| --- |
| license: bsd-3-clause |
| library_name: braindecode |
| pipeline_tag: feature-extraction |
| tags: |
| - eeg |
| - biosignal |
| - pytorch |
| - neuroscience |
| - braindecode |
| - foundation-model |
| - transformer |
| --- |
| |
| # REVE |
|
|
| **R**\ epresentation for **E**\ EG with **V**\ ersatile **E**\ mbeddings (REVE) from El Ouahidi et al. (2025) [reve]. |
|
|
| > **Architecture-only repository.** Documents the |
| > `braindecode.models.REVE` class. **No pretrained weights are |
| > distributed here.** Instantiate the model and train it on your own |
| > data. |
|
|
| ## Quick start |
|
|
| ```bash |
| pip install braindecode |
| ``` |
|
|
| ```python |
| from braindecode.models import REVE |
| |
| model = REVE( |
| n_chans=22, |
| sfreq=250, |
| input_window_seconds=4.0, |
| n_outputs=4, |
| ) |
| ``` |
|
|
| The signal-shape arguments above are illustrative defaults — adjust to |
| match your recording. |
|
|
| ## Documentation |
| - Full API reference: <https://braindecode.org/stable/generated/braindecode.models.REVE.html> |
| - Interactive browser (live instantiation, parameter counts): |
| <https://huggingface.co/spaces/braindecode/model-explorer> |
| - Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/reve.py#L35> |
|
|
|
|
| ## Architecture |
|
|
| 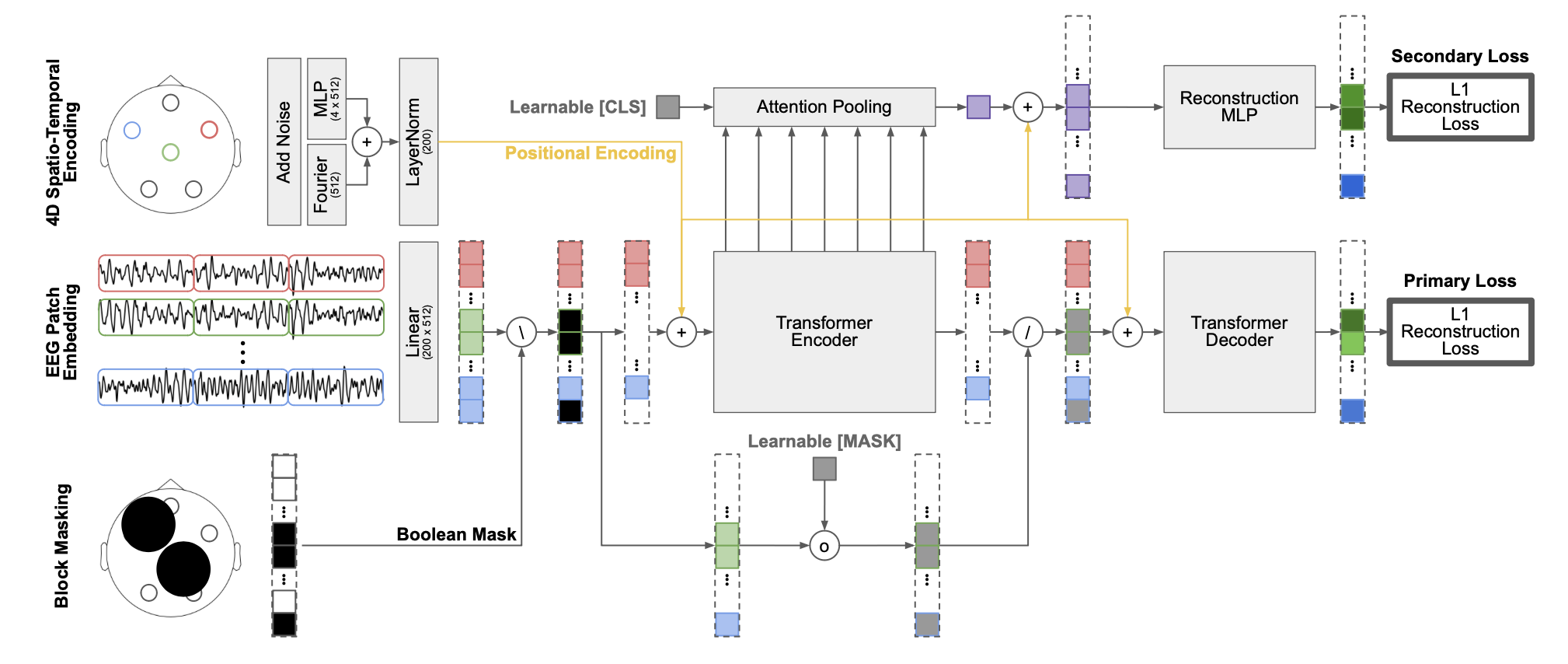 |
|
|
|
|
| ## Parameters |
|
|
| | Parameter | Type | Description | |
| |---|---|---| |
| | `embed_dim` | int, default=512 | Embedding dimension. Use 512 for REVE-Base, 1250 for REVE-Large. | |
| | `depth` | int, default=22 | Number of Transformer layers. | |
| | `heads` | int, default=8 | Number of attention heads. | |
| | `head_dim` | int, default=64 | Dimension per attention head. | |
| | `mlp_dim_ratio` | float, default=2.66 | FFN hidden dimension ratio: `mlp_dim = embed_dim × mlp_dim_ratio`. | |
| | `use_geglu` | bool, default=True | Use GEGLU activation (recommended) or standard GELU. | |
| | `freqs` | int, default=4 | Number of frequencies for Fourier positional embedding. | |
| | `patch_size` | int, default=200 | Temporal patch size in samples (200 samples = 1 second at 200 Hz). | |
| | `patch_overlap` | int, default=20 | Overlap between patches in samples. | |
| | `attention_pooling` | bool, default=False | Pooling strategy for aggregating transformer outputs before classification. If `False` (default), all tokens are flattened into a single vector of size `(n_chans x n_patches x embed_dim)`, which is then passed through LayerNorm and a linear classifier. If `True`, uses attention-based pooling with a learnable query token that attends to all encoder outputs, producing a single embedding of size `embed_dim`. Attention pooling is more parameter-efficient for long sequences and variable-length inputs. | |
|
|
|
|
| ## References |
|
|
| 1. El Ouahidi, Y., Lys, J., Thölke, P., Farrugia, N., Pasdeloup, B., Gripon, V., Jerbi, K. & Lioi, G. (2025). REVE: A Foundation Model for EEG - Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects. The Thirty-Ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=ZeFMtRBy4Z |
| 2. Défossez, A., Caucheteux, C., Rapin, J., Kabeli, O., & King, J. R. (2023). Decoding speech perception from non-invasive brain recordings. Nature Machine Intelligence, 5(10), 1097-1107. |
|
|
|
|
| ## Citation |
|
|
| Cite the original architecture paper (see *References* above) and braindecode: |
|
|
| ```bibtex |
| @article{aristimunha2025braindecode, |
| title = {Braindecode: a deep learning library for raw electrophysiological data}, |
| author = {Aristimunha, Bruno and others}, |
| journal = {Zenodo}, |
| year = {2025}, |
| doi = {10.5281/zenodo.17699192}, |
| } |
| ``` |
|
|
| ## License |
|
|
| BSD-3-Clause for the model code (matching braindecode). |
| Pretraining-derived weights, if you fine-tune from a checkpoint, |
| inherit the licence of that checkpoint and its training corpus. |
|
|

