

Add 1 files
Browse files- 1812/1812.01243.md +267 -0
1812/1812.01243.md
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
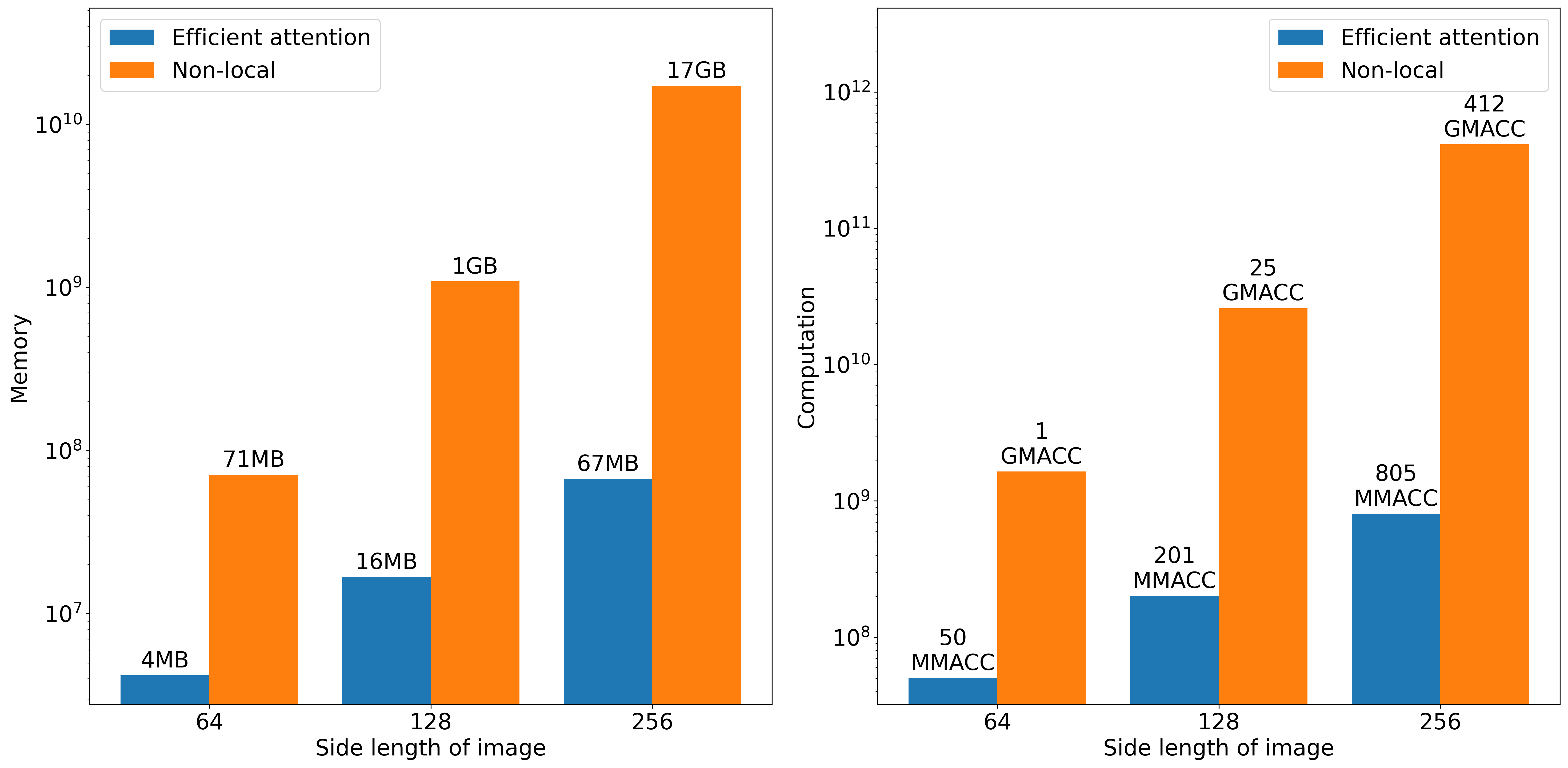
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Efficient Attention: Attention with Linear Complexities
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1812.01243
|
| 4 |
+
|
| 5 |
+
Published Time: Mon, 22 Jan 2024 02:00:54 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Shen Zhuoran††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT
|
| 9 |
+
|
| 10 |
+
Independent Researcher
|
| 11 |
+
|
| 12 |
+
4244 University Way NE #85406, Seattle, WA 98105, United States
|
| 13 |
+
|
| 14 |
+
cmsflash99@gmail.com Zhang Mingyuan, Zhao Haiyu, Yi Shuai
|
| 15 |
+
|
| 16 |
+
SenseTime International
|
| 17 |
+
|
| 18 |
+
182 Cecil Street, #36-02 Frasers Tower, Singapore 069547
|
| 19 |
+
|
| 20 |
+
zhangmingyuan,zhaohaiyu,yishuai@sensetime.com Equal contribution.Li Hongsheng
|
| 21 |
+
|
| 22 |
+
The Chinese University of Hong Kong
|
| 23 |
+
|
| 24 |
+
Sha Tin, Hong Kong
|
| 25 |
+
|
| 26 |
+
hsli@ee.cuhk.edu.hk
|
| 27 |
+
|
| 28 |
+
###### Abstract
|
| 29 |
+
|
| 30 |
+
Dot-product attention has wide applications in computer vision and natural language processing. However, its memory and computational costs grow quadratically with the input size. Such growth prohibits its application on high-resolution inputs. To remedy this drawback, this paper proposes a novel efficient attention mechanism equivalent to dot-product attention but with substantially less memory and computational costs. Its resource efficiency allows more widespread and flexible integration of attention modules into a network, which leads to better accuracies. Empirical evaluations demonstrated the effectiveness of its advantages. Efficient attention modules brought significant performance boosts to object detectors and instance segmenters on MS-COCO 2017. Further, the resource efficiency democratizes attention to complex models, where high costs prohibit the use of dot-product attention. As an exemplar, a model with efficient attention achieved state-of-the-art accuracies for stereo depth estimation on the Scene Flow dataset. Code is available at [https://github.com/cmsflash/efficient-attention](https://github.com/cmsflash/efficient-attention).
|
| 31 |
+
|
| 32 |
+
1 Introduction
|
| 33 |
+
--------------
|
| 34 |
+
|
| 35 |
+
Dot-product attention [[1](https://arxiv.org/html/1812.01243v10/#bib.bib1), [22](https://arxiv.org/html/1812.01243v10/#bib.bib22), [23](https://arxiv.org/html/1812.01243v10/#bib.bib23)] is a prevalent mechanism in neural networks for long-range dependency modeling, a key challenge to deep learning that convolution and recurrence struggle to solve. The mechanism computes the response at every position as a weighted sum of features at all positions in the previous layer. In contrast to the limited receptive fields of convolution or the recurrent layer, dot-product attention expands the receptive field to the entire input in one pass. Using dot-product attention to efficiently model long-range dependencies allows convolution and recurrence to focus on local dependency modeling, in which they specialize. The non-local module [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)], an adaptation of dot-product attention for computer vision, achieved state-of-the-art performance on video classification [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)] and generative adversarial image modeling [[28](https://arxiv.org/html/1812.01243v10/#bib.bib28), [2](https://arxiv.org/html/1812.01243v10/#bib.bib2)] and demonstrated significant improvements on object detection [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)], instance segmentation [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)], person re-identification [[14](https://arxiv.org/html/1812.01243v10/#bib.bib14)], image de-raining [[13](https://arxiv.org/html/1812.01243v10/#bib.bib13)], _etc_.
|
| 36 |
+
|
| 37 |
+
However, global dependency modeling on large inputs (_e.g_. long sequences, high-resolution images, large videos) remains an open problem. The quadratic 1 1 1 The complexities are quadratic with respect to the spatiotemporal size of the input, which is quartically w.r.t. the side length of a 2D feature map, or sextically w.r.t. the dimension of a 3D feature volume. memory and computational complexities with respect to the input size of dot-product attention inhibits its application on large inputs. For instance, a non-local module uses over 1 GB of GPU memory and over 25 GMACC 2 2 2 MACC stands for multiply-accumulation. 1 MACC means 1 multiplication and 1 addition operation. of computation for a 64-channel 128×128 128 128 128\times 128 128 × 128 feature map or over 68 GB and over 1.6 TMACC for a 64-channel 64×64×32 64 64 32 64\times 64\times 32 64 × 64 × 32 3D feature volume (_e.g_. for depth estimation or video tasks). The high memory and computational costs constrain the application of dot-product attention to the low-resolution parts of models [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23), [28](https://arxiv.org/html/1812.01243v10/#bib.bib28), [2](https://arxiv.org/html/1812.01243v10/#bib.bib2)] and prohibits its use for resolution-sensitive or resource-hungry tasks.
|
| 38 |
+
|
| 39 |
+

|
| 40 |
+
|
| 41 |
+
Figure 1: Illustration of the architecture of dot-product and efficient attention. Each box represents an input, output, or intermediate matrix. Above it is the name of the corresponding matrix, and inside are the variable name and the size of the matrix. ρ,ρ q,ρ k 𝜌 subscript 𝜌 𝑞 subscript 𝜌 𝑘\rho,\rho_{q},\rho_{k}italic_ρ , italic_ρ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT , italic_ρ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT are the normalizers on 𝑺,𝑸,𝑲 𝑺 𝑸 𝑲\bm{S},\bm{Q},\bm{K}bold_italic_S , bold_italic_Q , bold_italic_K, respectively. n,d,d k,d v 𝑛 𝑑 subscript 𝑑 𝑘 subscript 𝑑 𝑣 n,d,d_{k},d_{v}italic_n , italic_d , italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT , italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT are the input size and the dimensionalities of the input, the keys, and the values, respectively. ⨂tensor-product\bigotimes⨂ denotes matrix multiplication. When ρ,ρ q,ρ k 𝜌 subscript 𝜌 𝑞 subscript 𝜌 𝑘\rho,\rho_{q},\rho_{k}italic_ρ , italic_ρ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT , italic_ρ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT implement scaling normalization, the efficient attention mechanism is mathematically equivalent to dot-product attention. When they implement softmax normalization, the two mechanisms are approximately equivalent.
|
| 42 |
+
|
| 43 |
+
The need for global dependency modeling on large inputs motivates the exploration for a resource-efficient attention mechanism. An investigation into the non-local module revealed an intriguing discovery. As Figure [1](https://arxiv.org/html/1812.01243v10/#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Efficient Attention: Attention with Linear Complexities") shows, putting aside the normalization, dot-product attention involves two consecutive matrix multiplications. The first one (𝑺=𝑸𝑲 𝖳 𝑺 𝑸 superscript 𝑲 𝖳\bm{S}=\bm{Q}\bm{K}^{\mathsf{T}}bold_italic_S = bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT) computes pairwise similarities between pixels and forms per-pixel attention maps. The second (𝑫=𝑺𝑽 𝑫 𝑺 𝑽\bm{D}=\bm{S}\bm{V}bold_italic_D = bold_italic_S bold_italic_V) aggregates the values 𝑽 𝑽\bm{V}bold_italic_V by the per-pixel attention maps to produce the output. Since matrix multiplication is associative, switching the order from (𝑸𝑲 𝖳)𝑽 𝑸 superscript 𝑲 𝖳 𝑽(\bm{Q}\bm{K}^{\mathsf{T}})\bm{V}( bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT ) bold_italic_V to 𝑸(𝑲 𝖳𝑽)𝑸 superscript 𝑲 𝖳 𝑽\bm{Q}(\bm{K}^{\mathsf{T}}\bm{V})bold_italic_Q ( bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT bold_italic_V ) has no impact on the effect but changes the complexities from O(n 2)𝑂 superscript 𝑛 2 O(n^{2})italic_O ( italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) to O(d kd v)𝑂 subscript 𝑑 𝑘 subscript 𝑑 𝑣 O(d_{k}d_{v})italic_O ( italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT ), for n 𝑛 n italic_n the input size and d k,d v subscript 𝑑 𝑘 subscript 𝑑 𝑣 d_{k},d_{v}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT , italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT the dimensionalities of the keys and the values, respectively. This change removes the O(n 2)𝑂 superscript 𝑛 2 O(n^{2})italic_O ( italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) terms in the complexities of the module, making it linear in complexities. Further, d kd v subscript 𝑑 𝑘 subscript 𝑑 𝑣 d_{k}d_{v}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT is significantly less than n 2 superscript 𝑛 2 n^{2}italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT in practical cases, hence this new term will not become a new bottleneck. Therefore, switching the order of multiplication to 𝑸(𝑲 𝖳𝑽)𝑸 superscript 𝑲 𝖳 𝑽\bm{Q}(\bm{K}^{\mathsf{T}}\bm{V})bold_italic_Q ( bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT bold_italic_V ) results in a substantially more efficient mechanism, which this paper names efficient attention.
|
| 44 |
+
|
| 45 |
+
The new mechanism is mathematically equivalent to dot-product attention with scaling normalization and approximately equivalent with softmax normalization. Experiments empirically verified that when the equivalence is approximate, it does not impact accuracies. In addition, experiments showed that its efficiency allows the integration of more attention modules into a network and integration into high-resolution parts of a network, which lead to significantly higher accuracies. Further, experiments demonstrated that efficient attention democratizes attention to tasks where dot-product attention is inapplicable due to resource constraints.
|
| 46 |
+
|
| 47 |
+
Another discovery is that efficient attention brings a new interpretation to the attention mechanism. Assuming the keys are of dimensionality d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT and the input size is n 𝑛 n italic_n, one can interpret the d k×n subscript ��� 𝑘 𝑛 d_{k}\times n italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT × italic_n key matrix as d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT template attention maps, each corresponding to a semantic aspect of the input. Then, the query at each pixel is d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT coefficients for each of the d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT template attention maps, respectively. Under this interpretation, efficient and dot-product attention differs in that dot-product attention first synthesizes the pixel-wise attention maps from the coefficients and lets each pixel aggregate the values with its own attention map, while efficient attention first aggregates the values by the template attention maps to form template outputs (_i.e_. global context vectors) and lets each pixel aggregate the template outputs.
|
| 48 |
+
|
| 49 |
+
The principal contribution of this paper is the efficient attention mechanism, which:
|
| 50 |
+
|
| 51 |
+
1. 1.has linear memory and computational complexities with respect to the size of the input;
|
| 52 |
+
2. 2.possesses the same representational power as the prevalent dot-product attention mechanism;
|
| 53 |
+
3. 3.allows the integration of more attention modules into a neural network and into higher-resolution parts of the network, which brings substantial performance boosts to tasks such as object detection and instance segmentation (on MS-COCO 2017); and
|
| 54 |
+
4. 4.facilitates the application of attention on resource-hungry tasks, such as stereo depth estimation (on the Scene Flow dataset).
|
| 55 |
+
|
| 56 |
+
2 Related works
|
| 57 |
+
---------------
|
| 58 |
+
|
| 59 |
+
### 2.1 Dot-product attention
|
| 60 |
+
|
| 61 |
+
[[1](https://arxiv.org/html/1812.01243v10/#bib.bib1)] proposed the initial formulation of the dot-product attention mechanism to improve word alignment in machine translation. Successively, [[22](https://arxiv.org/html/1812.01243v10/#bib.bib22)] proposed to completely replace recurrence with attention and named the resultant architecture the Transformer. The Transformer architecture is highly successful on sequence tasks. They hold the state-of-the-art records on virtually all tasks in natural language processing [[7](https://arxiv.org/html/1812.01243v10/#bib.bib7), [20](https://arxiv.org/html/1812.01243v10/#bib.bib20), [26](https://arxiv.org/html/1812.01243v10/#bib.bib26)] and is highly competitive on end-to-end speech recognition [[8](https://arxiv.org/html/1812.01243v10/#bib.bib8), [18](https://arxiv.org/html/1812.01243v10/#bib.bib18)]. [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)] first adapted dot-product attention for computer vision and proposed the non-local module. They achieved state-of-the-art performance on video classification and demonstrated significant improvements on object detection, instance segmentation, and pose estimation. Subsequent works applied it to various fields in computer vision, including image restoration [[16](https://arxiv.org/html/1812.01243v10/#bib.bib16)], video person re-identification [[14](https://arxiv.org/html/1812.01243v10/#bib.bib14)], generative adversarial image modeling [[28](https://arxiv.org/html/1812.01243v10/#bib.bib28), [2](https://arxiv.org/html/1812.01243v10/#bib.bib2)], image de-raining [[13](https://arxiv.org/html/1812.01243v10/#bib.bib13)], and few-shot learning [[9](https://arxiv.org/html/1812.01243v10/#bib.bib9), [11](https://arxiv.org/html/1812.01243v10/#bib.bib11)], _etc_.
|
| 62 |
+
|
| 63 |
+
Efficient attention mainly builds upon the version of dot-product attention in the non-local module. Following [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)], the team conducted most experiments on object detection and instance segmentation. The paper compares the resource efficiency of the efficient attention module against the non-local module under the same performance and their performance under the same resource constraints.
|
| 64 |
+
|
| 65 |
+
### 2.2 Scaling attention
|
| 66 |
+
|
| 67 |
+
Besides dot-product attention, there are a separate set of techniques the literature refers to as attention. This section refers to them as scaling attention. While dot-product attention is effective for global dependency modeling, scaling attention focuses on emphasizing important features and suppressing uninformative ones. For example, the squeeze-and-excitation (SE) module [[10](https://arxiv.org/html/1812.01243v10/#bib.bib10)] uses global average pooling and a linear layer to compute a scaling factor for each channel and then scales the channels accordingly. SE-enhanced models achieved state-of-the-art performance on image classification and substantial improvements on scene segmentation and object detection. On top of SE, CBAM [[24](https://arxiv.org/html/1812.01243v10/#bib.bib24)] added global max pooling beside global average pooling and an extra spatial attention submodule. GCNet [[3](https://arxiv.org/html/1812.01243v10/#bib.bib3)] proposes to replace the global average pooling by an adaptive pooling layer, which uses a linear layer to compute the weight for each position. These follow-up methods further improves upon the performance of SE [[10](https://arxiv.org/html/1812.01243v10/#bib.bib10)].
|
| 68 |
+
|
| 69 |
+
Despite both names containing attention, dot-product attention and scaling attention are two separate sets of techniques with highly divergent goals. When appropriate, one might take both techniques and let them work in conjunction. Therefore, it is unnecessary to make comparison of efficient attention with scaling attention techniques.
|
| 70 |
+
|
| 71 |
+
### 2.3 Efficient non-local operations
|
| 72 |
+
|
| 73 |
+
Recent literature proposed several methods for efficient non-local operations. LatentGNN [[29](https://arxiv.org/html/1812.01243v10/#bib.bib29)] proposes to approximate the single n×n 𝑛 𝑛 n\times n italic_n × italic_n affinity matrix in the non-local [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)] module by the product of three lower-rank matrices. In comparison, efficient attention is not an approximation of the non-local module, but is mathematically equivalent (using scaling normalization). In addition, there is a one-to-one mapping between the structural components of the non-local module and the efficient attention module. Therefore, in any field where the non-local module succeeded, one can guarantee the applicability of efficient attention as a drop-in replacement with substantially improved performance-cost trade-off.
|
| 74 |
+
|
| 75 |
+
CGNL [[27](https://arxiv.org/html/1812.01243v10/#bib.bib27)] proposes to flatten the height, width, and channel dimensions to a hwc ℎ 𝑤 𝑐 hwc italic_h italic_w italic_c-dimensional vector, applies a kernel function to expand the dimensionality to hwc×(p+1)ℎ 𝑤 𝑐 𝑝 1 hwc\times(p+1)italic_h italic_w italic_c × ( italic_p + 1 ), for p 𝑝 p italic_p the degree of Taylor expansion, and models global dependencies in that space. However, after flattening the input into a vector, the feature at each position becomes a scalar, which encodes limited information for interaction modeling. In contrast, efficient attention preserves a vector representation at each pixel and is capable to model richer interactions.
|
| 76 |
+
|
| 77 |
+
Section [4.1.2](https://arxiv.org/html/1812.01243v10/#S4.SS1.SSS2 "4.1.2 Comparison with competing methods ‣ 4.1 Comparison experiments ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities") presents empirical comparison between efficient attention and these competing methods in detail, which shows that efficient attention outperforms each of them.
|
| 78 |
+
|
| 79 |
+
3 Method
|
| 80 |
+
--------
|
| 81 |
+
|
| 82 |
+
### 3.1 A revisit of dot-product attention
|
| 83 |
+
|
| 84 |
+
Dot-product attention is a mechanism for long-range interaction modeling in neural networks. For each input feature vector 𝒙 i∈ℝ d subscript 𝒙 𝑖 superscript ℝ 𝑑\bm{x}_{i}\in\mathbb{R}^{d}bold_italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d end_POSTSUPERSCRIPT that corresponds to the i 𝑖 i italic_i-th position, dot-product attention first uses three linear layers to convert 𝒙 i subscript 𝒙 𝑖\bm{x}_{i}bold_italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT into three feature vectors, _i.e_., the query 𝒒 i∈ℝ d k subscript 𝒒 𝑖 superscript ℝ subscript 𝑑 𝑘\bm{q}_{i}\in\mathbb{R}^{d_{k}}bold_italic_q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, the key 𝒌 i∈ℝ d k subscript 𝒌 𝑖 superscript ℝ subscript 𝑑 𝑘\bm{k}_{i}\in\mathbb{R}^{d_{k}}bold_italic_k start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, and the value 𝒗 i∈ℝ d v subscript 𝒗 𝑖 superscript ℝ subscript 𝑑 𝑣\bm{v}_{i}\in\mathbb{R}^{d_{v}}bold_italic_v start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT end_POSTSUPERSCRIPT. The queries and keys must have the same feature dimension d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT. One can measure the similarity between the i 𝑖 i italic_i-th query and the j 𝑗 j italic_j-th key as ρ(𝒒 i 𝖳𝒌 j)𝜌 superscript subscript 𝒒 𝑖 𝖳 subscript 𝒌 𝑗\rho(\bm{q}_{i}^{\mathsf{T}}\bm{k}_{j})italic_ρ ( bold_italic_q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT bold_italic_k start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ), where ρ 𝜌\rho italic_ρ is a normalization function. In general, the similarities are asymmetric, since the queries and keys are the outputs of two separate layers. The dot-product attention module calculates the similarities between all pairs of positions. Using the similarities as weights, position i 𝑖 i italic_i aggregates the values from all positions via weighted summation to obtain its output feature.
|
| 85 |
+
|
| 86 |
+
If one represents all n 𝑛 n italic_n positions’ queries, keys, and values in matrix forms as 𝑸∈ℝ n×d k �� superscript ℝ 𝑛 subscript 𝑑 𝑘\bm{Q}\in\mathbb{R}^{n\times d_{k}}bold_italic_Q ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, 𝑲∈ℝ n×d k,𝑽∈ℝ n×d v formulae-sequence 𝑲 superscript ℝ 𝑛 subscript 𝑑 𝑘 𝑽 superscript ℝ 𝑛 subscript 𝑑 𝑣\bm{K}\in\mathbb{R}^{n\times d_{k}},\bm{V}\in\mathbb{R}^{n\times d_{v}}bold_italic_K ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT , bold_italic_V ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, respectively, the output of dot-product attention is
|
| 87 |
+
|
| 88 |
+
𝑫(𝑸,𝑲,𝑽)=ρ(𝑸𝑲 𝖳)𝑽.𝑫 𝑸 𝑲 𝑽 𝜌 𝑸 superscript 𝑲 𝖳 𝑽\bm{D}(\bm{Q},\bm{K},\bm{V})=\rho\left(\bm{Q}\bm{K}^{\mathsf{T}}\right)\bm{V}.bold_italic_D ( bold_italic_Q , bold_italic_K , bold_italic_V ) = italic_ρ ( bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT ) bold_italic_V .(1)
|
| 89 |
+
|
| 90 |
+
The normalization function has two common choices:
|
| 91 |
+
|
| 92 |
+
Scaling:ρ(𝒀)=𝒀 n,Softmax:ρ(𝒀)=σ row(𝒀),formulae-sequence Scaling:𝜌 𝒀 𝒀 𝑛 Softmax:𝜌 𝒀 subscript 𝜎 row 𝒀\displaystyle\begin{split}\text{Scaling: }&\rho(\bm{Y})=\frac{\bm{Y}}{n},\\ \text{Softmax: }&\rho(\bm{Y})=\sigma_{\text{row}}(\bm{Y}),\end{split}start_ROW start_CELL Scaling: end_CELL start_CELL italic_ρ ( bold_italic_Y ) = divide start_ARG bold_italic_Y end_ARG start_ARG italic_n end_ARG , end_CELL end_ROW start_ROW start_CELL Softmax: end_CELL start_CELL italic_ρ ( bold_italic_Y ) = italic_σ start_POSTSUBSCRIPT row end_POSTSUBSCRIPT ( bold_italic_Y ) , end_CELL end_ROW(2)
|
| 93 |
+
|
| 94 |
+
where σ row subscript 𝜎 row\sigma_{\text{row}}italic_σ start_POSTSUBSCRIPT row end_POSTSUBSCRIPT denotes applying the softmax function along each row of matrix 𝒀 𝒀\bm{Y}bold_italic_Y. An illustration of the dot-product attention module is in Figure [1](https://arxiv.org/html/1812.01243v10/#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Efficient Attention: Attention with Linear Complexities") (left).
|
| 95 |
+
|
| 96 |
+
The critical drawback of this mechanism is its resource demands. Since it computes a similarity between each pair of positions, there are n 2 superscript 𝑛 2 n^{2}italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT such similarities, which results in O(n 2)𝑂 superscript 𝑛 2 O(n^{2})italic_O ( italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) memory complexity and O(d kn 2)𝑂 subscript 𝑑 𝑘 superscript 𝑛 2 O(d_{k}n^{2})italic_O ( italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) computational complexity. Therefore, dot-product attention’s resource demands get prohibitively high on large inputs. In practice, application of the mechanism is only possible on low-resolution features.
|
| 97 |
+
|
| 98 |
+
### 3.2 Efficient attention
|
| 99 |
+
|
| 100 |
+
Observing the critical drawback of dot-product attention, this paper proposes the efficient attention mechanism, which is mathematically equivalent to dot-product attention but substantially faster and more memory efficient. In efficient attention, the individual feature vectors 𝑿∈ℝ n×d 𝑿 superscript ℝ 𝑛 𝑑\bm{X}\in\mathbb{R}^{n\times d}bold_italic_X ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d end_POSTSUPERSCRIPT still pass through three linear layers to form the queries 𝑸∈ℝ n×d k 𝑸 superscript ℝ 𝑛 subscript 𝑑 𝑘\bm{Q}\in\mathbb{R}^{n\times d_{k}}bold_italic_Q ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, keys 𝑲∈ℝ n×d k 𝑲 superscript ℝ 𝑛 subscript 𝑑 𝑘\bm{K}\in\mathbb{R}^{n\times d_{k}}bold_italic_K ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, and values 𝑽∈ℝ n×d v 𝑽 superscript ℝ 𝑛 subscript 𝑑 𝑣\bm{V}\in\mathbb{R}^{n\times d_{v}}bold_italic_V ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT end_POSTSUPERSCRIPT. However, instead of interpreting the keys as n 𝑛 n italic_n feature vectors in ℝ d k superscript ℝ subscript 𝑑 𝑘\mathbb{R}^{d_{k}}blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT, the module regards them as d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT single-channel feature maps. Efficient attention uses each of these feature maps as a weighting over all positions and aggregates the value features through weighted summation to form a global context vector. The name reflects the fact that the vector does not correspond to a specific position, but is a global description of the input features.
|
| 101 |
+
|
| 102 |
+
The following equation characterizes the efficient attention mechanism:
|
| 103 |
+
|
| 104 |
+
𝑬(𝑸,���,𝑽)=ρ q(𝑸)(ρ k(𝑲)𝖳𝑽),𝑬 𝑸 𝑲 𝑽 subscript 𝜌 𝑞 𝑸 subscript 𝜌 𝑘 superscript 𝑲 𝖳 𝑽\bm{E}(\bm{Q},\bm{K},\bm{V})=\rho_{q}(\bm{Q})\left(\rho_{k}(\bm{K})^{\mathsf{T% }}\bm{V}\right),bold_italic_E ( bold_italic_Q , bold_italic_K , bold_italic_V ) = italic_ρ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ( bold_italic_Q ) ( italic_ρ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ( bold_italic_K ) start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT bold_italic_V ) ,(3)
|
| 105 |
+
|
| 106 |
+
where ρ q subscript 𝜌 𝑞\rho_{q}italic_ρ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT and ρ k subscript 𝜌 𝑘\rho_{k}italic_ρ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT are normalization functions for the query and key features, respectively. The implementation of the same two normalization methods as for dot-production attention are
|
| 107 |
+
|
| 108 |
+
Scaling:ρ q(𝒀)=ρ k(𝒀)=𝒀 n,Softmax:ρ q(𝒀)=σ row(𝒀),ρ k(𝒀)=σ col(𝒀),formulae-sequence Scaling:subscript 𝜌 𝑞 𝒀 subscript 𝜌 𝑘 𝒀 𝒀 𝑛 formulae-sequence Softmax:subscript 𝜌 𝑞 𝒀 subscript 𝜎 row 𝒀 subscript 𝜌 𝑘 𝒀 subscript 𝜎 col 𝒀\displaystyle\begin{split}\text{Scaling: }&\rho_{q}(\bm{Y})=\rho_{k}(\bm{Y})=% \frac{\bm{Y}}{\sqrt{n}},\\ \text{Softmax: }&\rho_{q}(\bm{Y})=\sigma_{\text{row}}(\bm{Y}),\\ &\rho_{k}(\bm{Y})=\sigma_{\text{col}}(\bm{Y}),\end{split}start_ROW start_CELL Scaling: end_CELL start_CELL italic_ρ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ( bold_italic_Y ) = italic_ρ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ( bold_italic_Y ) = divide start_ARG bold_italic_Y end_ARG start_ARG square-root start_ARG italic_n end_ARG end_ARG , end_CELL end_ROW start_ROW start_CELL Softmax: end_CELL start_CELL italic_ρ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT ( bold_italic_Y ) = italic_σ start_POSTSUBSCRIPT row end_POSTSUBSCRIPT ( bold_italic_Y ) , end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL italic_ρ start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT ( bold_italic_Y ) = italic_σ start_POSTSUBSCRIPT col end_POSTSUBSCRIPT ( bold_italic_Y ) , end_CELL end_ROW(4)
|
| 109 |
+
|
| 110 |
+
where σ row,σ col subscript 𝜎 row subscript 𝜎 col\sigma_{\text{row}},\sigma_{\text{col}}italic_σ start_POSTSUBSCRIPT row end_POSTSUBSCRIPT , italic_σ start_POSTSUBSCRIPT col end_POSTSUBSCRIPT denote applying the softmax function along each row or column of matrix 𝒀 𝒀\bm{Y}bold_italic_Y, respectively.
|
| 111 |
+
|
| 112 |
+
The efficient attention module is a concrete implementation of the mechanism for computer vision data. For an input feature map 𝗫∈ℝ h×w×d 𝗫 superscript ℝ ℎ 𝑤 𝑑\bm{\mathsf{X}}\in\mathbb{R}^{h\times w\times d}bold_sansserif_X ∈ blackboard_R start_POSTSUPERSCRIPT italic_h × italic_w × italic_d end_POSTSUPERSCRIPT, the module flattens it to a matrix 𝑿∈ℝ hw×d 𝑿 superscript ℝ ℎ 𝑤 𝑑\bm{X}\in\mathbb{R}^{hw\times d}bold_italic_X ∈ blackboard_R start_POSTSUPERSCRIPT italic_h italic_w × italic_d end_POSTSUPERSCRIPT, applies the efficient attention mechanism on it, and reshapes the result to h×w×d v ℎ 𝑤 subscript 𝑑 𝑣 h\times w\times d_{v}italic_h × italic_w × italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT. If d v≠d subscript 𝑑 𝑣 𝑑 d_{v}\neq d italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT ≠ italic_d, it further applies a 1x1 convolution to restore the dimensionality to d 𝑑 d italic_d. Finally, it adds the resultant features to the input features to form a residual structure.
|
| 113 |
+
|
| 114 |
+
### 3.3 Equivalence between dot-product and efficient attention
|
| 115 |
+
|
| 116 |
+
Following is a formal proof of the equivalence between dot-product and efficient attention when using scaling normalization. Substituting the scaling normalization formula in Equation ([2](https://arxiv.org/html/1812.01243v10/#S3.E2 "2 ‣ 3.1 A revisit of dot-product attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities")) into Equation ([1](https://arxiv.org/html/1812.01243v10/#S3.E1 "1 ‣ 3.1 A revisit of dot-product attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities")) gives
|
| 117 |
+
|
| 118 |
+
𝑫(𝑸,𝑲,𝑽)=𝑸𝑲 𝖳 n𝑽.𝑫 𝑸 𝑲 𝑽 𝑸 superscript 𝑲 𝖳 𝑛 𝑽\bm{D}(\bm{Q},\bm{K},\bm{V})=\frac{\bm{Q}\bm{K}^{\mathsf{T}}}{n}\bm{V}.bold_italic_D ( bold_italic_Q , bold_italic_K , bold_italic_V ) = divide start_ARG bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT end_ARG start_ARG italic_n end_ARG bold_italic_V .(5)
|
| 119 |
+
|
| 120 |
+
Similarly, plugging the scaling normalization formulae in Equation ([4](https://arxiv.org/html/1812.01243v10/#S3.E4 "4 ‣ 3.2 Efficient attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities")) into Equation ([3](https://arxiv.org/html/1812.01243v10/#S3.E3 "3 ‣ 3.2 Efficient attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities")) results in
|
| 121 |
+
|
| 122 |
+
𝑬(𝑸,𝑲,𝑽)=𝑸 n(𝑲 𝖳 n𝑽).𝑬 𝑸 𝑲 𝑽 𝑸 𝑛 superscript 𝑲 𝖳 𝑛 𝑽\bm{E}(\bm{Q},\bm{K},\bm{V})=\frac{\bm{Q}}{\sqrt{n}}\left(\frac{\bm{K}^{% \mathsf{T}}}{\sqrt{n}}\bm{V}\right).bold_italic_E ( bold_italic_Q , bold_italic_K , bold_italic_V ) = divide start_ARG bold_italic_Q end_ARG start_ARG square-root start_ARG italic_n end_ARG end_ARG ( divide start_ARG bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT end_ARG start_ARG square-root start_ARG italic_n end_ARG end_ARG bold_italic_V ) .(6)
|
| 123 |
+
|
| 124 |
+
Since scalar multiplication is commutative with matrix multiplication and matrix multiplication is associative, we have
|
| 125 |
+
|
| 126 |
+
𝑬(𝑸,𝑲,𝑽)=𝑸 n(𝑲 𝖳 n𝑽)=1 n𝑸(𝑲 𝖳𝑽)=1 n(𝑸𝑲 𝖳)𝑽=𝑸𝑲 𝖳 n𝑽.𝑬 𝑸 𝑲 𝑽 𝑸 𝑛 superscript 𝑲 𝖳 𝑛 𝑽 1 𝑛 𝑸 superscript 𝑲 𝖳 𝑽 1 𝑛 𝑸 superscript 𝑲 𝖳 𝑽 𝑸 superscript 𝑲 𝖳 𝑛 𝑽\displaystyle\begin{split}\bm{E}(\bm{Q},\bm{K},\bm{V})&=\frac{\bm{Q}}{\sqrt{n}% }\left(\frac{\bm{K}^{\mathsf{T}}}{\sqrt{n}}\bm{V}\right)\\ &=\frac{1}{n}\bm{Q}\left(\bm{K}^{\mathsf{T}}\bm{V}\right)\\ &=\frac{1}{n}\left(\bm{Q}\bm{K}^{\mathsf{T}}\right)\bm{V}\\ &=\frac{\bm{Q}\bm{K}^{\mathsf{T}}}{n}\bm{V}.\end{split}start_ROW start_CELL bold_italic_E ( bold_italic_Q , bold_italic_K , bold_italic_V ) end_CELL start_CELL = divide start_ARG bold_italic_Q end_ARG start_ARG square-root start_ARG italic_n end_ARG end_ARG ( divide start_ARG bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT end_ARG start_ARG square-root start_ARG italic_n end_ARG end_ARG bold_italic_V ) end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL = divide start_ARG 1 end_ARG start_ARG italic_n end_ARG bold_italic_Q ( bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT bold_italic_V ) end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL = divide start_ARG 1 end_ARG start_ARG italic_n end_ARG ( bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT ) bold_italic_V end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL = divide start_ARG bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT end_ARG start_ARG italic_n end_ARG bold_italic_V . end_CELL end_ROW(7)
|
| 127 |
+
|
| 128 |
+
Comparing Equations ([5](https://arxiv.org/html/1812.01243v10/#S3.E5 "5 ‣ 3.3 Equivalence between dot-product and efficient attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities")) and ([7](https://arxiv.org/html/1812.01243v10/#S3.E7 "7 ‣ 3.3 Equivalence between dot-product and efficient attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities")), we get
|
| 129 |
+
|
| 130 |
+
𝑬(𝑸,𝑲,𝑽)=𝑫(𝑸,𝑲,𝑽).𝑬 𝑸 𝑲 𝑽 𝑫 𝑸 𝑲 𝑽\bm{E}(\bm{Q},\bm{K},\bm{V})=\bm{D}(\bm{Q},\bm{K},\bm{V}).bold_italic_E ( bold_italic_Q , bold_italic_K , bold_italic_V ) = bold_italic_D ( bold_italic_Q , bold_italic_K , bold_italic_V ) .(8)
|
| 131 |
+
|
| 132 |
+
Thus, the proof is complete.
|
| 133 |
+
|
| 134 |
+
The above proof works for the softmax normalization variant with one caveat. The two softmax operations on 𝑸,𝑲 𝑸 𝑲\bm{Q},\bm{K}bold_italic_Q , bold_italic_K are not exactly equivalent to the single softmax on 𝑸𝑲 𝖳 𝑸 superscript 𝑲 𝖳\bm{Q}\bm{K}^{\mathsf{T}}bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT. However, they closely approximate the effect of the original softmax function. The critical property of σ row(𝑸𝑲 𝖳)subscript 𝜎 row 𝑸 superscript 𝑲 𝖳\sigma_{\text{row}}\left(\bm{Q}\bm{K}^{\mathsf{T}}\right)italic_σ start_POSTSUBSCRIPT row end_POSTSUBSCRIPT ( bold_italic_Q bold_italic_K start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT ) is that each row of it sums up to 1 1 1 1 and represents a normalized attention distribution over all positions. The matrix σ row(𝑸)σ col(𝑲)𝖳 subscript 𝜎 row 𝑸 subscript 𝜎 col superscript 𝑲 𝖳\sigma_{\text{row}}(\bm{Q})\sigma_{\text{col}}(\bm{K})^{\mathsf{T}}italic_σ start_POSTSUBSCRIPT row end_POSTSUBSCRIPT ( bold_italic_Q ) italic_σ start_POSTSUBSCRIPT col end_POSTSUBSCRIPT ( bold_italic_K ) start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT shares this property. Therefore, the softmax variant of efficient attention is a close approximation of that variant of dot-product attention. Section [4.1](https://arxiv.org/html/1812.01243v10/#S4.SS1 "4.1 Comparison experiments ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities") demonstrates this claim empirically.
|
| 135 |
+
|
| 136 |
+
### 3.4 Interpretation of efficient attention
|
| 137 |
+
|
| 138 |
+
Efficient attention brings a new interpretation of the attention mechanism. In dot-product attention, selecting position i 𝑖 i italic_i as the reference position, one can collect the similarities of all positions to position i 𝑖 i italic_i and form an attention map 𝒔 i subscript 𝒔 𝑖\bm{s}_{i}bold_italic_s start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT for that position. The attention map 𝒔 i subscript 𝒔 𝑖\bm{s}_{i}bold_italic_s start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT represents the degree to which position i 𝑖 i italic_i attends to each position j 𝑗 j italic_j in the input. A higher value for position j 𝑗 j italic_j on 𝒔 i subscript 𝒔 𝑖\bm{s}_{i}bold_italic_s start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT means position i 𝑖 i italic_i attends more to position j 𝑗 j italic_j. In dot-product attention, every position i 𝑖 i italic_i has such an attention map 𝒔 i subscript 𝒔 𝑖\bm{s}_{i}bold_italic_s start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, which the mechanism uses to aggregate the values 𝑽 𝑽\bm{V}bold_italic_V to produce the output at position i 𝑖 i italic_i.
|
| 139 |
+
|
| 140 |
+
In contrast, efficient attention does not generate an attention map for each position. Instead, it interprets the keys 𝑲∈ℝ n×d k 𝑲 superscript ℝ 𝑛 subscript 𝑑 𝑘\bm{K}\in\mathbb{R}^{n\times d_{k}}bold_italic_K ∈ blackboard_R start_POSTSUPERSCRIPT italic_n × italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT end_POSTSUPERSCRIPT as d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT attention maps 𝒌 j 𝖳 subscript superscript 𝒌 𝖳 𝑗\bm{k}^{\mathsf{T}}_{j}bold_italic_k start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT. Each 𝒌 j 𝖳 subscript superscript 𝒌 𝖳 𝑗\bm{k}^{\mathsf{T}}_{j}bold_italic_k start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT is a global attention map that does not correspond to any specific position. Instead, each of them corresponds to a semantic aspect of the entire input. For example, one such attention map might cover the persons in the input. Another might correspond to the background. Section [6](https://arxiv.org/html/1812.01243v10/#S6 "6 Visualization ‣ Efficient Attention: Attention with Linear Complexities") gives several concrete examples. Efficient attention uses each 𝒌 j 𝖳 superscript subscript 𝒌 𝑗 𝖳\bm{k}_{j}^{\mathsf{T}}bold_italic_k start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT to aggregate the values 𝑽 𝑽\bm{V}bold_italic_V and produce a global context vector 𝒈 j subscript 𝒈 𝑗\bm{g}_{j}bold_italic_g start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT. Since 𝒌 j 𝖳 subscript superscript 𝒌 𝖳 𝑗\bm{k}^{\mathsf{T}}_{j}bold_italic_k start_POSTSUPERSCRIPT sansserif_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT describes a global, semantic aspect of the input, 𝒈 j subscript 𝒈 𝑗\bm{g}_{j}bold_italic_g start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT also summarizes a global, semantic aspect of the input. Then, position i 𝑖 i italic_i uses 𝒒 i subscript 𝒒 𝑖\bm{q}_{i}bold_italic_q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT as a set of coefficients over 𝒈 0,𝒈 1,…,𝒈 d k−1 subscript 𝒈 0 subscript 𝒈 1…subscript 𝒈 subscript 𝑑 𝑘 1\bm{g}_{0},\bm{g}_{1},\ldots,\bm{g}_{d_{k}-1}bold_italic_g start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT , bold_italic_g start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , bold_italic_g start_POSTSUBSCRIPT italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT - 1 end_POSTSUBSCRIPT. Using the previous example, a person pixel might place a large weight on the global context vector for persons to refine its representation. A pixel at the boundary of an object might have large weights on the global context vectors for both the object and the background to enhance the contrast.
|
| 141 |
+
|
| 142 |
+
### 3.5 Efficiency advantage
|
| 143 |
+
|
| 144 |
+
This section analyzes the efficiency advantage of efficient attention over dot-product attention in memory and computation. The reason behind the efficiency advantage is that efficient attention does not compute a similarity between each pair of positions, which would occupy O(n 2)𝑂 superscript 𝑛 2 O(n^{2})italic_O ( italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) memory and require O(d kn 2)𝑂 subscript 𝑑 𝑘 superscript 𝑛 2 O(d_{k}n^{2})italic_O ( italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) computation to generate. Instead, it only generates d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT global context vectors in ℝ d v superscript ℝ subscript 𝑑 𝑣\mathbb{R}^{d_{v}}blackboard_R start_POSTSUPERSCRIPT italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT end_POSTSUPERSCRIPT. This change eliminates the O(n 2)𝑂 superscript 𝑛 2 O(n^{2})italic_O ( italic_n start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) terms from both the memory and computational complexities of the module. Consequently, efficient attention has O(dn+d 2)𝑂 𝑑 𝑛 superscript 𝑑 2 O(dn+d^{2})italic_O ( italic_d italic_n + italic_d start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ) memory and O(d 2n)𝑂 superscript 𝑑 2 𝑛 O(d^{2}n)italic_O ( italic_d start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT italic_n ) computational complexities, assuming the common setting of d v=d,d k=d 2 formulae-sequence subscript 𝑑 𝑣 𝑑 subscript 𝑑 𝑘 𝑑 2 d_{v}=d,d_{k}=\frac{d}{2}italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT = italic_d , italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = divide start_ARG italic_d end_ARG start_ARG 2 end_ARG. Table [1](https://arxiv.org/html/1812.01243v10/#S3.T1 "Table 1 ‣ 3.5 Efficiency advantage ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities") shows complexity formulae of the efficient attention module and the non-local module (using dot-product attention) in detail. In computer vision, this complexity difference is substantial. Firstly, the input size n 𝑛 n italic_n is quadratic in image side length and often very large in practice. Secondly, d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT is a parameter of the module, which the designer of a network can tune to meet different resource requirements. Section [4.2.2](https://arxiv.org/html/1812.01243v10/#S4.SS2.SSS2 "4.2.2 Dimensionality of the keys ‣ 4.2 Ablation studies ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities") shows that, within a reasonable range, this parameter has minimal impact on performance. This result means that an efficient attention module can typically have a small d k subscript 𝑑 𝑘 d_{k}italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT, which further increases its efficiency advantage over dot-product attention.
|
| 145 |
+
|
| 146 |
+
Table 1: Comparison of resource usage of the efficient attention and non-local modules. This table assumes that d v=d,d k=d 2 formulae-sequence subscript 𝑑 𝑣 𝑑 subscript 𝑑 𝑘 𝑑 2 d_{v}=d,d_{k}=\frac{d}{2}italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT = italic_d , italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = divide start_ARG italic_d end_ARG start_ARG 2 end_ARG, which is a common setting in the literature for dot-product attention
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
Figure 2: Resource requirements under different input sizes. The blue and orange bars depict the resource requirements of the efficient attention and non-local modules, respectively. The calculation assumes d=d v=2d k=64 𝑑 subscript 𝑑 𝑣 2 subscript 𝑑 𝑘 64 d=d_{v}=2d_{k}=64 italic_d = italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT = 2 italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = 64. This is a typical setting of self-attention for computer vision. The figure is in log scale.
|
| 151 |
+
|
| 152 |
+
The rest of this section will give several concrete examples comparing the resource demands of the efficient attention and non-local modules. Figure [2](https://arxiv.org/html/1812.01243v10/#S3.F2 "Figure 2 ‣ 3.5 Efficiency advantage ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities") compares their resource consumption for image features with different sizes. Directly substituting the non-local module on the 64×64 64 64 64\times 64 64 × 64 feature map in SAGAN [[28](https://arxiv.org/html/1812.01243v10/#bib.bib28)] yields a 17-time saving of memory and 33-time saving of computation. The gap widens rapidly with the increase of the input size. For a 256×256 256 256 256\times 256 256 × 256 feature map, a non-local module would require impractical amounts of memory (17.2 GB) and computation (413 GMACC). With the same input size, an efficient attention module uses 1/257 the memory and 1/513 the computation. The difference is more prominent for 3D features. For a tiny 28×28×4 28 28 4 28\times 28\times 4 28 × 28 × 4 feature volume, an efficient attention module uses less than 1/10 the memory and computation in comparison to a non-local module. On a larger 64×64×32 64 64 32 64\times 64\times 32 64 × 64 × 32 feature volume, a non-local module requires 513 times the memory and 1025 times the computation of an efficient attention module.
|
| 153 |
+
|
| 154 |
+
4 Experiments on the MS-COCO task suite
|
| 155 |
+
---------------------------------------
|
| 156 |
+
|
| 157 |
+
This section presents comparison experiments on the MS-COCO 2017 dataset for object detection and instance segmentation. The baseline is a ResNet-50 Mask R-CNN with a 5-level feature pyramid [[15](https://arxiv.org/html/1812.01243v10/#bib.bib15)]. More architectural details are in Appendix [A](https://arxiv.org/html/1812.01243v10/#A1 "Appendix A Architecture details for experiments on MS-COCO 2017 ‣ Efficient Attention: Attention with Linear Complexities"). The backbones initialize from ImageNet pretrainings. All other modules use random initialization. All models trained for 24 epochs on 32 NVIDIA TITAN Xp GPUs. The batch size is 64. The learning rate is 1.25×10−4 1.25 superscript 10 4 1.25\times 10^{-4}1.25 × 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT at the beginning of training and drops by a factor of 10 at the start of the 18th and 21st epochs. The experiments by default use softmax normalization, d k=d v=64 subscript 𝑑 𝑘 subscript 𝑑 𝑣 64 d_{k}=d_{v}=64 italic_d start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT = italic_d start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT = 64, and reprojection to the original number of channels.
|
| 158 |
+
|
| 159 |
+
### 4.1 Comparison experiments
|
| 160 |
+
|
| 161 |
+
#### 4.1.1 Comparison with the non-local module
|
| 162 |
+
|
| 163 |
+
Table [2](https://arxiv.org/html/1812.01243v10/#S4.T2 "Table 2 ‣ 4.1.1 Comparison with the non-local module ‣ 4.1 Comparison experiments ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities") reports the comparison against the non-local module. Efficient attention achieves substantially better performance-cost trade-off. As rows res3 to fpn5 show, inserting an efficient attention module or a non-local module at the same location in a network has nearly identical effects on the performance, while efficient attention uses orders of magnitude less resources. Rows res3-4+fpn3-5 and res3-4+fpn1-5 show that under the same resource cap (TITAN Xp GPU, 12 GB VRAM), efficient attention achieves significantly better performance. Note that res3-4+fpn3-5 is the best configuration that fits in memory for non-local modules. Further inserting non-local modules to fpn1 or fpn2 would require gigabytes of memory per example.
|
| 164 |
+
|
| 165 |
+
Table 2: Comparison between the efficient attention and non-local modules on MS-COCO 2017 object detection and instance segmentation.Box, mask, mem., and comp. stand for box AP, mask AP, memory (in bytes), and computation (in MACC), respectively. Mem. and comp. only count the attention module(s). res{x} and fpn{x} indicate inserting attention modules after the x 𝑥 x italic_x-th ResBlock group or FPN level x 𝑥 x italic_x, respectively. res{x-y} and fpn{x-y} similarly mean inserting after every ResBlock group or FPN level within the range [x,y]𝑥 𝑦[x,y][ italic_x , italic_y ]
|
| 166 |
+
|
| 167 |
+
#### 4.1.2 Comparison with competing methods
|
| 168 |
+
|
| 169 |
+
Table [3](https://arxiv.org/html/1812.01243v10/#S4.T3 "Table 3 ‣ 4.1.2 Comparison with competing methods ‣ 4.1 Comparison experiments ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities") shows the comparison of absolute performance and performance improvement with competing approaches on MS-COCO 2017 object detection and instance segmentation. EA models has the highest performance and performance improvement in all settings while using the least resources. Note that EA’s baseline models are significantly stronger, which make the improvements more valuable.
|
| 170 |
+
|
| 171 |
+
Table 3: Comparison vs. competing methods on MS-COCO 2017 object detection and instance segmentation. For each model, the number outside the parentheses is the AP, and the number inside is the AP improvement over baseline. The table reports number of parameters and amount of computation as a percentage increase over the baseline Mask R-CNN. The team obtained these metrics by measuring the official open-source implementations of [[29](https://arxiv.org/html/1812.01243v10/#bib.bib29), [27](https://arxiv.org/html/1812.01243v10/#bib.bib27)]. The table does not report results for CGNL with ResNet-101 and ResNeXt-101 since [[27](https://arxiv.org/html/1812.01243v10/#bib.bib27)] did not report such results. The Table omits parameters and computation for instance segmentation since all methods modified the backbone, which the bounding box and the instance mask branches share. Therefore, the table reports the total parameter and computation change only in the rows for object detection to avoid repetition
|
| 172 |
+
|
| 173 |
+
### 4.2 Ablation studies
|
| 174 |
+
|
| 175 |
+
#### 4.2.1 Attention normalization
|
| 176 |
+
|
| 177 |
+
These experiments empirically compared the two methods Section [3.2](https://arxiv.org/html/1812.01243v10/#S3.SS2 "3.2 Efficient attention ‣ 3 Method ‣ Efficient Attention: Attention with Linear Complexities") specified, namely scaling and softmax normalization. Table [4](https://arxiv.org/html/1812.01243v10/#S4.T4 "Table 4 ‣ 4.2.1 Attention normalization ‣ 4.2 Ablation studies ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities") reports the experimental outcomes. The results demonstrate that the effectiveness does not depend on the specific normalization method. Following [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)], all other experiments used softmax normalization.
|
| 178 |
+
|
| 179 |
+
Table 4: Experiments on attention normalization methods on MS-COCO 2017 object detection and instance segmentation. Experiments inserted efficient attention modules at fpn1-5
|
| 180 |
+
|
| 181 |
+
#### 4.2.2 Dimensionality of the keys
|
| 182 |
+
|
| 183 |
+
These experiments tested the impact of the dimensionality of the keys on the effect of efficient attention. As in Table [5](https://arxiv.org/html/1812.01243v10/#S4.T5 "Table 5 ‣ 4.2.2 Dimensionality of the keys ‣ 4.2 Ablation studies ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities"), decreasing the dimensionality of the keys from 128 to 32 caused minimal accuracy change. This result reinforces the hypothesis in Section [1](https://arxiv.org/html/1812.01243v10/#S1 "1 Introduction ‣ Efficient Attention: Attention with Linear Complexities") that most attention maps are expressible as linear combinations of a limited set of template attention maps. Therefore, researchers can reduce the dimensionality of the keys and queries in efficient attention modules to further save resources.
|
| 184 |
+
|
| 185 |
+
Table 5: Experiments on the dimensionality of the keys on MS-COCO 2017 object detection and instance segmentation. Experiments inserted efficient attention modules at res3-4+fpn3-5
|
| 186 |
+
|
| 187 |
+
5 Experiments on other tasks
|
| 188 |
+
----------------------------
|
| 189 |
+
|
| 190 |
+
### 5.1 Stereo depth estimation
|
| 191 |
+
|
| 192 |
+
The experiments on efficient attention for stereo depth estimation used the Scene Flow dataset, a large-scale synthesized dataset with 39824 stereo frame pairs. The baseline is PSMNet [[4](https://arxiv.org/html/1812.01243v10/#bib.bib4)], a clean model with near state-of-the-art performance. The experiments empirically determined the optimal hyperparamters, which significantly outperform the setting in [[4](https://arxiv.org/html/1812.01243v10/#bib.bib4)] (batch size is 24, learning rate is 2×10−3 2 superscript 10 3 2\times 10^{-3}2 × 10 start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT, training length is 100 epochs, and the rest is the same as in [[4](https://arxiv.org/html/1812.01243v10/#bib.bib4)]), as in Table [7](https://arxiv.org/html/1812.01243v10/#S5.T7 "Table 7 ‣ 5.1 Stereo depth estimation ‣ 5 Experiments on other tasks ‣ Efficient Attention: Attention with Linear Complexities"). On top of the strong baseline, inserting an efficient attention module after the last 3D hourglass leads to further improvement and achieves a new state-of-the-art. In comparison, inserting a non-local module at the same place would require an astronomical 9.68 TB of memory, prohibiting any attempt to verify its effectiveness. Table [8](https://arxiv.org/html/1812.01243v10/#S5.T8 "Table 8 ‣ 5.1 Stereo depth estimation ‣ 5 Experiments on other tasks ‣ Efficient Attention: Attention with Linear Complexities") compares EA-PSMNet with other state-of-the-art approaches and shows that it substantially outperforms all competing methods.
|
| 193 |
+
|
| 194 |
+
Table 6: Experiments on THUMOS14 temporal action localization.mAP@x stands for mean average precision at IoU threshold x 𝑥 x italic_x. EA R-C3D is this paper’s model. Both models used ResNet-50 as the backbone
|
| 195 |
+
|
| 196 |
+
Table 7: Experiments on Scene Flow stereo depth estimation.EPE stands for end-point error and is lower the better. EA-PSMNet is this paper’s model. OOM indicates out of memory. Memory only counts the attention module
|
| 197 |
+
|
| 198 |
+
Table 8: Comparison with the state-of-the-art on Scene Flow stereo depth estimation.EPE stands for end-point error and is lower the better. EA-PSMNet is this paper’s model
|
| 199 |
+
|
| 200 |
+
### 5.2 Temporal action localization
|
| 201 |
+
|
| 202 |
+
This section presents experiments for temporal action localization on the THUMOS14 [[12](https://arxiv.org/html/1812.01243v10/#bib.bib12)] dataset. The baseline is R-C3D [[25](https://arxiv.org/html/1812.01243v10/#bib.bib25)]. The experiment added two efficient attention modules after res3 and res4 in the ResNet-50 backbone. Table [6](https://arxiv.org/html/1812.01243v10/#S5.T6 "Table 6 ‣ 5.1 Stereo depth estimation ‣ 5 Experiments on other tasks ‣ Efficient Attention: Attention with Linear Complexities") presents the results. At the table shows, efficient attention substantially improved the performance for this task.
|
| 203 |
+
|
| 204 |
+
6 Visualization
|
| 205 |
+
---------------
|
| 206 |
+
|
| 207 |
+

|
| 208 |
+
|
| 209 |
+
Figure 3: Visualization of global attention maps. The left-most column displays 4 images from MS-COCO 2017. The other three columns show three of the corresponding global attention maps from the efficient attention module at FPN level 1 for each respective example.
|
| 210 |
+
|
| 211 |
+
Figure [3](https://arxiv.org/html/1812.01243v10/#S6.F3 "Figure 3 ‣ 6 Visualization ‣ Efficient Attention: Attention with Linear Complexities") shows visualization of the global attention maps for various examples from the efficient attention module at fpn1 in the model corresponding to the last row in Table [2](https://arxiv.org/html/1812.01243v10/#S4.T2 "Table 2 ‣ 4.1.1 Comparison with the non-local module ‣ 4.1 Comparison experiments ‣ 4 Experiments on the MS-COCO task suite ‣ Efficient Attention: Attention with Linear Complexities"). The figure illustrates 3 sets of global attention maps each with a distinct, semantic focus. Column 2 tends to capture the foreground, column 3 tends to capture the core parts of objects, and column 4 tends to capture the peripheral of objects. The semantic distinctiveness of each set of global attention maps supports the analysis in Section [1](https://arxiv.org/html/1812.01243v10/#S1 "1 Introduction ‣ Efficient Attention: Attention with Linear Complexities") that the attention maps are linear combinations of a set of template attention maps each focusing on a semantically significant area.
|
| 212 |
+
|
| 213 |
+
7 Conclusion
|
| 214 |
+
------------
|
| 215 |
+
|
| 216 |
+
This paper has presented the efficient attention mechanism, an attention mechanism that is quadratically more memory- and computationally-efficient than the widely adopted dot-product attention mechanism. By dramatically reducing the resource usage, efficient attention enables a large number of new use cases of attention, particularly in domains with tight resource constraints or large inputs.
|
| 217 |
+
|
| 218 |
+
The experiments verified its effectiveness on four distinct tasks, object detection, instance segmentation, and stereo depth estimation. It brought significant improvement for each task. On object detection and stereo depth estimation, efficient attention-augmented models have set new states-of-the-art. Besides the tasks this paper evaluated efficient attention on, it has promising potential in other fields where attention has demonstrated effectiveness. These fields include generative adversarial image modeling [[28](https://arxiv.org/html/1812.01243v10/#bib.bib28), [2](https://arxiv.org/html/1812.01243v10/#bib.bib2)] and most tasks in natural language processing [[22](https://arxiv.org/html/1812.01243v10/#bib.bib22), [19](https://arxiv.org/html/1812.01243v10/#bib.bib19), [7](https://arxiv.org/html/1812.01243v10/#bib.bib7), [20](https://arxiv.org/html/1812.01243v10/#bib.bib20)]. Future plans include generalizing efficient attention to these fields, as well as other fields where the prohibitive costs have been preventing the application of attention.
|
| 219 |
+
|
| 220 |
+
References
|
| 221 |
+
----------
|
| 222 |
+
|
| 223 |
+
* [1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
|
| 224 |
+
* [2] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018.
|
| 225 |
+
* [3] Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, and Han Hu. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In ICCV, 2019.
|
| 226 |
+
* [4] Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo matching network. In CVPR, 2018.
|
| 227 |
+
* [5] Xinjing Cheng, Peng Wang, and Ruigang Yang. Learning depth with convolutional spatial propagation network. arXiv preprint arXiv:1810.02695, 2018.
|
| 228 |
+
* [6] Xuelian Cheng, Yiran Zhong, Mehrtash Harandi, Yuchao Dai, Xiaojun Chang, Tom Drummond, Hongdong Li, and Zongyuan Ge. Hierarchical neural architecture search for deep stereo matching. arXiv preprint arXiv:2010.13501, 2020.
|
| 229 |
+
* [7] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
|
| 230 |
+
* [8] Linhao Dong, Shuang Xu, and Bo Xu. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In ICASSP, 2018.
|
| 231 |
+
* [9] Ruibing Hou, Hong Chang, MA Bingpeng, Shiguang Shan, and Xilin Chen. Cross attention network for few-shot classification. In NeurIPS, pages 4003–4014, 2019.
|
| 232 |
+
* [10] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018.
|
| 233 |
+
* [11] Tao Hu, Pascal Mettes, Jia-Hong Huang, and Cees GM Snoek. Silco: Show a few images, localize the common object. In ICCV, pages 5067–5076, 2019.
|
| 234 |
+
* [12] Y.-G. Jiang, J. Liu, A. Roshan Zamir, G. Toderici, I. Laptev, M. Shah, and R. Sukthankar. THUMOS challenge: Action recognition with a large number of classes. [http://crcv.ucf.edu/THUMOS14/](http://crcv.ucf.edu/THUMOS14/), 2014.
|
| 235 |
+
* [13] Guanbin Li, Xiang He, Wei Zhang, Huiyou Chang, Le Dong, and Liang Lin. Non-locally enhanced encoder-decoder network for single image de-raining. In ACMMM, 2018.
|
| 236 |
+
* [14] Xingyu Liao, Lingxiao He, and Zhouwang Yang. Video-based person re-identification via 3d convolutional networks and non-local attention. arXiv preprint arXiv:1807.05073, 2018.
|
| 237 |
+
* [15] Tsung-Yi Lin, Piotr Dollár, Ross B Girshick, Kaiming He, Bharath Hariharan, and Serge J Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
|
| 238 |
+
* [16] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. arXiv preprint arXiv:1806.02919, 2018.
|
| 239 |
+
* [17] Jiahao Pang, Wenxiu Sun, Jimmy SJ Ren, Chengxi Yang, and Qiong Yan. Cascade residual learning: A two-stage convolutional neural network for stereo matching. In ICCV 2017 Workshops, 2017.
|
| 240 |
+
* [18]Ngoc-Quan Pham, Thai-Son Nguyen, Jan Niehues, Markus Muller, and Alex Waibel. Very deep self-attention networks for end-to-end speech recognition. arXiv preprint arXiv:1904.13377, 2019.
|
| 241 |
+
* [19] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. OpenAI Blog, 2018.
|
| 242 |
+
* [20] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 2019.
|
| 243 |
+
* [21] Xiao Song, Xu Zhao, Hanwen Hu, and Liangji Fang. Edgestereo: A context integrated residual pyramid network for stereo matching. In ACCV, 2018.
|
| 244 |
+
* [22] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
|
| 245 |
+
* [23] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, 2018.
|
| 246 |
+
* [24] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In ECCV, 2018.
|
| 247 |
+
* [25] Huijuan Xu, Abir Das, and Kate Saenko. R-c3d: Region convolutional 3d network for temporal activity detection. In ICCV, 2017.
|
| 248 |
+
* [26] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237, 2019.
|
| 249 |
+
* [27] Kaiyu Yue, Ming Sun, Yuchen Yuan, Feng Zhou, Errui Ding, and Fuxin Xu. Compact generalized non-local network. In NeurIPS, 2018.
|
| 250 |
+
* [28] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318, 2018.
|
| 251 |
+
* [29] Songyang Zhang, Shipeng Yan, and Xuming He. LatentGNN: Learning efficient non-local relations for visual recognition. In ICML, 2019.
|
| 252 |
+
|
| 253 |
+
Appendix A Architecture details for experiments on MS-COCO 2017
|
| 254 |
+
---------------------------------------------------------------
|
| 255 |
+
|
| 256 |
+
Table [9](https://arxiv.org/html/1812.01243v10/#A1.T9 "Table 9 ‣ Appendix A Architecture details for experiments on MS-COCO 2017 ‣ Efficient Attention: Attention with Linear Complexities") details the architecture the experiments used on MS-COCO 2017.
|
| 257 |
+
|
| 258 |
+
Table 9: Architecture details for experiments on MS-COCO 2017 object detection and instance segmentation. This table assumes the backbone architecture is ResNet-50. For ResNet-101 and ResNeXt-101, the only difference will be the number of ResBlocks in each ResBlock group (res1-4) and/or the type of the blocks (ResNeXtBlock (32x4d) instead of ResBlock)
|
| 259 |
+
|
| 260 |
+
Appendix B Fine-grain metrics for experiments on MS-COCO 2017
|
| 261 |
+
-------------------------------------------------------------
|
| 262 |
+
|
| 263 |
+
Table [10](https://arxiv.org/html/1812.01243v10/#A2.T10 "Table 10 ‣ Appendix B Fine-grain metrics for experiments on MS-COCO 2017 ‣ Efficient Attention: Attention with Linear Complexities") presents fine-grain object detection metrics on MS-COCO 2017. Table [11](https://arxiv.org/html/1812.01243v10/#A2.T11 "Table 11 ‣ Appendix B Fine-grain metrics for experiments on MS-COCO 2017 ‣ Efficient Attention: Attention with Linear Complexities") presents find-grain instance segmentation metrics on MS-COCO 2017.
|
| 264 |
+
|
| 265 |
+
Table 10: Fine-grain metrics for experiments on MS-COCO 2017 object detection.+n NL means adding n non-local [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)] blocks to the backbone and FPN. +n EA means adding n EA modules to the backbone and FPN. OOM indicates out-of-memory errors
|
| 266 |
+
|
| 267 |
+
Table 11: Fine-grain metrics for experiments on MS-COCO 2017 instance segmentation.+n NL means adding n non-local [[23](https://arxiv.org/html/1812.01243v10/#bib.bib23)] blocks to the backbone and FPN. +n EA means adding n EA modules to the backbone and FPN. OOM indicates out-of-memory errors
|