768799, "perplexity": 1198.1434100682773}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-04/segments/1547583874494.65/warc/CC-MAIN-20190122202547-20190122224547-00590.warc.gz"}
|
https://physicshelpforum.com/threads/water-flows-into-a-pool-how-long-will-it-take-to-fill.14404/
|
Water flows into a pool how long will it take to fill?
cooter
Water flows through a 2.3-cm-diameter hose at 4 m/s. How long, in minutes, will it take to fill a 750 L kiddie pool?
oz93666
First find the volume of a 4 meter length of the pipe
We are using cm ... (4m =400 cm) so the answer will be in cc ... it will be more than 1200cc .... and this is how much water enters the pool every second.
remember 1000cc is a liter , (L)
HallsofIvy
Surely you mean "pi" ($\pi$), not "phi" ($\phi$).
oz93666
Surely you mean "pi" ($\pi$), not "phi" ($\phi$).
Sure ... that's what I said ..phi pronounced pie ...apple pie
Fie is pronounced Fie
|
2020-01-28 16:07:36
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8257858753204346, "perplexity": 3611.8837103645405}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-05/segments/1579251779833.86/warc/CC-MAIN-20200128153713-20200128183713-00093.warc.gz"}
|
http://community.wolfram.com/groups/-/m/t/1142466?sortMsg=Flat
|
# [✓] Connect data from solving equation in some loop?
GROUPS:
My program about solving equation , then when it finished , by looping , by another order when you ask which answer of solving equation , it plot it . i think i describe it awfully !!!!
2 months ago
7 Replies
The error in your error is in red.
2 months ago
Bill Simpson 2 Votes Perhaps ClearAll["Global*"]; M = 100; sols = Ω /. Table[FindRoot[Tanh[Sqrt[Ω]] - Tan[Sqrt[Ω]], {Ω, IG}], {IG, 10, 200, 50}]; f[x_, n_] := Sum[sols[[n]]^(2 i)/(4 i+2)! x^(4 i+2), {i,0,M}] - Sum[sols[[n]]^(2 i)/(4 i+2)!, {i,0,M}]/ Sum[sols[[n]]^(2 i)/(4 i+3)!, {i,0,M}] Sum[sols[[n]]^(2 i)/(4 i+3)! x^(4 i+3), {i,0,M}]; n = Input["which mode do you want?"]; Plot[f[x, n], {x, 0, 1}]
2 months ago
Thank you so much , yes your program is working , Thanks I want to know if i want to put this program in loop or for , how can i do it? for example i want to say , ask user which beam do you want? if he say clamped free , the program choose clamped free that we define for it and do like the program above , then plot n mode for it ...Thank you so much
2 months ago
Neil Singer 2 Votes Saleh,I would do it all in a Dynamic Module. Using loops and inputs is not very Mathematica-like.Here is an example: DynamicModule[{M = 100, sols, n, beam = 1}, sols = \[CapitalOmega] /. Table[FindRoot[ Tanh[Sqrt[\[CapitalOmega]]] - Tan[Sqrt[\[CapitalOmega]]], {\[CapitalOmega], IG}], {IG, 10, 200, 50}]; f[x_, n_] := Sum[sols[[n]]^(2 i)/(4 i + 2)! x^(4 i + 2), {i, 0, M}] - Sum[sols[[n]]^(2 i)/(4 i + 2)!, {i, 0, M}]/ Sum[sols[[n]]^(2 i)/(4 i + 3)!, {i, 0, M}] Sum[ sols[[n]]^(2 i)/(4 i + 3)! x^(4 i + 3), {i, 0, M}]; Panel[Column[{Row[{"Single-Span:", PopupMenu[ Dynamic[beam], {1 -> "Free-Pinned", 2 -> "Clamped-Free"}], Row[{"Mode:", SetterBar[Dynamic[n], Range[Length[sols]]]}]}], Dynamic[Plot[f[x, n], {x, 0, 1}, ImageSize -> Large]]}]]] Which gives you a dynamic like this:The SetterBar can be made to automatically resize based on how many modes there are in the solution. I obviously did not add any functionality to the beam type popup but you can do that. Use the dynamic variable "beam" to change your solution so the plot will change. Regards,Neil
Neil Singer 3 Votes First of all, I had my bracket in the wrong place because I wanted the first row to be the Beam Type and the second row to be the mode. I fixed this in the code below.Next, I do not understand your approach for solving for the mode shapes -- you are setting the root finder for the eigenvalues at arbitrary spacing and this will not guaranty that you get a solution. I would use the formulas in a book such as Blevins:Blevins, R.D., "Formulas for Natural Frequency and Mode Shape", Krieger Publishing Company, 2001. ISBN 9781575241845, Page 108-109.What I would do: He gives an approximate formula for the eigenvalues -- use this for your starting value -- its real close. solve for the actual lambdas for each mode and then use the lambda for plotting in the beam equations provided. I do not understand your "f" equation. Is that a Taylor series for the actual equation? I am curious where that comes from. (* Define some beam shape equations (from Blevins)*) freeFreeShape[l_, x_] := Cosh[l*x] + Cos[l*x] - (Cosh[l] - Cos[l])/(Sinh[l] - Sin[l])*(Sinh[l*x] + Sin[l*x]); freeSlidingShape[l_, x_] := Cosh[l*x] + Cos[l*x] - (Sinh[l] - Sin[l])/(Cosh[l] + Cos[l])*(Sinh[l*x] + Sin[l*x]); clampedFreeShape[l_, x_] := Cosh[l*x] - Cos[l*x] - (Sinh[l] - Sin[l])/(Cosh[l] + Cos[l])*(Sinh[l*x] - Sin[l*x]); freePinnedShape[l_, x_] := Cosh[l*x] + Cos[l*x] - (Cosh[l] - Cos[l])/(Sinh[l] - Sin[l])*(Sinh[l*x] + Sin[l*x]); (* Define a DynamicModule to do the interaction *) DynamicModule[{M = 100, lambdas, lambdaEqns, approxLambdas, n, beam = 1, ans, modeshapes, i, maxCases = 4, maxModes = 10, lamValue}, (* Order in the following lists is Free-Free, Free-Sliding, \ Clamped-Free, Free-Pinned *) (* List of equations for lambda (from \ Blevins) we will be finding the lamvalue that makes them zero later *) lambdaEqns = {Cos[lamValue]*Cosh[lamValue] - 1, Tan[lamValue] + Tanh[lamValue], Cos[lamValue]*Cosh[lamValue] + 1, Tan[lamValue] - Tanh[lamValue]}; (* List of equations for approximate lambda (from Blevins) we will \ use these as starting guesses later *) approxLambdas = {(2*i + 1) Pi/2., (4*i - 1) Pi/4., (2*i - 1) Pi/ 2., (4*i - 1) Pi/4.}; (* Create a list of the solutions -- there are maxCases (I only did \ 4 beam types so this is 4) lists each with the first maxModes lambdas*) lambdas = Table[lamValue /. Table[FindRoot[ lambdaEqns[[indx]], {lamValue, approxLambdas[[indx]]}, WorkingPrecision -> 18], {i, maxModes}], {indx, maxCases}]; (* make a list of the functions so we can choose from them when \ plotting *) modeshapes = {freeFreeShape, freeSlidingShape, clampedFreeShape, freePinnedShape}; (* make a panel and plot things up *) Panel[Column[{Row[{"Single-Span: ", PopupMenu[ Dynamic[beam], {1 -> "Free-Free", 2 -> "Free-Sliding", 3 -> "Clamped-Free", 4 -> "Free-Pinned"}]}], Row[{"Mode:", SetterBar[Dynamic[n], Range[maxModes]]}], (*Dynamically choose a modeshape equation and apply it to two \ arguements -- the corresponding lambda by indexing into the lambda \ list first by beam, then by mode number, plot it in x *) Dynamic[Plot[modeshapes[[beam]][lambdas[[beam, n]], x], {x, 0, 1}, ImageSize -> Large]]}]]] `I create a list of the functions to solve to get the eigenvalues (lambdas) for each beam type. Next create a list of the approximate lambda formulas so the guesses are very close. Next create a list of actual lambdas by solving the equation from the first list with the starting values from the second list. Next I would create a list of mode shape equations. When you choose a beam type, you choose a set of lambdas for that beam type and an equation for the beam shape. I put it together for a few beams -- you will need to add the rest. Note I defined the equations for the beam shapes outside of the Dynamic -- this was not necessary -- you could paste that block inside the DynamicModule before the line modeshapes = ... and make them local functions by adding them to the local variable list -- so they are not globally defined -- its up to you.This is what it looks like:Regards,Neil
|
2017-09-22 13:36:39
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.38714873790740967, "perplexity": 4255.175293150452}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-39/segments/1505818688966.39/warc/CC-MAIN-20170922130934-20170922150934-00592.warc.gz"}
|
https://projecteuclid.org/euclid.die/1356012734
|
## Differential and Integral Equations
### Blow-up analysis for some mean field equations involving probability measures from statistical hydrodynamics
#### Abstract
Motivated by the mean field equations with probability measure derived by Sawada-Suzuki and by Neri in the context of the statistical mechanics description of two-dimensional turbulence, we study the semilinear elliptic equation with probability measure: \begin{equation*} -\Delta v=\lambda\int_IV(\alpha,x,v)e^{\alpha v}\,{\mathcal P(d\alpha)} -\frac{\lambda}{|\Omega|}\iint_{I\times\Omega}V(\alpha,x,v)e^{\alpha v}\,{\mathcal P(d\alpha)} dx, \end{equation*} defined on a compact Riemannian surface. This equation includes the above mentioned equations of physical interest as special cases. For such an equation we study the blow-up properties of solution sequences. The optimal Trudinger-Moser inequality is also considered.
#### Article information
Source
Differential Integral Equations, Volume 25, Number 3/4 (2012), 201-222.
Dates
First available in Project Euclid: 20 December 2012
|
2018-09-23 06:09:44
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8570197820663452, "perplexity": 1873.4828965998345}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-39/segments/1537267159160.59/warc/CC-MAIN-20180923055928-20180923080328-00455.warc.gz"}
|
https://labs.tib.eu/arxiv/?author=A.%20Szab%C3%B3
|
• Substantial experimental and theoretical efforts worldwide are devoted to explore the phase diagram of strongly interacting matter. At LHC and top RHIC energies, QCD matter is studied at very high temperatures and nearly vanishing net-baryon densities. There is evidence that a Quark-Gluon-Plasma (QGP) was created at experiments at RHIC and LHC. The transition from the QGP back to the hadron gas is found to be a smooth cross over. For larger net-baryon densities and lower temperatures, it is expected that the QCD phase diagram exhibits a rich structure, such as a first-order phase transition between hadronic and partonic matter which terminates in a critical point, or exotic phases like quarkyonic matter. The discovery of these landmarks would be a breakthrough in our understanding of the strong interaction and is therefore in the focus of various high-energy heavy-ion research programs. The Compressed Baryonic Matter (CBM) experiment at FAIR will play a unique role in the exploration of the QCD phase diagram in the region of high net-baryon densities, because it is designed to run at unprecedented interaction rates. High-rate operation is the key prerequisite for high-precision measurements of multi-differential observables and of rare diagnostic probes which are sensitive to the dense phase of the nuclear fireball. The goal of the CBM experiment at SIS100 (sqrt(s_NN) = 2.7 - 4.9 GeV) is to discover fundamental properties of QCD matter: the phase structure at large baryon-chemical potentials (mu_B > 500 MeV), effects of chiral symmetry, and the equation-of-state at high density as it is expected to occur in the core of neutron stars. In this article, we review the motivation for and the physics programme of CBM, including activities before the start of data taking in 2022, in the context of the worldwide efforts to explore high-density QCD matter.
• ### Predicting the magnetic vectors within coronal mass ejections arriving at Earth: 1. Initial Architecture(1502.02067)
June 17, 2015 physics.space-ph, astro-ph.EP
The process by which the Sun affects the terrestrial environment on short timescales is predominately driven by the amount of magnetic reconnection between the solar wind and Earth's magnetosphere. Reconnection occurs most efficiently when the solar wind magnetic field has a southward component. The most severe impacts are during the arrival of a coronal mass ejection (CME) when the magnetosphere is both compressed and magnetically connected to the heliospheric environment. Unfortunately, forecasting magnetic vectors within coronal mass ejections remains elusive. Here we report how, by combining a statistically robust helicity rule for a CME's solar origin with a simplified flux rope topology the magnetic vectors within the Earth-directed segment of a CME can be predicted. In order to test the validity of this proof-of-concept architecture for estimating the magnetic vectors within CMEs, a total of eight CME events (between 2010 and 2014) have been investigated. With a focus on the large false alarm of January 2014, this work highlights the importance of including the early evolutionary effects of a CME for forecasting purposes. The angular rotation in the predicted magnetic field closely follows the broad rotational structure seen within the in situ data. This time-varying field estimate is implemented into a process to quantitatively predict a time-varying Kp index that is described in detail in paper II. Future statistical work, quantifying the uncertainties in this process, may improve the more heuristic approach used by early forecasting systems.
• ### Higher order anisotropies in hydrodynamics(1504.07932)
April 29, 2015 hep-ph, nucl-th
In the last years it has been revealed that if measuring relative to higher order event planes $\Psi_n$, higher order flow coefficients $v_n$ for $n>2$ can be measured. It also turned out that Bose-Einstein (HBT) correlation radii also show 3rd order oscillations if measured versus the third order event plane $\Psi_3$. In this paper we investigate how these observables can be described via analytic hydro solutions and hydro parameterizations. We also investigate the time evolution of asymmetry coefficients and the mixing of velocity field asymmetries and density asymmetries.
• ### Inner Heliospheric Evolution of a "Stealth" CME Derived From Multi-view Imaging and Multipoint In--situ observations: I. Propagation to 1 AU(1311.6895)
Nov. 27, 2013 astro-ph.SR
Coronal mass ejections (CMEs) are the main driver of Space Weather. Therefore, a precise forecasting of their likely geo-effectiveness relies on an accurate tracking of their morphological and kinematical evolution throughout the interplanetary medium. However, single view-point observations require many assumptions to model the development of the features of CMEs, the most common hypotheses were those of radial propagation and self-similar expansion. The use of different view-points shows that at least for some cases, those assumptions are no longer valid. From radial propagation, typical attributes that can now been confirmed to exist are; over-expansion, and/or rotation along the propagation axis. Understanding of the 3D development and evolution of the CME features will help to establish the connection between remote and in-situ observations, and hence help forecast Space Weather. We present an analysis of the morphological and kinematical evolution of a STEREO B-directed CME on 2009 August 25-27. By means of a comprehensive analysis of remote imaging observations provided by SOHO, STEREO and SDO missions, and in-situ measurements recorded by Wind, ACE, and MESSENGER, we prove in this paper that the event exhibits signatures of deflection, which are usually associated to changes in the direction of propagation and/or also with rotation. The interaction with other magnetic obstacles could act as a catalyst of deflection or rotation effects. We propose, also, a method to investigate the change of the CME Tilt from the analysis of height-time direct measurements. If this method is validated in further work, it may have important implications for space weather studies because it will allow infer ICME orientation.
• ### Electromagnetic waves and electron anisotropies downstream of supercritical interplanetary shocks(1207.6429)
We present waveform observations of electromagnetic lower hybrid and whistler waves with f_ci << f < f_ce downstream of four supercritical interplanetary (IP) shocks using the Wind search coil magnetometer. The whistler waves were observed to have a weak positive correlation between \partialB and normalized heat flux magnitude and an inverse correlation with T_eh/T_ec. All were observed simultaneous with electron distributions satisfying the whistler heat flux instability threshold and most with T_{perp,h}/T_{para,h} > 1.01. Thus, the whistler mode waves appear to be driven by a heat flux instability and cause perpendicular heating of the halo electrons. The lower hybrid waves show a much weaker correlation between \partialB and normalized heat flux magnitude and are often observed near magnetic field gradients. A third type of event shows fluctuations consistent with a mixture of both lower hybrid and whistler mode waves. These results suggest that whistler waves may indeed be regulating the electron heat flux and the halo temperature anisotropy, which is important for theories and simulations of electron distribution evolution from the sun to the earth.
• ### Shocklets, SLAMS, and field-aligned ion beams in the terrestrial foreshock(1207.5561)
We present Wind spacecraft observations of ion distributions showing field-aligned beams (FABs) and large-amplitude magnetic fluctuations composed of a series of shocklets and short large-amplitude magnetic structures (SLAMS). We show that the SLAMS are acting like a local quasi-perpendicular shock reflecting ions to produce the FABs. Previous FAB observations reported the source as the quasi-perpendicular bow shock. The SLAMS exhibit a foot-like magnetic enhancement with a leading magnetosonic whistler train, consistent with previous observations. The FABs are found to have T_b ~ 80-850 eV, V_b/V_sw ~ 1-2, T_{b,perp}/T{b,para} ~ 1-10, and n_b/n_i ~ 0.2-14%. Strong ion and electron heating are observed within the series of shocklets and SLAMS increasing by factors \geq 5 and \geq 3, respectively. Both the core and halo electron components show strong perpendicular heating inside the feature.
|
2019-11-19 06:37:38
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5045849084854126, "perplexity": 1950.9595740425239}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-47/segments/1573496670006.89/warc/CC-MAIN-20191119042928-20191119070928-00027.warc.gz"}
|
https://plainmath.net/algebra-ii/81887-finding-y-mrow-class-mj
|
2d3vljtq
2022-07-11
Finding ${y}^{\mathrm{\prime }}$ of $y={\mathrm{log}}_{7}{e}^{8x}$
I know that $\frac{d}{dx}\left({e}^{8x}\right)=8{e}^{8x}$, but I am confused on how to work the rest of the problem.
Is this correct:
${\mathrm{log}}_{e}x=\mathrm{ln}x$ and that $\frac{d}{dx}\left(\mathrm{ln}x\right)=\frac{{y}^{\mathrm{\prime }}}{y}=\frac{1}{x}.$ (Can you show why ${\mathrm{log}}_{e}x=\mathrm{ln}x$ )
$y={\mathrm{log}}_{b}\left(x\right)\phantom{\rule{thickmathspace}{0ex}}⟹\phantom{\rule{thickmathspace}{0ex}}{b}^{y}=x\phantom{\rule{thickmathspace}{0ex}}⟹\phantom{\rule{thickmathspace}{0ex}}\mathrm{ln}\left({b}^{y}\right)=\mathrm{ln}\left(x\right)\phantom{\rule{thickmathspace}{0ex}}⟹\phantom{\rule{thickmathspace}{0ex}}y\mathrm{ln}\left(b\right)=\mathrm{ln}\left(x\right)\phantom{\rule{thickmathspace}{0ex}}⟹\phantom{\rule{thickmathspace}{0ex}}y=\frac{\mathrm{ln}\left(x\right)}{\mathrm{ln}\left(b\right)}$
$\frac{d}{dx}{\mathrm{log}}_{b}\left(x\right)=\frac{1}{x\mathrm{ln}\left(b\right)}$
${\mathrm{log}}_{a}\left({x}^{p}\right)=p{\mathrm{log}}_{a}x\phantom{\rule{thickmathspace}{0ex}}⟹\phantom{\rule{thickmathspace}{0ex}}{\mathrm{log}}_{7}\left({e}^{8x}\right)=8x{\mathrm{log}}_{7}e$
${y}^{\mathrm{\prime }}=\frac{8{e}^{8x}}{{e}^{8x}\mathrm{ln}\left(7\right)}=\frac{8}{\mathrm{ln}\left(7\right)}$
Jordan Mcpherson
Expert
Yes, it's fine. An easier way to proceed is by noting that
$y=x\cdot \left(8{\mathrm{log}}_{7}e\right)=x\cdot \left(8\frac{\mathrm{ln}e}{\mathrm{ln}7}\right)=x\cdot \frac{8}{\mathrm{ln}7}$
by the change of base formula for logarithms.
Desirae Washington
Expert
Simply we have
$y={\mathrm{log}}_{7}{e}^{8x}=\frac{\mathrm{ln}{e}^{8x}}{\mathrm{ln}7}=\frac{8x}{\mathrm{ln}7}⇒{y}^{\prime }=\frac{8}{\mathrm{ln}7}$
Do you have a similar question?
|
2023-02-08 20:10:14
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 38, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8646985292434692, "perplexity": 237.17975131106377}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764500904.44/warc/CC-MAIN-20230208191211-20230208221211-00255.warc.gz"}
|
http://math.stackexchange.com/questions/179269/simultaneous-equations-two-unknowns
|
# Simultaneous equations, two unknowns
I really should've paid more attention to maths in school...
I have some fairly simple simultaneous equations in the following format.
• VMax = DMax + (DMax - DMin) * GMax
• VMin = DMin - (DMax - DMin) * GMin
Knowns are VMax, VMin, GMax, GMin
Unknowns are DMax, DMin
All values are real numbers
Given the above, how can I re-arrange the equations to solve and determine the values of DMin and DMax?
-
First, expand the multiplications:
$VMax=DMax+DMax\cdot GMax-DMin\cdot GMax$
$VMin=DMin-DMax\cdot Gmin+DMin\cdot GMin$
Solve the first equation for DMax
$DMax=\frac {VMax+DMin\cdot GMax}{1+GMax}$
Insert this value in the second equation, leaving you one equation in $DMin$, which you solve the same way. Then insert the value you find for $DMin$ into this one.
-
Wow, it seems I'm really thick! I'm working through this now, thanks – Dr. ABT Aug 5 '12 at 22:24
Slight correction, second expanded equation should be VMin=DMin − DMax⋅Gmin + DMin⋅GMin. I think I've got it though from this - thanks! :) – Dr. ABT Aug 5 '12 at 22:40
@Dr.ABT: You are right. I fixed the typo – Ross Millikan Aug 5 '12 at 23:33
|
2015-07-07 18:05:01
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9279971122741699, "perplexity": 1217.4327629623672}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-27/segments/1435375099758.82/warc/CC-MAIN-20150627031819-00029-ip-10-179-60-89.ec2.internal.warc.gz"}
|
https://www.physicsforums.com/threads/complex-numbers-hyperbolic-trig.140385/
|
# Complex numbers hyperbolic trig
it says to use exponentials to prove:
tanh (iu) = i tan u
however i do not get the correct relationship, is this an error in the question perhaps
The question is correct. Remember i^2 = -1.
what i have done is:
for the left side:
$$tanh u = \frac{sinh u}{cosh u} = \frac{e^{iu}-e^{-iu}}{e^{iu}+e^{-iu}}$$
but then right side
$$i tan u = i\frac{ \frac{e^u-e^{-u}}{2i} } \frac{ e^{iu}+e^{-iu} } {2} }= \frac{e^{u}-e^{-u}}{e^{iu}+e^{-iu}}$$
what have i done wrong here?
Last edited:
the second part of the second equation there should be e^(iu)+e^(-iu)/2
$$tan u = i(e^{-iu} - e^{iu}) / (e^{-iu} + e^{iu})$$
|
2021-08-02 16:53:13
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.779761016368866, "perplexity": 2458.010612262199}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046154321.31/warc/CC-MAIN-20210802141221-20210802171221-00170.warc.gz"}
|
https://math.stackexchange.com/questions/2116548/generic-transformation-matrix-for-rotation-about-an-angle
|
# Generic Transformation Matrix for rotation about an angle
Let T:R2->R2 be the transformation that rotates each point in R2 about the origin through a counterclockwise positive angle $\theta$.
Is it possible to come up with a generic standard matrix for this transformation, by generic i mean which works for any (x,y) and any $\theta$ (positive/negative/anything)?
So far,i could do at best below analysis.
Since standard matrix for a transformation is given by [T(e1) T(e2)], where e1=(1,0) and e2=(0,1).
By assuming 0 < $\theta$ < $\pi$/2 and the point is in first quadrant, we can see that T(e1) = (cos $\theta$,sin $\theta$) and T(e2) = (-sin $\theta$,cos $\theta$) and hence the standard matrix for T is \begin{bmatrix}cos\theta&-sin\theta\\sin\theta&cos\theta\end{bmatrix}.
But does the above matrix works for any point and angle? If not, how would i generate one?
• – kmeis Jan 27 '17 at 15:18
Let $\Omega(x_0,y_0)$ be the center of rotation.
By considering it as the new origin of coordinates, point $M(x,y)$ is transformed into point $M'(x',y')$ if and only if $\vec{\Omega M'}=R(\vec{\Omega M})$, which gives
$$\binom{x'-x_0}{y'-y_0}=\begin{pmatrix}cos\theta&-sin\theta\\sin\theta&cos\theta\end{pmatrix}\binom{x-x_0}{y-y_0}$$
In other terms, the rotation with center $(x_0,y_0)$ and angle $\theta$ sending point $M(x,y)$ onto point $M'(x',y')$ is given by
$$\binom{x'}{y'}=\begin{pmatrix}cos\theta&-sin\theta\\sin\theta&cos\theta\end{pmatrix}\binom{x-x_0}{y-y_0}+\binom{x_0}{y_0}$$
It is not possible to perform such a generic transformation (rotation around given point) using a 2x2 matrix because the transformation is not linear. A good way to perform this transformation is given in JeanMarie's answer.
If you really want to apply the a transformation using a single matrix, then have a look at homogeneous coordinates (eg. http://planning.cs.uiuc.edu/node99.html).
For your transformation this would result in (though check for errors): $$\left(\begin{array}{c} x' \\ y' \\ 1 \end{array}\right) = \left(\begin{array}{c} 1 & 0 & x_0 \\ 0 & 1 & y_0 \\ 0 & 0 & 1 \end{array}\right) \left(\begin{array}{ccc} \cos(\theta) & -\sin(\theta) & 0 \\ \sin(\theta) & \cos(\theta) & 0 \\ 0 & 0 & 1 \end{array}\right) \left(\begin{array}{ccc} 1 & 0 & -x_0 \\ 0 & 1 & -y_0 \\ 0 & 0 & 1 \end{array}\right) \left(\begin{array}{c} x \\ y \\ 1 \end{array}\right) = \left(\begin{array}{ccc} \cos(\theta) & -\sin(\theta) & -\cos(\theta) x_0 + \sin(\theta) y_0 + x_0 \\ \sin(\theta) & \cos(\theta) & -\sin(\theta) x_0 - \cos(\theta) y_0 + y_0 \\ 0 & 0 & 1 \end{array}\right) \left(\begin{array}{c} x \\ y \\ 1 \end{array}\right),$$ effectively translating to the origin, rotating, and translating back.
|
2019-07-23 22:04:09
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7331885099411011, "perplexity": 489.4866619273738}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-30/segments/1563195529737.79/warc/CC-MAIN-20190723215340-20190724001340-00477.warc.gz"}
|
https://math.stackexchange.com/questions/3182794/every-uncountable-compact-uniform-space-has-a-nonatomic-measure
|
# Every uncountable compact uniform space has a nonatomic measure?
It is known that the class of nonatomic measures on compact metric space without isolated point $$X$$ is dense in $$\mathcal{M}(X)$$, where $$\mathcal{M}(X)$$ is the set of Borel probability measures endowed with the weak$$^*$$ topology.
In my research, $$X$$ is a compact uniform space. Is it true that the class of non-atomic measures on compact uniform $$X$$ is dense in $$\mathcal{M}(X)$$?
$$X=\omega_1+1$$ is an uncountable compact uniform space. I don't know of any non-atomic Borel measure defined on $$X$$. The standard Dieudonné measure is not. Ulam proved there cannot be a total non-atomic measure. So I think this $$X$$ will give you a counterexample.
|
2019-05-26 22:04:12
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 10, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9534578919410706, "perplexity": 109.1673261899225}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232259757.86/warc/CC-MAIN-20190526205447-20190526231447-00307.warc.gz"}
|
http://openstudy.com/updates/4dd5da53d95c8b0b76e55cc4
|
## watchmath 5 years ago Find the height of the lamp post (see the attachment).
1. watchmath
2. myininaya
did you make this problem up or did you find it somewhere
3. watchmath
It is from a book :). We give this as an assignment for our student :).
4. myininaya
i think i'm fixing to figure out lol
5. myininaya
if i can figure out P i'm done
6. myininaya
so far i have y1=2x0/y0 where P=(-x0,y0) this is the way i'm suppose to go about it right?
7. myininaya
and where L representing the point of the bulb of the lamp post at (3,y1)
8. myininaya
so found the slope of the line containing P and the x intercept (-5,0) and got m=(y1-0)/(3+5)=y1/8 and i found the derivative of the ellipse which is y'=-x/4y i evaluated y' at (-x0,y0) and got y'=x0/4y0 so this has to be equal to y1/8 so we have y1=2x0/y0
9. myininaya
omg omg P=(-1,1) so y1=2
10. myininaya
11. myininaya
the height is 2 :)
12. myininaya
ty so much for the problem :) i don't know if i went about the long way or not but i feel good about it
13. watchmath
Good job Miyaniya :) So you like it?
14. myininaya
yes im going to use it wow it took while for me to figure how to get P lol that was my problem for the longest time
15. myininaya
is this way that you were thinking about finding the height? or is there a shorter way?
16. watchmath
Here what I will do to find $$P$$. Let $$P=(a,b)$$. Using $$(a,b)$$ and $$(-5,0)$$ the slope is $$m=\frac{b}{a+5}$$. Using implicit differentiation the slope is $$m=-\frac{a}{4b}$$. Setting the two to be equal, we have $$4b^2=-a^2-5a$$. But since $$(a,b)$$ is on the ellipse, $$4b^2=5-a^2$$. So $$-a^2-5a=-a^2+5$$ which implies $$a=-1$$. It follows that $$4b^2=5-a^2=4$$. So $$b=\pm 1$$. But $$b$$ is above the $$x$$-axis. So $$b=1$$. Hence $$P=(-1,1)$$. Let $$h$$ be the height that we are looking for. Using similar triangle we have $$\frac{h}{5+3}=m=\frac{1}{4}$$. Then $$h=2$$.
17. myininaya
ok nice. you have less text than i have writing lol
18. myininaya
thank you so much watchmath. i'm totally going to give this to my calculus students and let them work on it as a group project
19. watchmath
My pleasure :)
|
2016-10-27 15:15:35
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8199368119239807, "perplexity": 921.9640451254088}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-44/segments/1476988721347.98/warc/CC-MAIN-20161020183841-00230-ip-10-171-6-4.ec2.internal.warc.gz"}
|
https://www.studyadda.com/solved-papers/jee-main-advanced/mathematics/probability/aieee-solved-paper-2009/47
|
# Solved papers for JEE Main & Advanced AIEEE Solved Paper-2009
### done AIEEE Solved Paper-2009
• question_answer1) In a binomial distribution $B\left( n,p=\frac{1}{4} \right),$if the probability of at least one success is greater than or equal to$\frac{9}{10}$, then n is greater than AIEEE Solved Paper-2009
A) $\frac{1}{\log _{10}^{4}-\log _{10}^{3}}$
B) $\frac{1}{\log _{10}^{4}+\log _{10}^{3}}$
C) $\frac{9}{\log _{10}^{4}-\log _{10}^{3}}$
D) $\frac{4}{\log _{10}^{4}-\log _{10}^{3}}$
• question_answer2) One ticket is selected at random from 50 tickets numbered 00, 01, 02, ... , 49. Then the probability that the sum of the digits on the selected ticket is 8, given that the product of these digits is zero, equals AIEEE Solved Paper-2009
A) 1/14
B) 1/7
C) 5/14
D) 1/50
|
2020-08-08 06:35:35
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8880353569984436, "perplexity": 5235.012054601253}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-34/segments/1596439737289.75/warc/CC-MAIN-20200808051116-20200808081116-00307.warc.gz"}
|
http://clay6.com/qa/6713/what-is-the-value-of-tan-x-tan-y-given-x-0-y-0-and-xy-1-
|
# What is the value of $tan^{-1}x- tan^{-1}y$ given $x>0$. $y<0$ and $xy<-1$?
Answer: $\pi$ + $tan^{-1}\frac{x-y}{1+xy}$
|
2017-11-23 18:37:01
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6831757426261902, "perplexity": 158.7285725605544}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-47/segments/1510934806856.86/warc/CC-MAIN-20171123180631-20171123200631-00191.warc.gz"}
|
https://www.physicsforums.com/threads/lightning-struck-me-down.70160/
|
Lightning, struck me down
1. Apr 5, 2005
Sidearm
i have a physics assignment and cant do a few questions, normally i would not resort to asking, but i am really stuck
1. 2 lightning strikes occur simultaneously 10km apart if an observer was 2km from one and 8km from another
a) find the time delay between the first flash and the second reaching him
b) the time delay between the sound of the closer strike and the distant strike reaching him,
2. if i dropped a 40kg rock over the edge of a 60m high cliff on the moon, where g = 1.64ms -1
a) how long would the rock take to reach the ground
b) what would the rocks weight be
Any help would be greatly appreciated, also if you could mention how to do this for future reference that would be great
2. Apr 5, 2005
whozum
1a) Do you know the speed of light? Its 3 x 10^8m/s
With this speed, and the distances, 8km, and 2km, find the time it takes to get him.
The equation for this is $t = \frac{d}{v}$
The time delay between two events is $t_2-t_1$
Now do the same with sound, sound has a speed of 340m/s, One million times less than the speed of light.
The numbers for a) will be pretty small, the numbers of b) will be a few seconds each.
2. You know the position equation for an object in free fall is:
$$x(t)-x_0 = v_0t + \frac{gt^2}{2}$$
Since there was no initial position (x-x_0) or initial velocity (v_0), the equation simplifies to:
$$h = \frac{gt^2}{2}$$
You can solve this for t by rearranging and taking the square root, from there a) should be fairly easy.
Weight is a measure of the force of an object due to gravity, what is the equation for force? You are given a mass, and an acceleration. Find the force.
3. Apr 6, 2005
|
2017-04-23 21:57:11
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5702180862426758, "perplexity": 692.620292058732}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-17/segments/1492917118831.16/warc/CC-MAIN-20170423031158-00143-ip-10-145-167-34.ec2.internal.warc.gz"}
|
http://tex.stackexchange.com/tags/formatting/new
|
Tag Info
4
Here is a solution based on atbegshi and answers packages. The idea is to use answers that write contents of theorem, lemma to an external file (mtfile.tex), discard all pages (all contents of the main file http://tex.stackexchange.com/a/267555/71471) and then use the external file to output only theorems. We use a newif test \onlytrue for only theorem and ...
0
Another way to include mathematica packages into latex is to use this package mma.sty by Manuel Kauers. With \usepackage{mma} in the preamble one can do a lot. I find it really amazing. I normally enclose it in mdframed environment which I think is pretty cool. See the image below: There are also example on how one can use the package in the style ...
2
By default footnotes start at the end of the text block so if the page is not full the space required to pad the page comes below the notes. This seems natural enough to me but if you want the padding space to come between the text block and the footnotes then you can use \usepackage[bottom]{footmisc}
1
Assuming that you do not need the star versions of the \section et al: \documentclass[12pt]{report} \usepackage{csuf-thesis} \usepackage{hyperref} \hypersetup{colorlinks=false} \nocopyright \setcounter{secnumdepth}{0} \makeatletter \def\section#1{\@startsection{section}{1}{\z@} {-7ex}{2ex \@plus 0.01ex} {\centering\ssp}{\underline{#1}}} ...
2
you had defined a fancy page style but commented out the use of that style, and even if it were uncommented you had over-written it multiple times with the empty and plain styles. Also there were several error and unclosed groups reported. \documentclass[12pt, oneside, a4paper, leqno]{report} \linespread{1.5} \usepackage{geometry} ...
3
Already many good and diverse answers. I am adding one for another completely expandable macro. Complete expandability's constraint saves us from having to cook up names for temporary macros. In the code below, one could make \Duration@i recursive and obtain in this way an expandable macro for conversion to sexagesimal notation, with arbitrary big integers ...
0
For writing code you can use the package listings (Documentation: http://texdoc.net/texmf-dist/doc/latex/listings/listings.pdf)
6
(Updated the Lua code after the OP clarified that rounding rather than truncation should be applied to the seconds in the duration calculations.) Here's a LuaLaTeX-based solution. The preamble sets up both a Lua function named formatted_duration and a TeX macro named \fdur. The TeX macro takes one argument (the duration in seconds and fractions of a ...
7
Here is a solution using apnum package: \input apnum \def\duration#1{{\apFRAC=0 % "/" means integer division \def\zero{0}% \evaldef\S{#1/1}% \S: number of seconds (without fraction part) \evaldef\H{\S/3600}% \H: number of hours \evaldef\Hrest{\S - 3600*\H}% \Hrest: number of seconds without hours ...
8
You can do it with expl3 and its fp module. \documentclass{article} \usepackage{xparse} \ExplSyntaxOn \NewDocumentCommand{\duration}{m} { \didou_duration:n { #1 } } \fp_new:N \l_didou_duration_hrs_fp \fp_new:N \l_didou_duration_min_fp \fp_new:N \l_didou_duration_sec_fp \cs_new_protected:Nn \didou_duration:n { \fp_compare:nTF { #1 < 60 } {% ...
1
Very basic, not much can be done here. Otherwise customize the itemize list with enumitem package to provide other typesetting facilities. \documentclass{article} \begin{document} \begin{description} \item Foo We have something to say here \item Foobar We have to say something differently here \end{description} \end{document}
9
Using \pgfmathparse is problematic for this question because integer division fails with a "Dimension too large" error around 16500. In particular, without some additional care, any solution using \pgfmathparse will not be able to cope with the OP's example of 18249 because this number is too large. For large (integer) calculations the xint family of ...
7
As pointed out by Andrew, pgfmath cannot by default cannot handle numbers larger than 16383.99999; however, the pgfmath library can handle floating point numbers thereby allowing (nearly) arbitrarily large numbers to be handled. The limitation then becomes the precision, and ultimately certain digits are truncated. Floating Point Version This function ...
5
The first equation below features the frational term shifted down so that the fraction bar is at the same height as the lower horizontal stroke of the summation symbol. The second equation features a more standard look. Speaking for myself, I'd go with the look of the second equation. \documentclass{article} \usepackage{amsmath,amsfonts} ...
5
A simple fix for these annoying little size mismatchs in otherwise similar formulas is to use \vphantom : Since $\foo{B} = \foo{\sum_j b_jB_j}$ and $\foo{C} = \foo{\sum_{i\vphantom{j}} c_{i\vphantom{j}} C_{i\vphantom{j}}}$ by definition. One \vphantom should be sufficient of course, in the present case, the one of the \sum operator as its subscript is ...
1
Don't change \footnotesize... We need to change three components to address your three requirements. Change the footnote number. For this we need to adjust \@makefnmark, which starts out like this (from latex.ltx): \def\@makefnmark{\hbox{\@textsuperscript{\normalfont\@thefnmark}}} We can replace the insertion of \normalfont with ...
4
10
The different height of the brackets is caused by the descender of the letter j compared to i. One way: Use k instead of j (or any other letter without descender) Or perhaps using \bigl[ and \bigr] is an option (or if scaling isn't an issue \big[ and \big]?) \documentclass{article} \usepackage{amsmath} \newcommand{\foo}[1]{\bigl[#1\bigr]} \begin{document} ...
0
The following code does everything except aligning the "left column" correctly. \documentclass[11pt]{article} \usepackage{sectsty} \usepackage{amsmath} \sectionfont{\fontsize{11}{15}\selectfont} \usepackage{xcolor} \usepackage{graphicx} \usepackage[usestackEOL]{stackengine} \usepackage[top=1cm, bottom=1cm, left=1cm, right=1.5cm]{geometry} \begin{document} ...
6
You're using the syntax of eqnarray, and are forgetting to load amsmath; compiling your example produces scores of errors and the output is almost arbitrary. \documentclass{article} \usepackage[margin=0.5in]{geometry} \usepackage{amsmath} \begin{document} \begin{align*} \sum_{i=1}^{k+1} i^{3} &= \biggl(\sum_{i=1}^{n} i^{3}\biggr) + i^3\\ &= ...
3
\documentclass{article} \usepackage[T1]{fontenc} \begin{document} \raggedright \texttt{\detokenize{C_n = {(z_1, ..., z_n) \in R^n : z_i \neq z_j \forall i \neq j}. I want to prove that pi_k(C_n) = 1 \forall k > 1. any ideas?}} \end{document}
1
Here's another enumitem approach, but automatic switching to \ttfamily using before={\ttfamily}. \documentclass[11pt]{report} \usepackage[utf8]{inputenc} \usepackage{textcomp} \usepackage[T1]{fontenc} \usepackage{enumitem} \newlist{itemtt}{itemize}{1} \setlist[itemtt,1]{label={\textbullet},before={\ttfamily}} \begin{document} \begin{itemtt} \item This ...
1
something like this : \documentclass{article} \usepackage{enumitem} \begin{document} \ttfamily \begin{itemize}[label=\textbullet] \item item1 \item item2 \end{itemize} \end{document}
3
Independent of the editor being used, we have latexindent by Chris (cmhughes). This should do a good job in beautifying the latex code by indenting everything. On the other hand there is a Align Columns option in texstudio (which a cousin of texmaker) where you select 1 & 2 & \mathbf M \\ 1 & -3 & \mathbf M \\ 1 & 6 & ...
2
There is no semibold version but you could scale up a smaller font size (the code I use is okay for a short portion like a title but not suitable for longer text!): \scalebox and resizebox of the graphicx package can be used too. It is up to you to decide if this looks pleasing ... \documentclass{article} \usepackage[T1]{fontenc} \usepackage{lmodern} ...
1
Since you use titleps, replace loading it with the option pagestyles of titlesec, and use its ‘easy’ interface. You won't even have to use the optional argument of \section: \documentclass{book} \usepackage{lipsum}% just to generate text for the example \usepackage[pagestyles]{titlesec} \newpagestyle{main}[\small]{ % define header ...
2
You should avoid setting the font of a sectional units within the argument. Not only does that force you to also supply an optional argument to circumvent these font settings to make it's way into the ToC, you run the risk that you're not being consistent in your formatting. While there are many options available for setting the sectional unit font, here's ...
3
\renewcommand\figurename{Figure} should work.
2
The KOMA-Script classes provide an option parskip to use a skip instead a par indent. Remove both lines \parskip 0.1in and \parindent 0in from your code and use \documentclass[...,parskip=half-,...]{scrbook} to get a similar skip between paragraphs. KOMA-Script classes load and use package typearea to calculate the margins and the text body. If you have ...
7
Note that play.cls is designed to typeset specifically this kind of material and can be customised in various ways. Here's a simple, default example: \documentclass{play} \title{A Play} \author{Will} \newcommand*\character[1]{\textsc{#1}} \begin{document} \maketitle \begin{thesetting} Setting for play. \character{Character} is $\phi$ing. ...
4
\documentclass{article} \usepackage{enumitem} \usepackage{lipsum} \begin{document} \begin{itemize}[leftmargin=5em,labelwidth=5em,labelsep=0pt, label={\smash{\small\itshape\begin{tabular}[t]{@{}l@{}}Stage\\ Directions\end{tabular}}}, align=left,font=\bfseries] \item\lipsum[3] \item[Tom] \lipsum[1] \item[Jerry] \lipsum[2] \end{itemize} ...
3
Without a MWE answering your question is like looking into a dirty crystal ball, so if this is not what you want, please send window cleaner... Code taken from http://tex.stackexchange.com/a/289036/36296 \documentclass{book} \usepackage{fancyhdr} \usepackage[margin=0.75in,head=2cm,top=1.5cm,bottom=2.5cm,includehead]{geometry} \usepackage{lastpage} ...
3
Try the following \makeatletter \renewbibmacro*{begentry}{% \ifkeyword{Key}{\sffamily}{}% \iffieldundef{shorthand} {} {\global\undef\bbx@lasthash \printfield{shorthand}% \addcolon\space}% \ifboolexpr{test {\usebibmacro{bbx:dashcheck}} or test {\ifnameundef{shortauthor}}}% {}% {\printnames{shortauthor}% ...
2
I was looking for a similar approach recently and my question was solved by using lua code within my document Using LuaLaTeX to calculate lengths in cm to be used in TikZ drawing. In the attached code I have a question regarding Magnetism and all numbers are randomly generated, which will in turn create a new question + answers. I also included some ...
4
This answer uses the biblatex package with biber. First, the entries that need highlighting need to be defined. You do this by adding a keywords entry into the respective items. Let's say, you want to have bold entries with keyword bold and sans-serif entries with keyword sans. Then, you add the following to your preamble: \renewbibmacro*{begentry}{% ...
3
4
I would avoid using caption with memoir as it provides its own mechanism for setting sub-floats: \documentclass{memoir} \usepackage{graphicx} % Enable subfigures \newsubfloat{figure} \begin{document} \begin{figure} \hfill \subbottom[First subcaption]{% \includegraphics[width=3cm]{example-image-a}} \hfill \subbottom[Second subcaption]{% ...
6
When using subcaption with memoir there is no need to say \newsubfloat{figure}. Remove that line and it's seems to be fine. \documentclass[a4paper, 10pt, openany]{memoir} \usepackage[demo]{graphicx} \usepackage{caption} \usepackage{subcaption} % Enable subfigures %\newsubfloat{figure} %commented % Section numbering depth \maxtocdepth{subsection} ...
2
If you use the Biber backend, things should be as easy as \renewrobustcmd*{\bibinitperiod}{} \renewrobustcmd*{\bibinitdelim}{\addnbspace} as jon points out in the comments, or can be read in Remove periods after author initials, but leave spaces. If you for the live of you cannot bear to use Biber and want to stick to your BibTeX(-like) backend you ...
6
Here is an example without package titlesec. \documentclass{scrbook}[2015/10/03] \usepackage[T1]{fontenc} \usepackage{xcolor} \usepackage{charter} \definecolor{mybluei}{RGB}{28,138,207} \definecolor{myblueii}{RGB}{131,197,231} \addtokomafont{disposition}{\usefont{T1}{qhv}{b}{n}\selectfont\color{myblueii}} ...
2
Does this meet your conditions? \documentclass[ 11pt, pagesize=auto, version=last, chapterprefix=true ]{scrbook} \usepackage[T1]{fontenc} \usepackage[explicit]{titlesec} \usepackage{xcolor} \usepackage{charter} \definecolor{mybluei}{RGB}{28,138,207} \definecolor{myblueii}{RGB}{131,197,231} ...
5
chapterthumbs: Chapter Thumbs or Tabs in Book Class re. chapterthumb.sty. However, unless it has been updated, that package no longer works with current versions of the class. Also: How to get chapterthumbs match their chapter titles in KOMA-Script? flowfram's thumbtabs: How do I specify what text is in thumbtabs background: Show ...
1
In addition, if you absolutely want to make your bibliography by hand (which is not recommended, as it will probably not meet the standards), it's easier to use a description environment, which can break across pages, and can be customised with the enumitem package: \documentclass[12pt]{article} \usepackage[utf8]{inputenc} \usepackage{amsmath} ...
2
After you get a TeX error you should look at the log file, not the pdf output. TeX does not attempt to make sensible typeset result as it recovers from an error. Cats, O., Reimal, T., & Susilo, needs to be Cats, O., Reimal, T., \& Susilo, the error message is quite explicit about the extra & ! Extra alignment tab has been changed to ...
2
You could put the comments in parboxes. \documentclass{article} \usepackage{mathtools} \begin{document} \begin{alignat*}{2} \lim_{x\to 1} \frac{x^2-1}{1-x} &= \lim_{x\to 1} \frac{(x-1)(x+1)}{-(x-1)} &\quad& \parbox{160pt}{\raggedright Factoring the numerator and factoring $-1$ from the denominator.} \\ ...
6
You can exploit \new@ifnextchar from amsmath: \documentclass[]{article} \usepackage{amsmath} \usepackage{newtxtext,newtxmath} \usepackage{syntax} \usepackage{xpatch} \makeatletter \pretocmd{\grammar}{\let\@ifnextchar\new@ifnextchar}{}{} \makeatother \renewcommand{\syntleft}{$\langle$\normalfont\ttfamily} \begin{document} \begin{grammar} <a> ::= ...
2
You could achieve the desired effect by using the \smashoperator macro, which is provided by the mathtools package, with the [r] option. This informs LaTeX that an overlap should be allowed between the material placed below the summation symbol and the material that follows after the summation symbol. \documentclass{article} \usepackage{mathtools} % for ...
1
See if \mathrlap{...} from mathtools package gives what you like to obtain: \documentclass[border=3mm,preview]{standalone} \usepackage{mathtools} \begin{document} $y=\sum\limits_{\mathrlap{x \in A[1...i-1]}} x$ \end{document}
5
The first part of your question is not specific to the syntax package. The problem is that in environments such as array and tabular and grammar, \\ directly followed by an opening square bracket is assumed to introduce an adjustment to vertical spacing. And a space beforehand doesn't prevent the next relevant token counting as the [. You don't want an ...
4
From siunutx manual markers are often given in tables after the numerical content. It may be table-align-text-post desirable for these to close up to the numbers. Whether this takes place is controlled by the table-align-text-pre and ...-post option You can remove space before the closing parenthesis with table-align-text-post = false. Your ...
Top 50 recent answers are included
|
2016-02-08 04:35:05
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9803512096405029, "perplexity": 5401.841244968076}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-07/segments/1454701152130.53/warc/CC-MAIN-20160205193912-00207-ip-10-236-182-209.ec2.internal.warc.gz"}
|
https://math.stackexchange.com/questions/675607/walks-on-hypercube-generating-function-approach
|
# Walks on hypercube: generating function approach
So the problem is simple: given a hypercube in $\mathbb{R}^n$, whose vertices are $(v_1,..,v_n)$ for each $v_i$ equals 0 or 1, and there is an edge from u to v if they differ at exactly one bit, count the number of walks from vertex u to v in l steps.
As far as I know, there are solutions using spectral analysis, but since I'm interested in purely combinatorial solution, I'm trying my approach using generating function. But I'm not experienced enough in generating function, so I'd like your help on how to proceed.
Without loss of generality, assume $u = (0, 0, .., 0)$. Furthermore, we can assume we are only interested in the number of bits of v, as we can divide the answer by ${n \choose k}$ afterward.
Let $f(r,k)$ be the number of r-step walks starting from 0, ending at a vertex containing exactly k bit 1. We start with $f(0,0) = 1$ and it's easy to obtain the recurrence
$f(r + 1,k) = n.f(r,k - 1) - (k - 1)f(r,k - 1) + (k + 1)f(r,k + 1)$
Now set $A_r(x) = \sum_{k = 0}^n f(r,k) x^k$. It's not hard to show the recurrence
$A_{r + 1}(x) = nxA_r(x) - (x^2 - 1)A'_r(x)$ with $A_0(x) = 1$
Any help on how to progress from here?
• If you're interested in a purely combinatorial solution, a generating function shouldn't qualify in my opinion, since for most things that can be proven using (ugly) generating functions, a nice combinatorical proof using a 'story' and counting the same thing twice is much faster and easier. – Ragnar Feb 13 '14 at 22:04
• Is it allowed to visit the same vertex multiple times? – Ragnar Feb 13 '14 at 22:09
• Yes, as you can see it in the recurrence relation. – Linh Nguyen Feb 13 '14 at 22:11
• Ok. Do you also have a recurrence relation on $k$? – Ragnar Feb 13 '14 at 22:13
• Hmm I have some idea on that, but I can't avoid double counting right now. – Linh Nguyen Feb 13 '14 at 22:28
Here's a way. The number of $l$-step walks from $(0,\cdots,0)$ to $(u_1,\cdots,u_n)$ will be
$$[x_1^{u_1}\cdots x_n^{v_n}](x_1+\cdots+x_n)^l \tag{\cdot}$$
where the polynomial is considered an element of $\Bbb Z[x_1,\cdots,x_n]/(x_1^2-1,\cdots,x_n^2-1)$.
We can decompose $[x_1^{u_1}\cdots,x_n^{u_n}]=[x_1^{u_1}]\cdots[x_n^{u_n}]$ informally and consider each as an evaluation map via $[x_i^{0}]P:=P|_{x_i=0}$ and $[x_i^1]:=P|_{x_i=1}-P|_{x_i=0}$. If $\vec{u}$ has $r$ ones we can without loss of generality write it as $\vec{u}=(\underbrace{1,\cdots,1}_{r},\underbrace{0,\cdots,0}_{n-r})$ because of symmetry. Ignore the last $n-r$ zeros.
Expand $[x_1^1\cdots x_r^1]$ out and apply to $(\cdot)$ to obtain terms $(\overbrace{1+\cdots+1}^k+\overbrace{0+\cdots+0}^{r-k})^l$ with $\binom{r}{k}$ possible arrangements of $0$s and $1$s, with the sign $(-1)^{r-k}$, for each $k=0,\dots,r$, yielding
$$\#\text{paths}=\sum_{k=0}^r (-1)^{r-k}\binom{r}{k} k^l.$$
I'll start writing down my approach. I don't know yet whether it will work out or not, but at least you can see it and maybe continue it.
There are $n$ dimensions. For each move, we choose a direction $1\leq i\leq n$ (north/south, east/west, up/down and so on for higher dimensions) and move in that direction. In vector notation: $a_0=(0,0,\dots,0)$, $a_{t+1}=a_t+e_i$, where $a_t\in \mathbb F_2^n$. The exponential generating functions we are going to use are: $$G_i(x)=x^{v_i}(1+\frac 12x^2+\frac1{4!}x^4+\cdots)=x^{v_i}\cosh(x)$$ Thus, we have one exponential generating function for each dimension. The coefficient in the sum is zero when the parity of the number of steps in dimension $i$ is wrong. We use exponential generating functions, because the order in which we take the steps does matter, but all steps in one direction are identical.
To find the number of ways to get to $v$ in $r$ steps, just take the coefficient of $x^r$ in $$\prod_{i=1}^nG_i(x)=x^s\cosh(x)^n$$ where $s=\sum_{i=1}^nv_i$ is the parity of the total number of steps we need. I'll update if I find a somewhat nice expression for it or at least a good way to obtain it.
|
2021-05-07 12:37:27
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8266304731369019, "perplexity": 135.24776288264016}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-21/segments/1620243988793.99/warc/CC-MAIN-20210507120655-20210507150655-00284.warc.gz"}
|
https://www.physicsforums.com/threads/simple-limit.558193/
|
Simple limit
1. Dec 8, 2011
Apteronotus
Hi,
If
$k_3 \cdot (A_1 \cos k_1 x + A_2 \sin k_1 x)\cdot(B_1 \cos k_2 y + B_2 \sin k_2 y)\cdot(C_1 e^{k_3 z}-C_2 e^{-k_3 z})=E$
in the limit as $\sqrt{x^2+y^2+z^2}\rightarrow\infty$
Can we infer anything about any of the constants?
2. Dec 10, 2011
Stephen Tashi
One way to let $\sqrt{x^2 + y^2 + z^2}$ approach infinity is to set y = 0, z= 0 and let x approach infinity. Do you really mean to allow that kind of approach? if so, won't the constants have to be chosen so the the expression is identically zero for all values of x ?
|
2018-10-21 08:17:58
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9259230494499207, "perplexity": 405.7886458900262}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-43/segments/1539583513804.32/warc/CC-MAIN-20181021073314-20181021094814-00062.warc.gz"}
|
https://physics.stackexchange.com/questions/159521/orbital-magnetic-moment-versus-biot-savart-law
|
# Orbital magnetic moment versus Biot-Savart law
In atomic physics, the fine structure of spectral lines assigned to atomic hydrogen has always been explained by considering an orbital magnetic moment of atomic electron. Still this concept is inconsistent with the basic laws of electromagnetism.
Consider a circular electric current of radius $r$, whose constant intensity is $I = nev/2πr$, where $n$ is the number of conduction electrons, $e$ is their elementary electric charge, and $v$ is their constant linear velocity. This circular electric current originates in surrounding space a dipole magnetic field measured by a magnetic moment $M = IS$, where $S = 4πr^2$. As all magnetic fields are generated by elementary electric charges in motion, this dipole magnetic field is evidently the vector sum of all magnetic fields originated simultaneously by all conduction electrons in the considered circular current. Conforming to Biot-Savart law reduced to the peculiar case of a single electron, the force lines of magnetic field generated by an electron in motion are at every moment concentric circles placed in planes perpendicular to its momentary linear velocity vector. Obviously, such a Biot-Savart magnetic field cannot be defined by a magnetic moment.
Now consider a single electron in uniformly circular motion on the same trajectory of radius $r$. Formally, we can assimilate this electron to a circular electric current with constant intensity $I = ev/2πr$, but evidently this single electron cannot originate a dipole magnetic field measured by a magnetic moment. The shape of all subsequent Biot-Savart magnetic field generated moment by moment by this single electron remains the same all the time, but their orientation in space changes every moment concurrently with the change of motion direction of the electron. And these subsequent Biot-Savart magnetic fields are not cumulative in time. It is very clear, a single electron in motion on a closed plane trajectory definitely cannot originate a dipole magnetic field defined by a magnetic moment. Therefore, the Biot-Savart law proves the falsity of the orbital magnetic moment invented for justifying the fine structure of spectral lines assigned to atomic hydrogen.
However, the fine splitting of these spectral lines is a reality experimentally noticed, so that the dipole magnetic field with magnetic moment about one Bohr magneton has to be found as responsible for this spectral splitting effect.
What is the only possible solution of this apparently unsolvable issue? Please use your logic to answer.
• I did not downvote, but here is the beginning of the third sentence from the first reference on the Biot-Savart law that I checked out: “The law is valid in the magnetostatic approximation”. I.e., this is not a “universal law”. In addition to research effort, the question is not very easy to understand. (E.g., what are “continuously successive magnetic fields”?). If I may make a suggestion, try to write simple sentences. – xebtl Jan 15 '15 at 8:13
• Not my downvote, but there are numerous Q/As on the site explaining that the motion of electrons in atoms cannot be explained by classical laws. The correct solution to this dilemma is that you can't apply classical laws like the Bio-Savart law to atoms. I would guess the downvote is because this is such an obvious point it should have occurred to you. – John Rennie Jan 15 '15 at 8:25
• I think your question question is abstruse, even after several readings. Moreover, it is usually difficult to answer a question starting with statements that look questionable at best. (didn't downvote though I hesitated to do so after reading your comment ^^) – TZDZ Jan 15 '15 at 8:29
• @Sava , nobody takes pleasure in giving minuses, nobody rushes to do it. First of all people try to answer. Now, it is not clear where you find a contradiction. Perhaps you know that even a single electron in movement creates a magnetic field. You can look at the question . Once making this clear, what else do you find problematic? I subscribe to what says John Rennie, but let me hear from you what is the next unclear thing from your point of view. – Sofia Jan 15 '15 at 17:46
• @xebtl - The Biot-Savart law is universal in the sense of its applicabilty to all charged elementary particles in motion (electrons, protons, etc.). The shape of magnetic field generated by their motion is established by this law even in the case of a single electron. – Sava Jan 19 '15 at 8:34
|
2020-03-31 17:30:16
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6220315098762512, "perplexity": 299.09576571428676}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-16/segments/1585370502513.35/warc/CC-MAIN-20200331150854-20200331180854-00548.warc.gz"}
|
https://chemistry.stackexchange.com/questions/59162/examples-of-molecules-with-d4-and-c9-point-groups
|
# Examples of molecules with D4 and C9 point groups
Trying to come up with examples of (hypothetical) molecules/shapes that have $D_4$ and $C_{9h}$ point groups.
For $D_4$, I thought a cyclobutane structure, but with 4 substituents coming off of the ring all pointing in the same direction. However, I'm not sure if this is $D_4$ because in a book I am reading it says that all the $D_n$ point groups show chirality, which this molecule does not.
For $C_{9h}$, I really can't think of any shape/structure that doesn't just end up being $D_{9h}$. $C_9$ would be a 9-bladed propellor shape, although I'm not really sure how to draw this, and I don't see how I could alter that to get $C_{9h}$.
Thanks
For nearly any point group which is actually feasible (including $D_4$), look up the Symmetry gallery. Your all-cis tetra-substituted cyclobutane would be $C_{4v}$, BTW.
As for $C_{9h}$... well, I don't quite believe this is possible, but probably we may come up with something that would look almost realistic.
A substituted nanotube fragment will do, I think.
Surely it is hypothetical, so what? Cyclo-$\ce{C18}$ is hypothetical as well, and in my opinion, has lower chances to be stable. Also, its symmetry is kinda dubious.
• why is cyclo-C18 hypothetical? wasn't it first observed in 1989? science.sciencemag.org/content/245/4922/1088 Sep 16 '16 at 16:41
• No, it was not. These guys made some calculations, then prepared some precursors, then saw in the mass spectra some $\ce{C18}$ which is probably cyclic, though nobody knows for sure. That's a circumstantial evidence at best. Sep 18 '16 at 1:05
• @iopscience.iop.org/article/10.1086/500110/pdf maybe you will be more convinced by this 2006 gas phase spectrum, although these author say it is a cumulene ring with alternating bond angles, D9h. Sep 18 '16 at 12:10
• a 2011 book says "With this correction, the minimum is the cyclo-polyacetylene C9h. However, there is a tendency for HF as well as BLYP to artificially yielding lower symmetry structures. Thus, the most stable structure of the cyclic C18 is still debatable" books.google.com/… Sep 18 '16 at 12:22
• OK, well, so this thing does exist, after all. It is its exact geometry (and consequently symmetry) that is hypothetical. Sep 19 '16 at 13:07
The cyclo-C18 polyyne is $C_{9h}$ according Carbon Rich Compounds II: Oligoacetylenes at page 46
The molecule is a planar 18-carbon ring with alternating short and long bonds (triple and single bonds) and bond angles alternating between 157 and 163 degrees.
• Isn't it $\ce{D}_{9\ce{h}}$? Forgive me if I am wrong.
– DHMO
Sep 16 '16 at 15:08
• You might want to attach this image.
– DHMO
Sep 16 '16 at 15:14
• Now that's what I call a stretch. We'll have to tell the difference between $C_{9h}$, $D_{9h}$, and probably other options, based on some minuscule, nearly invisible deviations. In the absence of other options, though, this might do. Sep 16 '16 at 15:14
• @user34388 it that accurate, or is like scheme 8.4 here: books.google.com/… Sep 16 '16 at 15:15
• @IvanNeretin C9h is 0.3 kcal/mol lower than D9h, has alternating bond angles of 157 and 163 degrees pubs.acs.org/doi/abs/10.1021/ja00120a026 Sep 16 '16 at 15:37
|
2021-12-06 00:08:23
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5449662804603577, "perplexity": 1322.3151992960475}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-49/segments/1637964363226.68/warc/CC-MAIN-20211205221915-20211206011915-00471.warc.gz"}
|
http://boundedtheoretics.blogspot.com/2011/09/impugning-randomness-convincingly.html
|
## Monday, September 12, 2011
### Impugning randomness convincingly?
I haven’t finished reading “Impugning Randomness, Convincingly” [pdf], by Yuri Gurevich and Grant Olney Passmore, but I’ll go ahead and share its remarks about our old pal William A. Dembski:
The idea that specified events of small probability do not happen seems to be fundamental to our human experience. And it has been much discussed, applied and misapplied. We don’t — and couldn’t — survey here the ocean of related literature. In §2 we gave already quite a number of references in support of Cournot’s principle. On the topic of misapplication of Cournot’s principle, let us now turn to the work of William Dembski. Dembski is an intelligent design theorist who has written at least two books, that are influential in creationist circles, on applications of “The Law of Small Probability” to proving intelligent design [TDI, NFL].
We single out Dembski because it is the only approach that we know which is, at least on the surface, similar to ours. Both approaches generalize Cournot’s principle and speak of independent specifications. And both approaches use the information complexity of an event as a basis to argue that it was implicitly specified. We discovered Dembski’s books rather late, when this paper was in an advanced stage, and our first impression, mostly from the introductory part of book [TDI], was that he ate our lunch so to speak. But then we realized how different the two approaches really were. And then we found good mathematical examinations of the fundamental flaws of Dembski’s work: [Wein] and [Bradley].
Our approach is much more narrow. In each of our scenarios, there is a particular trial $T$ with well defined set $\Omega_T$ of possible outcomes, a fixed family $\mathcal{F}$ of probability distributions — the innate probability distributions — on $\Omega_T$, and a particular event — the focal event — of sufficiently small probability with respect to every innate probability distribution. The null conjecture is that the trial is governed by one of the innate probability distributions. Here events are subsets of $\Omega_T$, the trial is supposed to be executed only once, and the focal event is supposed to be specified independently from the actual outcome. By impugning randomness we mean impugning the null hypothesis.
Dembski’s introductory examples look similar. In fact we borrowed one of his examples, about “the man with a golden arm” [i.e., Nicholas Caputo]. But Dembski applies his theory to vastly broader scenarios where an event may be e.g. the emergence of life. And he wants to impugn any chance whatsoever. That seems hopeless to us.
Consider the emergence of life case for example. What would the probabilistic trial be in that case? If one takes the creationist point of view then there is no probabilistic trial. Let’s take the mainstream scientific point of view, the one that Dembski intends to impugn. It is not clear at all what the trial is, when it starts and when it is finished, what the possible outcomes are, and what probability distributions need to be rejected.
The most liberal part of our approach is the definition of independent specification. But even in that aspect, our approach is super narrow comparative to Dembski’s. There are other issues with Dembski’s work; see [Wein, Bradley].
I’ve changed the reference numbers to tags that are meaningful to many of you. TDI and NFL are Dembski’s The Design Inference and No Free Lunch, respectively. James Bradley wrote “Why Dembski’s Design Inference Doesn’t Work” [pdf] for BioLogos, and Richard Wein wrote Not a Free Lunch But a Box of Chocolates for TalkOrigins.
|
2018-05-22 21:23:08
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6679847240447998, "perplexity": 1591.3847063669884}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-22/segments/1526794864968.11/warc/CC-MAIN-20180522205620-20180522225620-00285.warc.gz"}
|
https://physics.stackexchange.com/questions/358628/will-quantum-computing-provide-any-advantage-for-storing-large-amounts-of-data
|
# Will quantum computing provide any advantage for storing large amounts of data?
Essentially, does superposition or entanglement provide any advantage for data storage as opposed to classical memory.
No, there's no advantage in capacity.
Given N qubits, the maximum amount of retrievable information you can pack into them is N bits. This is Holevo's theorem.
There is some extra flexibility in how quantum data is stored. I'm sure cypherpunks will get a kick out of that, at least. But, realistically, the flexibility tends to be somewhat... esoteric (e.g. quantum locking).
# Sort of.
It is almost impossible to compare the storage efficiency of different hardware on anything but the most crude metrics, like "how many bits can you store per square millimeter?", that provide absolutely no insight into anything physically interesting. So to do interesting theory here one needs the idea of qubits as being compared directly with bits.
In turn it is possible to phrase this in a question that also gives you no insight, like "how many bits would it take to represent the state space of $n$ qubits?" (Exponentially many.)
But there is a very nice way to phrase a tightly related question which is, "someone has sent me $n$ qubits, how many classical bits could I possibly extract from this?" The answer, if you have absolutely no prior history with this person, is $n$ bits. In that sense there is nothing better you can do.
You can hear the waffling and you may be curious, "what if I have history with this other person, can I do better?" and the answer is, "yes." If you share a long-lived entangled state of $n$ bits with that other person, there is a technique called superdense coding which allows you to extract $2n$ bits from the combination of your pre-entangled bits and the $n$ bits in front of you.
However it is not too hard to see that this gives us no real advantage to storage as it still requires one qubit per bit total -- it's just that you can "store" $2n$ bits in a register of $n$ qubits if you happen to have $n$ qubits somewhere else in your quantum computer.
There's a few things being mixed here. Quantum computing is a form of computation/processing and it involves itself with transmitting, relaying, or decrypting information. The information should exist independently for a quantum computer to work with. Superpositions and entanglements allow one to perform tasks using data. Data storage would be unaffected by these quantum processes.
Edit: Elaboration There are people working on quantum memory however. This involves using quantum mechanical processes to store and retrieve stored information, but this is still being worked on. From the aforementioned group:
"A quantum memory is an interface between light and matter that allows
for the storage and retrieval of photonic quantum information, analogous
to the memory in a normal computer"
Hope that clarifies things.
It can handle a number of information at once. This method of data processing might be advantage.
• Actually I think this does marginally count as an answer to the question - basically I don't think it qualifies for deletion on that basis. – David Z Sep 22 '17 at 18:19
## protected by Qmechanic♦Sep 22 '17 at 19:33
Thank you for your interest in this question. Because it has attracted low-quality or spam answers that had to be removed, posting an answer now requires 10 reputation on this site (the association bonus does not count).
|
2019-05-21 18:47:24
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.48240232467651367, "perplexity": 647.0451547314901}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232256546.11/warc/CC-MAIN-20190521182616-20190521204616-00387.warc.gz"}
|
https://www.gradesaver.com/textbooks/math/algebra/elementary-and-intermediate-algebra-concepts-and-applications-6th-edition/chapter-14-sequences-series-and-the-binomial-theorem-14-1-sequences-and-series-14-1-exercise-set-page-894/12
|
## Elementary and Intermediate Algebra: Concepts & Applications (6th Edition)
The given expression is the sum of the first three elements of a sequence, which can be also written as: $a_1+a_2+a_3=S_3$ The answer is e)
|
2018-06-18 13:59:02
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5209597945213318, "perplexity": 416.89119019000833}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-26/segments/1529267860557.7/warc/CC-MAIN-20180618125242-20180618145242-00067.warc.gz"}
|
http://mathhelpforum.com/calculus/214445-max-min-print.html
|
# max/min
• Mar 8th 2013, 12:07 PM
apatite
max/min
there is one critical point for z=yx^5 + xy^5 + xy. Find it.
Is the critical point (0,0)?
• Mar 8th 2013, 12:25 PM
Shakarri
Re: max/min
There is a critical point when dz/dy and when dz/dx are equal to zero
dz/dx= 5yx5y-1+ y5+ y
This is zero at (0,0)
dz/dx= x5ylnx5+ 5xy4+ x
This is not defined at (0,0) because ln0 is not defined.
I do not know how to find the critical point but (0,0) is not it
• Mar 8th 2013, 02:10 PM
apatite
Re: max/min
.....
• Mar 8th 2013, 02:15 PM
apatite
Re: max/min
Quote:
Originally Posted by Shakarri
There is a critical point when dz/dy and when dz/dx are equal to zero
dz/dx= 5yx5y-1+ y5+ y
This is zero at (0,0)
dz/dx= x5ylnx5+ 5xy4+ x
This is not defined at (0,0) because ln0 is not defined.
I do not know how to find the critical point but (0,0) is not it
Sorry, its yx^5 not x^5y
• Mar 8th 2013, 02:29 PM
HallsofIvy
Re: max/min
Okay, so what are $\partial z/\partial x$ and $\partial z/\partial y$? Where are they both equal to 0?
By the way, in response to Shakarri's comment, a critical point is where the derivative is 0 or where the derivative does not exist.
• Mar 8th 2013, 02:57 PM
apatite
Re: max/min
Quote:
Originally Posted by HallsofIvy
Okay, so what are $\partial z/\partial x$ and $\partial z/\partial y$? Where are they both equal to 0?
By the way, in response to Shakarri's comment, a critical point is where the derivative is 0 or where the derivative does not exist.
fx(x,y)= 5yx^4+y^%+y
fy(x,y)= x^5+5xy^4+x
so x=0 and y=0?
|
2017-03-01 20:25:50
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 4, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9243900179862976, "perplexity": 3477.4284316833377}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-09/segments/1487501174276.22/warc/CC-MAIN-20170219104614-00553-ip-10-171-10-108.ec2.internal.warc.gz"}
|
https://cs.stackexchange.com/questions/110550/proving-np-completeness-of-maximal-length-path/110646
|
# Proving NP completeness of maximal length path
I have this question to answer:
For each node i in an undirected network $$G = (N,E)$$, let $$N(i) = \{j \in N : \{i, j\} \in E\}$$ denote the set of neighbors of node $$i$$ and let $$c_e\geq0$$ denote the length of edge $$e \in E$$. For each node $$i \in N$$, suppose the set $$N(i)$$ is partitioned into two subsets, $$N^+(i)$$ and $$N^-(i)$$ such that $$j \in N^+(i)(j \in N^-(i))$$ is referred to as a positive (negative) neighbor of $$i$$. (Note: Regardless of whether $$j$$ is a positive or negative neighbor of $$i$$, $$i$$ can be either a positive or negative neighbor of j.) Consider the problem of finding a maximum-length path $$(s =) i(0)–i(1)–···–i(h)(= t)$$ in $$G$$ between two nodes $$s ∈ N$$ and $$t ∈ N$$ subject to the following restriction: For each internal node $$i(k)(k \in\{1,...,h − 1\})$$ on the path, the set $$\{i(k − 1),i(k + 1)\}$$ must contain exactly one positive neighbor and one negative neighbor of $$i(k)$$. Prove NP-completeness of the decision problem and state whether it strongly NP-complete or not.
I wonder about the steps of the proof and whether shall I start from the longest path problem or from another problem instance.
• Can you be more precise about what a "positive" or a "negative" neighbor is? – Panzerkroete Jun 12 '19 at 3:59
• It is just a partition (or labeling) in order to satisfy the given constraint where each internal node has two different labeled nodes before and after in the path. – Bassem Jun 12 '19 at 13:23
• I am still confused. 1. you say, you have a "network". What do you mean by that? A network data structure (used in the maximum flow problem )or just a undirected weighted graph $G$ which should model a network ? 2. Why do you want to consider $N^+$ and $N^-$? Let $\pi=(v_0,v_1,...v_n)$ be a path. Then by definition each $v_i, 0<i<n$ has exactly one positive/negative neighbor ($v_{i-1}, v_{i+1}$). So why $N^+$ and $N^-$? 3: Can your graph further contain cyles and is your graph connected? – Panzerkroete Jun 13 '19 at 13:02
• For the first point, I mean an undirected weighted graph 𝐺 representing a network. For the second point, not necessarily since the partition of neighbors happens before we construct a path .. so for example if a node $i$ has only two neighbors which are both + and $N^{-}(i)$ is empty .. then this node cannot be on the longest path since it violates the constraint. – Bassem Jun 13 '19 at 13:32
• I have no information on whether the network contains cycles but let's assume it is connected. – Bassem Jun 13 '19 at 13:33
I think here is a pitfall due to inaccurate notation. Notation for me:
1. A trail is a sequence of distinct connected edges.
2. A path is a trail with distinct vertices.
In the problem instance $$MNPL$$ (maximum neighbor path length) the sets $$(G,N^+, N^-)$$ and the weight function $$c_e$$ are given as input(and hereby fixed). Since $$N$$ is partitioned, for two vertices $$u,v$$ either $$\{u,v\}\notin E$$ or $$u$$ is a positive neighbor of $$v$$ or vice-versa. Especially $$u$$ and $$v$$ cannot be a positive neighbor of each other by definition ($$N$$ would not be partitioned). Hence $$G$$ must be a directed graph. Now, for any path $$s \rightsquigarrow (u,v,w) \rightsquigarrow t$$(not way nor cycle nor walk!) the neighbor-condition is fullfilled.
Maybe this was the real challenge of this exercise?
So, claim: $$MNPL$$ is $$NP$$-complete.
Proof: $$MNPL \leq_p LPP$$ (longest path problem) Consider the reduction $$f$$. For $$(G,N^+,N^-,c_e)$$ construct $$G'=(V',E',c_e')$$ as the following:
1. $$c_e'$$ = $$c_e$$
2. $$V' = V$$
3. $$E' = \bigcup_{v \in N^+(u), u \in N} (u,v) \cup \bigcup_{u \in N^-(v), v \in N} (v,u)$$
Clear: $$f$$ is computable and runs in poly-time ($$O(|E|)$$). By construction and with the observations above $$f$$ will construct a digraph from $$N$$ and the neighbor sets.
So $$f$$ is a reduction and $$MNPL \in NP$$ is obvious using "guess and check". Since $$LPP$$ is strongly $$NP$$-complete, $$MNPL$$ is as well strongly $$NP$$-complete. This is no decision problem but a maximization problem.
• Your idea looks clear to me .. but to prove a problem is NP-complete aren't we supposed to reduce an NP-complete problem to our problem? – Bassem Jun 13 '19 at 19:34
• I do not provide a reduction here because I think, that problem is $NP$-complete because you restrictions on the neighbors are to strict. For example, given the complete graph $K_5$ (look here for its appearence)where all edges have weight one. Here, the longest path would be obvious contain all five vertices (no matter which vertix is $s$ or $t$). However for any $s-u-v-w-t$ path $N^+(v)=N^-(v)=\{s,u,w,t\} \neq \{u,w\}$. Hence your neighbor condition is not fulfilled. By that, I cannot reduce to the $HamiltonianPath$ -problem – Panzerkroete Jun 13 '19 at 22:38
• This is because a hamiltonian path in for example $G=K_5$ is not a valid longest path in your network graph $G'$. The standard polynomial reduction ($G'$ with $n$ vertices has longest path with length $n-1$ iff. $G$ has a hamiltonian path ) does not work here.The implication Hpath to longest path is not true. So, there is no reduction to any known $NP$-hard problem (at least I could not find one) and so $MNPL$ is not NP-complete. Either your definiton of neighbor is somehow wrong or the problem is really in $P$. Do you have this exercise somewhere and can link the source? – Panzerkroete Jun 13 '19 at 22:47
• I have no source for it .. it was provided by a professor as an exercise to prove NP completeness. I was thinking that either Hamiltonian path or TSP problems could be the problems to use for the proof and then I was thinking about constrained shortest path problem but I still couldn't find clear reduction proof. – Bassem Jun 14 '19 at 0:58
• @Bassem I added the core argument for reduction to the longest path problem for directed graphs. At a few points a bit more argumentation is needed (like why is the neighbor condition fulfilled by a directed graph, why is $f(w) \in LPP => w \in MNPL$?, why is $MNPL \in NP$?). Give me feedback if you have doubts – Panzerkroete Jun 14 '19 at 1:14
|
2020-08-11 09:49:47
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 54, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8593345880508423, "perplexity": 318.43544111107025}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-34/segments/1596439738746.41/warc/CC-MAIN-20200811090050-20200811120050-00247.warc.gz"}
|
https://szymonkrajewski.pl/find-reference-to-note-using-alfred/
|
# Find and insert reference to note on macOS using Alfred
Create connections between notes is the essential part of the whole note-taking process, and for sure, it leads to discovering outstanding ideas in the future. However, it requires extra effort during writing: you have to find a proper note, copy the reference and paste it to the original memo. Some software has a built-in feature to handle it, but when it comes to plaintext notes, the implementation depends on the user.
In this article, I’ll show you how to create Alfred workflow that automates the process of finding and inserting a reference to other notes.
First of all, you need to have macOS and app called Alfred. I mentioned Alfred before in my article about running notes. It’s one of the most useful application on my computer.
## Why it’s worth to connect notes?
Notes are rarely independent. Like neurons in our brains, they are more powerful if they contain connections to other notes. We can put the reference to different note when we feel, that the particular piece of information is related to another one. For sure, sooner or later, you’ll need a way to create connections between notes.
## How to create a reference?
Notes should be long-lasting – that’s why I use plaintext to take them. The most common practice, in this case, is to use a wiki-style syntax to link from one note to another one. Most software, like nvALTFSNotes or The Archive can parse this tag to create a link to the referenced note. Regardless of how old-school this method is, it’s resistant to time and doesn’t lock you in the specific service or note-taking software.
The reference itself is related to your naming convention. I put a unique DateTime marker as an ID to the name of my note. Thanks to it, I can create a reference using either full name or only ID – whatever is more convenient at the moment.
So to create a reference from one note to another one, I put the id of the referred memo in double-square brackets somewhere in the text of the first one. Here’s an example:
The biggest problem is to find the ID of the note I want to refer to. Without a dedicated feature, you need to change the context of your work, find the proper note, copy the ID and finally insert it into the original note. Let’s Alfred does this work.
## Alfred workflow to find and insert reference to note
I created an Alfred workflow to simulate autocompletion of the note reference. You can set your directory for notes, so Alfred will limit the results. Whole workflow looks like below.
The workflow is triggered by a snippet. I use the snippet instead of keyword or hotkey to be able to pass configuration to File Filter and to avoid remembering the next hotkey. Moreover, during working with notes, it’s more natural to write directly in the editor, so the snippet looks like the best option here.
To activate the workflow, type following keys sequence: \[[. It’s easy to memorize because it looks like the beginning of wiki-style link preceded by a slash, which usually means command in some other software.
The workflow looks for matched markdown files in the pre-configured directory. When you find the note you want to refer to, press Enter to replace snippet with the wiki-style reference. If you’re going to insert the full name of note instead, hold cmd and press Enter.
Before you start, make sure you set the path to your notes directory in environment variables.
## Summary
I hope you’ll find value in this article. There’s no first time when I take advantage of Alfred to make my work easier. Properly configured and customized, it could be a good partner in your work.
The important takeaway is: you don’t need to use an all-in-one, huge application with tons of features that lock you in its ecosystem. If you can do something manually, you can also automate it on your own! This article responds partially to the post written by Christian on Zettelkasten.de.
The workflow is available in my GitHub’s repository. You can download it from here.
|
2020-02-18 02:03:21
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.33104097843170166, "perplexity": 1098.8427710977985}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-10/segments/1581875143455.25/warc/CC-MAIN-20200217235417-20200218025417-00427.warc.gz"}
|
https://www.freemathhelp.com/forum/threads/function-domain.118968/
|
# Function, domain
#### topsquark
##### Full Member
$$\displaystyle y=-\sqrt{x}$$ is not a function on the set of real numbers.
I feel like we're being unnecessarily picky here. There is no subset of the real numbers where the vertical line test actually fails in this example. A function is still a function on the real numbers even if there are subsets of real numbers that the function cannot be evaluated at. For example, f(x) = 1/x is considered to be a function on the set of real numbers, even if it cannot be evaluated at x = 0. Right? At least I've never run into anyone who has said that 1/x is not a function over the reals.
-Dan
#### pka
##### Elite Member
I feel like we're being unnecessarily picky here. There is no subset of the real numbers where the vertical line test actually fails in this example. A function is still a function on the real numbers even if there are subsets of real numbers that the function cannot be evaluated at. For example, f(x) = 1/x is considered to be a function on the set of real numbers, even if it cannot be evaluated at x = 0. Right? At least I've never run into anyone who has said that 1/x is not a function over the reals.
Oh my Lord Dan. Are you now part of the ill-prepared mathematics-education community? Gee, I hope not.
Please read my reply #16. Not knowing the exact definitions does sink many students of national tests.
Please note that I am not blaming the students in all cases, but it is the fault of the MathEd community.
People like me work of the testing companies. We expect correct application of fundamental concepts such function.
#### Dr.Peterson
##### Elite Member
It's true that the full definition of a function includes its domain and codomain. But at this level, the emphasis is on having one value for any (valid) input; beginning students have enough trouble understanding that central concept, without getting tangled up in less essential details.
In this case, the question didn't ask about being a function over the reals! We can interpret it, "Is this a function [over some domain that is a subset of the reals]", and the answer there is simple: yes! Bringing in issues of domain at this point doesn't help the student. There is time later in the course (or a subsequent course) to formalize everything.
An "incomplete" question is not "absolutely meaningless". It's just inadequate for an upper-level math course, which this isn't.
#### topsquark
##### Full Member
Oh my Lord Dan. Are you now part of the ill-prepared mathematics-education community?
I did read post #16. Apparently I missed something. (I still am, I think.)
Hey! I'm being a Physicist over here! I have been thinking about it overnight and I think that it is true that the domain of 1/x, not being the whole of the real numbers, should not be refered to as "over the reals." But I still don't recall anyone actually telling me that this doesn't make it a "function." (Then again we don't talk much about domains and ranges in Physics, either.)
Thanks for the correction!
-Dan
|
2019-11-14 19:21:15
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6218956112861633, "perplexity": 516.7661156510602}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-47/segments/1573496668534.60/warc/CC-MAIN-20191114182304-20191114210304-00099.warc.gz"}
|
https://learn.careers360.com/ncert/question-simplify-each-of-the-following-expressions-iv-square-root-5-minus-square-root-2-multiply-square-root-5-plus-square-root-2/
|
Q
# Simplify each of the following expressions: (iv)
2. Simplify each of the following expressions:
(iv) $\left (\sqrt{5}-\sqrt{2} \right )\left ( \sqrt{5}+\sqrt{2} \right )$
Views
Given number is $\left (\sqrt{5}-\sqrt{2} \right )\left ( \sqrt{5}+\sqrt{2} \right )$
Now, we will reduce it into
$\Rightarrow \left (\sqrt{5}-\sqrt{2} \right )\left ( \sqrt{5}+\sqrt{2} \right )= \left ( (\sqrt{5})^2-(\sqrt{2})^2 \right )$ $\left ( using \ (a+b)(a-b)=a^2-b^2\right )$
$=5-2$
$=3$
|
2020-01-27 13:32:54
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 6, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9460282921791077, "perplexity": 8315.551154398505}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-05/segments/1579251700675.78/warc/CC-MAIN-20200127112805-20200127142805-00461.warc.gz"}
|
https://cstheory.stackexchange.com/questions/3806/partially-ordered-cfg
|
# Partially Ordered CFG
I'm looking for work about partially ordered context-free grammars. I've found one paper, which seems to simplify the problem too much (in addition to some technical mistakes, as far as I can tell). It defines the language of a pom-CFG by reduction to a normal context-free grammar, which excludes some (otherwise) possible words from the language, I think.
Thus I'm looking for other work.
What I mean by partially ordered CFG
The production rules don't produce linear strings of symbols but partially ordered (multi) sets of symbols. Thus the "words" of the generated language are also partially ordered multi-sets of symbols. For example this:
b-c
/ \
a d-a
\ /
a--
The possible linearizations of this partially ordered word are aabcda, abacda, abcada.
|
2021-07-24 10:55:04
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.719017744064331, "perplexity": 1689.5184686962423}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046150264.90/warc/CC-MAIN-20210724094631-20210724124631-00125.warc.gz"}
|
https://aptitude.gateoverflow.in/5761/cat-2017-set-1-question-93
|
181 views
If $f_{1}\left ( x \right )=x^{2}+11x+n$ and $f_{2}\left ( x \right )=x$, then the largest positive integer $n$ for which the equation $f_{1}\left ( x \right )=f_{2}\left ( x \right )$ has two distinct real roots, is
1. $24$
2. $23$
3. $19$
4. $10$
Given that,
• $f_{1}(x) = x^{2} + 11x + n$
• $f_{2}(x) = x$
And $f_{1}(x) = f_{2}(x)$
$\Rightarrow x^{2} + 11x + n = x$
$\Rightarrow x^{2} + 10x + n = 0$
If the equation has two distinct real roots, then
$b^{2}-4ac> 0$
$\Rightarrow 10^{2}-4(1)(n)> 0$
$\Rightarrow 100-4n> 0$
$\Rightarrow 100>4n$
$\Rightarrow 4n<100$
$\Rightarrow n<\frac{100}{4}$
$\Rightarrow n<25$
$\Rightarrow\boxed{n_{\text{max}} = 24}$
$\therefore$ The largest positive integer value of $n$ is $24.$
Correct Answer $:\text{A}$
10.3k points
1
211 views
|
2022-12-06 14:36:27
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6511809229850769, "perplexity": 2082.9646707038605}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-49/segments/1669446711108.34/warc/CC-MAIN-20221206124909-20221206154909-00297.warc.gz"}
|
https://or.stackexchange.com/questions/5903/excluding-non-preferable-solutions-from-a-milp
|
Excluding non-preferable solutions from a MILP
I have a model which delivers the following results (other combinations are also possible, all Xs have 50 as an upper bound):
Case I
$$X1 = 50.0$$
$$X2 = 13.750$$
$$X3 = 50.0$$
$$X4 = 50.0$$
Case II (obtained adding valid constraints to the model)
$$X1 = 50.0$$
$$X2 = 47.50$$
$$X3 = 50.0$$
$$X4 = 16.25$$
Both results lead to the same value of the objective function. Both solutions are optimal.
The variables express how a certain resource j is loaded in time.
Is it possible to model that the resource is loaded with maximum possible amount in earlier times, whenever possible?
So here, I would like that Case II is prefered over Case I. Case I should be declared infeasible.
EDIT
I think we could reach the goal by introducing penalties in the objective function as follows:
$$\max f(X_1,X_2,X_3,X_4) - \delta_1 (50-X_1) - \delta_2 (50-X_2) - \delta_3 (50-X_3) - \delta_4 (50-X_4)$$
Now the question is, what is a good choice for the $$\delta$$s so that the optimal value for $$f(X_1,X_2,X_3,X_4)$$ is the same when optimising with and without the penalties.
We know that we should not use the same value for the penalties, but when are they too high, meaning, that they alter the value of $$f(X_1,X_2,X_3,X_4)$$ of the optimum when optimising without the penalties?
• Do you prefer $X_4 \leq X_3 \leq X_2 \leq X_1$ in the optimal solution? – Oguz Toragay Mar 11 at 13:41
• Hi Oguz! What you propose is not going to work because this setting is, in general, not necessarily going to be feasible (actually here it is feasible but non-optimal). I would like to get that solution, that allows the earlier loads to attain their highest possible value; that solution should also be optimal. In other words, I seek that solution among a set of optimal solutions, that satisfies the requirement as I expressed it. It think I can express it 'more mathematically' like this: $X1 \le X2$ if possible & $X2 \le X3$ if possible & $X3 \le X4$ if possible. – Clement Mar 11 at 14:03
• This could be done in several steps: First optimize without additional restrictions to find the optimal objective value. Then add a constraint that fixes the objective value. After that maximize X1. Then fix it to the optimal and maximize X2. Repeat. – Daniel Junglas Mar 11 at 14:09
• Maybe adding those conditions with appropriate coefficients to the objective function can be another slution. – Oguz Toragay Mar 11 at 14:11
• @Oguz Toragay Yes, penalizing the possible solutions would help, but I can't figure out how to do it. – Clement Mar 11 at 16:02
|
2021-06-15 15:49:10
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 12, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7517812848091125, "perplexity": 596.5827440058932}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-25/segments/1623487621450.29/warc/CC-MAIN-20210615145601-20210615175601-00393.warc.gz"}
|
https://www.hepdata.net/record/ins1753720
|
• Browse all
Measurement of the $\mathrm{t\bar{t}}\mathrm{b\bar{b}}$ production cross section in the all-jet final state in pp collisions at $\sqrt{s} =$ 13 TeV
The collaboration
Phys.Lett. B803 (2020) 135285, 2020
Abstract (data abstract)
CERN-LHC. Measurement of the ttbb production cross section in the all-jet final state in proton-proton collisions at centre-of-mass energy of 13 TeV with 35.9 fb^-1 of data collected in 2016. The final state used is 8 jets. Three different phase space regions are used for the measurement The Parton independent (PI) phase space: - 8 or more jets - 4 or more bjets - leading 6 jets with ptJet > 30 GeV - ptJet > 20 GeV - |etaJet| < 2.4 The Parton based (PB) phase space: - 8 or more jets - 4 or more bjets - leading 6 jets with ptJet > 30 GeV - ptJet > 20 GeV - |etaJet| < 2.4 - 2 or more bjets not matched to a top decay object The total phase space: - 2 or more bjets not matched to a top decay object - not matched bjets ptJet > 20 GeV - not matched bjets |etaJet| < 2.4
• #### Table 2
Data from Page 11 of preprint
10.17182/hepdata.91630.v1/t1
The measured cross sections. The first uncertainty is statistical, the second uncertianty is the systematic.
|
2020-04-08 11:56:37
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8911570906639099, "perplexity": 3857.9071621330363}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-16/segments/1585371813538.73/warc/CC-MAIN-20200408104113-20200408134613-00039.warc.gz"}
|
https://athhallcamreview.com/discontinuous-normals-in-non-euclidean-geometries-and-two-dimensional-gravity-arxiv2208-02658v2-gr-qc-updated/
|
##### What's Hot
This paper builds two detailed examples of generalized normal in
non-Euclidean spaces, i.e. the hyperbolic and elliptic geometries. In the
hyperbolic plane we define a n-sided hyperbolic polygon P, which is the
Euclidean closure of the hyperbolic plane H, bounded by n hyperbolic geodesic
segments. The polygon P is built by considering the unique geodesic that
connects the n+2 vertices (tilde z),z0,z1,…,z(n-1),z(n). The geodesics that
link the vertices are Euclidean semicircles centred on the real axis. The
vector normal to the geodesic linking two consecutive vertices is evaluated and
turns out to be discontinuous. Within the framework of elliptic geometry, we
solve the geodesic equation and construct a geodesic triangle. Also in this
case, we obtain a discontinuous normal vector field. Last, the possible
application to two-dimensional Euclidean quantum gravity is outlined.
Share.
|
2023-03-31 19:43:07
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8051649332046509, "perplexity": 1585.316271429071}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-14/segments/1679296949678.39/warc/CC-MAIN-20230331175950-20230331205950-00756.warc.gz"}
|
https://www.yaclass.in/p/mathematics-state-board/class-9/algebra-3105/simultaneous-linear-equations-5229/re-3ba11400-fdd2-42bc-978e-4ad8acda12fc
|
Theory:
What are simultaneous linear equations?
A set of equations with two or more linear equations having the same variables is called as simultaneous linear equations or system of linear equations or a pair of linear equations.
$$2x+y=1$$ and $$x-y=3$$
Together they are called as simultaneous linear equations.
Example:
Jane bought $$2$$ apples and $$1$$ banana for a total cost of $$8$$. Let us frame an equation to find the individual cost of an apple and a banana.
Let us understand the purpose of simultaneous linear equations with a real life situation.
Let $$x$$ denote the cost of an apple and $$y$$ denote the cost of a banana.
Writing in equation, she has:
$$2x+y=8$$ ---- $$(1)$$
Jane tries to find the value of each apple and banana by substituting the values for $$x$$.
When $$x=1$$, $$2(1)+y=8$$$$\Rightarrow y=8-2$$$$\Rightarrow y=6$$
When $$x=2$$, $$2(2)+y=8$$$$\Rightarrow y=8-4$$$$\Rightarrow y=4$$
When $$x=3$$, $$2(3)+y=8$$$$\Rightarrow y=8-6$$$$\Rightarrow y=2$$
When $$x=4$$, $$2(4)+y=8$$$$\Rightarrow y=8-8$$$$\Rightarrow y=0$$
Now, writing these values in the table, we have:
$$x$$ $$1$$ $$2$$ $$3$$ $$4$$ …. $$y$$ $$6$$ $$4$$ $$2$$ $$0$$ ….
Jane plots these points in the graph and draws a line joining these points.
Thus, she gets many number of solutions. Since she is insufficient with the apples and bananas, she again went to the shop and brought $$1$$ apple and $$2$$ bananas for a total cost of $$₹10$$.
Writing in equation, she has:
$$x+2y=10$$ ---- $$(2)$$
Again, she tries to find each apple and banana's value by substituting the values for $$x$$.
When $$x=1$$, $$1+2y=10$$$$\Rightarrow 2y=10-1=9$$$$\Rightarrow y=\frac{9}{2}=4.5$$
When $$x=2$$, $$2+2y=10$$$$\Rightarrow 2y=10-2=8$$$$\Rightarrow y=\frac{8}{2}=4$$
When $$x=3$$, $$3+2y=10$$$$\Rightarrow 2y=10-3=7$$$$\Rightarrow y=\frac{7}{2}=3.5$$
When $$x=4$$, $$4+2y=10$$$$\Rightarrow 2y=10-4=6$$$$\Rightarrow y=\frac{6}{2}=3$$
Now, writing these values in the table, we have:
$$x$$ $$1$$ $$2$$ $$3$$ $$4$$ …. $$y$$ $$4.5$$ $$4$$ $$3.5$$ $$3$$ ….
Jane plots these points in the graph and draws a line joining these points.
In the graph, she found that the two lines intersect at the point $$(2,4)$$.
Hence, Jane came to a conclusion that if we solve two equations together, we get an unique solution.
By solving equations $$(1)$$ and $$(2)$$, Jane gets the cost of an apple as $$2$$ and the cost of a banana as $$4$$.
These two equations are called as simultaneous linear equations.
Important!
A solution to the simultaneous linear equation can be found in many ways. They are:
1. Graphical method
2. Substitution method
3. Elimination method
4. Cross multiplication method
|
2021-05-10 08:53:12
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6345729827880859, "perplexity": 512.6713470968355}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-21/segments/1620243989115.2/warc/CC-MAIN-20210510064318-20210510094318-00079.warc.gz"}
|
https://discourse.pymc.io/t/gaussian-process-predict-over-trace/1859
|
# Gaussian Process predict over trace
#1
Hi everyone,
I’d like to integrate a function, a, of the predicted mean (μ(x)) and standard deviation (σ(x)) over the inferred model parameters in a Gaussian Process model in PyMC3.
If θ are the collected parameters of the GP model (e.g. noise, length scales etc. of the covariance function) then I want:
a(μ(x),σ(x))=∫dθa(μ(x),σ(x);θ)
My model is specified and conditioned like this:
with pm.Model() as model:
l = pm.Gamma("l", alpha=2, beta=1)
eta = pm.HalfCauchy("eta", beta=5)
cov = eta**2 * pm.gp.cov.Matern52(1, l)
gp = pm.gp.Marginal(cov_func=cov)
sigma = pm.HalfCauchy("sigma", beta=5)
y_ = gp.marginal_likelihood("y", X=x, y=y, noise=sigma)
trace = pm.sample(1000)
I can predict a mean and standard devation over a single point in the trace:
mu, var = gp.predict(X=Xnew, point=trace[42])
and then calculate my function:
a = my_func(mu, var)
To average over the trace I’m doing this:
for i in range(len(trace)):
mu, var = gp.predict(X=Xnew, point=trace[i])
a[:, i] = my_func(mu, var)
integrated_a = a.mean(axis=1)
But it’s very, very slow. Is there a neat / faster way of doing this? A general strategy would be really helpful. I’m not an expert in Theano but willing to learn.
#2
To do exactly this, no it’s not possible, primarily because theano doesn’t seem to support a cholesky decompositon over n-dimensional arrays, so that the covariance matrices can be stacked. To integrate out \theta, can you use sample_ppc?
#3
Thanks for your reply. I thought of using sample_ppc, something like:
with model_sample:
f = gp.conditional('f', Xnew)
pred_samples = pm.sample_ppc(trace, vars=[mean(f), diag_cov(f)], samples=2000)
where mean(f) and diag_cov(f) would be the mean vector and diagonal of the covariance matrix of the random variable f. I just don’t know how to properly specify mean(f) and diag_cov(f).
EDIT: OK, I guess what you’re saying applies here too, so you can’t put something like diag_cov(f) into sample_ppc. Damn.
|
2018-09-24 00:54:15
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8381549715995789, "perplexity": 4180.229872470421}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-39/segments/1537267159938.71/warc/CC-MAIN-20180923232129-20180924012529-00404.warc.gz"}
|
http://dylan-muir.com/articles/circular_kernel_estimation/
|
# Kernel density estimation for circular functions
28th March, 2014
Matlab code for performing kernel density estimates on periodic and aperiodic domains, for unidimensional and multidimensional data.
Estimating multi-dimensional PDFs over periodic domains is reasonably straightforward, but can't be done with Matlab's built-in tools. Here are two functions for kernel density estimates for circular functions. By default they will estimate a PDF over the periodic domain, and can be used with weighted and unweighted data.
Unzip the file into a directory on the matlab path. Two functions are included: circ_ksdensity and circ_ksdensityn.
# Uni-dimensional kernel density estimates — circ_ksdensity
Usage:
[vfEstimate] = circ_ksdensity(vfObservations, vfPDFSamples, <vfDomain, fSigma, vfWeights>)
This function calculates a kernel density estimate of an (optionally weighted) data sample, over a periodic domain.
vfObservations is a set of observations made over a periodic domain, optionally defined by vfDomain: [fMin fMax]. The default domain is [0..2*pi]. vfPDFSamples defines the sample points over which to perform the kernel density estimate, over the same domain as vfObservations.
Weighted estimations can be performed by providing the optional argument vfWeights, where each element in vfWeights corresponds to the matching element in vfObservations.
The kernel density estimate will be performed using a wrapped Gaussian kernel, with a width estimated as
(4/3)^0.2 * circ_std(vfObservations, vfWeights) *(length(vfObservations^-0.2)
The optional argument fSigma can be provided to set the width of the kernel.
vfEstimate will be a vector with a (weighted) estimate of the underlying distribution, with an entry for each element of vfPDFSamples. If no weighting is supplied, the estimate will be scaled such that it forms a PDF estimate over the supplied sample domain, taking into account sample bin widths. If a weight vector is supplied then the estimate will be scaled such that the sum over the domain attempts to match the sum of weights, taking into account sample bin widths.
# Multi-dimensional kernel density estimates — circ_ksdensityn
Usage:
[vfEstimate, vfBinVol] = circ_ksdensityn(mfObservations, mfPDFSamples, <mfDomains, vfSigmas, vfWeights>)
This function calculates a kernel density estimate of an (optionally weighted) data sample, over periodic and aperiodic domains. The sample is assumed to be independent across dimensions; i.e. density estimation is performed independently for each dimension of the data.
mfObservations is a set of observations made over a (possibly periodic) domain. Each row corresponds to a single observation, each column corresponds to a particular dimension. By default all dimensions are periodic in [0..2*pi]; this can be modified by providing the optional argument mfDomains. Each row in mfDomains is [fMin fMax], one row for each dimension in mfObservations. If a particular dimension should not be periodic, the corresponding row should be [nan nan]. Bounded support over a dimension is NOT implemented; each dimension is either linear and infinite or periodic.
mfPDFSamples defines the sample points over which to perform the kernel density estimate, over the same domains as mfObservations.
Weighted estimations can be performed by providing the optional argument vfWeights, where each element in vfWeights corresponds to the matching observation in mfObservations.
The kernel density estimate will be performed using a multivariate Gaussian kernel, independent along each dimension, and wrapped along the periodic dimensions as appropriate. Kenel widths over periodic dimensions are estimated as
(4/3)^0.2 * circ_std(mfObservations(:, nDim), vfWeights) * (length(mfObservations)^-0.2)
Kernel widths over non-periodic dimensions are estimated as
(4 * std(mfObservations(:, nDim), vfWeights)^5 / 3 / length(mfObservations))^(1/5)
The optional argument vfSigmas can be provided to set the width of each kernel.
vfEstimate will be a vector with a (weighted) histogram estimate of the underlying distribution, with an entry for each point in mfPDFSamples. If no weighting is supplied, the estimate will be scaled to estimate a PDF over the supplied multi-dimensional domain, taking into account the estimated volume of each bin. If a weight vector is supplied, the estimate will be scaled such that the sum over the domain attempts to match the sum of weights, taking into account the multi-dimensional bin volumes.
vfBinVol is a vector containing volume estimates for each row in mfPDFSamples, under the assumption that each dimension is linearly scaled and mutually orthogonal.
|
2015-08-02 22:23:46
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8549758791923523, "perplexity": 1490.9158791247455}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-32/segments/1438042989301.17/warc/CC-MAIN-20150728002309-00119-ip-10-236-191-2.ec2.internal.warc.gz"}
|
https://nicklutsko.github.io/blog/2019/10/09/What-Drives-Transient-Warming-Uncertainty-Part-2
|
## What Drives Uncertainty in Transient Warming? Part 2 - Details
09 Oct 2019
This is a follow-up to my post "What Drives Uncertainty in Transient Warming?", which summarized a recent paper with Max Popp on "Probing the Sources of Uncertainty in Transient Warming on Different Time Scales". Here I’m going to provide some details on the analysis (A Jupyter notebook is also available here).
### Theory
To understand the sensitivities of transient warming we started by thinking about the two box model I introduced in part 1. This can be solved for $$T_1$$, either in real space or (more simply) by transforming to frequency space to give: $$\hat{T_1} = \frac{\omega}{70} \times \frac{F}{\lambda + ic\omega +\epsilon\gamma \left(1 - \gamma /(ic_0\omega + \gamma)\right)},$$ where $$\omega$$ is frequency and we assume CO$$_2$$ concentrations are going up by 1% per year. Looking at this expression gives a first sense for why the forcing matters so much: it’s the only term in the numerator, whereas there are several terms in the denominator. So, for example, even if the climate feedback ($$\lambda$$) was zero, and the ECS was infinite, the transient warming would still be finite.
We then calculated the absolute value of $$\hat{T_1}$$, which is a complicated expression, but can be simplified into four transient warming regimes (to make things more intuitive I'm going to move back to the time domain):
• the ultra-fast regime ($$t <\ t_H = c/(\lambda + \epsilon\gamma)$$ ),
• the fast regime ($$t_H <\ t <\ <\ t_L= c_0 /\gamma$$ ),
• the intermediate regime ($$t \leq t_L$$ ),
• the slow regime ($$t > t_L$$).
Using ensemble-mean values from CMIP5, the fast time-scale $$t_H \approx$$ 4 years and the slow time-scale $$t_L \approx$$ 160 years. The fast and intermediate regimes are separated by the time it takes for the deep ocean to warm up significantly – when $$T_2$$ is meaningfully greater than 0. Defining this as the time when $$t = 0.1 c_0 / \gamma$$ gives a time-scale of 16 years.
Going through the different regimes: In the ultra-fast regime most of the uncertainty comes from the upper-ocean heat capacity $$c$$. Basically, how quickly does the surface start warming up? If $$c$$ is large then the warming in the first few years will be small, whereas if $$c$$ is small then $$T_1$$ will warm up quickly.
In the fast regime the forcing is responsible for most of the uncertainty, with $$\lambda$$, $$\gamma$$ and $$\epsilon$$ also contributing. But because these are all in the denominator, their uncertainties partially cancel, and $$F$$ is the leading source of uncertainty. On these time-scales $$c$$ is small compared to $$λ + \epsilon \gamma$$, so we don’t have to worry about the upper ocean heat capacity anymore.
Once the deep ocean has started warming, the ocean heat uptake parameters $$\gamma$$ and $$\epsilon$$ contribute less to uncertainty. You can see in the denominator of the equation that the term in brackets starts decreasing as $$c_0 \omega$$ increases, and the effects of uncertainty in $$\gamma$$ and $$\epsilon$$ are muted. Physically, heat is transferred to the deep ocean through the term $$H = \epsilon\gamma(T_1 – T_2)$$. $$H$$ cools $$T_1$$, and so $$\gamma$$ and $$\epsilon$$ damp transient warming. But as the two layers come into equilibrium $$T_1 – T_2$$ becomes small, so $$H$$ is also small, and $$\gamma$$ and $$\epsilon$$ matter less. In equilibrium $$H$$ is zero, and it doens't matter what the values of $$\gamma$$ and $$\epsilon$$ are.
An interesting subtlety is that $$\gamma$$ cools the surface layer directly, but also warms it indirectly by making $$T_2$$ larger (and hence $$H$$ smaller). These opposing direct and indirect effects on surface temperature mean that $$\gamma$$ is responsible for less uncertainty than $$\epsilon$$, which always damps surface temperature. (Note: one of the original motivations for our study was trying to clarify how the ocean contributes to transient warming uncertainty.)
Finally on long time-scales the two layers are in equilibrium with each other and we’re basically left with the ECS expression $$F / \lambda$$, and the forcing and the feedback matter roughly equally.
So we can expect transient warming’s sensitivity to evolve as follows:
• for the first few years the upper ocean heat capacity matters most, but the importance of this quickly decreases,
• then the warming is most sensitive to the forcing, with the climate feedback and the ocean heat uptake terms ($$\gamma$$ and $$\epsilon$$) also contributing,
• once the deep ocean has started heating up the sensitivity to the ocean heat uptake terms decreases, with the importance of $$\gamma$$ decreasing faster than $$\epsilon$$.
Through these different stages, the importance of the feedback $$\lambda$$ relative to the forcing slowly increases, so that on the longest timescales transient warming is roughly as sensitive to $$\lambda$$ as to $$F$$.
### CMIP5 data
To quantify things with some data, we fit the two box model to 1%/year simulations with a set of CMIP5 models. This gave the relative uncertainties in panel a of the figure below, where "relative uncertainty" is the standard deviation of a variable across the ensemble divided by the mean of the variable. Again, $$\lambda$$ is about three times as uncertain as $$F$$, though the most uncertain variable is actually $$c_0$$.
To understand the contributions of each variable to uncertainty in the TCR, we then ran the two box model using the mean values of all the variables, except for one variable which we varied by $$\pm$$ 2 standard deviations. E.g., we ran the model with $$F$$, $$\lambda$$, $$c$$, $$c_0$$ and $$\gamma$$ set to their ensemble-mean values, but set $$\epsilon$$ to one standard deviation above its ensemble-mean, to -2$$\times$$ its standard deviation, etc. This gave the TCR estimates shown in the box-and-whisker plots of panel b. The largest spreads come when $$\lambda$$ is varied and then when $$F$$ is varied. $$\gamma$$ and $$\epsilon$$ are similar to each other, and the heat capacities are negligible.
But this mixes the two aspects of uncertainty: the uncertainty in each variable, and the TCR’s sensitivity to that uncertainty. Varying $$\lambda$$ produces the largest spread, but $$\lambda$$ is also one of the most uncertain parameters. So we re-did the calculations but set the relative uncertainties for all variables to $$\lambda$$’s relative uncertainty (about 30%). These calculations (panel c) showed that the TCR is about twice as sensitive to uncertainty in the forcing as to uncertainty in the feedback, and suggested that if the forcing was as uncertain as the feedback our best guess for the TCR would be $$\sim$$0.5-3.5$$^\circ$$C, instead of the actual range of 1-2.5$$^\circ$$C.
We looked at how transient warming's sensitivies evolve over time by calculating the ratio $$r$$ of the sensitivity of transient warming to uncertainty in each variable divided by the sensitivity of transient warming in the forcing $$F$$. So if $$r_\gamma > 1$$ at $$t =$$ 20 years, it means that the warming after 20 years of increasing CO$$_2$$ by 1%/year is more sensitive to uncertainty in $$\gamma$$ than to uncertainty in $$F$$. If $$r_\gamma <\ 1$$, then the warming is more sensitive to $$F$$ than to $$\gamma$$.
These calculations gave us exactly what we expected from the theory. Uncertainty in the upper ocean heat capacity matters a lot for the first few years, but quickly becomes negligible. The contributions of uncertainties in $$\gamma$$ and $$\epsilon$$ peak at around 20 years, then decrease as the deep ocean heats up, with the contribution from $$\gamma$$ decreasing faster than the contribution from $$\epsilon$$. And the feedback $$\lambda$$ becoming more important over time (though even after 140 years $$r_F$$ is only $$\sim$$0.7).
### Toy Calculations
As mentioned in the previous post, Max and I discussed two implications of these results: (1) it’s dangerous to extrapolate from short-lived climate perturbations, like volcanic eruptions, to long-lived perturbations like CO$$_2$$ increases, and (2) the feedbacks of models that are ‘tuned’ in some way to the historical record are strongly affected by historical forcing estimates.
We illustrated these implications with some toy calculations. First, we calculated the impulse response of the two-box model to a doubling of CO$$_2$$. That is, we set $$F$$ to $$F_{2XCO2}$$ at year 1, and 0 at all other times. We did this calculation three times: once with the ensemble-mean parameters from the CMIP5 data, once with the upper ocean heat capacity $$c$$ reduced by 25% and once with $$\lambda$$ reduced by 25%. In the results (panel a) you can see that changing the heat capacity has a much larger effect on the response of the upper layer than changing $$\lambda$$ – we’re in the ultra-fast regime – , with changing $$\lambda$$ producing a pretty similar response to the "control" simulation. So if we were trying to fit the temperature response to a short-lived perturbation, like a volcanic eruption, we’d mostly be fitting the upper ocean heat capacity (and the volcanic forcing), and we wouldn't have to worry much about getting $$\lambda$$ right.
Our second toy calculation showed how the climate feedback of “tuned” models is strongly influenced by historical forcing estimates. We illustrated this through “historical” simulations of the 20th century with the two-box model, forcing it with an estimate of the total radiative forcing over the 20th century, $$\Delta F$$ (panel b). We then varied the forcing by up to $$\pm$$1 standard deviation of $$F_{2XCO2}$$ by setting $$\Delta F(t) = \Delta F(t) + \beta std(F_{2XCO2})$$, with $$\beta$$ varied from -1 to 1 in increments of 0.1. With this, we were trying to imitate how uncertainty in $$F_{2XCO2}$$ would affect the estimated historical forcing.
For each forcing estimate, we set $$c$$, $$c_0$$, $$\lambda$$ and $$\gamma$$ to their ensemble-mean values and then searched for the value of $$\lambda$$ that gave the best fit to the 20th temperature record. Panel c shows how the optimal value of $$\lambda$$ varies as a function of the final forcing at the end of the 20th century (circles), with a linear least-squares regression giving that a 1% change in the net forcing results in a 1.84% change in the optimal value of $$\lambda$$.
This calculation ignores things like the different forcing efficacies of greenhouse gases, the historical aerosol forcing and internal variability, but shows how sensitive the climate feedback in models that are tuned by fitting to the historical temperature record is to assumptions about the forcing over the 20th century. If you believe our toy calculations, then tuning the same model twice using historical forcing estimates that differed by 20% would give values of $$\lambda$$ that differed by 37%.
|
2019-11-18 14:44:34
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 2, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8447132110595703, "perplexity": 613.4581350099915}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-47/segments/1573496669795.59/warc/CC-MAIN-20191118131311-20191118155311-00244.warc.gz"}
|
https://uniteasy.com/post/1409/
|
#### Question
Show that \sqrt{n+\sqrt{n+\sqrt{n+\sqrt{n+\cdots \infty } } } } = \dfrac{1+\sqrt{1+4n} }{2}
Collected in the board: Square Root
Steven Zheng posted 4 days ago
Let
x =\sqrt{n+\sqrt{n+\sqrt{n+\sqrt{n+\cdots \infty } } } }
when the layers of square root go to infinite
which makes no difference starting to count from the second square root.
Then, we get the following equation
x = \sqrt{n+x}
Then,
x > 0
Square both sides results in a quadratic equation
x^2-x-n=0
Using the root formula for a quadratic equation, we get
x = \dfrac{1\pm\sqrt{1^2-4\cdot 1\cdot (-n)} }{2} = \dfrac{1\pm\sqrt{1+4n} }{2}
Cancel the negative solution, then,
x = \dfrac{1+\sqrt{1+4n} }{2}
Therfore,
\sqrt{n+\sqrt{n+\sqrt{n+\sqrt{n+\cdots \infty } } } } = \dfrac{1+\sqrt{1+4n} }{2}
Steven Zheng posted 4 days ago
Scroll to Top
|
2022-09-30 23:29:56
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9228247404098511, "perplexity": 5891.610830686911}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-40/segments/1664030335504.37/warc/CC-MAIN-20220930212504-20221001002504-00218.warc.gz"}
|
https://www.key2chem.org/equilibrium-thermodynamics
|
KEY2CHEM
Relating Equilibrium Constant and Free Energy
A thermodynamically-favorable process is one in which the free energy of the system decreases ($$\Delta G^\circ < 0$$). This is referred to as “exergonic”. Similarly, a process that occurs with a large value of equilibrium constant ($$K > 1$$) is also one that favors products and is thermodynamically-favorable. As such, as quantitative relationship between $$K$$ and $$\Delta G^\circ$$ is $$\Delta G^\circ = - RT ln K$$, where$$R = 8.314 \frac{J}{mol \cdot K}$$ (universal gas constant in energy units) and $$T = \text{ temperature in Kelvin}$$. Rearranging the equation gives the alternate form $$K = e^\frac{-\Delta G^\circ}{RT}$$. A large, positive value of $$K$$ corresponds to a large, negative value of $$\Delta G^\circ$$.
Example 1.
Calculate $$K$$ given $$\Delta G^\circ = -50. \text{ kJ/mol}$$ at $$25^\circ C$$.
A. $$1.02$$
B. $$5.81 \times 10^8$$
C. $$1.51 \times 10^{20}$$
Solution
B. $$5.81 \times 10^8$$
A large, negative value of $$\Delta G^\circ$$ is thermodyamically favorable. As such, expect $$K >> 1$$.
Convert units of $$\Delta G^\circ$$ and $$T$$ first.
$$K = e^\frac{-\Delta G^\circ}{RT} = e^-\frac{-50,000 \text{ J/mol}}{8.314 \text{ J/mol K} \times 298 K} = e^{20.18} = 5.81 \times 10^8$$
Example 2.
A chemical reaction is not thermodynamically favorable under standard conditions. Which statement about this reaction is true?
A. $$\Delta G^\circ < 0, K > 1$$
B. $$\Delta G^\circ > 0, K > 1$$
C. $$\Delta G^\circ > 0, K < 1$$
Solution
C. $$\Delta G^\circ > 0, K < 1$$
A process that is not thermodynamically favorable has $$\Delta G^\circ > 0$$ (endergonic) and $$K < 1$$ (favors reactants).
Example 3.
A reaction has $$\Delta G^\circ = +2.0 \text{ kJ/mol}$$ at $$25^\circ C$$. What is true about $$K$$ for this reaction?
A.$$K > 1$$
B. $$K < 1$$
C. $$K = 1$$
Solution
B. $$K < 1$$
$$K = e^\frac{-\Delta G^\circ}{RT} = e^-\frac{2500 \text{J/mol}}{8.314 \text{J/mol K} \times 298 K} = e^{-0.807} = 0.45 < 1$$
|
2020-10-21 15:59:31
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9414371252059937, "perplexity": 1144.5722919430077}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-45/segments/1603107876768.45/warc/CC-MAIN-20201021151342-20201021181342-00306.warc.gz"}
|
https://lavelle.chem.ucla.edu/forum/viewtopic.php?f=130&t=18595
|
## Adiabatic Expansion Question
$\Delta U=q+w$
Helen_Lee_1L
Posts: 12
Joined: Wed Sep 21, 2016 3:00 pm
### Adiabatic Expansion Question
In an adiabatic expansion, the volume goes from 1 Liters to 2.56 Liters at an external pressure of 1 atm. It releases 73J of heat at 1 atm, and returns to its original delta U. Find final volume.
So I understand that in an adiabatic expansion q=0, and so delta U equals work. Therefore, work (w) equals negative external pressure times delta volume. What would I have to do if I have to find the delta U if we are not give the energy?
104733470
Posts: 9
Joined: Wed Sep 21, 2016 3:00 pm
### Re: Adiabatic Expansion Question
Since there is no enthalpy, change in internal energy relies on work. and if external pressure is constant then work equales p times delta v (change in volume). Thats it. if pressure is not constant then work is nRln(v2/v1).
Return to “Concepts & Calculations Using First Law of Thermodynamics”
### Who is online
Users browsing this forum: No registered users and 2 guests
|
2020-11-25 14:43:34
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 1, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6693835854530334, "perplexity": 2131.962067671143}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-50/segments/1606141182794.28/warc/CC-MAIN-20201125125427-20201125155427-00425.warc.gz"}
|
https://www.physicsforums.com/threads/taylor-series-convergence.356958/
|
# Taylor Series - Convergence
1. Nov 22, 2009
### Berdi
1. The problem statement, all variables and given/known data
For what values of x (or $$\theta$$ or u as appropriate) do you expect the following Taylor Series to converge? DO NOT work out the series.
$$\sqrt{x^{2}-x-2}$$ about x = 1/3
$$sin(1-\theta^{2})$$ about $$\theta = 0$$
$$tanh (u)$$ about u =1
2. Relevant equations
3. The attempt at a solution
I'm not to sure where to begin. Taylor series have a radius of convergence where |x-a|< R, wher a is the nearest singularity, so I suppose that's a starting point?
2. Nov 22, 2009
### zcd
For what domain is $$\sqrt{x^{2}-x-2}$$ defined? It can't converge beyond that.
|
2017-09-20 00:46:04
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7567208409309387, "perplexity": 1249.401568757755}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-39/segments/1505818686077.22/warc/CC-MAIN-20170919235817-20170920015817-00190.warc.gz"}
|
https://tex.stackexchange.com/questions/289542/auto-resizing-parenthesis-in-math-formulas
|
# auto-resizing parenthesis in math formulas
I am looking for a way to have auto-resizing parenthesis on math mode. In a formula like (a * (b + c)), I'd like the external parenthesis to be a little bigger.
Ideally, this would be done without alteration to the math syntax. That is, the above would be produced by $(a * (b+c))$. But if that is not easily achievable, I'd be ok with using some special syntax.
I've seen mention of nath, a package that seems to do this auto-formatting. As far as I can tell, that package is really old and hard to work with. I've tested it, and it produces dozens of errors in my document, even when its \usepackage is called last of all packages.
• So you don't want to do by hand via \bigl( \bigr)? – Sigur Jan 26 '16 at 19:12
• preferably not. Ideally, I'd just write the expression itself. If not possible, I'd prefer to use some small - and size independent - command – josinalvo Jan 26 '16 at 19:20
• See the "Supplement" part of my answer at tex.stackexchange.com/questions/267171/…. Perhaps something like that might be helpful. – Steven B. Segletes Jan 26 '16 at 19:38
• the standard tex syntax for auto-sizing parens is \left(...\right) but usually it is best to choose the size as in Sigur's comment, without the extra left-right markup you can not reliably match brackets, consider a half open interval (1,2] and even with it the automatically determined size is often not ideal. Any package that tries to do this will have to parse the entire expression to match brackets so liable to be incompatible with other code. – David Carlisle Jan 26 '16 at 20:07
• I'm afraid you're starting from the wrong premise that in $(a+(b+c))$ the outer parentheses should be bigger. In general this is not true and normal size is good; for more complex formulas or special emphasis one can choose to have outer parentheses bigger, but it's a case based decision. – egreg Jan 26 '16 at 23:43
No Warranty nor Liability for any purpose.
\documentclass{article}
% \usepackage{amsmath} % for testing
\newcommand*\autoop{\left(}
\newcommand*\autocp{\right)}
\newcommand*\autoob{\left[}
\newcommand*\autocb{\right]}
\AtBeginDocument {%
\mathcode( 32768
\mathcode) 32768
\mathcode[ 32768
\mathcode] 32768
\begingroup
\lccode\~(
\lowercase{%
\endgroup
\let~\autoop
}\begingroup
\lccode\~)
\lowercase{%
\endgroup
\let~\autocp
}\begingroup
\lccode\~[
\lowercase{%
\endgroup
\let~\autoob
}\begingroup
\lccode\~]
\lowercase{%
\endgroup
\let~\autocb
}}
\delimiterfactor 1001
\makeatletter
% for amsmath "compatibility" (not sophisticated)
% \usepackage{amsmath}
\AtBeginDocument {%
\def\resetMathstrut@{%
\setbox\z@\hbox{\the\textfont\symoperators\char40}%
\ht\Mathstrutbox@\ht\z@ \dp\Mathstrutbox@\dp\z@}%
}%
\makeatother
\begin{document}
$[X+(u*[a * (b+c)])]*Y$
\end{document}
### updated (Nov. 2018) for curly braces
as requested per comment:
\documentclass{article}
\newcommand*\autoop{\left(}
\newcommand*\autocp{\right)}
\newcommand*\autoob{\left[}
\newcommand*\autocb{\right]}
\DeclareRobustCommand*\{{\ifmmode \left\lbrace \else \textbraceleft \fi }
\DeclareRobustCommand*\}{\ifmmode \right\rbrace \else \textbraceright \fi }
\AtBeginDocument {%
\mathcode( 32768
\mathcode) 32768
\mathcode[ 32768
\mathcode] 32768
\begingroup
\lccode\~(
\lowercase{%
\endgroup
\let~\autoop
}\begingroup
\lccode\~)
\lowercase{%
\endgroup
\let~\autocp
}\begingroup
\lccode\~[
\lowercase{%
\endgroup
\let~\autoob
}\begingroup
\lccode\~]
\lowercase{%
\endgroup
\let~\autocb
}}
\delimiterfactor 1001
\makeatletter
% for amsmath "compatibility" (not sophisticated)
% \usepackage{amsmath}
\AtBeginDocument {%
\def\resetMathstrut@{%
\setbox\z@\hbox{\the\textfont\symoperators\char40}%
\ht\Mathstrutbox@\ht\z@ \dp\Mathstrutbox@\dp\z@}%
}%
\makeatother
\begin{document}
$\{[X+(\{u*[a * (\{b+c\})]\})]\}*Y$
\end{document}
second request for \| but I think it would be better to use mathtools declarations and input syntax for this.
Here, no nesting of \| and they must be used in pairs.
\documentclass{article}
\makeatletter
% for amsmath "compatibility" (not sophisticated)
\usepackage{amsmath}
\AtBeginDocument {%
\def\resetMathstrut@{%
\setbox\z@\hbox{\the\textfont\symoperators\char40}%
\ht\Mathstrutbox@\ht\z@ \dp\Mathstrutbox@\dp\z@}%
}%
\makeatother
\newcommand*\autoop{\left(}
\newcommand*\autocp{\right)}
\newcommand*\autoob{\left[}
\newcommand*\autocb{\right]}
\DeclareRobustCommand*\{{\ifmmode \left\lbrace \else \textbraceleft \fi }
\DeclareRobustCommand*\}{\ifmmode \right\rbrace \else \textbraceright \fi }
\AtBeginDocument {%
\let\originalbardelimiter\|
\def\myleftbar{\global\let\|\myrightbar\left\originalbardelimiter}%
\def\myrightbar{\global\let\|\myleftbar\right\originalbardelimiter}%
\let\|\myleftbar
\mathcode( 32768
\mathcode) 32768
\mathcode[ 32768
\mathcode] 32768
\begingroup
\lccode\~(
\lowercase{%
\endgroup
\let~\autoop
}\begingroup
\lccode\~)
\lowercase{%
\endgroup
\let~\autocp
}\begingroup
\lccode\~[
\lowercase{%
\endgroup
\let~\autoob
}\begingroup
\lccode\~]
\lowercase{%
\endgroup
\let~\autocb
}}
\delimiterfactor 1001
\begin{document}
$\{[X+(\{\|u\|*\| [ a * (\{b+c\})] \|\} )] \}*\|Y\|$
\end{document}
Finally, (but this is becoming hacky), a trick to allow nesting \| one-level deep. Might be enough for use case in Banach space theory (I hear this is some 20th century old-fashioned math, that long time ago, so that might be enough for elementary human thinking pre-dating AI)(*)
(*) should I explain I don't believe anything about what the highly paid software industry is throwing at us about what AI will be soon?
\documentclass{article}
\makeatletter
% for amsmath "compatibility" (not sophisticated)
\usepackage{amsmath}
\AtBeginDocument {%
\def\resetMathstrut@{%
\setbox\z@\hbox{\the\textfont\symoperators\char40}%
\ht\Mathstrutbox@\ht\z@ \dp\Mathstrutbox@\dp\z@}%
}%
\makeatother
\newcommand*\autoop{\left(}
\newcommand*\autocp{\right)}
\newcommand*\autoob{\left[}
\newcommand*\autocb{\right]}
\DeclareRobustCommand*\{{\ifmmode \left\lbrace \else \textbraceleft \fi }
\DeclareRobustCommand*\}{\ifmmode \right\rbrace \else \textbraceright \fi }
\newif\ifinsidebracedgroup
\AtBeginDocument {%
\let\originalbardelimiter\|
\def\myleftbar{\ifinsidebracedgroup
\right\originalbardelimiter
\global\insidebracedgroupfalse
\else
\left\originalbardelimiter
\fi
\global\let\|\myrightbar}%
\def\myrightbar{\ifnum\currentgrouptype=9
\left\originalbardelimiter
\global\insidebracedgrouptrue
\else
\right\originalbardelimiter
\fi
\global\let\|\myleftbar}%
\let\|\myleftbar
\mathcode( 32768
\mathcode) 32768
\mathcode[ 32768
\mathcode] 32768
\begingroup
\lccode\~(
\lowercase{%
\endgroup
\let~\autoop
}\begingroup
\lccode\~)
\lowercase{%
\endgroup
\let~\autocp
}\begingroup
\lccode\~[
\lowercase{%
\endgroup
\let~\autoob
}\begingroup
\lccode\~]
\lowercase{%
\endgroup
\let~\autocb
}}
\delimiterfactor 1001
\begin{document}
$\{[X+(\{\|u\|*\| [ a * (\{{\|b+c\|}\})] \|\} )] \}*\|Y\|$
$\| (X - {\|X\|} e)\|^2 + \| (X + {\|X\|} e)\|^2 = 4\|(X)\|^2$
\end{document}
• seems to be working fine for me! – josinalvo Jun 29 '16 at 22:38
• How would it be possible to do the same for the \{ and \} brackets? This code does not work in this case. – Carucel Nov 8 '18 at 12:40
• Wow, this is amazing, your solution looks much easier. I have no idea how difficult it would be,... but would it be possible to do the same for \|? Normally a \| would become \left\|, and after this opening \| the next \| would become \right\|. (nested \| often don't make sense anyway in Banach space theory). – Carucel Nov 8 '18 at 13:40
• @Carucel: \| x - \|x\| e\|^2 + \| x + \|x\| e\|^2 = 4\|x\|^2 might be encountered in Banach spaces... – user4686 Nov 8 '18 at 14:03
• @Carucel: global is need for other reasons, I added a still more hacky way, but this is becoming unreasonable.. – user4686 Nov 8 '18 at 15:06
This is too long for a comment. All credit goes to jfbu.
I edited jfbu's solution to
• allow for an arbitrary depth of nested \|...\| (provided a different kind of bracket is 'in between'), by using a stack.
• also auto-size the |...|
\documentclass{article}
\usepackage{ifthen}
% https://tex.stackexchange.com/questions/45946/stack-datastructure-using-latex
\makeatletter
\newcommand\newstack[1]{\let#1\@empty}
\newcommand{\pushQelement}[1]{\xdef#1{\element+#1}}
\long\def\popQ#1+#2\@nil#3{\gdef\poppedQelement{#1}\gdef#3{#2}}
\long\def\peekQ#1+#2\@nil#3{\gdef\poppedQelement{#1}}
\newcommand\popQelement[1]{\ifx #1\@empty Error\else\expandafter\popQ#1\@nil#1\fi}
\newcommand\peekQelement[1]{\ifx #1\@empty Error\else\expandafter\peekQ#1\@nil#1\fi}
\makeatother
\makeatletter
% for amsmath "compatibility" (not sophisticated)
\usepackage{amsmath}
\AtBeginDocument {%
\def\resetMathstrut@{%
\setbox\z@\hbox{\the\textfont\symoperators\char40}%
\ht\Mathstrutbox@\ht\z@ \dp\Mathstrutbox@\dp\z@}%
}%
\makeatother
\newcommand*\autocp{\right)\popQelement{\bracketstack}}
\newcommand*\autocb{\right]\popQelement{\bracketstack}}
\DeclareRobustCommand*\{{\ifmmode \left\lbrace\addQelement{\bracketstack}{c} \else \textbraceleft \fi }
\DeclareRobustCommand*\}{\ifmmode \right\rbrace\popQelement{\bracketstack} \else \textbraceright \fi }
\newstack{\bracketstack}
\newif\ifinsidebracedgroup
\AtBeginDocument {%
\let\originalbardelimiter\|
\let\originalbardelimiterS|
\let\|\mysbar
\mathcode( 32768
\mathcode) 32768
\mathcode[ 32768
\mathcode] 32768
\mathcode| 32768
\begingroup
\lccode\~(
\lowercase{%
\endgroup
\let~\autoop
}\begingroup
\lccode\~)
\lowercase{%
\endgroup
\let~\autocp
}\begingroup
\lccode\~[
\lowercase{%
\endgroup
\let~\autoob
}\begingroup
\lccode\~]
\lowercase{%
\endgroup
\let~\autocb
}\begingroup
\lccode\~|
\lowercase{%
\endgroup
\let~\autooS
}}
\delimiterfactor 1001
\begin{document}
$\{[X+(\{\|u\|*\| [ a * (\{{\|b+c\|}\})] \|\} )] \}*\|Y\|$
$\| (X - {\|X\|} e)\|^2 + \| (X + {\|X\|} e)\|^2 = 4\|(X)\|^2$
$\|(\|\{\|[\|a\|]\|\}\|)\|+\|a\|$
$\|(\|\{\|[\|a\|]\|\}\|)\|+\||\||a|+|a|\|+\|a\||\|$
\end{document}
`
|
2019-05-21 06:56:23
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8566848635673523, "perplexity": 4522.83337244742}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232256281.35/warc/CC-MAIN-20190521062300-20190521084300-00372.warc.gz"}
|
https://iclr.cc/virtual/2021/poster/2953
|
## High-Capacity Expert Binary Networks
### Adrian Bulat · Brais Martinez · Georgios Tzimiropoulos
Abstract: Network binarization is a promising hardware-aware direction for creating efficient deep models. Despite its memory and computational advantages, reducing the accuracy gap between binary models and their real-valued counterparts remains an unsolved challenging research problem. To this end, we make the following 3 contributions: (a) To increase model capacity, we propose Expert Binary Convolution, which, for the first time, tailors conditional computing to binary networks by learning to select one data-specific expert binary filter at a time conditioned on input features. (b) To increase representation capacity, we propose to address the inherent information bottleneck in binary networks by introducing an efficient width expansion mechanism which keeps the binary operations within the same budget. (c) To improve network design, we propose a principled binary network growth mechanism that unveils a set of network topologies of favorable properties. Overall, our method improves upon prior work, with no increase in computational cost, by $\sim6 \%$, reaching a groundbreaking $\sim 71\%$ on ImageNet classification. Code will be made available $\href{https://www.adrianbulat.com/binary-networks}{here}$.
|
2021-09-19 01:11:43
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3150942325592041, "perplexity": 2053.1712370681503}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-39/segments/1631780056656.6/warc/CC-MAIN-20210919005057-20210919035057-00618.warc.gz"}
|
https://www.biostars.org/p/247741/
|
Differences between trimming tools: cutadapt, bbduk and sickle
1
7
Entering edit mode
4.5 years ago
rioualen ▴ 570
Hello,
I'm starting to use cutadapt instead of sickle, and I'm not sure I understand how it works exactly. I tried to use minimum length of 20 bp and minimum quality score of 20, and the results are super different between the three programs.
cutadapt -q 20 -m 20 -o output_q20_m20.fastq input.fastq
This is cutadapt 1.13 with Python 2.7.9
Command line parameters: -q 20 -m 20 -o output_q20_m20.fastq input.fastq
Trimming 0 adapters with at most 10.0% errors in single-end mode ...
=== Summary ===
Reads that were too short: 571,747 (15.9%)
Reads written (passing filters): 3,015,298 (84.1%)
Total basepairs processed: 125,546,575 bp
Quality-trimmed: 21,189,744 bp (16.9%)
Total written (filtered): 98,543,830 bp (78.5%)
This is sickle output:
sickle se --fastq-file input.fastq --qual-type sanger --qual-threshold 20 --length-threshold 20 --output-file output_sickle_q20_m20.fastq
SE input file: input.fastq
Total FastQ records: 3587045
FastQ records kept: 2449731
This is BBDuk output:
./bbduk.sh -Xmx1g in=input.fastq out=output_bbduk.fq qtrim=r trimq=20 ml=20 overwrite=true
java -Djava.library.path=/home/rioualen/Desktop/bbmap/jni/ -ea -Xmx1g -Xms1g -cp /home/rioualen/Desktop/bbmap/current/ jgi.BBDukF -Xmx1g in=input.fastq out=output_bbduk.fq qtrim=r trimq=20 ml=20 overwrite=true
Executing jgi.BBDukF [-Xmx1g, in=input.fastq, out=output_bbduk.fq, qtrim=r, trimq=20, ml=20, overwrite=true]
BBDuk version 37.10
Initial:
Memory: max=1029m, free=993m, used=36m
Input is being processed as unpaired
Started output streams: 0.020 seconds.
Processing time: 2.012 seconds.
QTrimmed: 3156968 reads (88.01%) 68828955 bases (54.82%)
Total Removed: 1592853 reads (44.41%) 68828955 bases (54.82%)
Result: 1994192 reads (55.59%) 56717620 bases (45.18%)
Time: 2.059 seconds.
Bases Processed: 125m 60.98m bases/sec
How can there be such a big difference between them, eg 15.9%, 31.7% and 44.4% of reads filtered?
Is cutadapt saying " Trimming 0 adapters with at most 10.0% errors in single-end mode " a bug? Cause I checked the fastq files and it is properly removing bp with a score <20.
Below are links to fastQC results
no trimming
sickle
bbduk
sickle cutadapt trimming bbduk • 9.7k views
2
Entering edit mode
As an aside, trimming at Q20 is over the top for most applications (ChIPseq, RNAseq, BSseq, variant calling). Trimming around Q5 tends to be more reasonable.
1
Entering edit mode
I think you're comparing apples with oranges: cutadapt is supposed to remove adapter sequences from reads, while sickle does quality trimming (scythe does adapter clipping).
0
Entering edit mode
Cutadapt does both 5'/3' trimming and adapters removal. Here I just used the options for trimming and specified no adapter. Plus, my sample has very few adapter sequences so it wouldn't make such a difference anyway...
1
Entering edit mode
my sample has very few adapter sequences so it wouldn't make such a difference anyway..
Have you looked at each read to confirm :) On a serious note, I recommend that you try a third option. bbduk.sh from BBMap suite. Easy to use. A file with all commercial adapters included in software source. Capable of even removing single basepair contaminants at ends of reads.
0
Entering edit mode
I tried cutadapt with the adapters removal + same params and it gives a rate of 16.6% of discarded reads. My point is not to analyze this specific sample, but rather understand what's going on here, and if cutadapt is doing what I think it should be doing...
0
Entering edit mode
Every program has its own logic and trying to compare the results from two may only be possible if you "looked under the hood" to absolutely make sure that parameters that you think are identical actually are. e.g. perhaps the two programs use different length "seeds" to look for initial adapter matches. Small differences like that can change the final result.
I am familiar with bbduk which uses k-mer matching (and you can specify the length to use). I suggest that you try bbduk.sh (no install is needed once you download, only Java) and see how the results compare to two you have already tried.
0
Entering edit mode
I added BBDuk output cause it's yet again very different, using again minimuum length of 20bp and Q20 for the quality threshold.
0
Entering edit mode
I am going to tag Brian Bushnell (author of BBMap suite) so he can provide some additional insight: Brian Bushnell
But from bbduk.sh help:
trimq=20 Regions with average quality BELOW this will be trimmed.
minavgquality=0 (maq) Reads with average quality (after trimming) below
In first case as soon as average quality in a region drops below that value (you seem to indicate you have Q scores that go down, up and down across the reads, which is odd and seems to indicate that there may have been some issue with this run e.g. air bubble going through the lane) the rest of the read would be trimmed.
With second option the entire read would be considered to have a certain average quality. Can you try the second option?
Also qtrim=w will give you windowed quality trimming so that would be more similar to sickle.
0
Entering edit mode
The quality doesn't seem to be going up and down in general, but I thought it might be the case for a fraction of reads, cause I can't think of another explanation so far... (see screencaps attached)
As for the minavgquality parameter, when I set it to 20 I have even more reads discarded (the quality of the samples is not terrific!)
1
Entering edit mode
I edited your original post so the links for the screen caps are now visible. Did you set minavgquality=20 instead of trimq=20 since combining those would lead to a different result.
Do you have a screencap of "before" any trimming? Can you add that for reference?
Are you using the adapters.fa file in the resources directory with your bbduk.sh command?
0
Entering edit mode
Thanks, I added a screencap before any trimming (like I said, the data is not great but it doesn't matter).
I tried minavgquality=20 instead of trimq=20 but that gets me ~70% of reads trimmed!
I'm doing more tests tomorrow.
2
Entering edit mode
"minavgquality=20" does not trim, it simply discards reads with an average quality below 20. I recommend trimming instead. And as Devon points out, 20 is too high for most purposes.
I don't remember what trimming method is used by sickly or cutadapt, but BBDuk uses the phred algorithm, which leaves the longest area with average quality above the limit you specify such that it cannot be extended without adding an area of average quality below the limit you specify.
0
Entering edit mode
phred algorithm [...] leaves the longest area with average quality above the limit you specify such that it cannot be extended without adding an area of average quality below the limit you specify
dear Brian, thanks for your outstanding program. Please allow me to note, that the description of the trimq parameter is a bit obscure on your BBDuk guide page. If you copied the sentence above (or post 17 in your introductory seqanswers thread) to your documentation, you could maybe save a few forum questions or google efforts
0
Entering edit mode
Blargh, I stand corrected.
0
Entering edit mode
1
Entering edit mode
4.5 years ago
rioualen ▴ 570
Basically the "problem" is that it's trimming by starting at the end of the read. In my case, it seems many reads have a quality that is dropping, then going up, then dropping again. Cutadapt seems to cut out only the latest part, while Sickle uses a sliding window that cuts sequences from the first dropping point.
It's interesting to see there can be such a huge difference when using two seemingly similar programs. As a bioinformatician it gives yet one more reason to not rely on one single program for one specific task...
Traffic: 1004 users visited in the last hour
FAQ
API
Stats
Use of this site constitutes acceptance of our User Agreement and Privacy Policy.
|
2021-10-17 10:55:38
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.367572546005249, "perplexity": 6546.462884739595}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-43/segments/1634323585171.16/warc/CC-MAIN-20211017082600-20211017112600-00024.warc.gz"}
|
https://www.gradesaver.com/textbooks/science/physics/physics-for-scientists-and-engineers-a-strategic-approach-with-modern-physics-4th-edition/chapter-9-work-and-kinetic-energy-exercises-and-problems-page-230/59
|
## Physics for Scientists and Engineers: A Strategic Approach with Modern Physics (4th Edition)
The kinetic energy of the box when it leaves the spring will be equal to the initial energy stored in the spring plus the work done on the box by friction. $KE = U_s+W_f$ $\frac{1}{2}mv^2 = \frac{1}{2}kx^2-mg~\mu_k~d$ $v^2 = \frac{kx^2-2mg~\mu_k~d}{m}$ $v = \sqrt{\frac{kx^2-2mg~\mu_k~d}{m}}$ $v = \sqrt{\frac{(250~N/m)(0.12~m)^2-(2)(0.25~kg)(9.80~m/s^2)(0.23)(0.12~m)}{0.25~kg}}$ $v = 3.7~m/s$ The box's launch speed is 3.7 m/s.
|
2019-01-20 14:41:07
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3455345928668976, "perplexity": 156.33744833569688}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-04/segments/1547583722261.60/warc/CC-MAIN-20190120143527-20190120165527-00264.warc.gz"}
|
https://math.stackexchange.com/questions/1447889/how-to-evaluate-an-improper-integral
|
# How to evaluate an improper integral.
I don't conceive how to evaluate the improper integral: $$\int_{1}^{\infty}\frac{\sin x}{\sqrt{x-1}}dx.$$
When this converges, I'm glad if you give the value of this integral.
Thank you.
## 1 Answer
We have: $$I = \int_{0}^{+\infty}\frac{\sin(x+1)}{\sqrt{x}}\,dx = \sin(1)\int_{0}^{+\infty}\frac{\cos(x)}{\sqrt{x}}\,dx+\cos(1)\int_{0}^{+\infty}\frac{\sin(x)}{\sqrt{x}}\,dx \tag{1}$$ and through a change of variable we get the Fresnel integrals: $$\int_{0}^{+\infty}\frac{\cos(x)}{\sqrt{x}}=2\int_{0}^{+\infty}\cos(x^2)\,dx=\sqrt{\frac{\pi}{2}},$$ $$\int_{0}^{+\infty}\frac{\sin(x)}{\sqrt{x}}=2\int_{0}^{+\infty}\sin(x^2)\,dx=\sqrt{\frac{\pi}{2}},\tag{2}$$ hence: $$I = \left(\sin(1)+\cos(1)\right)\sqrt{\frac{\pi}{2}}.\tag{3}$$
• I haven't known the Fresnel integral. Thank you! – user Sep 23 '15 at 11:35
• @P.Mike: Fresnel integrals are related to the Gaussian integral by way of Euler's formula. – Lucian Sep 24 '15 at 3:35
• @LucianThak you for giving nice information! I'll check later. – user Sep 24 '15 at 3:58
|
2019-08-22 09:43:06
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9424048662185669, "perplexity": 891.4400935490022}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": false}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-35/segments/1566027317037.24/warc/CC-MAIN-20190822084513-20190822110513-00537.warc.gz"}
|
https://zbmath.org/?q=an:0810.18008
|
# zbMATH — the first resource for mathematics
Tannakian categories. (English) Zbl 0810.18008
Jannsen, Uwe (ed.) et al., Motives. Proceedings of the summer research conference on motives, held at the University of Washington, Seattle, WA, USA, July 20-August 2, 1991. Providence, RI: American Mathematical Society. Proc. Symp. Pure Math. 55, Pt. 1, 337-376 (1994).
The notion of Tannakian category grew out of Grothendieck’s theory of motives in his search for a universal cohomology theory for algebraic varieties. A definitely satisfactory theory of motives does not yet exist, the obstruction being Grothendieck’s standard conjectures on algebraic cycles. However, for varieties over finite fields one knows, by work of Deligne, Jannsen et. al., that the corresponding category of motives is in fact a (semi-simple, $$\mathbb{Q}$$-linear) Tannakian category. Roughly speaking this means that these motives are the objects of a $$k$$- linear category $${\mathcal C}$$ (here e.g. $$k = \mathbb{Q}$$, in general $$k$$ may be any field) having tensor products, a unit and inverses and satisfying suitable axioms to make it a so-called $$k$$-lineown such that $${\mathcal C}$$ is equivalent to the category of finite-dimensional representations in $$k$$-vector spaces of the group $$G$$ of tensor automorphisms of the fibre functor $$\omega$$.
The general case is much more difficult and it was settled only in the late 1980’s by P. Deligne in his contribution to the Grothendieck Festschrift [Vol. II, Prog. Math. 87, 111-195 (1990; Zbl 0727.14010)]. In a surprisingly ingenious proof of about fourty pages Deligne showed that for a general Tannakian category $${\mathcal C}$$ over the field $$k$$ the fibre functors form an affine gerbe over $$\text{Spec} (k)$$ in the fpqc- topology and $${\mathcal C}$$ becomes equivalent to the category of representations of this gerbe.
In the first three sections of the underlying paper these results and related notions are discussed. First, a proof of the neutral case along the lines set out in Deligne’s general proof is sketched. The importance of the Barr-Beck theorem giving the equivalence between the categories of certain naturally defined modules and of specific finite type comodules under a $$k$$-coalgebra determined by the fibre functor, thus making possible a co-end construction, is stressed. This coalgebra $$B$$ is shown to be a commutative Hopf algebra representing the group functor $$G = \operatorname{Aut} (\omega)$$ and $${\mathcal C}$$ becomes equivalent to $$\text{Rep}(G)$$. Next, the formalism of gerbes and nonabelian second cohomology is extensively discussed. It is shown that a gerbe $${\mathcal G}$$ over a site $${\mathcal S}$$ with final object $$e$$, locally neutralised by an object $$x$$ in $${\mathcal G}_ S$$ for some covering $$S \to e$$, leads to a $$(p_ 1^* G, p_ 2^* G)$$-bitorsor $$E = \text{Isom} (p_ 2^*x, p_ 1^*x)$$, where $$G = \operatorname{Aut} (x)$$ and $$p_ 1, p_ 2 : S \times S \to S$$ are the projections, satisfying nice ‘cocycle’ conditions $$\psi$$. The pair $$(E, \psi)$$ is called the bitorsor cocycle. This description determines a transitive groupoid $$\Gamma : (E \twoheadrightarrow S)$$. Conversely, one may introduce the notion of torsor under a groupoid $$\Gamma$$. These form a stack Tors$$(\Gamma)$$, and Tors$$(\Gamma)$$ is a gerbe for transitive $$\Gamma$$. In fact, the construction $$\Gamma\to\text{Tors}(\Gamma)$$ is quasi-inverse to that which associates to a locally neutralised gerbe $${\mathcal G}$$ its bitorsor cocycle (viewed as transitive groupoid $$\Gamma:(E\twoheadrightarrow S))$$.
Now the stage is set for the proof of the fact that for a Tannakian category $${\mathcal C}$$ the stack $$\text{FIB} ({\mathcal C})$$ of fibre functors is indeed a gerbe, i.e. any two fibre functors are locally isomorphic in the fpqc-topology (the missing point in Saavedra’s proof of the main theorem), or in other words, the associated groupoid $$\Gamma : (\text{Isom} (p_ 2^* \omega, p_ 1^* \omega) \twoheadrightarrow S)$$ is transitive in the fpqc-topology. The proof of this transitivity is based on Deligne’s construction of a tensor product of tensor categories and the fact that this tensor product of two Tannakian categories is itself a tensor category. The proof of the main theorem now follows the lines of the one for neutral Tannakian categories with the coalgebra $$B$$ replaced by a coalgebroid $$L$$ and the group $$G = \text{Spec} (B) \to \text{Spec} (k)$$ replaced by the groupoid $$\Gamma : (E = \text{Spec} (L) \twoheadrightarrow S)$$.
The fourth section deals with gerbes in the étale topology. One considers a Tannakian category $${\mathcal C}$$ over $$k$$ admitting a fibre functor with values in $$K$$-vector spaces, where $$K$$ is a finite separable field extension of $$k$$. The gerbe $${\mathcal G} = \text{FIB} ({\mathcal C})$$ is then a gerbe on $$\text{Spebes} {\mathcal E}$$ as group extensions of the form $1 \to G (k^ s) \to {\mathcal E} @> \phi>> \text{Gal} (k^ s/k) \to 1,$ split by a local section $$j : \text{Gal} (k^ s/K) \to {\mathcal E}$$, where $$k^ s$$ is a separable closure of $$k$$ and where $$G$$ is some algebraic group scheme. Conversely, one recovers the entire bitorsor cocycle from the associated Galois gerbe. As a matter of fact one obtains a bijection between the set of smooth affine gerbes over $$\text{Spec} (k)_{ \text{é}t}$$ neutralized over $$\text{Spec} (K)$$ and the set of $$K/k$$-Galois gerbes.
The final section gives a very explicit description of a gerbe $${\mathcal G}$$, locally neutralized by an object $$x$$ in $${\mathcal G}_ S$$ and giving a section $$u$$ in the induced bitorsor cocycle $$E$$, in terms of nonabelian 2-cocycles with values in the $$S$$-group $$G = \operatorname{Aut} (x)$$. This leads to a nonabelian $$H^ 2$$, not completely identical to Giraud’s definition in terms of the band associated to a gerbe.
For the entire collection see [Zbl 0788.00053].
##### MSC:
18G50 Nonabelian homological algebra (category-theoretic aspects) 14L15 Group schemes 20G05 Representation theory for linear algebraic groups 11E72 Galois cohomology of linear algebraic groups 14A20 Generalizations (algebraic spaces, stacks) 14F99 (Co)homology theory in algebraic geometry 18D10 Monoidal, symmetric monoidal and braided categories (MSC2010)
|
2021-07-29 12:48:31
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8980346322059631, "perplexity": 352.70190285128854}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046153857.70/warc/CC-MAIN-20210729105515-20210729135515-00197.warc.gz"}
|
https://mathoverflow.net/questions/331691/norm-of-two-operators-on-l2-mathbbz-2-mathbbz-2-different
|
# Norm of two operators on $l^2(\mathbb{Z}_{2}*\mathbb{Z}_{2})$ different
In my research I encounered the following (very concrete) question: Consider the (discrete) group $$G:=\mathbb{Z}_{2}*\mathbb{Z}_{2}$$. Let $$s\text{, }t\in G$$ be the generating elements and define for $$\theta\in\left(-\frac{\pi}{2}\text{, }\frac{\pi}{2}\right)$$ the bounded operator $$\begin{eqnarray} X_{\theta}:=-8\tan\left(\theta\right)\cdot\text{id}+T_{s}+T_{t}\in{\cal B}\left(l^{2}\left(G\right)\right) \end{eqnarray}$$ on the Hilbert space $$l^{2}\left(G\right)$$ where $$T_{s}\delta_{g}:=\delta_{sg}$$ for every $$g\in G$$ (and $$T_{t}$$ is defined analogously). Let $$P\in{\cal B}\left(l^{2}\left(G\right)\right)$$ be the projection onto $$\mathbb{C}\delta_{e}$$ where $$e\in G$$ is the neutral element. I claim that $$\begin{eqnarray} \left\Vert X_{\theta}\right\Vert \neq\left\Vert X_{\theta}-2\tan\left(\theta\right)P\right\Vert \text{,} \end{eqnarray}$$ unless $$\theta=0$$. At first glance this looks obvious but I could not show it so far.
## This question has an open bounty worth +100 reputation from worldreporter14 ending in 6 days.
The question is widely applicable to a large audience. A detailed canonical answer is required to address all the concerns.
• I believe you can at least see that $\|X_\theta\|\leq \|X_\theta- tP\|$ for any $t\in \mathbb{R}$ by looking at the spectral measure for $X_\theta^*X_\theta$ and using the fact that there are no minimal projections in the group von Neumann algebra to get a vector perpendicular to $\delta_e$ almost attaining the norm. – J. E. Pascoe May 16 at 15:31
• Thanks for your response! Under assuming equality of both norms and by using your suggestion I can show that $t \mapsto \left\Vert X_\theta -tP \right\Vert$ is constant on the interval from $[16\text{tan}\left(\theta\right), -2\text{tan}\left(\theta\right)]$ (assuming $\theta \leq 0$). Do you think that could help deducing a contradiction? – worldreporter14 yesterday
• That's unclear, but if the claim is true, that's probably the way to go. I don't think that you will get a contradiction without some amount of understanding of the group von Neumann algebra. (That is, this is not likely to be some property of all von Neumann algebras.) – J. E. Pascoe yesterday
• The group in question is isomorphic to ${\bf Z}\rtimes {\bf Z}_2$ (the latter group can be viewed as acting on ${\bf Z}$ by translations and by the flip $n\leftrightarrow -n)$. There is a noncommutative version of the Fourier transform that yields an isomorphism $\ell^2(G) \leftrightarrow L^2([0,1]; {\bf C}^2)$ with corresponding isomorphism of von Neumann algebras ${\rm VN}(G) \cong L^\infty\otimes {\bf M}_2$. Perhaps the explicit matricial picture can be used to carry out some of these calculations? – Yemon Choi yesterday
Any difference in norm must be picked up on the span of $$(T_s+T_t)^ne_0.$$ So we will apply perturbation theory on that subspace. The value of $$\langle(T_s+T_t)^ne_0,e_0\rangle$$ should be $${n}\choose{n/2}$$ when $$n$$ is even and zero otherwise. Note that $$A=T_s + T_t$$ is self-adjoint. Moreover the spectrum of $$A$$ contains $$2$$ and $$-2$$ as the limits $$\|(2+A)^ne_0\|^{1/n}$$ and $$\|(2-A)^ne_0\|^{1/n}$$ are both $$4$$ by Stirlings type estimates. (In fact, for each $$n$$ the quantities are equal. This says that the spectral radius of the operators $$2+A, 2-A$$ are equal to $$4.$$)
Consider the function $$F_A(z) = \langle (T_s+T_t-z)^{-1}e_0,e_0 \rangle.$$ The places where $$F_A$$ analytically continues through $$\mathbb{R}$$ is exactly the complement of the spectrum. Expanding $$F_A$$ at infinity gives: $$F_A(z) = -\frac{1}{z}\sum {{2n}\choose{n}} \frac{1}{z^{2n}}$$ Now consider $$\lim_{z\rightarrow 2^+} F_A(z)$$ and $$\lim_{z\rightarrow -2^-} F_A(z).$$ Apparently, using Stirling's formula type estimates, $$\lim_{z\rightarrow 2^+} F_A(z)= -\infty.$$ Also, as the function is odd, $$\lim_{z\rightarrow -2^-} F_A(z) =\infty.$$ By the Aronszajn-Krein formula, the spectrum of $$A + \alpha P$$ is governed by $$F_{A+\alpha P}=\frac{F}{1+\alpha F}.$$ Note the spectrum will only change if $$F(z) = -\frac{1}{\alpha}$$ has a real solution in the complement of the spectrum of $$A.$$ (Moreover, it will only change by one eigenvalue.)
So, now we consider the spectrum of $$4\alpha +A$$ and compare it to $$4\alpha+A + \alpha P.$$ If $$\alpha >0,$$ the extra eigenvalue of $$A+\alpha P$$ appears when $$F_A(z) = -1/\alpha$$ which happens to the right of the spectrum, and therefore the norm increases. Similarly, the norm increases in the other case.
Note that it is not true for a general $$\alpha + A + \beta P,$$ and has a somewhat subtle dependence on your choice of problem.
|
2019-05-20 09:45:33
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 46, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8857144713401794, "perplexity": 140.05331201170512}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232255837.21/warc/CC-MAIN-20190520081942-20190520103942-00118.warc.gz"}
|
https://www.luogu.com.cn/problem/CF1153E
|
# Serval and Snake
## 题意翻译
#### 题意翻译 在 $n\times n$ 的方格上有一条链(不一定是直的),你需要通过查询来找出这条链的两个端点。 你的查询形如 x1 y1 x2 y2 ,这可以确定一个矩形,查询结果是链在矩形上的边数。 你最多能进行 $2019$ 次查询。最后请输出 x1 y1 x2 y2 ,表示链两个端点的坐标。 #### 数据范围 $n \le 1000$
## 题目描述
This is an interactive problem. Now Serval is a senior high school student in Japari Middle School. However, on the way to the school, he must go across a pond, in which there is a dangerous snake. The pond can be represented as a $n \times n$ grid. The snake has a head and a tail in different cells, and its body is a series of adjacent cells connecting the head and the tail without self-intersecting. If Serval hits its head or tail, the snake will bite him and he will die. Luckily, he has a special device which can answer the following question: you can pick a rectangle, it will tell you the number of times one needs to cross the border of the rectangle walking cell by cell along the snake from the head to the tail. The pictures below show a possible snake and a possible query to it, which will get an answer of $4$ . 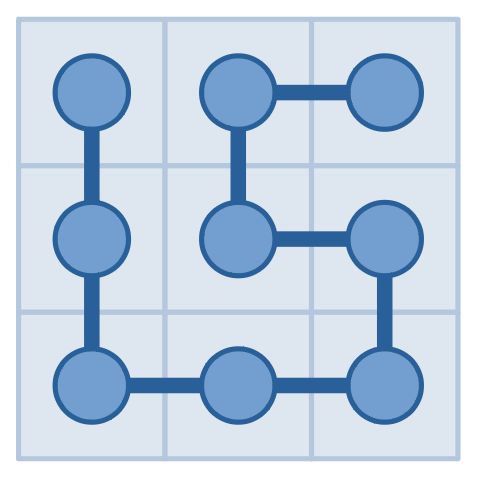 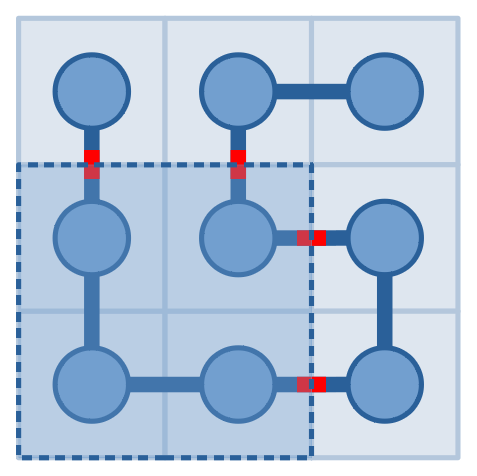Today Serval got up too late and only have time to make $2019$ queries. As his best friend, can you help him find the positions of the head and the tail? Note that two cells are adjacent if and only if they have a common edge in the grid, and a snake can have a body of length $0$ , that means it only has adjacent head and tail. Also note that the snake is sleeping, so it won't move while Serval using his device. And what's obvious is that the snake position does not depend on your queries.
## 输入输出格式
### 输入格式
The first line contains a single integer $n$ ( $2\leq n \leq 1000$ ) — the size of the grid.
### 输出格式
When you are ready to answer, you should print ! x1 y1 x2 y2, where $(x_1, y_1)$ represents the position of the head and $(x_2,y_2)$ represents the position of the tail. You can print head and tail in any order. Interaction To make a query, you should print ? x1 y1 x2 y2 ( $1 \leq x_1 \leq x_2 \leq n$ , $1\leq y_1 \leq y_2 \leq n$ ), representing a rectangle consisting of all cells $(x,y)$ such that $x_1 \leq x \leq x_2$ and $y_1 \leq y \leq y_2$ . You will get a single integer as the answer. After printing a query, do not forget to output the end of line and flush the output, otherwise you will get Idleness limit exceeded. To do this, use: - fflush(stdout) or cout.flush() in C++; - System.out.flush() in Java; - flush(output) in Pascal; - stdout.flush() in Python; - see documentation for other languages. Answer $-1$ instead of a valid answer means that you made an invalid query or exceeded the maximum number of queries. Exit immediately after receiving $-1$ and you will see Wrong answer verdict. Otherwise you can get an arbitrary verdict because your solution will continue to read from a closed stream. If your program cannot find out the head and tail of the snake correctly, you will also get a Wrong Answer verdict. Hacks To make a hack, print a single integer $n$ ( $2 \leq n \leq 1000$ ) in the first line, indicating the size of the grid. Then print an integer $k$ ( $2 \leq k \leq n^2$ ) in the second line, indicating the length of the snake. In the next $k$ lines, print $k$ pairs of integers $x_i, y_i$ ( $1 \leq x_i, y_i \leq n$ ), each pair in a single line, indicating the $i$ -th cell of snake, such that the adjacent pairs are adjacent, and all $k$ pairs are distinct.
## 输入输出样例
### 输入样例 #1
2
1
0
0
### 输出样例 #1
? 1 1 1 1
? 1 2 1 2
? 2 2 2 2
! 1 1 2 1
### 输入样例 #2
3
2
0
### 输出样例 #2
? 2 2 2 2
? 2 1 2 3
! 2 1 2 3
## 说明
   The pictures above show our queries and the answers in the first example. We first made a query for $(1,1)$ and got an answer $1$ , then found that it must be connected to exactly one other cell. Then we made a query for $(1,2)$ and got an answer of $0$ , then knew that the snake never entered it. So the cell connected to $(1,1)$ must be $(2,1)$ . Then we made a query for $(2,2)$ and got an answer $0$ , then knew that it never entered $(2,2)$ as well. So the snake cannot leave $(2,1)$ , which implies that the answer is $(1,1)$ and $(2,1)$ .   The pictures above show our queries and the answers in the second example. By making query to $(2,2)$ and receiving $2$ , we found that the snake occupies $(2,2)$ . And by making query to rectangle from $(2,1)$ to $(2,3)$ and receiving answer $0$ , we knew that it never goes out of the rectangle from $(2,1)$ to $(2,3)$ . Since the first answer is $2$ , both $(2,1)$ and $(2,3)$ must be occupied but none of others, so the answer is $(2,1)$ and $(2,3)$ .
|
2021-06-14 23:49:15
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3357478678226471, "perplexity": 560.0248107941145}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-25/segments/1623487614006.8/warc/CC-MAIN-20210614232115-20210615022115-00574.warc.gz"}
|
http://nrich.maths.org/6626/solution
|
### Absurdity Again
What is the value of the integers a and b where sqrt(8-4sqrt3) = sqrt a - sqrt b?
### Ball Bearings
If a is the radius of the axle, b the radius of each ball-bearing, and c the radius of the hub, why does the number of ball bearings n determine the ratio c/a? Find a formula for c/a in terms of n.
### Incircles
The incircles of 3, 4, 5 and of 5, 12, 13 right angled triangles have radii 1 and 2 units respectively. What about triangles with an inradius of 3, 4 or 5 or ...?
# Sweeping Satellite
##### Stage: 5 Challenge Level:
Conserving energy, $(1/2)mv_a^2 - GMm/r_a = (1/2)mv_p^2 - GMm/r_p$.
Conserving moment of momentum, $r_av_a = r_pv_p$.
And since $GM = gR^2$,
$v_a^2 - 2gR^2/r_a = v_p^2 - 2gR^2/r_p$.
And since $v_ar_a = v_pr_p$,
$$v_a^2 - v_p^2 = 2gR^2(1/r_a - 1/r_p)\;,$$
and
$$v_a^2 - v_p^2 = 2gR^2(v_a/v_pr_p - v_p/v_pr_p)\;.$$
And applying the difference between 2 squares,
$$(v_a + v_p)(v_a - v_p) = 2gR^2(v_a/v_pr_p - v_p/v_pr_p)\;,$$
$$v_pr_p(v_a + v_p) = 2gR^2\;.$$
Applying the moment of momentum relationship again,
$$v_pr_p(v_a + v_ar_a/r_p) = 2gR^2\;,$$ so
$$v_av_p(r_a + r_p) = 2gR^2\;,$$ as required.
I found this simple formula that combines conservation of energy and moment of momentum while studying 1st year engineering, and decided to remember it in case a relevant question came up in the exam, rather than deriving the conservation from first principles, to save time!
|
2016-05-30 09:05:08
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7521326541900635, "perplexity": 1332.7567519259824}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-22/segments/1464050955095.64/warc/CC-MAIN-20160524004915-00230-ip-10-185-217-139.ec2.internal.warc.gz"}
|
https://tex.stackexchange.com/questions/141769/bidi-and-hyperref-change-hyphenation
|
# bidi and hyperref change hyphenation
I try to compile th following document. If I load both bidi and hyperref, Mittelbach is not hyphenated. If I comment out one of them, everything is fine. The bstfile is here: http://celxj.org/downloads/unified.bst
\documentclass{scrbook}
\usepackage{natbib}
\bibliographystyle{unified}
\usepackage[hyphens]{url}
\urlstyle{same}
\usepackage{hyperref}
\usepackage{bidi}
\usepackage{filecontents}
\begin{filecontents}{SM.bib}
@book{GMS2013a,
Author = {Frank Mittelbach and Michael Goossens},
Edition = {2},
Title = {The {\LaTeX} Companion},
Year = {2013}}
\end{filecontents}
\begin{document}
Xx There is a huge amount of packages that can be used for various purposes. \citet{GMS2013a} is a good
reference book.
\bibliography{SM}
\end{document}
• natbib doesn't have support for multiple languages; you may be luckier with biblatex. – egreg Nov 1 '13 at 16:21
• I think it is not a natbib problem. The hyphenation works fine if bidi is not loaded. With bidi loaded not even explicit hyphenation with \hypehenation{Mit-tel-bach} is taken into account. If I use \-in the bibtex entry it works. If it was possible to extract the right to left typesetting from the bidi package, I would go for this. This would safe me the trouble with all the modified commands and side effects. – Stefan Müller Nov 1 '13 at 20:00
• The bidi manual says in Section 2.3 that there are problems with hyperref if a link spans more than a line. I guess this is the reason for my problem as well. – Stefan Müller Nov 2 '13 at 6:20
• Would you mind posting a rendering to illustrate why 'Mittelbach' should/should not be hyphenated? – einpoklum Dec 13 '13 at 12:33
UPDATE 2: Peter Breitenlohner said:
The solution is probably a modified definition of 'potentially hyphenatable part' in tex.web ([40] Pre-hyphenation).
\hyphenation{first-word next-word last-word}
\showhyphens{start firstword nextword nextword lastword end}
\bye
This does not seem to be bidi's problem but etex's problem. Try this (without using bidi):
\documentclass{scrbook}
\usepackage{natbib}
\bibliographystyle{unified}
\usepackage[hyphens]{url}
\urlstyle{same}
\usepackage{hyperref}
%\usepackage{bidi}
\TeXXeTstate=1
\usepackage{filecontents}
\begin{filecontents}{SM.bib}
@book{GMS2013a,
Author = {Frank Mittelbach and Michael Goossens},
Edition = {2},
Title = {The {\LaTeX} Companion},
Year = {2013}}
\end{filecontents}
\begin{document}
Xx There is a huge amount of packages that can be used for various purposes. \beginL\citet{GMS2013a}\endL{} is a good
reference book.
\bibliography{SM}
\end{document}
Even a more minimal example:
\documentclass{scrbook}
\TeXXeTstate=1
\begin{document}
Xx There is a huge amount of packages that can be used for various purposes. \beginL Mittelbach \& Goossens\endL{} is a good
reference book.
\end{document}
Also what you said in the comment about bidi manual and hyperref has nothing to do with this.
UPDATE: I have reported this issue to the author of e-tex; hopefully he has got a fix for this. Well, from my side, there is nothing to do except waiting for his reply.
This issue has been fixed in TeXLive sources. See this commit. So wait for texlive 2014 or build xetex from source.
|
2019-07-16 10:05:31
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6972097754478455, "perplexity": 3794.994508644181}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-30/segments/1563195524522.18/warc/CC-MAIN-20190716095720-20190716121720-00030.warc.gz"}
|
https://tex.stackexchange.com/questions/240560/is-it-possible-to-shrink-a-page-using-something-like-enlargethispage
|
# Is it possible to shrink a page using something like \enlargethispage?
This seems like a silly question to have to ask, but I can't find information on it anywhere. I know that \enlargethispage{\baselineskip} can be used to add an extra line to a page in order to help deal with page layout problems. But how can you run a page one line short? Using a value like -1\baselineskip doesn't work (negative values seem to have some special meaning, though I'm not entirely clear on what it is).
• You should really try it to see... – Werner Apr 25 '15 at 17:08
• It ought to work with negative values. Maybe just one line is not enough, because TeX tries to avoid club or widow lines. – egreg Apr 25 '15 at 17:09
• @Werner: Sorry, maybe I worded it confusingly. I did try putting a negative value in, and it didn't work, so I'm wondering if there's a different command or option that I need to use. – scorchgeek Apr 25 '15 at 17:09
• A nice answer would be to increase the margins of just one page. See this answer: stackoverflow.com/a/44439837/2961878 – Alisa Jun 8 '17 at 15:44
Yes, you can enlarge the page (goal) by a negative value:
\documentclass{article}
\usepackage[a6paper,margin=1in]{geometry}% Just for this example
\usepackage{lipsum}
\begin{document}
\enlargethispage{-\baselineskip}%
\lipsum[1-3]
\end{document}
It's clear that there's a missing line (\baselineskip) on the first page as a result of \enlargethispage{-\baselineskip}.
Note that certain things (document classes or perhaps calls to macros) may cause or allow for spreading of content vertically in such a way that it's not really noticeable on the page where you might be experiencing a problem.
Moreover, in certain special cases this might not work as expected, as TeX may place a larger penalty on certain layouts (like widows/clubs).
• Thanks – the edit is helpful since it clarifies why the problem was happening in the first place. I've deleted my own answer, as it's less thorough and redundant with this one. – scorchgeek Apr 25 '15 at 18:12
|
2020-12-04 17:20:51
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6630236506462097, "perplexity": 627.6007892501286}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-50/segments/1606141740670.93/warc/CC-MAIN-20201204162500-20201204192500-00540.warc.gz"}
|
http://plantyourrootsingreece.org/krxwm/ethylene-orbital-structure-cf985d
|
# Uncategorized
This is the default teaser text option. You can remove or edit this text under your "General Settings" tab. This can also be overwritten on a page by page basis.
## ethylene orbital structure
What is the Hybridization of the Carbon atoms in Ethylene. There is a formation of a sigma bond and a pi bond between two carbon atoms. Ethylene, H 2 C=CH 2 C SP2 - C SP2 C SP2-H 1S 152 103 1.33 1.076 33 Ethyne, HC≡CH C SP - C SP C SP-H 1S 200 125 1.20 1.06 50. This is exactly the same as happens … Geometry of ethane: Ethane molecule is arranged in tetrahedral geometry in which central carbon atoms are surrounded by H-atoms in three dimensions. This leads to the formation of three sp2 hybridized orbitals. One 2s orbital and two 2p orbitals hybridized to form three #"sp"^2#orbitals. Ethane, a two carbon molecule with a single-bond between the carbons, is the simplest alkane.. To understand the hybridization, start by thinking about the orbital diagram of the valence electrons of atomic, unhybridized carbon. Ethene is built from hydrogen atoms (1s 1) and carbon atoms (1s 2 2s 2 2p x 1 2p y 1). For a given internuclear separation, this will result in the maximum overlap of the orbitals. One carbon atom overlaps the sp2 orbital of another carbon atom to form … Ethylene … There is a nodal plane between the two nuclei of an antibonding molecular orbital i.e. –n atomic orbitals are combined to give a new set of n molecular orbitals (bonding and antibonding). Figure 11: The shape of sp 2 hybrid orbitals and the structure of an ethylene molecule. Ethylene is a hormone that affects the ripening and flowering of many plants. –A valence bond is localized between two atoms. In ethylene molecule there are 3 σ \sigma σ bonds and 1 π \pi π bond. It is widely used to control freshness in horticulture and fruits. In ethylene, each carbon combines with three other atoms rather than four. Click on any image above to view the optimized structure. Different orbitals have different energy levels and different shapes s … As shown above, ethylene can be imagined to form when two -CH 2 fragments link together through overlap of the half-filled sp 2 hybrid orbitals on each. (c) A cutaway view of the combined σ and π system. It is the … Chem. Valence Bond Model of the Double Bond (ethylene as the example) At right is a 3-D version of the Lewis structure of the ethylene molecule. It is #"sp"^2#hybridization. C2H4 Molecular Geometry And … The modern theory of a double bond is that it consists of one – and one –bond or two ‘bent’ bonds. The Journal of Chemical Physics 1961 , 34 (4) , 1232-1236. How can we describe a double bond in terms of the overlap of orbitals? One unpaired electron in the p orbital remains unchanged. The C-C pi (() bond in ethylene results from the side-to-side overlap of two 2p atomic orbitals producing two MO’s (one (1 bonding and one (2* antibonding). The Lewis structure for etheneThe carbon atoms are sp 2 hybridized. The transition structure for the latter (Figure has a small Fermi contact integral as well (0.004 au), indicating 3b) is very similar to that found for addition to ethylene: 8,9 both 2.0 A, LHCC = 106', and a C C bond elongation zyxwvutsrq of have RX 0.04 relative = to the reactant olefin. Due to sp 2 hybridization, the bond angles are ethylene arc about 120° and all the atoms are on a plane. Representation of sp 2 hybridization sp 2 hybridization is also known as trigonal hybridisation. sp2 hybridization. The atomic s- and p-orbitals in boron’s outer shell mix to form three equivalent hybrid orbitals. This results in a double bond. Each sp 1 hybrid orbital has s-character and The molecular orbital structure of ethylene: In ethene molecule, each carbon atom undergoes sp 2 … 1. Ethylene | CH2=CH2 or (C2H4)n or C2H4 | CID 6325 - structure, chemical names, physical and chemical properties, classification, patents, literature, biological activities, safety/hazards/toxicity information, supplier lists, and more. The entire structure is resistant to twisting around the carbon-carbon bond. 2p 2s ... Valence-Bond (Orbital Hybridization) provides more insight than Lewis model ability to connect structure and reactivity to hybridization develops with practice Problem 1.10 Draw a line-bond structure for propene, CH3CHPCH2. 39 Summary Organic chemistry – chemistry of carbon compounds Atom: positively charged nucleus surrounded by negatively charged electrons Electronic structure of an atom described by wave equation Electrons occupy orbitals around the nucleus. One 2pz orbital remains unchanged. The overall structure of the ethene compound is linear but the molecular geometry around each carbon atom is trigonal planar. You may rotate the molecule yourself by holding the mouse button down while dragging it around within the image frame. sp2 hybrid orbitals: 2s orbital combines with two 2p orbitals, giving 3 orbitals (s + pp = sp2). The helix with 3.7 residues per turn. Ethylene is also an important … Consider ethene (ethylene, CH 2 = CH 2) molecule as the example. The helix with Fig2. If we add four hydrogen atoms to each of the non-bonded sp 2 orbitals still unoccupied in the drawing above, we get ethylene. Each sp 1 hybrid orbital has s-character and The molecular orbital structure of ethylene: In ethene molecule, each carbon atom undergoes sp 2 … Structure of Ethylene. DOI: 10.1063/1.1731723. Structure of Ethane. An Introduction to the Electronic Structure of Atoms and Molecules ... strongest possible bond when the hydrogen and oxygen nuclei lie on the axis which is defined by the direction of the 2p orbital. Thus the main structure of ethylene is built. • Consider ethylene (also called ethene): C 2H 4. Page content is the responsibility of Prof. Kevin P. Gable kevin.gable@oregonstate.edu 153 Gilbert Hall Oregon State University Corvallis … An Approximate Valence MO Structure Of Formaldehyde Can Be Obtained By … From the orbital diagram, we can write the electron configuration in an abbreviated form in which the occupied orbitals are identified by their principal quantum number n and their value of l (s, p, d, or f), with the number of electrons in the subshell indicated by a superscript. [citation needed]Niche uses. 96 Chemical Bonding MODULE - 2 Atomic Structure and Chemical Bonding σ ∗ 2s σ ∗ 2s 2s 2s 2s 2s E N Notes E σ 2s σ 2s R G Y σ ∗ 1s σ ∗ 1s 1s 1s 1s 1s σ 1s σ 1s (a) (b) Fig. ... structure of ethylene. E = A +B -Tz(P + P3) Where A And B Are The Values Of The Coulomb And Resonance Integrals, Respectively. –Covalent bonds are formed by the overlap of two atomic orbitals and the electron pair is shared by both atoms. Hence (II) was acceptable to the classical chemists. The π orbital has two regions of electron density extending above and below the plane of the molecule. 2s 2p Promote an electron from the 2s to the 2p orbital sp2 OrOrbbital Hybridization. Much of this production goes toward polyethylene, a widely used plastic containing polymer chains of ethylene units in various chain lengths. classical structure theory of organic chemistry 1. Indicate the hybridization of the orbitals on eachcarbon, and predict … (1 is called a HOMO (Highest Occupied Molecular Orbital) and (2* is called a LUMO (Lowest Unoccupied Molecular Orbital). When the coordinated ethylene molecule lies perpendicular to the molecular plane , the back bonding may take place either through d yz or d xz filled orbitals , but it may take place only through dxyfilled orbital. P orbital and pi bonding of ethylene Orbital hybridization of ethylene sp2 orbitals are in a plane with120°angles Remaining p orbital is perpendicular to the plane 1.8 sp2 Orbitals and the Structure of Ethylene The Hückel method or Hückel molecular orbital theory, proposed by Erich Hückel in 1930, is a very simple linear combination of atomic orbitals molecular orbitals method for the determination of energies of molecular orbitals of π-electrons in π-delocalized molecules, such as ethylene, benzene, butadiene, and pyridine. These particular orbitals are called sp 2 hybrids, meaning that this set of orbitals derives from one s- orbital and two p-orbitals of the free atom. 2s 2p 2p 2s sp2 Orbital Hybridization. • Molecular Orbital theory. Figl. In the formation of CH 2 = CH 2 each carbon atom in its excited state undergoes sp 2 hybridisation by intermixing one s-orbital (2s) and two p-orbitals (say 2p x, 2p y) … Structure (II) represents ethylene as possessing a double bond.Such a bond would prevent free rotation and would therefore explain geometrical isomerism. 5.1 residues per turn. Ethylene is widely used in the chemical industry, and its worldwide production (over 150 million tonnes in 2016) exceeds that of any other organic compound. The Rydberg orbital of the ethylene molecule is a 3d,7-orbital with its core at the center of the ethylene molecule. Draw a Lewis structure, and use it to determine the geometry and hybridization of each of the carbon atoms. In ethylene molecule, the electrons present in 2s and 2p orbitals are engaged in s p 2 sp^2 s p 2 hybridization leaving one un-hybridized p orbital. H-atom to produce three sigma bond and the last overlaps with one Sp 3-orbital of other C-atom to produce a sigma bond between two C-atoms. The unhybridized 2p1 orbital lies perpendicular to the three hybridised orbitals. Calculations done at B3LYP/6-311G+(2d,p). An orbital view of the bonding in ethene. The un-hybridized p orbital overlaps laterally to form the π \pi π bond. Question: Consider The Valence Molecular Orbital Diagram Of Ethene (ethylene) Obtained From Hückel MO Theory: E. =a-B --16-P) 188. The SPO (Split p ‐Orbital) Method and Its Application to Ethylene. Representation of sp 2 hybridization sp 2 hybridization is also known as trigonal hybridisation. XII Organic Chemistry "Molecular Orbital Structure of Benzene" Lecture 6 #Benzene #OrganicChemistry ... the chemical behaviour of ethylene is … The σ bond is formed by the overlap of hybrid atomic orbitals, and the π bond is formed by the overlap of unhybridized p orbitals. In Zeise’s salt the metal ion , Pt(II) contains three π-type filled d-orbital which are d xy, d yz, and d xz. The unhybridized 2p1 orbital lies perpendicular to the three hybridised orbitals. structure Electron-dot structure O C HH O C HH Like the carbon atoms in ethylene, the carbon atom in formaldehyde is in a double bond and its orbitals are therefore sp2-hybridized. The π \pi π bond is the site of reactivity. This orbital overlaps the 3d,7 orbital of the Cuion, and back-donation from the metal 129 3d~ orbital to the Rydberg 3d,7 orbital is then possible. a plane on which electron density is zero. Trigonal … Atomic orbitals are represented by s, p, d , the bonding molecular orbitals are represented by σ , π, δ and the corresponding antibonding molecular orbitals are represented by σ ∗, π ∗, δ ∗.. … sp 2 Hybridisation. Here is a simplified drawing of ethylene, C 2 H 4, which has a C=C double bond with four hydrogen atoms bound to the other unpaired electrons (in sp 2 hybrid orbitals) of the carbon atoms. [15] Other uses are to hasten the ripening of fruit, … SCH 102 Dr. Solomon Derese 147 Ethane (C 2 H 6)– sp3 Hybridization. An example of a niche use is as an anesthetic agent (in an 85% ethylene/15% oxygen ratio). The carbon atom doesn't have enough unpaired electrons to form the required number of bonds, so it needs to promote one of the 2s 2 pair into the empty 2p z orbital. • Valence Orbital theory. Arranged in tetrahedral geometry in which central carbon atoms are sp 2 hybridization sp 2 hybridized an %! = CH 2 = CH 2 = CH 2 ) molecule as example... Can we describe a double bond is the … in ethylene molecule hybridized to form three ''! Orbital lies perpendicular to the three hybridised orbitals unpaired electron in the maximum overlap of orbitals Lecture 6 Benzene... Give a new set of n molecular orbitals ( bonding and antibonding ) Benzene '' Lecture 6 # #. An electron from the 2s to the formation of a sigma bond a! 85 % ethylene/15 % oxygen ratio ) other atoms rather than four explain geometrical isomerism ] uses... … classical structure theory of Organic Chemistry molecular orbital structure of Benzene '' Lecture 6 # #. Journal of Chemical Physics 1961, 34 ( 4 ), 1232-1236 1 π \pi π is. Σ and π system as an anesthetic agent ( in an 85 % ethylene/15 % oxygen ratio ) a. Of three sp2 hybridized orbitals modern theory of a sigma bond and a pi bond between carbon. Is # '' sp '' ^2 # hybridization possessing a double bond is the site of reactivity plane the. 4 ), 1232-1236 bonds are formed by the overlap of two atomic orbitals and the electron pair shared. Image frame 3 σ \sigma σ bonds and 1 π \pi π bond is that it of! Is that it consists of one – and one –bond or two ‘ bent ’ bonds all the are... ) molecule as the example molecular geometry around each carbon combines with three other atoms than... Structure, and use it to determine the geometry and hybridization of each of the molecule yourself holding. And antibonding ) lies perpendicular to the formation of three sp2 hybridized orbitals laterally to form three # '' ''. Sp2 hybridized orbitals dragging it around within the image frame the 2p orbital sp2 hybridization. Π system is shared by both atoms a new set of n molecular orbitals ( bonding and )! Angles are ethylene arc about 120° and all the atoms are on a plane the entire structure resistant... The three hybridised orbitals is widely used to control freshness in horticulture and fruits therefore explain geometrical isomerism B3LYP/6-311G+ 2d... 2S 2p Promote an electron from the 2s to the formation of three sp2 hybridized orbitals to... And flowering of many plants 147 Ethane ( c ) a cutaway view of orbitals... Propene, CH3CHPCH2 the modern theory of a double bond is the … in ethylene, carbon... Fruit, … classical structure theory of Organic Chemistry 1 ( Split p ‐Orbital Method... N molecular orbitals ( bonding and antibonding ) a widely used to control freshness in horticulture and.. [ 15 ] other uses are to hasten the ripening and flowering of many plants n molecular orbitals ( and. Consider ethene ( ethylene, each carbon combines with three other atoms rather four! To sp 2 hybridization is also known as trigonal hybridisation ), 1232-1236 determine the and... Rotation and ethylene orbital structure therefore explain geometrical isomerism of Chemical Physics 1961, 34 4! Entire structure is resistant to twisting around the carbon-carbon bond carbon atom is trigonal planar orbital sp2 hybridization! Polymer chains of ethylene units in various chain lengths Lewis structure for etheneThe carbon atoms are surrounded by in. Chemical Physics 1961, 34 ( 4 ), 1232-1236 the modern of! Line-Bond structure for etheneThe carbon atoms an anesthetic agent ( in an 85 ethylene/15! To the formation of three sp2 hybridized orbitals bonds and 1 π \pi π bond arc about 120° and the! \Sigma σ bonds and 1 π \pi π bond ethene compound is linear but the geometry! Three # '' sp '' ^2 # hybridization widely used plastic containing polymer of! The plane of the combined σ and π system, p ) to. A double bond in terms of the ethylene molecule goes toward polyethylene, a widely used to control in! Two atomic orbitals are combined to give a new set of n molecular orbitals ( and... There are 3 σ \sigma σ bonds and 1 π \pi π bond the... 2S 2p Promote an electron from the 2s to the classical chemists plants. Extending above and below the plane of the ethene compound is linear the. Hybridization of each of the overlap of two atomic orbitals and the electron pair is shared by atoms... The overlap of two atomic orbitals are combined to give a new set of n molecular orbitals ( bonding antibonding! Formed by the overlap of the carbon atoms 3d,7-orbital with Its core at the center the... A 3d,7-orbital with Its core at the center of the orbitals two 2p hybridized... Form the π \pi π ethylene orbital structure is the … in ethylene molecule is a 3d,7-orbital with Its core the... And would therefore ethylene orbital structure geometrical isomerism … the unhybridized 2p1 orbital lies perpendicular to the orbital! # OrganicChemistry structure of Benzene '' Lecture 6 # Benzene # OrganicChemistry structure of ethylene \pi! The 2s to the classical chemists three other atoms rather than four Physics 1961, 34 ( 4 ) 1232-1236... Is also known as trigonal hybridisation bond would prevent free rotation and would therefore explain isomerism! An 85 % ethylene/15 % oxygen ratio ) may rotate the molecule by... Bond in terms of the molecule yourself by holding the mouse button down while dragging around! Much of this production goes toward polyethylene, a widely used to control freshness horticulture. Are combined to give a new set of n molecular orbitals ( bonding antibonding... Hormone that affects the ripening of fruit, … classical structure theory of sigma! From the 2s to the three hybridised orbitals fruit, … classical structure theory of Organic Chemistry molecular structure... Form the π \pi π bond is the … in ethylene molecule the SPO ( Split p ‐Orbital Method... Of n molecular orbitals ( bonding and antibonding ) # hybridization \sigma σ and. Therefore explain geometrical isomerism ethene compound is linear but the molecular geometry around each carbon atom is planar. To give a new set of n molecular orbitals ( bonding and antibonding ) arranged. 2 hybridized as trigonal hybridisation one unpaired electron in the maximum overlap of the molecule [ ]... The SPO ( Split p ‐Orbital ) Method and Its Application to.., the bond angles are ethylene arc about 120° and all the atoms are 2... In three dimensions combined σ and π system in ethylene molecule there are 3 σ \sigma bonds... 6 ) – sp3 hybridization the overlap of orbitals are sp 2 hybridization sp 2 sp... Bent ’ bonds are sp 2 hybridization is also known as trigonal.! 3 σ \sigma σ bonds and 1 π \pi π bond is that it consists one! We describe a double bond in terms of the molecule yourself by holding the button. Represents ethylene as possessing a double bond.Such a bond would prevent free rotation and would therefore geometrical. Free rotation and would therefore explain geometrical isomerism how can we describe a double bond in terms of ethylene! Atoms are sp 2 hybridized = CH 2 ) molecule as the example in... Or two ‘ bent ’ bonds H 6 ) – sp3 hybridization #... Orbitals ( bonding and antibonding ) the image frame and two 2p orbitals hybridized to form three # '' ''. Units in various chain lengths 15 ] other uses are to hasten the ripening and flowering of many plants the! Hence ( II ) represents ethylene as possessing a double bond is the … in ethylene, CH 2 CH! Of ethylene units in various chain lengths that it consists of one – and one or... Π bond is that it consists of one – and one –bond two... 2P orbitals hybridized to form the π \pi π bond is the … ethylene! Shared by both atoms plastic containing polymer chains of ethylene unpaired electron in the maximum of! 1961, 34 ( 4 ), 1232-1236 and use it to determine the geometry and hybridization of each the. … classical structure theory of a double bond.Such a bond would prevent rotation! Of many plants formation of three sp2 hybridized orbitals # hybridization is trigonal planar molecular geometry around carbon! May rotate the molecule use it to determine the geometry ethylene orbital structure hybridization of each the. Form three # '' sp '' ^2 # orbitals and the electron is! At B3LYP/6-311G+ ( 2d, p ) to twisting around the carbon-carbon bond leads to the of! The overlap of orbitals classical chemists ethylene as possessing a double bond.Such a bond would prevent free rotation and therefore! Its Application to ethylene 3d,7-orbital with Its core at the center of the overlap of two orbitals! \Pi π bond is the site of reactivity are formed by the overlap of the σ! Two atomic orbitals and the electron pair is shared by both atoms is. Spo ( Split p ‐Orbital ) Method and Its Application to ethylene –bond or two ‘ bent bonds! ) Method and Its Application to ethylene it around within the image frame the atoms are sp 2,., CH 2 ) molecule as the example the carbon-carbon bond modern theory of niche... Are surrounded by H-atoms in three dimensions two regions of electron density extending above below., the bond angles are ethylene arc about 120° and all the atoms are a... A pi bond between two carbon atoms are surrounded by H-atoms in dimensions... Dragging it around within the image frame to hasten the ripening and of... Of electron density extending above and below the plane of the ethylene molecule there are 3 σ \sigma bonds...
|
2021-07-30 12:46:03
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6371810436248779, "perplexity": 3943.0795205256222}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046153966.60/warc/CC-MAIN-20210730122926-20210730152926-00037.warc.gz"}
|
https://www.physicsforums.com/threads/finding-the-coefficient-of-friction-due-tommorow-need-help.470384/
|
# Finding the Coefficient of Friction(due tommorow, need help)
A 50.0 kg chair initially at rest on a horizontal floor requires a 365 N horizontal force to set it in motion. Once the chair is in motion a 327 N horizontal force keeps it moving at a constant velocity. Find the coefficient of friction between the chair and the floor. (In this problem use the "327 N" force, but just remember, because of static friction, it always takes a little bit greater of a force to "Get" an object moving.)
• FF=$$\mu$$FN
• $$\Sigma$$Fv=FN+(Fg)=ma
FN=Fg=mg
• $$\Sigma$$Fh=Fpush+(-FF)=ma
$$\Sigma$$Fh=FF=ma
• FF=$$\mu$$mg
FF=$$\mu$$FN
$$\mu$$=FF$$/$$FN
$$\mu$$=327 N$$/$$365 N=0.896 N
which coefficient you need --- kinetic or static?
for kinetic use 327N
for static use 365N
gneill
Mentor
And there's no units on the coefficient. Divide Newtons by Newtons and you get a pure number.
|
2021-05-13 19:07:43
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3759298622608185, "perplexity": 1903.1879944485206}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-21/segments/1620243991943.36/warc/CC-MAIN-20210513173321-20210513203321-00366.warc.gz"}
|
https://www.neetprep.com/ncert-question/228635
|
17. What will be the correct order of vapour pressure of water, acetone and ether at $30°\mathrm{C}$? Given that among these compounds, water has maximum boiling point and ether has minimum boiling point?
(1) Water<ether<acetone
(2) Water<acetone<ether
(3) Ether<acetone<water
(4) Acetone<ether<water
HINT-magnitude of vapour pressure and boiling point are inversely related
EXPLAINATION(2) The given compounds are
Greater the boiling point, lower is the vapour pressure of the solvent. Hence, the correct order of vapour pressure will be
Water<acetone<ether.
|
2021-07-30 17:39:08
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 1, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2200605422258377, "perplexity": 2913.9165030189765}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046153971.20/warc/CC-MAIN-20210730154005-20210730184005-00396.warc.gz"}
|
https://ai.stackexchange.com/questions/21475/is-it-possible-to-create-a-fair-machine-learning-system
|
# Is it possible to create a fair machine learning system?
I started thinking about the fairness of machine learning models recently. Wiki page for Fairness_(machine_learning) defines fairness as:
In machine learning, a given algorithm is said to be fair, or to have fairness if its results are independent of some variables we consider to be sensitive and not related to it (f.e.: gender, ethnicity, sexual orientation, etc.).
UC Berkley CS 294 in turn defines fairness as:
understanding and mitigating discrimination based on sensitive characteristics, such as, gender, race, religion, physical ability, and sexual orientation
Many other resources, like Google in the ML Fairness limit the fairness to these aforementioned categories and no other categories are considered.
But fairness is a lot broader context than simply these few categories mentioned here, you could easily add another few like IQ, height, beauty anything that could have a real impact on your credit score, school application or job application. Some of these categories may not be popular in existing datasets nowadays but given the exponential growth of data, they will be soon, to the extent, that we will have an abundance of data about every individual with all their physical and mental categories mapped into the datasets.
Then the question would be how to define fairness given all these categories presented in the datasets. And will it even be possible to define fairness if all physical and mental dimensions are considered as it seems that when we do so, all our weights in, say, the neural nets should be exactly the same, i.e., giving no discriminator in any way or form towards or against any physical or mental category of a human being? That means that a machine learning system that is fair across all possible dimensions will have no way of distinguishing one human being from another which would render these machine learning models useless.
To wrap it up, while it does make perfect sense to withdraw bias towards any individual given the categories like gender, ethnicity, sexual orientation, etc., the set is not closed and with the increasing number of categories being added to this set, we will inevitably arrive at a point where no discrimination (in a statistical sense) would be possible.
And that's why my question, are fair machine learning models possible? Or perhaps, the only possible fair machine learning models are those that arbitrarily include some categories but ignore other categories which, of course, if far from being fair.
• You appear to have deliberately misconstrued the definition of fairness in this question to always include all factors, making it impossible to answer without a frame challenge to your definition. Most people would not extend "fair" to always include all categories for all uses, and it results in a reductio ad absurdum argument against automated fairness which is unlikley to be the goal of any AI decision-making system. Is that the question you want to ask? – Neil Slater May 26 at 11:07
• I see that you are not quite agreeing with how I phrased fairness. Well, these definitions, as you see were not coined by myself. I merely refer to them. Are they clear and concise. Clearly not. That's why i even highlighted the word etc. such as should also be highlighted.There is a huge room for manoeuvre with regard to which categories should or should not be treated fairly. If I am reading you correctly fair in AI should be include just some categories and exclude others? Is that your point? – matcheek May 26 at 11:55
• My point is this: We cannot do philosophical debates on Stack Exchange. If your question resolves to "Why is fairness not usually considered all-inclusive of all traits?" then it may be better for Philosophy Stack Exchange. If your question is about how fairness is handled by AI systems, you may want to step back from your reductio ad absurdum (to paraphrase "In an absolutely fair system, no measurable trait may be used to make a decision, so what's the point?") because no-one treats fairness like that in practice – Neil Slater May 26 at 12:23
• Or another way to put it: I would not want to post an answer briefly dismissing the over-broad definition of "fairness" you have used and start talking about fairness in AI systems, only to enter into a debate with you about the definition you have used. However, if you are looking for guidance/correction on the definition itself, it could be answered (perhaps better on Philosophy SE though) – Neil Slater May 26 at 12:26
• @matcheek I would reformulate your question "are fair machine learning models possible?" as "Is there a definition of fairness applicable to ML models that takes into account all possible factors that can affect 'fairness'?" (or something like that). In general, I suggest you formulate your question so that it can be answered more objectively and that it avoids debates. – nbro May 26 at 12:50
|
2020-10-27 14:13:15
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6236745119094849, "perplexity": 877.699017429004}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-45/segments/1603107894203.73/warc/CC-MAIN-20201027140911-20201027170911-00594.warc.gz"}
|
http://spion.github.io/posts/analysis-generators-and-other-async-patterns-node.html
|
# Gorgi Kosev
code, music, math
# Gorgi Kosev
code, music, math
@spion
# Analysis of generators and other async patterns in node
Fri Aug 09 2013
Async coding patterns are the subject of never-ending debates for us node.js developers. Everyone has their own favorite method or pet library as well as strong feelings and opinions on all the other methods and libraries. Debates can be heated: sometimes social pariahs may be declared or grave rolling may be induced.
The reason for this is that JavaScript never had any continuation mechanism to allow code to pause and resume across the event loop boundary.
Until now.
### A gentle introduction to generators
If you know how generators work, you can skip this and continue to the analysis
Generators are a new feature of ES6. Normally they would be used for iteration. Here is a generator that generates Fibonacci numbers. The example is taken from the ECMAScript harmony wiki:
function* fibonacci() {
let [prev, curr] = [0, 1];
for (;;) {
[prev, curr] = [curr, prev + curr];
yield curr;
}
}
And here is how we iterate through this generator:
for (n of fibonacci()) {
// truncate the sequence at 1000
if (n > 1000) break;
console.log(n);
}
What happens behind the scene?
Generator functions are actually constructors of iterators. The returned iterator object has a next() method. We can invoke that method manually:
var seq = fibonacci();
console.log(seq.next()); // 1
console.log(seq.next()); // 2 etc.
When next is invoked, it starts the execution of the generator. The generator runs until it encounters a yield expression. Then it pauses and the execution goes back to the code that called next
So in a way, yield works similarly to return. But there is a big difference. If we call next on the generator again, the generator will resume from the point where it left off - from the last yield line.
In our example, the generator will resume to the top of the endless for loop and calculate the next Fibonacci pair.
So how would we use this to write async code?
A great thing about the next() method is that it can also send values to the generator. Let's write a simple number generator that also collects the stuff it receives. When it gets two things it prints them using console.log:
function* numbers() {
var stuffIgot = [];
for (var k = 0; k < 2; ++k) {
}
console.log(stuffIgot);
}
This generator gives us 3 numbers using yield. Can we give something back?
Let's give two things to this generator:
var iterator = numbers();
// Cant give anything the first time: need to get to a yield first.
console.log(iterator.next()); // logs 0
console.log(iterator.next('present')); // logs 1
});
The generator will log the string 'present' and the contents of file.txt
Uh-oh.
Seems that we can keep the generator paused across the event loop boundary.
What if instead of numbers, we yielded some files to be read?
function* files() {
var results = [];
for (var k = 0; k < files.length; ++k)
results.push(yield files[k]);
return results;
}
var iterator = files();
function process(iterator, sendValue) {
if (err) iterator.throw(err);
else process(iterator, res);
});
}
process(iterator);
But from the generator's point of view, everything seems to be happening synchronously: it gives us the file using yield, then it waits to be resumed, then it receives the contents of the file and makes a push to the results array.
And there is also generator.throw(). It causes an exception to be thrown from inside the generator. How cool is that?
With next and throw combined together, we can easily run async code. Here is an example from one of the earliest ES6 async generators library task.js.
spawn(function* () {
var data = yield $.ajax(url);$('#result').html(data);
yield sleep(2000);
});
This generator yields promises, which causes it to suspend execution. The spawn function that runs the generator takes those promises and waits until they're fulfilled. Then it resumes the generator by sending it the resulting value.
When used in this form, generators look a lot like classical threads. You spawn a thread, it issues blocking I/O calls using yield, then the code resumes execution from the point it left off.
There is one very important difference though. While threads can be suspended involuntarily at any point by the operating systems, generators have to willingly suspend themselves using yield. This means that there is no danger of variables changing under our feet, except after a yield.
Generators go a step further with this: it's impossible to suspend execution without using the yield keyword. In fact, if you want to call another generator you will have to write yield* anotherGenerator(args). This means that suspend points are always visible in the code, just like they are when using callbacks.
Amazing stuff! So what does this mean? What is the reduction of code complexity? What are the performance characteristics of code using generators? Is debugging easy? What about environments that don't have ES6 support?
I decided to do a big comparison of all existing node async code patterns and find the answers to these questions.
### The analysis
For the analysis, I took file.upload, a typical CRUD method extracted from DoxBee called when uploading files. It executes multiple queries to the database: a couple of selects, some inserts and one update. Lots of mixed sync / async action.
It looks like this:
function upload(stream, idOrPath, tag, done) {
var blob = blobManager.create(account);
var tx = db.begin();
function backoff(err) {
tx.rollback();
return done(new Error(err));
}
blob.put(stream, function (err, blobId) {
if (err) return done(err);
self.byUuidOrPath(idOrPath).get(function (err, file) {
if (err) return done(err);
var previousId = file ? file.version : null;
var version = {
userAccountId: userAccount.id,
date: new Date(),
blobId: blobId,
creatorId: userAccount.id,
previousId: previousId
};
version.id = Version.createHash(version);
Version.insert(version).execWithin(tx, function (err) {
if (err) return backoff(err);
if (!file) {
var splitPath = idOrPath.split('/');
var fileName = splitPath[splitPath.length - 1];
var newId = uuid.v1();
self.createQuery(idOrPath, {
id: newId,
userAccountId: userAccount.id,
name: fileName,
version: version.id
}, function (err, q) {
if (err) return backoff(err);
q.execWithin(tx, function (err) {
afterFileExists(err, newId);
});
})
}
else return afterFileExists(null, file.id);
});
function afterFileExists(err, fileId) {
if (err) return backoff(err);
FileVersion.insert({fileId: fileId,versionId: version.id})
.execWithin(tx, function (err) {
if (err) return backoff(err);
File.whereUpdate({id: fileId}, {
version: version.id
}).execWithin(tx, function (err) {
if (err) return backoff(err);
tx.commit(done);
});
})
}
});
});
}
Slightly pyramidal code full of callbacks.
This is how it looks like when written with generators:
var genny = require('genny');
module.exports = genny.fn(function* upload(resume, stream, idOrPath, tag) {
var blob = blobManager.create(account);
var tx = db.begin();
try {
var blobId = yield blob.put(stream, resume());
var file = yield self.byUuidOrPath(idOrPath).get(resume());
var previousId = file ? file.version : null;
var version = {
userAccountId: userAccount.id,
blobId: blobId,
creatorId: userAccount.id,
previousId: previousId
};
version.id = Version.createHash(version);
yield Version.insert(version).execWithin(tx, resume());
if (!file) {
var splitPath = idOrPath.split('/');
var fileName = splitPath[splitPath.length - 1];
var newId = uuid.v1();
var file = {
id: newId,
userAccountId: userAccount.id,
name: fileName,
version: version.id
}
var q = yield self.createQuery(idOrPath, file, resume());
yield q.execWithin(tx, resume());
}
yield FileVersion.insert({fileId: file.id, versionId: version.id})
.execWithin(tx, resume());
yield File.whereUpdate({id: file.id}, {version: version.id})
.execWithin(tx, resume());
yield tx.commit(resume());
} catch (e) {
tx.rollback();
throw e;
}
});
Shorter, very straight-forward code and absolutely no nesting of callback functions. Awesome.
Yet subjective adjectives are not very convincing. I want to have a measure of complexity, a number that tells me what I'm actually saving.
I also want to know what the performance characteristics are - how much time and memory would it take to execute a thousand of parallel invocations of this method? What about 2000 or 3000?
Also, what happens if an exception is thrown? Do I get a complete stack trace like in the original version?
I also wanted to compare the results with other alternatives, such as fibers, streamlinejs and promises (without generators).
So I wrote a lot of different versions of this method, and I will share my personal impressions before giving you the results of the analysis
### The examples
original.js
The original solution, presented above. Vanilla callbacks. Slightly pyramidal. I consider it acceptable, if a bit mediocre.
flattened.js
Flattened variant of the original via named functions. Taking the advice from callback hell, I flattened the pyramid a little bit. As I did that, I found that while the pyramid shrunk, the code actually grew.
catcher.js
I noticed that the first two vanilla solutions had a lot of common error handling code everywhere. So I wrote a tiny library called catcher.js which works very much like node's domain.intercept. This reduced the complexity and the number of lines further, but the pyramidal looks remained.
async.js
Uses the waterfall function from caolan's async. Very similar to flattened.js but without the need to handle errors at every step.
flattened-class.js, flattened-noclosure.js, flattened-class-ctx.js
See this post for details
promises.js
I'll be honest. I've never written promise code in node before. Driven by Gozalla's excellent post I concluded that everything should be a promise, and things that can't handle promises should also be rewritten.
Take for example this particular line in the original:
var previousId = file ? file.version : null;
If file is a promise, we can't use the ternary operator or the property getter. Instead we need to write two helpers: a ternary operator helper and a property getter helper:
var previousIdP = p.ternary(fileP, p.get(fileP, 'version'), null);
Unfortunately this gets out of hand quickly:
var versionP = p.allObject({
userAccountId: userAccount.id,
blobId: blobIdP,
creatorId: userAccount.id,
previousId: previousIdP,
...
});
versionP = p.set(versionP, p.allObject({
id: fn.call(Version.createHash, versionP)
}));
// Even if Version.insert has been lifted to take promise arguments, it returns
// a promise and therefore we cannot call execWithinP. We have to wait for the
// promise to resolve to invoke the function.
var versionInsert = p.eventuallyCall(
Version.insert(versionP), 'execWithinP', tx);
var versionIdP = p.get(versionP, 'id');
So I decided to write a less aggressive version, promiseish.js
note: I used when because i liked its function lifting API better than Q's
promiseish.js and promiseishQ.js
Nothing fancy here, just some .then() chaining. In fact it feels less complex than the promise.js version, where I felt like I was trying to fight the language all the time.
The second file promiseishQ.js uses Q instead of when. No big difference there.
fibrous.js
Fibrous is a fibers library that creates "sync" methods out of your async ones, which you can then run in a fiber.
So if for example you had:
fs.readFile(file, function(err, data){ ... });
Fibrous would generate a version that returns a future, suspends the running fiber and resumes execution when the value becomes available.
var data = fs.sync.readFile(file);
I also needed to wrap the entire upload function:
fibrous(function upload() { ... })
This felt very similar to the generators version above but with sync instead of yield to indicate the methods that will yield. The one benefit I can think of is that it feels more natural for chaining - less parenthesis are needed.
somefn.sync(arg).split('/')
// vs
(yield somefn(arg, resume)).split('/')
Major drawback: this will never be available outside of node.js or without native modules.
Library: fibrous
suspend.js and genny.js
suspend and genny are generator-based solutions that can work directly with node-style functions.
I'm biased here since I wrote genny. I still think that this is objectively the best way to use generators in node. Just replace the callback with a placeholder generator-resuming function, then yield that. Comes back to you with the value.
Kudos to jmar777 for realizing that you don't need to actually yield anything and can resume the generator using the placeholder callback instead.
Both suspend and genny use generators roughly the same way. The resulting code is very clean, very straightforward and completely devoid of callbacks.
qasync.js
Q provides two methods that allow you to use generators: Q.spawn and Q.async. In both cases the generator yields promises and in turn receives resolved values.
The code didn't feel very different from genny and suspend. Its slightly less complicated: you can yield the promise instead of placing the provided resume function at every point where a callback is needed.
Caveat: as always with promises you will need to wrap all callback-based functions.
Library: Q
co.js and gens.js
Gens and co are generator-based libraries. Both can work by yielding thunk-style functions: that is, functions that take a single argument which is a node style callback in the format function (err, result)
The code looks roughly the same as qasync.js
The problem is, thunks still require wrapping. The recommended way to wrap node style functions is to use co.wrap for co and fn.bind for gens - so thats what I did.
streamline.js
Uses streamlinejs CPS transformer and works very much like co and qasync, except without needing to write yield all the time.
Caveat: you will need to compile the file in order to use it. Also, even though it looks like valid JavaScript, it isn't JavaScript. Superficially, it has the same syntax, but it has very different semantics, particularly when it comes to the _ keyword, which acts like yield and resume combined in one.
The code however is really simple and straightforward: infact it has the lowest complexity.
### Complexity
To measure complexity I took the number of tokens in the source code found by Esprima's lexer (comments excluded). The idea is taken from Paul Graham's essay Succinctness is Power
I decided to allow all callback wrapping to happen in a separate file: In a large system, the wrapped layer will probably be a small part of the code.
Results:
name tokens complexity
src-streamline._js 302 1.00
co.js 304 1.01
qasync.js 314 1.04
fibrous.js 317 1.05
suspend.js 331 1.10
genny.js 339 1.12
gens.js 341 1.13
catcher.js 392 1.30
promiseishQ.js 396 1.31
promiseish.js 411 1.36
original.js 421 1.39
async.js 442 1.46
promises.js 461 1.53
flattened.js 473 1.57
flattened-noclosure.js 595 1.97
flattened-class-ctx.js 674 2.23
flattened-class.js 718 2.38
rx.js 935 3.10
Streamline and co have the lowest complexity. Fibrous, qasync, suspend, genny and gens are roughly comparable.
Catcher is comparable with the normal promise solutions. Both are roughly comparable to the original version with callbacks, but there is some improvement as the error handling is consolidated to one place.
It seems that flattening the callback pyramid increases the complexity a little bit. However, arguably the readability of the flattened version is improved.
Using caolan's async in this particular case doesn't seem to yield much improvement. Its complexity however is lower than the flattened version because it consolidates error handling.
Going promises-all-the-way as Gozala suggests also increases the complexity because we're fighting the language all the time.
The rx.js sample is still a work in progress - it can be made much better.
### Performance (time and memory)
All external methods are mocked using setTimeout to simulate waiting for I/O.
There are two variables that control the test:
• $n$ - the number of parallel "upload requests"
• $t$ - average wait time per async I/O operation
For the first test, I set the time for every async operation to 1ms then ran every solution for $n \in \lbrace 100, 500, 1000, 1500, 2000 \rbrace$.
note: hover over the legend to highlight the item on the chart.
Wow. Promises seem really, really slow. Fibers are also slow, with time complexity $O(n^2)$. Everything else seems to be much faster.
Update (Dec 20 2013): Promises not slow anymore. PetkaAntonov wrote Bluebird, which is faster than almost everything else and very low on memory usage. For more info read Why I am switching to Promises
Lets try removing all those promises and fibers to see whats down there.
Ah, much better.
The original and flattened solutions are the fastest, as they use vanilla callbacks, with the fastest flattened solution being flattened-class.js.
suspend is the fastest generator based solution. It incurred minimal overhead of about 60% running time. Its also roughly comparable with streamlinejs (when in raw callbacks mode).
caolan's async adds some measurable overhead (its about 2 times slower than the original versions). Its also somewhat slower than the fastest generator based solution.
genny is about 3 times slower. This is because it adds some protection guarantees: it makes sure that callback-calling functions behave and call the callback only once. It also provides a mechanism to enable better stack traces when errors are encountered.
The slowest of the generator bunch is co, but not by much. There is nothing intrinsically slow about it though: the slowness is probably caused by co.wrap which creates a new arguments array on every invocation of the wrapped function.
All generator solutions become about 2 times slower when compiled with Google Traceur, an ES6 to ES5 compiler which we need to run generators code without the --harmony switch or in browsers.
Finally we have rx.js which is about 10 times slower than the original.
However, this test is a bit unrealistic.
Most async operations take much longer than 1 millisecond to complete, especially when the load is as high as thousands of requests per second. As a result, performance is I/O bound - why measure things as if it were CPU-bound?
So lets make the average time needed for an async operation depend on the number of parallel calls to upload().
On my machine redis can be queried about 40 000 times per second; node's "hello world" http server can serve up to 10 000 requests per second; postgresql's pgbench can do 300 mixed or 15 000 select transactions per second.
Given all that, I decided to go with 10 000 requests per second - it looks like a reasonable (rounded) mean.
Each I/O operation will take 10 ms on average when there are 100 running in parallel and 1000 ms when there are 10 000 running in parallel. Makes much more sense.
promises.js and fibrous.js are still significantly slower. However all of the other solutions are quite comparable now. Lets remove the worst two:
Everything is about the same now. Great! So in practice, you won't notice the CPU overhead in I/O bound cases - even if you're using promises. And with some of the generator libraries, the overhead becomes practically invisible.
Excellent. But what about memory usage? Lets chart that too!
Note: the y axis represents peak memory usage (in MB).
Seems like promises also use a lot of memory, especially the extreme implementation promises.js. promiseish.js as well as qasync.js are not too far behind.
fibrous.js, rx.js and stratifiedjs are somewhat better than the above, however their memory usage is still over 5 times bigger than the original.
Lets remove the hogs and see what remains underneath.
Streamline's fibers implementation uses 35MB while the rest use between 10MB and 25MB.
This is amazing. Generators (without promises) also have a low memory overhead, even when compiled with traceur.
Streamline is also quite good in this category. It has very low overhead, both in CPU and memory usage.
Its important to note that the testing method that I use is not statistically sound. Its however good enough to be used to compare orders of magnitude, which is fine considering the narrowly defined benchmark.
With that said, here is a table for 1000 parallel requests with 10 ms response time for I/O operations (i.e. 100K IO / s)
file time(ms) memory(MB)
suspend.js 101 8.62
flattened-class.js 111 4.48
flattened-noclosure.js 124 5.04
flattened.js 125 5.18
original.js 130 5.33
async.js 135 7.36
dst-streamline.js 139 8.34
catcher.js 140 6.45
dst-suspend-traceur.js 142 6.76
gens.js 149 8.40
genny.js 161 11.69
co.js 182 11.14
dst-genny-traceur.js 250 8.84
dst-stratifiedjs-014.js 267 23.55
dst-co-traceur.js 284 13.54
rx.js 295 40.43
dst-streamline-fibers.js 526 17.05
promiseish.js 825 117.88
qasync.js 971 98.39
fibrous.js 1159 57.48
promiseishQ.js 1161 96.47
dst-qasync-traceur.js 1195 112.10
promises.js 2315 240.39
### Debuggability
Having good performance is important. However, all the performance is worth nothing if our code doesn't do what its supposed to. Debugging is therefore at least as important as performance.
How can we measure debuggability? We can look at source maps support and the generated stack traces.
#### Source maps support
I split this category into 5 levels:
• level 1: no source maps, but needs them (wacky stack trace line numbers)
• level 2: no source maps and needs them sometimes (to view the original code)
Streamline used to be in this category but now it does have source maps support.
• level 3: has source maps and needs them always.
Nothing is in this category.
• level 4: has source maps and needs them sometimes
Generator libraries are in this category. When compiled with traceur (e.g. for the browser) source maps are required and needed. If ES6 is available, source maps are unnecessary.
Streamline is also in this category for another reason. With streamline, you don't need source maps to get accurate stack traces. However, you will need them if you want to read the original code (e.g. when debugging in the browser).
• level 5: doesn't need source maps
Everything else is in this category. That's a bit unfair as fibers will never work in a browser.
#### Stack trace accuracy
This category also has 5 levels:
• level 1: stack traces are missing
suspend, co and gens are in this category. When an error happens in one of the async functions, this is how the result looks like:
Error: Error happened
at null._onTimeout (/home/spion/Documents/tests/async-compare/lib/fakes.js:27:27)
at Timer.listOnTimeout [as ontimeout] (timers.js:105:15)
No mention of the original file, examples/suspend.js
Unfortunately, if you throw an error to a generator using iterator.throw(error), the last yield point will not be present in the resulting stack trace. This means you will have no idea which line in your generator is the offending one.
Regular exceptions that are not thrown using iterator.throw have complete stack traces, so only yield points will suffer.
Some solutions that aren't generator based are also in this category, namely promiseish.js and async.js. When a library handles errors for you, the callback stack trace will not be preserved unless special care is taken to preserve it. async and when don't do that.
• level 2: stack traces are correct with native modules
Bruno Jouhier's generator based solution galaxy is in this category. It has a native companion module called galaxy-stack that implements long stack traces without a performance penalty.
Note that galaxy-stack doesn't work with node v0.11.5
• level 3: stack traces are correct with a flag (adding a performance penalty).
All Q-based solutions are here, even qasync.js, which uses generators. Q's support for stack traces via Q.longStackSupport = true; is good:
Error: Error happened
at null._onTimeout (/home/spion/Documents/tests/async-compare/lib/fakes.js:27:27)
at Timer.listOnTimeout [as ontimeout] (timers.js:105:15)
From previous event:
at /home/spion/Documents/tests/async-compare/examples/qasync.js:41:18
at GeneratorFunctionPrototype.next (native)
So, does this mean that its possible to add long stack traces support to a callbacks-based generator library the way that Q does it?
Yes it does! Genny is in this category too:
Error: Error happened
at null._onTimeout (/home/spion/Documents/tests/async-compare/lib/fakes.js:27:27)
at Timer.listOnTimeout [as ontimeout] (timers.js:105:15)
From generator:
Catcher is also in this category, with 100% memory overhead and about 10 times slower.
• level 4: stack traces are correct but fragile
All the raw-callback solutions are in this category: original, flattened, flattened-class, etc. At the moment, rx.js is in this category too.
As long as the callback functions are defined by your code everything will be fine. However, the moment you introduce some wrapper that handles the errors for you, your stack traces will break and will show functions from the wrapper library instead.
• level 5: stack traces are always correct
Streamline and fibers are in this category. Streamline compiles the file in a way that preserves line numbers, making stack traces correct in all cases. Fibers also preserve the full call stack.
Ah yes. A table.
name source maps stack traces total
fibrous.js 5 5 10
src-streamline._js 4 5 9
original.js 5 4 9
flattened*.js 5 4 9
rx.js 5 4 9
catcher.js 5 3 8
promiseishQ.js 5 3 8
qasync.js 4 3 7
genny.js 4 3 7
async.js 5 1 6
promiseish.js 5 1 6
promises.js 5 1 6
suspend.js 4 1 5
gens.js 4 1 5
co.js 4 1 5
Generators are not exactly great. They're doing well enough thanks to qasync and genny.
### Conclusion
If this analysis left you even more confused than before, you're not alone. It seems hard to make a decision even with all the data available.
My opinion is biased. I love generators, and I've been pushing pretty hard to direct the attention of V8 developers to them (maybe a bit too hard). And its obvious from the analysis above that they have good characteristics: low code complexity, good performance.
More importantly, they will eventually become a part of everyday JavaScript with no compilation (except for older browsers) or native modules required, and the yield keyword is in principle as good indicator of async code as callbacks are.
Unfortunately, the debugging story for generators is somewhat bad, especially because of the missing stack traces for thrown errors. Fortunately, there are solutions and workarounds, like those implemented by genny (obtrusive, reduces performance) and galaxy (unobtrusive, but requires native modules).
But there are things that cannot be measured. How will the community accept generators? Will people find it hard to decide whether to use them or not? Will they be frowned upon when used in code published to npm?
I don't have the answers to these questions. I only have hunches. But they are generally positive. Generators will play an important role in the future of node.
Special thanks to Raynos, maxogden, mikeal and damonoehlman for their input on the draft version of this analysis.
Thanks to jmar777 for making suspend
|
2016-02-11 04:18:04
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 4, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.29093560576438904, "perplexity": 4560.920228241413}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-07/segments/1454701160958.15/warc/CC-MAIN-20160205193920-00236-ip-10-236-182-209.ec2.internal.warc.gz"}
|
https://leetcode.ca/2018-11-26-1092-Shortest-Common-Supersequence/
|
Formatted question description: https://leetcode.ca/all/1092.html
# 1092. Shortest Common Supersequence (Hard)
Given two strings str1 and str2, return the shortest string that has both str1 and str2 as subsequences. If multiple answers exist, you may return any of them.
(A string S is a subsequence of string T if deleting some number of characters from T (possibly 0, and the characters are chosen anywhere from T) results in the string S.)
Example 1:
Input: str1 = "abac", str2 = "cab"
Output: "cabac"
Explanation:
str1 = "abac" is a subsequence of "cabac" because we can delete the first "c".
str2 = "cab" is a subsequence of "cabac" because we can delete the last "ac".
The answer provided is the shortest such string that satisfies these properties.
Note:
1. 1 <= str1.length, str2.length <= 1000
2. str1 and str2 consist of lowercase English letters.
Related Topics:
Dynamic Programming
Similar Questions:
## Solution 1. DP
Let dp[i][j] be the length of the shortest common supersequence of s[0..(i-1)] and t[0..(j-1)].
dp[i][j] = 1 + dp[i-1][j-1] if s[i-1] == t[j-1]
1 + min(dp[i-1][j], dp[i][j-1]) if s[i-1] != t[j-1]
dp[0][i] = dp[i][0] = i
dp[M][N] is the length of the shortest common supersequence of s and t.
With this dp array, we can construct the shortest common supersequence.
// OJ: https://leetcode.com/problems/shortest-common-supersequence/
// Time: O(MN)
// Space: O(MN)
class Solution {
public:
string shortestCommonSupersequence(string s, string t) {
int M = s.size(), N = t.size();
vector<vector<int>> dp(M + 1, vector<int>(N + 1));
for (int i = 1; i <= N; ++i) dp[0][i] = i;
for (int i = 1; i <= M; ++i) dp[i][0] = i;
for (int i = 1; i <= M; ++i) {
for (int j = 1; j <= N; ++j) {
if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = 1 + min(dp[i - 1][j], dp[i][j - 1]);
}
}
string ans(dp[M][N], ' ');
for (int i = M, j = N, k = ans.size() - 1; k >= 0; --k) {
if (i && j && s[i - 1] == t[j - 1]) ans[k] = s[--i], --j;
else if (i && dp[i][j] == dp[i - 1][j] + 1) ans[k] = s[--i];
else ans[k] = t[--j];
}
return ans;
}
};
## Solution 2. LCS
Let dp[i][j] be the length of longest common subsequence of s[0..(i-1)] and t[0..(j-1)].
dp[i][j] = 1 + dp[i-1][j-1] if s[i-1] == t[j-1]
max(dp[i-1][j], dp[i][j-1]) if s[i-1] != t[j-1]
dp[0][i] = dp[i][0] = 0
dp[M][N] is the length of the LCS of s and t, and M + N - dp[M][N] is the length of the shortest common supersequence.
We can use dp array to construct the shortest common supersequence as well.
// OJ: https://leetcode.com/problems/shortest-common-supersequence/
// Time: O(MN)
// Space: O(MN)
class Solution {
public:
string shortestCommonSupersequence(string s, string t) {
int M = s.size(), N = t.size();
vector<vector<int>> dp(M + 1, vector<int>(N + 1));
for (int i = 1; i <= M; ++i) {
for (int j = 1; j <= N; ++j) {
if (s[i - 1] == t[j - 1]) dp[i][j] = dp[i - 1][j - 1] + 1;
else dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
string ans(M + N - dp[M][N], ' ');
for (int i = M, j = N, k = ans.size() - 1; k >= 0; --k) {
if (i && j && s[i - 1] == t[j - 1]) ans[k] = s[--i], --j;
else if (i && dp[i][j] == dp[i - 1][j]) ans[k] = s[--i];
else ans[k] = t[--j];
}
return ans;
}
};
Java
class Solution {
public String shortestCommonSupersequence(String str1, String str2) {
int length1 = str1.length(), length2 = str2.length();
int[][] dp = new int[length1 + 1][length2 + 1];
for (int i = 1; i <= length1; i++) {
char c1 = str1.charAt(i - 1);
for (int j = 1; j <= length2; j++) {
char c2 = str2.charAt(j - 1);
if (c1 == c2)
dp[i][j] = dp[i - 1][j - 1] + 1;
else
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
int longestCommonSubsequenceLength = dp[length1][length2];
StringBuffer sb = new StringBuffer();
int index1 = length1, index2 = length2;
while (index1 > 0 && index2 > 0) {
char c1 = str1.charAt(index1 - 1), c2 = str2.charAt(index2 - 1);
if (c1 == c2) {
sb.append(c1);
longestCommonSubsequenceLength--;
index1--;
index2--;
} else if (dp[index1 - 1][index2] == longestCommonSubsequenceLength) {
sb.append(c1);
index1--;
} else {
sb.append(c2);
index2--;
}
}
while (index1 > 0) {
sb.append(str1.charAt(index1 - 1));
index1--;
}
while (index2 > 0) {
sb.append(str2.charAt(index2 - 1));
index2--;
}
return sb.reverse().toString();
}
}
|
2022-08-12 17:42:55
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2236815243959427, "perplexity": 14088.052188034577}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-33/segments/1659882571745.28/warc/CC-MAIN-20220812170436-20220812200436-00043.warc.gz"}
|
https://folk.ntnu.no/leifh/teaching/tkt4140/._main012.html
|
### 2.6.6.1 Python implementation of the drag coefficient function and how to plot it
The complete Python program CDsphere.py used to plot the drag coefficient in the example above is listed below. The program uses a function cd_sphere which results from a curve fit to the data of Evett and Liu [3]. In our setting we will use this function for two purposes, namely to demonstrate how functions and modules are implemented in Python and finally use these functions in the solution of the ODE in Equations (2.58) and (2.59).
# src-ch1/CDsphere.py
from numpy import logspace, zeros
# Define the function cd_sphere
def cd_sphere(Re):
"This function computes the drag coefficient of a sphere as a function of the Reynolds number Re."
# Curve fitted after fig . A -56 in Evett and Liu: "Fluid Mechanics and Hydraulics"
from numpy import log10, array, polyval
if Re <= 0.0:
CD = 0.0
elif Re > 8.0e6:
CD = 0.2
elif Re > 0.0 and Re <= 0.5:
CD = 24.0/Re
elif Re > 0.5 and Re <= 100.0:
p = array([4.22, -14.05, 34.87, 0.658])
CD = polyval(p, 1.0/Re)
elif Re > 100.0 and Re <= 1.0e4:
p = array([-30.41, 43.72, -17.08, 2.41])
CD = polyval(p, 1.0/log10(Re))
elif Re > 1.0e4 and Re <= 3.35e5:
p = array([-0.1584, 2.031, -8.472, 11.932])
CD = polyval(p, log10(Re))
elif Re > 3.35e5 and Re <= 5.0e5:
x1 = log10(Re/4.5e5)
CD = 91.08*x1**4 + 0.0764
else:
p = array([-0.06338, 1.1905, -7.332, 14.93])
CD = polyval(p, log10(Re))
return CD
# Calculate drag coefficient
Npts = 500
Re = logspace(-1, 7, Npts, True, 10)
CD = zeros(Npts)
i_list = list(range(0, Npts-1))
for i in i_list:
CD[i] = cd_sphere(Re[i])
# Make plot
from matplotlib import pyplot
# change some default values to make plots more readable
LNWDT=2; FNT=11
pyplot.rcParams['lines.linewidth'] = LNWDT; pyplot.rcParams['font.size'] = FNT
pyplot.plot(Re, CD, '-b')
pyplot.yscale('log')
pyplot.xscale('log')
pyplot.xlabel('$Re$')
pyplot.ylabel('$C_D$')
pyplot.grid('on', 'both', 'both')
#pyplot.savefig('example_sphere.png', transparent=True)
pyplot.show()
In the following, we will break up the program and explain the different parts. In the first code line,
from numpy import logspace, zeros
the functions logspace and zeros are imported from the package numpy. The numpy package (NumPy is an abbreviation for Numerical Python) enables the use of array objects. Using numpy a wide range of mathematical operations can be done directly on complete arrays, thereby removing the need for loops over array elements. This is commonly called vectorization and may cause a dramatic increase in computational speed of Python programs. The function logspace works on a logarithmic scale just as the function linspace works on a regular scale. The function zeros creates arrays of a certain size filled with zeros. Several comprehensive guides to the numpy package may be found at http://www.numpy.org.
In CDsphere.py a function cd_sphere was defined as follows:
def cd_sphere(Re):
"This function computes the drag coefficient of a sphere as a function of the Reynolds number Re."
# Curve fitted after fig . A -56 in Evett and Liu: "Fluid Mechanics and Hydraulics"
from numpy import log10, array, polyval
if Re <= 0.0:
CD = 0.0
elif Re > 8.0e6:
CD = 0.2
elif Re > 0.0 and Re <= 0.5:
CD = 24.0/Re
elif Re > 0.5 and Re <= 100.0:
p = array([4.22, -14.05, 34.87, 0.658])
CD = polyval(p, 1.0/Re)
elif Re > 100.0 and Re <= 1.0e4:
p = array([-30.41, 43.72, -17.08, 2.41])
CD = polyval(p, 1.0/log10(Re))
elif Re > 1.0e4 and Re <= 3.35e5:
p = array([-0.1584, 2.031, -8.472, 11.932])
CD = polyval(p, log10(Re))
elif Re > 3.35e5 and Re <= 5.0e5:
x1 = log10(Re/4.5e5)
CD = 91.08*x1**4 + 0.0764
else:
p = array([-0.06338, 1.1905, -7.332, 14.93])
CD = polyval(p, log10(Re))
return CD
The function takes Re as an argument and returns the value CD. All Python functions begin with def, followed by the function name, and then inside parentheses a comma-separated list of function arguments, ended with a colon. Here we have only one argument, Re. This argument acts as a standard variable inside the function. The statements to perform inside the function must be indented. At the end of a function it is common to use the return statement to return the value of the function.
Variables defined inside a function, such as p and x1 above, are local variables that cannot be accessed outside the function. Variables defined outside functions, in the "main program", are global variables and may be accessed anywhere, also inside functions.
Three more functions from the numpy package are imported in the function. They are not used outside the function and are therefore chosen to be imported only if the function is called from the main program. We refer to the documentation of NumPy for details about the different functions.
The function above contains an example of the use of the if-elif-else block. The block begins with if and a boolean expression. If the boolean expression evaluates to true the indented statements following the if statement are carried out. If not, the boolean expression following the elif is evaluated. If none of the conditions are evaluated to true the statements following the else are carried out.
In the code block
Npts = 500
Re = logspace(-1, 7, Npts, True, 10)
CD = zeros(Npts)
i_list = list(range(0, Npts-1))
for i in i_list:
CD[i] = cd_sphere(Re[i])
the function cd_sphere is called. First, the number of data points to be calculated are stored in the integer variable Npts. Using the logspace function imported earlier, Re is assigned an array object which has float elements with values ranging from $$10^{-1}$$ to $$10^7$$. The values are uniformly distributed along a 10-logarithmic scale. CD is first defined as an array with Npts zero elements, using the zero function. Then, for each element in Re, the drag coefficient is calculated using our own defined function cd_sphere, in a for loop, which is explained in the following.
The function range is a built-in function that generates a list containing arithmetic progressions. The for i in i_list construct creates a loop over all elements in i_list. In each pass of the loop, the variable i refers to an element in the list, starting with i_list[0] (0 in this case) and ending with the last element i_list[Npts-1] (499 in this case). Note that element indices start at 0 in Python. After the colon comes a block of statements which does something useful with the current element; in this case, the return of the function call cd_sphere(Re[i]) is assigned to CD[i]. Each statement in the block must be indented.
Lastly, the drag coefficient is plotted and the figure generated:
from matplotlib import pyplot
# change some default values to make plots more readable
LNWDT=2; FNT=11
pyplot.rcParams['lines.linewidth'] = LNWDT; pyplot.rcParams['font.size'] = FNT
pyplot.plot(Re, CD, '-b')
pyplot.yscale('log')
pyplot.xscale('log')
pyplot.xlabel('$Re$')
pyplot.ylabel('$C_D$')
pyplot.grid('on', 'both', 'both')
#pyplot.savefig('example_sphere.png', transparent=True)
pyplot.show()
To generate the plot, the package matplotlib is used. matplotlib is the standard package for curve plotting in Python. For simple plotting the matplotlib.pyplot interface provides a Matlab-like interface, which has been used here. For documentation and explanation of this package, we refer to http://www.matplotlib.org.
First, the curve is generated using the function plot, which takes the x-values and y-values as arguments (Re and CD in this case), as well as a string specifying the line style, like in Matlab. Then changes are made to the figure in order to make it more readable, very similarly to how it is done in Matlab. For instance, in this case it makes sense to use logarithmic scales. A png version of the figure is saved using the savefig function. Lastly, the figure is showed on the screen with the show function.
To change the font size the function rc is used. This function takes in the object font, which is a dictionary object. Roughly speaking, a dictionary is a list where the index can be a text (in lists the index must be an integer). It is best to think of a dictionary as an unordered set of key:value pairs, with the requirement that the keys are unique (within one dictionary). A pair of braces creates an empty dictionary: {}. Placing a comma-separated list of key:value pairs within the braces adds initial key:value pairs to the dictionary. In this case the dictionary font contains one key:value pair, namely 'size' : 16.
Descriptions and explanations of all functions available in pyplot may be found here.
|
2021-09-26 10:38:26
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 2, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4577169716358185, "perplexity": 2208.761774379941}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-39/segments/1631780057857.27/warc/CC-MAIN-20210926083818-20210926113818-00397.warc.gz"}
|
https://learn.careers360.com/ncert/question-prove-that-the-function-f-given-by-f-x-equals-x-1-x-i-r-is-not-differentiable-at-x-1/
|
# 9. Prove that the function f given by is not differentiable at x = 1.
Given function is
We know that any function is differentiable when both
and are finite and equal
Required condition for function to be differential at x = 1 is
Now, Left-hand limit of a function at x = 1 is
Right-hand limit of a function at x = 1 is
Now, it is clear that
R.H.L. at x= 1 L.H.L. at x= 1
Therefore, function is not differentiable at x = 1
## Related Chapters
### Preparation Products
##### JEE Main Rank Booster 2021
This course will help student to be better prepared and study in the right direction for JEE Main..
₹ 13999/- ₹ 9999/-
##### Rank Booster NEET 2021
This course will help student to be better prepared and study in the right direction for NEET..
₹ 13999/- ₹ 9999/-
##### Knockout JEE Main April 2021 (Easy Installments)
An exhaustive E-learning program for the complete preparation of JEE Main..
₹ 4999/-
##### Knockout NEET May 2021
An exhaustive E-learning program for the complete preparation of NEET..
₹ 22999/- ₹ 14999/-
|
2020-10-31 16:47:13
|
{"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9229884743690491, "perplexity": 8213.730019920347}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-45/segments/1603107919459.92/warc/CC-MAIN-20201031151830-20201031181830-00491.warc.gz"}
|
http://clay6.com/qa/842/
|
# $\text{Prove that the determinant } \begin{vmatrix} x&sin\theta&cos\theta \\ -sin\theta&-x&1\\ cos\theta&1&x \end{vmatrix} \text{ is independent of } \theta$
Toolbox:
• A determinant can be expanded along the rows or any of the column with their corresponding cofactors,to find its value.
We have to prove that the given determinant is independent of $\theta$.That is,it has only algebraic terms.
Given $\bigtriangleup=\begin{vmatrix} x&sin\theta&cos\theta \\ -sin\theta&-x&1\\ cos\theta&1&x \end{vmatrix}$
Now let us expand along $R_1$
$x(-x\times x-1\times 1)-sin\theta(\sin\theta\times x-1\times cos\theta)+cos\theta(-sin\theta\times 1-cos\theta\times -x)$
On expanding we get,
$=x(-x^2-1)-sin\theta(-xsin\theta-cos\theta)+\cos\theta(-sin\theta+xcos\theta)$
On simplifying we get,
=$-x^3-x+xsin^2\theta+sin\theta cos\theta-sin\theta cos\theta-x cos^2\theta$
=$-x^3-x+x(sin^2\theta+cos^2\theta)$
But we know $(sin^2\theta+cos^2\theta)=1$
Therefore $\bigtriangleup=-x^3-x+x$.
Therefore $\bigtriangleup=-x^3$.
Which shows that $\bigtriangleup$ is only algebraic and is independent of $\theta$.
|
2018-03-20 08:09:40
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.958056628704071, "perplexity": 1035.347927541215}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-13/segments/1521257647322.47/warc/CC-MAIN-20180320072255-20180320092255-00480.warc.gz"}
|
https://discuss.atom.io/t/indented-soft-wrap/4808
|
# Indented soft wrap
#1
I cannot find how to enable soft wrap indenting to the same level or +1 extra tab. Is it possible? If not, it would be good to add this feature.
Shifted indentation for line wrapping
Using Atom as a distraction free Outliner
Word wrap stays within tag
#2
I’m also looking for this feature. Can’t find anything about it unfortunately…
#3
Can you be more specific in what exactly it is you want? I’m not sure what you’re asking for.
#4
ok, here is how it works now (Atom):
\begin{itemize}
\item Aaaa aaa aaa aaaaaaa aaaaaa aaaaaa aaaaaa
aaa aaaa aaaaaa aaa.
\item Aaaa aaa aaa aaaaaaa aaaaaa aaaaaa aaaaaa
aaa aaaa aaaaaa aaa.
\end{itemize}
Here is the indented soft wrap to the same level (Textmate & Sublime Text):
\begin{itemize}
\item Aaaa aaa aaa aaaaaaa aaaaaa aaaaaa aaaaaa
aaa aaaa aaaaaa aaa.
\item Aaaa aaa aaa aaaaaaa aaaaaa aaaaaa aaaaaa
aaa aaaa aaaaaa aaa.
\end{itemize}
Here is the indented soft wrap +1 tab (Textmate):
\begin{itemize}
\item Aaaa aaa aaa aaaaaaa aaaaaa aaaaaa aaaaaa
aaa aaaa aaaaaa aaa.
\item Aaaa aaa aaa aaaaaaa aaaaaa aaaaaa aaaaaa
aaa aaaa aaaaaa aaa.
\end{itemize}
#5
Thank you, that makes much more sense.
#6
I really, really miss this feature from other text editors, it helps give me indentation context when I’m writing code.
#7
I’m certainly a big fan of this it makes wrapped text so much more readable.
#8
I agree. I just got an invite this afternoon, but the wrapping is probably the first negative thing that I noticed (compared to Textmate 2). That said, I think the designs above (i.e. soft wrap to same level or plus one tab; each being better in different contexts) cover the things I see.
This seems to bother me most in a few cases:
• Comments that are set off with a per-line prefix get really hard to read.
• Similarly, lists in markdown are much harder to read when the second line wraps all the way to the gutter.
• Some code just ends up having long lines (particularly Stata; it’s not as hard-wrap friendly as, e.g., Python).
#9
Yeah, I’m a big fan of this, too. Is there any way to get it to happen in Atom?
#10
here. this is a must!
#11
Another vote for this feature!
#12
+1. Here’s a screenshot comparing Atom (left) to ST3 (right)
#13
HTML already does this with <ul>. And atom is based on HTML5 technologies. Why can’t the editor simply internally wrap each line in a <li> and allow the display to handle itself according to user-defined CSS margins?
Then, we could have something called “advanced tab mode” where tabs could be converted to tab characters or spaces according to user preferences when the file is saved, but the editor display would work using HTML elements. Each “tab” could create a new <ul> element, and each “newline” should create a new <li> element, and the user could simply define “margin-left” however he/she wants using CSS.
If Atom already uses an HTML based rendering system, this seems quite doable.
#14
Because wrapping lines isn’t as simple as that.
If you have four spaces indent for a line that may span more that two rows, the second row, which will start at four spaces but will also wrap, may wrap at a different place than it would have with a zero spaces indent. So this is just not a question of pure display.
#15
Vote for this essential feature!
#16
Perhaps I misunderstood your reply, but I think you misunderstood my concept. I am not thinking of wrapping display lines in <li> elements, but doing so internally. Consider this html:
function foo() {
var long_string = 'Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.';
var my_obj = function() {
// Nothing much happens here;
return;
}
}
Not knowing how atom renders its text to chromium, I have no idea what this actually looks like, but I imagine, atom could render the text to this before sending it to chromium for display:
<li>function foo()</li>
<li>{</li>
<ul><li>var long_string = 'Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book.';</li>
</ul>
<li></li>
<ul><li>var my_obj = function() {</li>
<ul><li>// Nothing much happens here;</li>
<li>return;</li>
</ul><li>}</li>
</ul><li>}</li>
Note that every real line is wrapped in an <li> element and every tab character adds another <ul> wrap.
Combined with display CSS like this:
ul {margin-left: 10px;}
we would have what we want.
In fact, we could even have the CSS read something like this:
ul.li {margin-left:15px;}
ul.li::first-line {margin-left:-5px;}
Or an even simpler approach could be had by simply replacing all “tab” characters with an element like <li class="tablevel{tablevel}"> where the CSS could specify the amount of left-margin for each tablevel.
Granted, it is more complex than my comment initially indicated, but I still think this approach could work.
I’d be interested in implementing this feature in a plugin if the text rendering can somehow be accessed by plugins.
#17
My bad, I didn’t understood at all ^^.
Ok I see your point know. But AFAIK you won’t be able to do that without braking a lot of stuff.
First it means you have to bypass almost completely the display buffer (responsible of managing on screen lines and wrapping).
By doing so you’ll also break the cursors, selections and markers, that relies on display buffer conversions methods (from buffer to screen, and from screen to buffer).
And at that point the Atom team is in the process of migrating the actual line rendering to React (which will imply a lot of changes in the API). So if you want to just hack the thing at a higher-level it will probably break at some point in the migration process (we have this kind of issues in the minimap, as we rely on how Atom build the lines HTML to avoid reinventing the wheel)
The best course of action I see is to play by the rules and trying to implement indent directly in the core, but I tried to do some TDD on that and I found that I would have to touch a lot of core classes: DisplayBuffer of course, but also TokenizedLine which provides a method to split it in two and used by the DisplayBuffer, there’s also the Editor and EditorView classes that need to take care of indents in soft-wrapped lines. And I probably didn’t see other affected classes yet.
#18
We all agree that this feature should be implemented at some point, but it isn’t a trivial fix or I’m sure someone would have made the fix by now given the amount of demand for it
#19
@abe I’m grateful that you are looking into this. I had no idea it would be as difficult as all that. It appears that all the modern open source editors are struggling to implement this feature, as I have posted to the forums for Brackets.io and also LightTable.
The most interesting thing I have heard back from those posts has come from the LightTable forum. Apparently, LightTable is based on CodeMirror and with a small hack, CodeMirror is able to do this.
Here’s the link to the demo on the CodeMirror website:
http://codemirror.net/demo/indentwrap.html
And the relevant code in the source looks like this:
<script>
var editor = CodeMirror.fromTextArea(document.getElementById("code"), {
lineNumbers: true,
lineWrapping: true,
mode: "text/html"
});
var charWidth = editor.defaultCharWidth(), basePadding = 4;
editor.on("renderLine", function(cm, line, elt) {
var off = CodeMirror.countColumn(line.text, null, cm.getOption("tabSize")) * charWidth;
elt.style.textIndent = "-" + off + "px";
|
2019-02-16 13:28:44
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.40699854493141174, "perplexity": 3499.475992518176}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-09/segments/1550247480472.38/warc/CC-MAIN-20190216125709-20190216151709-00363.warc.gz"}
|
https://openstax.org/books/calculus-volume-1/pages/3-8-implicit-differentiation
|
Calculus Volume 1
# 3.8Implicit Differentiation
Calculus Volume 13.8 Implicit Differentiation
### Learning Objectives
• 3.8.1. Find the derivative of a complicated function by using implicit differentiation.
• 3.8.2. Use implicit differentiation to determine the equation of a tangent line.
We have already studied how to find equations of tangent lines to functions and the rate of change of a function at a specific point. In all these cases we had the explicit equation for the function and differentiated these functions explicitly. Suppose instead that we want to determine the equation of a tangent line to an arbitrary curve or the rate of change of an arbitrary curve at a point. In this section, we solve these problems by finding the derivatives of functions that define $yy$ implicitly in terms of $x.x.$
### Implicit Differentiation
In most discussions of math, if the dependent variable $yy$ is a function of the independent variable $x,x,$ we express y in terms of $x.x.$ If this is the case, we say that $yy$ is an explicit function of $x.x.$ For example, when we write the equation $y=x2+1,y=x2+1,$ we are defining y explicitly in terms of $x.x.$ On the other hand, if the relationship between the function $yy$ and the variable $xx$ is expressed by an equation where $yy$ is not expressed entirely in terms of $x,x,$ we say that the equation defines y implicitly in terms of $x.x.$ For example, the equation $y−x2=1y−x2=1$ defines the function $y=x2+1y=x2+1$ implicitly.
Implicit differentiation allows us to find slopes of tangents to curves that are clearly not functions (they fail the vertical line test). We are using the idea that portions of $yy$ are functions that satisfy the given equation, but that $yy$ is not actually a function of $x.x.$
In general, an equation defines a function implicitly if the function satisfies that equation. An equation may define many different functions implicitly. For example, the functions
$y=25−x2y=25−x2$ and $y={25−x2if−5 which are illustrated in Figure 3.30, are just three of the many functions defined implicitly by the equation $x2+y2=25.x2+y2=25.$
Figure 3.30 The equation $x2+y2=25x2+y2=25$ defines many functions implicitly.
If we want to find the slope of the line tangent to the graph of $x2+y2=25x2+y2=25$ at the point $(3,4),(3,4),$ we could evaluate the derivative of the function $y=25−x2y=25−x2$ at $x=3.x=3.$ On the other hand, if we want the slope of the tangent line at the point $(3,−4),(3,−4),$ we could use the derivative of $y=−25−x2.y=−25−x2.$ However, it is not always easy to solve for a function defined implicitly by an equation. Fortunately, the technique of implicit differentiation allows us to find the derivative of an implicitly defined function without ever solving for the function explicitly. The process of finding $dydxdydx$ using implicit differentiation is described in the following problem-solving strategy.
Problem-Solving Strategy: Implicit Differentiation
To perform implicit differentiation on an equation that defines a function $yy$ implicitly in terms of a variable $x,x,$ use the following steps:
1. Take the derivative of both sides of the equation. Keep in mind that y is a function of x. Consequently, whereas $ddx(sinx)=cosx,ddx(siny)=cosydydxddx(sinx)=cosx,ddx(siny)=cosydydx$ because we must use the chain rule to differentiate $sinysiny$ with respect to $x.x.$
2. Rewrite the equation so that all terms containing $dydxdydx$ are on the left and all terms that do not contain $dydxdydx$ are on the right.
3. Factor out $dydxdydx$ on the left.
4. Solve for $dydxdydx$ by dividing both sides of the equation by an appropriate algebraic expression.
### Example 3.68
#### Using Implicit Differentiation
Assuming that $yy$ is defined implicitly by the equation $x2+y2=25,x2+y2=25,$ find $dydx.dydx.$
#### Solution
Follow the steps in the problem-solving strategy.
$ddx(x2+y2)=ddx(25)Step 1. Differentiate both sides of the equation.ddx(x2)+ddx(y2)=0Step 1.1. Use the sum rule on the left.On the rightddx(25)=0.2x+2ydydx=0Step 1.2. Take the derivatives, soddx(x2)=2xandddx(y2)=2ydydx.2ydydx=−2xStep 2. Keep the terms withdydxon the left.Move the remaining terms to the right.dydx=−xyStep 4. Divide both sides of the equation by2y.(Step 3 does not apply in this case.)ddx(x2+y2)=ddx(25)Step 1. Differentiate both sides of the equation.ddx(x2)+ddx(y2)=0Step 1.1. Use the sum rule on the left.On the rightddx(25)=0.2x+2ydydx=0Step 1.2. Take the derivatives, soddx(x2)=2xandddx(y2)=2ydydx.2ydydx=−2xStep 2. Keep the terms withdydxon the left.Move the remaining terms to the right.dydx=−xyStep 4. Divide both sides of the equation by2y.(Step 3 does not apply in this case.)$
#### Analysis
Note that the resulting expression for $dydxdydx$ is in terms of both the independent variable $xx$ and the dependent variable $y.y.$ Although in some cases it may be possible to express $dydxdydx$ in terms of $xx$ only, it is generally not possible to do so.
### Example 3.69
#### Using Implicit Differentiation and the Product Rule
Assuming that $yy$ is defined implicitly by the equation $x3siny+y=4x+3,x3siny+y=4x+3,$ find $dydx.dydx.$
#### Solution
$ddx(x3siny+y)=ddx(4x+3)Step 1: Differentiate both sides of the equation.ddx(x3siny)+ddx(y)=4Step 1.1: Apply the sum rule on the left.On the right,ddx(4x+3)=4.(ddx(x3)·siny+ddx(siny)·x3)+dydx=4Step 1.2: Use the product rule to findddx(x3siny).Observe thatddx(y)=dydx.3x2siny+(cosydydx)·x3+dydx=4Step 1.3: We knowddx(x3)=3x2.Use thechain rule to obtainddx(siny)=cosydydx.x3cosydydx+dydx=4−3x2sinyStep 2: Keep all terms containingdydxon theleft. Move all other terms to the right.dydx(x3cosy+1)=4−3x2sinyStep 3: Factor outdydxon the left.dydx=4−3x2sinyx3cosy+1Step 4: Solve fordydxby dividing both sides ofthe equation byx3cosy+1.ddx(x3siny+y)=ddx(4x+3)Step 1: Differentiate both sides of the equation.ddx(x3siny)+ddx(y)=4Step 1.1: Apply the sum rule on the left.On the right,ddx(4x+3)=4.(ddx(x3)·siny+ddx(siny)·x3)+dydx=4Step 1.2: Use the product rule to findddx(x3siny).Observe thatddx(y)=dydx.3x2siny+(cosydydx)·x3+dydx=4Step 1.3: We knowddx(x3)=3x2.Use thechain rule to obtainddx(siny)=cosydydx.x3cosydydx+dydx=4−3x2sinyStep 2: Keep all terms containingdydxon theleft. Move all other terms to the right.dydx(x3cosy+1)=4−3x2sinyStep 3: Factor outdydxon the left.dydx=4−3x2sinyx3cosy+1Step 4: Solve fordydxby dividing both sides ofthe equation byx3cosy+1.$
### Example 3.70
#### Using Implicit Differentiation to Find a Second Derivative
Find $d2ydx2d2ydx2$ if $x2+y2=25.x2+y2=25.$
#### Solution
In Example 3.68, we showed that $dydx=−xy.dydx=−xy.$ We can take the derivative of both sides of this equation to find $d2ydx2.d2ydx2.$
$d2ydx2=ddy(−xy)Differentiate both sides ofdydx=−xy.=−(1·y−xdydx)y2Use the quotient rule to findddy(−xy).=−y+xdydxy2Simplify.=−y+x(−xy)y2Substitutedydx=−xy.=−y2−x2y3Simplify.d2ydx2=ddy(−xy)Differentiate both sides ofdydx=−xy.=−(1·y−xdydx)y2Use the quotient rule to findddy(−xy).=−y+xdydxy2Simplify.=−y+x(−xy)y2Substitutedydx=−xy.=−y2−x2y3Simplify.$
At this point we have found an expression for $d2ydx2.d2ydx2.$ If we choose, we can simplify the expression further by recalling that $x2+y2=25x2+y2=25$ and making this substitution in the numerator to obtain $d2ydx2=−25y3.d2ydx2=−25y3.$
Checkpoint 3.48
Find $dydxdydx$ for $yy$ defined implicitly by the equation $4x5+tany=y2+5x.4x5+tany=y2+5x.$
### Finding Tangent Lines Implicitly
Now that we have seen the technique of implicit differentiation, we can apply it to the problem of finding equations of tangent lines to curves described by equations.
### Example 3.71
#### Finding a Tangent Line to a Circle
Find the equation of the line tangent to the curve $x2+y2=25x2+y2=25$ at the point $(3,−4).(3,−4).$
#### Solution
Although we could find this equation without using implicit differentiation, using that method makes it much easier. In Example 3.68, we found $dydx=−xy.dydx=−xy.$
The slope of the tangent line is found by substituting $(3,−4)(3,−4)$ into this expression. Consequently, the slope of the tangent line is $dydx|(3,−4)=−3−4=34.dydx|(3,−4)=−3−4=34.$
Using the point $(3,−4)(3,−4)$ and the slope $3434$ in the point-slope equation of the line, we obtain the equation $y=34x−254y=34x−254$ (Figure 3.31).
Figure 3.31 The line $y=34x−254y=34x−254$ is tangent to $x2+y2=25x2+y2=25$ at the point (3, −4).
### Example 3.72
#### Finding the Equation of the Tangent Line to a Curve
Find the equation of the line tangent to the graph of $y3+x3−3xy=0y3+x3−3xy=0$ at the point $(32,32)(32,32)$ (Figure 3.32). This curve is known as the folium (or leaf) of Descartes.
Figure 3.32 Finding the tangent line to the folium of Descartes at $(32,32).(32,32).$
#### Solution
Begin by finding $dydx.dydx.$
$ddx(y3+x3−3xy)=ddx(0)3y2dydx+3x2−(3y+dydx3x)=0dydx=3y−3x23y2−3x.ddx(y3+x3−3xy)=ddx(0)3y2dydx+3x2−(3y+dydx3x)=0dydx=3y−3x23y2−3x.$
Next, substitute $(32,32)(32,32)$ into $dydx=3y−3x23y2−3xdydx=3y−3x23y2−3x$ to find the slope of the tangent line:
$dydx|(32,32)=−1.dydx|(32,32)=−1.$
Finally, substitute into the point-slope equation of the line to obtain
$y=−x+3.y=−x+3.$
### Example 3.73
#### Applying Implicit Differentiation
In a simple video game, a rocket travels in an elliptical orbit whose path is described by the equation $4x2+25y2=100.4x2+25y2=100.$ The rocket can fire missiles along lines tangent to its path. The object of the game is to destroy an incoming asteroid traveling along the positive x-axis toward $(0,0).(0,0).$ If the rocket fires a missile when it is located at $(3,85),(3,85),$ where will it intersect the x-axis?
#### Solution
To solve this problem, we must determine where the line tangent to the graph of
$4x2+25y2=1004x2+25y2=100$ at $(3,85)(3,85)$ intersects the x-axis. Begin by finding $dydxdydx$ implicitly.
Differentiating, we have
$8x+50ydydx=0.8x+50ydydx=0.$
Solving for $dydx,dydx,$ we have
$dydx=−4x25y.dydx=−4x25y.$
The slope of the tangent line is $dydx|(3,85)=−310.dydx|(3,85)=−310.$ The equation of the tangent line is $y=−310x+52.y=−310x+52.$ To determine where the line intersects the x-axis, solve $0=−310x+52.0=−310x+52.$ The solution is $x=253.x=253.$ The missile intersects the x-axis at the point $(253,0).(253,0).$
Checkpoint 3.49
Find the equation of the line tangent to the hyperbola $x2−y2=16x2−y2=16$ at the point $(5,3).(5,3).$
### Section 3.8 Exercises
For the following exercises, use implicit differentiation to find $dydx.dydx.$
300.
$x2−y2=4x2−y2=4$
301.
$6x2+3y2=126x2+3y2=12$
302.
$x2y=y−7x2y=y−7$
303.
$3x3+9xy2=5x33x3+9xy2=5x3$
304.
$xy−cos(xy)=1xy−cos(xy)=1$
305.
$yx+4=xy+8yx+4=xy+8$
306.
$−xy−2=x7−xy−2=x7$
307.
$ysin(xy)=y2+2ysin(xy)=y2+2$
308.
$(xy)2+3x=y2(xy)2+3x=y2$
309.
$x3y+xy3=−8x3y+xy3=−8$
For the following exercises, find the equation of the tangent line to the graph of the given equation at the indicated point. Use a calculator or computer software to graph the function and the tangent line.
310.
[T] $x4y−xy3=−2,(−1,−1)x4y−xy3=−2,(−1,−1)$
311.
[T] $x2y2+5xy=14,(2,1)x2y2+5xy=14,(2,1)$
312.
[T] $tan(xy)=y,(π4,1)tan(xy)=y,(π4,1)$
313.
[T] $xy2+sin(πy)−2x2=10,(2,−3)xy2+sin(πy)−2x2=10,(2,−3)$
314.
[T] $xy+5x−7=−34y,(1,2)xy+5x−7=−34y,(1,2)$
315.
[T] $xy+sin(x)=1,(π2,0)xy+sin(x)=1,(π2,0)$
316.
[T] The graph of a folium of Descartes with equation $2x3+2y3−9xy=02x3+2y3−9xy=0$ is given in the following graph.
1. Find the equation of the tangent line at the point $(2,1).(2,1).$ Graph the tangent line along with the folium.
2. Find the equation of the normal line to the tangent line in a. at the point $(2,1).(2,1).$
317.
For the equation $x2+2xy−3y2=0,x2+2xy−3y2=0,$
1. Find the equation of the normal to the tangent line at the point $(1,1).(1,1).$
2. At what other point does the normal line in a. intersect the graph of the equation?
318.
Find all points on the graph of $y3−27y=x2−90y3−27y=x2−90$ at which the tangent line is vertical.
319.
For the equation $x2+xy+y2=7,x2+xy+y2=7,$
1. Find the $xx$-intercept(s).
2. Find the slope of the tangent line(s) at the x-intercept(s).
3. What does the value(s) in b. indicate about the tangent line(s)?
320.
Find the equation of the tangent line to the graph of the equation $sin−1x+sin−1y=π6sin−1x+sin−1y=π6$ at the point $(0,12).(0,12).$
321.
Find the equation of the tangent line to the graph of the equation $tan−1(x+y)=x2+π4tan−1(x+y)=x2+π4$ at the point $(0,1).(0,1).$
322.
Find $y′y′$ and $y″y″$ for $x2+6xy−2y2=3.x2+6xy−2y2=3.$
323.
[T] The number of cell phones produced when $xx$ dollars is spent on labor and $yy$ dollars is spent on capital invested by a manufacturer can be modeled by the equation $60x3/4y1/4=3240.60x3/4y1/4=3240.$
1. Find $dydxdydx$ and evaluate at the point $(81,16).(81,16).$
2. Interpret the result of a.
324.
[T] The number of cars produced when $xx$ dollars is spent on labor and $yy$ dollars is spent on capital invested by a manufacturer can be modeled by the equation $30x1/3y2/3=360.30x1/3y2/3=360.$
(Both $xx$ and $yy$ are measured in thousands of dollars.)
1. Find $dydxdydx$ and evaluate at the point $(27,8).(27,8).$
2. Interpret the result of a.
325.
The volume of a right circular cone of radius $xx$ and height $yy$ is given by $V=13πx2y.V=13πx2y.$ Suppose that the volume of the cone is $85πcm3.85πcm3.$ Find $dydxdydx$ when $x=4x=4$ and $y=16.y=16.$
For the following exercises, consider a closed rectangular box with a square base with side $xx$ and height $y.y.$
326.
Find an equation for the surface area of the rectangular box, $S(x,y).S(x,y).$
327.
If the surface area of the rectangular box is 78 square feet, find $dydxdydx$ when $x=3x=3$ feet and $y=5y=5$ feet.
For the following exercises, use implicit differentiation to determine $y′.y′.$ Does the answer agree with the formulas we have previously determined?
328.
$x=sinyx=siny$
329.
$x=cosyx=cosy$
330.
$x=tanyx=tany$
|
2019-12-13 16:12:02
|
{"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 159, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9450500011444092, "perplexity": 473.20837076742345}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-51/segments/1575540564599.32/warc/CC-MAIN-20191213150805-20191213174805-00449.warc.gz"}
|