
Commit ·
bfc01ab
1
Parent(s): bfea71b
uploaded weights
Browse files- LICENSE +24 -0
- README.md +33 -3
- config.json +3 -0
- flow_upscaler.safetensors +3 -0
- upscaler_unet.py +397 -0
LICENSE
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
This is free and unencumbered software released into the public domain.
|
| 2 |
+
|
| 3 |
+
Anyone is free to copy, modify, publish, use, compile, sell, or
|
| 4 |
+
distribute this software, either in source code form or as a compiled
|
| 5 |
+
binary, for any purpose, commercial or non-commercial, and by any
|
| 6 |
+
means.
|
| 7 |
+
|
| 8 |
+
In jurisdictions that recognize copyright laws, the author or authors
|
| 9 |
+
of this software dedicate any and all copyright interest in the
|
| 10 |
+
software to the public domain. We make this dedication for the benefit
|
| 11 |
+
of the public at large and to the detriment of our heirs and
|
| 12 |
+
successors. We intend this dedication to be an overt act of
|
| 13 |
+
relinquishment in perpetuity of all present and future rights to this
|
| 14 |
+
software under copyright law.
|
| 15 |
+
|
| 16 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
|
| 17 |
+
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
|
| 18 |
+
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
|
| 19 |
+
IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
|
| 20 |
+
OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
|
| 21 |
+
ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
|
| 22 |
+
OTHER DEALINGS IN THE SOFTWARE.
|
| 23 |
+
|
| 24 |
+
For more information, please refer to <https://unlicense.org/>
|
README.md
CHANGED
|
@@ -1,3 +1,33 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Flow Upscaler
|
| 2 |
+
|
| 3 |
+
**Flow Upscaler** is a fast Latent Upscaler model that works in [Flux.2](https://bfl.ai/models/flux-2) latent space.
|
| 4 |
+
|
| 5 |
+
Under the hood, it is a lightweight **Rectified flow** model with **59M** parameters generating upscaled latents in just one denoising step.
|
| 6 |
+
|
| 7 |
+
**[ComfyUI Node](https://github.com/TensorForger/comfyui-flow-upscaler)**
|
| 8 |
+
|
| 9 |
+
Features:
|
| 10 |
+
|
| 11 |
+
* Upscaling latents for image from **512x512** to **1024x1024** on RTX 5090 takes **7ms**
|
| 12 |
+
* The model is trained only for **2X** upscaling, but you can chain it many times up to **8K** resolution
|
| 13 |
+
* The training process involves **Flow Distillation** with Flux.2 as a teacher what forces it to understand image semantic very well
|
| 14 |
+
|
| 15 |
+
Here is one **4X** upscaled image (two passes):
|
| 16 |
+

|
| 17 |
+
|
| 18 |
+
## How it works
|
| 19 |
+
|
| 20 |
+
Architecturally, Flow Upscaler is a Unet with SDXL-style ResNet blocks. It takes the noisy sample on input and predicts velocity on output. This generation process happens in high resolution space. The low resolution latents are passed in a separate conditioning encoder that emits control signals that are passed to main Unet encoder through FiLM conditioning.
|
| 21 |
+
|
| 22 |
+
No attention is used, so compute scales linearly with image area. This makes generation in 8K possible.
|
| 23 |
+
|
| 24 |
+
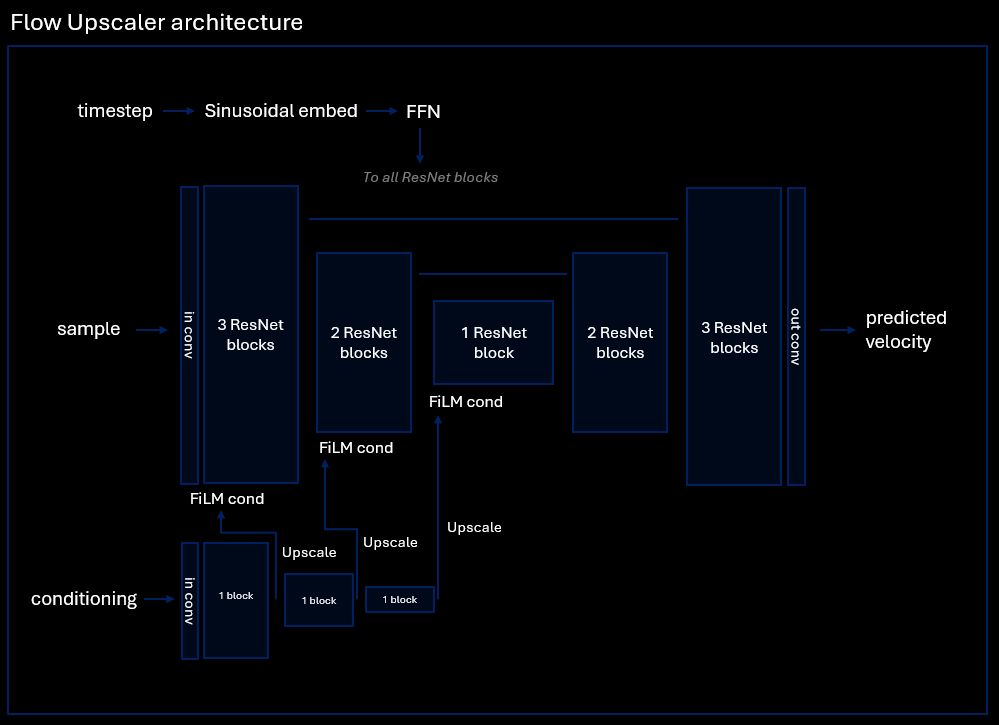
|
| 25 |
+
|
| 26 |
+
The model is trained through Flow Distillation with Flux.2-klein-4B as a teacher. We generated 20K various images with Flux storing initial noise, generated latents and downscaled latents for conditioning. The downscaled latents are generated throgh decoding high resolution latents, downscaling in pixel space and encoding back to latents because downscaling directly in latents breaks some "latent patterns" that makes image blurry if you decode it.
|
| 27 |
+
|
| 28 |
+
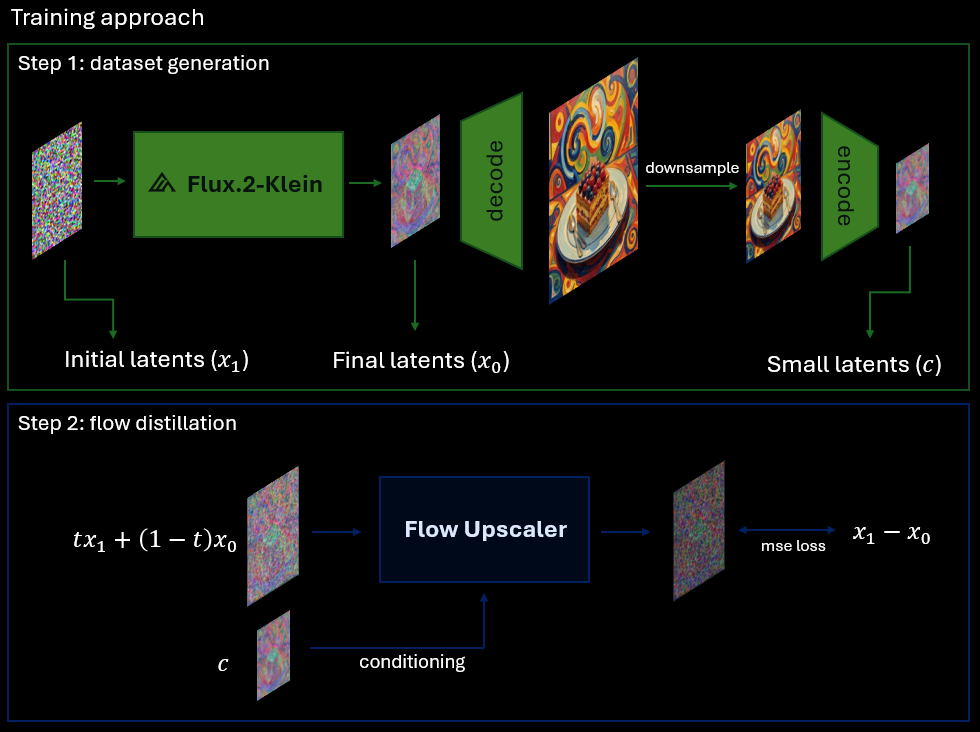
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
## Training code
|
| 32 |
+
|
| 33 |
+
If you want to explore training code or use model outside of ComfyUI directly from code, see `notebooks/flow_upscaler` in [https://github.com/tensorforger/CTGMWorkshop](https://github.com/tensorforger/CTGMWorkshop)
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_type": "custom"
|
| 3 |
+
}
|
flow_upscaler.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:91eb93b40179441e569e01fe04f20fd9b951e434f88c84dd0ba523f830a81839
|
| 3 |
+
size 237085968
|
upscaler_unet.py
ADDED
|
@@ -0,0 +1,397 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def make_group_norm(
|
| 7 |
+
channels: int, max_groups: int = 32, eps: float = 1e-6
|
| 8 |
+
) -> nn.GroupNorm:
|
| 9 |
+
groups = min(max_groups, channels)
|
| 10 |
+
while channels % groups != 0 and groups > 1:
|
| 11 |
+
groups -= 1
|
| 12 |
+
return nn.GroupNorm(groups, channels, eps=eps)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class SinusoidalTimeEmbedding(nn.Module):
|
| 16 |
+
def __init__(self, dim: int = 128, max_period: int = 10000):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.dim = dim
|
| 19 |
+
self.max_period = max_period
|
| 20 |
+
|
| 21 |
+
def forward(self, timesteps: torch.Tensor) -> torch.Tensor:
|
| 22 |
+
half = self.dim // 2
|
| 23 |
+
|
| 24 |
+
freqs = torch.exp(
|
| 25 |
+
-torch.log(torch.tensor(float(self.max_period), device=timesteps.device))
|
| 26 |
+
* torch.arange(half, device=timesteps.device, dtype=timesteps.dtype)
|
| 27 |
+
/ half
|
| 28 |
+
)
|
| 29 |
+
args = timesteps[:, None] * freqs[None]
|
| 30 |
+
emb = torch.cat([torch.sin(args), torch.cos(args)], dim=-1)
|
| 31 |
+
|
| 32 |
+
if self.dim % 2 == 1:
|
| 33 |
+
emb = F.pad(emb, (0, 1))
|
| 34 |
+
|
| 35 |
+
return emb
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class ConditioningEncoder(nn.Module):
|
| 39 |
+
def __init__(self, time_dim: int = 128, cond_dim: int = 256):
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.time_embed = SinusoidalTimeEmbedding(time_dim)
|
| 42 |
+
|
| 43 |
+
self.time_proj = nn.Sequential(
|
| 44 |
+
nn.Linear(time_dim, cond_dim),
|
| 45 |
+
nn.SiLU(),
|
| 46 |
+
nn.Linear(cond_dim, cond_dim),
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
def forward(self, timestep: torch.Tensor) -> torch.Tensor:
|
| 50 |
+
time_vec = self.time_proj(self.time_embed(timestep))
|
| 51 |
+
return time_vec
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class ConditionedResidualBlock(nn.Module):
|
| 55 |
+
"""
|
| 56 |
+
SDXL-style residual block:
|
| 57 |
+
GN -> SiLU -> Conv
|
| 58 |
+
+ condition (scale/shift)
|
| 59 |
+
GN -> SiLU -> Dropout -> Conv
|
| 60 |
+
+ skip connection
|
| 61 |
+
"""
|
| 62 |
+
|
| 63 |
+
def __init__(
|
| 64 |
+
self,
|
| 65 |
+
input_channels: int,
|
| 66 |
+
output_channels: int,
|
| 67 |
+
cond_dim: int = 256,
|
| 68 |
+
dropout: float = 0.0,
|
| 69 |
+
):
|
| 70 |
+
super().__init__()
|
| 71 |
+
|
| 72 |
+
self.norm1 = make_group_norm(input_channels)
|
| 73 |
+
self.conv1 = nn.Conv2d(
|
| 74 |
+
input_channels, output_channels, kernel_size=3, padding=1
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
self.cond_proj = nn.Sequential(
|
| 78 |
+
nn.SiLU(),
|
| 79 |
+
nn.Linear(cond_dim, 2 * output_channels),
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
self.norm2 = make_group_norm(output_channels)
|
| 83 |
+
self.dropout = nn.Dropout(dropout)
|
| 84 |
+
self.conv2 = nn.Conv2d(
|
| 85 |
+
output_channels, output_channels, kernel_size=3, padding=1
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
if input_channels != output_channels:
|
| 89 |
+
self.skip = nn.Conv2d(
|
| 90 |
+
input_channels, output_channels, kernel_size=1, bias=False
|
| 91 |
+
)
|
| 92 |
+
else:
|
| 93 |
+
self.skip = nn.Identity()
|
| 94 |
+
|
| 95 |
+
def forward(self, x: torch.Tensor, cond: torch.Tensor) -> torch.Tensor:
|
| 96 |
+
residual = self.skip(x)
|
| 97 |
+
|
| 98 |
+
h = self.norm1(x)
|
| 99 |
+
h = F.silu(h)
|
| 100 |
+
h = self.conv1(h)
|
| 101 |
+
|
| 102 |
+
scale_shift = self.cond_proj(cond)
|
| 103 |
+
scale, shift = scale_shift.chunk(2, dim=1)
|
| 104 |
+
|
| 105 |
+
h = self.norm2(h)
|
| 106 |
+
h = h * (1 + scale[:, :, None, None]) + shift[:, :, None, None]
|
| 107 |
+
h = F.silu(h)
|
| 108 |
+
h = self.dropout(h)
|
| 109 |
+
h = self.conv2(h)
|
| 110 |
+
|
| 111 |
+
return h + residual
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class DownStage(nn.Module):
|
| 115 |
+
def __init__(
|
| 116 |
+
self,
|
| 117 |
+
input_channels: int,
|
| 118 |
+
output_channels: int,
|
| 119 |
+
cond_dim: int = 256,
|
| 120 |
+
dropout: float = 0.0,
|
| 121 |
+
num_blocks: int = 1,
|
| 122 |
+
downsample_first: bool = False,
|
| 123 |
+
):
|
| 124 |
+
super().__init__()
|
| 125 |
+
self.downsample_first = downsample_first
|
| 126 |
+
|
| 127 |
+
self.blocks = nn.ModuleList()
|
| 128 |
+
for i in range(num_blocks):
|
| 129 |
+
in_ch = input_channels if i == 0 else output_channels
|
| 130 |
+
self.blocks.append(
|
| 131 |
+
ConditionedResidualBlock(
|
| 132 |
+
input_channels=in_ch,
|
| 133 |
+
output_channels=output_channels,
|
| 134 |
+
cond_dim=cond_dim,
|
| 135 |
+
dropout=dropout,
|
| 136 |
+
)
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
self.downsample = nn.Conv2d(
|
| 140 |
+
output_channels, output_channels, kernel_size=3, stride=2, padding=1
|
| 141 |
+
)
|
| 142 |
+
|
| 143 |
+
def forward(self, x: torch.Tensor, cond: torch.Tensor):
|
| 144 |
+
|
| 145 |
+
if self.downsample_first:
|
| 146 |
+
x = self.downsample(x)
|
| 147 |
+
|
| 148 |
+
for block in self.blocks:
|
| 149 |
+
x = block(x, cond)
|
| 150 |
+
skip = x
|
| 151 |
+
|
| 152 |
+
if not self.downsample_first:
|
| 153 |
+
x = self.downsample(x)
|
| 154 |
+
|
| 155 |
+
return x, skip
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
class UpStage(nn.Module):
|
| 159 |
+
def __init__(
|
| 160 |
+
self,
|
| 161 |
+
input_channels: int,
|
| 162 |
+
skip_channels: int,
|
| 163 |
+
output_channels: int,
|
| 164 |
+
cond_dim: int = 256,
|
| 165 |
+
dropout: float = 0.0,
|
| 166 |
+
num_blocks: int = 1,
|
| 167 |
+
):
|
| 168 |
+
super().__init__()
|
| 169 |
+
|
| 170 |
+
self.upsample = nn.Upsample(
|
| 171 |
+
scale_factor=2, mode="bilinear", align_corners=False
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
self.blocks = nn.ModuleList()
|
| 175 |
+
for i in range(num_blocks):
|
| 176 |
+
in_ch = (input_channels + skip_channels) if i == 0 else output_channels
|
| 177 |
+
self.blocks.append(
|
| 178 |
+
ConditionedResidualBlock(
|
| 179 |
+
input_channels=in_ch,
|
| 180 |
+
output_channels=output_channels,
|
| 181 |
+
cond_dim=cond_dim,
|
| 182 |
+
dropout=dropout,
|
| 183 |
+
)
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
def forward(
|
| 187 |
+
self, x: torch.Tensor, skip: torch.Tensor, cond: torch.Tensor
|
| 188 |
+
) -> torch.Tensor:
|
| 189 |
+
x = self.upsample(x)
|
| 190 |
+
|
| 191 |
+
if x.shape[-2:] != skip.shape[-2:]:
|
| 192 |
+
x = F.interpolate(
|
| 193 |
+
x, size=skip.shape[-2:], mode="bilinear", align_corners=False
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
x = torch.cat([x, skip], dim=1)
|
| 197 |
+
|
| 198 |
+
for block in self.blocks:
|
| 199 |
+
x = block(x, cond)
|
| 200 |
+
|
| 201 |
+
return x
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class LowResEncoder(nn.Module):
|
| 205 |
+
def __init__(
|
| 206 |
+
self,
|
| 207 |
+
sample_channels: int = 32,
|
| 208 |
+
base_channels: int = 128,
|
| 209 |
+
cond_dim: int = 1024,
|
| 210 |
+
dropout: float = 0.0,
|
| 211 |
+
):
|
| 212 |
+
super().__init__()
|
| 213 |
+
|
| 214 |
+
self.in_conv = nn.Conv2d(
|
| 215 |
+
sample_channels, base_channels, kernel_size=1, padding=0
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
self.block_1 = ConditionedResidualBlock(
|
| 219 |
+
input_channels=base_channels,
|
| 220 |
+
output_channels=base_channels,
|
| 221 |
+
cond_dim=cond_dim,
|
| 222 |
+
dropout=dropout,
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
self.block_2 = DownStage(
|
| 226 |
+
input_channels=base_channels,
|
| 227 |
+
output_channels=base_channels,
|
| 228 |
+
cond_dim=cond_dim,
|
| 229 |
+
dropout=dropout,
|
| 230 |
+
num_blocks=1,
|
| 231 |
+
downsample_first=True,
|
| 232 |
+
)
|
| 233 |
+
|
| 234 |
+
self.block_3 = DownStage(
|
| 235 |
+
input_channels=base_channels,
|
| 236 |
+
output_channels=base_channels,
|
| 237 |
+
cond_dim=cond_dim,
|
| 238 |
+
dropout=dropout,
|
| 239 |
+
num_blocks=1,
|
| 240 |
+
downsample_first=True,
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
def forward(self, latents_small, cond):
|
| 244 |
+
x = self.in_conv(latents_small)
|
| 245 |
+
block_1_out = self.block_1(x, cond)
|
| 246 |
+
block_2_out, _ = self.block_2(block_1_out, cond)
|
| 247 |
+
block_3_out, _ = self.block_3(block_2_out, cond)
|
| 248 |
+
|
| 249 |
+
return block_1_out, block_2_out, block_3_out
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
class FilmCond2D(nn.Module):
|
| 253 |
+
def __init__(self, base_channels: int = 256, cond_channels: int = 256):
|
| 254 |
+
super().__init__()
|
| 255 |
+
|
| 256 |
+
self.cond_proj = nn.Sequential(
|
| 257 |
+
nn.SiLU(),
|
| 258 |
+
nn.Conv2d(cond_channels, base_channels * 2, kernel_size=1),
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
def forward(self, x, cond):
|
| 262 |
+
scale_shift = self.cond_proj(cond)
|
| 263 |
+
scale, shift = scale_shift.chunk(2, dim=1)
|
| 264 |
+
|
| 265 |
+
x = x * (1 + scale) + shift
|
| 266 |
+
|
| 267 |
+
return x
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
class UpscalerUNet(nn.Module):
|
| 271 |
+
def __init__(
|
| 272 |
+
self,
|
| 273 |
+
sample_channels: int = 32,
|
| 274 |
+
base_channels: int = 384,
|
| 275 |
+
time_dim: int = 512,
|
| 276 |
+
cond_dim: int = 1024,
|
| 277 |
+
dropout: float = 0.01,
|
| 278 |
+
):
|
| 279 |
+
super().__init__()
|
| 280 |
+
|
| 281 |
+
self.conditioning = ConditioningEncoder(
|
| 282 |
+
time_dim=time_dim,
|
| 283 |
+
cond_dim=cond_dim,
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
self.in_conv = nn.Conv2d(
|
| 287 |
+
sample_channels, base_channels, kernel_size=1, padding=0
|
| 288 |
+
)
|
| 289 |
+
|
| 290 |
+
self.low_res_encoder = LowResEncoder(base_channels=base_channels)
|
| 291 |
+
|
| 292 |
+
self.film_cond_1 = FilmCond2D(
|
| 293 |
+
base_channels=base_channels, cond_channels=base_channels
|
| 294 |
+
)
|
| 295 |
+
self.film_cond_2 = FilmCond2D(
|
| 296 |
+
base_channels=base_channels, cond_channels=base_channels
|
| 297 |
+
)
|
| 298 |
+
self.film_cond_3 = FilmCond2D(
|
| 299 |
+
base_channels=base_channels, cond_channels=base_channels
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
self.down_stages = nn.ModuleList(
|
| 303 |
+
[
|
| 304 |
+
DownStage(
|
| 305 |
+
input_channels=base_channels,
|
| 306 |
+
output_channels=base_channels,
|
| 307 |
+
cond_dim=cond_dim,
|
| 308 |
+
dropout=dropout,
|
| 309 |
+
num_blocks=3,
|
| 310 |
+
),
|
| 311 |
+
DownStage(
|
| 312 |
+
input_channels=base_channels,
|
| 313 |
+
output_channels=base_channels,
|
| 314 |
+
cond_dim=cond_dim,
|
| 315 |
+
dropout=dropout,
|
| 316 |
+
num_blocks=2,
|
| 317 |
+
),
|
| 318 |
+
]
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
self.mid_stages = nn.ModuleList(
|
| 322 |
+
[
|
| 323 |
+
ConditionedResidualBlock(
|
| 324 |
+
input_channels=base_channels,
|
| 325 |
+
output_channels=base_channels,
|
| 326 |
+
cond_dim=cond_dim,
|
| 327 |
+
dropout=dropout,
|
| 328 |
+
)
|
| 329 |
+
for i in range(1)
|
| 330 |
+
]
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
self.up_stages = nn.ModuleList(
|
| 334 |
+
[
|
| 335 |
+
UpStage(
|
| 336 |
+
input_channels=base_channels,
|
| 337 |
+
skip_channels=base_channels,
|
| 338 |
+
output_channels=base_channels,
|
| 339 |
+
cond_dim=cond_dim,
|
| 340 |
+
dropout=dropout,
|
| 341 |
+
num_blocks=2,
|
| 342 |
+
),
|
| 343 |
+
UpStage(
|
| 344 |
+
input_channels=base_channels,
|
| 345 |
+
skip_channels=base_channels,
|
| 346 |
+
output_channels=base_channels,
|
| 347 |
+
cond_dim=cond_dim,
|
| 348 |
+
dropout=dropout,
|
| 349 |
+
num_blocks=3,
|
| 350 |
+
),
|
| 351 |
+
]
|
| 352 |
+
)
|
| 353 |
+
|
| 354 |
+
self.out_conv = nn.Conv2d(
|
| 355 |
+
base_channels, sample_channels, kernel_size=1, padding=0
|
| 356 |
+
)
|
| 357 |
+
|
| 358 |
+
def forward(
|
| 359 |
+
self, sample: torch.Tensor, timestep: torch.Tensor, latents_small: torch.Tensor
|
| 360 |
+
) -> torch.Tensor:
|
| 361 |
+
cond = self.conditioning(timestep)
|
| 362 |
+
|
| 363 |
+
B, C, H, W = sample.shape
|
| 364 |
+
|
| 365 |
+
lr_cond_1, lr_cond_2, lr_cond_3 = self.low_res_encoder(latents_small, cond)
|
| 366 |
+
|
| 367 |
+
lr_cond_1 = torch.nn.functional.interpolate(lr_cond_1, (H, W), mode="bilinear")
|
| 368 |
+
lr_cond_2 = torch.nn.functional.interpolate(
|
| 369 |
+
lr_cond_2, (H // 2, W // 2), mode="bilinear"
|
| 370 |
+
)
|
| 371 |
+
lr_cond_3 = torch.nn.functional.interpolate(
|
| 372 |
+
lr_cond_3, (H // 4, W // 4), mode="bilinear"
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
x = self.in_conv(sample)
|
| 376 |
+
x = self.film_cond_1(x, lr_cond_1)
|
| 377 |
+
|
| 378 |
+
skips = []
|
| 379 |
+
|
| 380 |
+
x, skip = self.down_stages[0](x, cond)
|
| 381 |
+
skips.append(skip)
|
| 382 |
+
|
| 383 |
+
x = self.film_cond_2(x, lr_cond_2)
|
| 384 |
+
|
| 385 |
+
x, skip = self.down_stages[1](x, cond)
|
| 386 |
+
skips.append(skip)
|
| 387 |
+
|
| 388 |
+
x = self.film_cond_3(x, lr_cond_3)
|
| 389 |
+
|
| 390 |
+
for mid in self.mid_stages:
|
| 391 |
+
x = mid(x, cond)
|
| 392 |
+
|
| 393 |
+
for up in self.up_stages:
|
| 394 |
+
x = up(x, skips.pop(), cond)
|
| 395 |
+
|
| 396 |
+
x = self.out_conv(x)
|
| 397 |
+
return x
|