Spaces:
Sleeping

Sleeping
update readme.md
Browse files
README.md
CHANGED
|
@@ -10,108 +10,4 @@ pinned: false
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
| 13 |
-
# Python FAQs Question Answering App
|
| 14 |
-
|
| 15 |
-
This repository contains the implementation of a Question Answering (QA) app built using Retrieval Augmented Generation (RAG) techniques. The app leverages Large Language Model `mistralai/Mistral-7B-Instruct-v0.3` to answer questions about Python FAQs by retrieving and utilizing relevant data from `https://docs.python.org/3/faq/index.html`.
|
| 16 |
-
|
| 17 |
-
## Table of Contents
|
| 18 |
-
- [Introduction to RAG](#introduction-to-rag)
|
| 19 |
-
- [Purpose of RAG](#purpose-of-rag)
|
| 20 |
-
- [Components of a RAG Application](#components-of-a-rag-application)
|
| 21 |
-
- [Workflow of a RAG Application](#workflow-of-a-rag-application)
|
| 22 |
-
- [Tools and Technologies](#tools-and-technologies)
|
| 23 |
-
- [Installation and Setup](#installation-and-setup)
|
| 24 |
-
- [Running the Application](#running-the-application)
|
| 25 |
-
- [Example Application Workflow](#example-application-workflow)
|
| 26 |
-
- [Advanced Techniques and Resources](#advanced-techniques-and-resources)
|
| 27 |
-
|
| 28 |
-
## Introduction to RAG
|
| 29 |
-
|
| 30 |
-
**Retrieval Augmented Generation (RAG)** is a technique for building sophisticated question-answering (Q&A) applications using Large Language Models (LLMs). These applications enhance the capabilities of LLMs by augmenting them with additional, relevant data.
|
| 31 |
-
|
| 32 |
-
## Purpose of RAG
|
| 33 |
-
- **Enhancing LLMs**: Integrates private or recent data to improve the model's reasoning ability.
|
| 34 |
-
- **Application**: Used to create Q&A chatbots for specific data sources.
|
| 35 |
-
|
| 36 |
-
## Components of a RAG Application
|
| 37 |
-
1. **Indexing**
|
| 38 |
-
- **Loading Data**: Ingesting data using DocumentLoaders.
|
| 39 |
-
- **Splitting Text**: Breaking large documents into smaller chunks using text splitters.
|
| 40 |
-
- **Storing Data**: Indexing and storing text chunks using a VectorStore and an Embeddings model.
|
| 41 |
-
|
| 42 |
-
2. **Retrieval and Generation**
|
| 43 |
-
- **Retrieving Data**: Using a Retriever to fetch relevant data chunks based on user queries.
|
| 44 |
-
- **Generating Answers**: Using a ChatModel or LLM to produce answers by combining user queries with retrieved data.
|
| 45 |
-
|
| 46 |
-
## Workflow of a RAG Application
|
| 47 |
-
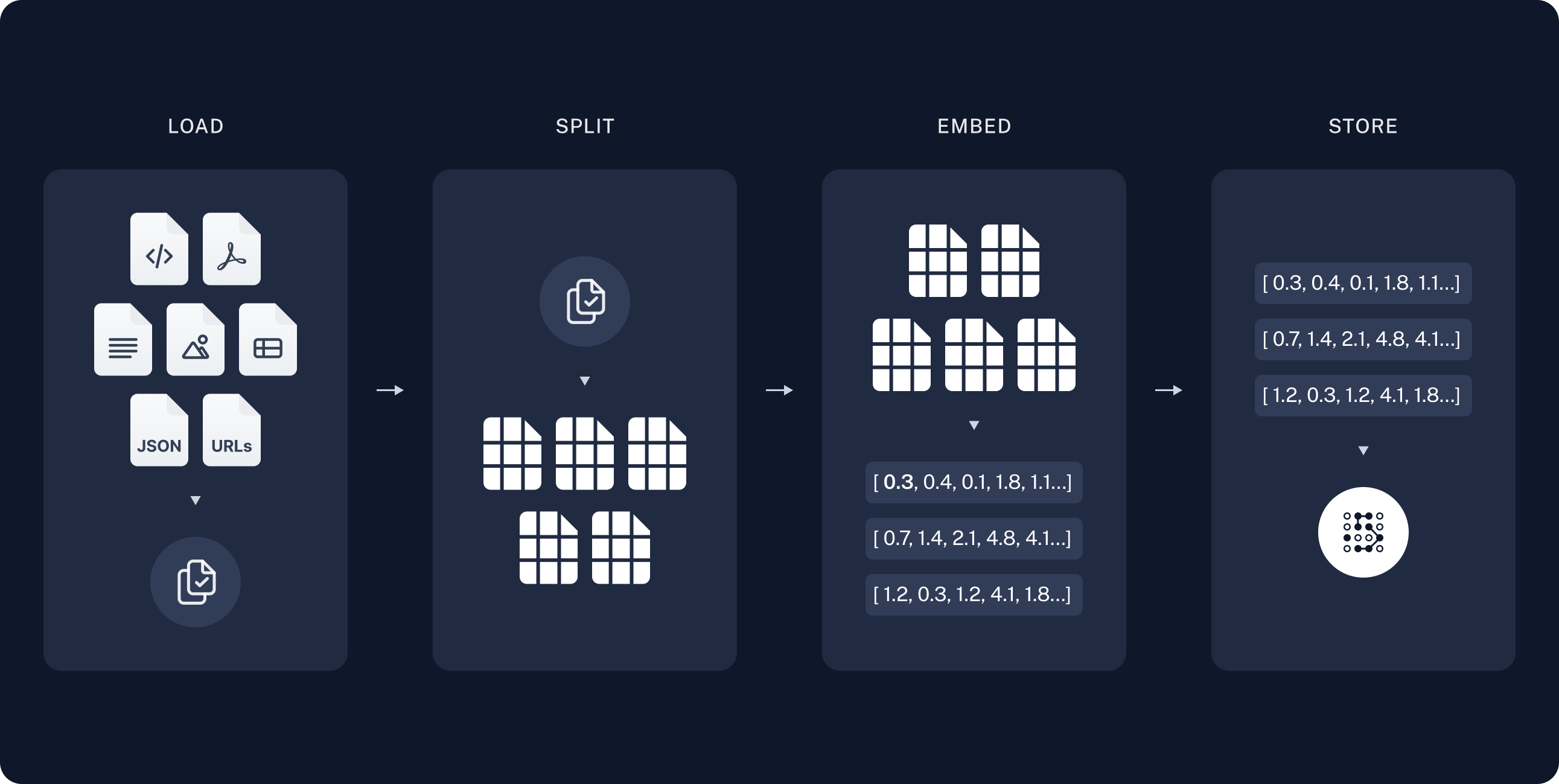
1. **Indexing Phase**
|
| 48 |
-
- **Load**: Import data using DocumentLoaders.
|
| 49 |
-
- **Split**: Use text splitters to divide large documents.
|
| 50 |
-
- **Store**: Index and store chunks in a VectorStore.
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
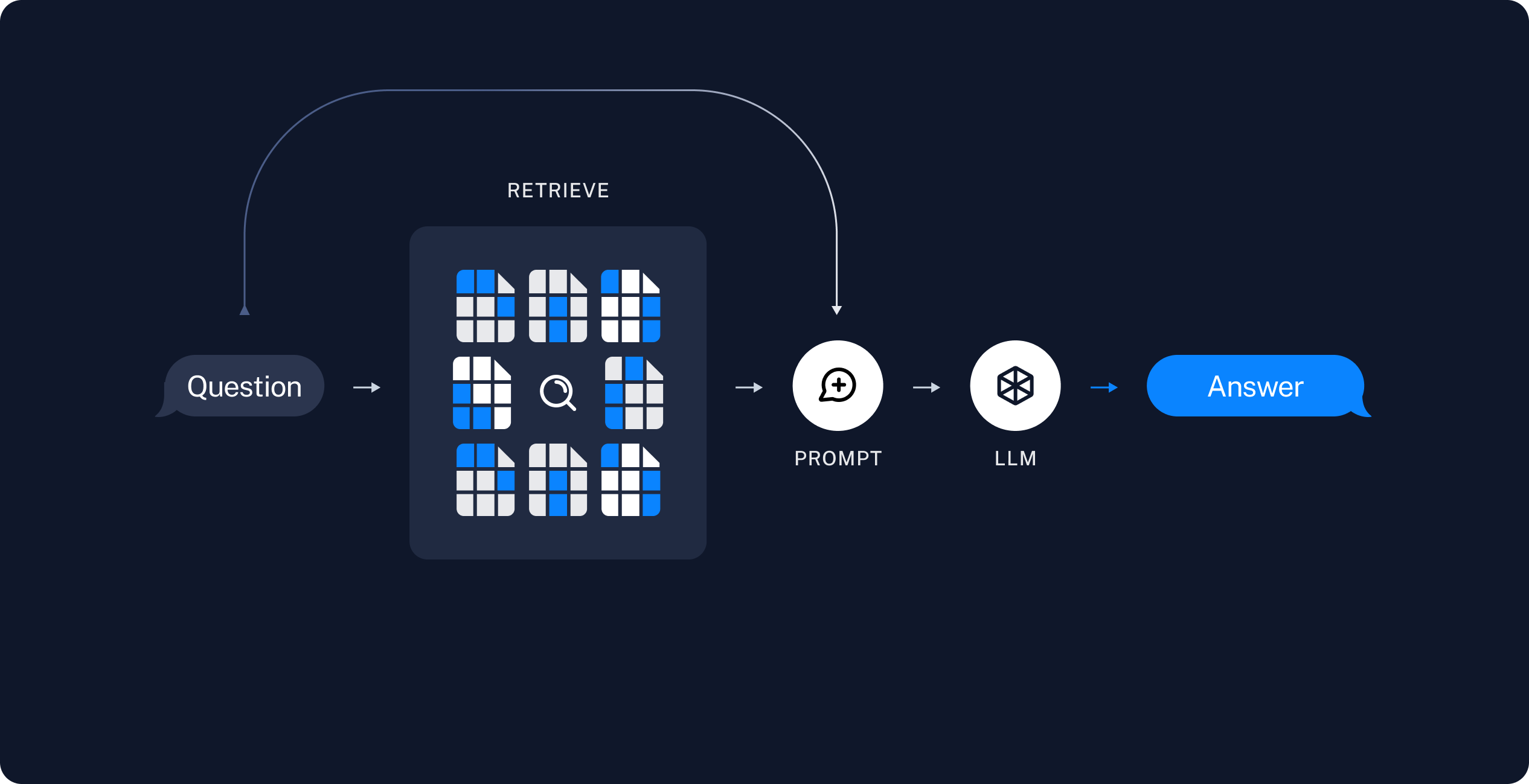
2. **Retrieval and Generation Phase**
|
| 54 |
-
- **Retrieve**: Retrieve relevant chunks based on user queries.
|
| 55 |
-
- **Generate**: Use retrieved data and user queries to generate answers.
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
## Tools and Technologies
|
| 59 |
-
- **LangChain**: Components for building Q&A applications.
|
| 60 |
-
- **DocumentLoaders**: For loading data.
|
| 61 |
-
- **Text Splitters**: For breaking down documents.
|
| 62 |
-
- **VectorStore**: For storing and indexing data chunks.
|
| 63 |
-
- **Embeddings Model**: For creating searchable vector representations.
|
| 64 |
-
- **Retriever**: For fetching relevant data chunks.
|
| 65 |
-
- **ChatModel/LLM**: For generating answers.
|
| 66 |
-
|
| 67 |
-
## Installation and Setup
|
| 68 |
-
|
| 69 |
-
1. Clone the repository:
|
| 70 |
-
```bash
|
| 71 |
-
git clone https://github.com/your-repo/python-faqs-qa-app.git
|
| 72 |
-
cd python-faqs-qa-app
|
| 73 |
-
```
|
| 74 |
-
|
| 75 |
-
2. Install the required dependencies:
|
| 76 |
-
```bash
|
| 77 |
-
pip install -r requirements.txt
|
| 78 |
-
```
|
| 79 |
-
|
| 80 |
-
3. Set up environment variables:
|
| 81 |
-
Create a `.env` file in the root directory and add your API keys:
|
| 82 |
-
```bash
|
| 83 |
-
LANGCHAIN_API_KEY=your_langchain_api_key
|
| 84 |
-
HUGGINGFACEHUB_API_TOKEN=your_huggingfacehub_api_token
|
| 85 |
-
```
|
| 86 |
-
|
| 87 |
-
## Running the Application
|
| 88 |
-
|
| 89 |
-
1. Run the Streamlit app:
|
| 90 |
-
```bash
|
| 91 |
-
streamlit run app.py
|
| 92 |
-
```
|
| 93 |
-
|
| 94 |
-
2. Open your browser and go to `http://localhost:8501` to use the app.
|
| 95 |
-
|
| 96 |
-
## Example Application Workflow
|
| 97 |
-
|
| 98 |
-
1. **Data Ingestion**: Load a large text document using DocumentLoaders.
|
| 99 |
-
2. **Data Preparation**: Split the document into smaller chunks with text splitters.
|
| 100 |
-
3. **Data Indexing**: Store chunks in a VectorStore.
|
| 101 |
-
4. **Query Processing**:
|
| 102 |
-
- The Retriever searches the VectorStore for relevant data chunks based on user queries.
|
| 103 |
-
- Retrieved data and user queries are used by the LLM to generate answers.
|
| 104 |
-
|
| 105 |
-
## Advanced Techniques and Resources
|
| 106 |
-
|
| 107 |
-
- **LangSmith**: Tool for tracing and understanding the application.
|
| 108 |
-
- **RAG over Structured Data**: Applying RAG to structured data like SQL databases using LangChain.
|
| 109 |
-
|
| 110 |
-
---
|
| 111 |
-
|
| 112 |
-
Made with ❤️ on python by Raghu
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
|
| 117 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|