
FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
Paper • 2603.19835 • Published • 3
🏠 Homepage | 📝 Paper PDF | 🤗 Hugging Face | 🤖 ModelScope | 🐱 GitHub
Qwen Pilot, Alibaba Group | Published on March 20, 2026
FIPO is a value-free RL recipe for eliciting deeper reasoning from a clean base model. The central idea is simple: GRPO-style training works, but its token credit assignment is too coarse. FIPO densifies that signal with a discounted Future-KL term that reflects how the rest of the trajectory evolves after each token. Empirically, this granular reinforcement allows the model to break through the length stagnation observed in standard baselines. Trained on Qwen2.5-32B-Base, FIPO extends the average chain-of-thought length from 4,000 to over 10,000 tokens, driving AIME 2024 Pass@1 accuracy from 50.0% to a peak of 58.0% compared with DAPO.
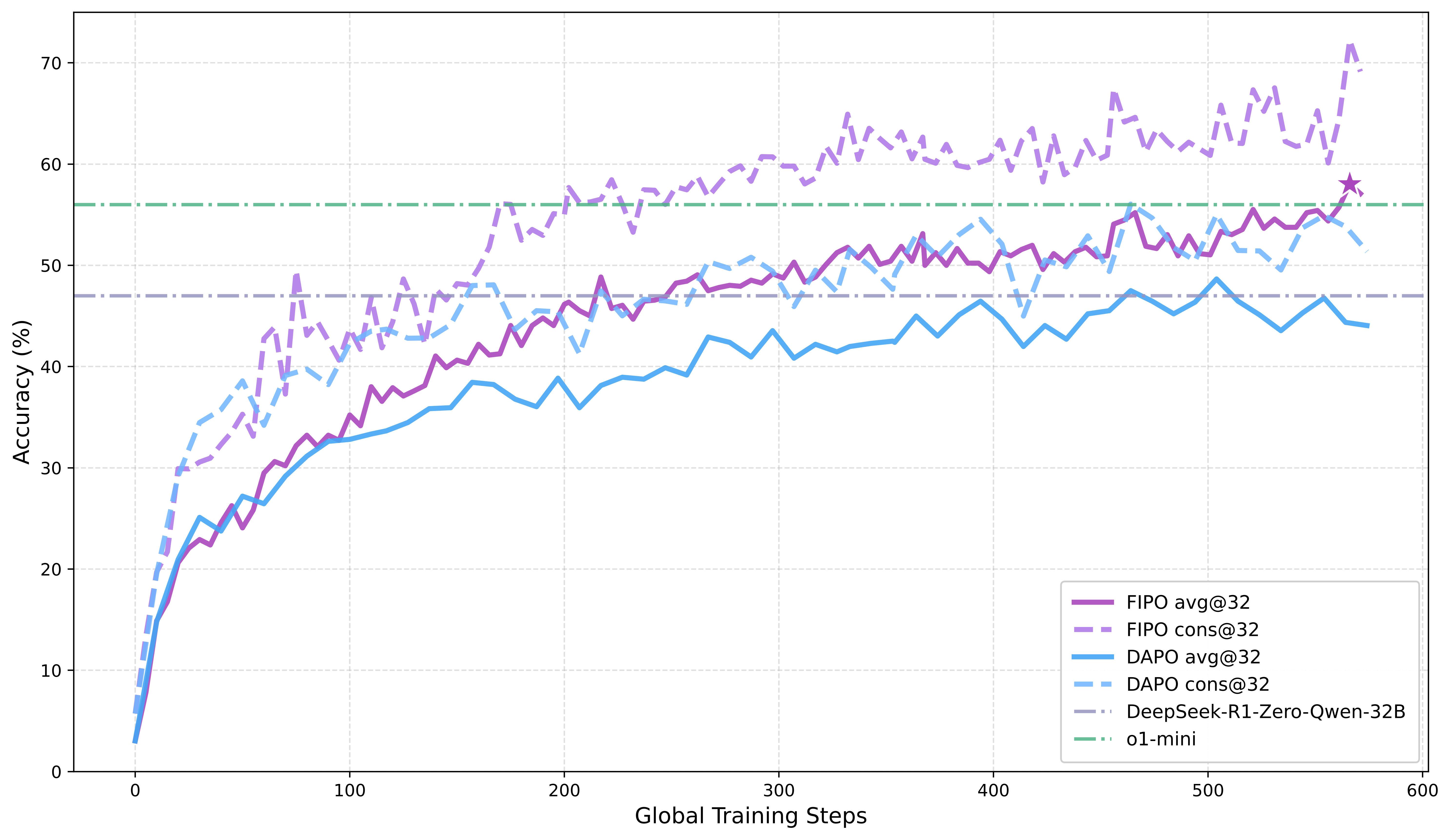
Figure 1. FIPO vs. baselines on AIME 2024. FIPO shows that pure RL training alone can outperform reproduced pure-RL baselines such as DAPO and DeepSeek-R1-Zero-32B, surpass o1-mini, and produce substantially longer responses on average.
Highlights
FIPO keeps the standard PPO/DAPO scaffold, but changes how token-level updates are weighted. The local signal is the signed log-probability shift between the current and old policy:
Positive values mean the token is being reinforced, while negative values mean it is being suppressed. Since reasoning is sequential, FIPO then accumulates this signal over the future trajectory:
FIPO maps this future signal into a bounded influence weight:
The final token-level FIPO loss keeps the standard clipped PPO/DAPO form, but replaces the original advantage with the future-aware one:
Under FIPO, the model continues to expand its reasoning budget instead of collapsing into that intermediate plateau. This helps the model use additional length as genuine reasoning depth.
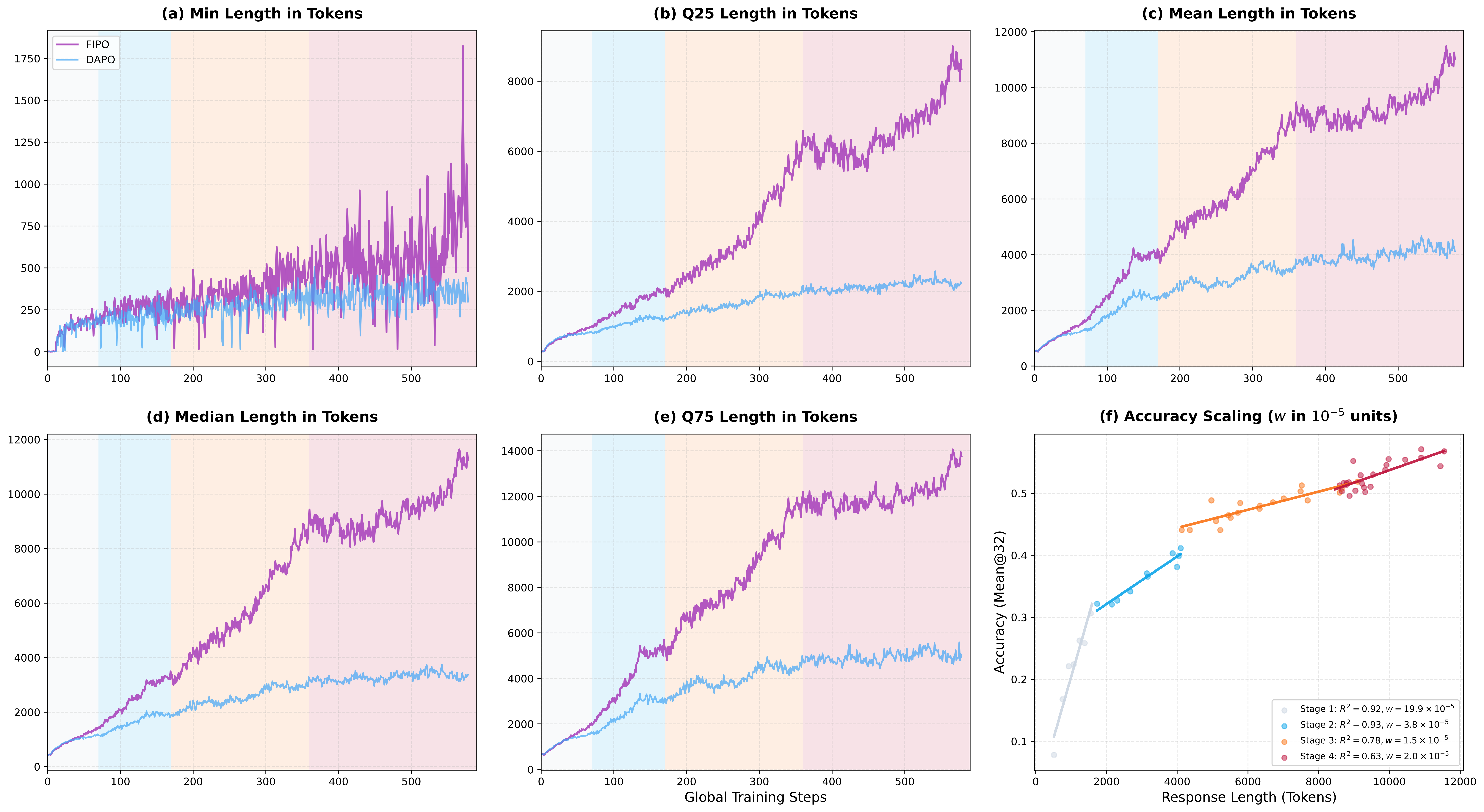
Figure 2. Dynamics of response length and performance scaling during training. Compared to the DAPO baseline, FIPO significantly increases response length and maintains a strong positive correlation between longer chain-of-thought and higher accuracy.
The FIPO objective yields longer responses and a stronger AIME 2024 peak than the DAPO baseline.
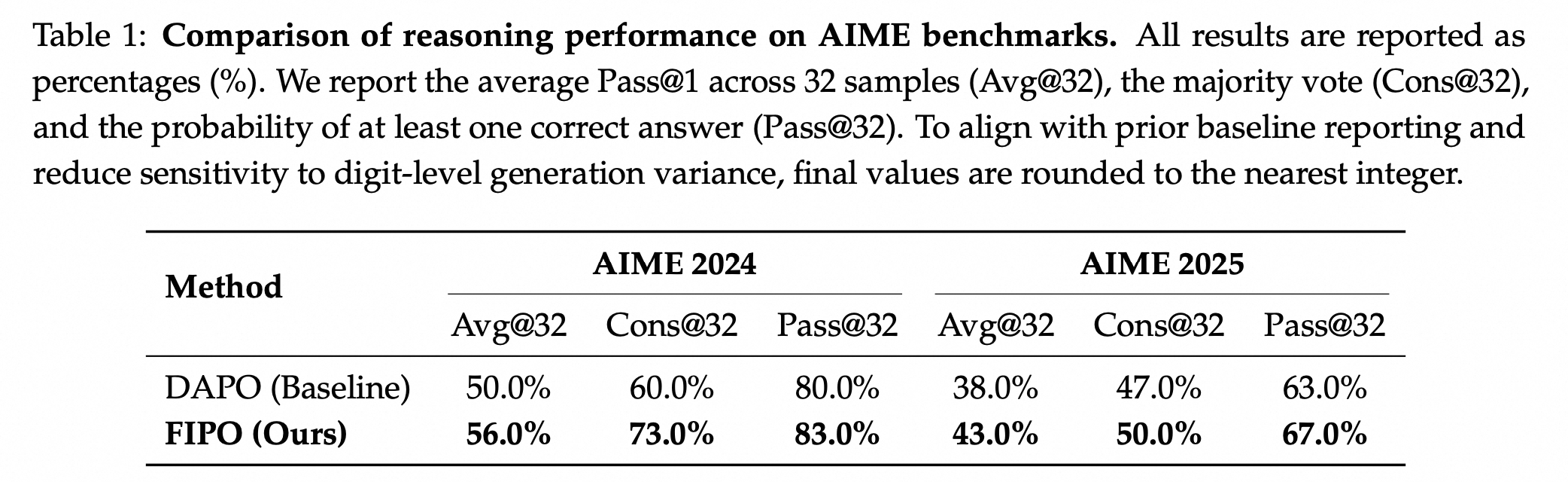
Figure 3. Main 32B result. FIPO outperforms reproduced pure-RL baselines on AIME 2024 while also producing substantially longer responses on average.
@misc{FIPO,
title = {FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization},
url = {[https://qwen-pilot.notion.site/fipo](https://qwen-pilot.notion.site/fipo)},
author = {Chiyu Ma and Shuo Yang and Kexin Huang and Jinda Lu and Haoming Meng and Shangshang Wang and Bolin Ding and Soroush Vosoughi and Guoyin Wang and Jingren Zhou},
year = {2026},
month = {March},
}
Base model
Qwen/Qwen2.5-32B