# BridgeTower
## Overview
The BridgeTower model was proposed in [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://huggingface.co/papers/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a
bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
This paper has been accepted to the [AAAI'23](https://aaai.org/Conferences/AAAI-23/) conference.
The abstract from the paper is the following:
*Vision-Language (VL) models with the TWO-TOWER architecture have dominated visual-language representation learning in recent years.
Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder.
Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BRIDGETOWER, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the crossmodal encoder.
This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BRIDGETOWER achieves state-of-the-art performance on various downstream vision-language tasks.
In particular, on the VQAv2 test-std set, BRIDGETOWER achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs.
Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.*
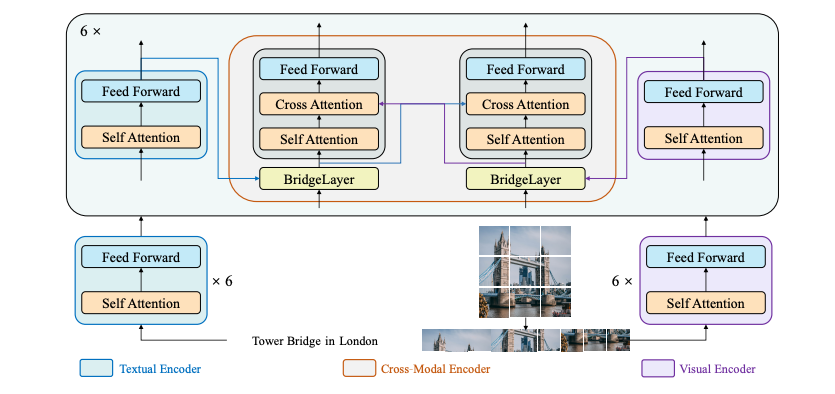 BridgeTower architecture. Taken from the original paper.
This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
## Usage tips and examples
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
The [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) wraps [RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer) and [BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) and [BridgeTowerForContrastiveLearning](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForContrastiveLearning).
```python
import requests
from PIL import Image
from transformers import BridgeTowerForContrastiveLearning, BridgeTowerProcessor
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc", device_map="auto")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
outputs = model(**encoding)
scores[text] = outputs
```
The following example shows how to run image-text retrieval using [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) and [BridgeTowerForImageAndTextRetrieval](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForImageAndTextRetrieval).
```python
import requests
from PIL import Image
from transformers import BridgeTowerForImageAndTextRetrieval, BridgeTowerProcessor
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm", device_map="auto")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
outputs = model(**encoding)
scores[text] = outputs.logits[0, 1].item()
```
The following example shows how to run masked language modeling using [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) and [BridgeTowerForMaskedLM](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForMaskedLM).
```python
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm", device_map="auto")
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
.a cat looking out of the window.
```
Tips:
- This implementation of BridgeTower uses [RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer) to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
- Checkpoints for pre-trained [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) and [bridgetower masked language modeling and image text matching](https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm) are released.
- Please refer to [Table 5](https://huggingface.co/papers/2206.08657) for BridgeTower's performance on Image Retrieval and other down stream tasks.
## BridgeTowerConfig[[transformers.BridgeTowerConfig]]
#### transformers.BridgeTowerConfig[[transformers.BridgeTowerConfig]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/configuration_bridgetower.py#L104)
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a Bridgetower
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [BridgeTower/bridgetower-base](https://huggingface.co/BridgeTower/bridgetower-base)
Configuration objects inherit from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) and can be used to control the model outputs. Read the
documentation from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) for more information.
Example:
```python
>>> from transformers import BridgeTowerModel, BridgeTowerConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration
>>> configuration = BridgeTowerConfig()
>>> # Initializing a model from the BridgeTower/bridgetower-base style configuration
>>> model = BridgeTowerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
**Parameters:**
share_cross_modal_transformer_layers (`bool`, *optional*, defaults to `True`) : Whether cross modal transformer layers are shared.
hidden_act (`str`, *optional*, defaults to `gelu`) : The non-linear activation function (function or string) in the decoder. For example, `"gelu"`, `"relu"`, `"silu"`, etc.
hidden_size (`int`, *optional*, defaults to `768`) : Dimension of the hidden representations.
initializer_factor (`Union[float, int]`, *optional*, defaults to `1`) : A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
layer_norm_eps (`float`, *optional*, defaults to `1e-05`) : The epsilon used by the layer normalization layers.
share_link_tower_layers (`bool`, *optional*, defaults to `False`) : Whether the bride/link tower layers are shared.
link_tower_type (`str`, *optional*, defaults to `"add"`) : Type of the bridge/link layer.
num_attention_heads (`int`, *optional*, defaults to `12`) : Number of attention heads for each attention layer in the Transformer decoder.
num_hidden_layers (`int`, *optional*, defaults to `6`) : Number of hidden layers in the Transformer decoder.
tie_word_embeddings (`bool`, *optional*, defaults to `False`) : Whether to tie weight embeddings according to model's `tied_weights_keys` mapping.
init_layernorm_from_vision_encoder (`bool`, *optional*, defaults to `False`) : Whether to init LayerNorm from the vision encoder.
text_config (`Union[dict, ~configuration_utils.PreTrainedConfig]`, *optional*) : The config object or dictionary of the text backbone.
vision_config (`Union[dict, ~configuration_utils.PreTrainedConfig]`, *optional*) : The config object or dictionary of the vision backbone.
## BridgeTowerTextConfig[[transformers.BridgeTowerTextConfig]]
#### transformers.BridgeTowerTextConfig[[transformers.BridgeTowerTextConfig]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/configuration_bridgetower.py#L65)
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a Bridgetower
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [BridgeTower/bridgetower-base](https://huggingface.co/BridgeTower/bridgetower-base)
Configuration objects inherit from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) and can be used to control the model outputs. Read the
documentation from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) for more information.
Example:
```python
>>> from transformers import BridgeTowerTextConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration for the text model
>>> configuration = BridgeTowerTextConfig()
>>> # Accessing the configuration
>>> configuration
```
**Parameters:**
vocab_size (`int`, *optional*, defaults to `50265`) : Vocabulary size of the model. Defines the number of different tokens that can be represented by the `input_ids`.
hidden_size (`int`, *optional*, defaults to `768`) : Dimension of the hidden representations.
num_hidden_layers (`int`, *optional*, defaults to `12`) : Number of hidden layers in the Transformer decoder.
num_attention_heads (`int`, *optional*, defaults to `12`) : Number of attention heads for each attention layer in the Transformer decoder.
initializer_factor (`Union[float, int]`, *optional*, defaults to `1`) : A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
intermediate_size (`int`, *optional*, defaults to `3072`) : Dimension of the MLP representations.
hidden_act (`str`, *optional*, defaults to `gelu`) : The non-linear activation function (function or string) in the decoder. For example, `"gelu"`, `"relu"`, `"silu"`, etc.
hidden_dropout_prob (`Union[float, int]`, *optional*, defaults to `0.1`) : The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`Union[float, int]`, *optional*, defaults to `0.1`) : The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to `514`) : The maximum sequence length that this model might ever be used with.
type_vocab_size (`int`, *optional*, defaults to `1`) : The vocabulary size of the `token_type_ids`.
layer_norm_eps (`float`, *optional*, defaults to `1e-05`) : The epsilon used by the layer normalization layers.
pad_token_id (`int`, *optional*, defaults to `1`) : Token id used for padding in the vocabulary.
bos_token_id (`int`, *optional*, defaults to `0`) : Token id used for beginning-of-stream in the vocabulary.
eos_token_id (`Union[int, list[int]]`, *optional*, defaults to `2`) : Token id used for end-of-stream in the vocabulary.
use_cache (`bool`, *optional*, defaults to `True`) : Whether or not the model should return the last key/values attentions (not used by all models). Only relevant if `config.is_decoder=True` or when the model is a decoder-only generative model.
is_decoder (`bool`, *optional*, defaults to `False`) : Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
add_cross_attention (`bool`, *optional*, defaults to `False`) : Whether cross-attention layers should be added to the model.
## BridgeTowerVisionConfig[[transformers.BridgeTowerVisionConfig]]
#### transformers.BridgeTowerVisionConfig[[transformers.BridgeTowerVisionConfig]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/configuration_bridgetower.py#L27)
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a Bridgetower
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [BridgeTower/bridgetower-base](https://huggingface.co/BridgeTower/bridgetower-base)
Configuration objects inherit from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) and can be used to control the model outputs. Read the
documentation from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) for more information.
Example:
```python
>>> from transformers import BridgeTowerVisionConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration for the vision model
>>> configuration = BridgeTowerVisionConfig()
>>> # Accessing the configuration
>>> configuration
```
**Parameters:**
hidden_size (`int`, *optional*, defaults to `768`) : Dimension of the hidden representations.
num_hidden_layers (`int`, *optional*, defaults to `12`) : Number of hidden layers in the Transformer decoder.
num_channels (`int`, *optional*, defaults to `3`) : The number of input channels.
patch_size (`Union[int, list[int], tuple[int, int]]`, *optional*, defaults to `16`) : The size (resolution) of each patch.
image_size (`Union[int, list[int], tuple[int, int]]`, *optional*, defaults to `288`) : The size (resolution) of each image.
initializer_factor (`Union[float, int]`, *optional*, defaults to `1`) : A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
layer_norm_eps (`float`, *optional*, defaults to `1e-05`) : The epsilon used by the layer normalization layers.
stop_gradient (`bool`, *optional*, defaults to `False`) : Whether to stop gradient for training.
share_layernorm (`bool`, *optional*, defaults to `True`) : Whether LayerNorm layers are shared.
remove_last_layer (`bool`, *optional*, defaults to `False`) : Whether to remove the last layer from the vision encoder.
## BridgeTowerImageProcessor[[transformers.BridgeTowerImageProcessor]]
#### transformers.BridgeTowerImageProcessor[[transformers.BridgeTowerImageProcessor]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/image_processing_bridgetower.py#L81)
Constructs a BridgeTowerImageProcessor image processor.
preprocesstransformers.BridgeTowerImageProcessor.preprocesshttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/image_processing_utils.py#L382[{"name": "images", "val": ": typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']]"}, {"name": "*args", "val": ""}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.processing_utils.ImagesKwargs]"}]- **images** (`Union[PIL.Image.Image, numpy.ndarray, torch.Tensor, list[PIL.Image.Image], list[numpy.ndarray], list[torch.Tensor]]`) --
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
- **return_tensors** (`str` or [TensorType](/docs/transformers/v5.8.0/en/internal/file_utils#transformers.TensorType), *optional*) --
Returns stacked tensors if set to `'pt'`, otherwise returns a list of tensors.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) --
Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class
for the complete list of supported arguments.0`~image_processing_base.BatchFeature`- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
**Parameters:**
size_divisor (`int`, *kwargs*, *optional*, defaults to `self.size_divisor`) : The size by which to make sure both the height and width can be divided.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) : Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class for the complete list of supported arguments.
**Returns:**
``~image_processing_base.BatchFeature``
- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
## BridgeTowerImageProcessorPil[[transformers.BridgeTowerImageProcessorPil]]
#### transformers.BridgeTowerImageProcessorPil[[transformers.BridgeTowerImageProcessorPil]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/image_processing_pil_bridgetower.py#L75)
Constructs a BridgeTowerImageProcessor image processor.
preprocesstransformers.BridgeTowerImageProcessorPil.preprocesshttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/image_processing_utils.py#L382[{"name": "images", "val": ": typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']]"}, {"name": "*args", "val": ""}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.processing_utils.ImagesKwargs]"}]- **images** (`Union[PIL.Image.Image, numpy.ndarray, torch.Tensor, list[PIL.Image.Image], list[numpy.ndarray], list[torch.Tensor]]`) --
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
- **return_tensors** (`str` or [TensorType](/docs/transformers/v5.8.0/en/internal/file_utils#transformers.TensorType), *optional*) --
Returns stacked tensors if set to `'pt'`, otherwise returns a list of tensors.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) --
Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class
for the complete list of supported arguments.0`~image_processing_base.BatchFeature`- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
**Parameters:**
size_divisor (`int`, *kwargs*, *optional*, defaults to `self.size_divisor`) : The size by which to make sure both the height and width can be divided.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) : Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class for the complete list of supported arguments.
**Returns:**
``~image_processing_base.BatchFeature``
- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
## BridgeTowerProcessor[[transformers.BridgeTowerProcessor]]
#### transformers.BridgeTowerProcessor[[transformers.BridgeTowerProcessor]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/processing_bridgetower.py#L42)
Constructs a BridgeTowerProcessor which wraps a image processor and a tokenizer into a single processor.
[BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) offers all the functionalities of [BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) and [RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer). See the
[~BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) and [~RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer) for more information.
__call__transformers.BridgeTowerProcessor.__call__https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/processing_utils.py#L631[{"name": "images", "val": ": typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor'], NoneType] = None"}, {"name": "text", "val": ": str | list[str] | list[list[str]] | None = None"}, {"name": "videos", "val": ": typing.Union[list['PIL.Image.Image'], numpy.ndarray, ForwardRef('torch.Tensor'), list[numpy.ndarray], list['torch.Tensor'], list[list['PIL.Image.Image']], list[list[numpy.ndarray]], list[list['torch.Tensor']], transformers.video_utils.URL, list[transformers.video_utils.URL], list[list[transformers.video_utils.URL]], transformers.video_utils.Path, list[transformers.video_utils.Path], list[list[transformers.video_utils.Path]], NoneType] = None"}, {"name": "audio", "val": ": typing.Union[numpy.ndarray, ForwardRef('torch.Tensor'), collections.abc.Sequence[numpy.ndarray], collections.abc.Sequence['torch.Tensor'], NoneType] = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.processing_utils.ProcessingKwargs]"}]- **images** (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `list[PIL.Image.Image]`, `list[np.ndarray]`, `list[torch.Tensor]`) --
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. Both channels-first and channels-last formats are supported.
- **text** (`TextInput`, `PreTokenizedInput`, `list[TextInput]`, `list[PreTokenizedInput]`, *optional*) --
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
- **videos** (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`) --
The video or batch of videos to be prepared. Each video can be a 4D NumPy array or PyTorch
tensor, or a nested list of 3D frames. Both channels-first and channels-last formats are supported.
- **audio** (`np.ndarray`, `torch.Tensor`, `list[np.ndarray]`, `list[torch.Tensor]`) --
The audio or batch of audio to be prepared. Each audio can be a NumPy array or PyTorch
tensor.
- **return_tensors** (`str` or [TensorType](/docs/transformers/v5.8.0/en/internal/file_utils#transformers.TensorType), *optional*) --
If set, will return tensors of a particular framework. Acceptable values are:
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return NumPy `np.ndarray` objects.0[BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature)A [BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature) object with processed inputs in a dict format.
Main method to prepare for model inputs. This method forwards the each modality argument to its own processor
along with `kwargs`. Please refer to the docstring of the each processor attributes for more information.
**Parameters:**
image_processor (`BridgeTowerImageProcessor`) : The image processor is a required input.
tokenizer (`RobertaTokenizer`) : The tokenizer is a required input.
**Returns:**
`[BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature)`
A [BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature) object with processed inputs in a dict format.
## BridgeTowerModel[[transformers.BridgeTowerModel]]
#### transformers.BridgeTowerModel[[transformers.BridgeTowerModel]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1085)
The bare BridgeTower Model transformer outputting BridgeTowerModelOutput object without any specific head on
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerModel.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1158[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_token_type_idx", "val": ": int | None = None"}, {"name": "labels", "val": ": torch.LongTensor | None = None"}, {"name": "interpolate_pos_encoding", "val": ": bool = False"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **image_token_type_idx** (`int`, *optional*) --
- The token type ids for images.
- **labels** (`torch.LongTensor` of shape `(batch_size,)`, *optional*) --
Labels are currently not supported.
- **interpolate_pos_encoding** (`bool`, *optional*, defaults to `False`) --
Whether to interpolate the pre-trained position encodings.0`BridgeTowerModelOutput` or `tuple(torch.FloatTensor)`A `BridgeTowerModelOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerModel](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerModel) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **text_features** (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_size)`) -- Sequence of hidden-states at the text output of the last layer of the model.
- **image_features** (`torch.FloatTensor` of shape `(batch_size, image_sequence_length, hidden_size)`) -- Sequence of hidden-states at the image output of the last layer of the model.
- **pooler_output** (`torch.FloatTensor` of shape `(batch_size, hidden_size x 2)`) -- Concatenation of last layer hidden-state of the first token of the text and image sequence (classification
token), respectively, after further processing through layers used for auxiliary pretraining tasks.
- **hidden_states** (`tuple[torch.FloatTensor]`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple[torch.FloatTensor]`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import httpx
>>> from io import BytesIO
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> with httpx.stream("GET", url) as response:
... image = Image.open(BytesIO(response.read()))
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])
```
**Parameters:**
config ([BridgeTowerModel](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerModel)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
``BridgeTowerModelOutput` or `tuple(torch.FloatTensor)``
A `BridgeTowerModelOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
## BridgeTowerForContrastiveLearning[[transformers.BridgeTowerForContrastiveLearning]]
#### transformers.BridgeTowerForContrastiveLearning[[transformers.BridgeTowerForContrastiveLearning]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1621)
BridgeTower Model with a image-text contrastive head on top computing image-text contrastive loss.
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerForContrastiveLearning.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1635[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "return_loss", "val": ": bool | None = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **return_loss** (`bool`, *optional*) --
Whether or not to return the contrastive loss.0`BridgeTowerContrastiveOutput` or `tuple(torch.FloatTensor)`A `BridgeTowerContrastiveOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerForContrastiveLearning](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForContrastiveLearning) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`) -- Image-text contrastive loss.
- **logits** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) -- Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
- **text_embeds** (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`) -- The text embeddings obtained by applying the projection layer to the pooler_output.
- **image_embeds** (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`) -- The image embeddings obtained by applying the projection layer to the pooler_output.
- **cross_embeds** (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`) -- The text-image cross-modal embeddings obtained by applying the projection layer to the pooler_output.
- **hidden_states** (`tuple[torch.FloatTensor]`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import httpx
>>> from io import BytesIO
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> with httpx.stream("GET", urls[0]) as response:
... image1 = Image.open(BytesIO(response.read()))
>>> with httpx.stream("GET", urls[1]) as response:
... image2 = Image.open(BytesIO(response.read()))
>>> images = [image1, image2]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126
```
**Parameters:**
config ([BridgeTowerForContrastiveLearning](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForContrastiveLearning)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
``BridgeTowerContrastiveOutput` or `tuple(torch.FloatTensor)``
A `BridgeTowerContrastiveOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
## BridgeTowerForMaskedLM[[transformers.BridgeTowerForMaskedLM]]
#### transformers.BridgeTowerForMaskedLM[[transformers.BridgeTowerForMaskedLM]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1418)
BridgeTower Model with a language modeling head on top as done during pretraining.
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerForMaskedLM.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1436[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "labels", "val": ": torch.LongTensor | None = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **labels** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`0[MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or `tuple(torch.FloatTensor)`A [MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerForMaskedLM](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForMaskedLM) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) -- Masked language modeling (MLM) loss.
- **logits** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) -- Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
- **hidden_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import httpx
>>> from io import BytesIO
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> with httpx.stream("GET", url) as response:
... image = Image.open(BytesIO(response.read())).convert("RGB")
>>> text = "a looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
**Parameters:**
config ([BridgeTowerForMaskedLM](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForMaskedLM)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
`[MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or `tuple(torch.FloatTensor)``
A [MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
## BridgeTowerForImageAndTextRetrieval[[transformers.BridgeTowerForImageAndTextRetrieval]]
#### transformers.BridgeTowerForImageAndTextRetrieval[[transformers.BridgeTowerForImageAndTextRetrieval]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1519)
BridgeTower Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the
[CLS] token) for image-to-text matching.
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerForImageAndTextRetrieval.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1530[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "labels", "val": ": torch.LongTensor | None = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **labels** (`torch.LongTensor` of shape `(batch_size, 1)`, *optional*) --
Labels for computing the image-text matching loss. 0 means the pairs don't match and 1 means they match.
The pairs with 0 will be skipped for calculation.0[SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or `tuple(torch.FloatTensor)`A [SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerForImageAndTextRetrieval](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForImageAndTextRetrieval) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) -- Classification (or regression if config.num_labels==1) loss.
- **logits** (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`) -- Classification (or regression if config.num_labels==1) scores (before SoftMax).
- **hidden_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import httpx
>>> from io import BytesIO
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> with httpx.stream("GET", url) as response:
... image = Image.open(BytesIO(response.read()))
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
**Parameters:**
config ([BridgeTowerForImageAndTextRetrieval](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForImageAndTextRetrieval)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
`[SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or `tuple(torch.FloatTensor)``
A [SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
BridgeTower architecture. Taken from the original paper.
This model was contributed by [Anahita Bhiwandiwalla](https://huggingface.co/anahita-b), [Tiep Le](https://huggingface.co/Tile) and [Shaoyen Tseng](https://huggingface.co/shaoyent). The original code can be found [here](https://github.com/microsoft/BridgeTower).
## Usage tips and examples
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers.
The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder.
In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
The [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) wraps [RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer) and [BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) into a single instance to both
encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) and [BridgeTowerForContrastiveLearning](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForContrastiveLearning).
```python
import requests
from PIL import Image
from transformers import BridgeTowerForContrastiveLearning, BridgeTowerProcessor
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc", device_map="auto")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
outputs = model(**encoding)
scores[text] = outputs
```
The following example shows how to run image-text retrieval using [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) and [BridgeTowerForImageAndTextRetrieval](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForImageAndTextRetrieval).
```python
import requests
from PIL import Image
from transformers import BridgeTowerForImageAndTextRetrieval, BridgeTowerProcessor
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm", device_map="auto")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
outputs = model(**encoding)
scores[text] = outputs.logits[0, 1].item()
```
The following example shows how to run masked language modeling using [BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) and [BridgeTowerForMaskedLM](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForMaskedLM).
```python
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm", device_map="auto")
# prepare inputs
encoding = processor(image, text, return_tensors="pt").to(model.device)
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
.a cat looking out of the window.
```
Tips:
- This implementation of BridgeTower uses [RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer) to generate text embeddings and OpenAI's CLIP/ViT model to compute visual embeddings.
- Checkpoints for pre-trained [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) and [bridgetower masked language modeling and image text matching](https://huggingface.co/BridgeTower/bridgetower-base-itm-mlm) are released.
- Please refer to [Table 5](https://huggingface.co/papers/2206.08657) for BridgeTower's performance on Image Retrieval and other down stream tasks.
## BridgeTowerConfig[[transformers.BridgeTowerConfig]]
#### transformers.BridgeTowerConfig[[transformers.BridgeTowerConfig]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/configuration_bridgetower.py#L104)
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a Bridgetower
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [BridgeTower/bridgetower-base](https://huggingface.co/BridgeTower/bridgetower-base)
Configuration objects inherit from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) and can be used to control the model outputs. Read the
documentation from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) for more information.
Example:
```python
>>> from transformers import BridgeTowerModel, BridgeTowerConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration
>>> configuration = BridgeTowerConfig()
>>> # Initializing a model from the BridgeTower/bridgetower-base style configuration
>>> model = BridgeTowerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
**Parameters:**
share_cross_modal_transformer_layers (`bool`, *optional*, defaults to `True`) : Whether cross modal transformer layers are shared.
hidden_act (`str`, *optional*, defaults to `gelu`) : The non-linear activation function (function or string) in the decoder. For example, `"gelu"`, `"relu"`, `"silu"`, etc.
hidden_size (`int`, *optional*, defaults to `768`) : Dimension of the hidden representations.
initializer_factor (`Union[float, int]`, *optional*, defaults to `1`) : A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
layer_norm_eps (`float`, *optional*, defaults to `1e-05`) : The epsilon used by the layer normalization layers.
share_link_tower_layers (`bool`, *optional*, defaults to `False`) : Whether the bride/link tower layers are shared.
link_tower_type (`str`, *optional*, defaults to `"add"`) : Type of the bridge/link layer.
num_attention_heads (`int`, *optional*, defaults to `12`) : Number of attention heads for each attention layer in the Transformer decoder.
num_hidden_layers (`int`, *optional*, defaults to `6`) : Number of hidden layers in the Transformer decoder.
tie_word_embeddings (`bool`, *optional*, defaults to `False`) : Whether to tie weight embeddings according to model's `tied_weights_keys` mapping.
init_layernorm_from_vision_encoder (`bool`, *optional*, defaults to `False`) : Whether to init LayerNorm from the vision encoder.
text_config (`Union[dict, ~configuration_utils.PreTrainedConfig]`, *optional*) : The config object or dictionary of the text backbone.
vision_config (`Union[dict, ~configuration_utils.PreTrainedConfig]`, *optional*) : The config object or dictionary of the vision backbone.
## BridgeTowerTextConfig[[transformers.BridgeTowerTextConfig]]
#### transformers.BridgeTowerTextConfig[[transformers.BridgeTowerTextConfig]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/configuration_bridgetower.py#L65)
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a Bridgetower
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [BridgeTower/bridgetower-base](https://huggingface.co/BridgeTower/bridgetower-base)
Configuration objects inherit from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) and can be used to control the model outputs. Read the
documentation from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) for more information.
Example:
```python
>>> from transformers import BridgeTowerTextConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration for the text model
>>> configuration = BridgeTowerTextConfig()
>>> # Accessing the configuration
>>> configuration
```
**Parameters:**
vocab_size (`int`, *optional*, defaults to `50265`) : Vocabulary size of the model. Defines the number of different tokens that can be represented by the `input_ids`.
hidden_size (`int`, *optional*, defaults to `768`) : Dimension of the hidden representations.
num_hidden_layers (`int`, *optional*, defaults to `12`) : Number of hidden layers in the Transformer decoder.
num_attention_heads (`int`, *optional*, defaults to `12`) : Number of attention heads for each attention layer in the Transformer decoder.
initializer_factor (`Union[float, int]`, *optional*, defaults to `1`) : A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
intermediate_size (`int`, *optional*, defaults to `3072`) : Dimension of the MLP representations.
hidden_act (`str`, *optional*, defaults to `gelu`) : The non-linear activation function (function or string) in the decoder. For example, `"gelu"`, `"relu"`, `"silu"`, etc.
hidden_dropout_prob (`Union[float, int]`, *optional*, defaults to `0.1`) : The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
attention_probs_dropout_prob (`Union[float, int]`, *optional*, defaults to `0.1`) : The dropout ratio for the attention probabilities.
max_position_embeddings (`int`, *optional*, defaults to `514`) : The maximum sequence length that this model might ever be used with.
type_vocab_size (`int`, *optional*, defaults to `1`) : The vocabulary size of the `token_type_ids`.
layer_norm_eps (`float`, *optional*, defaults to `1e-05`) : The epsilon used by the layer normalization layers.
pad_token_id (`int`, *optional*, defaults to `1`) : Token id used for padding in the vocabulary.
bos_token_id (`int`, *optional*, defaults to `0`) : Token id used for beginning-of-stream in the vocabulary.
eos_token_id (`Union[int, list[int]]`, *optional*, defaults to `2`) : Token id used for end-of-stream in the vocabulary.
use_cache (`bool`, *optional*, defaults to `True`) : Whether or not the model should return the last key/values attentions (not used by all models). Only relevant if `config.is_decoder=True` or when the model is a decoder-only generative model.
is_decoder (`bool`, *optional*, defaults to `False`) : Whether the model is used as a decoder or not. If `False`, the model is used as an encoder.
add_cross_attention (`bool`, *optional*, defaults to `False`) : Whether cross-attention layers should be added to the model.
## BridgeTowerVisionConfig[[transformers.BridgeTowerVisionConfig]]
#### transformers.BridgeTowerVisionConfig[[transformers.BridgeTowerVisionConfig]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/configuration_bridgetower.py#L27)
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a Bridgetower
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the [BridgeTower/bridgetower-base](https://huggingface.co/BridgeTower/bridgetower-base)
Configuration objects inherit from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) and can be used to control the model outputs. Read the
documentation from [PreTrainedConfig](/docs/transformers/v5.8.0/en/main_classes/configuration#transformers.PreTrainedConfig) for more information.
Example:
```python
>>> from transformers import BridgeTowerVisionConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration for the vision model
>>> configuration = BridgeTowerVisionConfig()
>>> # Accessing the configuration
>>> configuration
```
**Parameters:**
hidden_size (`int`, *optional*, defaults to `768`) : Dimension of the hidden representations.
num_hidden_layers (`int`, *optional*, defaults to `12`) : Number of hidden layers in the Transformer decoder.
num_channels (`int`, *optional*, defaults to `3`) : The number of input channels.
patch_size (`Union[int, list[int], tuple[int, int]]`, *optional*, defaults to `16`) : The size (resolution) of each patch.
image_size (`Union[int, list[int], tuple[int, int]]`, *optional*, defaults to `288`) : The size (resolution) of each image.
initializer_factor (`Union[float, int]`, *optional*, defaults to `1`) : A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
layer_norm_eps (`float`, *optional*, defaults to `1e-05`) : The epsilon used by the layer normalization layers.
stop_gradient (`bool`, *optional*, defaults to `False`) : Whether to stop gradient for training.
share_layernorm (`bool`, *optional*, defaults to `True`) : Whether LayerNorm layers are shared.
remove_last_layer (`bool`, *optional*, defaults to `False`) : Whether to remove the last layer from the vision encoder.
## BridgeTowerImageProcessor[[transformers.BridgeTowerImageProcessor]]
#### transformers.BridgeTowerImageProcessor[[transformers.BridgeTowerImageProcessor]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/image_processing_bridgetower.py#L81)
Constructs a BridgeTowerImageProcessor image processor.
preprocesstransformers.BridgeTowerImageProcessor.preprocesshttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/image_processing_utils.py#L382[{"name": "images", "val": ": typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']]"}, {"name": "*args", "val": ""}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.processing_utils.ImagesKwargs]"}]- **images** (`Union[PIL.Image.Image, numpy.ndarray, torch.Tensor, list[PIL.Image.Image], list[numpy.ndarray], list[torch.Tensor]]`) --
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
- **return_tensors** (`str` or [TensorType](/docs/transformers/v5.8.0/en/internal/file_utils#transformers.TensorType), *optional*) --
Returns stacked tensors if set to `'pt'`, otherwise returns a list of tensors.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) --
Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class
for the complete list of supported arguments.0`~image_processing_base.BatchFeature`- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
**Parameters:**
size_divisor (`int`, *kwargs*, *optional*, defaults to `self.size_divisor`) : The size by which to make sure both the height and width can be divided.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) : Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class for the complete list of supported arguments.
**Returns:**
``~image_processing_base.BatchFeature``
- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
## BridgeTowerImageProcessorPil[[transformers.BridgeTowerImageProcessorPil]]
#### transformers.BridgeTowerImageProcessorPil[[transformers.BridgeTowerImageProcessorPil]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/image_processing_pil_bridgetower.py#L75)
Constructs a BridgeTowerImageProcessor image processor.
preprocesstransformers.BridgeTowerImageProcessorPil.preprocesshttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/image_processing_utils.py#L382[{"name": "images", "val": ": typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']]"}, {"name": "*args", "val": ""}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.processing_utils.ImagesKwargs]"}]- **images** (`Union[PIL.Image.Image, numpy.ndarray, torch.Tensor, list[PIL.Image.Image], list[numpy.ndarray], list[torch.Tensor]]`) --
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
- **return_tensors** (`str` or [TensorType](/docs/transformers/v5.8.0/en/internal/file_utils#transformers.TensorType), *optional*) --
Returns stacked tensors if set to `'pt'`, otherwise returns a list of tensors.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) --
Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class
for the complete list of supported arguments.0`~image_processing_base.BatchFeature`- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
**Parameters:**
size_divisor (`int`, *kwargs*, *optional*, defaults to `self.size_divisor`) : The size by which to make sure both the height and width can be divided.
- ****kwargs** ([ImagesKwargs](/docs/transformers/v5.8.0/en/main_classes/processors#transformers.ImagesKwargs), *optional*) : Additional image preprocessing options. Model-specific kwargs are listed above; see the TypedDict class for the complete list of supported arguments.
**Returns:**
``~image_processing_base.BatchFeature``
- **data** (`dict`) -- Dictionary of lists/arrays/tensors returned by the __call__ method ('pixel_values', etc.).
- **tensor_type** (`Union[None, str, TensorType]`, *optional*) -- You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at
initialization.
## BridgeTowerProcessor[[transformers.BridgeTowerProcessor]]
#### transformers.BridgeTowerProcessor[[transformers.BridgeTowerProcessor]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/processing_bridgetower.py#L42)
Constructs a BridgeTowerProcessor which wraps a image processor and a tokenizer into a single processor.
[BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) offers all the functionalities of [BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) and [RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer). See the
[~BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) and [~RobertaTokenizer](/docs/transformers/v5.8.0/en/model_doc/mvp#transformers.RobertaTokenizer) for more information.
__call__transformers.BridgeTowerProcessor.__call__https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/processing_utils.py#L631[{"name": "images", "val": ": typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor'], NoneType] = None"}, {"name": "text", "val": ": str | list[str] | list[list[str]] | None = None"}, {"name": "videos", "val": ": typing.Union[list['PIL.Image.Image'], numpy.ndarray, ForwardRef('torch.Tensor'), list[numpy.ndarray], list['torch.Tensor'], list[list['PIL.Image.Image']], list[list[numpy.ndarray]], list[list['torch.Tensor']], transformers.video_utils.URL, list[transformers.video_utils.URL], list[list[transformers.video_utils.URL]], transformers.video_utils.Path, list[transformers.video_utils.Path], list[list[transformers.video_utils.Path]], NoneType] = None"}, {"name": "audio", "val": ": typing.Union[numpy.ndarray, ForwardRef('torch.Tensor'), collections.abc.Sequence[numpy.ndarray], collections.abc.Sequence['torch.Tensor'], NoneType] = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.processing_utils.ProcessingKwargs]"}]- **images** (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `list[PIL.Image.Image]`, `list[np.ndarray]`, `list[torch.Tensor]`) --
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
tensor. Both channels-first and channels-last formats are supported.
- **text** (`TextInput`, `PreTokenizedInput`, `list[TextInput]`, `list[PreTokenizedInput]`, *optional*) --
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
- **videos** (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`) --
The video or batch of videos to be prepared. Each video can be a 4D NumPy array or PyTorch
tensor, or a nested list of 3D frames. Both channels-first and channels-last formats are supported.
- **audio** (`np.ndarray`, `torch.Tensor`, `list[np.ndarray]`, `list[torch.Tensor]`) --
The audio or batch of audio to be prepared. Each audio can be a NumPy array or PyTorch
tensor.
- **return_tensors** (`str` or [TensorType](/docs/transformers/v5.8.0/en/internal/file_utils#transformers.TensorType), *optional*) --
If set, will return tensors of a particular framework. Acceptable values are:
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return NumPy `np.ndarray` objects.0[BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature)A [BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature) object with processed inputs in a dict format.
Main method to prepare for model inputs. This method forwards the each modality argument to its own processor
along with `kwargs`. Please refer to the docstring of the each processor attributes for more information.
**Parameters:**
image_processor (`BridgeTowerImageProcessor`) : The image processor is a required input.
tokenizer (`RobertaTokenizer`) : The tokenizer is a required input.
**Returns:**
`[BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature)`
A [BatchFeature](/docs/transformers/v5.8.0/en/main_classes/feature_extractor#transformers.BatchFeature) object with processed inputs in a dict format.
## BridgeTowerModel[[transformers.BridgeTowerModel]]
#### transformers.BridgeTowerModel[[transformers.BridgeTowerModel]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1085)
The bare BridgeTower Model transformer outputting BridgeTowerModelOutput object without any specific head on
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerModel.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1158[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_token_type_idx", "val": ": int | None = None"}, {"name": "labels", "val": ": torch.LongTensor | None = None"}, {"name": "interpolate_pos_encoding", "val": ": bool = False"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **image_token_type_idx** (`int`, *optional*) --
- The token type ids for images.
- **labels** (`torch.LongTensor` of shape `(batch_size,)`, *optional*) --
Labels are currently not supported.
- **interpolate_pos_encoding** (`bool`, *optional*, defaults to `False`) --
Whether to interpolate the pre-trained position encodings.0`BridgeTowerModelOutput` or `tuple(torch.FloatTensor)`A `BridgeTowerModelOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerModel](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerModel) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **text_features** (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_size)`) -- Sequence of hidden-states at the text output of the last layer of the model.
- **image_features** (`torch.FloatTensor` of shape `(batch_size, image_sequence_length, hidden_size)`) -- Sequence of hidden-states at the image output of the last layer of the model.
- **pooler_output** (`torch.FloatTensor` of shape `(batch_size, hidden_size x 2)`) -- Concatenation of last layer hidden-state of the first token of the text and image sequence (classification
token), respectively, after further processing through layers used for auxiliary pretraining tasks.
- **hidden_states** (`tuple[torch.FloatTensor]`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple[torch.FloatTensor]`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import httpx
>>> from io import BytesIO
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> with httpx.stream("GET", url) as response:
... image = Image.open(BytesIO(response.read()))
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])
```
**Parameters:**
config ([BridgeTowerModel](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerModel)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
``BridgeTowerModelOutput` or `tuple(torch.FloatTensor)``
A `BridgeTowerModelOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
## BridgeTowerForContrastiveLearning[[transformers.BridgeTowerForContrastiveLearning]]
#### transformers.BridgeTowerForContrastiveLearning[[transformers.BridgeTowerForContrastiveLearning]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1621)
BridgeTower Model with a image-text contrastive head on top computing image-text contrastive loss.
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerForContrastiveLearning.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1635[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "return_loss", "val": ": bool | None = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **return_loss** (`bool`, *optional*) --
Whether or not to return the contrastive loss.0`BridgeTowerContrastiveOutput` or `tuple(torch.FloatTensor)`A `BridgeTowerContrastiveOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerForContrastiveLearning](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForContrastiveLearning) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`) -- Image-text contrastive loss.
- **logits** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) -- Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
- **text_embeds** (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`) -- The text embeddings obtained by applying the projection layer to the pooler_output.
- **image_embeds** (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`) -- The image embeddings obtained by applying the projection layer to the pooler_output.
- **cross_embeds** (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`) -- The text-image cross-modal embeddings obtained by applying the projection layer to the pooler_output.
- **hidden_states** (`tuple[torch.FloatTensor]`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import httpx
>>> from io import BytesIO
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> with httpx.stream("GET", urls[0]) as response:
... image1 = Image.open(BytesIO(response.read()))
>>> with httpx.stream("GET", urls[1]) as response:
... image2 = Image.open(BytesIO(response.read()))
>>> images = [image1, image2]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126
```
**Parameters:**
config ([BridgeTowerForContrastiveLearning](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForContrastiveLearning)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
``BridgeTowerContrastiveOutput` or `tuple(torch.FloatTensor)``
A `BridgeTowerContrastiveOutput` or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
## BridgeTowerForMaskedLM[[transformers.BridgeTowerForMaskedLM]]
#### transformers.BridgeTowerForMaskedLM[[transformers.BridgeTowerForMaskedLM]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1418)
BridgeTower Model with a language modeling head on top as done during pretraining.
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerForMaskedLM.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1436[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "labels", "val": ": torch.LongTensor | None = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **labels** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`0[MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or `tuple(torch.FloatTensor)`A [MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerForMaskedLM](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForMaskedLM) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) -- Masked language modeling (MLM) loss.
- **logits** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) -- Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
- **hidden_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import httpx
>>> from io import BytesIO
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> with httpx.stream("GET", url) as response:
... image = Image.open(BytesIO(response.read())).convert("RGB")
>>> text = "a looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
**Parameters:**
config ([BridgeTowerForMaskedLM](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForMaskedLM)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
`[MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or `tuple(torch.FloatTensor)``
A [MaskedLMOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.MaskedLMOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
## BridgeTowerForImageAndTextRetrieval[[transformers.BridgeTowerForImageAndTextRetrieval]]
#### transformers.BridgeTowerForImageAndTextRetrieval[[transformers.BridgeTowerForImageAndTextRetrieval]]
[Source](https://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1519)
BridgeTower Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the
[CLS] token) for image-to-text matching.
This model inherits from [PreTrainedModel](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel). Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
forwardtransformers.BridgeTowerForImageAndTextRetrieval.forwardhttps://github.com/huggingface/transformers/blob/v5.8.0/src/transformers/models/bridgetower/modeling_bridgetower.py#L1530[{"name": "input_ids", "val": ": torch.LongTensor | None = None"}, {"name": "attention_mask", "val": ": torch.FloatTensor | None = None"}, {"name": "token_type_ids", "val": ": torch.LongTensor | None = None"}, {"name": "pixel_values", "val": ": torch.FloatTensor | None = None"}, {"name": "pixel_mask", "val": ": torch.LongTensor | None = None"}, {"name": "inputs_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "image_embeds", "val": ": torch.FloatTensor | None = None"}, {"name": "labels", "val": ": torch.LongTensor | None = None"}, {"name": "**kwargs", "val": ": typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs]"}]- **input_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.
Indices can be obtained using [AutoTokenizer](/docs/transformers/v5.8.0/en/model_doc/auto#transformers.AutoTokenizer). See [PreTrainedTokenizer.encode()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.encode) and
[PreTrainedTokenizer.__call__()](/docs/transformers/v5.8.0/en/internal/tokenization_utils#transformers.PreTrainedTokenizerBase.__call__) for details.
[What are input IDs?](../glossary#input-ids)
- **attention_mask** (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
- **token_type_ids** (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) --
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0, 1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
- **pixel_values** (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)`, *optional*) --
The tensors corresponding to the input images. Pixel values can be obtained using
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor). See `BridgeTowerImageProcessor.__call__()` for details ([BridgeTowerProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerProcessor) uses
[BridgeTowerImageProcessor](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerImageProcessor) for processing images).
- **pixel_mask** (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*) --
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
[What are attention masks?](../glossary#attention-mask)
- **inputs_embeds** (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) --
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
- **image_embeds** (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*) --
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
- **labels** (`torch.LongTensor` of shape `(batch_size, 1)`, *optional*) --
Labels for computing the image-text matching loss. 0 means the pairs don't match and 1 means they match.
The pairs with 0 will be skipped for calculation.0[SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or `tuple(torch.FloatTensor)`A [SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.
The [BridgeTowerForImageAndTextRetrieval](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForImageAndTextRetrieval) forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module`
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
- **loss** (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) -- Classification (or regression if config.num_labels==1) loss.
- **logits** (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`) -- Classification (or regression if config.num_labels==1) scores (before SoftMax).
- **hidden_states** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) -- Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
- **attentions** (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) -- Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import httpx
>>> from io import BytesIO
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> with httpx.stream("GET", url) as response:
... image = Image.open(BytesIO(response.read()))
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
**Parameters:**
config ([BridgeTowerForImageAndTextRetrieval](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerForImageAndTextRetrieval)) : Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the [from_pretrained()](/docs/transformers/v5.8.0/en/main_classes/model#transformers.PreTrainedModel.from_pretrained) method to load the model weights.
**Returns:**
`[SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or `tuple(torch.FloatTensor)``
A [SequenceClassifierOutput](/docs/transformers/v5.8.0/en/main_classes/output#transformers.modeling_outputs.SequenceClassifierOutput) or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([BridgeTowerConfig](/docs/transformers/v5.8.0/en/model_doc/bridgetower#transformers.BridgeTowerConfig)) and inputs.