

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -14,13 +14,12 @@ tags:
|
|
| 14 |
|
| 15 |
# CTNet
|
| 16 |
|
| 17 |
-
CTNet from Zhao, W et al (2024) .
|
| 18 |
|
| 19 |
-
> **Architecture-only repository.**
|
| 20 |
> `braindecode.models.CTNet` class. **No pretrained weights are
|
| 21 |
-
> distributed here**
|
| 22 |
-
> data
|
| 23 |
-
> separately.
|
| 24 |
|
| 25 |
## Quick start
|
| 26 |
|
|
@@ -39,166 +38,47 @@ model = CTNet(
|
|
| 39 |
)
|
| 40 |
```
|
| 41 |
|
| 42 |
-
The signal-shape arguments above are
|
| 43 |
-
|
| 44 |
|
| 45 |
## Documentation
|
| 46 |
-
|
| 47 |
-
-
|
| 48 |
-
<https://braindecode.org/stable/generated/braindecode.models.CTNet.html>
|
| 49 |
-
- Interactive browser with live instantiation:
|
| 50 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 51 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/ctnet.py#L27>
|
| 52 |
|
| 53 |
-
## Architecture description
|
| 54 |
-
|
| 55 |
-
The block below is the rendered class docstring (parameters,
|
| 56 |
-
references, architecture figure where available).
|
| 57 |
-
|
| 58 |
-
<div class='bd-doc'><main>
|
| 59 |
-
<p>CTNet from Zhao, W et al (2024) [ctnet]_.</p>
|
| 60 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#5cb85c;color:white;font-size:11px;font-weight:600;margin-right:4px;">Convolution</span><span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#56B4E9;color:white;font-size:11px;font-weight:600;margin-right:4px;">Attention/Transformer</span>
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
A Convolutional Transformer Network for EEG-Based Motor Imagery Classification
|
| 65 |
-
|
| 66 |
-
.. figure:: https://raw.githubusercontent.com/snailpt/CTNet/main/architecture.png
|
| 67 |
-
:align: center
|
| 68 |
-
:alt: CTNet Architecture
|
| 69 |
-
|
| 70 |
-
CTNet is an end-to-end neural network architecture designed for classifying motor imagery (MI) tasks from EEG signals.
|
| 71 |
-
The model combines convolutional neural networks (CNNs) with a Transformer encoder to capture both local and global temporal dependencies in the EEG data.
|
| 72 |
-
|
| 73 |
-
The architecture consists of three main components:
|
| 74 |
-
|
| 75 |
-
1. **Convolutional Module**:
|
| 76 |
-
|
| 77 |
-
- Apply :class:`EEGNet` to perform some feature extraction, denoted here as
|
| 78 |
-
_PatchEmbeddingEEGNet module.
|
| 79 |
-
|
| 80 |
-
2. **Transformer Encoder Module**:
|
| 81 |
-
|
| 82 |
-
- Utilizes multi-head self-attention mechanisms as EEGConformer but
|
| 83 |
-
with residual blocks.
|
| 84 |
-
|
| 85 |
-
3. **Classifier Module**:
|
| 86 |
-
|
| 87 |
-
- Combines features from both the convolutional module
|
| 88 |
-
and the Transformer encoder.
|
| 89 |
-
- Flattens the combined features and applies dropout for regularization.
|
| 90 |
-
- Uses a fully connected layer to produce the final classification output.
|
| 91 |
-
|
| 92 |
-
Parameters
|
| 93 |
-
----------
|
| 94 |
-
activation : nn.Module, default=nn.GELU
|
| 95 |
-
Activation function to use in the network.
|
| 96 |
-
num_heads : int, default=4
|
| 97 |
-
Number of attention heads in the Transformer encoder.
|
| 98 |
-
embed_dim : int or None, default=None
|
| 99 |
-
Embedding size (dimensionality) for the Transformer encoder.
|
| 100 |
-
num_layers : int, default=6
|
| 101 |
-
Number of encoder layers in the Transformer.
|
| 102 |
-
n_filters_time : int, default=20
|
| 103 |
-
Number of temporal filters in the first convolutional layer.
|
| 104 |
-
kernel_size : int, default=64
|
| 105 |
-
Kernel size for the temporal convolutional layer.
|
| 106 |
-
depth_multiplier : int, default=2
|
| 107 |
-
Multiplier for the number of depth-wise convolutional filters.
|
| 108 |
-
pool_size_1 : int, default=8
|
| 109 |
-
Pooling size for the first average pooling layer.
|
| 110 |
-
pool_size_2 : int, default=8
|
| 111 |
-
Pooling size for the second average pooling layer.
|
| 112 |
-
cnn_drop_prob: float, default=0.3
|
| 113 |
-
Dropout probability after convolutional layers.
|
| 114 |
-
att_positional_drop_prob : float, default=0.1
|
| 115 |
-
Dropout probability for the positional encoding in the Transformer.
|
| 116 |
-
final_drop_prob : float, default=0.5
|
| 117 |
-
Dropout probability before the final classification layer.
|
| 118 |
-
|
| 119 |
-
Notes
|
| 120 |
-
-----
|
| 121 |
-
This implementation is adapted from the original CTNet source code
|
| 122 |
-
[ctnetcode]_ to comply with Braindecode's model standards.
|
| 123 |
-
|
| 124 |
-
References
|
| 125 |
-
----------
|
| 126 |
-
.. [ctnet] Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024).
|
| 127 |
-
CTNet: a convolutional transformer network for EEG-based motor imagery
|
| 128 |
-
classification. Scientific Reports, 14(1), 20237.
|
| 129 |
-
.. [ctnetcode] Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024).
|
| 130 |
-
CTNet source code:
|
| 131 |
-
https://github.com/snailpt/CTNet
|
| 132 |
-
|
| 133 |
-
.. rubric:: Hugging Face Hub integration
|
| 134 |
-
|
| 135 |
-
When the optional ``huggingface_hub`` package is installed, all models
|
| 136 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 137 |
-
Hugging Face Hub. Install with::
|
| 138 |
-
|
| 139 |
-
pip install braindecode[hub]
|
| 140 |
-
|
| 141 |
-
**Pushing a model to the Hub:**
|
| 142 |
-
|
| 143 |
-
.. code::
|
| 144 |
-
from braindecode.models import CTNet
|
| 145 |
-
|
| 146 |
-
# Train your model
|
| 147 |
-
model = CTNet(n_chans=22, n_outputs=4, n_times=1000)
|
| 148 |
-
# ... training code ...
|
| 149 |
-
|
| 150 |
-
# Push to the Hub
|
| 151 |
-
model.push_to_hub(
|
| 152 |
-
repo_id="username/my-ctnet-model",
|
| 153 |
-
commit_message="Initial model upload",
|
| 154 |
-
)
|
| 155 |
|
| 156 |
-
|
| 157 |
|
| 158 |
-
..
|
| 159 |
-
from braindecode.models import CTNet
|
| 160 |
|
| 161 |
-
# Load pretrained model
|
| 162 |
-
model = CTNet.from_pretrained("username/my-ctnet-model")
|
| 163 |
|
| 164 |
-
|
| 165 |
-
model = CTNet.from_pretrained("username/my-ctnet-model", n_outputs=4)
|
| 166 |
|
| 167 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 168 |
|
| 169 |
-
.. code::
|
| 170 |
-
import torch
|
| 171 |
|
| 172 |
-
|
| 173 |
-
# Extract encoder features (consistent dict across all models)
|
| 174 |
-
out = model(x, return_features=True)
|
| 175 |
-
features = out["features"]
|
| 176 |
|
| 177 |
-
|
| 178 |
-
|
| 179 |
|
| 180 |
-
**Saving and restoring full configuration:**
|
| 181 |
-
|
| 182 |
-
.. code::
|
| 183 |
-
import json
|
| 184 |
-
|
| 185 |
-
config = model.get_config() # all __init__ params
|
| 186 |
-
with open("config.json", "w") as f:
|
| 187 |
-
json.dump(config, f)
|
| 188 |
-
|
| 189 |
-
model2 = CTNet.from_config(config) # reconstruct (no weights)
|
| 190 |
-
|
| 191 |
-
All model parameters (both EEG-specific and model-specific such as
|
| 192 |
-
dropout rates, activation functions, number of filters) are automatically
|
| 193 |
-
saved to the Hub and restored when loading.
|
| 194 |
-
|
| 195 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 196 |
-
</div>
|
| 197 |
|
| 198 |
## Citation
|
| 199 |
|
| 200 |
-
|
| 201 |
-
*References* section above) and braindecode:
|
| 202 |
|
| 203 |
```bibtex
|
| 204 |
@article{aristimunha2025braindecode,
|
|
|
|
| 14 |
|
| 15 |
# CTNet
|
| 16 |
|
| 17 |
+
CTNet from Zhao, W et al (2024) [ctnet].
|
| 18 |
|
| 19 |
+
> **Architecture-only repository.** Documents the
|
| 20 |
> `braindecode.models.CTNet` class. **No pretrained weights are
|
| 21 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 22 |
+
> data.
|
|
|
|
| 23 |
|
| 24 |
## Quick start
|
| 25 |
|
|
|
|
| 38 |
)
|
| 39 |
```
|
| 40 |
|
| 41 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 42 |
+
match your recording.
|
| 43 |
|
| 44 |
## Documentation
|
| 45 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.CTNet.html>
|
| 46 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 47 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 48 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/ctnet.py#L27>
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
## Architecture
|
| 52 |
|
| 53 |
+
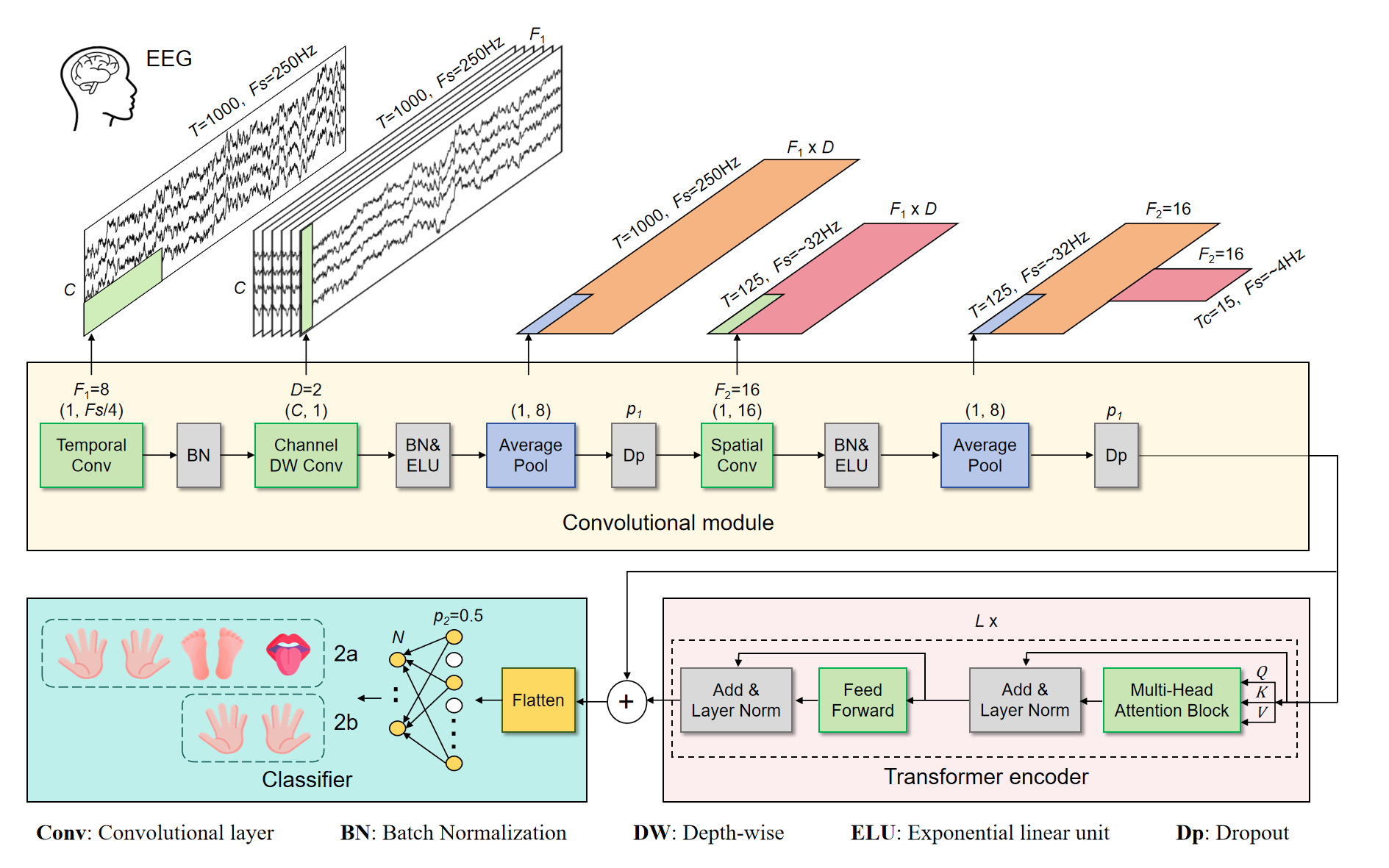
|
|
|
|
| 54 |
|
|
|
|
|
|
|
| 55 |
|
| 56 |
+
## Parameters
|
|
|
|
| 57 |
|
| 58 |
+
| Parameter | Type | Description |
|
| 59 |
+
|---|---|---|
|
| 60 |
+
| `activation` | nn.Module, default=nn.GELU | Activation function to use in the network. |
|
| 61 |
+
| `num_heads` | int, default=4 | Number of attention heads in the Transformer encoder. |
|
| 62 |
+
| `embed_dim` | int or None, default=None | Embedding size (dimensionality) for the Transformer encoder. |
|
| 63 |
+
| `num_layers` | int, default=6 | Number of encoder layers in the Transformer. |
|
| 64 |
+
| `n_filters_time` | int, default=20 | Number of temporal filters in the first convolutional layer. |
|
| 65 |
+
| `kernel_size` | int, default=64 | Kernel size for the temporal convolutional layer. |
|
| 66 |
+
| `depth_multiplier` | int, default=2 | Multiplier for the number of depth-wise convolutional filters. |
|
| 67 |
+
| `pool_size_1` | int, default=8 | Pooling size for the first average pooling layer. |
|
| 68 |
+
| `pool_size_2` | int, default=8 | Pooling size for the second average pooling layer. cnn_drop_prob: float, default=0.3 Dropout probability after convolutional layers. |
|
| 69 |
+
| `att_positional_drop_prob` | float, default=0.1 | Dropout probability for the positional encoding in the Transformer. |
|
| 70 |
+
| `final_drop_prob` | float, default=0.5 | Dropout probability before the final classification layer. |
|
| 71 |
|
|
|
|
|
|
|
| 72 |
|
| 73 |
+
## References
|
|
|
|
|
|
|
|
|
|
| 74 |
|
| 75 |
+
1. Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024). CTNet: a convolutional transformer network for EEG-based motor imagery classification. Scientific Reports, 14(1), 20237.
|
| 76 |
+
2. Zhao, W., Jiang, X., Zhang, B., Xiao, S., & Weng, S. (2024). CTNet source code: https://github.com/snailpt/CTNet
|
| 77 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 78 |
|
| 79 |
## Citation
|
| 80 |
|
| 81 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 82 |
|
| 83 |
```bibtex
|
| 84 |
@article{aristimunha2025braindecode,
|