
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 46 51 | id int64 599M 2.8B | node_id stringlengths 18 32 | number int64 1 7.38k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 0 | created_at timestamp[ns, tz=UTC] | updated_at timestamp[ns, tz=UTC] | closed_at timestamp[us] | author_association stringclasses 4
values | sub_issues_summary dict | active_lock_reason float64 | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | draft float64 0 1 ⌀ | pull_request dict | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/315 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/315/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/315/comments | https://api.github.com/repos/huggingface/datasets/issues/315/events | https://github.com/huggingface/datasets/issues/315 | 645,888,943 | MDU6SXNzdWU2NDU4ODg5NDM= | 315 | [Question] Best way to batch a large dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists... | [
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | open | false | null | [] | null | [] | 2020-06-25T22:30:20Z | 2020-10-27T15:38:17Z | 1970-01-01T00:00:00 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I'm training on large datasets such as Wikipedia and BookCorpus. Following the instructions in [the tutorial notebook](https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb), I see the following recommended for TensorFlow:
```python
train_tf_dataset = train_tf_dataset.filter(... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/315/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/315/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/314 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/314/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/314/comments | https://api.github.com/repos/huggingface/datasets/issues/314/events | https://github.com/huggingface/datasets/pull/314 | 645,461,174 | MDExOlB1bGxSZXF1ZXN0NDM5OTM4MTMw | 314 | Fixed singlular very minor spelling error | {
"avatar_url": "https://avatars.githubusercontent.com/u/40696362?v=4",
"events_url": "https://api.github.com/users/SchizoidBat/events{/privacy}",
"followers_url": "https://api.github.com/users/SchizoidBat/followers",
"following_url": "https://api.github.com/users/SchizoidBat/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-06-25T10:45:59Z | 2020-06-26T08:46:41Z | 2020-06-25T12:43:59 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | An instance of "independantly" was changed to "independently". That's all. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/314/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/314/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/314.diff",
"html_url": "https://github.com/huggingface/datasets/pull/314",
"merged_at": "2020-06-25T12:43:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/314.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/314... | true |
https://api.github.com/repos/huggingface/datasets/issues/313 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/313/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/313/comments | https://api.github.com/repos/huggingface/datasets/issues/313/events | https://github.com/huggingface/datasets/pull/313 | 645,390,088 | MDExOlB1bGxSZXF1ZXN0NDM5ODc4MDg5 | 313 | Add MWSC | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/followin... | null | [] | 2020-06-25T09:22:02Z | 2020-06-30T08:28:11Z | 2020-06-30T08:28:11 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Adding the [Modified Winograd Schema Challenge](https://github.com/salesforce/decaNLP/blob/master/local_data/schema.txt) dataset which formed part of the [decaNLP](http://decanlp.com/) benchmark. Not sure how much use people would find for it it outside of the benchmark, but it is general purpose.
Code is heavily bo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/313/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/313/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/313.diff",
"html_url": "https://github.com/huggingface/datasets/pull/313",
"merged_at": "2020-06-30T08:28:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/313.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/313... | true |
https://api.github.com/repos/huggingface/datasets/issues/312 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/312/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/312/comments | https://api.github.com/repos/huggingface/datasets/issues/312/events | https://github.com/huggingface/datasets/issues/312 | 645,025,561 | MDU6SXNzdWU2NDUwMjU1NjE= | 312 | [Feature request] Add `shard()` method to dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/4564897?v=4",
"events_url": "https://api.github.com/users/jarednielsen/events{/privacy}",
"followers_url": "https://api.github.com/users/jarednielsen/followers",
"following_url": "https://api.github.com/users/jarednielsen/following{/other_user}",
"gists... | [] | closed | false | null | [] | null | [] | 2020-06-24T22:48:33Z | 2020-07-06T12:35:36Z | 2020-07-06T12:35:36 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Currently, to shard a dataset into 10 pieces on different ranks, you can run
```python
rank = 3 # for example
size = 10
dataset = nlp.load_dataset('wikitext', 'wikitext-2-raw-v1', split=f"train[{rank*10}%:{(rank+1)*10}%]")
```
However, this breaks down if you have a number of ranks that doesn't divide cleanly... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/312/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/312/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/311/comments | https://api.github.com/repos/huggingface/datasets/issues/311/events | https://github.com/huggingface/datasets/pull/311 | 645,013,131 | MDExOlB1bGxSZXF1ZXN0NDM5NTQ3OTg0 | 311 | Add qa_zre | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-06-24T22:17:22Z | 2020-06-29T16:37:38Z | 2020-06-29T16:37:38 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Adding the QA-ZRE dataset from ["Zero-Shot Relation Extraction via Reading Comprehension"](http://nlp.cs.washington.edu/zeroshot/).
A common processing step seems to be replacing the `XXX` placeholder with the `subject`. I've left this out as it's something you could easily do with `map`. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/311/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/311/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/311.diff",
"html_url": "https://github.com/huggingface/datasets/pull/311",
"merged_at": "2020-06-29T16:37:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/311.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/311... | true |
https://api.github.com/repos/huggingface/datasets/issues/310 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/310/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/310/comments | https://api.github.com/repos/huggingface/datasets/issues/310/events | https://github.com/huggingface/datasets/pull/310 | 644,806,720 | MDExOlB1bGxSZXF1ZXN0NDM5MzY1MDg5 | 310 | add wikisql | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-06-24T18:00:35Z | 2020-06-25T12:32:25Z | 2020-06-25T12:32:25 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Adding the [WikiSQL](https://github.com/salesforce/WikiSQL) dataset.
Interesting things to note:
- Have copied the function (`_convert_to_human_readable`) which converts the SQL query to a human-readable (string) format as this is what most people will want when actually using this dataset for NLP applications.
- ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/310/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/310/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/310.diff",
"html_url": "https://github.com/huggingface/datasets/pull/310",
"merged_at": "2020-06-25T12:32:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/310.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/310... | true |
https://api.github.com/repos/huggingface/datasets/issues/309 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/309/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/309/comments | https://api.github.com/repos/huggingface/datasets/issues/309/events | https://github.com/huggingface/datasets/pull/309 | 644,783,822 | MDExOlB1bGxSZXF1ZXN0NDM5MzQ1NzYz | 309 | Add narrative qa | {
"avatar_url": "https://avatars.githubusercontent.com/u/8019486?v=4",
"events_url": "https://api.github.com/users/Varal7/events{/privacy}",
"followers_url": "https://api.github.com/users/Varal7/followers",
"following_url": "https://api.github.com/users/Varal7/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [] | 2020-06-24T17:26:18Z | 2020-09-03T09:02:10Z | 2020-09-03T09:02:09 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Test cases for dummy data don't pass
Only contains data for summaries (not whole story) | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/309/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/309/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/309.diff",
"html_url": "https://github.com/huggingface/datasets/pull/309",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/309.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/309"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/308 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/308/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/308/comments | https://api.github.com/repos/huggingface/datasets/issues/308/events | https://github.com/huggingface/datasets/pull/308 | 644,195,251 | MDExOlB1bGxSZXF1ZXN0NDM4ODYyMzYy | 308 | Specify utf-8 encoding for MRPC files | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-23T22:44:36Z | 2020-06-25T12:52:21Z | 2020-06-25T12:16:10 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Fixes #307, again probably a Windows-related issue. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/308/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/308/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/308.diff",
"html_url": "https://github.com/huggingface/datasets/pull/308",
"merged_at": "2020-06-25T12:16:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/308.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/308... | true |
https://api.github.com/repos/huggingface/datasets/issues/307 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/307/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/307/comments | https://api.github.com/repos/huggingface/datasets/issues/307/events | https://github.com/huggingface/datasets/issues/307 | 644,187,262 | MDU6SXNzdWU2NDQxODcyNjI= | 307 | Specify encoding for MRPC | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-23T22:24:49Z | 2020-06-25T12:16:09Z | 2020-06-25T12:16:09 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Same as #242, but with MRPC: on Windows, I get a `UnicodeDecodeError` when I try to download the dataset:
```python
dataset = nlp.load_dataset('glue', 'mrpc')
```
```python
Downloading and preparing dataset glue/mrpc (download: Unknown size, generated: Unknown size, total: Unknown size) to C:\Users\Python\.cache... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/307/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/307/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/306/comments | https://api.github.com/repos/huggingface/datasets/issues/306/events | https://github.com/huggingface/datasets/pull/306 | 644,176,078 | MDExOlB1bGxSZXF1ZXN0NDM4ODQ2MTI3 | 306 | add pg19 dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/108653?v=4",
"events_url": "https://api.github.com/users/lucidrains/events{/privacy}",
"followers_url": "https://api.github.com/users/lucidrains/followers",
"following_url": "https://api.github.com/users/lucidrains/following{/other_user}",
"gists_url": ... | [] | closed | false | null | [] | null | [] | 2020-06-23T22:03:52Z | 2020-07-06T07:55:59Z | 2020-07-06T07:55:59 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | https://github.com/huggingface/nlp/issues/274
Add functioning PG19 dataset with dummy data
`cos_e.py` was just auto-linted by `make style` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/306/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/306/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/306.diff",
"html_url": "https://github.com/huggingface/datasets/pull/306",
"merged_at": "2020-07-06T07:55:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/306.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/306... | true |
https://api.github.com/repos/huggingface/datasets/issues/305 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/305/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/305/comments | https://api.github.com/repos/huggingface/datasets/issues/305/events | https://github.com/huggingface/datasets/issues/305 | 644,148,149 | MDU6SXNzdWU2NDQxNDgxNDk= | 305 | Importing downloaded package repository fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] | closed | false | null | [] | null | [] | 2020-06-23T21:09:05Z | 2020-07-30T16:44:23Z | 2020-07-30T16:44:23 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | The `get_imports` function in `src/nlp/load.py` has a feature to download a package as a zip archive of the github repository and import functions from the unpacked directory. This is used for example in the `metrics/coval.py` file, and would be useful to add BLEURT (@ankparikh).
Currently however, the code seems to... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/305/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/305/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/304/comments | https://api.github.com/repos/huggingface/datasets/issues/304/events | https://github.com/huggingface/datasets/issues/304 | 644,091,970 | MDU6SXNzdWU2NDQwOTE5NzA= | 304 | Problem while printing doc string when instantiating multiple metrics. | {
"avatar_url": "https://avatars.githubusercontent.com/u/51091425?v=4",
"events_url": "https://api.github.com/users/codehunk628/events{/privacy}",
"followers_url": "https://api.github.com/users/codehunk628/followers",
"following_url": "https://api.github.com/users/codehunk628/following{/other_user}",
"gists_u... | [
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] | closed | false | null | [] | null | [] | 2020-06-23T19:32:05Z | 2020-07-22T09:50:58Z | 2020-07-22T09:50:58 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When I load more than one metric and try to print doc string of a particular metric,. It shows the doc strings of all imported metric one after the other which looks quite confusing and clumsy.
Attached [Colab](https://colab.research.google.com/drive/13H0ZgyQ2se0mqJ2yyew0bNEgJuHaJ8H3?usp=sharing) Notebook for problem ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/304/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/303 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/303/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/303/comments | https://api.github.com/repos/huggingface/datasets/issues/303/events | https://github.com/huggingface/datasets/pull/303 | 643,912,464 | MDExOlB1bGxSZXF1ZXN0NDM4NjI3Nzcw | 303 | allow to move files across file systems | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-23T14:56:08Z | 2020-06-23T15:08:44Z | 2020-06-23T15:08:43 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Users are allowed to use the `cache_dir` that they want.
Therefore it can happen that we try to move files across filesystems.
We were using `os.rename` that doesn't allow that, so I changed some of them to `shutil.move`.
This should fix #301 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/303/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/303/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/303.diff",
"html_url": "https://github.com/huggingface/datasets/pull/303",
"merged_at": "2020-06-23T15:08:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/303.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/303... | true |
https://api.github.com/repos/huggingface/datasets/issues/302 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/302/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/302/comments | https://api.github.com/repos/huggingface/datasets/issues/302/events | https://github.com/huggingface/datasets/issues/302 | 643,910,418 | MDU6SXNzdWU2NDM5MTA0MTg= | 302 | Question - Sign Language Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [] | 2020-06-23T14:53:40Z | 2020-11-25T11:25:33Z | 2020-11-25T11:25:33 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | An emerging field in NLP is SLP - sign language processing.
I was wondering about adding datasets here, specifically because it's shaping up to be large and easily usable.
The metrics for sign language to text translation are the same.
So, what do you think about (me, or others) adding datasets here?
An exa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5757359?v=4",
"events_url": "https://api.github.com/users/AmitMY/events{/privacy}",
"followers_url": "https://api.github.com/users/AmitMY/followers",
"following_url": "https://api.github.com/users/AmitMY/following{/other_user}",
"gists_url": "https://ap... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/302/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/302/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/301 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/301/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/301/comments | https://api.github.com/repos/huggingface/datasets/issues/301/events | https://github.com/huggingface/datasets/issues/301 | 643,763,525 | MDU6SXNzdWU2NDM3NjM1MjU= | 301 | Setting cache_dir gives error on wikipedia download | {
"avatar_url": "https://avatars.githubusercontent.com/u/33862536?v=4",
"events_url": "https://api.github.com/users/hallvagi/events{/privacy}",
"followers_url": "https://api.github.com/users/hallvagi/followers",
"following_url": "https://api.github.com/users/hallvagi/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-23T11:31:44Z | 2020-06-24T07:05:07Z | 2020-06-24T07:05:07 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | First of all thank you for a super handy library! I'd like to download large files to a specific drive so I set `cache_dir=my_path`. This works fine with e.g. imdb and squad. But on wikipedia I get an error:
```
nlp.load_dataset('wikipedia', '20200501.de', split = 'train', cache_dir=my_path)
```
```
OSError ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/33862536?v=4",
"events_url": "https://api.github.com/users/hallvagi/events{/privacy}",
"followers_url": "https://api.github.com/users/hallvagi/followers",
"following_url": "https://api.github.com/users/hallvagi/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/301/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/301/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/300/comments | https://api.github.com/repos/huggingface/datasets/issues/300/events | https://github.com/huggingface/datasets/pull/300 | 643,688,304 | MDExOlB1bGxSZXF1ZXN0NDM4NDQ4Mjk1 | 300 | Fix bertscore references | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-23T09:38:59Z | 2020-06-23T14:47:38Z | 2020-06-23T14:47:37 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I added some type checking for metrics. There was an issue where a metric could interpret a string a a list. A `ValueError` is raised if a string is given instead of a list.
Moreover I added support for both strings and lists of strings for `references` in `bertscore`, as it is the case in the original code.
Both... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/300/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/300/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/300.diff",
"html_url": "https://github.com/huggingface/datasets/pull/300",
"merged_at": "2020-06-23T14:47:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/300.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/300... | true |
https://api.github.com/repos/huggingface/datasets/issues/299 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/299/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/299/comments | https://api.github.com/repos/huggingface/datasets/issues/299/events | https://github.com/huggingface/datasets/pull/299 | 643,611,557 | MDExOlB1bGxSZXF1ZXN0NDM4Mzg0NDgw | 299 | remove some print in snli file | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-06-23T07:46:06Z | 2020-06-23T08:10:46Z | 2020-06-23T08:10:44 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR removes unwanted `print` statements in some files such as `snli.py` | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/299/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/299/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/299.diff",
"html_url": "https://github.com/huggingface/datasets/pull/299",
"merged_at": "2020-06-23T08:10:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/299.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/299... | true |
https://api.github.com/repos/huggingface/datasets/issues/298 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/298/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/298/comments | https://api.github.com/repos/huggingface/datasets/issues/298/events | https://github.com/huggingface/datasets/pull/298 | 643,603,804 | MDExOlB1bGxSZXF1ZXN0NDM4Mzc4MDM4 | 298 | Add searchable datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-23T07:33:03Z | 2020-06-26T07:50:44Z | 2020-06-26T07:50:43 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | # Better support for Numpy format + Add Indexed Datasets
I was working on adding Indexed Datasets but in the meantime I had to also add more support for Numpy arrays in the lib.
## Better support for Numpy format
New features:
- New fast method to convert Numpy arrays from Arrow structure (up to x100 speed up... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 1,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/298/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/298/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/298.diff",
"html_url": "https://github.com/huggingface/datasets/pull/298",
"merged_at": "2020-06-26T07:50:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/298.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/298... | true |
https://api.github.com/repos/huggingface/datasets/issues/297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/297/comments | https://api.github.com/repos/huggingface/datasets/issues/297/events | https://github.com/huggingface/datasets/issues/297 | 643,444,625 | MDU6SXNzdWU2NDM0NDQ2MjU= | 297 | Error in Demo for Specific Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/60150701?v=4",
"events_url": "https://api.github.com/users/s-jse/events{/privacy}",
"followers_url": "https://api.github.com/users/s-jse/followers",
"following_url": "https://api.github.com/users/s-jse/following{/other_user}",
"gists_url": "https://api.... | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | [] | null | [] | 2020-06-23T00:38:42Z | 2020-07-17T17:43:06Z | 2020-07-17T17:43:06 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Selecting `natural_questions` or `newsroom` dataset in the online demo results in an error similar to the following.

| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/297/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/297/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/296 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/296/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/296/comments | https://api.github.com/repos/huggingface/datasets/issues/296/events | https://github.com/huggingface/datasets/issues/296 | 643,423,717 | MDU6SXNzdWU2NDM0MjM3MTc= | 296 | snli -1 labels | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2020-06-22T23:33:30Z | 2020-06-23T14:41:59Z | 2020-06-23T14:41:58 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I'm trying to train a model on the SNLI dataset. Why does it have so many -1 labels?
```
import nlp
from collections import Counter
data = nlp.load_dataset('snli')['train']
print(Counter(data['label']))
Counter({0: 183416, 2: 183187, 1: 182764, -1: 785})
```
| {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/296/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/296/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/295 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/295/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/295/comments | https://api.github.com/repos/huggingface/datasets/issues/295/events | https://github.com/huggingface/datasets/issues/295 | 643,245,412 | MDU6SXNzdWU2NDMyNDU0MTI= | 295 | Improve input warning for evaluation metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/19514537?v=4",
"events_url": "https://api.github.com/users/Tiiiger/events{/privacy}",
"followers_url": "https://api.github.com/users/Tiiiger/followers",
"following_url": "https://api.github.com/users/Tiiiger/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-22T17:28:57Z | 2020-06-23T14:47:37Z | 2020-06-23T14:47:37 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi,
I am the author of `bert_score`. Recently, we received [ an issue ](https://github.com/Tiiiger/bert_score/issues/62) reporting a problem in using `bert_score` from the `nlp` package (also see #238 in this repo). After looking into this, I realized that the problem arises from the format `nlp.Metric` takes inpu... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/295/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/295/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/294 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/294/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/294/comments | https://api.github.com/repos/huggingface/datasets/issues/294/events | https://github.com/huggingface/datasets/issues/294 | 643,181,179 | MDU6SXNzdWU2NDMxODExNzk= | 294 | Cannot load arxiv dataset on MacOS? | {
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url":... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [] | 2020-06-22T15:46:55Z | 2020-06-30T15:25:10Z | 2020-06-30T15:25:10 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I am having trouble loading the `"arxiv"` config from the `"scientific_papers"` dataset on MacOS. When I try loading the dataset with:
```python
arxiv = nlp.load_dataset("scientific_papers", "arxiv")
```
I get the following stack trace:
```bash
JSONDecodeError Traceback (most recen... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8917831?v=4",
"events_url": "https://api.github.com/users/JohnGiorgi/events{/privacy}",
"followers_url": "https://api.github.com/users/JohnGiorgi/followers",
"following_url": "https://api.github.com/users/JohnGiorgi/following{/other_user}",
"gists_url":... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/294/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/294/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/293 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/293/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/293/comments | https://api.github.com/repos/huggingface/datasets/issues/293/events | https://github.com/huggingface/datasets/pull/293 | 642,942,182 | MDExOlB1bGxSZXF1ZXN0NDM3ODM1ODI4 | 293 | Don't test community datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-22T10:15:33Z | 2020-06-22T11:07:00Z | 2020-06-22T11:06:59 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR disables testing for community datasets on aws.
It should fix the CI that is currently failing. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/293/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/293/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/293.diff",
"html_url": "https://github.com/huggingface/datasets/pull/293",
"merged_at": "2020-06-22T11:06:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/293.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/293... | true |
https://api.github.com/repos/huggingface/datasets/issues/292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/292/comments | https://api.github.com/repos/huggingface/datasets/issues/292/events | https://github.com/huggingface/datasets/pull/292 | 642,897,797 | MDExOlB1bGxSZXF1ZXN0NDM3Nzk4NTM2 | 292 | Update metadata for x_stance dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/5830820?v=4",
"events_url": "https://api.github.com/users/jvamvas/events{/privacy}",
"followers_url": "https://api.github.com/users/jvamvas/followers",
"following_url": "https://api.github.com/users/jvamvas/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2020-06-22T09:13:26Z | 2020-06-23T08:07:24Z | 2020-06-23T08:07:24 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Thank you for featuring the x_stance dataset in your library. This PR updates some metadata:
- Citation: Replace preprint with proceedings
- URL: Use a URL with long-term availability
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/292/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/292.diff",
"html_url": "https://github.com/huggingface/datasets/pull/292",
"merged_at": "2020-06-23T08:07:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/292.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/292... | true |
https://api.github.com/repos/huggingface/datasets/issues/291 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/291/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/291/comments | https://api.github.com/repos/huggingface/datasets/issues/291/events | https://github.com/huggingface/datasets/pull/291 | 642,688,450 | MDExOlB1bGxSZXF1ZXN0NDM3NjM1NjMy | 291 | break statement not required | {
"avatar_url": "https://avatars.githubusercontent.com/u/12967587?v=4",
"events_url": "https://api.github.com/users/mayurnewase/events{/privacy}",
"followers_url": "https://api.github.com/users/mayurnewase/followers",
"following_url": "https://api.github.com/users/mayurnewase/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-06-22T01:40:55Z | 2020-06-23T17:57:58Z | 2020-06-23T09:37:02 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/291/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/291/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/291.diff",
"html_url": "https://github.com/huggingface/datasets/pull/291",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/291.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/291"
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/290 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/290/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/290/comments | https://api.github.com/repos/huggingface/datasets/issues/290/events | https://github.com/huggingface/datasets/issues/290 | 641,978,286 | MDU6SXNzdWU2NDE5NzgyODY= | 290 | ConnectionError - Eli5 dataset download | {
"avatar_url": "https://avatars.githubusercontent.com/u/8490096?v=4",
"events_url": "https://api.github.com/users/JovanNj/events{/privacy}",
"followers_url": "https://api.github.com/users/JovanNj/followers",
"following_url": "https://api.github.com/users/JovanNj/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2020-06-19T13:40:33Z | 2020-06-20T13:22:24Z | 2020-06-20T13:22:24 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, I have a problem with downloading Eli5 dataset. When typing `nlp.load_dataset('eli5')`, I get ConnectionError: Couldn't reach https://storage.googleapis.com/huggingface-nlp/cache/datasets/eli5/LFQA_reddit/1.0.0/explain_like_im_five-train_eli5.arrow
I would appreciate if you could help me with this issue. | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/290/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/290/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/289 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/289/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/289/comments | https://api.github.com/repos/huggingface/datasets/issues/289/events | https://github.com/huggingface/datasets/pull/289 | 641,934,194 | MDExOlB1bGxSZXF1ZXN0NDM3MDc0MTM3 | 289 | update xsum | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-06-19T12:28:32Z | 2020-06-22T13:27:26Z | 2020-06-22T07:20:07 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR makes the following update to the xsum dataset:
- Manual download is not required anymore
- dataset can be loaded as follow: `nlp.load_dataset('xsum')`
**Important**
Instead of using on outdated url to download the data: "https://raw.githubusercontent.com/EdinburghNLP/XSum/master/XSum-Dataset/XSum... | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/289/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/289/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/289.diff",
"html_url": "https://github.com/huggingface/datasets/pull/289",
"merged_at": "2020-06-22T07:20:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/289.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/289... | true |
https://api.github.com/repos/huggingface/datasets/issues/288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/288/comments | https://api.github.com/repos/huggingface/datasets/issues/288/events | https://github.com/huggingface/datasets/issues/288 | 641,888,610 | MDU6SXNzdWU2NDE4ODg2MTA= | 288 | Error at the first example in README: AttributeError: module 'dill' has no attribute '_dill' | {
"avatar_url": "https://avatars.githubusercontent.com/u/14964542?v=4",
"events_url": "https://api.github.com/users/wutong8023/events{/privacy}",
"followers_url": "https://api.github.com/users/wutong8023/followers",
"following_url": "https://api.github.com/users/wutong8023/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2020-06-19T11:01:22Z | 2020-06-21T09:05:11Z | 2020-06-21T09:05:11 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | /Users/parasol_tree/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:469: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/Users/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/288/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/287 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/287/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/287/comments | https://api.github.com/repos/huggingface/datasets/issues/287/events | https://github.com/huggingface/datasets/pull/287 | 641,800,227 | MDExOlB1bGxSZXF1ZXN0NDM2OTY0NTg0 | 287 | fix squad_v2 metric | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-19T08:24:46Z | 2020-06-19T08:33:43Z | 2020-06-19T08:33:41 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Fix #280
The imports were wrong | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/287/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/287/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/287.diff",
"html_url": "https://github.com/huggingface/datasets/pull/287",
"merged_at": "2020-06-19T08:33:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/287.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/287... | true |
https://api.github.com/repos/huggingface/datasets/issues/286 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/286/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/286/comments | https://api.github.com/repos/huggingface/datasets/issues/286/events | https://github.com/huggingface/datasets/pull/286 | 641,585,758 | MDExOlB1bGxSZXF1ZXN0NDM2NzkzMjI4 | 286 | Add ANLI dataset. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11016329?v=4",
"events_url": "https://api.github.com/users/easonnie/events{/privacy}",
"followers_url": "https://api.github.com/users/easonnie/followers",
"following_url": "https://api.github.com/users/easonnie/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-18T22:27:30Z | 2020-06-22T12:23:27Z | 2020-06-22T12:23:27 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I completed all the steps in https://github.com/huggingface/nlp/blob/master/CONTRIBUTING.md#how-to-add-a-dataset and push the code for ANLI. Please let me know if there are any errors. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/286/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/286/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/286.diff",
"html_url": "https://github.com/huggingface/datasets/pull/286",
"merged_at": "2020-06-22T12:23:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/286.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/286... | true |
https://api.github.com/repos/huggingface/datasets/issues/285 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/285/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/285/comments | https://api.github.com/repos/huggingface/datasets/issues/285/events | https://github.com/huggingface/datasets/pull/285 | 641,360,702 | MDExOlB1bGxSZXF1ZXN0NDM2NjAyMjk4 | 285 | Consistent formatting of citations | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-06-18T16:25:23Z | 2020-06-22T08:09:25Z | 2020-06-22T08:09:24 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | #283 | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/285/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/285/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/285.diff",
"html_url": "https://github.com/huggingface/datasets/pull/285",
"merged_at": "2020-06-22T08:09:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/285.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/285... | true |
https://api.github.com/repos/huggingface/datasets/issues/284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/284/comments | https://api.github.com/repos/huggingface/datasets/issues/284/events | https://github.com/huggingface/datasets/pull/284 | 641,337,217 | MDExOlB1bGxSZXF1ZXN0NDM2NTgxODQ2 | 284 | Fix manual download instructions | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-06-18T15:59:57Z | 2020-06-19T08:24:21Z | 2020-06-19T08:24:19 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR replaces the static `DatasetBulider` variable `MANUAL_DOWNLOAD_INSTRUCTIONS` by a property function `manual_download_instructions()`.
Some datasets like XTREME and all WMT need the manual data dir only for a small fraction of the possible configs.
After some brainstorming with @mariamabarham and @lhoestq... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/284/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/284/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/284.diff",
"html_url": "https://github.com/huggingface/datasets/pull/284",
"merged_at": "2020-06-19T08:24:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/284.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/284... | true |
https://api.github.com/repos/huggingface/datasets/issues/283 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/283/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/283/comments | https://api.github.com/repos/huggingface/datasets/issues/283/events | https://github.com/huggingface/datasets/issues/283 | 641,270,439 | MDU6SXNzdWU2NDEyNzA0Mzk= | 283 | Consistent formatting of citations | {
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_... | null | [] | 2020-06-18T14:48:45Z | 2020-06-22T17:30:46Z | 2020-06-22T17:30:46 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | The citations are all of a different format, some have "```" and have text inside, others are proper bibtex.
Can we make it so that they all are proper citations, i.e. parse by the bibtex spec:
https://bibtexparser.readthedocs.io/en/master/ | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/283/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/283/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/282 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/282/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/282/comments | https://api.github.com/repos/huggingface/datasets/issues/282/events | https://github.com/huggingface/datasets/pull/282 | 641,217,759 | MDExOlB1bGxSZXF1ZXN0NDM2NDgxNzMy | 282 | Update dataset_info from gcs | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-18T13:41:15Z | 2020-06-18T16:24:52Z | 2020-06-18T16:24:51 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Some datasets are hosted on gcs (wikipedia for example). In this PR I make sure that, when a user loads such datasets, the file_instructions are built using the dataset_info.json from gcs and not from the info extracted from the local `dataset_infos.json` (the one that contain the info for each config). Indeed local fi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/282/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/282/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/282.diff",
"html_url": "https://github.com/huggingface/datasets/pull/282",
"merged_at": "2020-06-18T16:24:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/282.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/282... | true |
https://api.github.com/repos/huggingface/datasets/issues/281 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/281/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/281/comments | https://api.github.com/repos/huggingface/datasets/issues/281/events | https://github.com/huggingface/datasets/issues/281 | 641,067,856 | MDU6SXNzdWU2NDEwNjc4NTY= | 281 | Private/sensitive data | {
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [] | 2020-06-18T09:47:27Z | 2020-06-20T13:15:12Z | 2020-06-20T13:15:12 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi all,
Thanks for this fantastic library, it makes it very easy to do prototyping for NLP projects interchangeably between TF/Pytorch.
Unfortunately, there is data that cannot easily be shared publicly as it may contain sensitive information.
Is there support/a plan to support such data with NLP, e.g. by readin... | {
"avatar_url": "https://avatars.githubusercontent.com/u/6368040?v=4",
"events_url": "https://api.github.com/users/MFreidank/events{/privacy}",
"followers_url": "https://api.github.com/users/MFreidank/followers",
"following_url": "https://api.github.com/users/MFreidank/following{/other_user}",
"gists_url": "h... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/281/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/281/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/280/comments | https://api.github.com/repos/huggingface/datasets/issues/280/events | https://github.com/huggingface/datasets/issues/280 | 640,677,615 | MDU6SXNzdWU2NDA2Nzc2MTU= | 280 | Error with SquadV2 Metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/32203792?v=4",
"events_url": "https://api.github.com/users/avinregmi/events{/privacy}",
"followers_url": "https://api.github.com/users/avinregmi/followers",
"following_url": "https://api.github.com/users/avinregmi/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2020-06-17T19:10:54Z | 2020-06-19T08:33:41Z | 2020-06-19T08:33:41 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I can't seem to import squad v2 metrics.
**squad_metric = nlp.load_metric('squad_v2')**
**This throws me an error.:**
```
ImportError Traceback (most recent call last)
<ipython-input-8-170b6a170555> in <module>
----> 1 squad_metric = nlp.load_metric('squad_v2')
~/env/lib6... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/280/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/279 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/279/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/279/comments | https://api.github.com/repos/huggingface/datasets/issues/279/events | https://github.com/huggingface/datasets/issues/279 | 640,611,692 | MDU6SXNzdWU2NDA2MTE2OTI= | 279 | Dataset Preprocessing Cache with .map() function not working as expected | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-06-17T17:17:21Z | 2021-07-06T21:43:28Z | 2021-04-18T23:43:49 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I've been having issues with reproducibility when loading and processing datasets with the `.map` function. I was only able to resolve them by clearing all of the cache files on my system.
Is there a way to disable using the cache when processing a dataset? As I make minor processing changes on the same dataset, I ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/279/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/279/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/278 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/278/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/278/comments | https://api.github.com/repos/huggingface/datasets/issues/278/events | https://github.com/huggingface/datasets/issues/278 | 640,518,917 | MDU6SXNzdWU2NDA1MTg5MTc= | 278 | MemoryError when loading German Wikipedia | {
"avatar_url": "https://avatars.githubusercontent.com/u/4698028?v=4",
"events_url": "https://api.github.com/users/gregburman/events{/privacy}",
"followers_url": "https://api.github.com/users/gregburman/followers",
"following_url": "https://api.github.com/users/gregburman/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [] | 2020-06-17T15:06:21Z | 2020-06-19T12:53:02Z | 2020-06-19T12:53:02 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, first off let me say thank you for all the awesome work you're doing at Hugging Face across all your projects (NLP, Transformers, Tokenizers) - they're all amazing contributions to us working with NLP models :)
I'm trying to download the German Wikipedia dataset as follows:
```
wiki = nlp.load_dataset("wikip... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/278/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/278/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/277 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/277/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/277/comments | https://api.github.com/repos/huggingface/datasets/issues/277/events | https://github.com/huggingface/datasets/issues/277 | 640,163,053 | MDU6SXNzdWU2NDAxNjMwNTM= | 277 | Empty samples in glue/qqp | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-06-17T05:54:52Z | 2020-06-21T00:21:45Z | 2020-06-21T00:21:45 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ```
qqp = nlp.load_dataset('glue', 'qqp')
print(qqp['train'][310121])
print(qqp['train'][362225])
```
```
{'question1': 'How can I create an Android app?', 'question2': '', 'label': 0, 'idx': 310137}
{'question1': 'How can I develop android app?', 'question2': '', 'label': 0, 'idx': 362246}
```
Notice that que... | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/277/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/277/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/276 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/276/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/276/comments | https://api.github.com/repos/huggingface/datasets/issues/276/events | https://github.com/huggingface/datasets/pull/276 | 639,490,858 | MDExOlB1bGxSZXF1ZXN0NDM1MDY5Nzg5 | 276 | Fix metric compute (original_instructions missing) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-16T08:52:01Z | 2020-06-18T07:41:45Z | 2020-06-18T07:41:44 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When loading arrow data we added in cc8d250 a way to specify the instructions that were used to store them with the loaded dataset.
However metrics load data the same way but don't need instructions (we use one single file).
In this PR I just make `original_instructions` optional when reading files to load a `Datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/276/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/276/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/276.diff",
"html_url": "https://github.com/huggingface/datasets/pull/276",
"merged_at": "2020-06-18T07:41:43Z",
"patch_url": "https://github.com/huggingface/datasets/pull/276.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/276... | true |
https://api.github.com/repos/huggingface/datasets/issues/275 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/275/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/275/comments | https://api.github.com/repos/huggingface/datasets/issues/275/events | https://github.com/huggingface/datasets/issues/275 | 639,439,052 | MDU6SXNzdWU2Mzk0MzkwNTI= | 275 | NonMatchingChecksumError when loading pubmed dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/48441753?v=4",
"events_url": "https://api.github.com/users/DavideStenner/events{/privacy}",
"followers_url": "https://api.github.com/users/DavideStenner/followers",
"following_url": "https://api.github.com/users/DavideStenner/following{/other_user}",
"g... | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | [] | null | [] | 2020-06-16T07:31:51Z | 2020-06-19T07:37:07Z | 2020-06-19T07:37:07 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I get this error when i run `nlp.load_dataset('scientific_papers', 'pubmed', split = 'train[:50%]')`.
The error is:
```
---------------------------------------------------------------------------
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-2-7742dea167d0> in <module... | {
"avatar_url": "https://avatars.githubusercontent.com/u/48441753?v=4",
"events_url": "https://api.github.com/users/DavideStenner/events{/privacy}",
"followers_url": "https://api.github.com/users/DavideStenner/followers",
"following_url": "https://api.github.com/users/DavideStenner/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/275/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/275/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/274/comments | https://api.github.com/repos/huggingface/datasets/issues/274/events | https://github.com/huggingface/datasets/issues/274 | 639,156,625 | MDU6SXNzdWU2MzkxNTY2MjU= | 274 | PG-19 | {
"avatar_url": "https://avatars.githubusercontent.com/u/108653?v=4",
"events_url": "https://api.github.com/users/lucidrains/events{/privacy}",
"followers_url": "https://api.github.com/users/lucidrains/followers",
"following_url": "https://api.github.com/users/lucidrains/following{/other_user}",
"gists_url": ... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2020-06-15T21:02:26Z | 2020-07-06T15:35:02Z | 2020-07-06T15:35:02 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, and thanks for all your open-sourced work, as always!
I was wondering if you would be open to adding PG-19 to your collection of datasets. https://github.com/deepmind/pg19 It is often used for benchmarking long-range language modeling. | {
"avatar_url": "https://avatars.githubusercontent.com/u/108653?v=4",
"events_url": "https://api.github.com/users/lucidrains/events{/privacy}",
"followers_url": "https://api.github.com/users/lucidrains/followers",
"following_url": "https://api.github.com/users/lucidrains/following{/other_user}",
"gists_url": ... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/274/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/273 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/273/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/273/comments | https://api.github.com/repos/huggingface/datasets/issues/273/events | https://github.com/huggingface/datasets/pull/273 | 638,968,054 | MDExOlB1bGxSZXF1ZXN0NDM0NjM0MzU4 | 273 | update cos_e to add cos_e v1.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-06-15T16:03:22Z | 2020-06-16T08:25:54Z | 2020-06-16T08:25:52 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR updates the cos_e dataset to add v1.0 as requested here #163
@nazneenrajani | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/273/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/273/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/273.diff",
"html_url": "https://github.com/huggingface/datasets/pull/273",
"merged_at": "2020-06-16T08:25:52Z",
"patch_url": "https://github.com/huggingface/datasets/pull/273.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/273... | true |
https://api.github.com/repos/huggingface/datasets/issues/272 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/272/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/272/comments | https://api.github.com/repos/huggingface/datasets/issues/272/events | https://github.com/huggingface/datasets/pull/272 | 638,307,313 | MDExOlB1bGxSZXF1ZXN0NDM0MTExOTQ3 | 272 | asd | {
"avatar_url": "https://avatars.githubusercontent.com/u/66900970?v=4",
"events_url": "https://api.github.com/users/sn696/events{/privacy}",
"followers_url": "https://api.github.com/users/sn696/followers",
"following_url": "https://api.github.com/users/sn696/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | null | [] | null | [] | 2020-06-14T08:20:38Z | 2020-06-14T09:16:41Z | 2020-06-14T09:16:41 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/272/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/272/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/272.diff",
"html_url": "https://github.com/huggingface/datasets/pull/272",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/272.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/272"
} | true | |
https://api.github.com/repos/huggingface/datasets/issues/271 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/271/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/271/comments | https://api.github.com/repos/huggingface/datasets/issues/271/events | https://github.com/huggingface/datasets/pull/271 | 638,135,754 | MDExOlB1bGxSZXF1ZXN0NDMzOTg3NDkw | 271 | Fix allociné dataset configuration | {
"avatar_url": "https://avatars.githubusercontent.com/u/37028092?v=4",
"events_url": "https://api.github.com/users/TheophileBlard/events{/privacy}",
"followers_url": "https://api.github.com/users/TheophileBlard/followers",
"following_url": "https://api.github.com/users/TheophileBlard/following{/other_user}",
... | [] | closed | false | null | [] | null | [] | 2020-06-13T10:12:10Z | 2020-06-18T07:41:21Z | 2020-06-18T07:41:20 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This is a patch for #244. According to the [live nlp viewer](url), the Allociné dataset must be loaded with :
```python
dataset = load_dataset('allocine', 'allocine')
```
This is redundant, as there is only one "dataset configuration", and should only be:
```python
dataset = load_dataset('allocine')
```
This ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/271/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/271/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/271.diff",
"html_url": "https://github.com/huggingface/datasets/pull/271",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/271.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/271"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/270/comments | https://api.github.com/repos/huggingface/datasets/issues/270/events | https://github.com/huggingface/datasets/issues/270 | 638,121,617 | MDU6SXNzdWU2MzgxMjE2MTc= | 270 | c4 dataset is not viewable in nlpviewer demo | {
"avatar_url": "https://avatars.githubusercontent.com/u/6441313?v=4",
"events_url": "https://api.github.com/users/rajarsheem/events{/privacy}",
"followers_url": "https://api.github.com/users/rajarsheem/followers",
"following_url": "https://api.github.com/users/rajarsheem/following{/other_user}",
"gists_url":... | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | null | [] | null | [] | 2020-06-13T08:26:16Z | 2020-10-27T15:35:29Z | 2020-10-27T15:35:13 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I get the following error when I try to view the c4 dataset in [nlpviewer](https://huggingface.co/nlp/viewer/)
```python
ModuleNotFoundError: No module named 'langdetect'
Traceback:
File "/home/sasha/.local/lib/python3.7/site-packages/streamlit/ScriptRunner.py", line 322, in _run_script
exec(code, module.__d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/270/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/269 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/269/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/269/comments | https://api.github.com/repos/huggingface/datasets/issues/269/events | https://github.com/huggingface/datasets/issues/269 | 638,106,774 | MDU6SXNzdWU2MzgxMDY3NzQ= | 269 | Error in metric.compute: missing `original_instructions` argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/1668462?v=4",
"events_url": "https://api.github.com/users/zphang/events{/privacy}",
"followers_url": "https://api.github.com/users/zphang/followers",
"following_url": "https://api.github.com/users/zphang/following{/other_user}",
"gists_url": "https://ap... | [
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2020-06-13T06:26:54Z | 2020-06-18T07:41:44Z | 2020-06-18T07:41:44 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I'm running into an error using metrics for computation in the latest master as well as version 0.2.1. Here is a minimal example:
```python
import nlp
rte_metric = nlp.load_metric('glue', name="rte")
rte_metric.compute(
[0, 0, 1, 1],
[0, 1, 0, 1],
)
```
```
181 # Read the predictio... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/269/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/269/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/268 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/268/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/268/comments | https://api.github.com/repos/huggingface/datasets/issues/268/events | https://github.com/huggingface/datasets/pull/268 | 637,848,056 | MDExOlB1bGxSZXF1ZXN0NDMzNzU5NzQ1 | 268 | add Rotten Tomatoes Movie Review sentences sentiment dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2020-06-12T15:53:59Z | 2020-06-18T07:46:24Z | 2020-06-18T07:46:23 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Sentence-level movie reviews v1.0 from here: http://www.cs.cornell.edu/people/pabo/movie-review-data/ | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/268/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/268/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/268.diff",
"html_url": "https://github.com/huggingface/datasets/pull/268",
"merged_at": "2020-06-18T07:46:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/268.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/268... | true |
https://api.github.com/repos/huggingface/datasets/issues/267 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/267/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/267/comments | https://api.github.com/repos/huggingface/datasets/issues/267/events | https://github.com/huggingface/datasets/issues/267 | 637,415,545 | MDU6SXNzdWU2Mzc0MTU1NDU= | 267 | How can I load/find WMT en-romanian? | {
"avatar_url": "https://avatars.githubusercontent.com/u/6045025?v=4",
"events_url": "https://api.github.com/users/sshleifer/events{/privacy}",
"followers_url": "https://api.github.com/users/sshleifer/followers",
"following_url": "https://api.github.com/users/sshleifer/following{/other_user}",
"gists_url": "h... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/followin... | null | [] | 2020-06-12T01:09:37Z | 2020-06-19T08:24:19Z | 2020-06-19T08:24:19 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I believe it is from `wmt16`
When I run
```python
wmt = nlp.load_dataset('wmt16')
```
I get:
```python
AssertionError: The dataset wmt16 with config cs-en requires manual data.
Please follow the manual download instructions: Some of the wmt configs here, require a manual download.
Please look into wm... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/267/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/267/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/266 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/266/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/266/comments | https://api.github.com/repos/huggingface/datasets/issues/266/events | https://github.com/huggingface/datasets/pull/266 | 637,156,392 | MDExOlB1bGxSZXF1ZXN0NDMzMTk1NDgw | 266 | Add sort, shuffle, test_train_split and select methods | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-06-11T16:22:20Z | 2020-06-18T16:23:25Z | 2020-06-18T16:23:24 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Add a bunch of methods to reorder/split/select rows in a dataset:
- `dataset.select(indices)`: Create a new dataset with rows selected following the list/array of indices (which can have a different size than the dataset and contain duplicated indices, the only constrain is that all the integers in the list must be sm... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/266/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/266/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/266.diff",
"html_url": "https://github.com/huggingface/datasets/pull/266",
"merged_at": "2020-06-18T16:23:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/266.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/266... | true |
https://api.github.com/repos/huggingface/datasets/issues/265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/265/comments | https://api.github.com/repos/huggingface/datasets/issues/265/events | https://github.com/huggingface/datasets/pull/265 | 637,139,220 | MDExOlB1bGxSZXF1ZXN0NDMzMTgxNDMz | 265 | Add pyarrow warning colab | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-11T15:57:51Z | 2020-08-02T18:14:36Z | 2020-06-12T08:14:16 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When a user installs `nlp` on google colab, then google colab doesn't update pyarrow, and the runtime needs to be restarted to use the updated version of pyarrow.
This is an issue because `nlp` requires the updated version to work correctly.
In this PR I added en error that is shown to the user in google colab if... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/265/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/265.diff",
"html_url": "https://github.com/huggingface/datasets/pull/265",
"merged_at": "2020-06-12T08:14:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/265.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/265... | true |
https://api.github.com/repos/huggingface/datasets/issues/264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/264/comments | https://api.github.com/repos/huggingface/datasets/issues/264/events | https://github.com/huggingface/datasets/pull/264 | 637,106,170 | MDExOlB1bGxSZXF1ZXN0NDMzMTU0ODQ4 | 264 | Fix small issues creating dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-11T15:20:16Z | 2020-06-12T08:15:57Z | 2020-06-12T08:15:56 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Fix many small issues mentioned in #249:
- don't force to install apache beam for commands
- fix None cache dir when using `dl_manager.download_custom`
- added new extras in `setup.py` named `dev` that contains tests and quality dependencies
- mock dataset sizes when running tests with dummy data
- add a note abou... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/264/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/264.diff",
"html_url": "https://github.com/huggingface/datasets/pull/264",
"merged_at": "2020-06-12T08:15:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/264.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/264... | true |
https://api.github.com/repos/huggingface/datasets/issues/263 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/263/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/263/comments | https://api.github.com/repos/huggingface/datasets/issues/263/events | https://github.com/huggingface/datasets/issues/263 | 637,028,015 | MDU6SXNzdWU2MzcwMjgwMTU= | 263 | [Feature request] Support for external modality for language datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "h... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [] | 2020-06-11T13:42:18Z | 2022-02-10T13:26:35Z | 2022-02-10T13:26:35 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | # Background
In recent years many researchers have advocated that learning meanings from text-based only datasets is just like asking a human to "learn to speak by listening to the radio" [[E. Bender and A. Koller,2020](https://openreview.net/forum?id=GKTvAcb12b), [Y. Bisk et. al, 2020](https://arxiv.org/abs/2004.10... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 18,
"-1": 0,
"confused": 0,
"eyes": 4,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 23,
"url": "https://api.github.com/repos/huggingface/datasets/issues/263/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/263/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/262 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/262/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/262/comments | https://api.github.com/repos/huggingface/datasets/issues/262/events | https://github.com/huggingface/datasets/pull/262 | 636,702,849 | MDExOlB1bGxSZXF1ZXN0NDMyODI3Mzcz | 262 | Add new dataset ANLI Round 1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/11016329?v=4",
"events_url": "https://api.github.com/users/easonnie/events{/privacy}",
"followers_url": "https://api.github.com/users/easonnie/followers",
"following_url": "https://api.github.com/users/easonnie/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-11T04:14:57Z | 2020-06-12T22:03:03Z | 2020-06-12T22:03:03 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Adding new dataset [ANLI](https://github.com/facebookresearch/anli/).
I'm not familiar with how to add new dataset. Let me know if there is any issue. I only include round 1 data here. There will be round 2, round 3 and more in the future with potentially different format. I think it will be better to separate them. | {
"avatar_url": "https://avatars.githubusercontent.com/u/11016329?v=4",
"events_url": "https://api.github.com/users/easonnie/events{/privacy}",
"followers_url": "https://api.github.com/users/easonnie/followers",
"following_url": "https://api.github.com/users/easonnie/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/262/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/262/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/262.diff",
"html_url": "https://github.com/huggingface/datasets/pull/262",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/262.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/262"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/261 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/261/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/261/comments | https://api.github.com/repos/huggingface/datasets/issues/261/events | https://github.com/huggingface/datasets/issues/261 | 636,372,380 | MDU6SXNzdWU2MzYzNzIzODA= | 261 | Downloading dataset error with pyarrow.lib.RecordBatch | {
"avatar_url": "https://avatars.githubusercontent.com/u/5248968?v=4",
"events_url": "https://api.github.com/users/cuent/events{/privacy}",
"followers_url": "https://api.github.com/users/cuent/followers",
"following_url": "https://api.github.com/users/cuent/following{/other_user}",
"gists_url": "https://api.g... | [] | closed | false | null | [] | null | [] | 2020-06-10T16:04:19Z | 2020-06-11T14:35:12Z | 2020-06-11T14:35:12 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I am trying to download `sentiment140` and I have the following error
```
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
518 download_mode=... | {
"avatar_url": "https://avatars.githubusercontent.com/u/5248968?v=4",
"events_url": "https://api.github.com/users/cuent/events{/privacy}",
"followers_url": "https://api.github.com/users/cuent/followers",
"following_url": "https://api.github.com/users/cuent/following{/other_user}",
"gists_url": "https://api.g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/261/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/261/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/260 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/260/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/260/comments | https://api.github.com/repos/huggingface/datasets/issues/260/events | https://github.com/huggingface/datasets/pull/260 | 636,261,118 | MDExOlB1bGxSZXF1ZXN0NDMyNDY3NDM5 | 260 | Consistency fixes | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | [] | closed | false | null | [] | null | [] | 2020-06-10T13:44:42Z | 2020-06-11T10:34:37Z | 2020-06-11T10:34:36 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | A few bugs I've found while hacking | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/260/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/260/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/260.diff",
"html_url": "https://github.com/huggingface/datasets/pull/260",
"merged_at": "2020-06-11T10:34:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/260.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/260... | true |
https://api.github.com/repos/huggingface/datasets/issues/259 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/259/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/259/comments | https://api.github.com/repos/huggingface/datasets/issues/259/events | https://github.com/huggingface/datasets/issues/259 | 636,239,529 | MDU6SXNzdWU2MzYyMzk1Mjk= | 259 | documentation missing how to split a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/2873355?v=4",
"events_url": "https://api.github.com/users/fotisj/events{/privacy}",
"followers_url": "https://api.github.com/users/fotisj/followers",
"following_url": "https://api.github.com/users/fotisj/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | null | [] | null | [] | 2020-06-10T13:18:13Z | 2023-03-14T13:56:07Z | 2020-06-18T22:20:24 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I am trying to understand how to split a dataset ( as arrow_dataset).
I know I can do something like this to access a split which is already in the original dataset :
`ds_test = nlp.load_dataset('imdb, split='test') `
But how can I split ds_test into a test and a validation set (without reading the data into m... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/259/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/259/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/258 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/258/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/258/comments | https://api.github.com/repos/huggingface/datasets/issues/258/events | https://github.com/huggingface/datasets/issues/258 | 635,859,525 | MDU6SXNzdWU2MzU4NTk1MjU= | 258 | Why is dataset after tokenization far more larger than the orginal one ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-06-10T01:27:07Z | 2020-06-10T12:46:34Z | 2020-06-10T12:46:34 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I tokenize wiki dataset by `map` and cache the results.
```
def tokenize_tfm(example):
example['input_ids'] = hf_fast_tokenizer.convert_tokens_to_ids(hf_fast_tokenizer.tokenize(example['text']))
return example
wiki = nlp.load_dataset('wikipedia', '20200501.en', cache_dir=cache_dir)['train']
wiki.map(token... | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/258/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/258/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/257 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/257/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/257/comments | https://api.github.com/repos/huggingface/datasets/issues/257/events | https://github.com/huggingface/datasets/issues/257 | 635,620,979 | MDU6SXNzdWU2MzU2MjA5Nzk= | 257 | Tokenizer pickling issue fix not landed in `nlp` yet? | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-06-09T17:12:34Z | 2020-06-10T21:45:32Z | 2020-06-09T17:26:53 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Unless I recreate an arrow_dataset from my loaded nlp dataset myself (which I think does not use the cache by default), I get the following error when applying the map function:
```
dataset = nlp.load_dataset('cos_e')
tokenizer = GPT2TokenizerFast.from_pretrained('gpt2', cache_dir=cache_dir)
for split in datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/257/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/257/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/256 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/256/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/256/comments | https://api.github.com/repos/huggingface/datasets/issues/256/events | https://github.com/huggingface/datasets/issues/256 | 635,596,295 | MDU6SXNzdWU2MzU1OTYyOTU= | 256 | [Feature request] Add a feature to dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-06-09T16:38:12Z | 2020-06-09T16:51:42Z | 2020-06-09T16:51:42 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Is there a straightforward way to add a field to the arrow_dataset, prior to performing map? | {
"avatar_url": "https://avatars.githubusercontent.com/u/8027676?v=4",
"events_url": "https://api.github.com/users/sarahwie/events{/privacy}",
"followers_url": "https://api.github.com/users/sarahwie/followers",
"following_url": "https://api.github.com/users/sarahwie/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/256/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/256/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/255 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/255/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/255/comments | https://api.github.com/repos/huggingface/datasets/issues/255/events | https://github.com/huggingface/datasets/pull/255 | 635,300,822 | MDExOlB1bGxSZXF1ZXN0NDMxNjg3MDM0 | 255 | Add dataset/piaf | {
"avatar_url": "https://avatars.githubusercontent.com/u/36986299?v=4",
"events_url": "https://api.github.com/users/RachelKer/events{/privacy}",
"followers_url": "https://api.github.com/users/RachelKer/followers",
"following_url": "https://api.github.com/users/RachelKer/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [] | 2020-06-09T10:16:01Z | 2020-06-12T08:31:27Z | 2020-06-12T08:31:27 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Small SQuAD-like French QA dataset [PIAF](https://www.aclweb.org/anthology/2020.lrec-1.673.pdf) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/255/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/255/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/255.diff",
"html_url": "https://github.com/huggingface/datasets/pull/255",
"merged_at": "2020-06-12T08:31:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/255.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/255... | true |
https://api.github.com/repos/huggingface/datasets/issues/254 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/254/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/254/comments | https://api.github.com/repos/huggingface/datasets/issues/254/events | https://github.com/huggingface/datasets/issues/254 | 635,057,568 | MDU6SXNzdWU2MzUwNTc1Njg= | 254 | [Feature request] Be able to remove a specific sample of the dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-09T02:22:13Z | 2020-06-09T08:41:38Z | 2020-06-09T08:41:38 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | As mentioned in #117, it's currently not possible to remove a sample of the dataset.
But it is a important use case : After applying some preprocessing, some samples might be empty for example. We should be able to remove these samples from the dataset, or at least mark them as `removed` so when iterating the datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/254/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/254/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/253 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/253/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/253/comments | https://api.github.com/repos/huggingface/datasets/issues/253/events | https://github.com/huggingface/datasets/pull/253 | 634,791,939 | MDExOlB1bGxSZXF1ZXN0NDMxMjgwOTYz | 253 | add flue dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-06-08T17:11:09Z | 2023-09-24T09:46:03Z | 2020-07-16T07:50:59 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR add the Flue dataset as requested in this issue #223 . @lbourdois made a detailed description in that issue.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/253/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/253/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/253.diff",
"html_url": "https://github.com/huggingface/datasets/pull/253",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/253.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/253"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/252 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/252/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/252/comments | https://api.github.com/repos/huggingface/datasets/issues/252/events | https://github.com/huggingface/datasets/issues/252 | 634,563,239 | MDU6SXNzdWU2MzQ1NjMyMzk= | 252 | NonMatchingSplitsSizesError error when reading the IMDB dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2020-06-08T12:26:24Z | 2021-08-27T15:20:58Z | 2020-06-08T14:01:26 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi!
I am trying to load the `imdb` dataset with this line:
`dataset = nlp.load_dataset('imdb', data_dir='/A/PATH', cache_dir='/A/PATH')`
but I am getting the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/mounts/Users/cisintern/antmarakis/anaconda3/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/17463361?v=4",
"events_url": "https://api.github.com/users/antmarakis/events{/privacy}",
"followers_url": "https://api.github.com/users/antmarakis/followers",
"following_url": "https://api.github.com/users/antmarakis/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/252/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/252/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/251 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/251/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/251/comments | https://api.github.com/repos/huggingface/datasets/issues/251/events | https://github.com/huggingface/datasets/pull/251 | 634,544,977 | MDExOlB1bGxSZXF1ZXN0NDMxMDgwMDkw | 251 | Better access to all dataset information | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [] | 2020-06-08T11:56:50Z | 2020-06-12T08:13:00Z | 2020-06-12T08:12:58 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Moves all the dataset info down one level from `dataset.info.XXX` to `dataset.XXX`
This way it's easier to access `dataset.feature['label']` for instance
Also, add the original split instructions used to create the dataset in `dataset.split`
Ex:
```
from nlp import load_dataset
stsb = load_dataset('glue', name=... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/251/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/251/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/251.diff",
"html_url": "https://github.com/huggingface/datasets/pull/251",
"merged_at": "2020-06-12T08:12:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/251.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/251... | true |
https://api.github.com/repos/huggingface/datasets/issues/250 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/250/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/250/comments | https://api.github.com/repos/huggingface/datasets/issues/250/events | https://github.com/huggingface/datasets/pull/250 | 634,416,751 | MDExOlB1bGxSZXF1ZXN0NDMwOTcyMzg4 | 250 | Remove checksum download in c4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-08T09:13:00Z | 2020-08-25T07:04:56Z | 2020-06-08T09:16:59 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | There was a line from the original tfds script that was still there and causing issues when loading the c4 script. This one should fix #233 and allow anyone to load the c4 script to generate the dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/250/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/250/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/250.diff",
"html_url": "https://github.com/huggingface/datasets/pull/250",
"merged_at": "2020-06-08T09:16:59Z",
"patch_url": "https://github.com/huggingface/datasets/pull/250.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/250... | true |
https://api.github.com/repos/huggingface/datasets/issues/249 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/249/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/249/comments | https://api.github.com/repos/huggingface/datasets/issues/249/events | https://github.com/huggingface/datasets/issues/249 | 633,393,443 | MDU6SXNzdWU2MzMzOTM0NDM= | 249 | [Dataset created] some critical small issues when I was creating a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2020-06-07T12:58:54Z | 2020-06-12T08:28:51Z | 2020-06-12T08:28:51 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, I successfully created a dataset and has made a pr #248.
But I have encountered several problems when I was creating it, and those should be easy to fix.
1. Not found dataset_info.json
should be fixed by #241 , eager to wait it be merged.
2. Forced to install `apach_beam`
If we should install it, then it m... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/249/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/249/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/248 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/248/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/248/comments | https://api.github.com/repos/huggingface/datasets/issues/248/events | https://github.com/huggingface/datasets/pull/248 | 633,390,427 | MDExOlB1bGxSZXF1ZXN0NDMwMDQ0MzU0 | 248 | add Toronto BooksCorpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-06-07T12:54:56Z | 2020-06-12T08:45:03Z | 2020-06-12T08:45:02 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | 1. I knew there is a branch `toronto_books_corpus`
- After I downloaded it, I found it is all non-english, and only have one row.
- It seems that it cites the wrong paper
- according to papar using it, it is called `BooksCorpus` but not `TornotoBooksCorpus`
2. It use a text mirror in google drive
- `bookscorpu... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/248/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/248/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/248.diff",
"html_url": "https://github.com/huggingface/datasets/pull/248",
"merged_at": "2020-06-12T08:45:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/248.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/248... | true |
https://api.github.com/repos/huggingface/datasets/issues/247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/247/comments | https://api.github.com/repos/huggingface/datasets/issues/247/events | https://github.com/huggingface/datasets/pull/247 | 632,380,078 | MDExOlB1bGxSZXF1ZXN0NDI5MTMwMzQ2 | 247 | Make all dataset downloads deterministic by applying `sorted` to glob and os.listdir | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-06-06T11:02:10Z | 2020-06-08T09:18:16Z | 2020-06-08T09:18:14 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR makes all datasets loading deterministic by applying `sorted()` to all `glob.glob` and `os.listdir` statements.
Are there other "non-deterministic" functions apart from `glob.glob()` and `os.listdir()` that you can think of @thomwolf @lhoestq @mariamabarham @jplu ?
**Important**
It does break backward c... | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/247/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/247/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/247.diff",
"html_url": "https://github.com/huggingface/datasets/pull/247",
"merged_at": "2020-06-08T09:18:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/247.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/247... | true |
https://api.github.com/repos/huggingface/datasets/issues/246 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/246/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/246/comments | https://api.github.com/repos/huggingface/datasets/issues/246/events | https://github.com/huggingface/datasets/issues/246 | 632,380,054 | MDU6SXNzdWU2MzIzODAwNTQ= | 246 | What is the best way to cache a dataset? | {
"avatar_url": "https://avatars.githubusercontent.com/u/112599?v=4",
"events_url": "https://api.github.com/users/Mistobaan/events{/privacy}",
"followers_url": "https://api.github.com/users/Mistobaan/followers",
"following_url": "https://api.github.com/users/Mistobaan/following{/other_user}",
"gists_url": "ht... | [] | closed | false | null | [] | null | [] | 2020-06-06T11:02:07Z | 2020-07-09T09:15:07Z | 2020-07-09T09:15:07 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | For example if I want to use streamlit with a nlp dataset:
```
@st.cache
def load_data():
return nlp.load_dataset('squad')
```
This code raises the error "uncachable object"
Right now I just fixed with a constant for my specific case:
```
@st.cache(hash_funcs={pyarrow.lib.Buffer: lambda b: 0})
```... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/246/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/246/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/245 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/245/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/245/comments | https://api.github.com/repos/huggingface/datasets/issues/245/events | https://github.com/huggingface/datasets/issues/245 | 631,985,108 | MDU6SXNzdWU2MzE5ODUxMDg= | 245 | SST-2 test labels are all -1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2020-06-05T21:41:42Z | 2021-12-08T00:47:32Z | 2020-06-06T16:56:41 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I'm trying to test a model on the SST-2 task, but all the labels I see in the test set are -1.
```
>>> import nlp
>>> glue = nlp.load_dataset('glue', 'sst2')
>>> glue
{'train': Dataset(schema: {'sentence': 'string', 'label': 'int64', 'idx': 'int32'}, num_rows: 67349), 'validation': Dataset(schema: {'sentence': 'st... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13238952?v=4",
"events_url": "https://api.github.com/users/jxmorris12/events{/privacy}",
"followers_url": "https://api.github.com/users/jxmorris12/followers",
"following_url": "https://api.github.com/users/jxmorris12/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/245/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/245/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/244/comments | https://api.github.com/repos/huggingface/datasets/issues/244/events | https://github.com/huggingface/datasets/pull/244 | 631,869,155 | MDExOlB1bGxSZXF1ZXN0NDI4NjgxMTcx | 244 | Add Allociné Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/37028092?v=4",
"events_url": "https://api.github.com/users/TheophileBlard/events{/privacy}",
"followers_url": "https://api.github.com/users/TheophileBlard/followers",
"following_url": "https://api.github.com/users/TheophileBlard/following{/other_user}",
... | [] | closed | false | null | [] | null | [] | 2020-06-05T19:19:26Z | 2020-06-11T07:47:26Z | 2020-06-11T07:47:26 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This is a french binary sentiment classification dataset, which was used to train this model: https://huggingface.co/tblard/tf-allocine.
Basically, it's a french "IMDB" dataset, with more reviews.
More info on [this repo](https://github.com/TheophileBlard/french-sentiment-analysis-with-bert). | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/244/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/244.diff",
"html_url": "https://github.com/huggingface/datasets/pull/244",
"merged_at": "2020-06-11T07:47:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/244.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/244... | true |
https://api.github.com/repos/huggingface/datasets/issues/243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/243/comments | https://api.github.com/repos/huggingface/datasets/issues/243/events | https://github.com/huggingface/datasets/pull/243 | 631,735,848 | MDExOlB1bGxSZXF1ZXN0NDI4NTY2MTEy | 243 | Specify utf-8 encoding for GLUE | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-05T16:33:00Z | 2020-06-17T21:16:06Z | 2020-06-08T08:42:01 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | #242
This makes the GLUE-MNLI dataset readable on my machine, not sure if it's a Windows-only bug. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/243/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/243.diff",
"html_url": "https://github.com/huggingface/datasets/pull/243",
"merged_at": "2020-06-08T08:42:01Z",
"patch_url": "https://github.com/huggingface/datasets/pull/243.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/243... | true |
https://api.github.com/repos/huggingface/datasets/issues/242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/242/comments | https://api.github.com/repos/huggingface/datasets/issues/242/events | https://github.com/huggingface/datasets/issues/242 | 631,733,683 | MDU6SXNzdWU2MzE3MzM2ODM= | 242 | UnicodeDecodeError when downloading GLUE-MNLI | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-05T16:30:01Z | 2020-06-09T16:06:47Z | 2020-06-08T08:45:03 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When I run
```python
dataset = nlp.load_dataset('glue', 'mnli')
```
I get an encoding error (could it be because I'm using Windows?) :
```python
# Lots of error log lines later...
~\Miniconda3\envs\nlp\lib\site-packages\tqdm\std.py in __iter__(self)
1128 try:
-> 1129 for obj in iterable:... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/242/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/241 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/241/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/241/comments | https://api.github.com/repos/huggingface/datasets/issues/241/events | https://github.com/huggingface/datasets/pull/241 | 631,703,079 | MDExOlB1bGxSZXF1ZXN0NDI4NTQwMDM0 | 241 | Fix empty cache dir | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-05T15:45:22Z | 2020-06-08T08:35:33Z | 2020-06-08T08:35:31 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | If the cache dir of a dataset is empty, the dataset fails to load and throws a FileNotFounfError. We could end up with empty cache dir because there was a line in the code that created the cache dir without using a temp dir. Using a temp dir is useful as it gets renamed to the real cache dir only if the full process is... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/241/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/241/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/241.diff",
"html_url": "https://github.com/huggingface/datasets/pull/241",
"merged_at": "2020-06-08T08:35:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/241.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/241... | true |
https://api.github.com/repos/huggingface/datasets/issues/240 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/240/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/240/comments | https://api.github.com/repos/huggingface/datasets/issues/240/events | https://github.com/huggingface/datasets/issues/240 | 631,434,677 | MDU6SXNzdWU2MzE0MzQ2Nzc= | 240 | Deterministic dataset loading | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | [] | closed | false | null | [] | null | [] | 2020-06-05T09:03:26Z | 2020-06-08T09:18:14Z | 2020-06-08T09:18:14 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When calling:
```python
import nlp
dataset = nlp.load_dataset("trivia_qa", split="validation[:1%]")
```
the resulting dataset is not deterministic over different google colabs.
After talking to @thomwolf, I suspect the reason to be the use of `glob.glob` in line:
https://github.com/huggingface/nlp/blob/2e0... | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_use... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/240/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/240/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/239 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/239/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/239/comments | https://api.github.com/repos/huggingface/datasets/issues/239/events | https://github.com/huggingface/datasets/issues/239 | 631,340,440 | MDU6SXNzdWU2MzEzNDA0NDA= | 239 | [Creating new dataset] Not found dataset_info.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2020-06-05T06:15:04Z | 2020-06-07T13:01:04Z | 2020-06-07T13:01:04 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, I am trying to create Toronto Book Corpus. #131
I ran
`~/nlp % python nlp-cli test datasets/bookcorpus --save_infos --all_configs`
but this doesn't create `dataset_info.json` and try to use it
```
INFO:nlp.load:Checking datasets/bookcorpus/bookcorpus.py for additional imports.
INFO:filelock:Lock 1397953257... | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/239/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/239/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/238 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/238/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/238/comments | https://api.github.com/repos/huggingface/datasets/issues/238/events | https://github.com/huggingface/datasets/issues/238 | 631,260,143 | MDU6SXNzdWU2MzEyNjAxNDM= | 238 | [Metric] Bertscore : Warning : Empty candidate sentence; Setting recall to be 0. | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [
{
"color": "25b21e",
"default": false,
"description": "A bug in a metric script",
"id": 2067393914,
"name": "metric bug",
"node_id": "MDU6TGFiZWwyMDY3MzkzOTE0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/metric%20bug"
}
] | closed | false | null | [] | null | [] | 2020-06-05T02:14:47Z | 2020-06-29T17:10:19Z | 2020-06-29T17:10:19 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When running BERT-Score, I'm meeting this warning :
> Warning: Empty candidate sentence; Setting recall to be 0.
Code :
```
import nlp
metric = nlp.load_metric("bertscore")
scores = metric.compute(["swag", "swags"], ["swags", "totally something different"], lang="en", device=0)
```
---
**What am I do... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/238/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/238/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/237 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/237/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/237/comments | https://api.github.com/repos/huggingface/datasets/issues/237/events | https://github.com/huggingface/datasets/issues/237 | 631,199,940 | MDU6SXNzdWU2MzExOTk5NDA= | 237 | Can't download MultiNLI | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-04T23:05:21Z | 2020-06-06T10:51:34Z | 2020-06-06T10:51:34 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When I try to download MultiNLI with
```python
dataset = load_dataset('multi_nli')
```
I get this long error:
```python
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-13-3b11f6be4cb9> in <m... | {
"avatar_url": "https://avatars.githubusercontent.com/u/15801338?v=4",
"events_url": "https://api.github.com/users/patpizio/events{/privacy}",
"followers_url": "https://api.github.com/users/patpizio/followers",
"following_url": "https://api.github.com/users/patpizio/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/237/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/237/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/236 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/236/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/236/comments | https://api.github.com/repos/huggingface/datasets/issues/236/events | https://github.com/huggingface/datasets/pull/236 | 631,099,875 | MDExOlB1bGxSZXF1ZXN0NDI4MDUwNzI4 | 236 | CompGuessWhat?! dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/1479733?v=4",
"events_url": "https://api.github.com/users/aleSuglia/events{/privacy}",
"followers_url": "https://api.github.com/users/aleSuglia/followers",
"following_url": "https://api.github.com/users/aleSuglia/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [] | 2020-06-04T19:45:50Z | 2020-06-11T09:43:42Z | 2020-06-11T07:45:21 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hello,
Thanks for the amazing library that you put together. I'm Alessandro Suglia, the first author of CompGuessWhat?!, a recently released dataset for grounded language learning accepted to ACL 2020 ([https://compguesswhat.github.io](https://compguesswhat.github.io)).
This pull-request adds the CompGuessWhat?! ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/236/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/236/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/236.diff",
"html_url": "https://github.com/huggingface/datasets/pull/236",
"merged_at": "2020-06-11T07:45:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/236.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/236... | true |
https://api.github.com/repos/huggingface/datasets/issues/235 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/235/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/235/comments | https://api.github.com/repos/huggingface/datasets/issues/235/events | https://github.com/huggingface/datasets/pull/235 | 630,952,297 | MDExOlB1bGxSZXF1ZXN0NDI3OTM1MjQ0 | 235 | Add experimental datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-04T15:54:56Z | 2020-06-12T15:38:55Z | 2020-06-12T15:38:55 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | ## Adding an *experimental datasets* folder
After using the 🤗nlp library for some time, I find that while it makes it super easy to create new memory-mapped datasets with lots of cool utilities, a lot of what I want to do doesn't work well with the current `MockDownloader` based testing paradigm, making it hard to ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/235/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/235/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/235.diff",
"html_url": "https://github.com/huggingface/datasets/pull/235",
"merged_at": "2020-06-12T15:38:55Z",
"patch_url": "https://github.com/huggingface/datasets/pull/235.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/235... | true |
https://api.github.com/repos/huggingface/datasets/issues/234 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/234/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/234/comments | https://api.github.com/repos/huggingface/datasets/issues/234/events | https://github.com/huggingface/datasets/issues/234 | 630,534,427 | MDU6SXNzdWU2MzA1MzQ0Mjc= | 234 | Huggingface NLP, Uploading custom dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-06-04T05:59:06Z | 2020-07-06T09:33:26Z | 2020-07-06T09:33:26 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hello,
Does anyone know how we can call our custom dataset using the nlp.load command? Let's say that I have a dataset based on the same format as that of squad-v1.1, how am I supposed to load it using huggingface nlp.
Thank you! | {
"avatar_url": "https://avatars.githubusercontent.com/u/42269506?v=4",
"events_url": "https://api.github.com/users/Nouman97/events{/privacy}",
"followers_url": "https://api.github.com/users/Nouman97/followers",
"following_url": "https://api.github.com/users/Nouman97/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/234/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/234/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/233 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/233/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/233/comments | https://api.github.com/repos/huggingface/datasets/issues/233/events | https://github.com/huggingface/datasets/issues/233 | 630,432,132 | MDU6SXNzdWU2MzA0MzIxMzI= | 233 | Fail to download c4 english corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/16605764?v=4",
"events_url": "https://api.github.com/users/donggyukimc/events{/privacy}",
"followers_url": "https://api.github.com/users/donggyukimc/followers",
"following_url": "https://api.github.com/users/donggyukimc/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2020-06-04T01:06:38Z | 2021-01-08T07:17:32Z | 2020-06-08T09:16:59 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | i run following code to download c4 English corpus.
```
dataset = nlp.load_dataset('c4', 'en', beam_runner='DirectRunner'
, data_dir='/mypath')
```
and i met failure as follows
```
Downloading and preparing dataset c4/en (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/adam/.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/233/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/233/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/232/comments | https://api.github.com/repos/huggingface/datasets/issues/232/events | https://github.com/huggingface/datasets/pull/232 | 630,029,568 | MDExOlB1bGxSZXF1ZXN0NDI3MjI5NDcy | 232 | Nlp cli fix endpoints | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-03T14:10:39Z | 2020-06-08T09:02:58Z | 2020-06-08T09:02:57 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | With this PR users will be able to upload their own datasets and metrics.
As mentioned in #181, I had to use the new endpoints and revert the use of dataclasses (just in case we have changes in the API in the future).
We now distinguish commands for datasets and commands for metrics:
```bash
nlp-cli upload_data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/232/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/232/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/232.diff",
"html_url": "https://github.com/huggingface/datasets/pull/232",
"merged_at": "2020-06-08T09:02:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/232.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/232... | true |
https://api.github.com/repos/huggingface/datasets/issues/231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/231/comments | https://api.github.com/repos/huggingface/datasets/issues/231/events | https://github.com/huggingface/datasets/pull/231 | 629,988,694 | MDExOlB1bGxSZXF1ZXN0NDI3MTk3MTcz | 231 | Add .download to MockDownloadManager | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-03T13:20:00Z | 2020-06-03T14:25:56Z | 2020-06-03T14:25:55 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | One method from the DownloadManager was missing and some users couldn't run the tests because of that.
@yjernite | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/231/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/231.diff",
"html_url": "https://github.com/huggingface/datasets/pull/231",
"merged_at": "2020-06-03T14:25:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/231.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/231... | true |
https://api.github.com/repos/huggingface/datasets/issues/230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/230/comments | https://api.github.com/repos/huggingface/datasets/issues/230/events | https://github.com/huggingface/datasets/pull/230 | 629,983,684 | MDExOlB1bGxSZXF1ZXN0NDI3MTkzMTQ0 | 230 | Don't force to install apache beam for wikipedia dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-06-03T13:13:07Z | 2020-06-03T14:34:09Z | 2020-06-03T14:34:07 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | As pointed out in #227, we shouldn't force users to install apache beam if the processed dataset can be downloaded. I moved the imports of some datasets to avoid this problem | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/230/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/230.diff",
"html_url": "https://github.com/huggingface/datasets/pull/230",
"merged_at": "2020-06-03T14:34:07Z",
"patch_url": "https://github.com/huggingface/datasets/pull/230.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/230... | true |
https://api.github.com/repos/huggingface/datasets/issues/229 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/229/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/229/comments | https://api.github.com/repos/huggingface/datasets/issues/229/events | https://github.com/huggingface/datasets/pull/229 | 629,956,490 | MDExOlB1bGxSZXF1ZXN0NDI3MTcxMzc5 | 229 | Rename dataset_infos.json to dataset_info.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
... | [] | closed | false | null | [] | null | [] | 2020-06-03T12:31:44Z | 2020-06-03T12:52:54Z | 2020-06-03T12:48:33 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | As the file required for the viewing in the live nlp viewer is named as dataset_info.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/229/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/229/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/229.diff",
"html_url": "https://github.com/huggingface/datasets/pull/229",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/229.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/229"
} | true |
https://api.github.com/repos/huggingface/datasets/issues/228 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/228/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/228/comments | https://api.github.com/repos/huggingface/datasets/issues/228/events | https://github.com/huggingface/datasets/issues/228 | 629,952,402 | MDU6SXNzdWU2Mjk5NTI0MDI= | 228 | Not able to access the XNLI dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/11817160?v=4",
"events_url": "https://api.github.com/users/aswin-giridhar/events{/privacy}",
"followers_url": "https://api.github.com/users/aswin-giridhar/followers",
"following_url": "https://api.github.com/users/aswin-giridhar/following{/other_user}",
... | [
{
"color": "94203D",
"default": false,
"description": "",
"id": 2107841032,
"name": "nlp-viewer",
"node_id": "MDU6TGFiZWwyMTA3ODQxMDMy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/nlp-viewer"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "https://api.git... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/35882?v=4",
"events_url": "https://api.github.com/users/srush/events{/privacy}",
"followers_url": "https://api.github.com/users/srush/followers",
"following_url": "https://api.github.com/users/srush/following{/other_user}",
"gists_url": "h... | null | [] | 2020-06-03T12:25:14Z | 2020-07-17T17:44:22Z | 2020-07-17T17:44:22 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When I try to access the XNLI dataset, I get the following error. The option of plain_text get selected automatically and then I get the following error.
```
FileNotFoundError: [Errno 2] No such file or directory: '/home/sasha/.cache/huggingface/datasets/xnli/plain_text/1.0.0/dataset_info.json'
Traceback:
File "/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/228/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/228/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/227/comments | https://api.github.com/repos/huggingface/datasets/issues/227/events | https://github.com/huggingface/datasets/issues/227 | 629,845,704 | MDU6SXNzdWU2Mjk4NDU3MDQ= | 227 | Should we still have to force to install apache_beam to download wikipedia ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gist... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2020-06-03T09:33:20Z | 2020-06-03T15:25:41Z | 2020-06-03T15:25:41 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, first thanks to @lhoestq 's revolutionary work, I successfully downloaded processed wikipedia according to the doc. 😍😍😍
But at the first try, it tell me to install `apache_beam` and `mwparserfromhell`, which I thought wouldn't be used according to #204 , it was kind of confusing me at that time.
Maybe we s... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/227/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/227/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/226 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/226/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/226/comments | https://api.github.com/repos/huggingface/datasets/issues/226/events | https://github.com/huggingface/datasets/pull/226 | 628,344,520 | MDExOlB1bGxSZXF1ZXN0NDI1OTA0MjEz | 226 | add BlendedSkillTalk dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [] | 2020-06-01T10:54:45Z | 2020-06-03T14:37:23Z | 2020-06-03T14:37:22 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This PR add the BlendedSkillTalk dataset, which is used to fine tune the blenderbot. | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/226/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/226/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/226.diff",
"html_url": "https://github.com/huggingface/datasets/pull/226",
"merged_at": "2020-06-03T14:37:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/226.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/226... | true |
https://api.github.com/repos/huggingface/datasets/issues/225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/225/comments | https://api.github.com/repos/huggingface/datasets/issues/225/events | https://github.com/huggingface/datasets/issues/225 | 628,083,366 | MDU6SXNzdWU2MjgwODMzNjY= | 225 | [ROUGE] Different scores with `files2rouge` | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d722e8",
"default": false,
"description": "Discussions on the metrics",
"id": 2067400959,
"name": "Metric discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwOTU5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Metric%20discussion"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gi... | null | [] | 2020-06-01T00:50:36Z | 2020-06-03T15:27:18Z | 2020-06-03T15:27:18 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | It seems that the ROUGE score of `nlp` is lower than the one of `files2rouge`.
Here is a self-contained notebook to reproduce both scores : https://colab.research.google.com/drive/14EyAXValB6UzKY9x4rs_T3pyL7alpw_F?usp=sharing
---
`nlp` : (Only mid F-scores)
>rouge1 0.33508031962733364
rouge2 0.145743337761... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/225/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/224/comments | https://api.github.com/repos/huggingface/datasets/issues/224/events | https://github.com/huggingface/datasets/issues/224 | 627,791,693 | MDU6SXNzdWU2Mjc3OTE2OTM= | 224 | [Feature Request/Help] BLEURT model -> PyTorch | {
"avatar_url": "https://avatars.githubusercontent.com/u/6889910?v=4",
"events_url": "https://api.github.com/users/adamwlev/events{/privacy}",
"followers_url": "https://api.github.com/users/adamwlev/followers",
"following_url": "https://api.github.com/users/adamwlev/following{/other_user}",
"gists_url": "http... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gi... | null | [] | 2020-05-30T18:30:40Z | 2023-08-26T17:38:48Z | 2021-01-04T09:53:32 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi, I am interested in porting google research's new BLEURT learned metric to PyTorch (because I wish to do something experimental with language generation and backpropping through BLEURT). I noticed that you guys don't have it yet so I am partly just asking if you plan to add it (@thomwolf said you want to do so on Tw... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/224/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/223 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/223/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/223/comments | https://api.github.com/repos/huggingface/datasets/issues/223/events | https://github.com/huggingface/datasets/issues/223 | 627,683,386 | MDU6SXNzdWU2Mjc2ODMzODY= | 223 | [Feature request] Add FLUE dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/58078086?v=4",
"events_url": "https://api.github.com/users/lbourdois/events{/privacy}",
"followers_url": "https://api.github.com/users/lbourdois/followers",
"following_url": "https://api.github.com/users/lbourdois/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2020-05-30T08:52:15Z | 2020-12-03T13:39:33Z | 2020-12-03T13:39:33 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Hi,
I think it would be interesting to add the FLUE dataset for francophones or anyone wishing to work on French.
In other requests, I read that you are already working on some datasets, and I was wondering if FLUE was planned.
If it is not the case, I can provide each of the cleaned FLUE datasets (in the form... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10469459?v=4",
"events_url": "https://api.github.com/users/yjernite/events{/privacy}",
"followers_url": "https://api.github.com/users/yjernite/followers",
"following_url": "https://api.github.com/users/yjernite/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/223/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/223/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/222 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/222/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/222/comments | https://api.github.com/repos/huggingface/datasets/issues/222/events | https://github.com/huggingface/datasets/issues/222 | 627,586,690 | MDU6SXNzdWU2Mjc1ODY2OTA= | 222 | Colab Notebook breaks when downloading the squad dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/338917?v=4",
"events_url": "https://api.github.com/users/carlos-aguayo/events{/privacy}",
"followers_url": "https://api.github.com/users/carlos-aguayo/followers",
"following_url": "https://api.github.com/users/carlos-aguayo/following{/other_user}",
"gis... | [] | closed | false | null | [] | null | [] | 2020-05-29T22:55:59Z | 2020-06-04T00:21:05Z | 2020-06-04T00:21:05 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
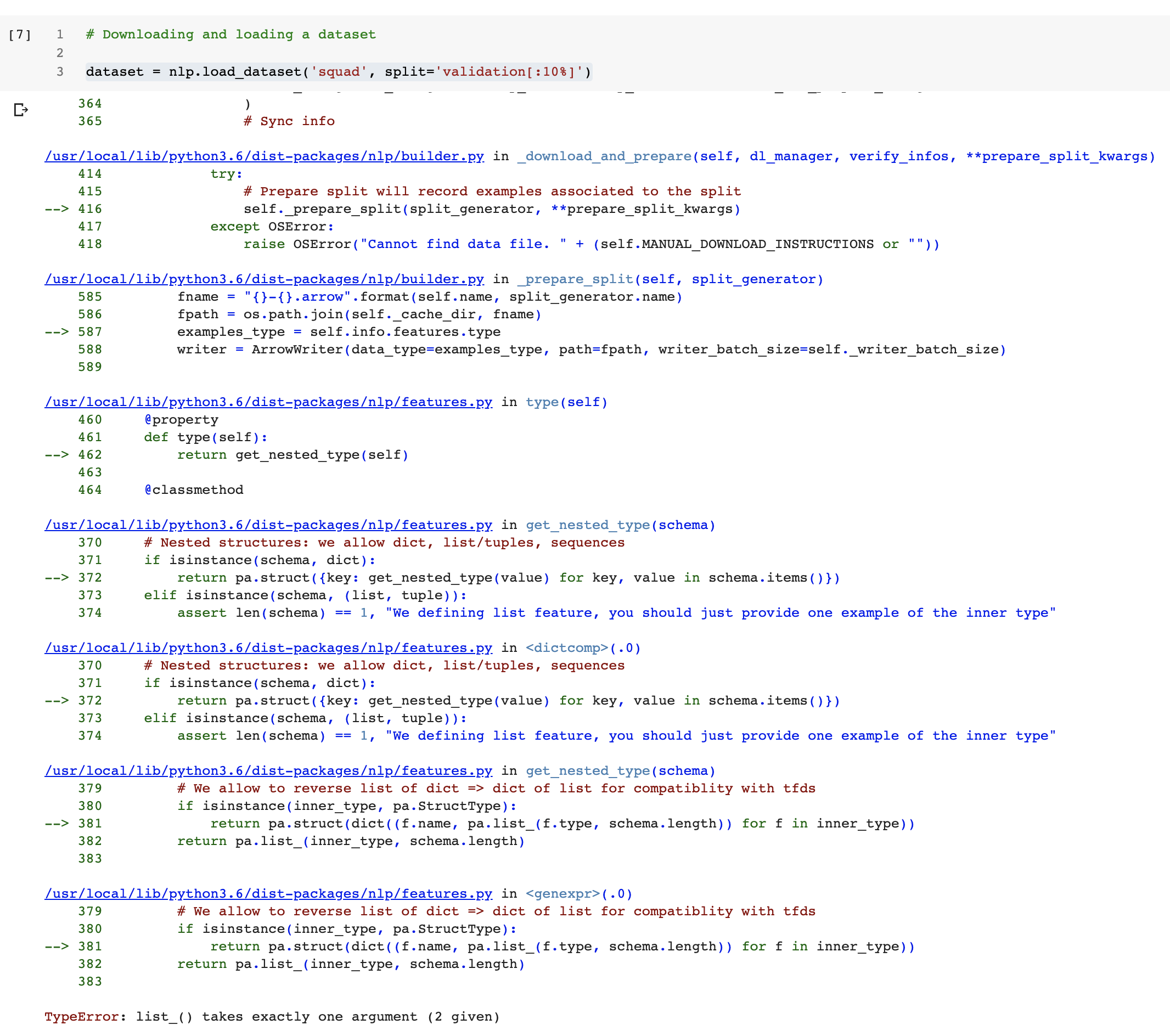
| {
"avatar_url": "https://avatars.githubusercontent.com/u/338917?v=4",
"events_url": "https://api.github.com/users/carlos-aguayo/events{/privacy}",
"followers_url": "https://api.github.com/users/carlos-aguayo/followers",
"following_url": "https://api.github.com/users/carlos-aguayo/following{/other_user}",
"gis... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/222/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/222/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/221 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/221/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/221/comments | https://api.github.com/repos/huggingface/datasets/issues/221/events | https://github.com/huggingface/datasets/pull/221 | 627,300,648 | MDExOlB1bGxSZXF1ZXN0NDI1MTI5OTc0 | 221 | Fix tests/test_dataset_common.py | {
"avatar_url": "https://avatars.githubusercontent.com/u/13635495?v=4",
"events_url": "https://api.github.com/users/tayciryahmed/events{/privacy}",
"followers_url": "https://api.github.com/users/tayciryahmed/followers",
"following_url": "https://api.github.com/users/tayciryahmed/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-05-29T14:12:15Z | 2020-06-01T12:20:42Z | 2020-05-29T15:02:23 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | When I run the command `RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_arcd` while working on #220. I get the error ` unexpected keyword argument "'download_and_prepare_kwargs'"` at the level of `load_dataset`. Indeed, this [function](https://github.com/huggingface/nlp/blob/ma... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/221/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/221/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/221.diff",
"html_url": "https://github.com/huggingface/datasets/pull/221",
"merged_at": "2020-05-29T15:02:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/221.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/221... | true |
https://api.github.com/repos/huggingface/datasets/issues/220 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/220/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/220/comments | https://api.github.com/repos/huggingface/datasets/issues/220/events | https://github.com/huggingface/datasets/pull/220 | 627,280,683 | MDExOlB1bGxSZXF1ZXN0NDI1MTEzMzEy | 220 | dataset_arcd | {
"avatar_url": "https://avatars.githubusercontent.com/u/13635495?v=4",
"events_url": "https://api.github.com/users/tayciryahmed/events{/privacy}",
"followers_url": "https://api.github.com/users/tayciryahmed/followers",
"following_url": "https://api.github.com/users/tayciryahmed/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [] | 2020-05-29T13:46:50Z | 2020-05-29T14:58:40Z | 2020-05-29T14:57:21 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Added Arabic Reading Comprehension Dataset (ARCD): https://arxiv.org/abs/1906.05394 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/220/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/220/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/220.diff",
"html_url": "https://github.com/huggingface/datasets/pull/220",
"merged_at": "2020-05-29T14:57:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/220.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/220... | true |
https://api.github.com/repos/huggingface/datasets/issues/219 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/219/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/219/comments | https://api.github.com/repos/huggingface/datasets/issues/219/events | https://github.com/huggingface/datasets/pull/219 | 627,235,893 | MDExOlB1bGxSZXF1ZXN0NDI1MDc2NjQx | 219 | force mwparserfromhell as third party | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-05-29T12:33:17Z | 2020-05-29T13:30:13Z | 2020-05-29T13:30:12 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | This should fix your env because you had `mwparserfromhell ` as a first party for `isort` @patrickvonplaten | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/219/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/219/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/219.diff",
"html_url": "https://github.com/huggingface/datasets/pull/219",
"merged_at": "2020-05-29T13:30:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/219.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/219... | true |
https://api.github.com/repos/huggingface/datasets/issues/218 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/218/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/218/comments | https://api.github.com/repos/huggingface/datasets/issues/218/events | https://github.com/huggingface/datasets/pull/218 | 627,173,407 | MDExOlB1bGxSZXF1ZXN0NDI1MDI2NzEz | 218 | Add Natual Questions and C4 scripts | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [] | 2020-05-29T10:40:30Z | 2020-05-29T12:31:01Z | 2020-05-29T12:31:00 | MEMBER | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | Scripts are ready !
However they are not processed nor directly available from gcp yet. | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/218/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/218/timeline | null | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/218.diff",
"html_url": "https://github.com/huggingface/datasets/pull/218",
"merged_at": "2020-05-29T12:31:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/218.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/218... | true |
https://api.github.com/repos/huggingface/datasets/issues/217 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/217/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/217/comments | https://api.github.com/repos/huggingface/datasets/issues/217/events | https://github.com/huggingface/datasets/issues/217 | 627,128,403 | MDU6SXNzdWU2MjcxMjg0MDM= | 217 | Multi-task dataset mixing | {
"avatar_url": "https://avatars.githubusercontent.com/u/13795113?v=4",
"events_url": "https://api.github.com/users/ghomasHudson/events{/privacy}",
"followers_url": "https://api.github.com/users/ghomasHudson/followers",
"following_url": "https://api.github.com/users/ghomasHudson/following{/other_user}",
"gist... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | open | false | null | [] | null | [] | 2020-05-29T09:22:26Z | 2022-10-22T00:45:50Z | 1970-01-01T00:00:00 | CONTRIBUTOR | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | null | {
"+1": 12,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 12,
"url": "https://api.github.com/repos/huggingface/datasets/issues/217/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/217/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/216/comments | https://api.github.com/repos/huggingface/datasets/issues/216/events | https://github.com/huggingface/datasets/issues/216 | 626,896,890 | MDU6SXNzdWU2MjY4OTY4OTA= | 216 | ❓ How to get ROUGE-2 with the ROUGE metric ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [] | 2020-05-28T23:47:32Z | 2020-06-01T00:04:35Z | 2020-06-01T00:04:35 | NONE | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.add([lp], [lg])
score = rouge.compute()
```
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"events_url": "https://api.github.com/users/astariul/events{/privacy}",
"followers_url": "https://api.github.com/users/astariul/followers",
"following_url": "https://api.github.com/users/astariul/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/216/timeline | null | completed | null | null | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.