

Datarus-R1: An Adaptive Multi-Step Reasoning LLM for Automated Data Analysis
Paper • 2508.13382 • Published • 15
winget install llama.cpp
# Start a local OpenAI-compatible server with a web UI:
llama serve -hf QuantFactory/Datarus-R1-14B-preview-GGUF:# Run inference directly in the terminal:
llama cli -hf QuantFactory/Datarus-R1-14B-preview-GGUF:# Download pre-built binary from:
# https://github.com/ggerganov/llama.cpp/releases# Start a local OpenAI-compatible server with a web UI:
./llama-server -hf QuantFactory/Datarus-R1-14B-preview-GGUF:# Run inference directly in the terminal:
./llama-cli -hf QuantFactory/Datarus-R1-14B-preview-GGUF:git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
cmake -B build
cmake --build build -j --target llama-server llama-cli# Start a local OpenAI-compatible server with a web UI:
./build/bin/llama-server -hf QuantFactory/Datarus-R1-14B-preview-GGUF:# Run inference directly in the terminal:
./build/bin/llama-cli -hf QuantFactory/Datarus-R1-14B-preview-GGUF:docker model run hf.co/QuantFactory/Datarus-R1-14B-preview-GGUF:This is quantized version of DatarusAI/Datarus-R1-14B-preview created using llama.cpp
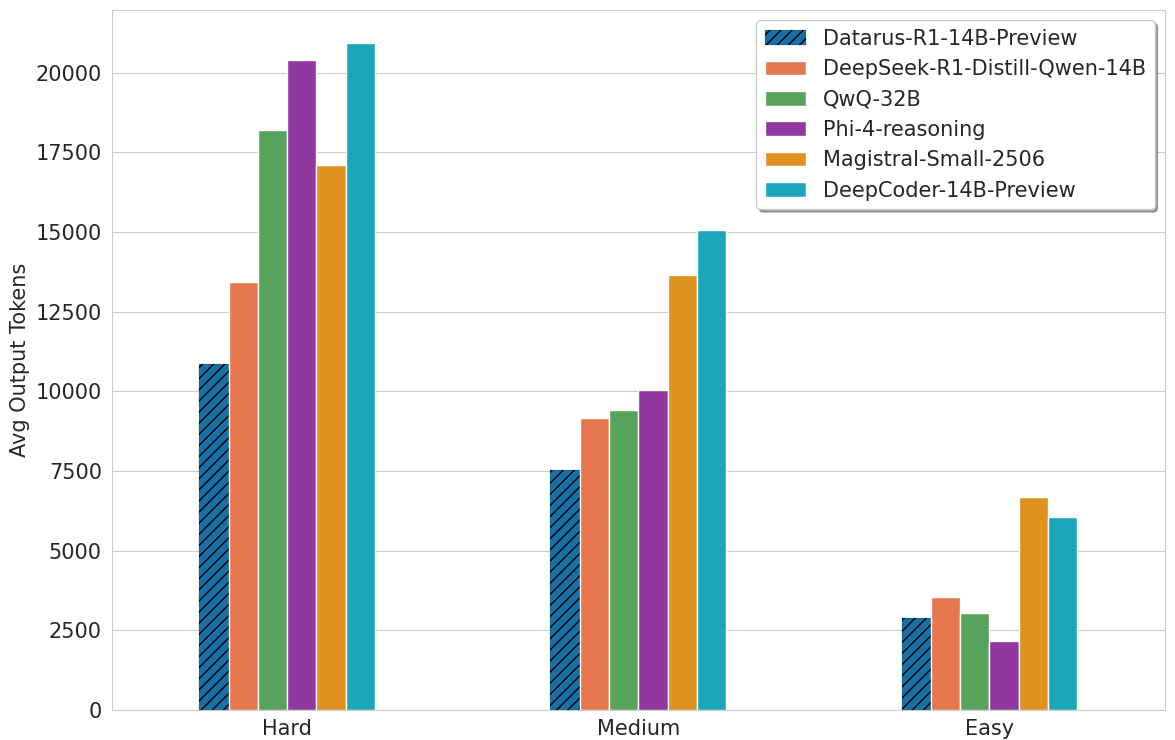
Datarus-R1-14B-Preview is a 14B-parameter open-weights language model fine-tuned from Qwen2.5-14B-Instruct, designed to act as a virtual data analyst and graduate-level problem solver. Unlike traditional models trained on isolated Q&A pairs, Datarus learns from complete analytical trajectories—including reasoning steps, code execution, error traces, self-corrections, and final conclusions—all captured in a ReAct-style notebook format.
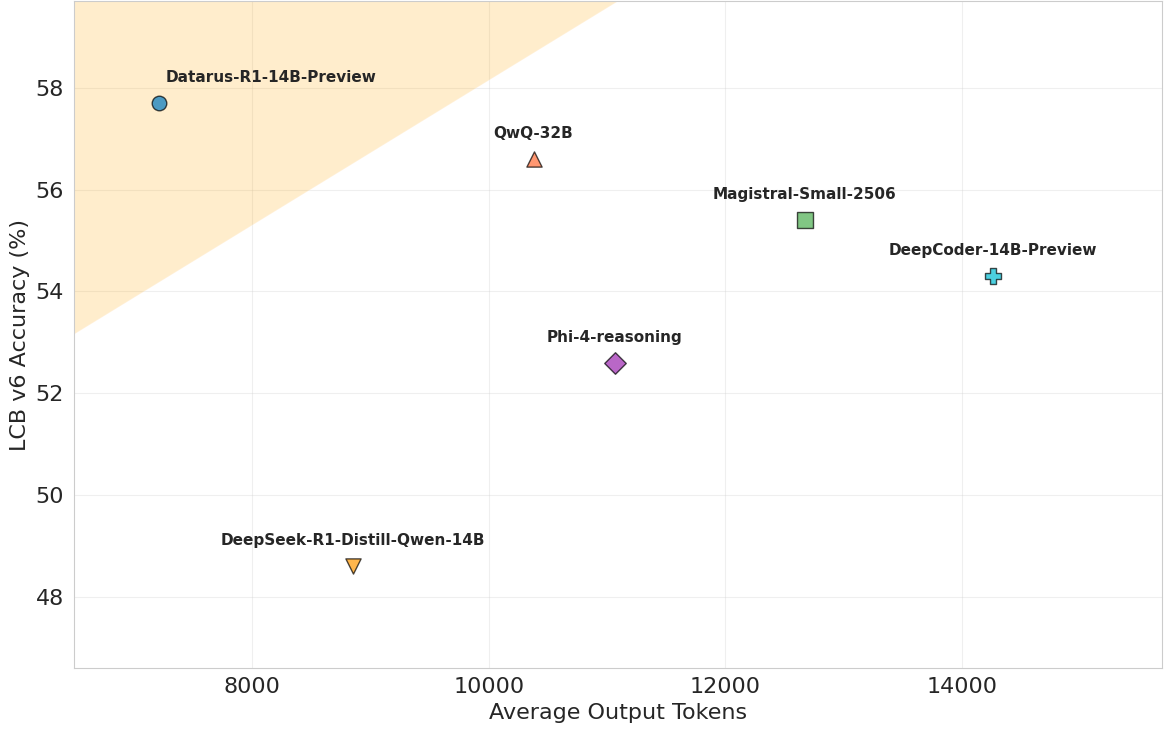
| Benchmark | Datarus-R1-14B-Preview | QwQ-32B | Phi-4-reasoning | DeepSeek-R1-Distill-14B |
|---|---|---|---|---|
| LiveCodeBench v6 | 57.7 | 56.6 | 52.6 | 48.6 |
| AIME 2024 | 70.1 | 76.2 | 74.6* | - |
| AIME 2025 | 66.2 | 66.2 | 63.1* | - |
| GPQA Diamond | 62.1 | 60.1 | 55.0 | 58.6 |
*Reported values from official papers
<step>, <thought>, <action>, <action_input>, <observation> tags<think> and <answer> tags@article{benchaliah2025datarus,
title={Datarus-R1: An Adaptive Multi-Step Reasoning LLM for Automated Data Analysis},
author={Ben Chaliah, Ayoub and Dellagi, Hela},
journal={arXiv preprint arXiv:2508.13382},
year={2025}
}
We welcome contributions! Please see our GitHub repository for:
This model is released under the Apache 2.0 License.
We thank the Qwen team for the excellent base model and the open-source community for their valuable contributions.
If you find this model and Agent pipeline useful, please consider Like/Star! Your support helps us continue improving the project.
Found a bug or have a feature request? Please open an issue on GitHub.
Made with ❤️ by the Datarus Team from Paris
4-bit
5-bit
6-bit
8-bit
Base model
Qwen/Qwen2.5-14B
Install (macOS, Linux)
# Start a local OpenAI-compatible server with a web UI: llama serve -hf QuantFactory/Datarus-R1-14B-preview-GGUF:# Run inference directly in the terminal: llama cli -hf QuantFactory/Datarus-R1-14B-preview-GGUF: