Spaces:
Sleeping


Sleeping
deploy: sync 9f3554b5 from GitHub Actions
Browse files- README.md +5 -3
- blog.md +0 -211
- src/server/app.py +23 -7
- src/server/environment.py +43 -15
README.md
CHANGED
|
@@ -35,11 +35,13 @@ A single LLM call can produce structurally valid HTML that looks nothing like th
|
|
| 35 |
### API
|
| 36 |
|
| 37 |
```
|
| 38 |
-
POST /reset?difficulty=easy|medium|hard → { session_id, screenshot_b64 }
|
| 39 |
-
POST /step { html, session_id }
|
| 40 |
-
POST /render { html }
|
| 41 |
```
|
| 42 |
|
|
|
|
|
|
|
| 43 |
Episodes run for up to 5 steps. Every submission is rendered by Playwright (headless Chromium) at `320×240` (low-res preview) and `640×480` (full-res, used for reward and Critic).
|
| 44 |
|
| 45 |
### Two-Agent Loop
|
|
|
|
| 35 |
### API
|
| 36 |
|
| 37 |
```
|
| 38 |
+
POST /reset?difficulty=easy|medium|hard&max_steps=5 → { session_id, screenshot_b64 }
|
| 39 |
+
POST /step { html, session_id } → { reward, render_low, render_full, done }
|
| 40 |
+
POST /render { html } → { image_b64 }
|
| 41 |
```
|
| 42 |
|
| 43 |
+
`max_steps` defaults to 5. Render resolutions default to `320×240` (low) and `640×480` (full) and can be overridden at startup via `LOW_RES=WxH` and `FULL_RES=WxH` env vars.
|
| 44 |
+
|
| 45 |
Episodes run for up to 5 steps. Every submission is rendered by Playwright (headless Chromium) at `320×240` (low-res preview) and `640×480` (full-res, used for reward and Critic).
|
| 46 |
|
| 47 |
### Two-Agent Loop
|
blog.md
DELETED
|
@@ -1,211 +0,0 @@
|
|
| 1 |
-
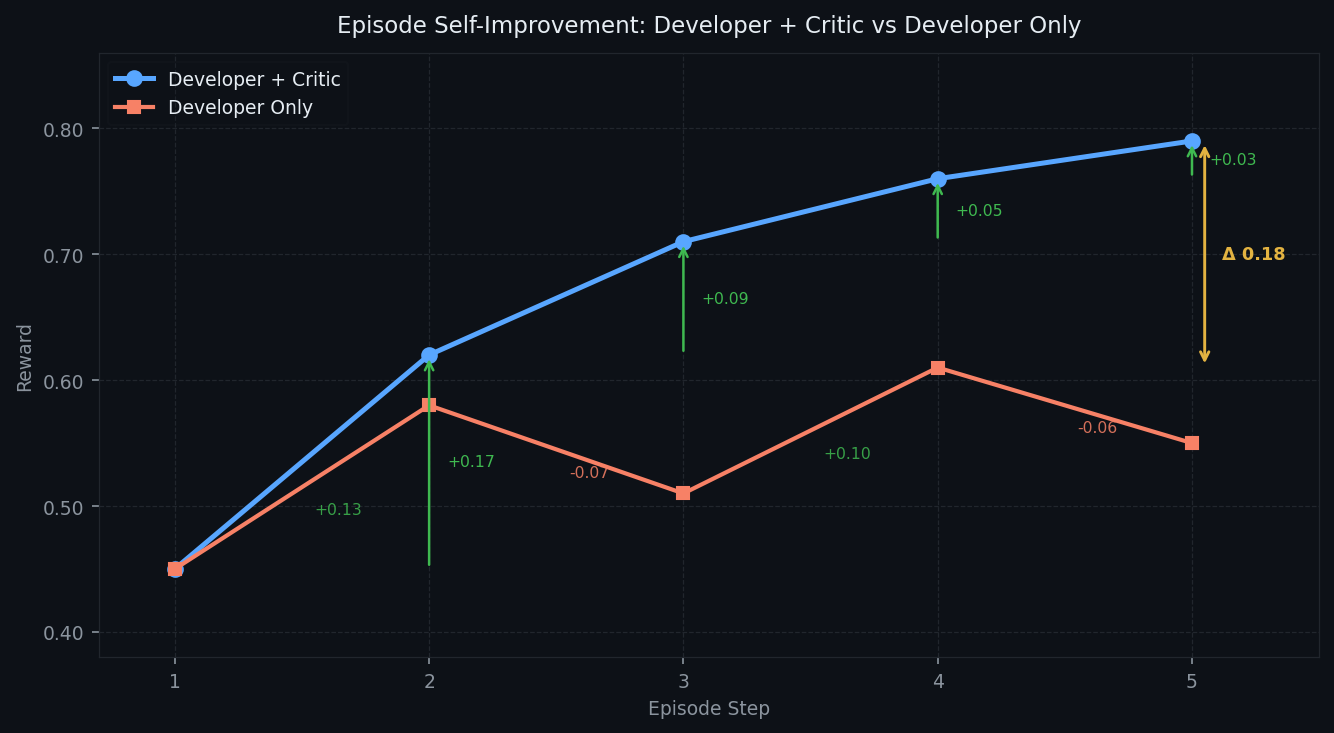
# VisionCoder OpenEnv | Screenshot-to-HTML with Multi-Agent RL
|
| 2 |
-
|
| 3 |
-
**Scaler × Meta PyTorch Hackathon 2026 | Solo submission by [@amaljoe88](https://huggingface.co/spaces/amaljoe88/vision-coder-openenv)**
|
| 4 |
-
|
| 5 |
-
---
|
| 6 |
-
|
| 7 |
-
## The Problem
|
| 8 |
-
|
| 9 |
-
Turn a screenshot into working HTML. It sounds simple but it forces a model to do two hard things at once: *understand what the UI looks like visually* and *express that understanding in code*. A single LLM call tends to produce structurally valid HTML that looks nothing like the reference. Headings are present, a button is present but the layout is wrong, colors are off, nothing is positioned correctly.
|
| 10 |
-
|
| 11 |
-
The deeper problem: **the model can't see its own output.** It generates HTML blindly, has no way to compare what it produced against the target, and has no feedback loop to improve.
|
| 12 |
-
|
| 13 |
-
We turned this into a **reinforcement learning problem**. The agent generates HTML, a real browser renders it, a reward function computes visual similarity to the reference, and the agent iterates. The environment runs as an HTTP API compatible with the OpenEnv standard.
|
| 14 |
-
|
| 15 |
-
---
|
| 16 |
-
|
| 17 |
-
## The Environment
|
| 18 |
-
|
| 19 |
-
### OpenEnv-Compatible HTTP API
|
| 20 |
-
|
| 21 |
-
```
|
| 22 |
-
POST /reset?difficulty=easy|medium|hard → { session_id, screenshot_b64 }
|
| 23 |
-
POST /step { html, session_id } → { reward, render_low, render_full, done }
|
| 24 |
-
POST /render { html } → { image_b64 }
|
| 25 |
-
```
|
| 26 |
-
|
| 27 |
-
Every HTML submission is rendered by a headless Chromium at two resolutions: `320×240` (low-res, passed back to the Developer each turn) and `640×480` (full-res, used by the Critic and reward computation). Episodes run for up to n(=5) steps.
|
| 28 |
-
|
| 29 |
-
### Composite Reward Function
|
| 30 |
-
|
| 31 |
-
The reward is a weighted sum of 8 sub-scores, each measuring a different aspect of visual and structural similarity. The weights asssigned to each reward are tuned using an auto research style approach (similar to [Andrej Karpathy's](https://github.com/karpathy/autoresearch)) - an AI agent loops through a large set of candidate weight combinations parallely and compares the reward ranking against human quality judgements to find the best correlation.
|
| 32 |
-
|
| 33 |
-
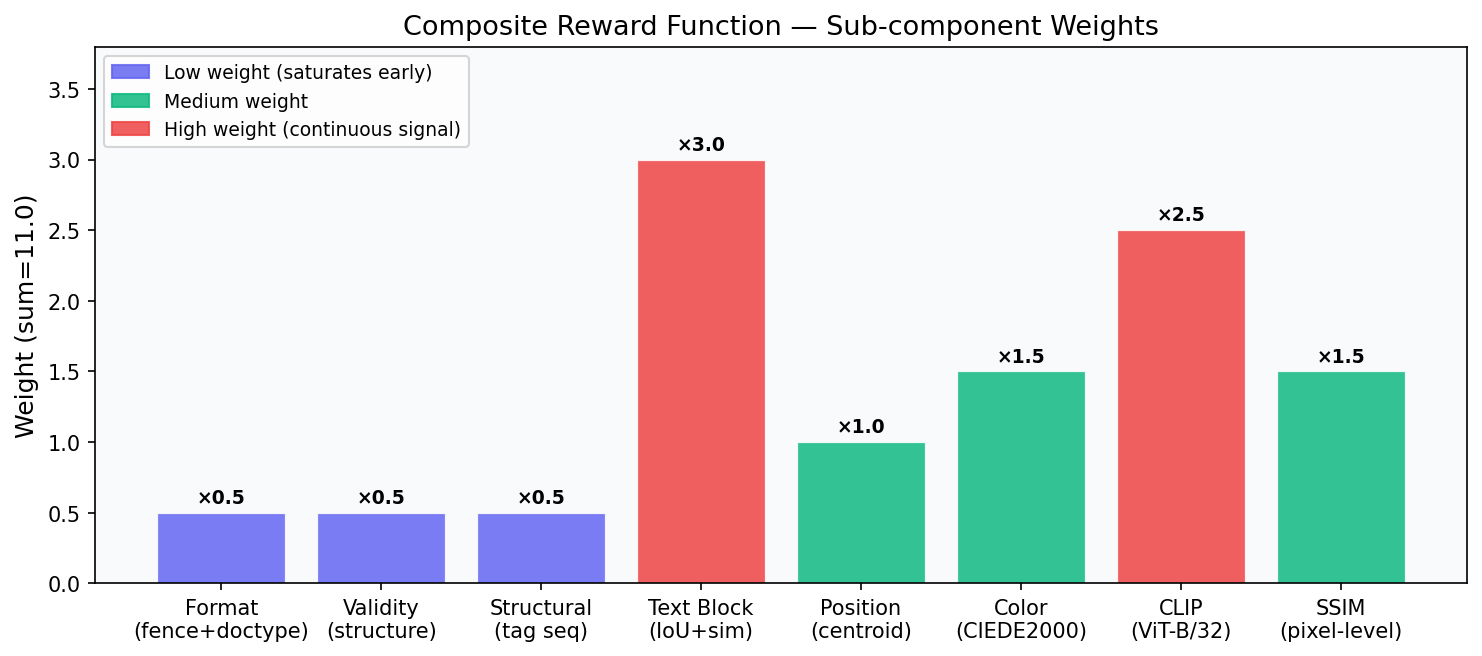
|
| 34 |
-
|
| 35 |
-
| Reward | Weight | What it measures |
|
| 36 |
-
|---|---|---|
|
| 37 |
-
| `format` | 0.5 | Has ` ```html ` fence + `<!DOCTYPE html>` |
|
| 38 |
-
| `validity` | 0.5 | Structural completeness (html/head/body, diverse tags) |
|
| 39 |
-
| `structural` | 0.5 | Tag-sequence similarity + inline-style property coverage |
|
| 40 |
-
| `text_block` | **3.0** | Hungarian-matched text block IoU + text similarity |
|
| 41 |
-
| `position` | 1.0 | Hungarian-matched centroid distance |
|
| 42 |
-
| `color` | 1.5 | Spatial CIEDE2000 on reference non-white pixels |
|
| 43 |
-
| `clip` | **2.5** | CLIP ViT-B/32 cosine similarity, renormalised (threshold 0.65) |
|
| 44 |
-
| `ssim` | 1.5 | Pixel-level SSIM (skimage, 320×240 RGB) |
|
| 45 |
-
|
| 46 |
-
Low-weight rewards (`format`, `validity`, `structural`) saturate early, a structurally complete page already scores near 1.0 on these regardless of visual quality. The high-weight rewards (`text_block`, `clip`, `ssim`) stay discriminative all the way to near-perfect renders. This keeps the gradient signal alive even when the model is already producing good output.
|
| 47 |
-
|
| 48 |
-
### Does the Reward Reflect Human Judgement?
|
| 49 |
-
|
| 50 |
-
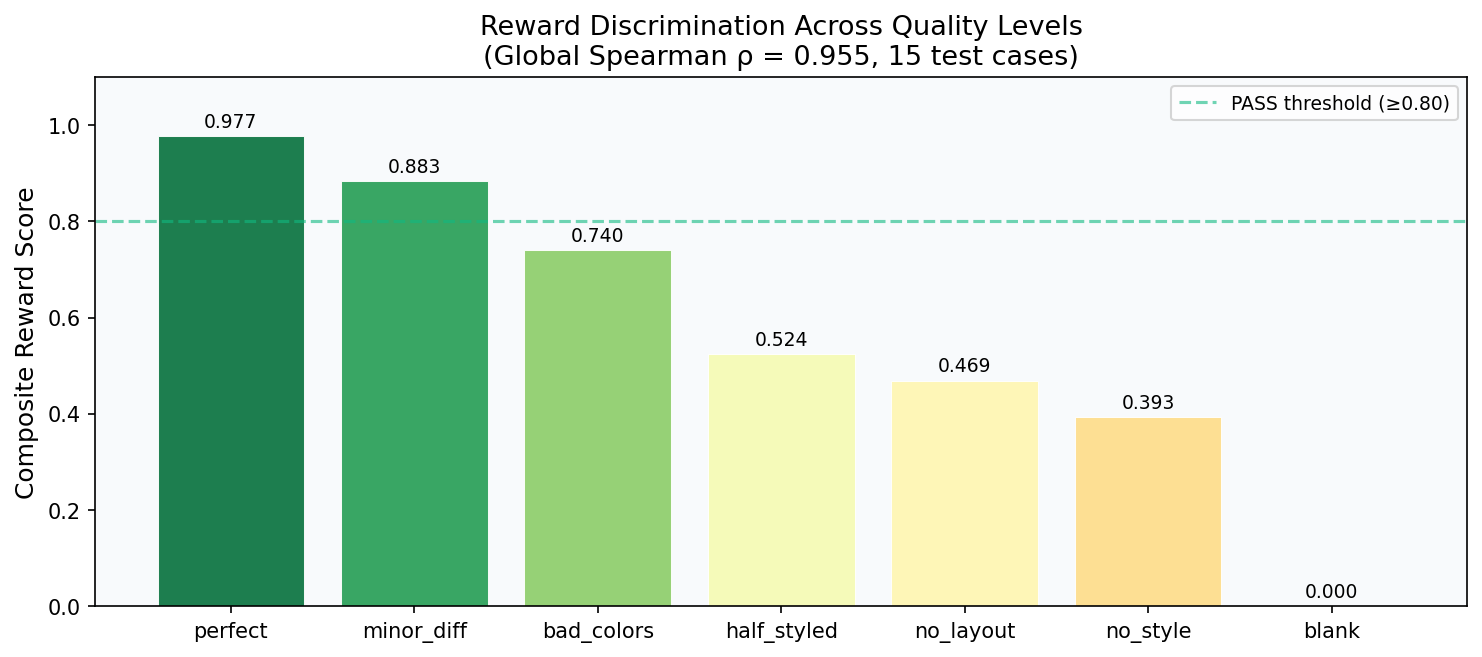
We validated the final reward function against human-labelled quality levels across 15 reference pages (5 per difficulty). For each reference, we tested 7 variants ranging from blank to perfect:
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
**Global Spearman ρ = 0.955** — the reward ranking matches human quality judgement on most of the test cases. The chart above shows the reward correctly ordering all 7 levels with clear gaps between them.
|
| 55 |
-
|
| 56 |
-
Browse all 15 test case renders with per-sub-reward breakdowns in the **[interactive demo](https://amaljoe.github.io/vision-coder-openenv/)**.
|
| 57 |
-
|
| 58 |
-
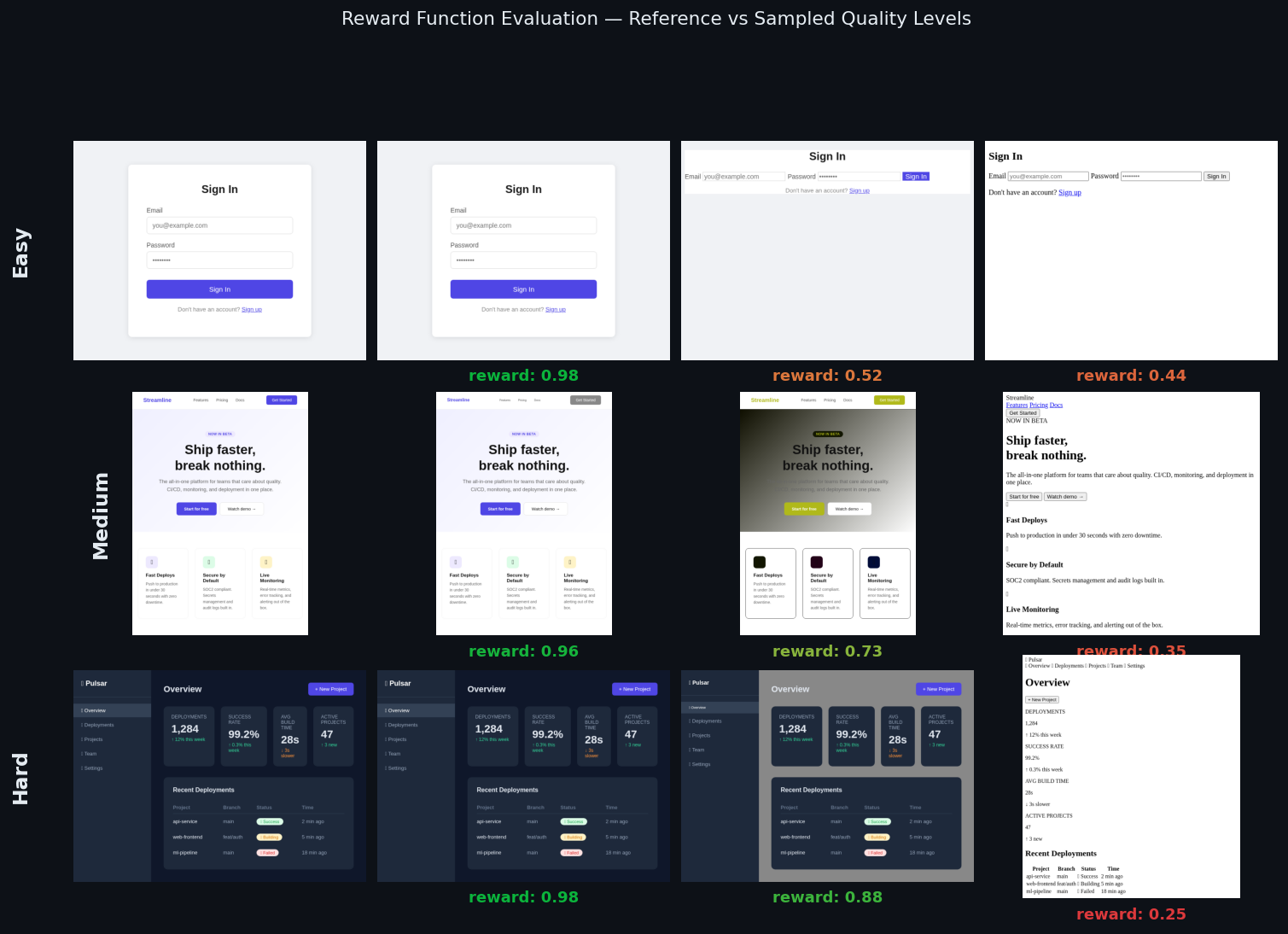
The grid below shows sampled renders from three tasks alongside their reward scores. Each row shows a reference and three variants at different quality levels, ordered from best to worst:
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
> **Content Multiplier:** We noticed strong correlation with human judgement for most pages, but blank renders were receiving rewards of ~0.3 from sub-rewards like `format` and `validity` that don't require visual content. To fix this, we applied a content multiplier: if the predicted render has fewer than 0.5% non-white pixels while the reference has content, the total reward is forced to 0. A blank page which typically means something prevented rendering (a JavaScript error, a malformed tag, or the model failing to generate HTML at all) now gets the worst possible reward and is correctly treated as a major failure signal.
|
| 63 |
-
|
| 64 |
-
---
|
| 65 |
-
|
| 66 |
-
## The Multi-Agent Architecture
|
| 67 |
-
|
| 68 |
-
### Why Two Agents?
|
| 69 |
-
|
| 70 |
-
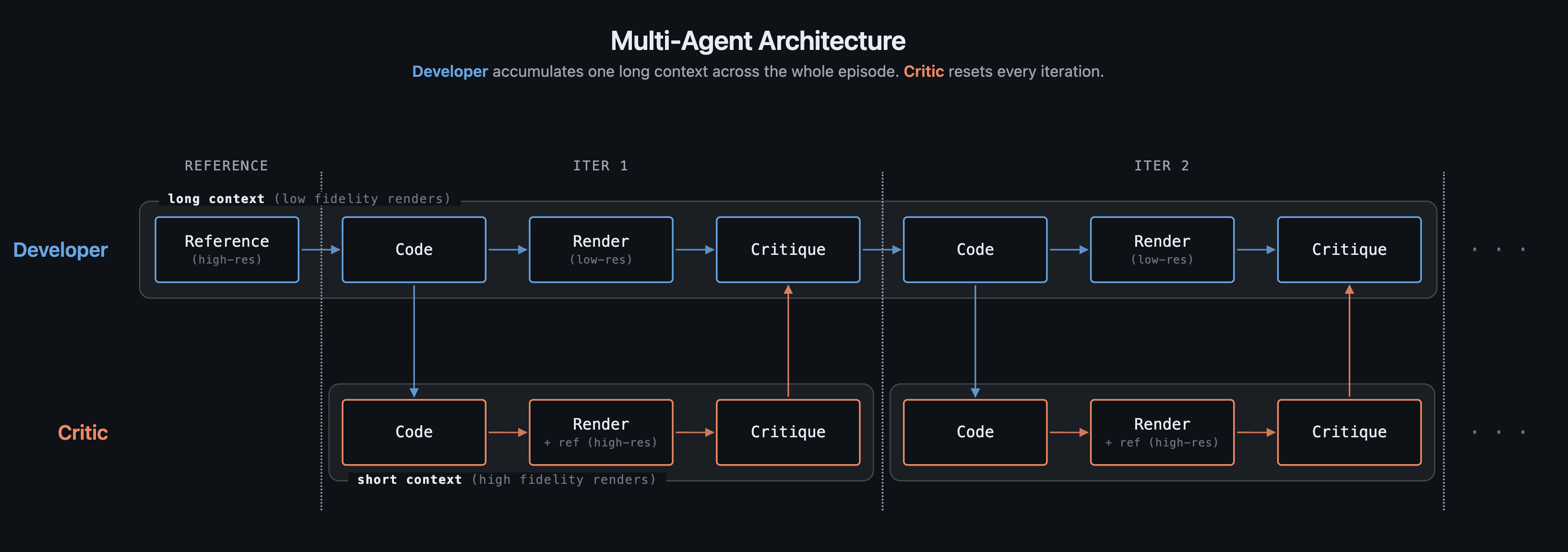
A single agent can generate HTML and receive a reward. But the reward is a single number: it tells the model *how bad* the output is, not *what is wrong* or *which selector to fix*. Without visual feedback, the model improvises changes at random and often regresses.
|
| 71 |
-
|
| 72 |
-
The Critic solves this. It looks at both the reference and the current render side by side, reads the HTML source, and produces specific CSS fix instructions. The Developer reads those fixes and applies them in the next step; no guessing required.
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
### Why Not Just Pass Everything to One Model?
|
| 77 |
-
|
| 78 |
-
Context cost. Vision models encode images as sequences of tokens; the number of tokens scales with pixel count:
|
| 79 |
-
|
| 80 |
-
| Image | Resolution | Visual tokens |
|
| 81 |
-
|---|---|---|
|
| 82 |
-
| Low-res render | 320×240 | ~256 |
|
| 83 |
-
| Full-res render / reference | 640×480 | ~1,024 |
|
| 84 |
-
| Full HD (hypothetical) | 1920×1080 | ~9,800 |
|
| 85 |
-
|
| 86 |
-
With full-HD inputs, two images alone would cost ~19,600 tokens exhausting the context budget of a typical consumer GPU before a single token of HTML is generated. Even at our working resolution, giving the Developer both high-res images every step would double its context cost per step across the entire episode and this cost increases quadratically with higher resolutions.
|
| 87 |
-
|
| 88 |
-
### What the Critic Produces
|
| 89 |
-
|
| 90 |
-
```
|
| 91 |
-
[+] HIGH | LAYOUT — products grid is 1-column; reference shows 3-column
|
| 92 |
-
→ FIX: `.products { display: grid; grid-template-columns: repeat(3, 1fr); gap: 24px; }`
|
| 93 |
-
|
| 94 |
-
[+] MEDIUM | COLOR — nav background is white; reference shows dark navy
|
| 95 |
-
→ FIX: `nav { background-color: #0f172a; }`
|
| 96 |
-
```
|
| 97 |
-
|
| 98 |
-
This is fundamentally different from abstract feedback ("the layout is wrong"). The Developer reads the `→ FIX:` line and applies it to the exact CSS selector, no interpretation required.
|
| 99 |
-
|
| 100 |
-
### Self-Improvement Over an Episode
|
| 101 |
-
|
| 102 |
-
Each developer step sees the HTML code generated so far alongside reviews from the critic model and its low-resolution renders (to maintain a manageable context size).
|
| 103 |
-
|
| 104 |
-
The graph below shows what happens with and without the Critic over a 5-step episode:
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
Without structured feedback, the Developer oscillates: it makes changes that sometimes improve and sometimes regress the reward. With the Critic providing selector-specific fixes, the reward climbs monotonically. By step 5, Developer + Critic has opened a **Δ0.21 gap** over Developer Only.
|
| 109 |
-
|
| 110 |
-
---
|
| 111 |
-
|
| 112 |
-
## RL Training: Full-Episode GRPO
|
| 113 |
-
|
| 114 |
-
### Full-Episode Training
|
| 115 |
-
|
| 116 |
-
Full-episode GRPO samples K complete trajectories, scores each one by total episode reward, and applies group-relative advantage to every token in the trajectory. Reward shaping is also used to add additional intermediate rewards (difference in rewards between each iteration):
|
| 117 |
-
|
| 118 |
-
```
|
| 119 |
-
R_total(t) = R_terminal + λ · Σ(r_s - r_{s-1} for s = t..n)
|
| 120 |
-
|
| 121 |
-
R_terminal = environment score at final step n ← main signal
|
| 122 |
-
r_s - r_{s-1} = per-step improvement delta ← shaped signal
|
| 123 |
-
λ = 0.2 ← keeps shaped signal subordinate
|
| 124 |
-
```
|
| 125 |
-
|
| 126 |
-
```
|
| 127 |
-
for each task:
|
| 128 |
-
sample K=4 full trajectories (different temperatures/seeds)
|
| 129 |
-
score each: R_terminal_k + shaped improvement deltas
|
| 130 |
-
advantage: A_t = (G_t - mean_k) / std_k
|
| 131 |
-
update: ∇ log π(a_t | s_t) · A_t for all tokens in trajectory
|
| 132 |
-
```
|
| 133 |
-
|
| 134 |
-
### Training Configuration
|
| 135 |
-
|
| 136 |
-
- **Base model**: [`Qwen/Qwen3.5-2B`](https://huggingface.co/Qwen/Qwen3.5-2B) (unified vision+text)
|
| 137 |
-
- **LoRA**: rank=16, α=32, 0.49% trainable parameters (10.9M / 2.2B)
|
| 138 |
-
- **Optimizer**: AdamW, lr=2e-5, max_grad_norm=1.0
|
| 139 |
-
- **Hardware**: 2× NVIDIA A100 80GB PCIe
|
| 140 |
-
- **Episodes**: 20 × 4 rollouts = 80 trajectories
|
| 141 |
-
|
| 142 |
-
### Training Curve
|
| 143 |
-
|
| 144 |
-
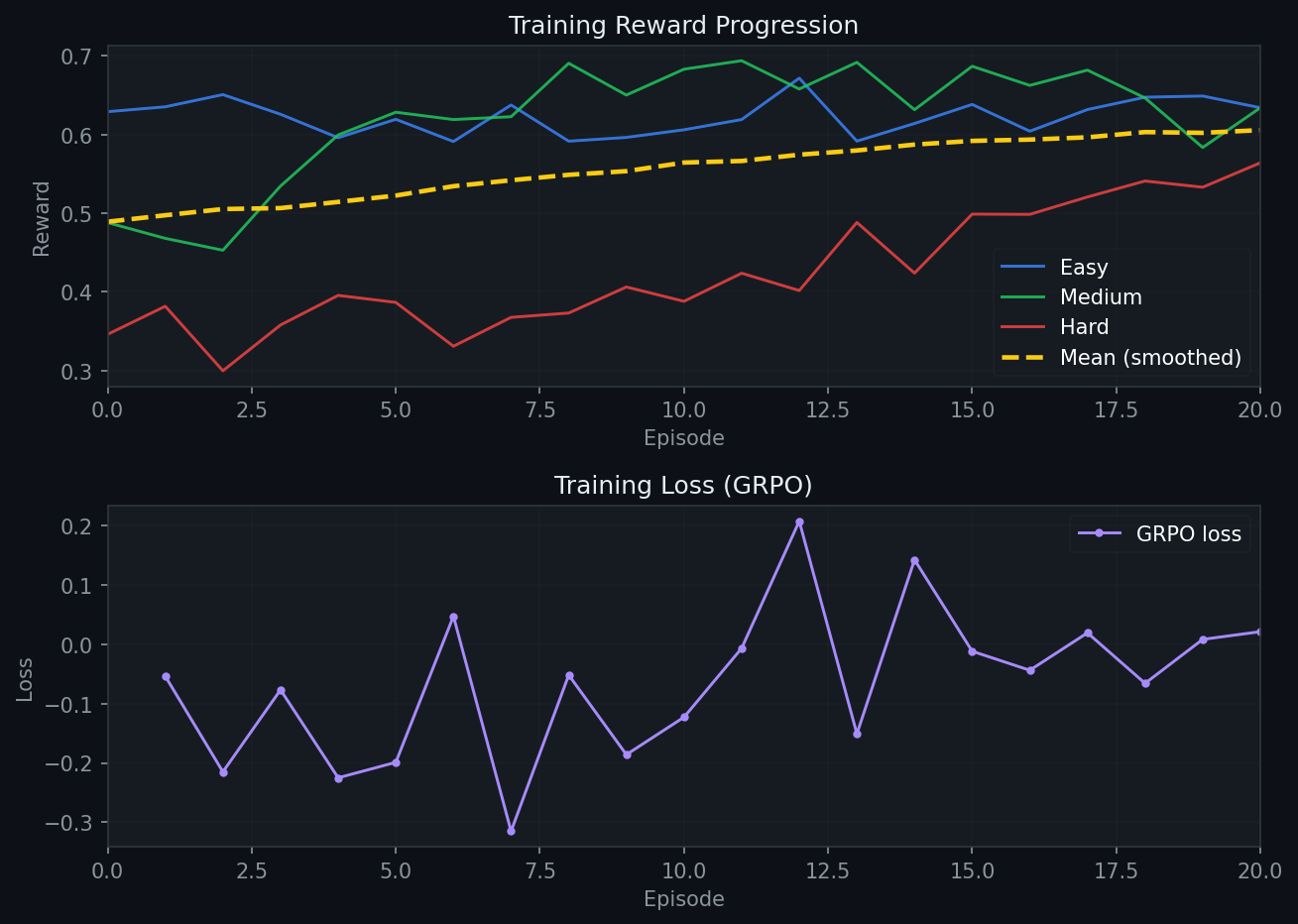
|
| 145 |
-
|
| 146 |
-
The three difficulty tracks tell different stories:
|
| 147 |
-
|
| 148 |
-
**Easy (blue)** starts at 0.629. Simple login forms and single-column layouts are already within reach of the base model. There is very little headroom left, so the curve shows mostly small fluctuations with a slight upward drift. The model is already close to its ceiling on these tasks at baseline.
|
| 149 |
-
|
| 150 |
-
**Medium (green)** starts at 0.488 and ends at 0.634 (+0.146). Multi-column grids and landing pages require the Critic's feedback to land correctly. The reward climbs early as the model learns to apply CSS fixes more precisely.
|
| 151 |
-
|
| 152 |
-
**Hard (red)** shows the clearest improvement: 0.346 → 0.564 (+0.218). Complex dashboards and Kanban boards depend on deeply nested flex/grid structures where small CSS errors collapse entire layout regions. At baseline, the model struggles to reconstruct these. With GRPO reinforcing the Critic's CSS fix patterns, it learns which selectors control which regions and how to fix them efficiently. The performance keeps on climbing even at 20 iterations and shows potential for more improvement. **Hard tasks benefit the most because they have the most to gain.**
|
| 153 |
-
|
| 154 |
-
---
|
| 155 |
-
|
| 156 |
-
## RL Training Results: Base vs Trained 2B
|
| 157 |
-
|
| 158 |
-
Scores at iteration 0 (untrained) vs iteration 20 (after GRPO training), from `https://raw.githubusercontent.com/amaljoe/vision-coder-openenv/main/assets/train.jsonl`:
|
| 159 |
-
|
| 160 |
-
| Difficulty | Base (iter 0) | Trained (iter 20) | Delta |
|
| 161 |
-
|---|---|---|---|
|
| 162 |
-
| easy | 0.629 | **0.634** | +0.005 |
|
| 163 |
-
| medium | 0.488 | **0.634** | +0.146 |
|
| 164 |
-
| hard | 0.346 | **0.564** | +0.218 |
|
| 165 |
-
| **mean** | 0.488 | **0.611** | +0.123 |
|
| 166 |
-
|
| 167 |
-
**+25.2% overall improvement** from 20 iterations of full-episode GRPO on 2× A100 80GB (~2h). The pattern matches the training curve: easy was already near its ceiling, medium gained meaningfully, and hard improved the most. The Critic's structured feedback is most valuable precisely where the task is most complex.
|
| 168 |
-
|
| 169 |
-
---
|
| 170 |
-
|
| 171 |
-
## Reproduce
|
| 172 |
-
|
| 173 |
-
### Run the Environment
|
| 174 |
-
|
| 175 |
-
```bash
|
| 176 |
-
pip install -e .
|
| 177 |
-
uvicorn openenv.server.app:app --host 0.0.0.0 --port 7860
|
| 178 |
-
```
|
| 179 |
-
|
| 180 |
-
### Run Inference
|
| 181 |
-
|
| 182 |
-
```bash
|
| 183 |
-
export API_BASE_URL=https://router.huggingface.co/v1
|
| 184 |
-
export MODEL_NAME=Qwen/Qwen3.5-35B-A3B
|
| 185 |
-
export HF_TOKEN=hf_...
|
| 186 |
-
python inference.py
|
| 187 |
-
```
|
| 188 |
-
|
| 189 |
-
### Run RL Training
|
| 190 |
-
|
| 191 |
-
```bash
|
| 192 |
-
python train.py --phase combined --episodes 20 --k-rollouts 4 \
|
| 193 |
-
--model Qwen/Qwen3.5-2B --checkpoint-dir checkpoints/run1
|
| 194 |
-
```
|
| 195 |
-
|
| 196 |
-
### Run Test Suite
|
| 197 |
-
|
| 198 |
-
Run the test suite to generate rewards for the test set. These rewards can be visualised in the [interactive demo](https://amaljoe.github.io/vision-coder-openenv/).
|
| 199 |
-
|
| 200 |
-
```bash
|
| 201 |
-
python tests/test_rewards.py --render # first run (needs Playwright)
|
| 202 |
-
python tests/test_rewards.py # subsequent runs (uses cached renders)
|
| 203 |
-
```
|
| 204 |
-
|
| 205 |
-
---
|
| 206 |
-
|
| 207 |
-
## Links
|
| 208 |
-
|
| 209 |
-
- **HF Space**: [amaljoe88/vision-coder-openenv](https://huggingface.co/spaces/amaljoe88/vision-coder-openenv)
|
| 210 |
-
- **GitHub**: [amaljoe/vision-coder-openenv](https://github.com/amaljoe/vision-coder-openenv)
|
| 211 |
-
- **Interactive demo**: [amaljoe.github.io/vision-coder-openenv](https://amaljoe.github.io/vision-coder-openenv/)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
src/server/app.py
CHANGED
|
@@ -11,12 +11,14 @@ Endpoints:
|
|
| 11 |
from __future__ import annotations
|
| 12 |
|
| 13 |
import logging
|
|
|
|
|
|
|
| 14 |
|
| 15 |
from fastapi import FastAPI, HTTPException, Query
|
| 16 |
from fastapi.responses import JSONResponse
|
| 17 |
|
| 18 |
from openenv.models import Action, Observation, RenderRequest, RenderResponse, State
|
| 19 |
-
from openenv.server.environment import VisionCoderEnvironment
|
| 20 |
|
| 21 |
logging.basicConfig(level=logging.INFO)
|
| 22 |
logger = logging.getLogger(__name__)
|
|
@@ -27,7 +29,21 @@ app = FastAPI(
|
|
| 27 |
version="2.0.0",
|
| 28 |
)
|
| 29 |
|
| 30 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
|
| 33 |
@app.get("/")
|
|
@@ -62,16 +78,16 @@ def health():
|
|
| 62 |
|
| 63 |
@app.post("/reset", response_model=Observation)
|
| 64 |
def reset(
|
| 65 |
-
difficulty: str = Query(
|
| 66 |
-
|
| 67 |
-
description="Task difficulty: easy | medium | hard | mixed",
|
| 68 |
-
)
|
| 69 |
) -> Observation:
|
| 70 |
"""Start a new episode. Returns session_id and the reference screenshot."""
|
| 71 |
if difficulty not in ("easy", "medium", "hard", "mixed"):
|
| 72 |
raise HTTPException(status_code=422, detail=f"Invalid difficulty: {difficulty!r}")
|
|
|
|
|
|
|
| 73 |
try:
|
| 74 |
-
obs = _env.reset(difficulty=difficulty)
|
| 75 |
logger.info(
|
| 76 |
"Session %s started — difficulty=%s sample=%d",
|
| 77 |
obs.session_id,
|
|
|
|
| 11 |
from __future__ import annotations
|
| 12 |
|
| 13 |
import logging
|
| 14 |
+
import os
|
| 15 |
+
from typing import Optional
|
| 16 |
|
| 17 |
from fastapi import FastAPI, HTTPException, Query
|
| 18 |
from fastapi.responses import JSONResponse
|
| 19 |
|
| 20 |
from openenv.models import Action, Observation, RenderRequest, RenderResponse, State
|
| 21 |
+
from openenv.server.environment import VisionCoderEnvironment, DEFAULT_MAX_STEPS, DEFAULT_LOW_RES, DEFAULT_FULL_RES
|
| 22 |
|
| 23 |
logging.basicConfig(level=logging.INFO)
|
| 24 |
logger = logging.getLogger(__name__)
|
|
|
|
| 29 |
version="2.0.0",
|
| 30 |
)
|
| 31 |
|
| 32 |
+
def _parse_res(env_var: str, default: tuple) -> tuple:
|
| 33 |
+
val = os.environ.get(env_var, "")
|
| 34 |
+
if val:
|
| 35 |
+
try:
|
| 36 |
+
w, h = val.split("x")
|
| 37 |
+
return (int(w), int(h))
|
| 38 |
+
except Exception:
|
| 39 |
+
logger.warning("Invalid %s=%r, using default %s", env_var, val, default)
|
| 40 |
+
return default
|
| 41 |
+
|
| 42 |
+
_env = VisionCoderEnvironment(
|
| 43 |
+
max_steps=int(os.environ.get("MAX_STEPS", DEFAULT_MAX_STEPS)),
|
| 44 |
+
low_res=_parse_res("LOW_RES", DEFAULT_LOW_RES),
|
| 45 |
+
full_res=_parse_res("FULL_RES", DEFAULT_FULL_RES),
|
| 46 |
+
)
|
| 47 |
|
| 48 |
|
| 49 |
@app.get("/")
|
|
|
|
| 78 |
|
| 79 |
@app.post("/reset", response_model=Observation)
|
| 80 |
def reset(
|
| 81 |
+
difficulty: str = Query(default="mixed", description="Task difficulty: easy | medium | hard | mixed"),
|
| 82 |
+
max_steps: Optional[int] = Query(default=None, description="Max turns for this episode (overrides server default)"),
|
|
|
|
|
|
|
| 83 |
) -> Observation:
|
| 84 |
"""Start a new episode. Returns session_id and the reference screenshot."""
|
| 85 |
if difficulty not in ("easy", "medium", "hard", "mixed"):
|
| 86 |
raise HTTPException(status_code=422, detail=f"Invalid difficulty: {difficulty!r}")
|
| 87 |
+
if max_steps is not None and max_steps < 1:
|
| 88 |
+
raise HTTPException(status_code=422, detail="max_steps must be >= 1")
|
| 89 |
try:
|
| 90 |
+
obs = _env.reset(difficulty=difficulty, max_steps=max_steps)
|
| 91 |
logger.info(
|
| 92 |
"Session %s started — difficulty=%s sample=%d",
|
| 93 |
obs.session_id,
|
src/server/environment.py
CHANGED
|
@@ -21,7 +21,9 @@ from openenv.server.rewards.validity_rewards import html_validity_reward
|
|
| 21 |
from openenv.server.rewards import extract_html
|
| 22 |
from openenv.server.rewards.visual_rewards import _render_html, clip_visual_reward
|
| 23 |
|
| 24 |
-
|
|
|
|
|
|
|
| 25 |
|
| 26 |
REWARD_WEIGHTS = {
|
| 27 |
"format": 0.5, # was 1.0 — saturates to 1.0 after early training; reduce weight
|
|
@@ -35,8 +37,8 @@ REWARD_WEIGHTS = {
|
|
| 35 |
}
|
| 36 |
_WEIGHT_SUM = sum(REWARD_WEIGHTS.values()) # 11.0
|
| 37 |
|
| 38 |
-
LOW_RES
|
| 39 |
-
FULL_RES =
|
| 40 |
|
| 41 |
DIFFICULTY_PROMPTS = {
|
| 42 |
"easy": (
|
|
@@ -70,6 +72,7 @@ class _Session:
|
|
| 70 |
difficulty: str
|
| 71 |
sample: dict
|
| 72 |
ref_image: Image.Image
|
|
|
|
| 73 |
step_count: int = 0
|
| 74 |
sample_index: int = 0
|
| 75 |
|
|
@@ -78,14 +81,29 @@ class VisionCoderEnvironment:
|
|
| 78 |
"""Multi-step, session-aware OpenEnv environment for screenshot-to-HTML generation.
|
| 79 |
|
| 80 |
Each reset() creates an independent session identified by session_id.
|
| 81 |
-
step() accepts session_id in the Action and allows up to
|
| 82 |
per episode before returning done=True.
|
| 83 |
|
| 84 |
step() returns render_low and render_full (base64 PNG) alongside the reward
|
| 85 |
so the Developer agent can inspect its render without an extra /render call.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
"""
|
| 87 |
|
| 88 |
-
def __init__(
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 89 |
self._max_samples = max_samples
|
| 90 |
self._datasets: Dict[str, list] = {}
|
| 91 |
self._dataset_indices: Dict[str, int] = {"easy": 0, "medium": 0, "hard": 0, "mixed": 0}
|
|
@@ -109,8 +127,15 @@ class VisionCoderEnvironment:
|
|
| 109 |
# OpenEnv interface
|
| 110 |
# ------------------------------------------------------------------
|
| 111 |
|
| 112 |
-
def reset(self, difficulty: str = "mixed") -> Observation:
|
| 113 |
-
"""Start a new episode. Returns session_id and the reference screenshot.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 114 |
dataset = self._get_dataset(difficulty)
|
| 115 |
key = difficulty if difficulty in ("easy", "medium", "hard") else "mixed"
|
| 116 |
|
|
@@ -123,7 +148,7 @@ class VisionCoderEnvironment:
|
|
| 123 |
|
| 124 |
ref_image = _render_html(sample["solution"])
|
| 125 |
if ref_image is None:
|
| 126 |
-
ref_image = Image.new("RGB",
|
| 127 |
|
| 128 |
session = _Session(
|
| 129 |
episode_id=episode_id,
|
|
@@ -131,6 +156,7 @@ class VisionCoderEnvironment:
|
|
| 131 |
difficulty=difficulty,
|
| 132 |
sample={**sample, "image": ref_image},
|
| 133 |
ref_image=ref_image,
|
|
|
|
| 134 |
sample_index=idx,
|
| 135 |
)
|
| 136 |
self._sessions[session_id] = session
|
|
@@ -146,7 +172,9 @@ class VisionCoderEnvironment:
|
|
| 146 |
"session_id": session_id,
|
| 147 |
"sample_index": idx,
|
| 148 |
"difficulty": difficulty,
|
| 149 |
-
"max_steps":
|
|
|
|
|
|
|
| 150 |
},
|
| 151 |
)
|
| 152 |
|
|
@@ -164,7 +192,7 @@ class VisionCoderEnvironment:
|
|
| 164 |
|
| 165 |
session = self._sessions[session_id]
|
| 166 |
session.step_count += 1
|
| 167 |
-
done = session.step_count >=
|
| 168 |
|
| 169 |
completions = [[{"content": action.html}]]
|
| 170 |
images = [session.ref_image]
|
|
@@ -202,14 +230,14 @@ class VisionCoderEnvironment:
|
|
| 202 |
done=done,
|
| 203 |
reward=total,
|
| 204 |
session_id=session_id,
|
| 205 |
-
render_low=_image_to_b64(pred_render, size=
|
| 206 |
-
render_full=_image_to_b64(pred_render),
|
| 207 |
metadata={
|
| 208 |
"episode_id": session.episode_id,
|
| 209 |
"session_id": session_id,
|
| 210 |
"step_count": session.step_count,
|
| 211 |
"difficulty": session.difficulty,
|
| 212 |
-
"max_steps":
|
| 213 |
"rewards": {
|
| 214 |
"format": fmt,
|
| 215 |
"validity": val,
|
|
@@ -232,7 +260,7 @@ class VisionCoderEnvironment:
|
|
| 232 |
"""
|
| 233 |
image = _render_html(extract_html(request.html))
|
| 234 |
if image is None:
|
| 235 |
-
image = Image.new("RGB",
|
| 236 |
return RenderResponse(
|
| 237 |
image_b64=_image_to_b64(image),
|
| 238 |
image_low_b64=_image_to_b64(image, size=LOW_RES),
|
|
@@ -248,6 +276,6 @@ class VisionCoderEnvironment:
|
|
| 248 |
session_id=s.session_id,
|
| 249 |
step_count=s.step_count,
|
| 250 |
sample_index=s.sample_index,
|
| 251 |
-
max_steps=
|
| 252 |
)
|
| 253 |
return State()
|
|
|
|
| 21 |
from openenv.server.rewards import extract_html
|
| 22 |
from openenv.server.rewards.visual_rewards import _render_html, clip_visual_reward
|
| 23 |
|
| 24 |
+
DEFAULT_MAX_STEPS = 5
|
| 25 |
+
DEFAULT_LOW_RES = (320, 240)
|
| 26 |
+
DEFAULT_FULL_RES = (640, 480)
|
| 27 |
|
| 28 |
REWARD_WEIGHTS = {
|
| 29 |
"format": 0.5, # was 1.0 — saturates to 1.0 after early training; reduce weight
|
|
|
|
| 37 |
}
|
| 38 |
_WEIGHT_SUM = sum(REWARD_WEIGHTS.values()) # 11.0
|
| 39 |
|
| 40 |
+
LOW_RES = DEFAULT_LOW_RES # module-level alias kept for external imports
|
| 41 |
+
FULL_RES = DEFAULT_FULL_RES
|
| 42 |
|
| 43 |
DIFFICULTY_PROMPTS = {
|
| 44 |
"easy": (
|
|
|
|
| 72 |
difficulty: str
|
| 73 |
sample: dict
|
| 74 |
ref_image: Image.Image
|
| 75 |
+
max_steps: int
|
| 76 |
step_count: int = 0
|
| 77 |
sample_index: int = 0
|
| 78 |
|
|
|
|
| 81 |
"""Multi-step, session-aware OpenEnv environment for screenshot-to-HTML generation.
|
| 82 |
|
| 83 |
Each reset() creates an independent session identified by session_id.
|
| 84 |
+
step() accepts session_id in the Action and allows up to max_steps turns
|
| 85 |
per episode before returning done=True.
|
| 86 |
|
| 87 |
step() returns render_low and render_full (base64 PNG) alongside the reward
|
| 88 |
so the Developer agent can inspect its render without an extra /render call.
|
| 89 |
+
|
| 90 |
+
Args:
|
| 91 |
+
max_steps: Default max developer turns per episode (overridable per reset).
|
| 92 |
+
low_res: Resolution for the low-res preview returned to the Developer.
|
| 93 |
+
full_res: Resolution for reward computation and Critic renders.
|
| 94 |
+
max_samples: Max dataset samples to load per difficulty.
|
| 95 |
"""
|
| 96 |
|
| 97 |
+
def __init__(
|
| 98 |
+
self,
|
| 99 |
+
max_steps: int = DEFAULT_MAX_STEPS,
|
| 100 |
+
low_res: tuple = DEFAULT_LOW_RES,
|
| 101 |
+
full_res: tuple = DEFAULT_FULL_RES,
|
| 102 |
+
max_samples: int = 2000,
|
| 103 |
+
):
|
| 104 |
+
self._default_max_steps = max_steps
|
| 105 |
+
self._low_res = low_res
|
| 106 |
+
self._full_res = full_res
|
| 107 |
self._max_samples = max_samples
|
| 108 |
self._datasets: Dict[str, list] = {}
|
| 109 |
self._dataset_indices: Dict[str, int] = {"easy": 0, "medium": 0, "hard": 0, "mixed": 0}
|
|
|
|
| 127 |
# OpenEnv interface
|
| 128 |
# ------------------------------------------------------------------
|
| 129 |
|
| 130 |
+
def reset(self, difficulty: str = "mixed", max_steps: Optional[int] = None) -> Observation:
|
| 131 |
+
"""Start a new episode. Returns session_id and the reference screenshot.
|
| 132 |
+
|
| 133 |
+
Args:
|
| 134 |
+
difficulty: Task difficulty — easy | medium | hard | mixed.
|
| 135 |
+
max_steps: Override max turns for this episode; uses env default when None.
|
| 136 |
+
"""
|
| 137 |
+
episode_max_steps = max_steps if max_steps is not None else self._default_max_steps
|
| 138 |
+
|
| 139 |
dataset = self._get_dataset(difficulty)
|
| 140 |
key = difficulty if difficulty in ("easy", "medium", "hard") else "mixed"
|
| 141 |
|
|
|
|
| 148 |
|
| 149 |
ref_image = _render_html(sample["solution"])
|
| 150 |
if ref_image is None:
|
| 151 |
+
ref_image = Image.new("RGB", self._full_res, color=(255, 255, 255))
|
| 152 |
|
| 153 |
session = _Session(
|
| 154 |
episode_id=episode_id,
|
|
|
|
| 156 |
difficulty=difficulty,
|
| 157 |
sample={**sample, "image": ref_image},
|
| 158 |
ref_image=ref_image,
|
| 159 |
+
max_steps=episode_max_steps,
|
| 160 |
sample_index=idx,
|
| 161 |
)
|
| 162 |
self._sessions[session_id] = session
|
|
|
|
| 172 |
"session_id": session_id,
|
| 173 |
"sample_index": idx,
|
| 174 |
"difficulty": difficulty,
|
| 175 |
+
"max_steps": episode_max_steps,
|
| 176 |
+
"low_res": list(self._low_res),
|
| 177 |
+
"full_res": list(self._full_res),
|
| 178 |
},
|
| 179 |
)
|
| 180 |
|
|
|
|
| 192 |
|
| 193 |
session = self._sessions[session_id]
|
| 194 |
session.step_count += 1
|
| 195 |
+
done = session.step_count >= session.max_steps
|
| 196 |
|
| 197 |
completions = [[{"content": action.html}]]
|
| 198 |
images = [session.ref_image]
|
|
|
|
| 230 |
done=done,
|
| 231 |
reward=total,
|
| 232 |
session_id=session_id,
|
| 233 |
+
render_low=_image_to_b64(pred_render, size=self._low_res),
|
| 234 |
+
render_full=_image_to_b64(pred_render, size=self._full_res),
|
| 235 |
metadata={
|
| 236 |
"episode_id": session.episode_id,
|
| 237 |
"session_id": session_id,
|
| 238 |
"step_count": session.step_count,
|
| 239 |
"difficulty": session.difficulty,
|
| 240 |
+
"max_steps": session.max_steps,
|
| 241 |
"rewards": {
|
| 242 |
"format": fmt,
|
| 243 |
"validity": val,
|
|
|
|
| 260 |
"""
|
| 261 |
image = _render_html(extract_html(request.html))
|
| 262 |
if image is None:
|
| 263 |
+
image = Image.new("RGB", self._full_res, color=(255, 255, 255))
|
| 264 |
return RenderResponse(
|
| 265 |
image_b64=_image_to_b64(image),
|
| 266 |
image_low_b64=_image_to_b64(image, size=LOW_RES),
|
|
|
|
| 276 |
session_id=s.session_id,
|
| 277 |
step_count=s.step_count,
|
| 278 |
sample_index=s.sample_index,
|
| 279 |
+
max_steps=s.max_steps,
|
| 280 |
)
|
| 281 |
return State()
|